?目錄
引言:打破大語言模型的記憶瓶頸,迎接AI交互新范式
一、Supermemory 核心技術
1.1 透明代理機制
1.2? 智能分段與檢索系統
1.3 自動Token管理
二、易用性
三、性能與成本
四、可靠性與兼容性
五、為何選擇 Supermemory?
六、對比分析:同類方案中的優勢
七、Supermemory 的應用場景
7.1 與任意內容對話 (Chat with)
7.2 個性化 AI 助手 (Personalized AI Assistants)
7.3 智能客服與支持 (Intelligent Customer Service & Support)
7.4 內容創作與分析 (Content Creation & Analysis)
7.5 軟件開發輔助 (Software Development Assistance)
八、內容處理與狀態追蹤
九、高級功能與開發者資源
9.1 高級功能
9.2 開發者資源
十、結論:開啟無限記憶AI的新紀元

🎬 攻城獅7號:個人主頁
🔥 個人專欄:《AI前沿技術要聞》
?? 君子慎獨!
?🌈 大家好,歡迎來訪我的博客!
?? 此篇文章主要介紹 Supermemory
📚 本期文章收錄在《AI前沿技術要聞》,大家有興趣可以自行查看!
?? 歡迎各位 ?? 點贊 👍 收藏 ?留言 📝!

引言:打破大語言模型的記憶瓶頸,迎接AI交互新范式
????????在人工智能飛速發展的今天,大型語言模型(LLM),諸如我們耳熟能詳的ChatGPT、Claude等,已深度融入工作與生活的各個層面,其卓越的對話與創作能力令人矚目。然而,這些尖端LLM亦面臨著一個共同的技術瓶頸——上下文窗口限制。無論是8k、32k,抑或是更為先進的128k tokens,這一窗口大小嚴格定義了模型單次交互中能夠"記憶"和處理的信息總量。一旦對話內容或所處理的文檔超越此閾值,模型便如同患上"健忘癥",先前的信息流會被無情截斷或遺忘,進而導致對話連貫性銳減,深度分析能力受限,最終嚴重影響用戶體驗。
????????試想,當您正與AI助手就某一復雜項目進行深度探討,或要求其依據一份冗長報告進行精準的總結分析時,卻愕然發現它已將先前的關鍵論點拋諸腦后,這種體驗無疑是令人沮喪且低效的。此類"失憶"現象不僅極大地制約了LLM在復雜任務場景下的應用潛力,也為致力于構建需長程記憶與深度理解能力的AI應用的開發者們設置了巨大的技術壁壘。
????????正是在這樣的時代背景與技術訴求下,Supermemory應運而生。該公司推出了一項名為Infinite Chat API的顛覆性技術,其核心目標直指徹底攻克LLM的上下文窗口限制難題,賦予AI應用真正意義上的"無限記憶"能力。Supermemory的愿景是使開發者無需對現有應用邏輯進行傷筋動骨的重寫,便能輕而易舉地為其AI應用集成一層持久化、可靈活擴展的記憶系統,從而為交互式AI應用的未來開啟全新的可能性與想象空間。本文將深入剖析Supermemory的核心技術棧、獨特的產品特性、廣泛的應用場景、顯著的技術優勢,并闡述其如何為AI開發者及最終用戶創造實實在在的價值,揭示其如何一步步致力于成為AI時代不可或缺的記憶基礎設施。
體驗地址:https://supermemory.chat/
官網地址:supermemory?
