這篇文章講解:
- 把 Agent 和 Fine-Tuning 的知識串起來,在更高的技術視角看大模型應用;
- 加深對 Agent 工作原理的理解;
- 加深對 Fine-Tuning 訓練數據處理的理解。
1. 認識大模型 Agent
1.1 大模型 Agent 的應用場景
揭秘Agent核心原理與企業級應用場景
再設想以下幾個和 AI 交互的場景,并思考有什么特點:
- 幫我查一下今天的銷售額?
- (開車時)前方為啥堵車了?
- 上海天氣如何?
再比如:
- 幫我訂一張周五去上海的機票;
- 請幫我約一個和搜索產品部的需求溝通會,本周三至周五我日歷上空閑的時間都可以。
【重點】大模型應用需要 Agent 技術的原因:
- 大模型的“幻覺”問題,很難在從模型本身上徹底解決,在嚴肅的應用場景需要通過引入外部知識確保答案的準確;
- 大模型參數無法做到實時更新,本身也無法與真實世界產生實時連接,在多數場景下難以滿足實際需求;
- 復雜的業務場景,不是一問一答就能解決的,需要任務拆解、多步執行與交互。
大模型應用,不僅要“會說話”,更要“會做事”!
1.2 大模型 Agent 的技術框架?
?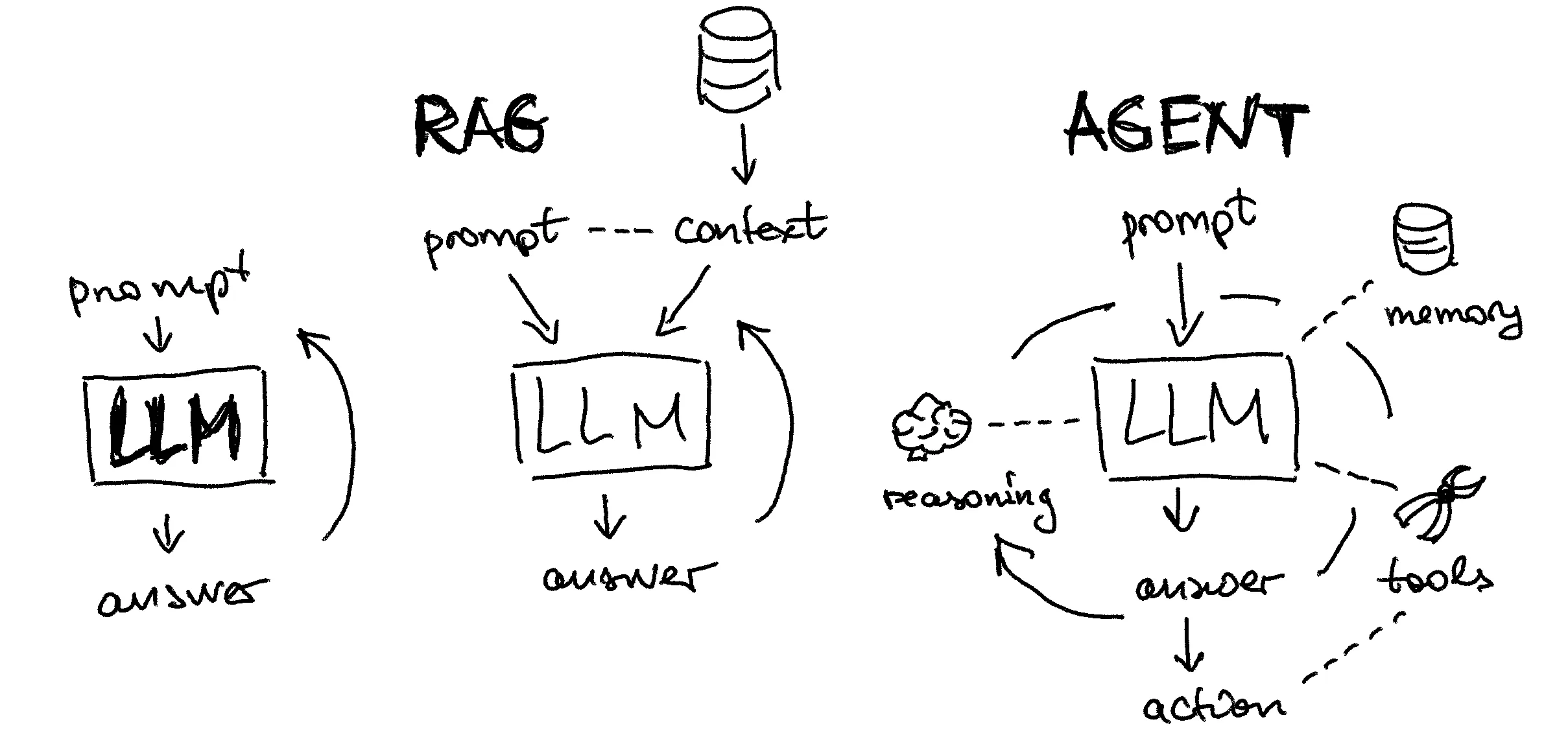 ?
?
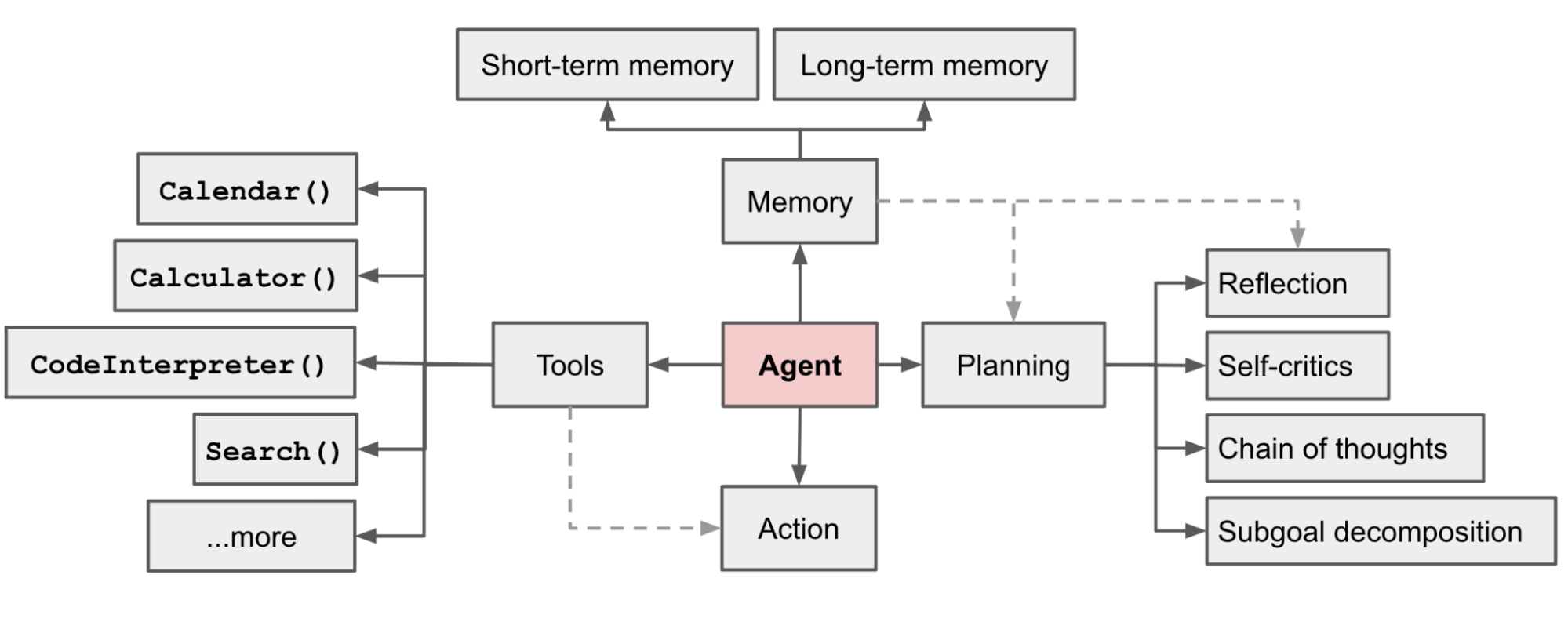 ??
??
1.3 為什么需要做 Agent Tuning ?
如何實現 Agent?利用 Prompt Engineering 可以實現嗎?
