Lora-Tuning
什么是Lora微調?
LoRA(Low-Rank Adaptation) 是一種參數高效微調方法(PEFT, Parameter-Efficient Fine-Tuning),它通過引入低秩矩陣到預訓練模型的權重變換中,實現無需大規模修改原模型參數即可完成下游任務的微調。即你微調后模型的參數 =?凍結模型參數 + Lora微調參數。
什么是微調?
在早期的機器學習中,構建一個模型并對其進行訓練是可行的。但到了深度學習階段,模型的參數量大且訓練的數據多,因此要從0到1訓練一個模型是非常耗時和耗資源的過程。
訓練,在其最簡單的意義上。您將一個未經訓練的模型,提供給它數據,并獲得一個高性能的模型。
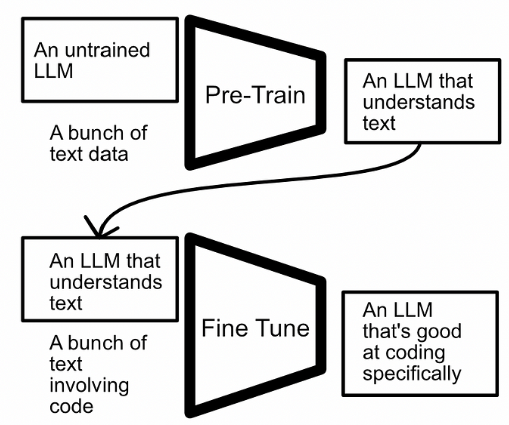
對于簡單問題來說,這仍然是一種流行的策略,但對于更復雜的問題,將訓練分為兩個部分,即“預訓練”和“微調”,可能會很有用。總體思路是在一個大規模數據集上進行初始訓練,并在一個定制的數據集上對模型進行優化。
最基本的微調形式?是使用與預訓練模型相同的過程來微調新數據上的模型。例如,您可以在大量的通用文本數據上訓練模型,然后使用相同的訓練策略,在更具體的數據集上微調該模型。
目前的話,在深度學習中,你所用的預訓練的模型就是別人從0到1訓練好給你用的,你后面的基于特定數據集所做的訓練其實是基于已有模型參數的基礎上去進行微調。