?注冊登錄后界面:
一、Supermemory 核心技術
??????? 它是智能代理與記憶系統的精妙融合,Supermemory所宣稱的"無限記憶"能力并非空中樓閣,其堅實基礎在于一套精心設計、高度協同的智能代理架構與極致高效的記憶系統。該架構通過以下三個關鍵環節的緊密配合,實現了對LLM上下文的智能化管理與動態擴展:
1.1 透明代理機制
????????Supermemory的首要核心優勢在于其匠心獨運的"透明代理"機制。開發者在集成過程中,無需對其現有的AI應用代碼進行大規模、高風險的修改,僅需一個簡單步驟——將原先指向OpenAI或其他LLM服務商API的請求URL,巧妙地更改為Supermemory提供的專屬API端點地址。
????????完成這一輕量級替換后,所有發往LLM的API請求都將首先流經Supermemory的智能中間層。Supermemory會運用其內置邏輯智能地處理這些請求,在必要時主動與自身強大、持久的記憶系統進行交互(例如,檢索相關歷史上下文、存儲新的對話信息),然后才將經過潛在優化與上下文動態注入的請求轉發給開發者預先選定的底層LLM(如GPT-4、Claude 3等各類先進模型)。
????????這種優雅的設計帶來了諸多顯而易見的好處:
(1)極低的集成成本:開發者幾乎無需觸動原有的核心代碼邏輯,學習曲線極為平緩,使得快速上手與部署成為可能。
(2)即時獲得增強功能:一旦切換完成,AI應用便能即刻開始利用Supermemory提供的持久記憶能力,無需經歷漫長而復雜的二次開發周期。
(3)廣泛的兼容性:得益于其代理特性,Supermemory能夠與任何兼容OpenAI API格式的主流模型及服務實現無縫協作,保障了技術選型的靈活性。
????????正如Supermemory在其宣傳中所強調的:"簡單到令人發指:一行代碼,立即生效!"這充分體現了其對開發者體驗的極致追求,無縫集成,即刻生效。
1.2? 智能分段與檢索系統
????????當用戶與AI的對話長度或待處理的文檔內容,不幸超出所選用LLM原生的上下文窗口限制時(例如,一個包含超過20k tokens的對話歷史或文檔),Supermemory的智能分段與檢索系統便會挺身而出,擔當起關鍵角色,實現高效精準的上下文管理。
????????該系統內部署了先進的自然語言處理算法,能夠將冗長的對話歷史或大型文檔內容,自動且智能地分割成一系列既保持較小規模、又最大限度保留原始語義連貫性的"內容塊"(chunks)。這些精心處理過的內容塊隨后會被高效地存儲在Supermemory的專用記憶庫中,并為之建立精密的索引結構,以便于后續的快速、精準檢索。
