一、考點分值占比與趨勢分析
綜合知識題分值統計表
| 年份 | 考題數量 | 總分值 | 分值占比 | 考察重點 |
|---|---|---|---|---|
| 2018 | 2 | 2 | 2.67% | 時間復雜度/穩定性判斷 |
| 2019 | 3 | 3 | 4.00% | 算法特性對比分析 |
| 2020 | 2 | 2 | 2.67% | 空間復雜度要求 |
| 2021 | 1 | 1 | 1.33% | 算法穩定性判斷 |
| 2022 | 3 | 3 | 4.00% | 綜合特性應用 |
| 2023 | 2 | 2 | 2.67% | 時間復雜度計算 |
| 2024 | 2 | 2 | 2.67% | 分治策略應用 |
案例題分值統計表
| 年份 | 考題數量 | 總分值 | 分值占比 | 考察形式 | 考察重點 |
|---|---|---|---|---|---|
| 2018 | 0 | 0 | 0% | - | - |
| 2019 | 1 | 5 | 6.67% | 算法填空 | 歸并排序實現 |
| 2020 | 1 | 5 | 6.67% | 流程圖補全 | 快速排序過程 |
| 2021 | 0 | 0 | 0% | - | - |
| 2022 | 1 | 5 | 6.67% | 偽代碼分析 | 堆排序原理 |
| 2023 | 1 | 5 | 6.67% | 復雜度計算 | 算法對比 |
| 2024 | 1 | 5 | 6.67% | 場景應用 | 穩定排序選擇 |
趨勢分析:排序算法在綜合知識題中保持年均2-4%的穩定分值,重點考察時間復雜度、穩定性與空間復雜度的組合判斷。案例題自2019年起呈現5年4考的規律,重點考核歸并排序、堆排序的具體實現和分治策略應用,2024年新增場景應用題,強調算法選擇能力。
二、真題考點深入挖掘
-
時間復雜度維度:
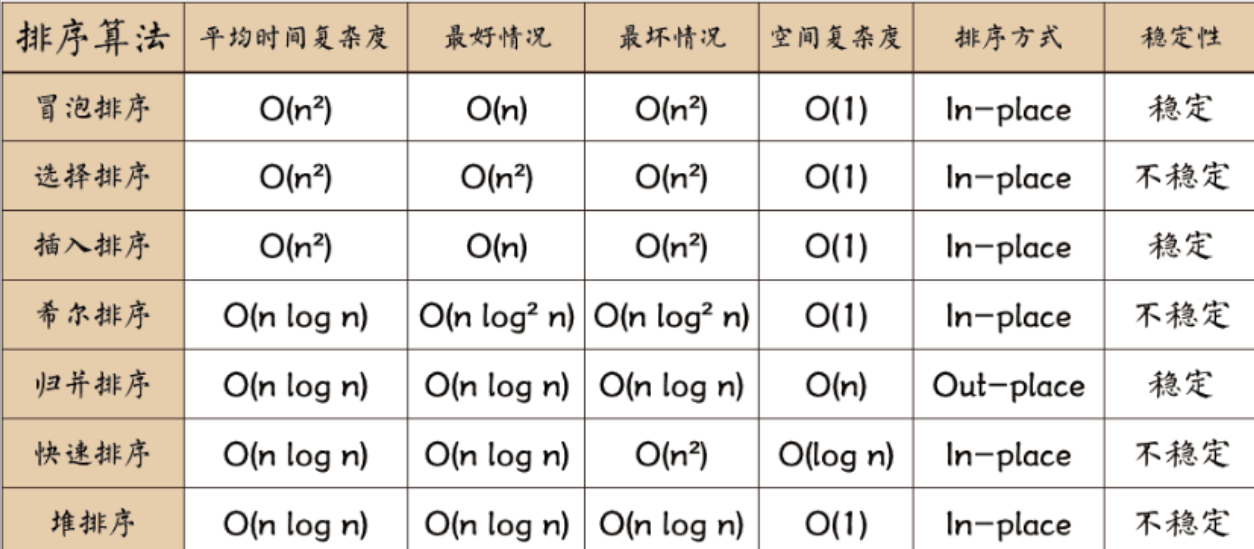
- 高頻考查O(nlogn)級算法:堆排序(2018/2022)、歸并排序(2019/2024)、快速排序(2020)的對比
- 特殊場景復雜度:冒泡排序最優情況O(n)(2021)、歸并排序空間復雜度O(n)(2019)
-
穩定性維度:
- 必考穩定排序判定:歸并排序(2018/2023)、冒泡排序(2021)的穩定性特征
- 不穩定算法陷阱:堆排序(2018/2022)、快速排序(2020)的不穩定特性
-
空間復雜度維度:
- 原地排序要求:堆排序O(1)(2018/2022)與快速排序遞歸棧空間(2020)對比
- 歸并排序空間消耗:案例題多次要求分析其O(n)特性(2019/2023)
-
算法策略維度:
- 分治法應用:歸并排序(2019)與快速排序(2020)的分治差異
- 堆結構應用:2022年案例題要求分析堆排序的二叉樹結構特征
典型命題規律:組合型題目占比達60%,如"O(nlogn)+穩定"選歸并排序(2018/2023),"O(nlogn)+原地"選堆排序(2018/2022)。
三、"wwwh"簡述
是什么:排序算法是將數據元素按特定順序排列的計算方法,核心指標包括時間復雜度、空間復雜度、穩定性。
為什么:
- 時間復雜度決定算法效率(如O(n2)級算法不適用大數據量)
- 空間復雜度影響內存消耗(如歸并排序需要額外存儲空間)
- 穩定性保障數據業務邏輯(如電商訂單按時間+金額雙排序)