那在深度學習階段,這種方式消耗GPU的程度還可以接收,那到了LLM階段,如果想通過微調全部參數來微調上一個已預訓練好的沒有凍結參數模型的話,那消費的GPU就不是一個量級上的,因此Lora就是針對LLM微調消耗資源大所提出優化方案。
Lora的思想
“低秩適應”(LoRA)是一種“參數高效微調”(PEFT)的形式,它允許使用少量可學習參數對大型模型進行微調 。LoRA改善微調的幾個關鍵點:
- 將微調視為學習參數的變化(
),而不是調整參數本身(
)。 ?
- 通過刪除重復信息,將這些變化壓縮成較小的表示。 ?
- 通過簡單地將它們添加到預訓練參數中來“加載”新的變化。
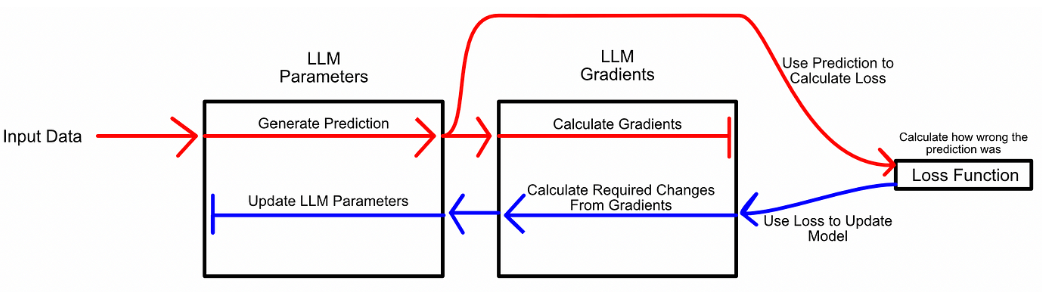
正如之前討論的,微調的最基本方法是迭代地更新參數。就像正常的模型訓練一樣,你讓模型進行推理,然后根據推理的錯誤程度更新模型的參數(反向傳播)。
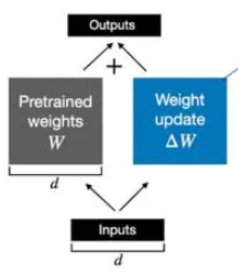
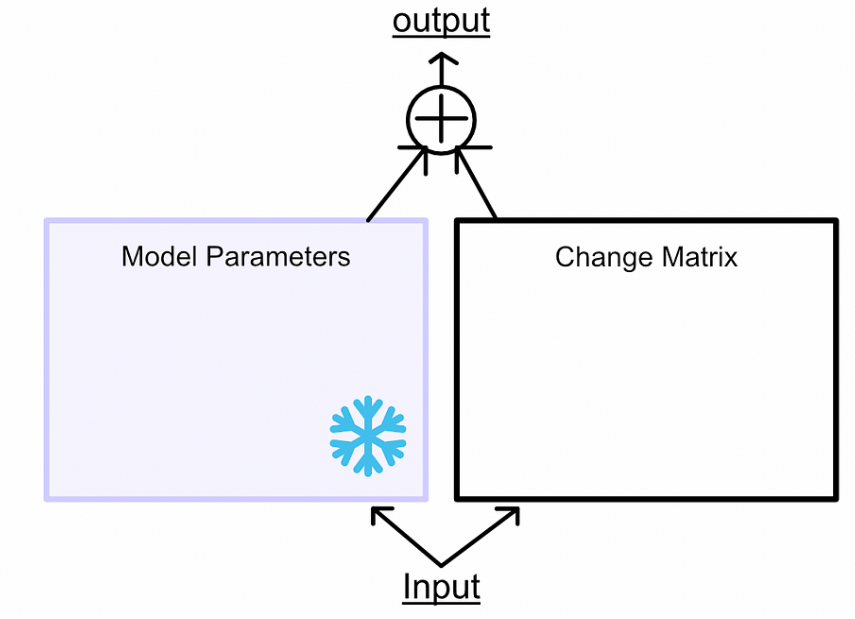
與其將微調視為學習更好的參數,LoRA 將微調視為學習參數變化:凍結模型參數,然后學習使模型在微調任務中表現更好所需的這些參數的變化。類似于訓練,首先讓模型推理,然后根據error進行更新。但是,不更新模型參數,而是更新模型參數的變化。如下面所示,藍色箭頭反向傳播只是去微調模型所需要的參數變化,沒有去微調模型原有的參數。
