參考視頻:卷積神經網絡(CNN)到底卷了啥?8分鐘帶你快速了解!
我們知道:
圖片是由像素點構成,即最終的成像效果是由背后像素的顏色數值所決定
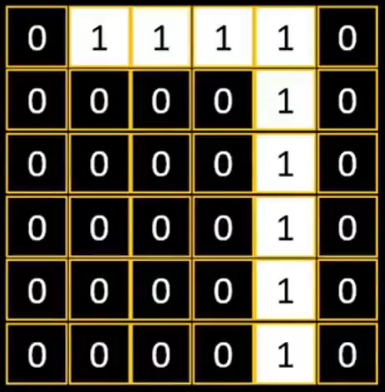
在Excel中:有這樣一個由數值0和1組成的6×6的區域
我們把0設置成黑色、1設置成白色。最終呈現的效果,是不是很像數字7?
 ?
?
而CNN模型能夠告訴我們
這樣一個6×6的像素圖,是否是數字7?或返回它屬于數字0~9的概率分別是多少?
下面,我們對這個CNN模型進行分解:
CNN模型第一步:提取特征,得到特征圖
1、利用多個不同的卷積核(也稱特征過濾器,如 3×3、5×5)對圖像做滑動窗口計算
2、每一個卷積核計算完成后,會得到一張對應的特征圖(一核對一圖)
本例中,需提取水平和垂直兩大特征部分,分別在下面的兩個3×3的卷積核中得到體現
 ?
?
滑動窗口計算規則:
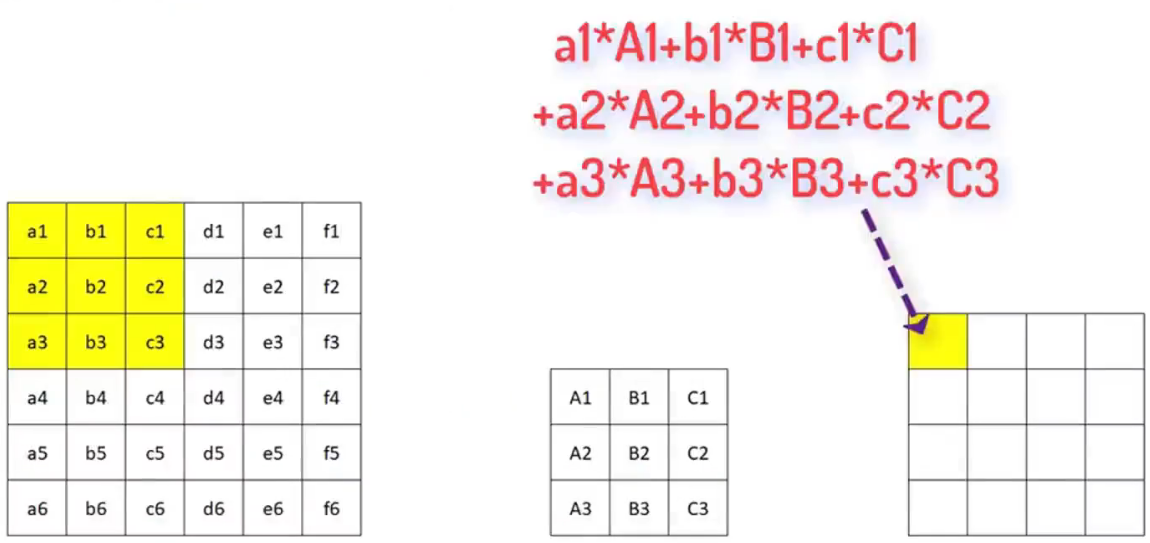
1、先按順序提取原始圖片中3×3的像素區域
2、再將其每個像素單元依次與卷積核內相對應的像素值相乘,再求和
3、再把結果記錄在新的4×4的像素圖上。
注意:輸入圖像、卷積核、特征圖、池化核的尺寸大小,有數學公式關系
這部分主要由卷積操作的參數(如核大小、步長、填充)決定
 ??
