
機器學習與深度學習概述 算法入門指南
- 一、引言:機器學習與深度學習
- (一)定義與區別
- (二)發展歷程
- (三)應用場景
- 二、機器學習基礎
- (一)監督學習
- (二)無監督學習
- (三)特征工程
- 三、深度學習入門
- (一)神經網絡基礎
- (二)常用的深度學習框架
- (三)深度學習中的優化算法
- 四、深度學習進階
- (一)卷積神經網絡(CNN)
- (二)循環神經網絡(RNN)及其變體
- (三)生成對抗網絡(GAN)
- 五、模型部署與優化
- (一)模型部署流程
- (二)模型優化技巧
- 六、未來展望與挑戰
- (一)技術發展趨勢
- (二)面臨的挑戰
- 七、附錄
一、引言:機器學習與深度學習
(一)定義與區別
- 機器學習
- 定義:機器學習是人工智能的一個分支,通過算法讓計算機從數據中自動學習規律,從而對新的數據進行預測或決策。
- 核心思想:強調“數據驅動”,通過特征工程提取數據中的有用信息。
- 應用場景:垃圾郵件分類、股票價格預測、客戶畫像等。
- 深度學習
- 定義:深度學習是機器學習的一個子領域,以神經網絡為核心,通過多層結構自動學習數據的特征表示。
- 核心思想:自動提取特征,減少人工干預,能夠處理復雜的非線性關系。
- 應用場景:圖像識別(人臉識別、自動駕駛)、語音識別(智能語音助手)、自然語言處理(機器翻譯、文本生成)等。
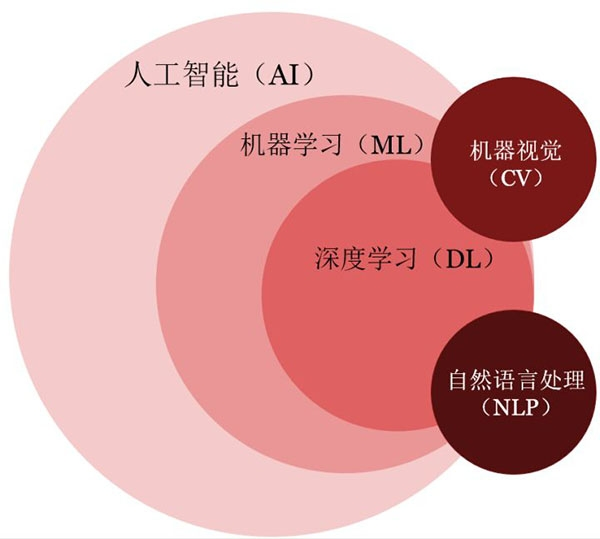
- 兩者關系
- 聯系:深度學習是機器學習的一個重要分支,繼承了機器學習的基本思想,但在特征提取和模型復雜度上有顯著提升。
- 區別:機器學習依賴人工特征工程,而深度學習通過多層神經網絡自動學習特征。
(二)發展歷程
- 機器學習
- 早期發展:20世紀中葉,線性回歸、邏輯回歸等算法被提出,奠定了統計學基礎。
- 中期發展:20世紀末,決策樹、支持向量機(SVM)等算法被廣泛研究和應用。
- 現代應用:隨著數據量的增加和計算能力的提升,機器學習在工業界和學術界得到廣泛應用。
- 深度學習
- 起源:20世紀40年代,人工神經網絡的概念被提出。
- 突破:2012年,Hinton團隊在ImageNet競賽中使用深度卷積神經網絡(CNN)取得突破性成績,標志著深度學習的崛起。
- 發展:近年來,深度學習在圖像識別、語音識別、自然語言處理等領域取得了顯著成果。
(三)應用場景
- 機器學習
- 垃圾郵件分類:通過特征提取(如關鍵詞頻率)和分類算法(如樸素貝葉斯)判斷郵件是否為垃圾郵件。
- 股票價格預測:利用歷史價格數據和回歸算法(如線性回歸)預測未來的股票價格。
- 客戶畫像:通過聚類算法(如K均值)對客戶進行分群,為精準營銷提供支持。
- 深度學習
- 圖像識別:使用卷積神經網絡(CNN)識別圖像中的物體,如人臉識別、自動駕駛中的交通標志識別。
- 語音識別:通過循環神經網絡(RNN)及其變體(如LSTM、GRU)將語音信號轉換為文字。
- 自然語言處理:使用Transformer架構實現機器翻譯、文本生成等任務。
二、機器學習基礎
(一)監督學習
- 算法原理與實例
- 線性回歸
- 原理:通過最小化預測值與真實值之間的平方誤差,找到最佳的線性關系。
- 數學公式:
y = θ 0 + θ 1 x 1 + θ 2 x 2 + ? + θ n x n y = \theta_0 + \theta_1 x_1 + \theta_2 x_2 + \dots + \theta_n x_n y=θ0?+θ1?x1?+θ2?x2?+?+θn?xn? - 實例:房價預測,根據房屋面積、房間數量等特征預測房價。
- 邏輯回歸
- 原理:通過Sigmoid函數將線性回歸的輸出映射到(0,1)區間,用于二分類問題。
- 數學公式:
P ( y = 1 ∣ x ) = 1 1 + e ? ( θ 0 + θ 1 x 1 + ? + θ n x n ) P(y=1|x) = \frac{1}{1 + e^{-(\theta_0 + \theta_1 x_1 + \dots + \theta_n x_n)}} P(y=1∣x)=1+e?(θ0?+θ1?x1?+?+θn?xn?)1? - 實例:醫學診斷,判斷患者是否患有某種疾病。
