為了適應 PD 分離式推理部署架構,百度智能云從物理網絡層面的「4us 端到端低時延」HPN 集群建設,到網絡流量層面的設備配置和管理,再到通信組件和算子層面的優化,顯著提升了上層推理服務的整體性能。
百度智能云在大規模 PD 分離式推理基礎設施優化的實踐中,充分展現了網絡基礎設施、通信組件與上層業務特征深度融合的重要性。
1. ? ?PD 分離式推理服務對網絡的需求
傳統的推理服務均是集中式,大多是單機部署。即使是多機部署,機器規模也非常小,對網絡的帶寬和時延需求都不大。當前大規模 PD 分離式推理系統來說,對網絡通信的需求則發生了變化:
- 引入大規模的 EP 專家并行。EP 會從單機和雙機的小規模,變成更大規模,因此 EP 之間的「 Alltoall 通信域」成倍增長。這對于網絡基礎設施、Alltoall 算子等的通信效率都提出了更高的要求,它們會直接影響 OTPS、TPOT 等指標,從而影響最終的用戶體驗。
- PD 分離式部署,Prefill 和 Decode 之間會有 KV Cache 流量的傳輸,KV Cache 通信的時延直接影響推理服務整體的性能。
為了提升大規模 PD 分離式推理系統的效率,百度智能云針對性地優化了網絡基礎設施和通信組件:
- 物理網絡層面:為適配 Alltoall 流量專門建設了「4us 端到端低時延」 HPN 集群,支持自適應路由功能徹底解決網絡哈希沖突,保證穩定的低時延。
- 流量管理層面:優化?Alltoall 多打一 incast 流量導致的降速問題。對 HPN 網絡中訓練、推理等不同類型流量進行隊列管理,實現訓推任務的互不干擾。通過自研高性能 KV Cache 傳輸庫實現 DCN 彈性 RDMA 滿帶寬傳輸。