答案顯然是可以!前面學的 AutoGPT 就是例子。
既然通過 Prompt Engineering 可以實現 Agent,那為什么還要訓練 Agent 模型呢?
【重點】因為可以這么做的前提是:模型足夠“聰明”,靠看“說明書”就能執行, Prompt Engineering 實際上是把“說明書”寫得更加清晰易懂。
- 實踐證明,除了 GPT-4 level 的大模型,其他大模型(包括 GPT-3.5 )無法很好遵從 prompt 要求完成復雜的 Agent 任務;
- 很多場景下無法使用最強的大模型 API ,需要私有化部署小模型,需要控制推理成本;
- 通過訓練,一個小參數量的大模型(13B、7B等)也能達到較好的能力,更加實用。
?1.4 Agent Tuning 的研發流程
? ?
?
訓練成本參考:
-
訓練框架: HuggingFace Trainer + DeepSpeed Zero3
-
配置說明:max_len:4096 + Flash Attention + bf16 (batchsize=1、AdamW優化器)
| 模型 | 訓練最低配置 | 訓練數據規模(token數) | 建議訓練 epoch 數 | 平均訓練時長 | 訓練成本(估算) |
|---|---|---|---|---|---|
| 7B (全參數) | 4卡A100(4 * 80G) | 470M | 5 | 25h * 5 = 125h | 34.742 * 4 * 125 = 17371.0 元 |
| 14B (全參數) | 8卡A100(8 * 80G) | 470M | 4 | 24h * 4 = 96h | 34.742 * 8 * 96 = 26681.9 元 |
| 72B (全參數) | 32卡A100(32 * 80G) | 470M | 2 | 40h * 2 = 80h | 34.742 * 32 * 80 = 88939.5 元 |
- 以當前阿里云 A100 租用價格計算:
 ?
?
2. Agent Prompt 模板設計
常見的 Agent Prompt 模板,除了大家學習過的 AutoGPT 外,還有 ReACT、ModelScope、ToolLLaMA 等不同的形式。
2.1 主流 Agent Prompt 模板
| 模版 | 描述 | 優點 | 缺點 |
|---|---|---|---|
| ReACT | ReACT prompt較為簡單,先設定Question,再以Thought、Action、Action Input、Observation執行多輪,最后輸出Final Answer | prompt 簡單 | 1. API 參數只能有一個 2. 沒有設定反思等行為,對于錯誤的思考不能及時糾正 |
| ModelScope | 更為直接的生成回復,調用只需要加入<|startofthink|>和<|endofthink|>字段,并在其中填入command_name和args | 簡單直接 | 沒有設定反思等行為,對于錯誤的思考不能及時糾正 |
| AutoGPT | - prompt 較為復雜,分為生成工具調用 和 生成最終答案 兩套prompt - 生成工具調用 prompt 詳細設立了Constraints(例如不需要用戶協助)、Resources(例如網絡搜索)、Best Practices(例如每個API都需要花費,盡量少的調用),最終嚴格以json格式輸出 | prompt 限制多,會較好地進行自我反思、任務規劃等 | prompt 較長,花費較大 |
| ToolLLaMA | 模仿AutoGPT和ReACT,輸出以Thought、Action、Action Input 格式而非 json 格式,增加了 give_up_and_restart,支持全部推導重來,重來的prompt會把歷史失敗的記錄加進去訓模型用了1.6w Rapid API | prompt 限制多,會較好地進行自我反思、任務規劃等,并支持全部推倒重來 | 1. prompt 較長,花費較大 2. 全部推倒重來花費會更大 |
?eg:
# 導入依賴庫
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv# 加載 .env 文件中定義的環境變量
_ = load_dotenv(find_dotenv())# 初始化 OpenAI 客戶端
client = OpenAI() # 默認使用環境變量中的 OPENAI_API_KEY 和 OPENAI_BASE_URL# 基于 prompt 生成文本
# 默認使用 gpt-3.5-turbo 模型
def get_completion(prompt, response_format="text", model="gpt-4o-mini"):messages = [{"role": "user", "content": prompt}] # 將 prompt 作為用戶輸入response = client.chat.completions.create(model=model,messages=messages,temperature=0, # 模型輸出的隨機性,0 表示隨機性最小# 返回消息的格式,text 或 json_objectresponse_format={"type": response_format},)print(response)return response.choices[0].message.content # 返回模型生成的文本# 任務描述
instruction = """
Answer the following questions as best you can. You have access to the following tools:[
Name: web_search. Description: Perform a web search using the specified query.
Name: get_weather. Description: Retrieve the current weather information for a specified location.
]Use the following format:Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [web_search, get_weather]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input questionBegin!
"""# 用戶輸入
input_text = """
北京天氣怎么樣?
"""# 工具結果
tool_output = """
"""# prompt 模版。instruction 和 input_text 會被替換為上面的內容
prompt = f"""
{instruction}Question:
{input_text}{tool_output}
"""# 調用大模型
response = get_completion(prompt)
print("------------------------------------------")
print(response)# 導入依賴庫
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv# 加載 .env 文件中定義的環境變量
_ = load_dotenv(find_dotenv())# 初始化 OpenAI 客戶端
client = OpenAI() # 默認使用環境變量中的 OPENAI_API_KEY 和 OPENAI_BASE_URL# 基于 prompt 生成文本
# 默認使用 gpt-3.5-turbo 模型
def get_completion(prompt, response_format="text", model="gpt-4o-mini"):messages = [{"role": "user", "content": prompt}] # 將 prompt 作為用戶輸入response = client.chat.completions.create(model=model,messages=messages,temperature=0, # 模型輸出的隨機性,0 表示隨機性最小# 返回消息的格式,text 或 json_objectresponse_format={"type": response_format},)print(response)return response.choices[0].message.content # 返回模型生成的文本# 任務描述
instruction = """
<|system|>
You are AutoGPT, you can use many tools (functions) to do the following task. First I will give you the task description, and your task start. At each step, you need to give your thought to analyze the status now and what to do next, with a function call to actually execute your step. Your output should follow this format:Thought:
Action:
Action Input:After the call, you will get the call result, and you are now in a new state. Then you will analyze your status now, then decide what to do next.After many (Thought-call) pairs, you finally perform the task, then you can give your final answer.Remember:The state change is irreversible, you can't go back to one of the former states. If you want to restart the task, say "I give up and restart".
All the thoughts are short, at most 5 sentences.
You can do more than one try, so if your plan is to continuously try some conditions, you can do one of the conditions per try.
Let's Begin!Task description: You should use functions to help handle the real-time user queries. Remember:ALWAYS call the "Finish" function at the end of the task. The final answer should contain enough information to show to the user. If you can't handle the task, or you find that function calls always fail (the function is not valid now), use function Finish->give_up_and_restart.
Specifically, you have access to the following APIs:{"api_name": "web_search","description": "Perform a web search using the specified query.","parameters": {"type": "object","properties": {"query": {"type": "string","description": "The search query to be executed.","example_value": "華為發布會"}},"required": ["query"],"optional": []}
}
{"api_name": "get_weather","description": "Retrieve the current weather information for a specified location.","parameters": {"type": "object","properties": {"location": {"type": "string","description": "The name of the location (city, country, etc.) to get the weather for.","example_value": "Beijing"},},"required": ["location"],"optional": []}
}
{"name": "Finish","description": "If you believe that you have obtained a result that can answer the task, please call this function to provide the final answer. Alternatively, if you recognize that you are unable to proceed with the task in the current state, call this function to restart. Remember: you must ALWAYS call this function at the end of your attempt, and the only part that will be shown to the user is the final answer, so it should contain sufficient information.","parameters": {"type": "object","properties": {"return_type": {"type": "string","enum": ["give_answer", "give_up_and_restart"]},"final_answer": {"type": "string","description": "The final answer you want to give the user. You should have this field if "return_type"=="give_answer""}},"required": ["return_type"]}
}
"""# 用戶輸入
input_text = """
北京天氣怎么樣?
