@浙大疏錦行
作業:
對之前的信貸項目,利用神經網絡訓練下,嘗試用到目前的知識點讓代碼更加規范和美觀。
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm
import pandas as pd
import warningswarnings.filterwarnings("ignore")# 設置GPU設備
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# 數據預處理函數
def preprocess_data(data_path):data = pd.read_csv(data_path)# 標簽編碼home_ownership_mapping = {'Own Home': 1, 'Rent': 2, 'Have Mortgage': 3, 'Home Mortgage': 4}data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)years_in_job_mapping = {'< 1 year': 1, '1 year': 2, '2 years': 3, '3 years': 4,'4 years': 5, '5 years': 6, '6 years': 7, '7 years': 8,'8 years': 9, '9 years': 10, '10+ years': 11}data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# 獨熱編碼data = pd.get_dummies(data, columns=['Purpose'])# 轉換bool為intfor col in data.select_dtypes(include=['bool']).columns:data[col] = data[col].astype(int)# Term映射term_mapping = {'Short Term': 0, 'Long Term': 1}data['Term'] = data['Term'].map(term_mapping)data.rename(columns={'Term': 'Long Term'}, inplace=True)# 填充缺失值for feature in data.select_dtypes(include=['int64', 'float64']).columns:mode_value = data[feature].mode()[0]data[feature].fillna(mode_value, inplace=True)return data# 加載并預處理數據
data = preprocess_data('data.csv')
X = data.drop('Credit Default', axis=1)
y = data['Credit Default']# 劃分數據集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y
)# 歸一化
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 轉換為Tensor
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train.values).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test.values).to(device)# 定義模型
class MLP(nn.Module):def __init__(self, input_dim, hidden_dim=10, output_dim=2):super().__init__()self.layers = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, output_dim))def forward(self, x):return self.layers(x)# 初始化模型
input_dim = X_train.shape[1]
model = MLP(input_dim=input_dim, output_dim=2).to(device) # 二分類問題輸出維度應為2# 損失函數和優化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam優化器# 訓練參數
num_epochs = 1000
batch_size = 64
n_batches = len(X_train) // batch_size# 訓練循環
losses = []
start_time = time.time()with tqdm(range(num_epochs), desc="訓練進度") as pbar:for epoch in pbar:epoch_loss = 0# 小批量訓練for i in range(n_batches):start = i * batch_sizeend = start + batch_sizebatch_X = X_train[start:end]batch_y = y_train[start:end]# 前向傳播outputs = model(batch_X)loss = criterion(outputs, batch_y)# 反向傳播optimizer.zero_grad()loss.backward()optimizer.step()epoch_loss += loss.item()avg_loss = epoch_loss / n_batcheslosses.append(avg_loss)# 更新進度條pbar.set_postfix({'Loss': f'{avg_loss:.4f}'})print(f'訓練時間: {time.time()-start_time:.2f}秒')# 繪制損失曲線
plt.figure(figsize=(10, 6))
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.grid(True)
plt.show()# 評估模型