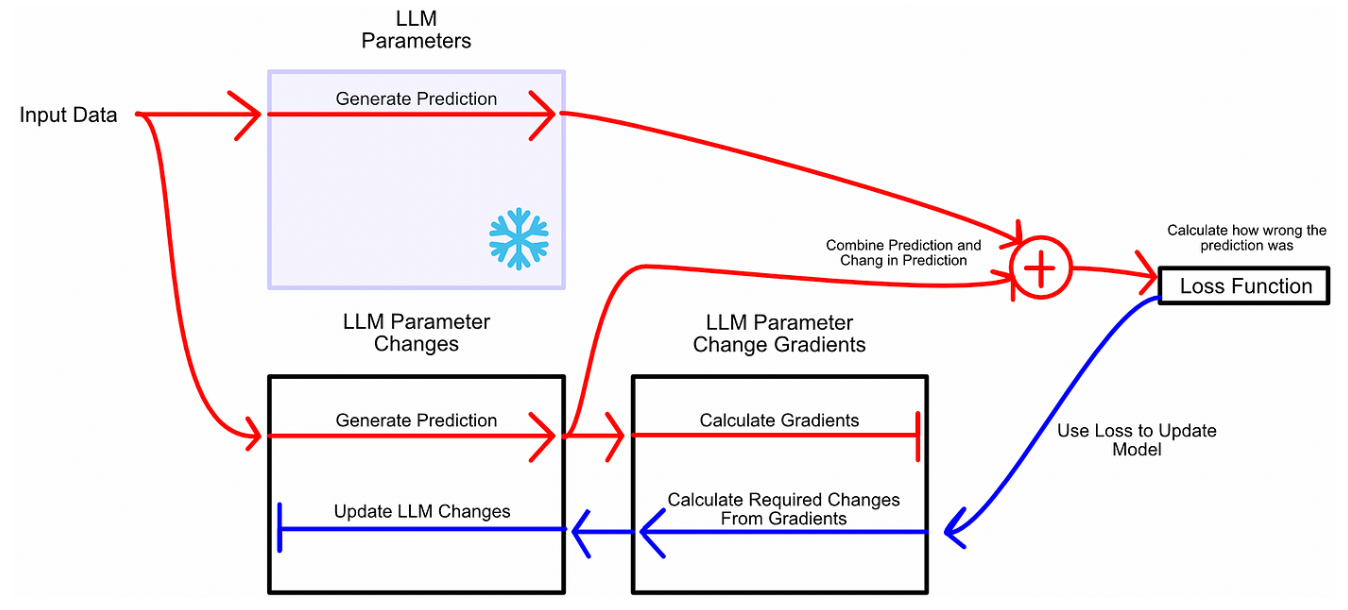
在微調的過程中可以不去微調W,去微調來捕捉
所需要進行的參數變化,那隨后二者相加就得到了微調后模型的參數。
那Lora體現的降低資源在哪?如如果形狀為[ 1000, 200 ]?的話,那如果我去微調原模型參數的話,那需要微調的參數有 1000 * 200 = 200,000。聰明的你可能想到了,那我去微調獲得參數的變化不也是一個[ 1000, 200 ]的矩陣,不然后面矩陣怎么相加。這就是Lora的巧妙之處,它將所需微調的
矩陣分解為低秩表示,你在這個過程不需要顯示計算
,只需要學習
的分解表示。比如
= [ 1000, 200 ]?可以被劃分為 [1000, 1] * [1, 200],那這樣的話所需要微調的參數就只有1000+200=1200,與200,000比的話,我們就可以明顯看出來Lora節省計算資源的秘密了。

補充:
- 那Lora為什么是低秩?首先我們要明確矩陣的秩的概念,矩陣秩在我們學線性代數中存在的概念,其定義為:矩陣中行(或列)向量線性無關的最大數量。換句話說,換句話說,矩陣的秩表示其可以提供多少個獨立的信息維度。如果秩越大,表示矩陣的行(列)越獨立,它們不能被其他另外的行(列)進行線性表示獲得;相反,如果秩越小,那么表示矩陣的行(列)獨立程度低,那么我可以根據其中所有獨立的行(列)來得到矩陣所有的行(列)。
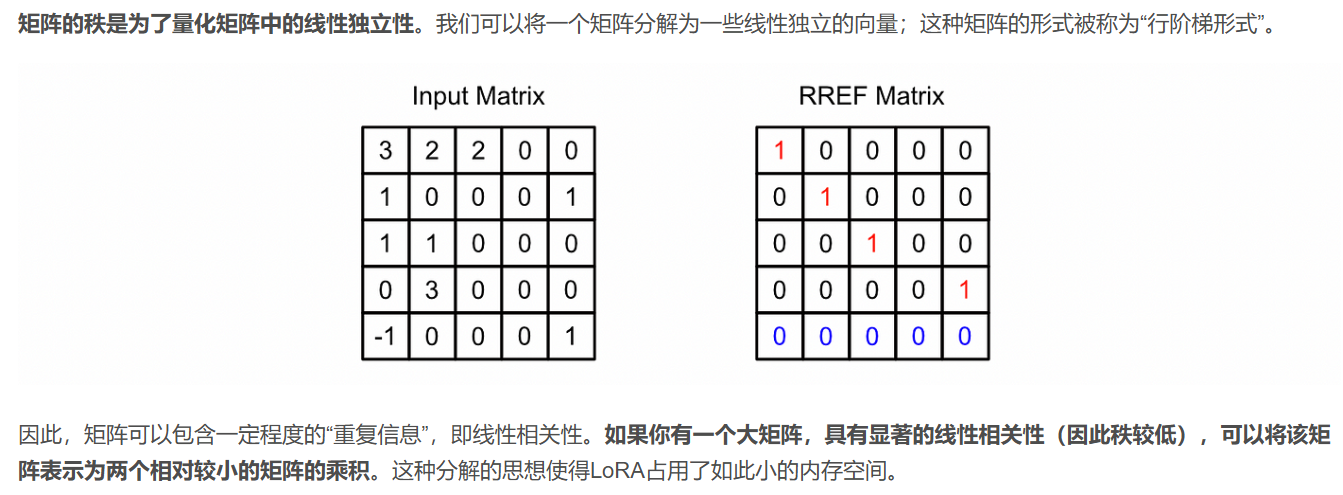