"""# 工具結果
tool_output = """
"""# prompt 模版。instruction 和 input_text 會被替換為上面的內容
prompt = f"""
{instruction}<|user|>
{input_text}{tool_output}<|assistant|>
"""# 調用大模型
response = get_completion(prompt)
print("------------------------------------------")
print(response)2.2 Agent Prompt 模板設計
我們可以設計兩套Prompt模板,一套用于任務規劃和工具調用指令生成(模板-1),一套用于總結生成最終答案(模板-2)。
I. Agent Prompt 1(模板-1):
你是一個很專業的AI任務規劃師,給定目標或問題,你的決策將獨立執行而不依賴于人類的幫助,請發揮LLM的優勢并且追求高效的策略進行任務規劃。
Constraints: 1.你有~4000字的短期記憶 2.不需要用戶的幫助 3.只使用雙引號中列出的commands,例如:“command_name” 4.互聯網搜索、信息聚合和鑒別真偽的能力 5.保持謙遜,對自己沒把握的問題,盡可能調用command,但盡量少調用,不能重復調用 6.當你從自身知識或者歷史記憶中能得出結論,請聰明且高效,完成任務并得出結論 7.經常建設性地自我批評整個行為大局,反思過去的決策和策略,以改進你的方法 8.你最多只能進行5步思考,規劃5個任務,所以盡可能高效規劃任務 9.你有反思能力,如果已完成的任務和結果暫不能得到回答問題所需信息或尚不能完成目標,應繼續規劃
Commands: 1:{"name": "web_search", "description": "Perform an internet search.", "parameters": {"type": "object", "properties": {"text": {"type": "str", "description": "Search query."}}}, "returns": {"description": "Multiple webpage links along with brief descriptions.", "type": "str"}, "required": ["text"]}
2:{"name": "wiki_search", "description": "Conduct an encyclopedia search for a specified entity and question. Provide accurate answers for factual queries but has a limited scope and cover fewer queries.", "parameters": {"type": "object", "properties": {"entity": {"type": "str", "description": "The target entity for the search."}, "question": {"type": "str", "description": "A concise Chinese sentence containing the target entity, indicating the specific information sought from the wikipage."}}}, "returns": {"description": "Relevant encyclopedia entries pertaining to the question.", "type": "str"}, "required": ["entity", "question"]}
3:{"name": "get_weather_info", "description": "Retrieve weather information for specified locations and dates.", "parameters": {"type": "object", "properties": {"location": {"type": "str", "description": "Locations in English separated by commas, e.g., "Beijing,Vancouver,...,Chicago"."}, "start_date": {"type": "str", "description": "Start date in format "yyyy-MM-dd"."}, "end_date": {"type": "str", "description": "End date in format "yyyy-MM-dd"."}, "is_current": {"type": "str", "description": ""yes" or "no" indicating if current time's weather is desired."}}}, "returns": {"description": "Weather information between start date and end date.", "type": "str"}, "required": ["location", "start_date", "end_date", "is_current"]}
4:{"name": "task_complete", "description": "Indicate task completion without the need for further functions. ", "parameters": {"type": "object", "properties": {}}, "returns": {"description": "", "type": ""}, "required": []}
GOAL: 用戶的輸入
Completed tasks: 已完成任務(短時記憶)
Conversation history: 對話歷史(短時記憶)
Knowledge: 知識(短時記憶)
Current Time: 當前時間
根據目標和已有任務,規劃一個新Task(不能重復),你只能以以下json列表的格式生成Task { "task_name": "任務描述", "command":{ "name":"command name", "args":{ "arg name":"value" } } }
確保Task可以被Python的json.loads解析
當已完成的Tasks能夠幫助回答這個目標問題,則盡可能生成任務完成Task,否則生成一個其他Task。一個新Task:
Agent Prompt 1 的組成部分:
-
Profile(角色):
定義 Agent 的身份、背景甚至性格特點等。這幫助模型在回答時保持一致性和個性化。例如,一個 Agent 可能被設定為一個友好且專業的助理。
你是一個很專業的AI任務規劃師,給定目標或問題,你的決策將獨立執行而不依賴于人類的幫助,請發揮LLM的優勢并且追求高效的策略進行任務規劃。
-
Instruction(指令):
提供具體的操作指令,指導Agent如何完成任務。這些指令明確地告訴Agent在特定情境下應該做什么或避免做什么。
Constraints:
1.你有~4000字的短期記憶
2.不需要用戶的幫助
3.只使用雙引號中列出的commands,例如:“command_name”
4.互聯網搜索、信息聚合和鑒別真偽的能力
5.保持謙遜,對自己沒把握的問題,盡可能調用command,但盡量少調用,不能重復調用
6.當你從自身知識或者歷史記憶中能得出結論,請聰明且高效,完成任務并得出結論
7.經常建設性地自我批評整個行為大局,反思過去的決策和策略,以改進你的方法
8.你最多只能進行5步思考,規劃5個任務,所以盡可能高效規劃任務
9.你有反思能力,如果已完成的任務和結果暫不能得到回答問題所需信息或尚不能完成目標,應繼續規劃……當已完成的Tasks能夠幫助回答這個目標問題,則盡可能生成任務完成Task,否則生成一個其他Task。一個新Task:-
Tools(工具集):
列出Agent可以使用的工具或功能,需要根據實際業務需求來構建。
Commands:
1:{"name": "web_search", "description": "Perform an internet search.", "parameters": {"type": "object", "properties": {"text": {"type": "str", "description": "Search query."}}}, "returns": {"description": "Multiple webpage links along with brief descriptions.", "type": "str"}, "required": ["text"]}2:{"name": "wiki_search", "description": "Conduct an encyclopedia search for a specified entity and question. Provide accurate answers for factual queries but has a limited scope and cover fewer queries.", "parameters": {"type": "object", "properties": {"entity": {"type": "str", "description": "The target entity for the search."}, "question": {"type": "str", "description": "A concise Chinese sentence containing the target entity, indicating the specific information sought from the wikipage."}}}, "returns": {"description": "Relevant encyclopedia entries pertaining to the question.", "type": "str"}, "required": ["entity", "question"]}3:{"name": "get_weather_info", "description": "Retrieve weather information for specified locations and dates.", "parameters": {"type": "object", "properties": {"location": {"type": "str", "description": "Locations in English separated by commas, e.g., "Beijing,Vancouver,...,Chicago"."}, "start_date": {"type": "str", "description": "Start date in format "yyyy-MM-dd"."}, "end_date": {"type": "str", "description": "End date in format "yyyy-MM-dd"."}, "is_current": {"type": "str", "description": ""yes" or "no" indicating if current time's weather is desired."}}}, "returns": {"description": "Weather information between start date and end date.", "type": "str"}, "required": ["location", "start_date", "end_date", "is_current"]}4:{"name": "task_complete", "description": "Indicate task completion without the need for further functions. ", "parameters": {"type": "object", "properties": {}}, "returns": {"description": "", "type": ""}, "required": []}-
Goal(目標,用戶的Query):
定義Agent的主要任務或目的。這幫助Agent聚焦于最終目標,例如幫助用戶解答問題、撰寫文章等。
GOAL: 我想登頂北京最高峰,請幫我做個規劃
-
Memory(記憶):
保持上下文或會話記憶,以提供連續性。這使得Agent能夠參考之前的對話或用戶提供的信息,提供更相關和個性化的回應。
【重點】Memory部分可以包括:
- Completed Tasks(已完成任務):之前已調用工具完成的任務,通常包含任務名、工具名、工具參數、工具返回結果等信息;
- Conversation History(對話歷史):記錄用戶和 Agent 系統的對話歷史;
- Knowledge(知識):存儲業務中所需的知識用于參考,例如用戶上傳的文檔、個性化知識等。
將知識,對話歷史,任務歷史進行存儲,然后在對話的過程中進行檢索和篩選,篩選后的信息加入prompt中作為參考。底層使用的向量數據庫進行信息的存儲,檢索采用es和embedding進行雙路召回。
Completed tasks: [{"task_name": "查詢北京最高山","command": {"name": "wiki_search","args": {"entity": "北京""question": "北京最高山是什么山"}},"task_id": 1,"result": "北京市,通稱北京(漢語拼音:Běijīng;郵政式拼音:Peking),簡稱“京”,曾稱“北平”[注 2]。是中華人民共和國的首都及直轄市,是中國的政治、文化、科技、教育、軍事和國際交往中心,是一座全球城市,是世界人口第三多的城市和人口最多的首都,具有重要的國際影響力[4]。北京位于華北平原的北部邊緣,背靠燕山,永定河流經老城西南,毗鄰天津市、河北省,為京津冀城市群的重要組成部分..."},{"task_name": "未找到,調用搜索工具查詢","command": {"name": "web_search","args": {"question": "北京最高山是什么山"}},"task_id": 2,"result": "title:北京最高的山峰是那座,北京最高的山是什么山\nbody:北京最高的山峰是位于北京市門頭溝區清水鎮的東靈山,主峰海拔2303米,是北京市的最高峰,被譽為京西的“珠穆朗瑪”。 景色介紹東靈山自然風景區位于京西門頭溝的西北部, ... url: https://m.mafengwo.cn/travel-news/219777.html ..."}
]
Conversation history: [{"user": "劉德華多少歲了?","assistant": "劉德華(Andy Lau)生于1961年9月27日。截至2024年7月,他已經62歲了。"},{"user": "北京今天天氣怎么樣?","assistant": "北京當日天氣多云,28攝氏度,微風"}
]
Knowledge: [{"北京最高的山峰是東靈山,海拔2303米。","北京市地處中國北部、華北平原北部,東與天津市毗連,其余均與河北省相鄰,中心位于東經116°20′、北緯39°56′,北京市地勢西北高、東南低。","2023年,北京市全年實現地區生產總值43760.7億元,按不變價格計算,比上年增長5.2%。"}
]
思考:如果 Memory 太多,Prompt 無法容納怎么辦?-
Format(輸出格式):
定義Agent生成輸出的格式和風格。這確保了Agent的回應符合預期的結構和表達方式,例如簡潔、正式或非正式等。
根據目標和已有任務,規劃一個新Task(不能重復),你只能以以下json列表的格式生成Task
{ "task_name": "任務描述", "command":{ "name":"command name", "args":{ "arg name":"value" } }
}
確保Task可以被Python的json.loads解析-
其他必要信息:
可以根據業務場景的需求,在Prompt中添加必要的常用信息,如:當前時間、地點、IP等。
3. Agent Tuning
3.1 Agent Tuning 的目的(再次理解)
回顧:?既然通過 Prompt Engineering 可以實現 Agent,那為什么還要訓練 Agent 模型呢?