怎么樣:
- 比較類排序:通過元素比較確定次序(冒泡/快速/堆排序)
- 非比較類排序:通過數值特征確定次序(桶/基數排序,但不在當前考點范圍)
如何做:
- 判斷數據規模:小數據(n≤50)可用插入排序
- 分析穩定性需求:需要穩定則排除堆/快速排序
- 評估空間限制:內存緊張時選擇原地排序(堆/快速)
- 綜合決策:典型場景如"大數據+穩定"用歸并排序,"大數據+內存受限"用堆排序
四、真題演練與解析
題目62(第1空)
題干:要求時間復雜度O(nlogn)且穩定,應選( )
選項:A.插入排序 B.堆排序 C.快速排序 D.歸并排序
解析:
- 排除法:插入排序O(n2)不滿足時間要求
- 堆排序和快速排序均為不穩定算法
- 歸并排序同時滿足O(nlogn)和穩定
答案:D
題目29
題干:穩定的排序算法是( )
選項:A.冒泡 B.快速 C.堆 D.簡單選擇
解析:
- 快速排序在劃分時可能改變相等元素順序
- 堆排序在調整堆結構時破壞穩定性
- 簡單選擇排序跨位置交換導致不穩定
答案:A
題目63(第2空)
題干:時間復雜度O(nlogn)且空間復雜度O(1)應選( )
解析:
- 歸并排序空間復雜度O(n)不符合
- 快速排序遞歸棧空間平均O(logn)
- 堆排序是唯一滿足O(1)空間的O(nlogn)算法
答案:B
五、極簡備考筆記
| 算法 | 時間復雜度 | 空間復雜度 | 穩定性 | 核心特征 |
|---|---|---|---|---|
| 冒泡排序 | O(n2)/O(n)最優 | O(1) | 穩定 | 相鄰元素交換 |
| 快速排序 | O(nlogn)平均 | O(logn) | 不穩定 | 分治+基準元素 |
| 堆排序 | O(nlogn) | O(1) | 不穩定 | 完全二叉樹結構 |
| 歸并排序 | O(nlogn) | O(n) | 穩定 | 分治+額外存儲空間 |
| 插入排序 | O(n2)/O(n)最優 | O(1) | 穩定 | 適合小規模數據 |
速記要點:
- 穩快空:穩定選歸并,快速要空間,堆排省內存
- 時間三強:堆/快/歸都是O(nlogn)
- 特殊場景:完全有序時冒泡排序最優
六、考點記憶順口溜
堆快歸并,時間優(時間復雜度最優)
空間堆快,原地走(堆排序和快速排序是原地排序)
穩定歸并,冒泡有(穩定算法代表)
選擇插入,分情況(根據數據規模選擇)
分治策略,歸并牛(歸并排序采用分治法)
二叉樹形,堆結構(堆排序的樹形特征)
基準元素,快速排(快速排序的核心)
相鄰交換,冒泡來(冒泡排序原理)
七、多角度解答
-
知識體系角度:
排序算法屬于數據結構核心模塊,與樹結構(堆排序)、遞歸思想(快速排序)、分治策略(歸并排序)緊密關聯。掌握排序算法有助于理解更復雜的算法設計范式。 -
命題意圖角度:
真題多設計組合條件(如"O(nlogn)+穩定")來考察考生對算法特性的綜合理解能力,重點檢測知識體系的完整性和應用能力。 -
解題技巧角度:
采用"條件拆解法":先處理時間復雜度→再篩選空間復雜度→最后驗證穩定性。遇到案例題時,先識別算法特征(如出現merge()函數即為歸并排序)。 -
錯誤防范角度:
高頻易錯點包括:
- 混淆快速排序最好/平均時間復雜度(都是O(nlogn))
- 忽視遞歸調用棧對空間復雜度的影響
- 誤判插入排序的穩定性(實際是穩定算法)





)







創建窗口)




)