- 決策樹
- 原理:通過特征選擇(如信息增益、增益率)構建樹形結構,將數據劃分為不同的類別。
- 實例:客戶購買行為預測,根據客戶的年齡、收入等特征判斷其是否購買某產品。
- 支持向量機(SVM)
- 原理:在高維空間中尋找最優分割超平面,最大化不同類別之間的間隔。
- 數學公式:
maximize? 2 ∥ w ∥ subject?to? y i ( w ? x i + b ) ≥ 1 \text{maximize} \ \frac{2}{\|w\|} \quad \text{subject to} \ y_i(w \cdot x_i + b) \geq 1 maximize?∥w∥2?subject?to?yi?(w?xi?+b)≥1 - 實例:圖像分類,將圖像分為不同的類別。
- 線性回歸
- 模型評估方法
- 交叉驗證
- 原理:將數據集劃分為k個子集,每次使用一個子集作為測試集,其余作為訓練集,重復k次。
- 實例:通過10折交叉驗證評估模型的性能。
- 混淆矩陣
- 定義:用于評估分類模型的性能,包括真正例(TP)、假正例(FP)、真負例(TN)、假負例(FN)。
- 指標:準確率(Accuracy)、召回率(Recall)、F1值等。
- 實例:通過混淆矩陣評估醫學診斷模型的性能。
- 交叉驗證
(二)無監督學習
- 算法原理與實例
- K均值聚類
- 原理:通過迭代優化,將數據劃分為k個簇,每個簇內的數據點相似度高,簇間相似度低。
- 實例:客戶分群,根據客戶的消費行為、年齡等特征將客戶劃分為不同群體。
- 主成分分析(PCA)
- 原理:通過降維技術,將高維數據投影到低維空間,同時保留數據的主要特征。
- 實例:高維數據可視化,將多維數據降維到2D或3D進行可視化。
- K均值聚類
- 聚類效果評估
- 輪廓系數
- 定義:衡量聚類效果的指標,值越接近1,聚類效果越好。
- 實例:通過輪廓系數選擇合適的聚類簇數。
- 輪廓系數
(三)特征工程
- 特征選擇
- 過濾法
- 原理:基于統計學方法(如卡方檢驗)篩選與目標變量相關性高的特征。
- 實例:在文本分類中,通過卡方檢驗篩選關鍵詞。
- 包裹法
- 原理:通過模型性能(如交叉驗證準確率)選擇特征。
- 實例:遞歸特征消除法(RFE)用于選擇對模型性能貢獻最大的特征。
- 過濾法
- 特征構造
- 多項式特征
- 原理:通過原始特征構造新的特征,如 ( x_1^2, x_1 x_2 ) 等,提升模型性能。
- 實例:在房價預測中,構造房屋面積的平方特征。
- 交互特征
- 原理:結合不同特征生成新的特征,如用戶年齡與消費頻次的交互特征。
- 實例:在客戶購買行為預測中,構造年齡與收入的交互特征。
- 多項式特征
- 特征歸一化與標準化
- 歸一化
- 原理:將特征值縮放到[0,1]區間,公式為
x ′ = x ? min ? ( x ) max ? ( x ) ? min ? ( x ) x' = \frac{x - \min(x)}{\max(x) - \min(x)} x′=max(x)?min(x)x?min(x)? - 實例:在距離計算中,避免不同量綱特征對結果的影響。
- 原理:將特征值縮放到[0,1]區間,公式為
- 標準化
- 原理:將特征值轉換為均值為0,標準差為1的分布,公式為
x ′ = x ? μ σ x' = \frac{x - \mu}{\sigma} x′=σx?μ? - 實例:在機器學習模型中,避免不同量綱特征對模型的影響。
- 原理:將特征值轉換為均值為0,標準差為1的分布,公式為
- 歸一化
三、深度學習入門
(一)神經網絡基礎
- 神經元模型
- 生物神經元與人工神經元
- 類比:生物神經元通過突觸傳遞信號,人工神經元通過權重和激活函數模擬這一過程。
- 結構:輸入(特征)、權重、偏置、激活函數、輸出。
- 激活函數
- Sigmoid函數:將輸出映射到(0,1)區間,公式為
σ ( x ) = 1 1 + e ? x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e?x1? - ReLU函數:將負值置為0,正值保持不變,公式為