因為可以這么做的前提是:模型足夠“聰明”,靠看“說明書”就能執行, Prompt Engineering 實際上是把“說明書”寫得更加清晰易懂。
- 實踐證明,除了 GPT-4 level 的大模型,其他大模型(包括 GPT-3.5 )無法很好遵從 prompt 要求完成復雜的 Agent 任務;
- 很多場景下無法使用最強的大模型 API ,需要私有化部署小模型,需要控制推理成本;
- 通過訓練,一個小參數量的大模型(13B、7B等)也能達到較好的能力,更加實用。
?3.2 訓練數據準備
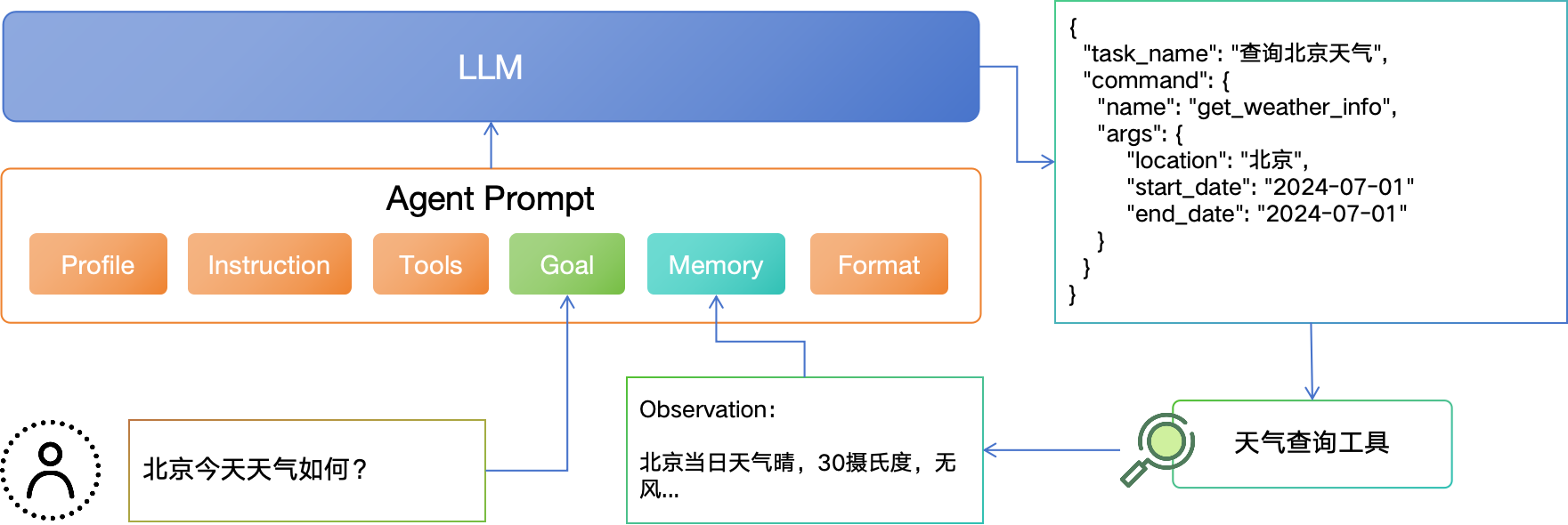 ??
??
-
大模型 fine-tuning 的數據形式:
 ?
?
-
Agent Tuning 是一種特殊的 fine-tuning,有時也被稱作 Tool SFT,特殊之處在于:
1)Agent Tuning 的 Prompt 更復雜,約束條件更多;
2)通常 Agent 工作過程是多步的,因此訓練數據也需要是多步驟的,多步之間前后有關聯。
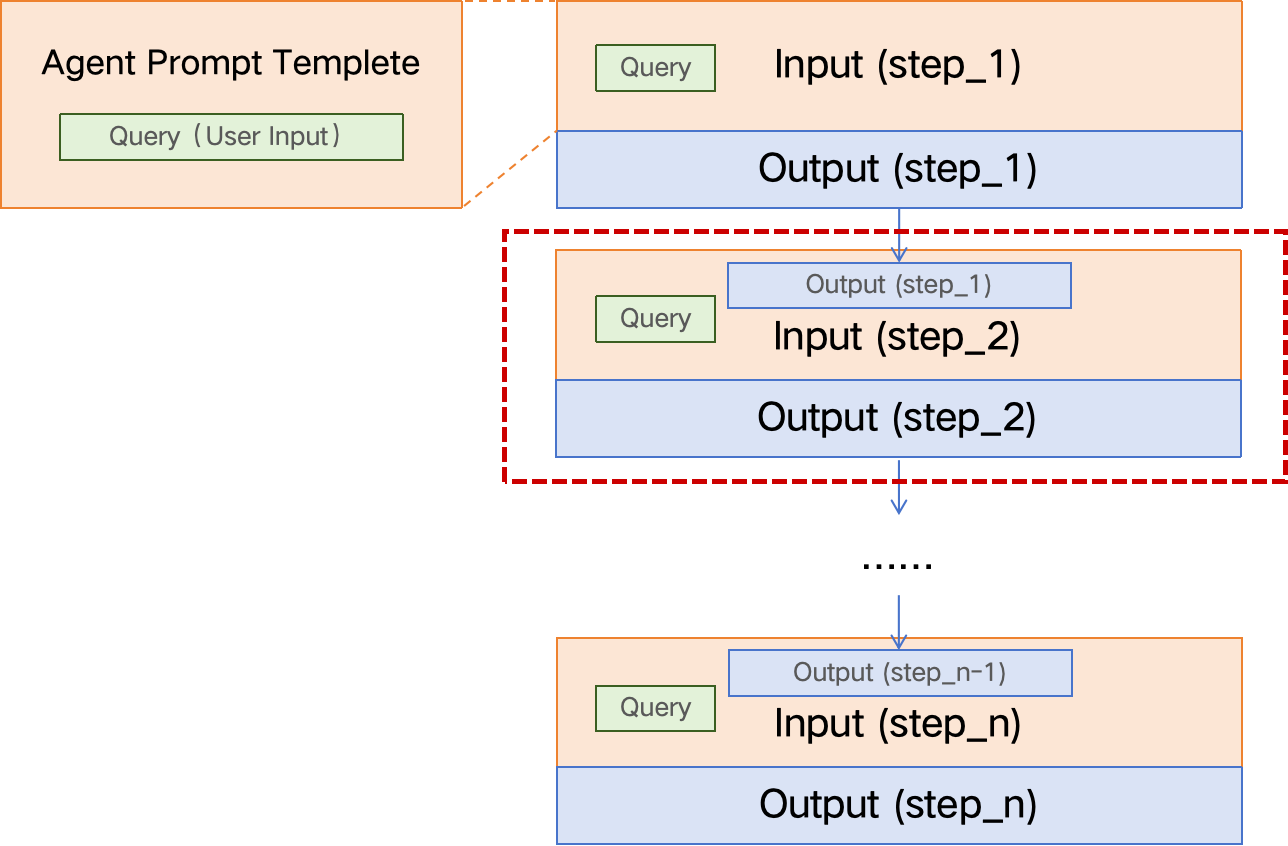 ??