- 通信組件層面:Alltoall 算子優化,相比開源的方案,大幅提升 Prefill 和 Decode 的 Alltoall 通信性能。針對 batch size 級別的動態冗余專家編排,將專家均衡度控制在了 1.2 以下,確保集群中所有 GPU 通信時間大致相同。優化雙流,實現最大程度的計算和通信 overlap,整體提升 20% 吞吐。
下面我們逐一介紹百度智能云在以上幾個層面的優化實踐。
2. ? ?解決方案和最佳實踐
2.1. ? ?建設適配 Alltoall 流量特征的 HPN 網絡設施
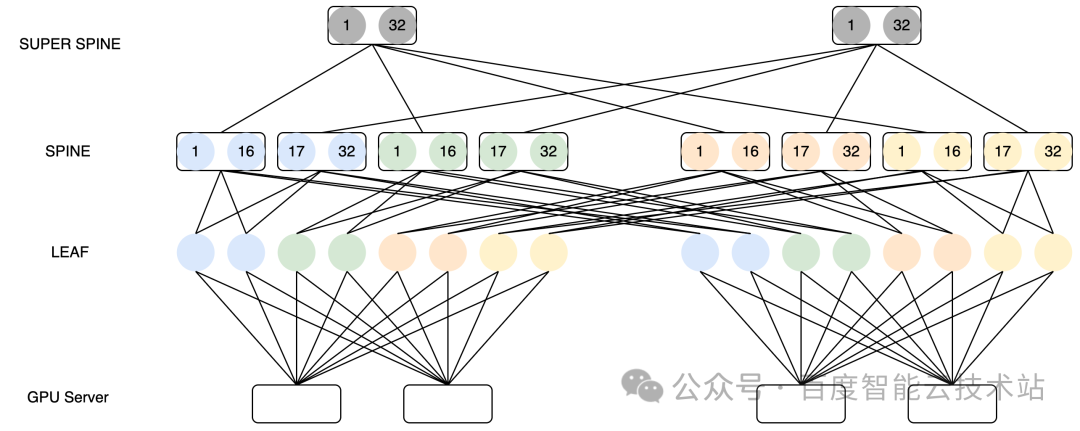
百度智能云在訓練場景下的 HPN 網絡架構設計已經有著豐富的經驗,AIPod 使用多導軌網絡架構,GPU 服務器配有 8 張網卡,然后每張網卡分別連到一個匯聚組的不同 LEAF 上。在 LEAF 和 SPINE 層面,通過 Full Mesh 的方式進行互聯。
以下圖為例,考慮一個訓練場景下的 3 層架構?HPN 網絡:
?2.1.1. ? ?訓練和推理任務的流量特征
- 非 MoE 訓練任務的流量特征
在傳統非 MoE 的訓練場景下,跨機通信產生的流量大多數都是同號卡流量。例如在梯度同步時候產生的 AllReduce 或者 ReduceScatter 或者 AllGather,PP 之間的 SendRecv 等。同號卡通信最佳情況可以只經過一跳,以上圖為例,每個 LEAF 交換機有 64 個下聯口,因此 64 臺服務器規模同號卡通信理論上可以做到一跳可達。
規模再大,就只能經過 SPINE 或者最差經過 SUPER SPINE 來進行通信。為了減少流量上送 SPINE,百度百舸在任務調度的時候會自動進行服務器的親和性調度。在創建任務的時候,盡量把同一通信組下的 Rank 排布在同一 LEAF 交換機下的服務器內,那么理論上大部分流量都可以收斂在 LEAF 下。
- MoE 推理流量特征