ReLU ( x ) = max ? ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x) - 實例:在神經網絡中,選擇合適的激活函數可以加速訓練并避免梯度消失問題。
- Sigmoid函數:將輸出映射到(0,1)區間,公式為
- 生物神經元與人工神經元
- 神經網絡結構
- 單層感知機
- 原理:只能解決線性可分問題,通過線性組合和激活函數輸出結果。
- 局限性:無法處理非線性問題。
- 多層感知機(MLP)
- 原理:通過隱藏層解決非線性問題,隱藏層的神經元可以提取數據的復雜特征。
- 實例:手寫數字識別,通過多層感知機提取數字的特征并進行分類。
- 單層感知機
- 前向傳播與反向傳播
- 前向傳播
- 過程:從輸入層到輸出層逐層計算,最終得到預測值。
- 實例:在神經網絡中,輸入特征通過每一層的計算得到最終輸出。
- 反向傳播
- 原理:通過鏈式法則計算梯度,更新網絡的權重,以最小化損失函數。
- 實例:在訓練過程中,通過反向傳播調整權重,使模型的預測值接近真實值。
- 前向傳播
(二)常用的深度學習框架
- TensorFlow
- 特點
- 計算圖:通過構建靜態計算圖優化計算效率。
- 硬件加速:支持GPU、TPU等硬件加速。
- 特點
- PyTorch
- 特點
- 動態圖:通過動態圖便于調試和開發。
- 靈活性:支持自定義操作和靈活的張量操作。
- 特點
(三)深度學習中的優化算法
- 梯度下降法
- 批量梯度下降
- 原理:每次更新使用全部數據,計算梯度,更新公式為
θ = θ ? α ? θ J ( θ ) \theta = \theta - \alpha \nabla_\theta J(\theta) θ=θ?α?θ?J(θ) - 優點:收斂穩定。
- 缺點:計算量大,速度慢。
- 原理:每次更新使用全部數據,計算梯度,更新公式為
- 隨機梯度下降
- 原理:每次只用一個樣本更新,更新公式為
θ = θ ? α ? θ J ( θ ; x ( i ) ; y ( i ) ) \theta = \theta - \alpha \nabla_\theta J(\theta; x^{(i)}; y^{(i)}) θ=θ?α?θ?J(θ;x(i);y(i)) - 優點:計算速度快。
- 缺點:收斂過程有波動。
- 原理:每次只用一個樣本更新,更新公式為
- 小批量梯度下降
- 原理:每次使用小批量數據更新,綜合了批量和隨機梯度下降的優點。
- 實例:在深度學習中,通常使用小批量梯度下降進行訓練。
- 批量梯度下降
- 動量優化算法
- 原理:在梯度下降中引入動量項,公式為
v = γ v ? α ? θ J ( θ ) θ = θ + v \begin{aligned} v &= \gamma v - \alpha \nabla_\theta J(\theta) \\ \theta &= \theta + v \end{aligned} vθ?=γv?α?θ?J(θ)=θ+v?- 作用:加快收斂速度,避免局部最優。
- 實例:在訓練深度神經網絡時,動量優化算法可以加速收斂。
- 原理:在梯度下降中引入動量項,公式為
- Adam優化算法
- 原理:結合了動量和自適應學習率的優點,公式為
m = β 1 m + ( 1 ? β 1 ) ? θ J ( θ ) v = β 2 v + ( 1 ? β 2 ) ( ? θ J ( θ ) ) 2 θ = θ ? α m v + ? \begin{aligned} m &= \beta_1 m + (1 - \beta_1) \nabla_\theta J(\theta) \\ v &= \beta_2 v + (1 - \beta_2) (\nabla_\theta J(\theta))^2 \\ \theta &= \theta - \alpha \frac{m}{\sqrt{v} + \epsilon} \end{aligned} mvθ?=β1?m+(1?β1?)?θ?J(θ)=β2?v+(1?β2?)(?θ?J(θ))2=θ?αv?+?m?? - 優點:自適應調整學習率,適合處理稀疏梯度。