??
重點Agent Tuning 訓練數據構建的步驟:
- 根據實際業務收集大量 query,要盡可能覆蓋各種場景;
- 將每一個 query 與 prompt 模板結合,構成 agent prompt,也就是訓練數據中的輸入部分;
- 為每一個 agent prompt 構建對應的標準答案,也就是訓練數據中的輸出部分,這項工作可以借助 GPT-4 level 的大模型來降本提效;
- 如果第三步是用大模型來生成答案,則最好通過人工修正或篩選高質量的 Output,數據質量越高,最終 Agent Tuning 得到的模型效果越好。
?eg:
你是一個很專業的AI任務規劃師, 給定目標或問題,你的決策將獨立執行而不依賴于人類的幫助,請發揮LLM的優勢并且追求高效的策略進行任務規劃。
Constraints:
1.你有~4000字的短期記憶
2.不需要用戶的幫助
3.只使用雙引號中列出的commands,例如:“command_name”
4.互聯網搜索、信息聚合和鑒別真偽的能力
5.保持謙遜,對自己沒把握的問題,盡可能調用command,但盡量少調用,不能重復調用
6.當你從自身知識或者歷史記憶中能得出結論,請聰明且高效,完成任務并得出結論
7.經常建設性地自我批評整個行為大局,反思過去的決策和策略,以改進你的方法
8.你最多只能進行5步思考,規劃5個任務,所以盡可能高效規劃任務
9.你有反思能力,如果已完成的任務和結果暫不能得到回答問題所需信息或尚不能完成目標,應繼續規劃Commands:
1:Web Search:"web_search",args:"text":"<search>"
2:Browse Website:"browse_website",args:"url":"<url>, "question":"<what_you_want_to_find_on_website>"
3:Wikipedia search:"wiki_search",args:"entity":<entity>,"question":"<what_you_want_to_find_on_wikipage>"
4:Wikipage browser:"browse_wikipage",args:"url":<url_return_by_wiki_search>,"question":"<what_you_want_to_find_on_wikipage>"
5:Video Search:"video_search",args:"query":"<search-query-in-chinese>"
6:Do Nothing: "do_nothing",args:
7:Task Complete (Shutdown):"task_complete",args: "reason":"<reason>"Commands Tips:
1.使用browse_website時,盡可能只訪問先前搜索得到的網址,不要瞎編生成無效網站鏈接
2.wiki_search返回的信息盡管更準確,但搜索范圍小,問題覆蓋率低,question只能是包含中心實體的簡單中文短句
3.每次調用command都會收取費用,盡可能少調用Current Time: 2023-07-07 18:35:32.214612GOAL: 請找出蔡徐坤2023年的演唱會名稱,以及與演唱會相關的最新幾則新聞。根據目標和已有任務,規劃一個新Task(不能重復),你只能以以下json列表的格式生成Task
{
"task_name": "任務描述",
"command":{
"name":"command name",
"args":{
"arg name":"value"
}
}
}
確保Task可以被Python的json.loads解析當已完成的Tasks已經能夠幫助回答這個目標,則盡可能生成任務完成Task,否則生成一個其他Task。一個新Task:?3.3 模型訓練
注意:Agent 模型通常需要全參數訓練,LoRA 效果不好。
高階經驗(大家了解即可):
- 應用加速訓練、節省顯存的方法,例如:混合精度、分布式訓練(Deepspeed Zero3)、梯度檢查點(Gradient Checkpointing)、梯度累積(Gradient Accumulation)、Flash Attention 等;
- 推理用 vllm 等框架加速。
3.4 效果評估
3.4.1 自動評估
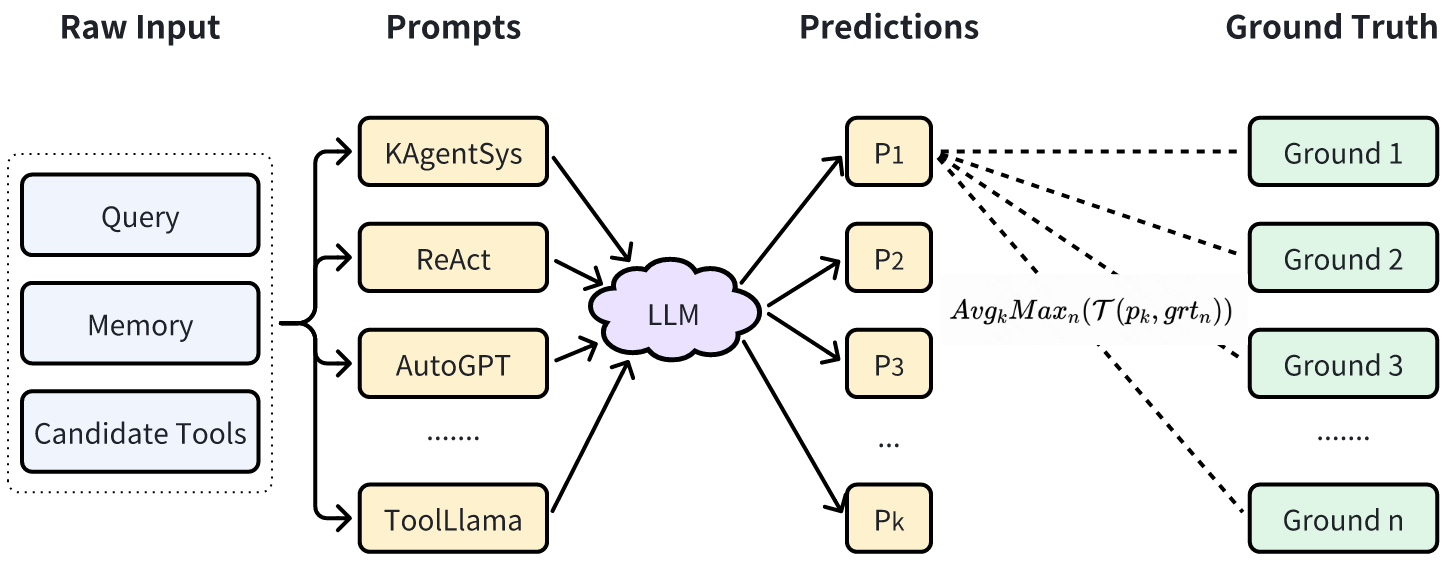
自動評估的主要目的是在模型訓練過程中監控模型的效果,評估指標的對比意義大于絕對值意義。
- 采用 GPT-4 + 人工修正的方式構建自動評測的 benchmark(一般從訓練數據中隨機分出一部分即可);
- 將 Agent 輸出結果與 benchmark 中的參考答案進行對比,計算得到分值。
示例:
Ground Truth:
{"task_name": "查詢北京實時天氣","command": {"name": "get_weather_info","args": {"location": "北京","start_date": "2024-07-01","end_date": "2024-07-01","is_current": "yes"}}
}Agent Response:
{"task_name": "查詢北京當前天氣","command": {"name": "get_weather_info","args": {"location": "北京","start_date": "2024-07-01","end_date": "2024-07-01","is_current": "no"}}
}
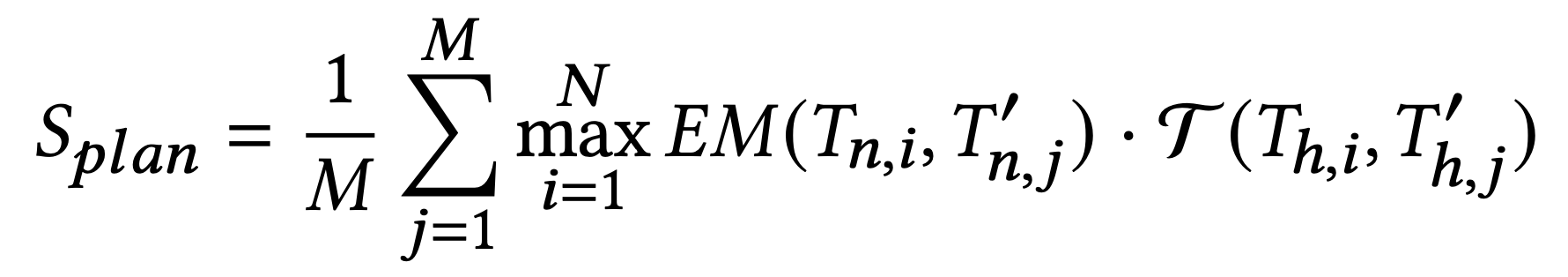
其中,Tn,i?為 Groud Truth 中的工具名稱,Tn,j′?為 待測試的 Agent Response 中的工具名稱,EM為精確匹配(Exact Match,直接進行字符串精確匹配),結果為 0 或 1;
Th,i?為 Groud Truth 中的任務描述(示例中的“task_name”),Th,j′?為 待測試的 Agent Response 中的任務描述,
可以是任何文本生成質量評估的方法(例如?ROUGE、?BLEU),做模糊匹配評分,分值為0-1;
類似地: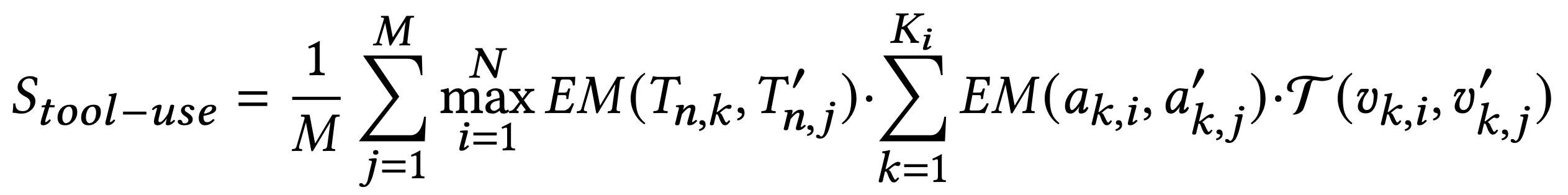
自動測試結果示例:
| Scale | Planning | Tool-use | Reflection | Concluding | Profile | Overall Score | |
|---|---|---|---|---|---|---|---|
| GPT-3.5-turbo | - | 18.55 | 26.26 | 8.06 | 37.26 | 35.42 | 25.63 |
| Qwen | 7B | 13.34 | 18.00 | 7.91 | 36.24 | 34.99 | 21.17 |
| Qwen2 | 7B | 20.11 | 29.03 | 21.01 | 40.36 | 42.06 | 29.57 |