????????當后續的對話交互發生,或者AI需要基于過往信息生成響應時,Supermemory并不會草率地將所有歷史記錄一股腦地塞給LLM。恰恰相反,其高度智能的檢索系統會首先細致分析當前對話的意圖、主題以及上下文關聯,然后從龐大的記憶庫中,以極高的精度提取出與當前任務**最為相關**的歷史信息片段。這些經過嚴格篩選、高度相關的上下文片段,將被巧妙地重新注入到發送給目標LLM的請求之中,作為其生成響應的"記憶"支撐。
????????這種智能分段與檢索機制所帶來的優勢是多方面的:
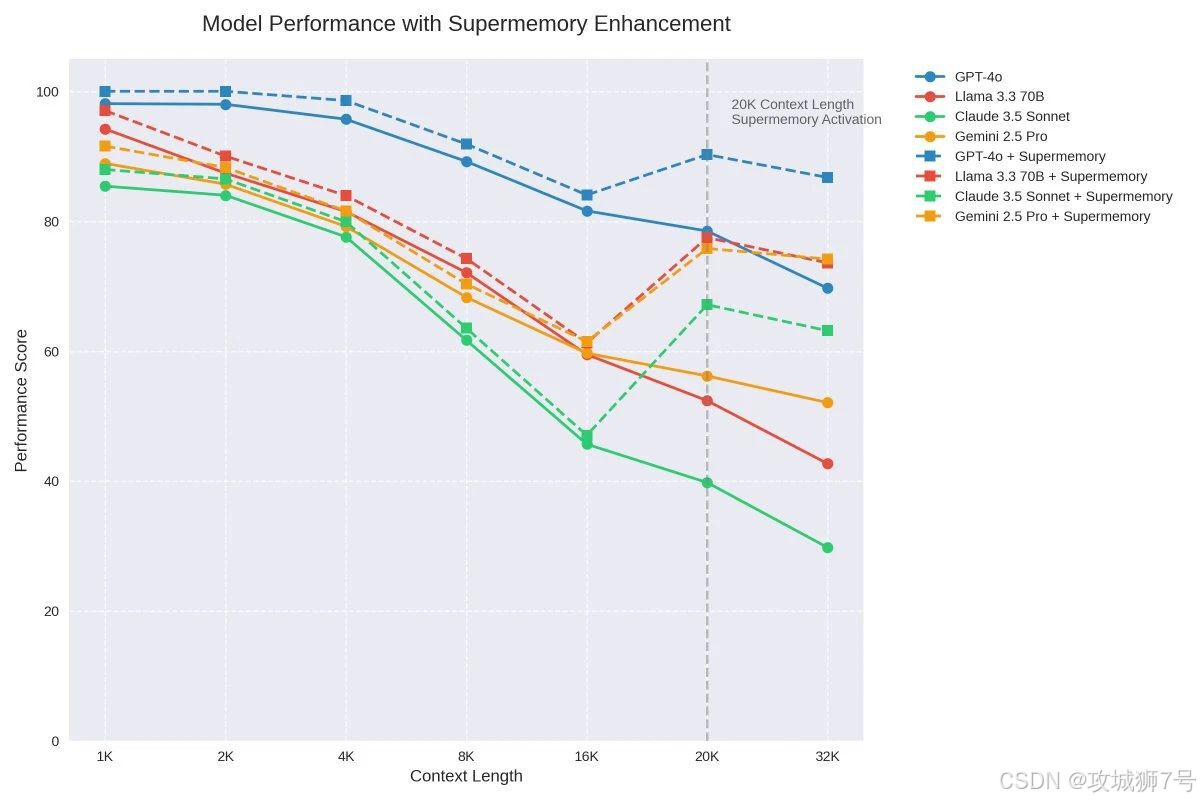
(1)突破Token限制:從根本上解決了LLM固有的上下文窗口大小問題,使得AI應用在理論上能夠處理并"記住"無限長度的對話歷史或文檔內容。
(2)提高處理效率:通過僅向LLM提供最相關、最精華的信息,有效避免了不必要的Token消耗和冗余計算開銷,從而顯著加快了模型的響應速度。
(3)降低運行成本:經由精簡發送給LLM的Token數量,能夠大幅度減少調用LLM API所需支付的費用。Supermemory官方聲稱,此項優化甚至可以為用戶節省高達70%乃至90%的Token使用量。
(4)提升響應質量:確保LLM在生成響應時,能夠充分利用最關鍵、最相關的背景信息,從而顯著提高回答的準確性、相關性以及整體對話的連貫性。
1.3 自動Token管理
????????除了強大的智能分段和精準檢索能力外,Supermemory還具備先進的自動Token管理功能。該系統會根據實際的交互需求以及所選用的上游LLM的具體Token限制(如最大輸入長度),智能地、動態地控制最終注入到請求中的Token數量,實現性能與成本的雙重優化保障。
????????這意味著Supermemory能夠主動進行以下優化:
(1)避免性能瓶頸:有效防止因一次性向上游LLM推送過多、過長的上下文信息,而可能導致的響應延遲顯著增加,甚至處理失敗等問題。
(2)防止成本失控:通過動態調整注入上下文的長度與密度,確保Token使用量始終維持在一個合理且經濟的范圍內,幫助用戶有效控制AI應用的運營成本。
(3)減少請求失敗風險:嚴格確保最終發送給LLM的請求符合其最大Token輸入限制,從而顯著降低因超出限制而導致的API調用錯誤或服務中斷的風險。
????????通過上述三大核心技術的緊密協同與高效運作,Supermemory為AI應用構建了一個既強大又高效的外部記憶層。這使得AI應用不僅能夠"記住"遠超其原生模型能力的上下文信息,還能靈活利用這些信息進行更深度、更連貫的交互,同時保持了卓越的運行性能和令人滿意的成本效益。
二、易用性
????????Supermemory 集成極為簡便,三步集成,零學習成本:
(1)獲取 API Key:官網注冊獲取。