- 實例:在深度學習中,Adam優化算法是常用的優化算法之一。
- 原理:結合了動量和自適應學習率的優點,公式為
四、深度學習進階
(一)卷積神經網絡(CNN)
- 卷積層
- 卷積操作
- 原理:通過濾波器在輸入數據上滑動,提取局部特征。
- 實例:在圖像處理中,使用卷積操作提取邊緣特征。
- 濾波器參數
- 大小:如3×3、5×5等,影響特征提取的范圍。
- 數量:決定輸出特征圖的維度。
- 步長:決定濾波器移動的步長,步長越大,輸出特征圖越小。
- 卷積操作
- 池化層
- 最大池化
- 原理:在局部區域內取最大值,減少特征圖的尺寸。
- 實例:在圖像分類中,通過最大池化保留重要特征。
- 平均池化
- 原理:在局部區域內取平均值,平滑特征。
- 實例:在圖像處理中,通過平均池化減少噪聲。
- 最大池化
- 全連接層
- 作用:將卷積層和池化層提取的特征進行整合,用于分類或回歸任務。
- 實例:在圖像分類任務中,全連接層將特征圖展平后進行分類。
- 經典CNN架構
- LeNet
- 結構:簡單的卷積神經網絡,用于手寫數字識別。
- 特點:包含卷積層、池化層和全連接層。
- AlexNet
- 結構:在ImageNet競賽中取得突破性成果,包含多個卷積層和全連接層。
- 特點:使用ReLU激活函數,引入Dropout防止過擬合。
- VGGNet
- 結構:使用多個3×3卷積層堆疊,結構簡單但參數量大。
- 特點:適用于圖像分類任務。
- ResNet
- 結構:引入殘差連接,解決了深層網絡訓練困難的問題。
- 特點:可以構建非常深的網絡,如ResNet-50、ResNet-101等。
- LeNet
(二)循環神經網絡(RNN)及其變體
- RNN基本原理
- 結構
- 時間步:RNN通過時間步處理序列數據,每個時間步的輸出依賴于前一時間步的輸出。
- 公式:
h t = f ( W h h h t ? 1 + W x h x t + b h ) h_t = f(W_{hh} h_{t-1} + W_{xh} x_t + b_h) ht?=f(Whh?ht?1?+Wxh?xt?+bh?)
- 實例
- 文本生成:根據前一個字符生成下一個字符。
- 問題:梯度消失和梯度爆炸問題,導致無法處理長序列。
- 結構
- 長短期記憶網絡(LSTM)
-
結構
- 輸入門:控制新信息進入細胞狀態。
- 遺忘門:控制舊信息從細胞狀態中移除。
- 輸出門:控制細胞狀態輸出到隱藏狀態。
- 公式:
i t = σ ( W x i x t + W h i h t ? 1 + b i ) f t = σ ( W x f x t + W h f h t ? 1 + b f ) o t = σ ( W x o x t + W h o h t ? 1 + b o ) c ~ t = tanh ? ( W x c x t + W h c h t ? 1 + b c ) c t = f t c t ? 1 + i t c ~ t h t = o t tanh ? ( c t ) \begin{aligned} i_t &= \sigma(W_{xi} x_t + W_{hi} h_{t-1} + b_i) \\ f_t &= \sigma(W_{xf} x_t + W_{hf} h_{t-1} + b_f) \\ o_t &= \sigma(W_{xo} x_t + W_{ho} h_{t-1} + b_o) \\ \tilde{c}_t &= \tanh(W_{xc} x_t + W_{hc} h_{t-1} + b_c) \\ c_t &= f_t c_{t-1} + i_t \tilde{c}_t \\ h_t &= o_t \tanh(c_t) \end{aligned} it?ft?ot?c~t?ct?ht??=σ(Wxi?xt?+Whi?ht?1?+bi?)=σ(Wxf?xt?+Whf?ht?1?+bf?)=σ(Wxo?xt?+Who?ht?1?+bo?)=tanh(Wxc?xt?+Whc?ht?1?+bc?)=ft?ct?1?+it?c~t?=ot?tanh(ct?)?