??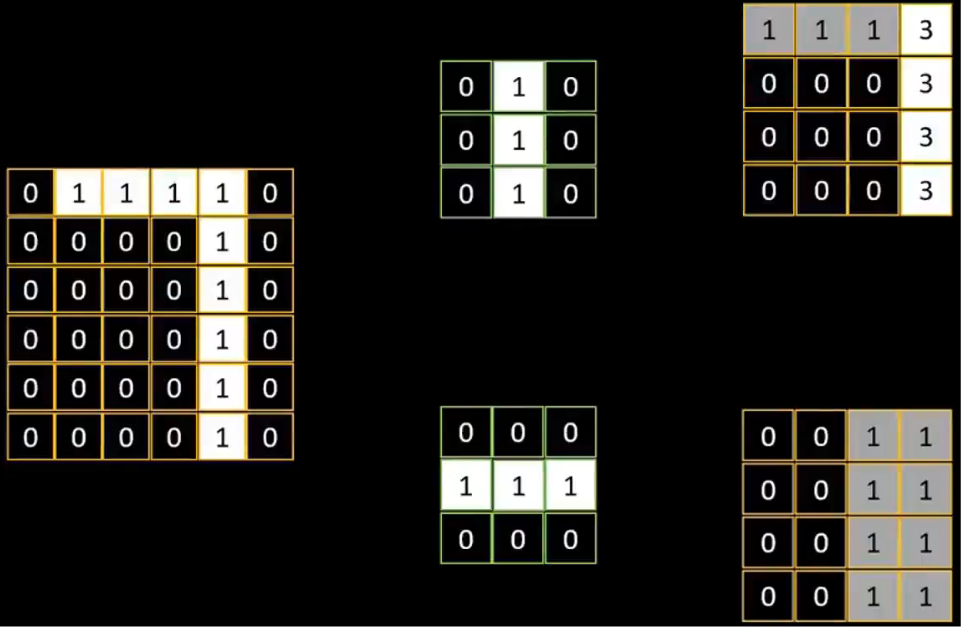
本例整個計算完成后,我們會得到兩個4×4的特征圖(一個卷積核對應一個特征圖)
我們可以看到:
根據特征圖的顏色深淺(數字大小),原始圖片中的7
垂直部分特征被很好提取出來了(明顯),而水平部分特征卻沒被提取出來(不明顯)
這是因為在特征提取計算的過程中,像素圖從原6×6被降維成了4×4,邊緣特征丟失了
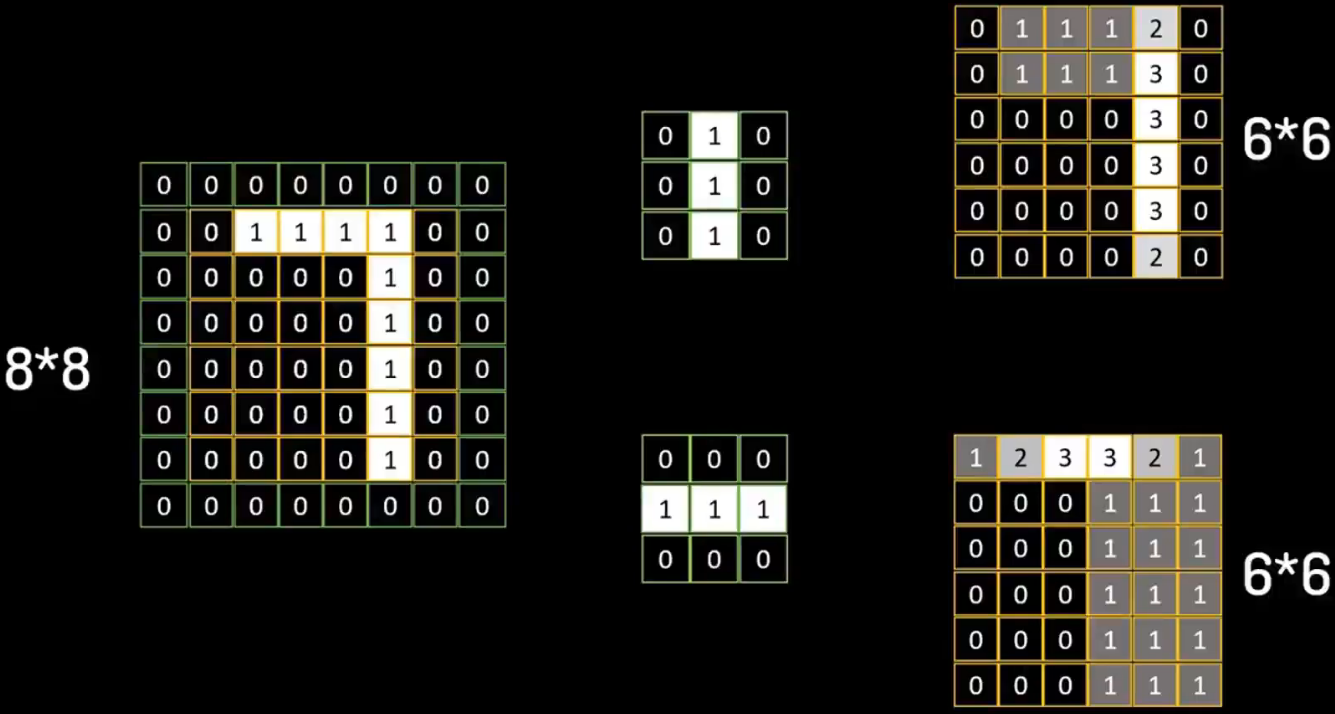
這里使用一種被稱為Padding的擴充方法,為了解決邊緣特征的提取問題
將原始的6×6圖像,先擴充成8×8,擴充部分的像素值均設為 0
這樣,在特征提取計算后,轉化后特征圖的像素同為6×6,最終兩個特征都能完美提取到