(2)更換請求 URL:將原有LLM API基礎URL替換為Supermemory端點。
(3)添加認證信息:請求頭中加入API Key。
????????完成后,應用即可利用Supermemory,無需復雜改造,對開發者極為友好。
簡易用法一:
curl https://api.supermemory.ai/v3/search \
? --request GET \
? --header 'Content-Type: application/json' \
? --header 'Authorization: Bearer YOUR_SECRET_TOKEN' \
? -d '{"q": "This is the content of my first memory."}'
簡易用法二(python sdk代碼):
import os
from supermemory import Supermemoryclient = Supermemory(api_key=os.environ.get("SUPERMEMORY_API_KEY"), # This is the default and can be omitted
)client.memory.create(content="This is the content of my first memory.",
)response = client.search.execute(q="documents related to python",
)
print(response.results)
注意:更多用法請參考官方文檔
三、性能與成本
(1)性能優勢:實現真正無限上下文;顯著降低Token用量;幾乎不增加延遲;通過更完整上下文提升響應質量。
(2)成本效益:提供10萬tokens免費存儲;超出后固定月費20美元;每個對話線程含2萬免費tokens,超出部分每百萬tokens收費1美元。此混合模式兼具成本可預測性與擴展性。
????????總之一句話,體現了實用主義。
四、可靠性與兼容性
企業級的保障:
(1)錯誤處理:若Supermemory處理管道出問題,請求會自動回退直連原始LLM,保證服務不中斷。API響應包含診斷標頭(如`x-supermemory-conversation-id`, `x-supermemory-context-modified`),錯誤時提供`x-supermemory-error`標頭。
(1)廣泛兼容性:支持任何兼容OpenAI API格式的模型和服務,如OpenAI、Google Gemini、Anthropic Claude及Groq Cloud上的模型,賦予開發者選擇靈活性。
五、為何選擇 Supermemory?