-
實例
- 機器翻譯:通過編碼器 - 解碼器架構將源語言翻譯為目標語言。
- 優勢:解決了RNN中的梯度消失問題,能夠處理長序列。
-
- 門控循環單元(GRU)
- 結構
- 更新門:控制舊信息的保留和新信息的更新。
- 重置門:控制舊信息對新信息的影響。
- 公式:
z t = σ ( W x z x t + W h z h t ? 1 + b z ) r t = σ ( W x r x t + W h r h t ? 1 + b r ) h ~ t = tanh ? ( W x h x t + W h h ( r t h t ? 1 ) + b h ) h t = ( 1 ? z t ) h t ? 1 + z t h ~ t \begin{aligned} z_t &= \sigma(W_{xz} x_t + W_{hz} h_{t-1} + b_z) \\ r_t &= \sigma(W_{xr} x_t + W_{hr} h_{t-1} + b_r) \\ \tilde{h}_t &= \tanh(W_{xh} x_t + W_{hh} (r_t h_{t-1}) + b_h) \\ h_t &= (1 - z_t) h_{t-1} + z_t \tilde{h}_t \end{aligned} zt?rt?h~t?ht??=σ(Wxz?xt?+Whz?ht?1?+bz?)=σ(Wxr?xt?+Whr?ht?1?+br?)=tanh(Wxh?xt?+Whh?(rt?ht?1?)+bh?)=(1?zt?)ht?1?+zt?h~t??
- 實例
- 語音識別:將語音信號轉換為文字。
- 優勢:結構比LSTM簡單,訓練速度更快。
- 結構
- 應用案例
- 機器翻譯
- 編碼器 - 解碼器架構:編碼器將源語言序列編碼為固定長度的向量,解碼器將其解碼為目標語言序列。
- 實例:將英文翻譯為中文。
- 語音識別
- 過程:將語音信號轉換為特征向量,通過RNN及其變體進行建模,輸出文字。
- 實例:智能語音助手(如Siri、小愛同學)。
- 機器翻譯
(三)生成對抗網絡(GAN)
- 生成器與判別器
- 生成器
- 作用:生成虛假數據,使其盡可能接近真實數據。
- 結構:通常是一個神經網絡,輸入噪聲向量,輸出生成的數據。
- 實例:生成圖像、文本等。
- 判別器
- 作用:判斷輸入數據是真實數據還是虛假數據。
- 結構:通常是一個神經網絡,輸出一個概率值,表示輸入數據為真實數據的概率。
- 實例:判斷圖像是否為真實圖像。
- 生成器
- 訓練過程
- 交替訓練
- 過程:生成器和判別器交替更新,生成器試圖欺騙判別器,判別器試圖正確區分真實和虛假數據。
- 公式:
min ? G max ? D V ( D , G ) = E x ~ p data ( x ) [ log ? D ( x ) ] + E z ~ p z ( z ) [ log ? ( 1 ? D ( G ( z ) ) ) ] \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log (1 - D(G(z)))] Gmin?Dmax?V(D,G)=Ex~pdata?(x)?[logD(x)]+Ez~pz?(z)?[log(1?D(G(z)))]
- 實例
- 圖像生成:通過GAN生成藝術圖像、虛擬人物等。
- 數據增強:在小樣本數據集上通過生成數據提升模型性能。
- 交替訓練
- 應用領域
- 圖像生成
- 實例:生成藝術圖像、虛擬人物等。
- 數據增強
- 實例:在醫學圖像領域,通過生成數據擴充數據集。
- 圖像生成
五、模型部署與優化
(一)模型部署流程
- 模型保存與加載
- 保存模型
- TensorFlow:使用
model.save()保存模型為H5文件或SavedModel格式。 - PyTorch:使用
torch.save()保存模型的權重。
- TensorFlow:使用
- 加載模型
- TensorFlow:使用