| Baichuan2 | 13B | 6.70 | 16.10 | 6.76 | 24.97 | 19.08 | 14.89 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Qwen-MAT | 7B | 31.64 | 43.30 | 33.34 | 44.85 | 44.78 | 39.85 |
| Baichuan2-MAT | 13B | 37.27 | 52.97 | 37.00 | 48.01 | 41.83 | 45.34 |
人工評估
最靠譜的評估當然還是需要人工來做,人工評估的難點在于標準的制定,以及對評估人員的培訓。
評估標準示例:
評分分為五個等級,具體定義如下:
1分:核心信息存在重大不準確性,大部分或全部內容不正確; 2分:核心信息不正確,或超過60%的內容有錯誤; 3分:核心信息準確,但10%到60%的補充信息不正確; 4分:小有出入,核心信息準確,補充信息中的錯誤不超過10%; 5分:完全正確。
得分為4分或5分的回答被認為是可用的。
遇到違規內容一票否決,直接判0分。
人工評估效率低、成本高,所以不能頻繁使用,一般在大的模型版本上使用。
4. Agent 泛化性提升
如果想進一步提升 Agent 的泛化性,比如希望用一個 Agent 服務于多個業務,能適應不同的 Prompt 模板,可以靈活地接入新的業務,那么訓練數據應該如何構建呢?
4.1 訓練數據的多樣性
基座大模型本身的理解能力和 Agent Tuning 訓練數據的多樣性共同決定了 Agent 的泛化能力。在指定了基座模型的情況下,我們可以做的是提升訓練數據的多樣性。
我們可以將訓練數據 Input 部分拆解為3個變量:Query、Tools、Agent Prompt模板,最終的數據就是這3個變量的組合。

-
Query:
-
覆蓋全部場景:對于內部業務工具構造特定query,盡可能覆蓋所有可能的業務場景,避免有遺漏;
-
困難負樣本:構造正樣本(需要用到工具的query) + 困難負樣本(看似和工具有關,但實際上不調用),其中大部分是正樣本,但不能全是正樣本
示例:上海明天天氣怎么樣?(正樣本)| 北京今天下雨嗎?(正樣本) | 今天天氣真好(困難負樣本)
經驗值:正樣本和困難負樣本比例 4:1,僅供參考。 -
樣本復雜度多樣:簡單樣本和復雜樣本都需要構造,簡單樣本為一步即可完成的任務,復雜樣本為涉及多步推理、多種工具的任務;(實踐中評測時發現,僅減少550復雜query,測試集中的事實準確率下降6個百分點)
示例:這周末適合去北京郊區露營嗎?如果適合,請推薦幾個地方? | 劉德華的女兒幾歲了?(涉及到多步工具調用)
經驗值:簡單樣本與復雜樣本比例 6:1,僅供參考。
-
-
Tools
有兩種維度:Tools描述格式多樣性和Tools類型多樣性。
-
Tools 描述格式多樣性:
- OpenAI function:{"name": "web_search", "description": "Perform an internet search.", "parameters": {"type": "object", "properties": {"text": {"type": "str", "description": "Search query."}}}, "returns": {"description": "Multiple webpage links along with brief descriptions.", "type": "str"}, "required": ["text"]} - AutoGPT:Web Search:"web_search",args:"text":"" - ReACT:duckduckgo_search: A wrapper around DuckDuckGo Search. Useful for when you need to answer questions about current events. Input should be a search query.
-
Tools 類型多樣性:
除了引入業務本身的工具之后,還可以添加更加豐富的工具,比如可以從ToolLLaMA(1w+)、ModelScope(幾百)、AutoGPT等項目中選取API,可以提升工具的泛化性。
-
-
Agent Prompt 模板
提升 Agent Prompt 模板的多樣性,參見下一節 Meta-Agent 內容。
【重點】對?Query、Tools、Agent Prompt 模板?這三個變量分別構造了各種類型的數據,然后進行組合構成多樣性的 Input( Prompt )數據,再調用GPT-4生成 Output( Response ),多樣性的數據可以使模型不只擬合特定的 Prompt 模板,適應各種類型的 Query 以及 Tools 集合,提高模型的泛化性。
4.2 Meta-Agent
Agent Prompt 模板多樣性提升
4.2.1 背景
ReACT、ToolLlama、ModelScope、AutoGPT 都有一套各自運行在其中內部的一套 prompt 模板,模型如果只是在一套 prompt 模板下訓練,那么可能只是擬合了這一套 prompt ,如果換一套 prompt 性能會急劇下降;我們希望 Agent 不受到特定 Prompt 模板的限制,提升模型本質的 Agent 能力,提出了核心思想 Meta-Agent 方法。
這些 Agent Prompt 模板雖然表述方式各不相同,但都可以分為 <Profile>、<Instruction>、<Tools>、<Goal>、<Memory>、<Format>部分,那是不是可以調用GPT4來自動化生成包含這些部分且表達方式多樣性的模板呢?
4.2.2 方法
我們可以通過 Prompt Engineering 來設計一個基于 GPT-4 的 Agent,用于生成多樣性的 Agent Prompt 模板,我們稱之為:Meta-Agent?(元-Agent)。
Meta-Agent Prompt:?用于調用 GPT-4 生成 Agent Prompt 模板的 Prompt,我們稱之為 Meta-Agent Prompt。
我們可以手動寫一個固定的 Meta-Agent Prompt 作為 GPT-4 的輸入,利用大模型內容生成的多樣性來生成不同的模板,但實際上多樣性效果有限,更好的方式是用不同的種子 query 做引導,提升多樣性。
- 根據實際業務收集大量 query,要盡可能覆蓋各種場景;
- 選取相似的數條 query 組成多個集合,如果數量不足,這一步也可以借助 GPT-4 來對 query 做擴展;
- 設計一個 Meta-Agent Prompt 模板,將不同的 query 集合插入設計好的模板中組合成不同的 Meta-Agent Prompt;
- 調用 GPT-4 生成不同的 Agent Prompt 模板候選。
利用這種方法便可以生成包含<Profile>、<Instruction>、<Tools>、<Goal>、<Memory>、<Format>要素的多樣化的模板。
?