model.eval()
with torch.no_grad():outputs = model(X_test)_, predicted = torch.max(outputs, 1)accuracy = (predicted == y_test).float().mean()print(f'測試集準確率: {accuracy.item()*100:.2f}%')使用設備: cuda:0
訓練進度: 100%|██████████| 1000/1000 [03:01<00:00, 5.50it/s, Loss=0.4466]
訓練時間: 181.73秒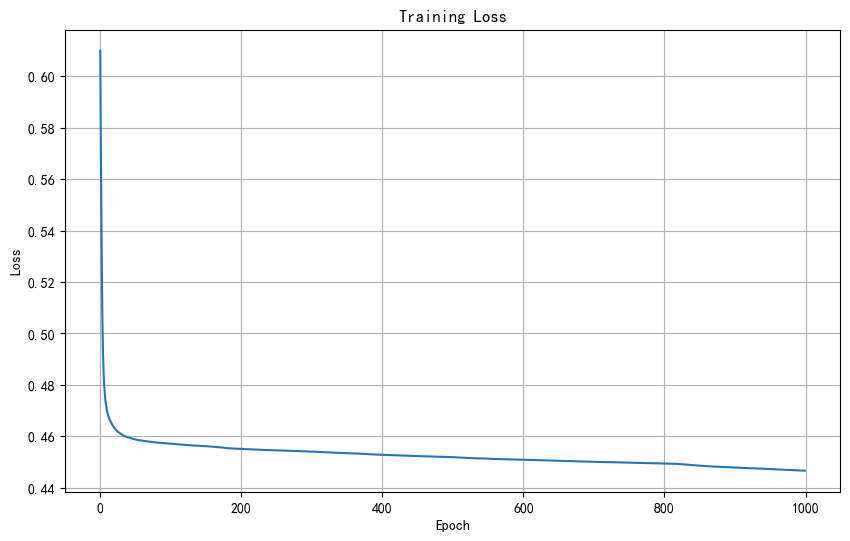
測試集準確率: 77.20%代碼耗時過長,進行優化
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
import time
from tqdm import tqdm
import matplotlib.pyplot as plt
import warnings# 禁用警告
warnings.filterwarnings("ignore")# 設備配置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# ==================== 數據預處理函數 ====================
def preprocess_data(data_path):"""優化點1:封裝預處理邏輯為函數"""data = pd.read_csv(data_path)# 標簽編碼(優化點2:使用字典映射替代if-else)mapping_dicts = {'Home Ownership': {'Own Home': 1, 'Rent': 2, 'Have Mortgage': 3, 'Home Mortgage': 4},'Years in current job': {'< 1 year': 1, '1 year': 2, '2 years': 3, '3 years': 4,'4 years': 5, '5 years': 6, '6 years': 7, '7 years': 8,'8 years': 9, '9 years': 10, '10+ years': 11},'Term': {'Short Term': 0, 'Long Term': 1}}for col, mapping in mapping_dicts.items():data[col] = data[col].map(mapping)# 獨熱編碼(優化點3:自動處理新特征)data = pd.get_dummies(data, columns=['Purpose'], drop_first=True)# 優化點4:自動類型轉換for col in data.select_dtypes(include=['bool', 'uint8']).columns:data[col] = data[col].astype(int)# 優化點5:統一缺失值處理num_cols = data.select_dtypes(include=['int64', 'float64']).columnsdata[num_cols] = data[num_cols].fillna(data[num_cols].mode().iloc[0])return data# ==================== 數據加載與分割 ====================
data = preprocess_data('data.csv')
X = data.drop('Credit Default', axis=1)
y = data['Credit Default']# 優化點6:分層抽樣保證類別平衡
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y
)# 歸一化(優化點7:避免數據泄露)
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# ==================== 模型定義 ====================
class MLP(nn.Module):"""優化點8:參數化模型結構"""def __init__(self, input_dim, hidden_dims=[64, 32], output_dim=2):super().__init__()layers = []prev_dim = input_dim# 動態構建隱藏層for hidden_dim in hidden_dims:layers.extend([nn.Linear(prev_dim, hidden_dim),nn.ReLU(),nn.Dropout(0.3) # 優化點9:添加Dropout防止過擬合])prev_dim = hidden_dimlayers.append(nn.Linear(prev_dim, output_dim))self.net = nn.Sequential(*layers)def forward(self, x):return self.net(x)# ==================== 訓練配置 ====================
# 轉換為Tensor
X_train_t = torch.FloatTensor(X_train).to(device)
y_train_t = torch.LongTensor(y_train.values).to(device)
X_test_t = torch.FloatTensor(X_test).to(device)
y_test_t = torch.LongTensor(y_test.values).to(device)# 創建DataLoader(優化點10:批處理)
train_dataset = TensorDataset(X_train_t, y_train_t)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)# 初始化模型
model = MLP(input_dim=X_train.shape[1]).to(device)# 損失函數與優化器(優化點11:AdamW + 權重衰減)