tf.keras.models.load_model()加載模型。 - PyTorch:使用
torch.load()加載模型權重。
- TensorFlow:使用
- 保存模型
- 模型轉換
- ONNX格式
- 定義:ONNX(Open Neural Network Exchange)是一種開放的模型格式,支持多種深度學習框架之間的模型轉換。
- 實例:將TensorFlow模型轉換為ONNX格式,然后在PyTorch中加載。
- ONNX格式
- 部署平臺
- 服務器端部署
- API接口:使用Flask或FastAPI等框架搭建API接口,將模型部署到服務器上。
- 實例:通過API接口接收用戶請求,返回模型預測結果。
- 移動端部署
- 模型壓縮:通過剪枝、量化等技術減小模型大小。
- 實例:將模型部署到移動設備上,如iOS或Android應用。
- 服務器端部署
(二)模型優化技巧
- 模型剪枝
- 原理:去除不重要的權重或神經元,減少模型大小和計算量。
- 實例:通過剪枝將模型的參數量減少一半,同時保持性能。
- 模型量化
- 原理:將模型參數從浮點數轉換為低精度表示(如INT8),加速模型推理速度。
- 實例:將模型量化后部署到邊緣設備上,提升推理速度。
- 知識蒸餾
- 原理:將復雜模型的知識遷移到輕量級模型,提升輕量級模型的性能。
- 實例:通過知識蒸餾將ResNet-50的知識遷移到MobileNet,提升MobileNet的性能。
六、未來展望與挑戰
(一)技術發展趨勢
- 自動機器學習(AutoML)
- 定義:通過自動化流程選擇模型、調整超參數,降低算法工程師的工作負擔。
- 實例:使用AutoML工具(如Google AutoML)自動選擇最佳模型和超參數。
- 強化學習與深度學習的結合
- 定義:強化學習通過與環境交互獲得獎勵,深度學習用于建模和優化。
- 實例:在機器人控制中,通過強化學習和深度學習實現自主決策。
- 聯邦學習
- 定義:在數據隱私保護的前提下,通過分布式訓練實現模型優化。
- 實例:在醫療領域,通過聯邦學習在不同醫院之間共享模型,保護患者隱私。
(二)面臨的挑戰
- 數據隱私與安全
- 問題:在大規模數據收集和使用過程中,如何保護用戶隱私,防止數據泄露。
- 解決方案:使用加密技術、差分隱私等方法保護數據隱私。
- 模型可解釋性
- 問題:深度學習模型通常被視為“黑盒”,難以解釋其決策過程。
- 解決方案:開發可解釋性工具(如LIME、SHAP)幫助理解模型的決策依據。
- 算力需求
- 問題:隨著模型規模的增大,對計算資源的需求越來越高。
- 解決方案:使用更高效的硬件(如GPU、TPU)、優化算法(如分布式訓練)。
七、附錄
- 數學基礎
- 線性代數
- 向量與矩陣運算:加法、乘法、轉置等。
- 特征值與特征向量:在PCA和SVD中的應用。
- 概率論
- 概率分布:高斯分布、伯努利分布等。
- 貝葉斯定理:在樸素貝葉斯分類器中的應用。
- 優化理論
- 梯度下降法:原理和應用。
- 拉格朗日乘數法:在約束優化中的應用。
- 線性代數
- 編程基礎
- Python基礎
- 數據結構:列表、字典、集合等。
- 函數與類:定義和使用。
- NumPy庫
- 數組操作:創建、索引、切片等。
- 矩陣運算:加法、乘法、轉置等。
- Pandas庫
- 數據處理:讀取、清洗、篩選數據。
- 數據可視化:使用Matplotlib和Seaborn繪制圖表。
- Python基礎
- 實驗與實踐
- 實驗設計
- 數據集選擇:常見的機器學習和深度學習數據集。
- 實驗流程:數據預處理、模型訓練、模型評估。
- 實踐項目
- 機器學習項目:垃圾郵件分類、房價預測等。
- 深度學習項目:手寫數字識別、圖像分類、文本生成等。
- 實驗設計
![[C語言初階]掃雷小游戲](http://pic.xiahunao.cn/[C語言初階]掃雷小游戲)


 - /安全與維護組件/ai-predictive-maintenance-turbine)



)






)

)