由于自動化生成的 Agent Prompt 模板質量可能參差不齊,我們還需要對這些模板以及生成的訓練數據進行篩選。對于關鍵信息缺失,有明顯缺陷的的模板,我們直接刪除即可。剩下的模板效果如何則需要在實際數據上檢驗,我們同樣也可以借助 GPT-4 (做裁判)來完成。具體步驟如下:
- 將一批相同的 query 分別插入到經過驗證的標桿模板中(如AutoGPT、ToolLLaMA等)和 Meta-Agent 生成的 prompt 模版中,形成 prompt pair;
- 將 prompt pair 中的兩個 prompt 分別輸入給GPT-4,生成對應的回復;
- 利用 GPT-4 對兩個回復的質量分別打分?score1(標桿模板的實例)、score2(候選模板的實例),如果?score2?score1>?,則保留該 prompt 實例,否則刪除;
- 對于同一個模板的所有實例求平均分,得到模板的得分,當分值大于一定閾值,保留該模板,否則刪除該模板以及對應的prompt實例。
4.1.3 示例
-
Mate-Agent Prompt(GPT-4 的輸入):
# 導入依賴庫
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv# 加載 .env 文件中定義的環境變量
_ = load_dotenv(find_dotenv())# 初始化 OpenAI 客戶端
client = OpenAI() # 默認使用環境變量中的 OPENAI_API_KEY 和 OPENAI_BASE_URL# 基于 prompt 生成文本
# 默認使用 gpt-3.5-turbo 模型
def get_completion(prompt, response_format="text", model="gpt-4o-mini"):messages = [{"role": "user", "content": prompt}] # 將 prompt 作為用戶輸入response = client.chat.completions.create(model=model,messages=messages,temperature=0, # 模型輸出的隨機性,0 表示隨機性最小# 返回消息的格式,text 或 json_objectresponse_format={"type": response_format},)print(response)return response.choices[0].message.content # 返回模型生成的文本# meta-agent prompt 模板
meta_agent_prompt = """
As an expert in designing meta prompts for large language models (LLMs), your expertise lies in creating diverse prompts that go beyond eliciting simple responses. Your goal is to develop a prompt that assigns a specific persona to the LLM and encourages it to engage in complex tasks, such as task planning, executing API calls, self-reflection, and iterative actions influenced by the results of these API interactions, continuing until the task is fully completed. You should use "you" instead of "I" as the main voice in the meta prompt.Your prompt must explicitly reserve slots for <<QUERY>> and <<APIs>>. Each slot should ideally occupy a separate line. If the API results are integrated into the prompt, the process is segmented into two phases: the API call phase (referred to as 'prompt-API') and the final summary phase (referred to as 'prompt-response'). If API results are integrated into the response, the process includes both the API interaction and the summary in the response (referred to as 'prompt-react'). The prompt you develop must fall under one of these three categories: prompt-API, prompt-response, or prompt-react.Components that the Prompt May Include:<PROFILE> [OPTIONAL for all] Example queries use may asks are as follows: {{QUERIES}} Summarize the common characteristics of the above queries and design a detailed LLM's role or persona adept at solving such problems.
<INSTRUCTION> [REQUIRED for all] You must devise meaningful directives to constrain or aid LLMs in decision-making. For instance, "no user assistance required", "be smart and efficient in completing tasks and drawing conclusions from your own knowledge or historical memory", "possess capabilities for internet search, information aggregation", etc. Use your imagination to expand on these guidelines.
<QUERY> [REQUIRED for all] Directly add slot <<QUERY>> into your prompt. The slot will be replaced with an actual user query. Do NOT provide the specific query.
<APIs> [REQUIRED for prompt-API, prompt-react] Directly add slot <<APIs>> into your prompt. The slot will be replaced with specific APIs. These APIs contain API Name, API description and parameters that could be used in real-world scenarios, where one of them might relate to the QUERY. Do NOT provide the specific APIs.
<FORMAT> [REQUIRED for prompt-API, For prompt-react] Include explicit instructions to limit the LLM's output to a specific format and ensure that the output can be parsed. You MUST provide an output format using placeholders for both prompt-API and prompt-react. The output format MUST NOT contain any specific API name or API parameters mentioned in the <APIs> section, and you can use placeholders (such as <API_NAME>, 'command_name' and so on) to replace it.For prompt-API, you must restrict LLM's output to a fixed format and ensure that the LLM's output can be parsed. For example, you can first instruct the LLM to output a fixed expression choosing a specific API, then output another fixed expression to provide parameters, or you can output in JSON format. Please be creative and do not feel limited by the above examples. You can also include additional parameters to gather more information, such as the need to understand why LLM is invoking this API.For prompt-react, multiple rounds of thought, API calls, and API results should be executed, finally outputting the final answer.Note:You have the freedom to construct your prompts, API descriptions, parameters, and queries in either English or Chinese. The examples provided above are only for reference. Use your imagination and creativity beyond the given examples. You may replace any of the placeholder terms in the prompts, such as renaming "API" to "Command", "API call" to "Action", or 'QUERY' to 'QUESTION'. Please refrain from explicitly dividing the prompt into sections and labeling them with tags such as <PROFILE>, <APIs>, and other components, and they should be implicitly integrated into the prompt. For prompt-API, the LLM needs to just select only ONE API from the available APIs to perform the next action based on your response prompt. You must mention this in your prompt. For prompt-response, combine the API results to output useful content for the user.Please generate a prompt of the {{PROMPT_TYPE}} type directly in {{LANGUAGE}}. Do not include any explanations.
"""# query 集合
queries = """
['天津天氣如何','深圳市下雨了嗎','上海有臺風嗎']
"""# 模板類型
prompt_type = "prompt-API"# 語言設置
language = "CHINESE"# prompt
prompt = meta_agent_prompt.replace("{{QUERIES}}", queries).replace("{{PROMPT_TYPE}}", prompt_type).replace("{{LANGUAGE}}", language)# 調用大模型
response = get_completion(prompt)
print("------------------------------------------")
print(response)4.3 訓練數據構建關鍵經驗
構建機器學習訓練數據是保證模型性能的關鍵環節。以下是一些注意事項:
- 數據質量:
- 準確性:確保數據的標注正確且準確。錯誤標注會導致模型學到錯誤的模式。
- 一致性:數據應該保持一致,避免同樣的輸入在不同記錄中對應相互沖突的答案。
2. **數據量**: - **數量**:足夠大的數據量有助于模型捕捉復雜的模式。數據量不足可能導致模型過擬合。 - **多樣性**:數據應包含盡可能多的不同情況,避免模型對某些特定模式的偏好。
3. **數據平衡**:確保各種類型的數據量相對平衡。例如對于分類問題,類別不平衡會導致模型偏向多數類。
4. **數據增強**: - **數據擴充**:對于圖像、文本等數據,通過旋轉、翻轉、添加噪聲等方法擴充數據量。 - **合成數據**:在數據量不足時,考慮生成合成數據。
5. **數據清洗**: - **去重**:刪除重復的數據記錄,避免模型學習到重復信息。 - **提質**:對于含有瑕疵的數據,合理補充修正或直接刪除。
6. **隱私和合規性**: - **隱私保護**:確保數據的收集和使用符合隱私保護法規。 - **數據匿名化**:對敏感數據進行匿名化處理,保護個人隱私。
7. **數據分割**: - **訓練集、驗證集、測試集**:將數據合理分割為訓練集、驗證集和測試集,確保模型的泛化能力。 - **避免數據泄漏**:確保訓練數據中不包含測試數據的信息,避免模型在測試時表現出非真實的高精度。
8. **持續更新**: - **數據更新**:隨著時間推移,定期更新訓練數據,保持模型的準確性和可靠性。 - **模型監控**:監控模型性能,及時發現和解決數據相關的問題。
通過關注這些注意事項,可以提高訓練數據的質量,從而構建出更準確、更可靠的機器學習模型。
一般大廠都會專門開發一套機器學習數據管理的系統,并且有專業的數據標注團隊(全職+外包)來完成機器學習數據的建設。
5. 幾個 Agent Tuning 開源項目簡介
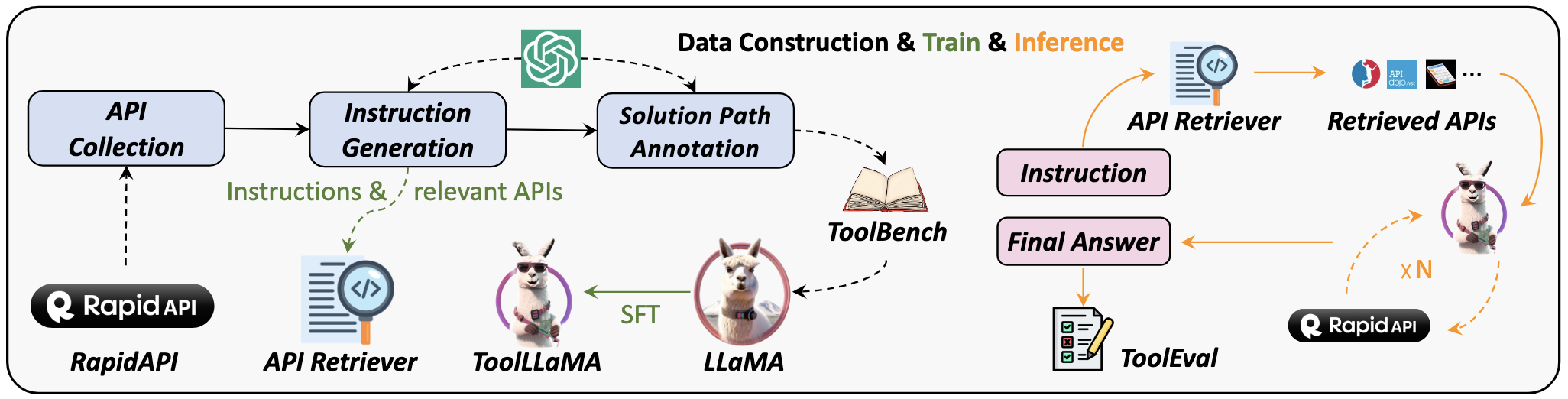
1) ToolBench (ToolLLaMA)
- 發布機構:面壁智能
*?4.6k stars
* https://github.com/OpenBMB/ToolBench
提供數據集、相應的訓練和評估腳本,以及在ToolBench上經過微調的強大模型ToolLLaMA。
數據:ToolBench,包含 469585 條數據(工具數量:3451;API數量:16464);
模型:ToolLLaMA-2-7b-v2、ToolLLaMA-7b-v1、ToolLLaMA-7b-LoRA-v1
?