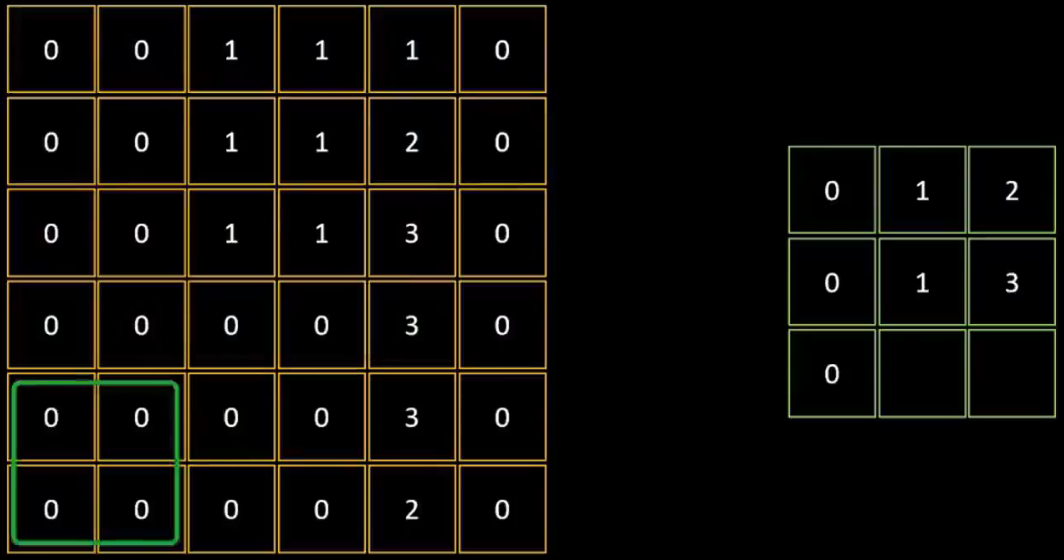
CNN模型的第二步:最大池化Max Pooling
常用最大池化或平均池化,使用池化核(如 2×2)對特征圖降采樣,減少參數數量和計算量,降低數據維度。換句話說,就是將圖片數據進一步壓縮,僅反映特征圖中最突出的特點。
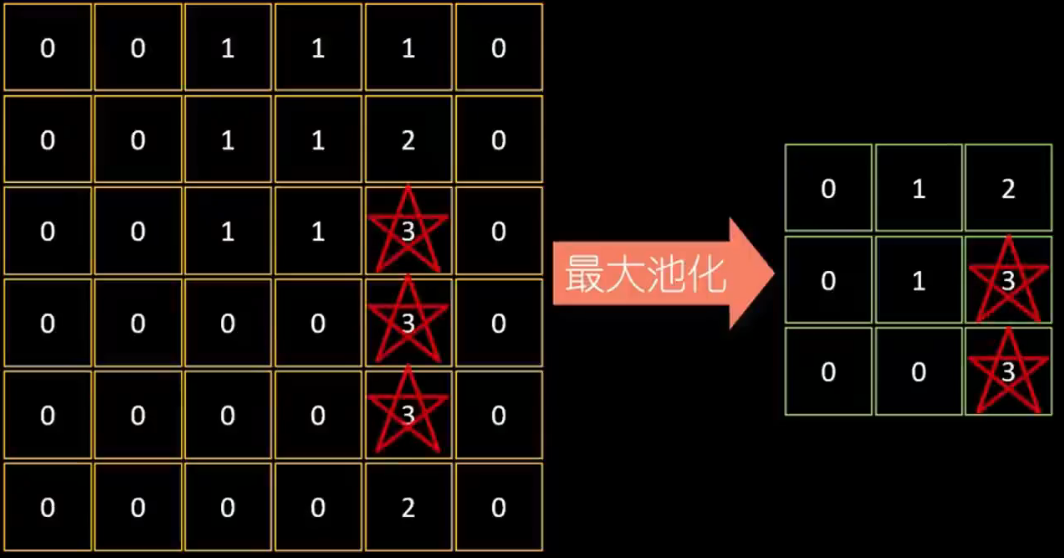
1、將6×6的特征圖,用2×2的網格(池化核),分割成3×3的部分
2、再提取每個部分中的最大值
3、再放于最大池化后的3×3網格中。池化后的數據保留了原始圖中最精華的特征部分
注意:輸入圖像、卷積核、特征圖、池化核的大小之間,有數學公式關系
這部分主要由卷積操作的參數(如核大小、步長、填充)決定
 ?