????????自建記憶層(RAG)挑戰重重:向量數據庫選型與維護、嵌入模型選擇與優化、記憶層邏輯構建(處理多格式內容、數據清洗、分塊、檢索算法、上下文管理等)耗時費力。Supermemory提供端到端解決方案:
(1)經濟易用:免費起步,API簡潔,部署快速。
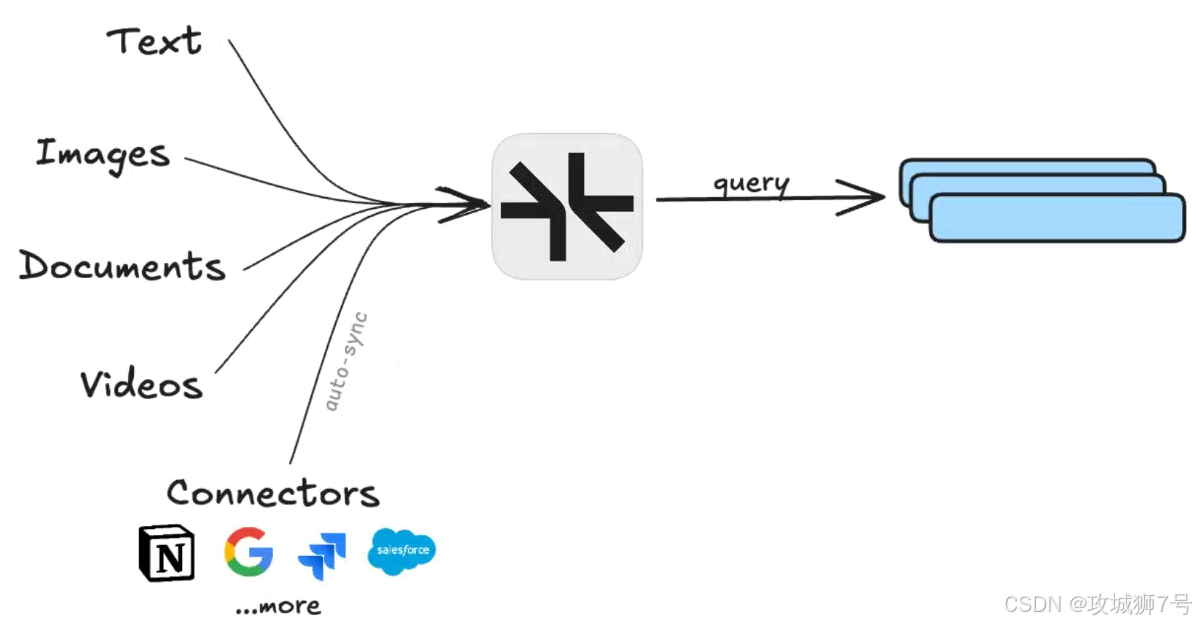
(2)便捷連接器:內置對Notion、Google Drive等支持,強大的網頁及PDF處理,提供SDK接入私有數據源。
(3)生產就緒:企業級安全,亞秒級低延遲,高可用(99.9%正常運行時間)。
????????專注核心業務,選擇Supermemory,開發者可專注于產品創新而非底層技術。
六、對比分析:同類方案中的優勢
(1)vs Cloudflare AutoRAG:Supermemory數據歸屬用戶,連接器更多,元數據過濾更高級,查詢優化更強,性能與擴展性更優。AutoRAG功能基礎,鎖定Cloudflare生態。
(2)vs Turbopuffer:Turbopuffer是高性能向量數據庫,用戶需自行處理RAG流程。Supermemory是完整記憶解決方案,集成內容提取、分塊、嵌入、高級檢索等。
????????Supermemory憑借完整RAG、高級搜索、可擴展性、易集成、可定制和生產就緒特性,在功能、靈活性和易用性間取得平衡。
七、Supermemory 的應用場景
????????Supermemory憑借其"無限記憶"能力,可廣泛賦能各類AI應用,釋放無限潛能:
7.1 與任意內容對話 (Chat with)
(1)與個人數據對話:如Twitter書簽、Pocket收藏、RSS訂閱、個人筆記等,將分散的信息孤島整合為個性化知識庫,AI可助你回顧、總結、發現新洞見。
(2)與專業文檔對話:上傳研究報告、法律文件、技術手冊、電子書等,AI能快速定位信息、回答問題、提煉摘要,成為強大的閱讀和研究助手。
(3)與企業知識庫對話:整合公司內部Wiki、共享文檔、項目管理工具(如Notion、Slack、Google Drive)、歷史郵件、客服記錄等,打造智能內部顧問或AI知識管理系統,提升信息檢索效率和決策質量。新員工培訓、政策查詢、項目復盤等場景均可受益。
(4)與網頁內容對話:直接輸入URL,Supermemory即可抓取網頁內容并允許你進行對話式查詢,無論是新聞文章、博客帖子還是產品頁面。
7.2 個性化 AI 助手 (Personalized AI Assistants)
(1)學習與研究助理:長期跟蹤用戶的學習進度、閱讀材料、筆記和疑問,提供定制化的學習建議和知識梳理。
(2)健康與生活教練:記錄用戶的健康數據、飲食習慣、運動情況,提供個性化的健康指導和生活建議。