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-4)# 學習率調度器(優化點12:余弦退火)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=50)# ==================== 訓練循環 ====================
def train_model(model, train_loader, criterion, optimizer, num_epochs=100):"""優化點13:封裝訓練過程"""train_losses = []best_loss = float('inf')patience, counter = 5, 0pbar = tqdm(range(num_epochs), desc="訓練進度")for epoch in pbar:model.train()epoch_loss = 0for batch_X, batch_y in train_loader:optimizer.zero_grad()outputs = model(batch_X)loss = criterion(outputs, batch_y)loss.backward()optimizer.step()epoch_loss += loss.item()# 計算平均損失avg_loss = epoch_loss / len(train_loader)train_losses.append(avg_loss)# 早停機制(優化點14)if avg_loss < best_loss:best_loss = avg_losscounter = 0torch.save(model.state_dict(), 'best_model.pth')else:counter += 1if counter >= patience:print(f"\n早停觸發,最佳損失: {best_loss:.4f}")break# 更新進度條pbar.set_postfix({'Loss': f'{avg_loss:.4f}','LR': f"{optimizer.param_groups[0]['lr']:.2e}"})scheduler.step()return train_losses# 執行訓練
start_time = time.time()
loss_history = train_model(model, train_loader, criterion, optimizer, num_epochs=100)
print(f"訓練耗時: {time.time()-start_time:.2f}秒")# ==================== 結果可視化 ====================
plt.figure(figsize=(10, 5))
plt.plot(loss_history, label='訓練損失')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('訓練損失曲線')
plt.legend()
plt.grid(True)
plt.show()# ==================== 模型評估 ====================
model.load_state_dict(torch.load('best_model.pth'))
model.eval()
with torch.no_grad():y_pred = model(X_test_t)_, predicted = torch.max(y_pred, 1)acc = accuracy_score(y_test, predicted.cpu())print(f"\n測試集準確率: {acc*100:.2f}%")# 優化點15:輸出分類報告
from sklearn.metrics import classification_report
print("\n分類報告:")
print(classification_report(y_test, predicted.cpu()))使用設備: cuda:0
訓練進度: 33%|███▎ | 33/100 [00:06<00:13, 5.12it/s, Loss=0.4611, LR=2.87e-04]早停觸發,最佳損失: 0.4596
訓練耗時: 6.45秒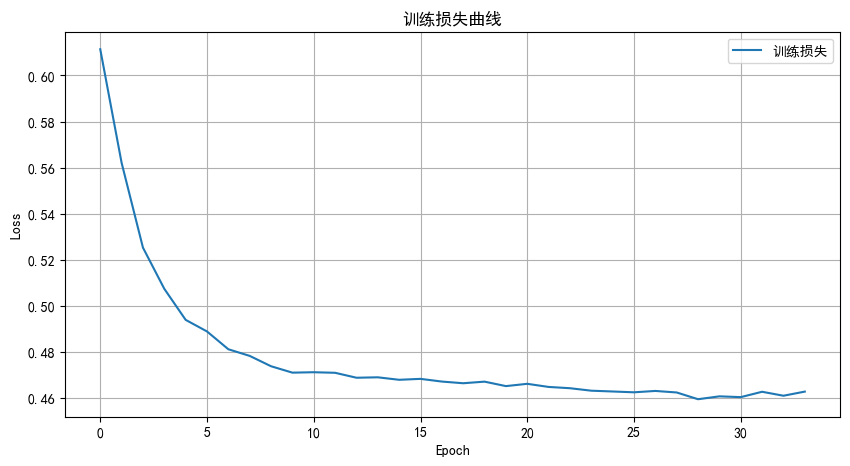
測試集準確率: 77.80%分類報告:precision recall f1-score support0 0.77 0.98 0.86 10771 0.83 0.27 0.40 423accuracy 0.78 1500macro avg 0.80 0.62 0.63 1500
weighted avg 0.79 0.78 0.73 1500探索性作業(隨意完成):
嘗試進入nn.Module中,查看他的方法
方法一:使用?dir()?查看所有方法和屬性
import torch.nn as nn# 列出 nn.Module 的所有方法和屬性
print(dir(nn.Module))這會輸出?nn.Module?的所有成員,包括方法、屬性和特殊方法(以?__?開頭和結尾的)。
方法二:使用?help()?查看詳細文檔
help(nn.Module)這會顯示?nn.Module?的完整文檔,包括方法的詳細說明、參數和返回值。
方法三:查看特定方法的源代碼
如果你想深入了解某個方法的實現,可以使用?inspect?模塊查看源代碼:
import inspect
from torch.nn import Module# 查看 forward 方法的源代碼
print(inspect.getsource(Module.forward)))







)






題解(更新中))

![[C語言實戰]C語言內存管理實戰:實現自定義malloc與free(四)](http://pic.xiahunao.cn/[C語言實戰]C語言內存管理實戰:實現自定義malloc與free(四))
- YOLO知識蒸餾(下)設置蒸餾超參數:以yolov8-pose為例)