- 為什么要談到秩?就是因為你
Lora微調的過程
- 首先凍結模型參數。使用這些參數進行推理,但不會更新它們。然后創建兩個矩陣,當它們相乘時,它們的大小將與我們正在微調的模型的權重矩陣的大小相同。在一個大型模型中,有多個權重矩陣,為每個權重矩陣創建一個這樣的配對。
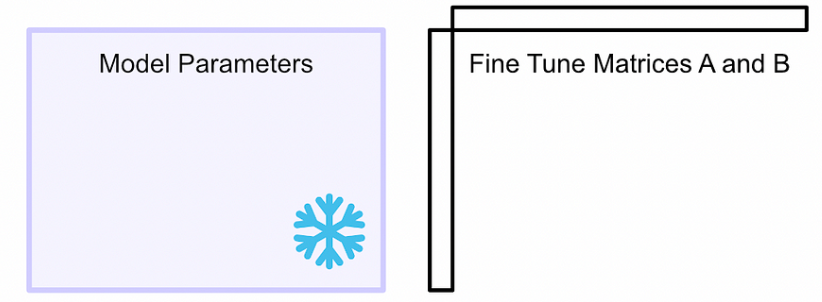
- LoRA將這些矩陣稱為矩陣“A”和“B”。這些矩陣一起代表了LoRA微調過程中的可學習參數。
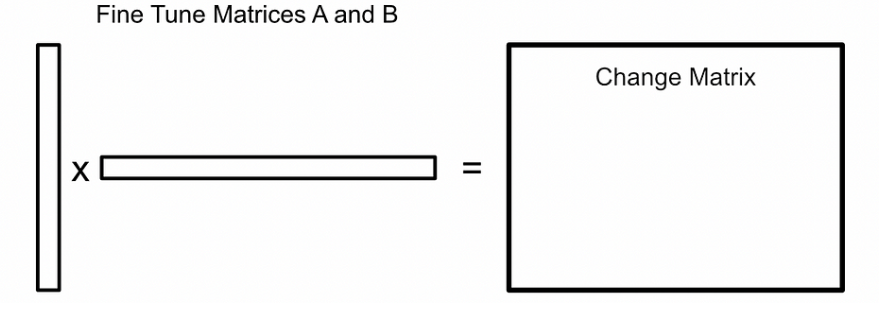
- 將輸入通過凍結的權重和變化矩陣傳遞。
- 根據兩個輸出的組合計算損失,然后根據損失更新矩陣A和B。
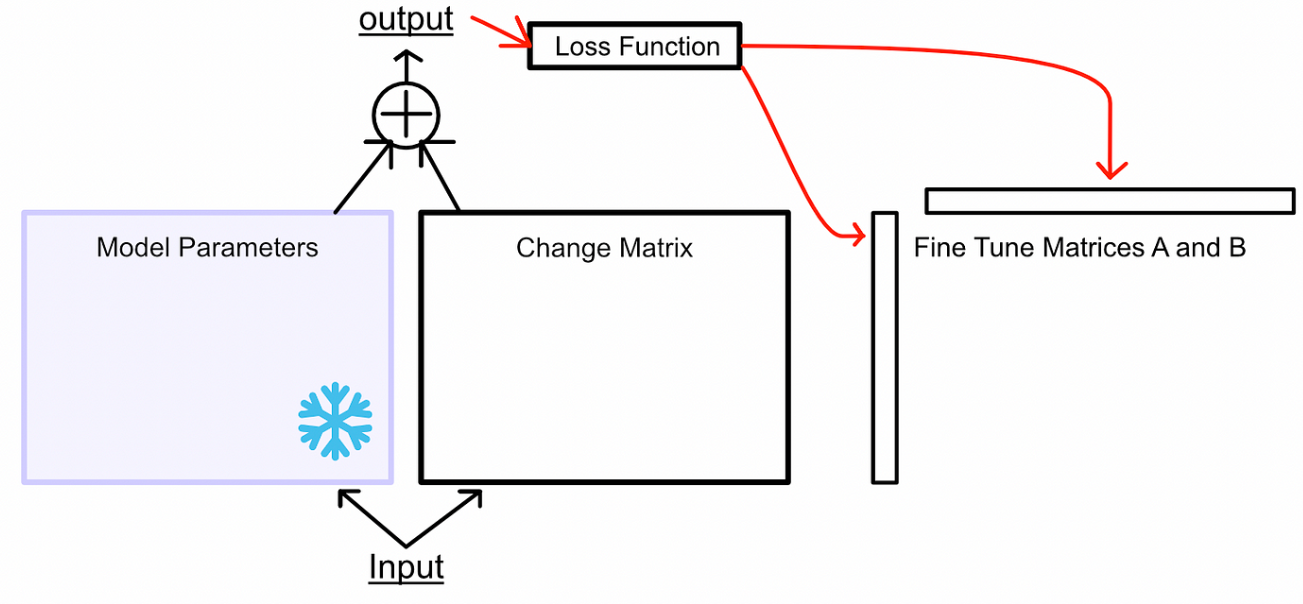
這些變化矩陣是即時計算的,從未被存儲,這就是為什么LoRA的內存占用如此小的原因。實際上,在訓練期間只存儲模型參數、矩陣A和B以及A和B的梯度。
。
當我們最終想要使用這個微調模型進行推斷時,我們只需計算變化矩陣,并將變化添加到權重中。這意味著LoRA不會改變模型的推斷時間

Lora在Transformer的應用
在大模型中(如BERT、GPT-3),全參數微調需要對模型的所有參數進行更新,代價非常高,尤其是當模型規模達到數十億甚至百億參數時。
例如