(3)項目管理與協作:記住項目的歷史討論、決策過程、任務分配,幫助團隊成員快速了解背景,保持信息同步。
7.3 智能客服與支持 (Intelligent Customer Service & Support)
(1)全天候客服機器人:基于完整的歷史交互數據和產品知識庫,提供更精準、更個性化的客戶支持,理解復雜問題,減少重復提問。
(2)客服坐席輔助:實時為人工客服提供相關的歷史信息和解決方案建議,提升服務效率和客戶滿意度。
7.4 內容創作與分析 (Content Creation & Analysis)
(1)長篇內容生成:基于大量背景資料和用戶指定的主題、風格,輔助創作報告、文章、甚至劇本。
(2)深度文本分析:對海量文本數據(如用戶評論、市場報告)進行深度理解和模式挖掘,提供有價值的商業洞察。
7.5 軟件開發輔助 (Software Development Assistance)
(1)代碼庫問答:讓開發者能夠與整個代碼倉庫進行對話,理解模塊功能、查找代碼示例、輔助調試。
(2)API文檔助手:快速學習和查詢復雜API的用法。
????????Supermemory通過提供持久記憶層,極大地擴展了AI應用的邊界,使其能夠勝任更復雜、更依賴歷史信息的任務,從而在各個行業和領域創造新的價值。
八、內容處理與狀態追蹤
(1)支持類型:文本筆記(note)、PDF(pdf)、網頁(webpage)、Google文檔(google_doc)、圖像(image)、視頻(video)、Notion頁面(notion_doc)、推文(tweet)。
(2)處理流程:內容提取 -> AI增強(摘要、標簽、分類)-> 智能分塊(句子級別,保留重疊)-> 嵌入 -> 索引。
(3)處理狀態:queued -> extracting -> chunking -> embedding -> indexing -> done / failed。監控狀態有助于管理數據接入。
九、高級功能與開發者資源
9.1 高級功能
(1)重排序(Reranking):通過`rerank=true`參數啟用,使用`bge-reranker-base`模型提升搜索結果質量,不額外收費但略增延遲。
(2)多模態支持與文檔清理摘要:未來功能,文檔暫未提供。
(3)自動檢測內容類型:簡化內容提交,系統自動判斷。
9.2 開發者資源
(1)SDKs:提供Typescript和Python SDK簡化集成。
(2)產品更新:持續迭代,如2025-04-30更新增強了文檔、開發者平臺、可靠性、分類支持等。
十、結論:開啟無限記憶AI的新紀元