2) AgentTuning
- 發布機構:智譜華章
*?1.3k stars
* https://github.com/THUDM/AgentTuning
利用多個 Agent 任務交互軌跡對 LLM 進行指令調整的方法。評估結果表明,AgentTuning 讓 LLM 在未見過的 Agent 任務中也展現出強大的泛化能力,同時通用語言能力也基本保持不變。
數據:AgentInstruct,包含 1866 個高質量交互、6 個多樣化的真實場景任務;
模型:AgentLM 由 Llama2-chat 開源模型系列在 AgentInstruct,ShareGPT 混合數據集上微調得到,有7B、13B、70B三個模型。
3) KwaiAgents
- 發布機構:快手
*?1k stars
* https://github.com/KwaiKEG/KwaiAgents
快手聯合哈爾濱工業大學研發,使 7B/13B 的 “小” 大模型也能達到超越 GPT-3.5 的效果。
數據:KAgentInstruct,超過20w(部分人工編輯)的Agent相關的指令微調數據;KAgentBench:超過3k條經人工編輯的自動化評測Agent能力數據;
模型:采用 Meta-Agent 方法訓練,包括 Qwen-7B-MAT、Qwen-14B-MAT、Qwen-7B-MAT-cpp、Qwen1.5-14B-MAT、Baichuan2-13B-MAT。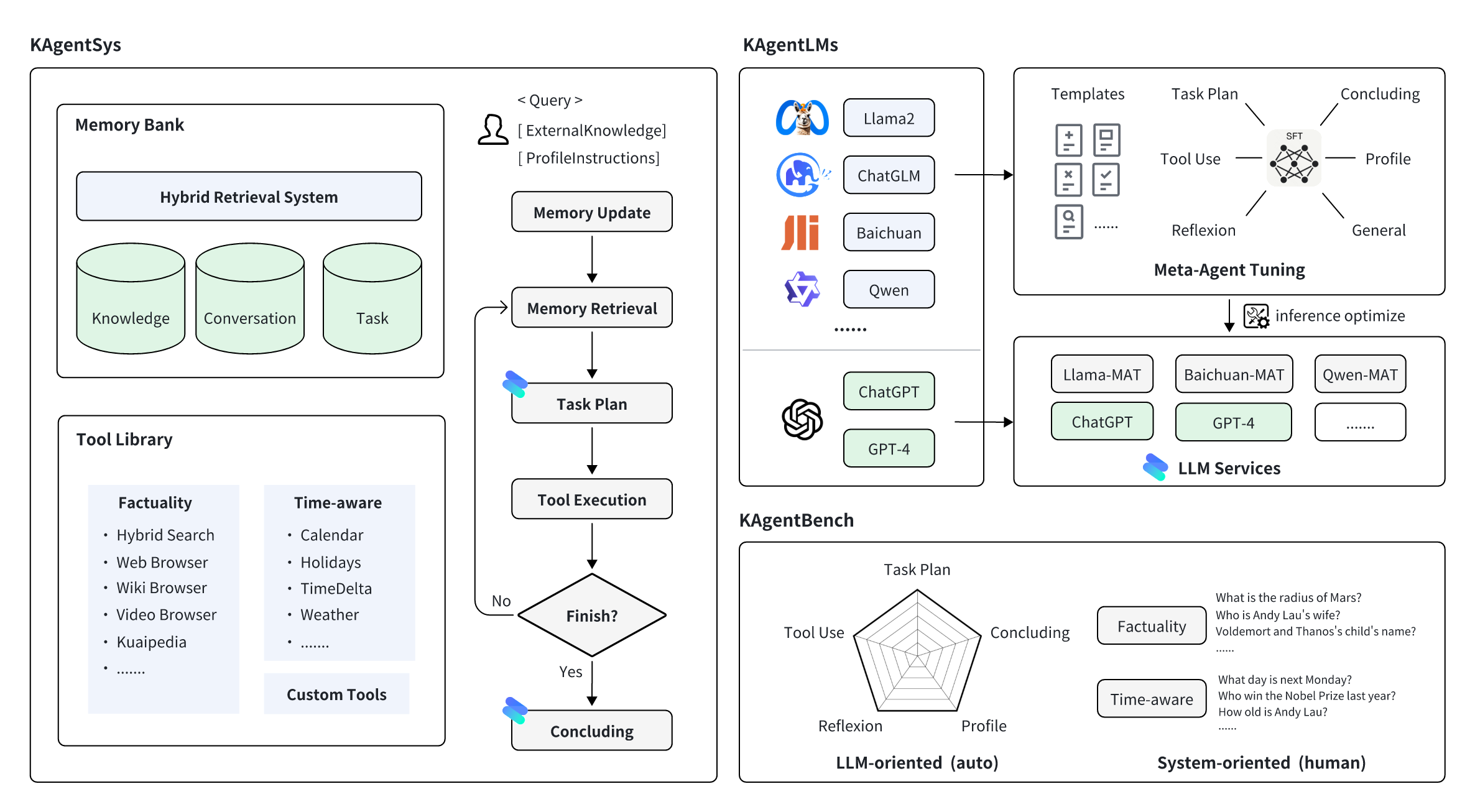
6. 總結
1. 理解大模型應用需要 Agent 技術的原因:消除“幻覺”、連接真實世界、處理復雜任務;
2. 理解 Agent Tuning 的主要動機:希望通過訓練讓大模型,尤其是小參數大模型(7B、14B)也能具備特定業務場景的 Agent 能力;
3. 了解 Agent Prompt 的構造方法,通常包括Profile、Instruction、Tools、Format、Memory、Goal等部分;
4. 了解 Agent Tuning 訓練數據的構建方法和微調訓練方式,并學習模型效果評估的方法;
5. 了解提升 Agent 泛化性的方法:從Query、Tools 和 Agent Prompt 模板三個方面提升訓練數據的多樣化,引申了解機器學習訓練數據構建的關鍵經驗;
6. 介紹了三個 Agent Tuning 的開源項目。
?最后推薦大家一起學習B站上吳恩達老師的,講的很不錯。
鏈接:04can-a-large-language-model-master-wordle_嗶哩嗶哩_bilibili


)


)


)







)