- 通常,在Transformer的多頭自注意力層中,密集網絡(用于構建Q、K和V)的深度只有1。也就是說,只有一個輸入層和一個由權重連接的輸出層。
-
這些淺層密集網絡是Transformer中大部分可學習參數,非常非常大。可能有超過100,000個輸入神經元連接到100,000個輸出神經元,這意味著描述其中一個網絡的單個權重矩陣可能有10B個參數。因此,盡管這些網絡的深度只有1,但它們非常寬,因此描述它們的權重矩陣非常大。
LoRA 認為:
神經網絡中某些層的權重矩陣(如自注意力中的
,
,
,
)在特定任務微調時,其更新矩陣是低秩的。
因此,LoRA不直接更新原始大權重矩陣 W,而是將權重的變化用一個低秩矩陣來表達,從而減少需要訓練的參數數量。
Lora Rank
LoRA有一個超參數,稱為Rank,它描述了用于構建之前討論的變化矩陣的深度。較高的值意味著更大的和矩陣,這意味著它們可以在變化矩陣中編碼更多的線性獨立信息。(聯想矩陣的秩)
“r"參數可以被視為"信息瓶頸”。較小的r值意味著A和B可以用更小的內存占用編碼較少的信息。較大的r值意味著A和B可以編碼更多的信息,但內存占用更大。(100張1塊錢,就能夠表達一張100塊錢,那你給我更多我錢我也愿意啊,能讓我住豪宅開跑車我也愿意啊(doge))。
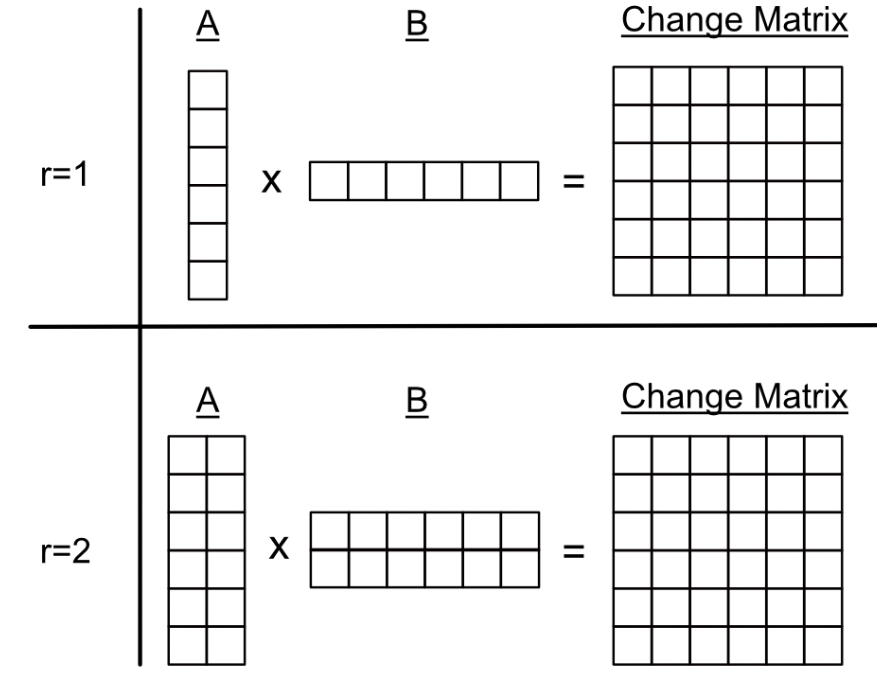
一個具有r值等于1和2的LoRA的概念圖。在這兩個例子中,分解的A和B矩陣導致相同大小的變化矩陣,但是r=2能夠將更多線性獨立的信息編碼到變化矩陣中,因為A和B矩陣中包含更多信息。