?
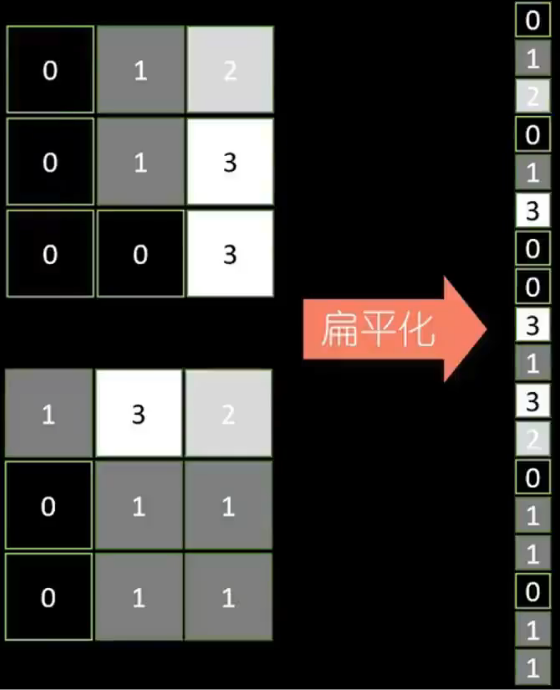
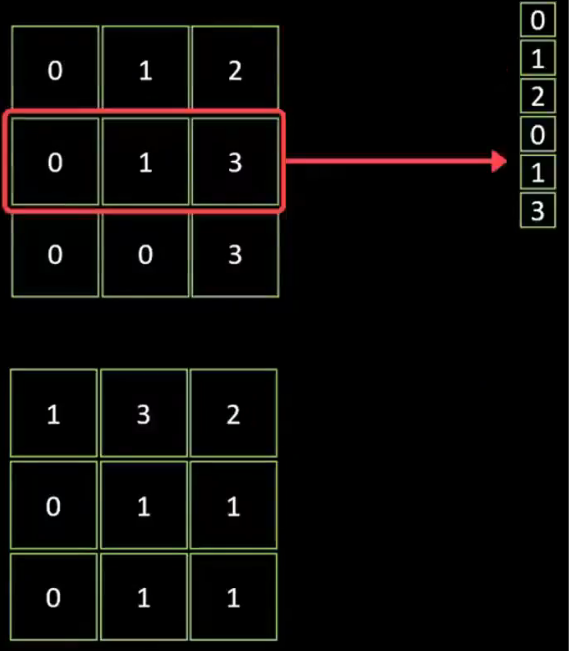
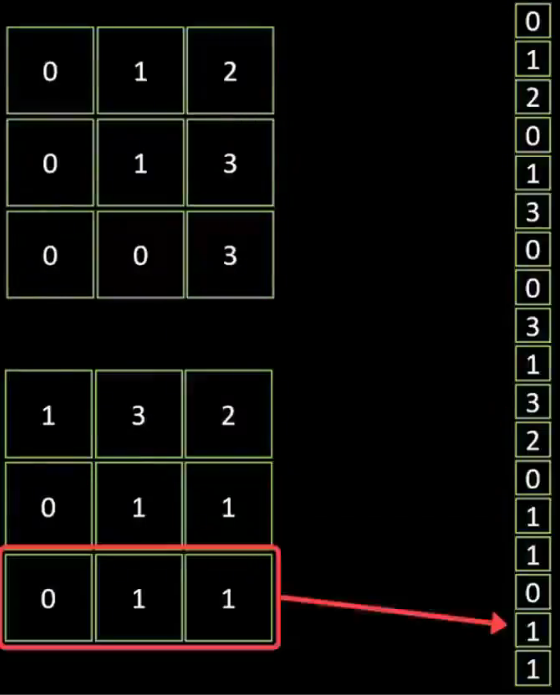
CNN模型第三步:把池化后的數據,做扁平化處理
1、把池化后的兩個3×3的像素圖,疊加轉化成一維的數據條(一維向量)
2、再將數據條錄入到后面的全連接隱藏層,最終產生輸出
 ?
? ?
?
