TomatoSCI分析日記——層次聚類
今天介紹的是一種常見的聚類方法——層次聚類。層次聚類會將數據集劃分成嵌套的簇,形成一個層次結構(樹狀圖),經常用于探究樣本的相似性。用大白話來說,就是:我有一大堆樣品,每個樣品都有n個特征,我們通過層次聚類利用這些特征可以把這些樣品劃分為不同的類群。
1.層次聚類的兩種方式
層次聚類通常分為“向下分裂”和“向上合并”兩類。
向下分裂:從一個整體開始,每一步將最不相似的點或子簇分開,直到每個樣本成為單獨的簇。
向上合并:每一步合并兩個最相似的簇,直到只剩一個簇或達到設定的聚類數。
兩種方法各有千秋,向下分裂不容易受異常值影響,向上合并策略更靈活。在實際中,更多的是選擇“向上合并”。
2.如何確定分多少類(簇數)?
在講解實例之前,我們還要確定一件事,就是要分多少類(簇數)。我們最好是通過一個有說服力的指標去確定簇數,而不是分幾簇有利于我的實際情況就去分幾簇,隨意分簇導致的后果就是當我們的分析結果遭到質疑的時候我們往往很難有足夠證據去反駁。
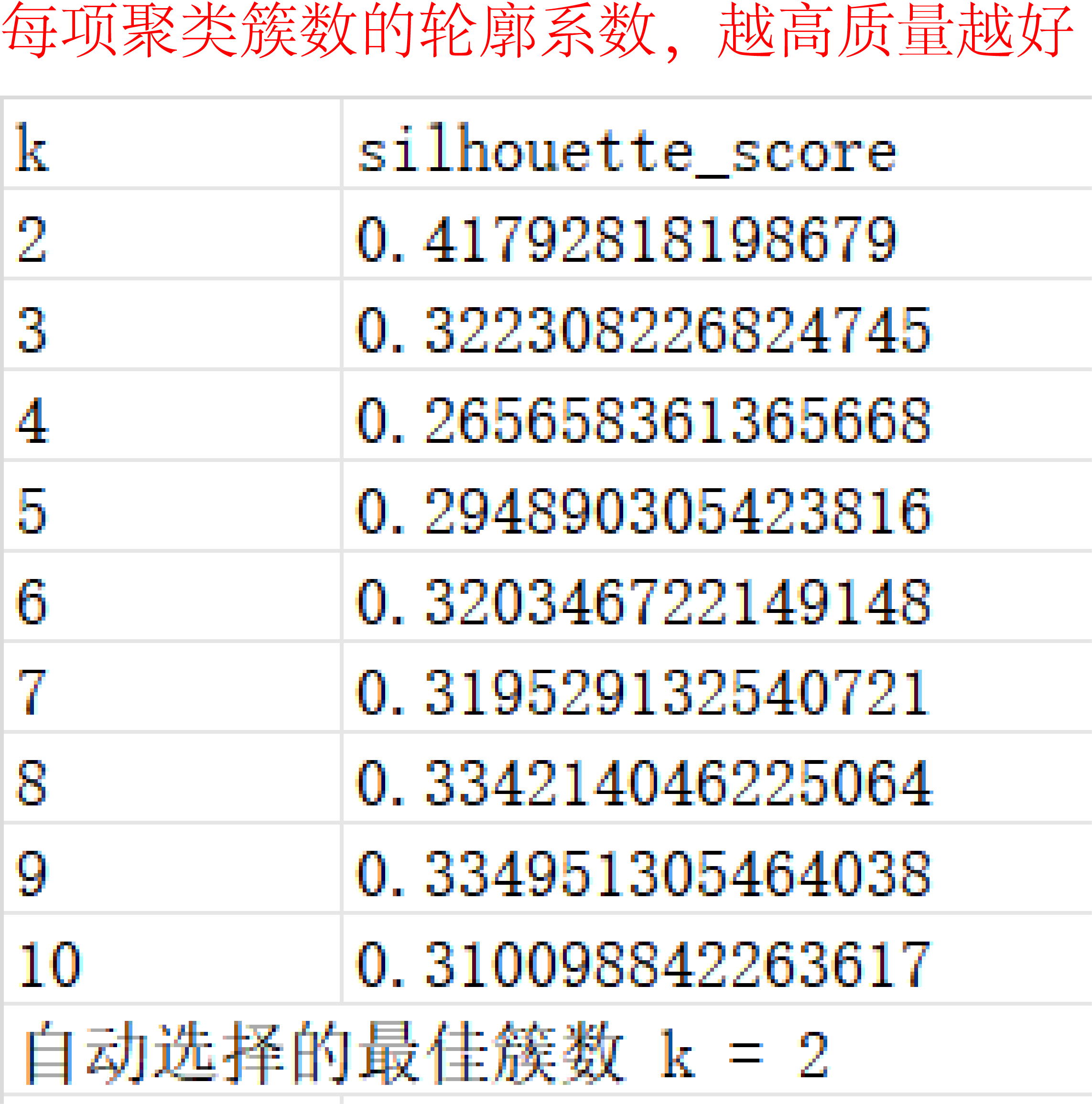
這里就需要引入“輪廓系數”。輪廓系數是衡量聚類效果好壞的一個經典指標,它能夠同時反映數據點與自身簇的緊密度以及與最近鄰簇的分離度,用來評價聚類的合理性。通常使用所有樣本的輪廓系數的平均值對聚類整體質量進行評價,數值越大效果越好。在聚類時,可以比較不同k下的平均輪廓系數,選擇輪廓系數最大時的k。這樣我們的聚類就有了有力的依據。
3.示例
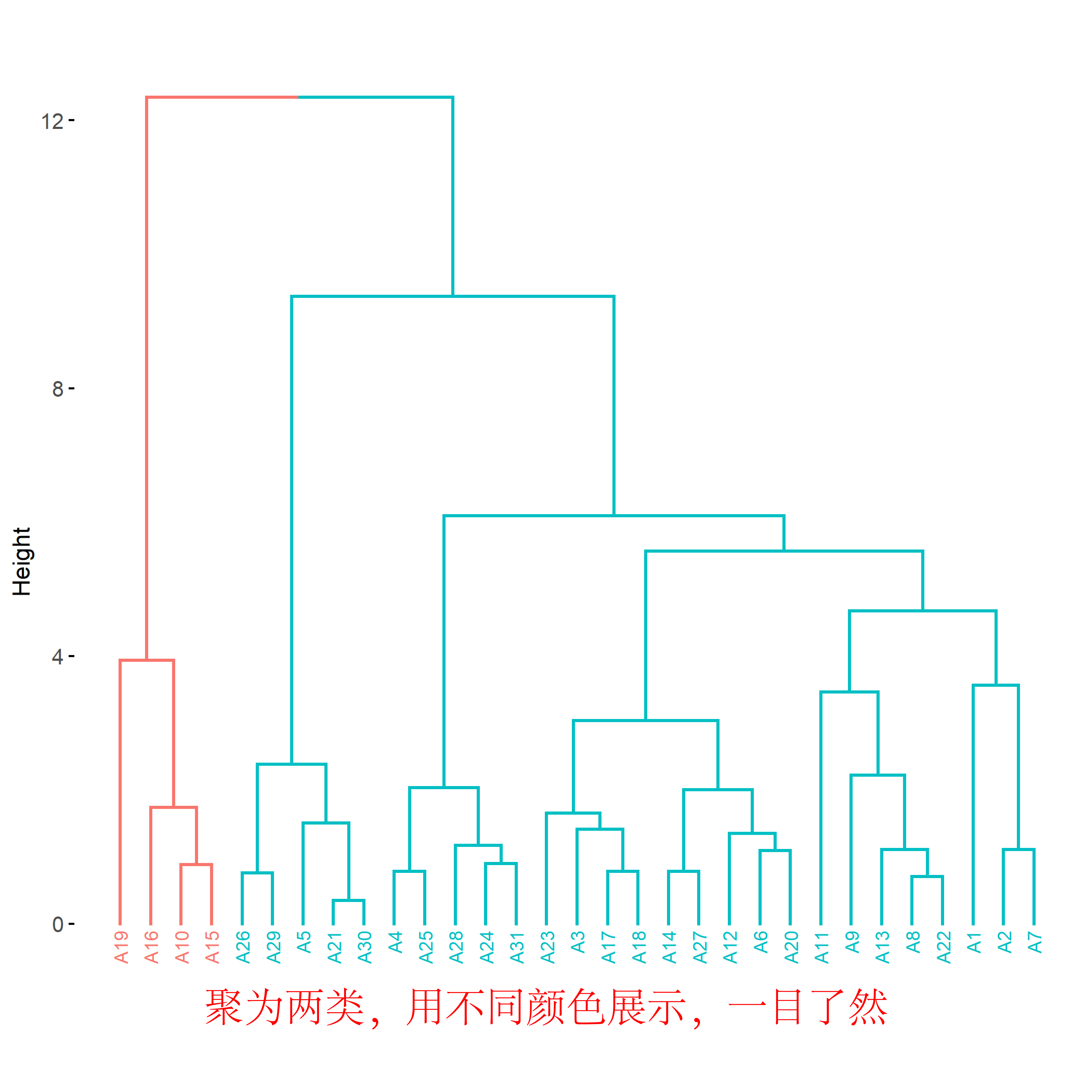