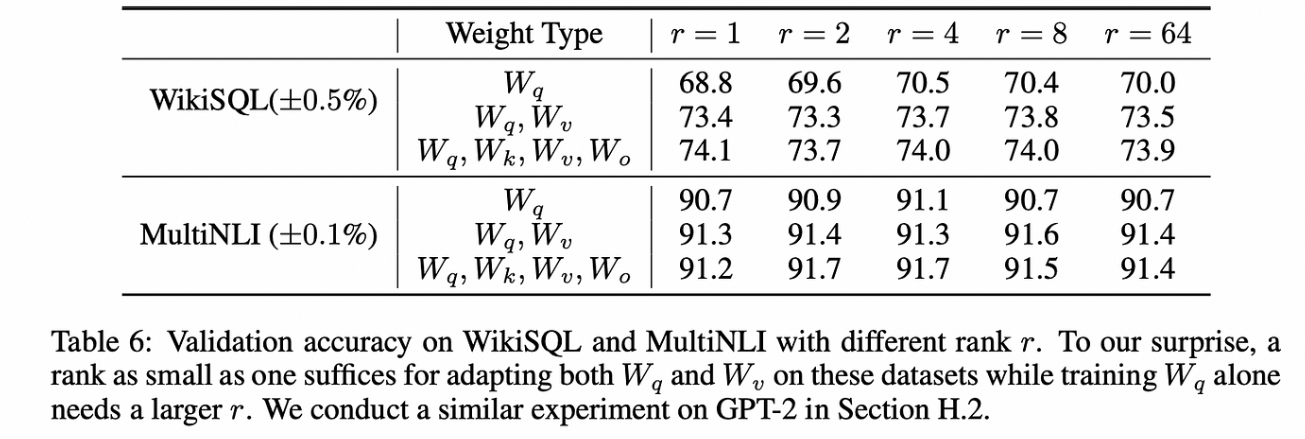
事實證明,LoRA論文所做的核心假設,即模型參數的變化具有低隱式秩(即你用較少獨立的行(列)來表示一個完整的矩陣是可行的),是一個相當強的假設。微軟(LoRA的出版商)的人員嘗試了一些值,并發現即使是秩為一的矩陣也表現出色。
LoRA論文中建議:當數據與預訓練中使用的數據相似時,較低的r值可能就足夠了。當在非常新的任務上進行微調時,可能需要對模型進行重大的邏輯更改,這時可能需要較高的r值。(遇到新的問題,需要更多信息來輔助判斷)
圖源:【大模型微調】LoRA — 其實大模型微調也沒那么難!_lora微調-CSDN博客
Prefix-Tuning
P-Tuning
Lora Tuning?是針對 encoding部分的微調,而在P-tuning中是針對embedding的微調。
什么是P-tuning?
P-Tuning,它是一種微調大語言模型(Large Language Model, LLM)的方法。與傳統的全參數微調(Fine-tuning)不同,P-Tuning 只在模型輸入層或中間層插入可學習的“Prompt Embeddings”(也稱 Prompt Tokens/Prefix 等),從而極大減少微調參數量。其核心思想可以歸納為:
- 凍結(freeze)大部分或全部原始模型參數?