這里提一點:全連接隱藏層
意味著這里的任意一個神經元都與前后層的所有神經元相連接
這樣就可以保證,最終的輸出值,是基于圖片整體信息的結果
在輸出階段:
可使用Sigmoid函數,返回0~1的值,代表該圖片是否是7的概率
也可用Softmax函數,返回該圖案分別屬于0~9的概率
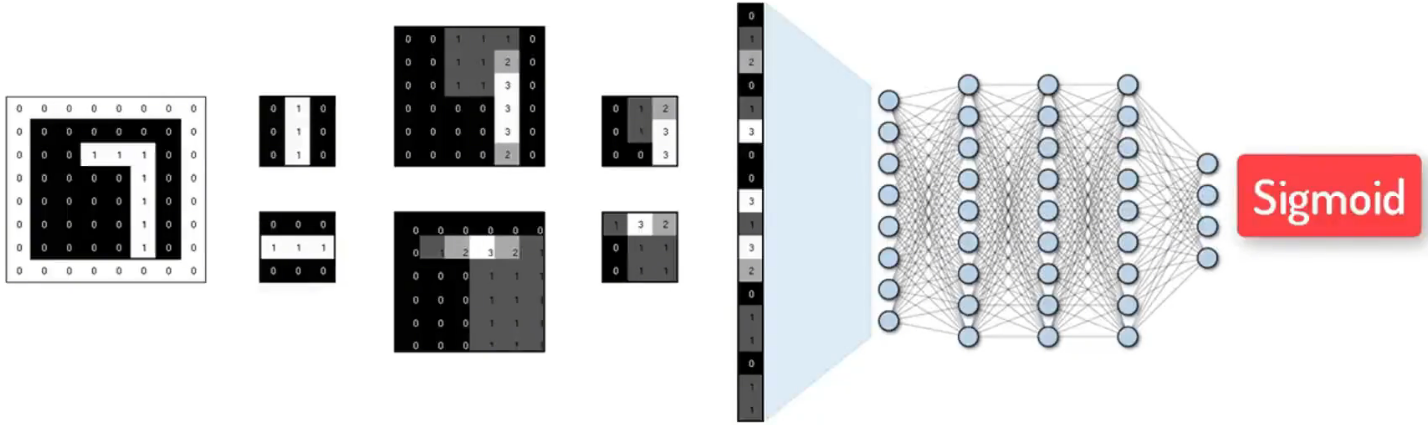
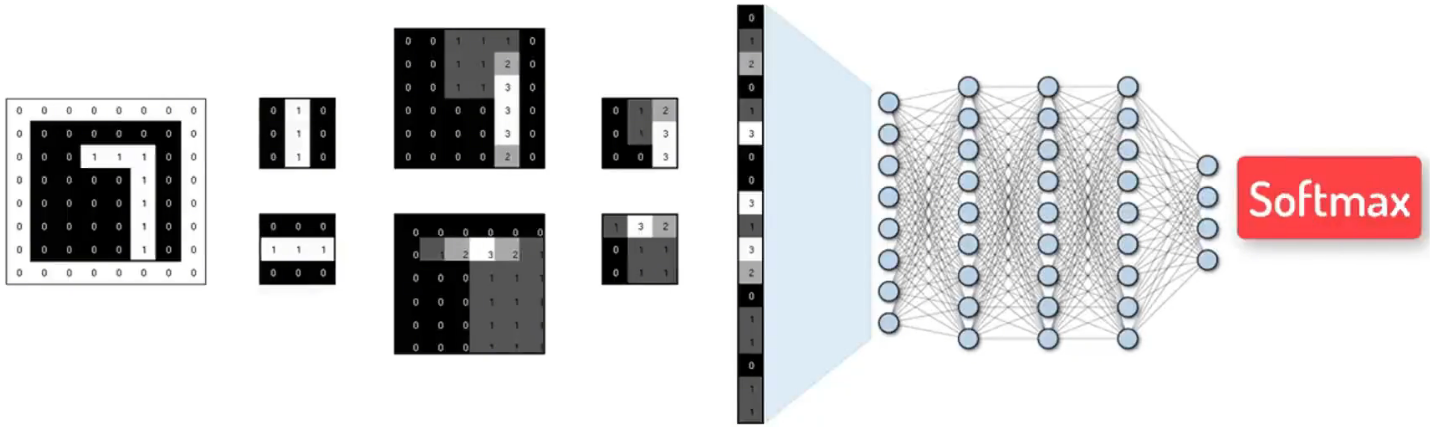
到這里,一個完整的CNN模型的數據流就完成了!

)


)







)






題解(更新中))