圖1是示例數據,每行為一個樣本,每列為一個特征,量綱如果不同則需要標準化。圖2是聚2-10簇時的輪廓系數,我們可以看到當簇數為2時輪廓系數最大,因此我們選擇聚2類。圖3的樹狀圖是層次聚類的經典可視化方式,使用了不同顏色區分不同簇,結果一目了然。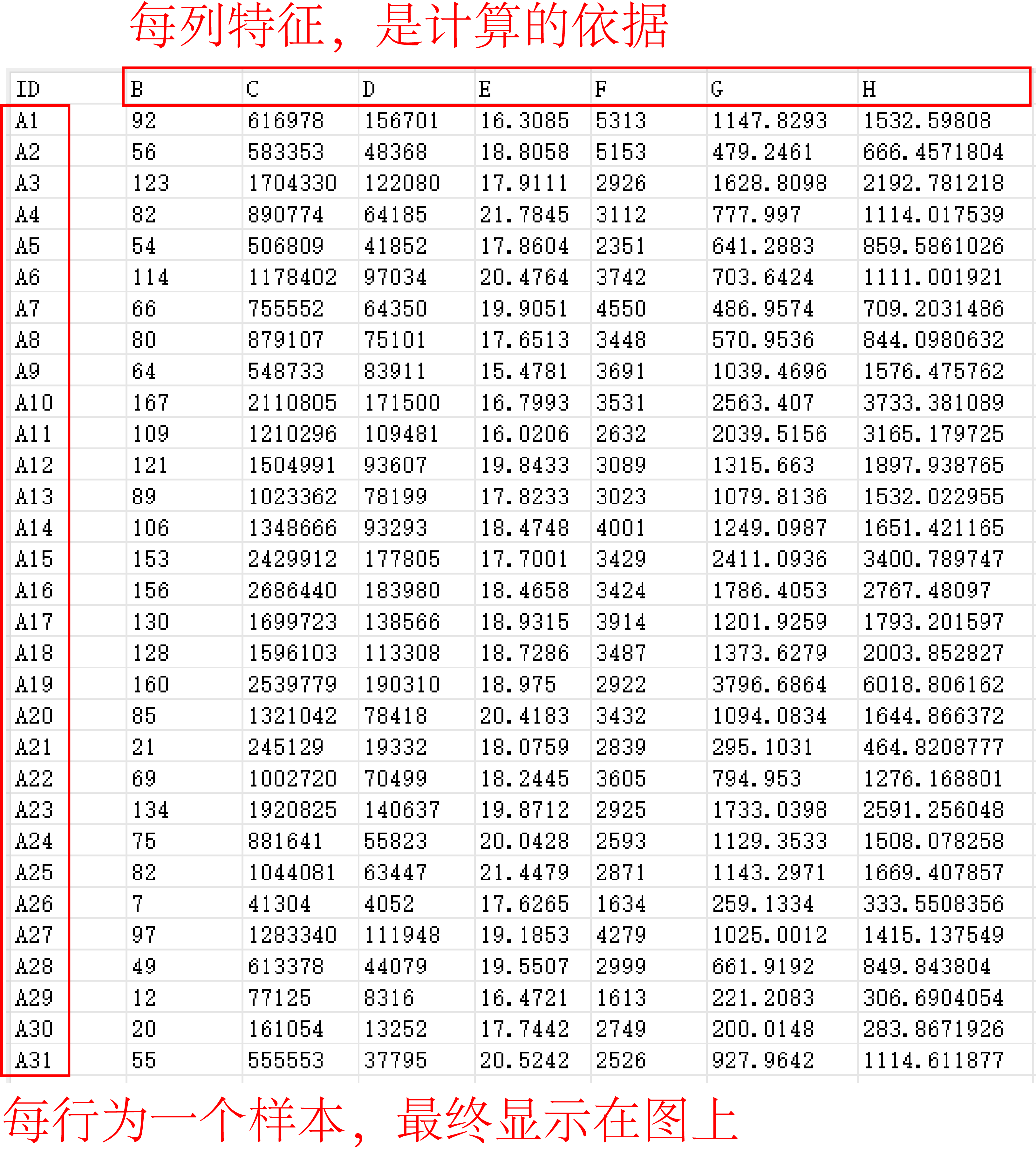
4.結語
歡迎來訪TomatoSCI。等你就位!







)






題解(更新中))

![[C語言實戰]C語言內存管理實戰:實現自定義malloc與free(四)](http://pic.xiahunao.cn/[C語言實戰]C語言內存管理實戰:實現自定義malloc與free(四))
- YOLO知識蒸餾(下)設置蒸餾超參數:以yolov8-pose為例)