- 引入少量可訓練的參數(Prompt Embeddings)?
- 通過梯度反向傳播僅更新這部分可訓練參數
即通過學習連續的、可訓練的“軟提示”(soft prompts)來引導預訓練模型完成下游任務,而不是像傳統微調那樣直接修改或微調模型的全部參數。模型在訓練過程中會將這些 Prompt Embeddings 拼接到原輸入或模型內部隱藏層的輸入里,從而讓預訓練模型更好地針對任務進行表征/生成。因為只訓練這部分 Prompt Embeddings,而模型的主體參數并未改變,所以對硬件資源和訓練數據需求更小,微調速度也更快。
兩階段對比,Prompt Tuning v.s. P Tuning
第一階段,Prompt Tuning
凍結主模型全部參數,在訓練數據前加入一小段Prompt,只訓練Prompt的表示層,即一個Embedding模塊。論文實驗表明,只要模型規模夠大,簡單加入 Prompt tokens 進行微調,就能取得很好的效果。
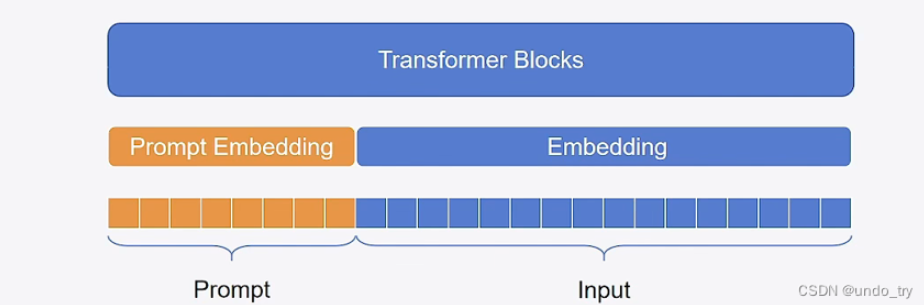
第二階段,在Prompt Tuning的基礎上,對 Prompt部分 進行進一步的encoding計算,加速收斂。具體來說,PEFT中支持兩種編碼方式,一種是LSTM,一種是MLP。與Prompt-Tuning不同的是,Prompt的形式只有Soft Prompt。
硬提示(Hard Prompt):離散的、人工可讀的;?軟提示(Soft Prompt):連續的、可訓練的。
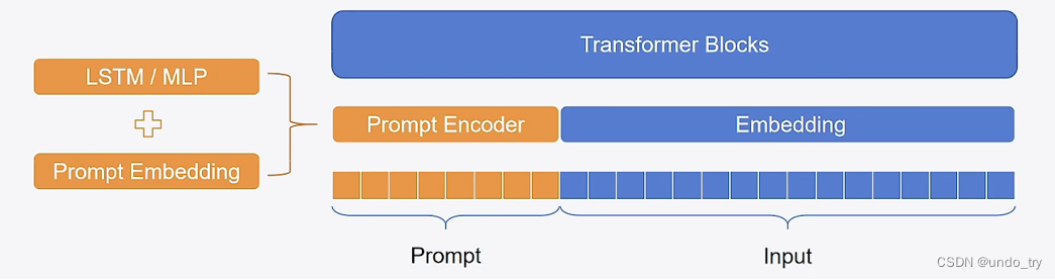
總結:P Tuning將Prompt轉換為可以學習的Embedding層,并用MLP+LSTM的方式來對Prompt Embedding進行一層處理。?
- 相比Prefix Tuning,P Tuning僅限于輸入層,沒有在每一層都加virtual token ?
- 經過預訓練的LM的詞嵌入已經變得高度離散,如果隨機初始化virtual token,容易優化到局部最優值,而這些virtual token理論是應該有相關關聯的。因此,作者通過實驗發現用一個prompt encoder來編碼會收斂更快,效果更好。即用一個LSTM+MLP去編碼這些virtual token以后,再輸入到模型。?