????????Supermemory 以其創新的透明代理、智能分段與檢索技術,成功突破了大型語言模型長期存在的上下文窗口限制。它不僅僅是一個技術上的改進,更是對 AI 交互方式的一次深刻革新。通過極簡的集成方式,Supermemory 使得開發者能夠輕松地為現有和未來的 AI 應用賦予"無限記憶",大幅降低了構建長程記憶應用的門檻和成本。
????????無論是需要處理海量文檔的知識問答、需要保持長期對話連貫性的個性化助手,還是希望從歷史數據中學習和進化的智能體,Supermemory 都提供了一個強大、可靠且經濟高效的解決方案。它在性能優化、成本控制、易用性和兼容性方面的出色表現,使其成為開發者構建下一代智能應用的理想選擇。
????????更重要的是,Supermemory 積極擁抱開源,其核心項目已在 GitHub 上開放源代碼 (https://github.com/supermemoryai/supermemory)。這不僅體現了團隊的技術自信和開放合作的精神,也為開發者提供了更大的靈活性和控制權,可以根據自身需求進行定制和擴展,并參與到項目的共同建設中。這種開放的姿態無疑將加速 Supermemory 技術的普及和生態的繁榮。開源項目技術棧:
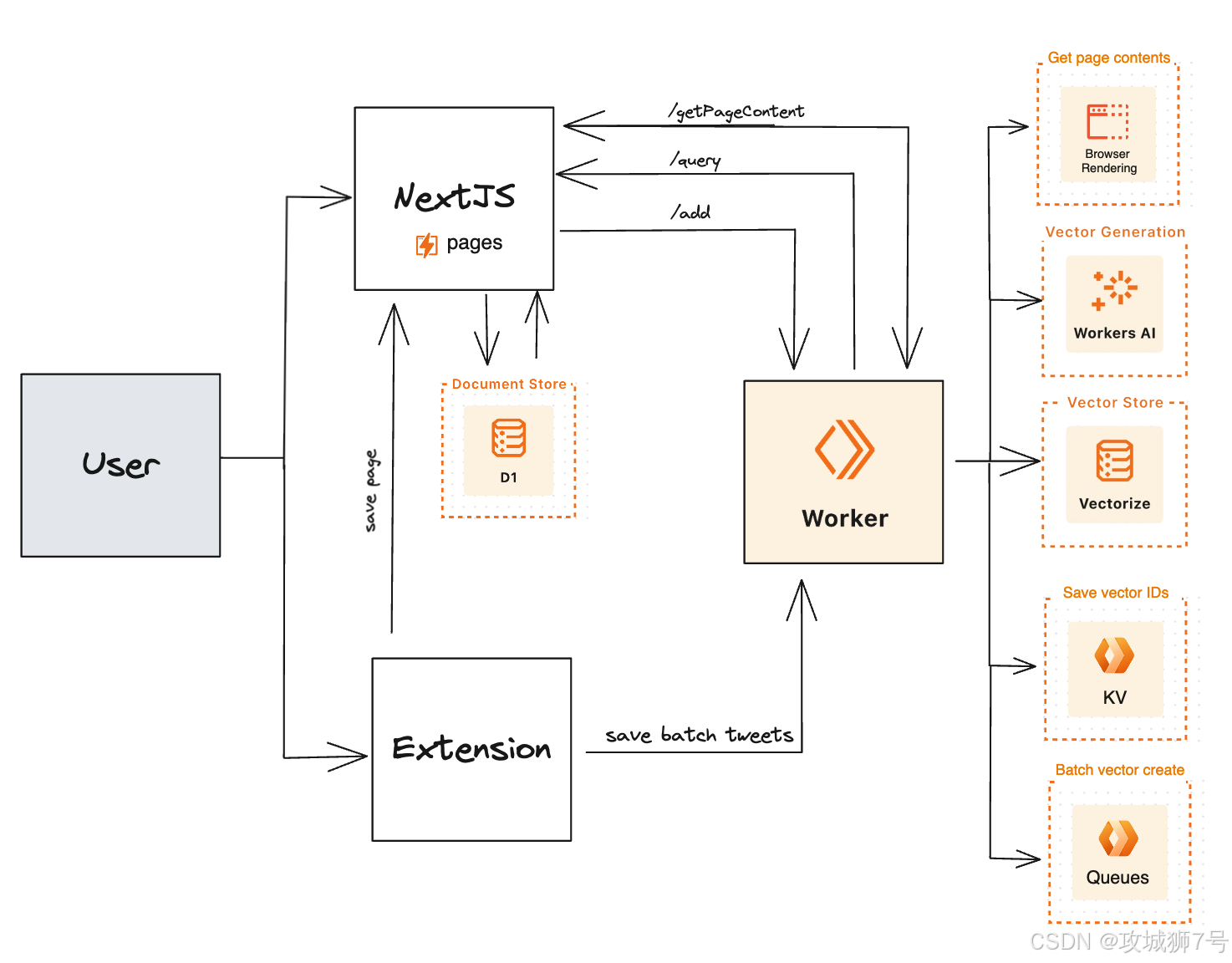
????????隨著技術的不斷演進和應用場景的持續拓展,Supermemory 有望成為 AI 領域的核心記憶組件,如同數據庫之于傳統軟件一樣,為人工智能的進一步發展奠定堅實的"記憶基石"。它不僅僅解決了當前 LLM 的一個痛點,更為我們描繪了一個 AI 擁有更強認知能力、能夠與人類進行更深度、更持久協作的未來。Supermemory 正引領我們進入一個全新的、擁有無限記憶的 AI 交互新紀元。
????????核心理念:LLM本身很強大,但正確的上下文能使其更有效。Supermemory負責構建這個"上下文池"并提供搜索工具。
????????主要特性概覽:想法捕捉、書簽管理、聯系人信息、Twitter書簽導入、強大搜索、與知識庫聊天、記憶刷新(相關內容重學習)、(將推出)AI寫作助手、注重隱私、可自托管、多平臺集成。
????????Supermemory 的目標不僅僅是解決 LLM 的上下文限制問題,更是要構建一個強大、通用、易于訪問的"AI 記憶層",讓每一個 AI 應用都能擁有持久的、可擴展的、智能的記憶能力。通過不斷的技術創新和生態建設,Supermemory 有望成為推動 AI 應用從"即時智能"邁向"持續智能"的關鍵力量。
看到這里了還不給博主點一個:
?? 點贊??收藏 ?? 關注!
💛 💙 💜 ?? 💚💓 💗 💕 💞 💘 💖
再次感謝大家的支持!
你們的點贊就是博主更新最大的動力!


















)