- 作者在實驗中發現,相同參數規模,如果進行全參數微調,Bert的在NLU(自然語言理解)任務上的效果,超過GPT很多;但是在P-Tuning下,GPT可以取得超越Bert的效果。
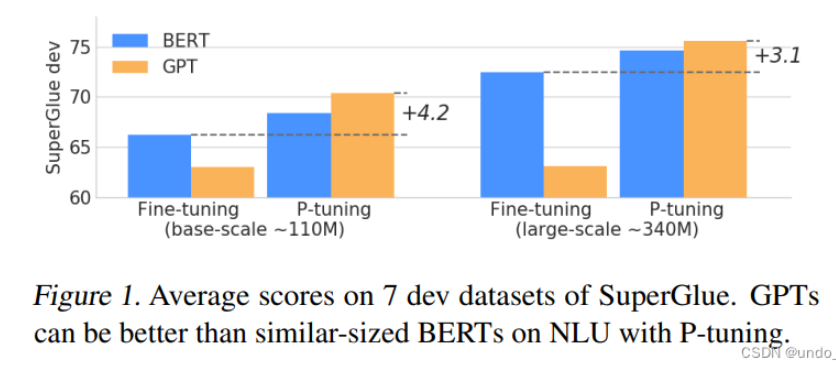
圖源:參數高效微調PEFT(二)快速入門P-Tuning、P-Tuning V2-CSDN博客
P-tuning?v.s. Prompt Engineering?
Prompt Engineering?是人工提示工程,屬于離散提示。它的做法是通過精心設計的自然語言提示(例如“請完成這個句子:...”)可以誘導模型完成任務,而無需微調。但這需要手動設計和篩選提示,效率低下且效果不穩定。
而P-tuning 則在這兩者之間找到了一個平衡點。它的核心思想是:
- 不再使用離散的、人工設計的自然語言提示。
- 引入一小段可訓練的連續向量(soft prompt)作為模型輸入的前綴或嵌入,而不是直接修改模型的內部參數。
- 在訓練過程中,只優化這部分軟提示的參數,而凍結預訓練模型的絕大部分參數。
P-tuning與Prompt Engineering的區別,關鍵就在你提示的語言是什么類型的,Prompt Engineering所使用的提示語言是人類語言,而P-tuning所使用的提示語言是我們給預訓練模型“悄悄地”加上的一段“指令”,這段指令不是用人類語言寫成的,而是模型自己“學出來”的最有效的連續向量,能夠最大化地引導模型在特定任務上給出正確的輸出。
一張圖總結各種Tuning
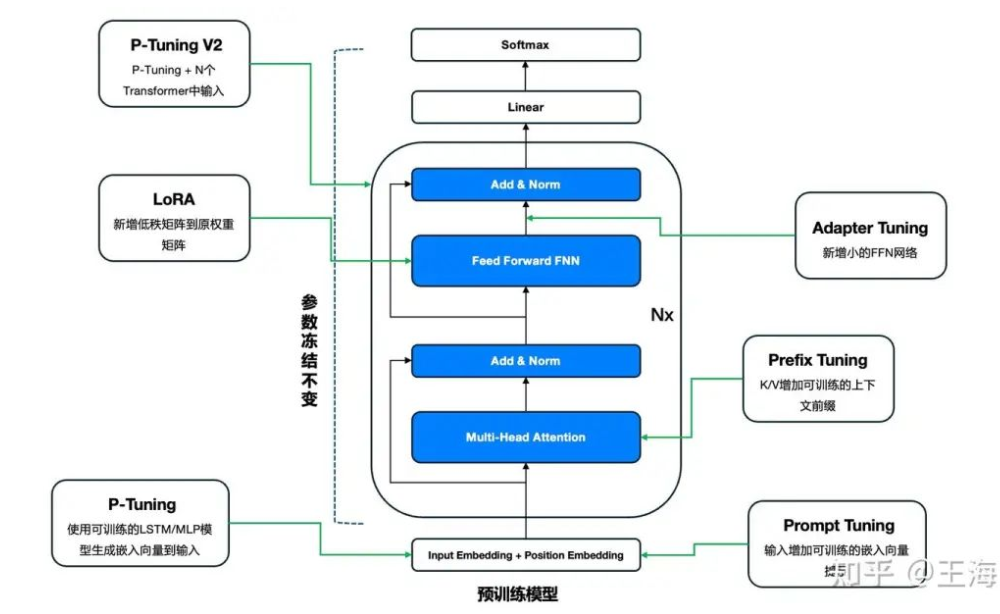



)



)