對于推理服務來說,MoE EP 之間的 Alltoall 通信流量模式與 AllReduce 等不同,會產生大量的跨導軌流量。雖然對于 Prefill 階段來說,可以通過軟件實現層面規避掉跨導軌的流量,但是 Decode 階段仍然無法避免跨導軌,這會導致多機之間的通信不只是同號卡通信,跨機流量大部分并不能一跳可達,會有大量的流量上到 SPINE 或者 SUPER SPINE,從而導致時延增加。
- MoE 訓練流量特征
對于 MoE 訓練的流量會更加復雜,綜合了訓練和推理的流量特征,既存在傳統的梯度同步產生的?AllReduce 或者 ReduceScatter 或者 AllGather,PP 之間的 SendRecv,也存在 EP 之間的 Alltoall 流量。這些流量不但會出現跨導軌傳輸的問題,他們之間可能會存在 overlap 導致互相干擾。
2.1.2. ? 面向 EP 的 HPN 架構優化
鑒于 Alltoall 通信的特點,我們在設計 HPN 網絡的時候,會考慮優先保證跨導軌流量至多 2 跳可達,讓 Alltoall 流量收斂到 SPINE 層,以這種方式盡量減少跨導軌的通信時延。如下圖所示:
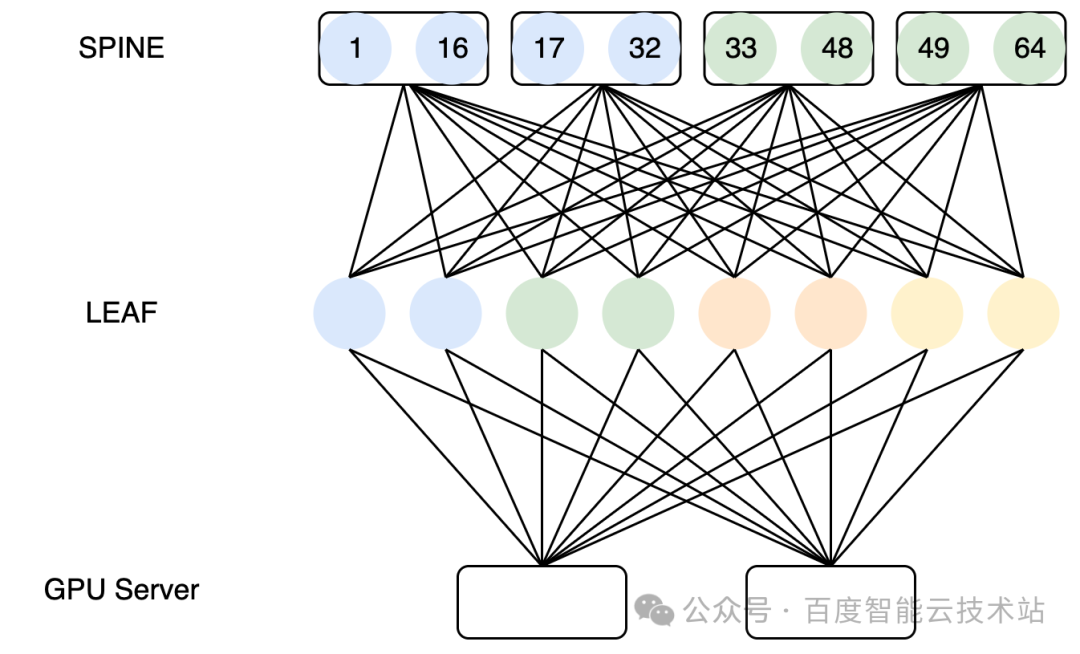
LEAF 層所有設備全部有一根線接入同一臺 SPINE 交換機,這樣可以讓集群內 Alltoall 跨導軌流量全部收斂到 SPINE 層,跨導軌通信時延可以進一步從 5us+ 縮小為 4us。
這種經過優化后的 HPN 網絡架構,能接入的卡數主要取決于交換機芯片支持的最大的下聯口有多少。雖然對于超大模型的訓練任務來說,這個集群規模可能不夠,但是對于推理來說,通常不需要那么大規模的機器,是可以滿足需求的。
2.1.3. ? ?自適應路由徹底消除 hash 沖突
同時,由于 Alltoall 通信流量的特征,LEAF 到 SPINE 之間的通信流量會成為常態。當流量需要通過 SPINE 傳輸的時候,會由 hash 選擇 SPINE 出口的過程,這時候有可能會產生 hash 沖突,導致網絡抖動。因此為了避免 hash 沖突,百度智能云基于自研交換機實現自適應路由。如下圖所示:
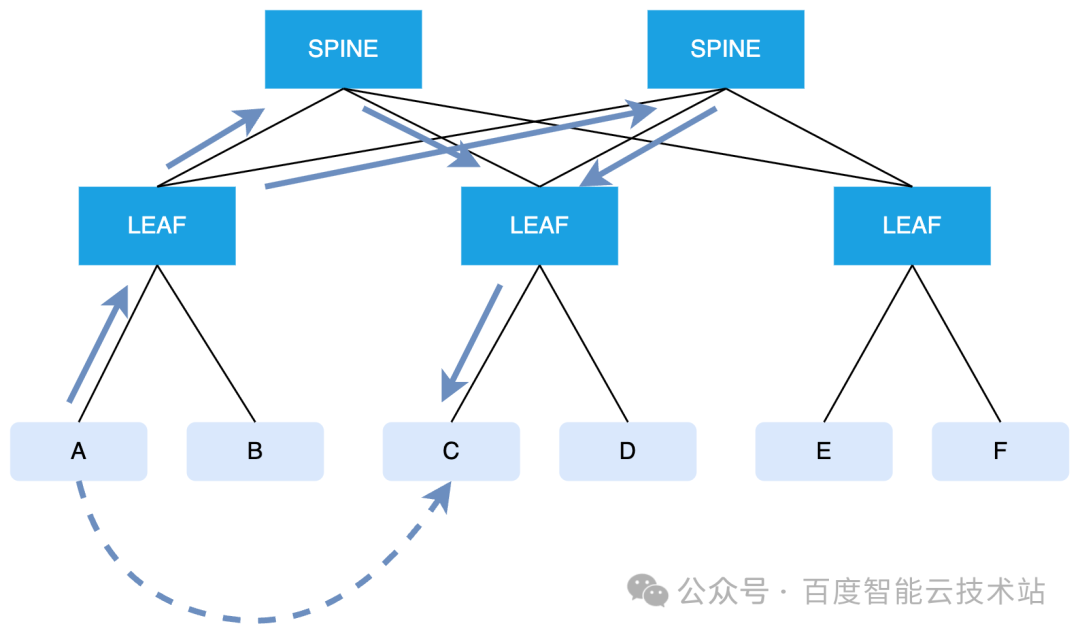
假設 A 和 C 進行 Alltoall 跨導軌通信,A 發出的流量必然要經過 SPINE,那么流量在到達 LEAF 的時候,會基于 packet 做 hash,并結合鏈路的負載情況動態選擇最優的出口,將報文發送到多個 SPINE 上。
基于報文 hash 到不同的物理路徑,百度智能云實現了鏈路負載均衡,消除因 hash 沖突時延增加導致的性能抖動,實現穩定的低時延網絡。
詳情可參考:徹底解決網絡哈希沖突,百度百舸的高性能網絡 HPN 落地實踐
2.2. ? ?Alltoall 和 KV Cache 流量的管理和優化
2.2.1.??? 避免 incast 造成降速,不同類型流量的分隊列管理
- Alltoall 多打一,不合理的配置造成降速
在推理服務中,EP 間的 Alltoall 通信流量特性與傳統訓練中的 AllReduce 完全不同,網絡上多打一造成的 incast 流量非常常見。這種 incast 的嚴重程度會隨著規模的增大而增大。incast 流量的突發,可能會造成接收側網卡上聯的交換機端口向發送側反壓 PFC,導致網絡降速。
傳統 Alltoall 流量多打一的示意圖如下,假設機器 A 和機器 C 的 GPU0、GPU2、GPU4、GPU6 都需要給機器 B 的 GPU0 發送數據,那么在網絡上就會出現 8 打 1 的情況。
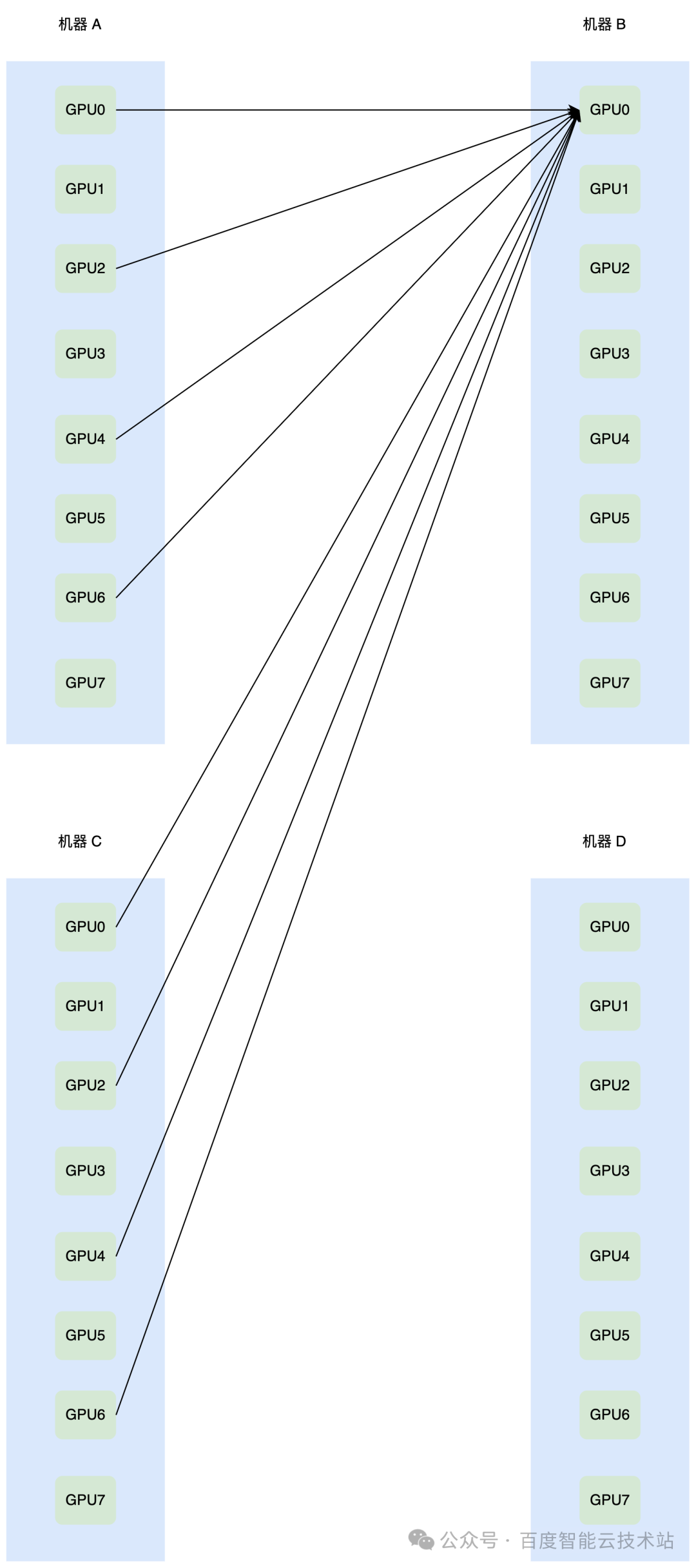
傳統的 Alltoall 實現,例如 PyTorch 內部調用的 Alltoall,是使用 send recv 去實現的,如果使用 PXN 可以縮小網絡上的發生多打一的規模,但是多打一依然存在,如下圖所示:
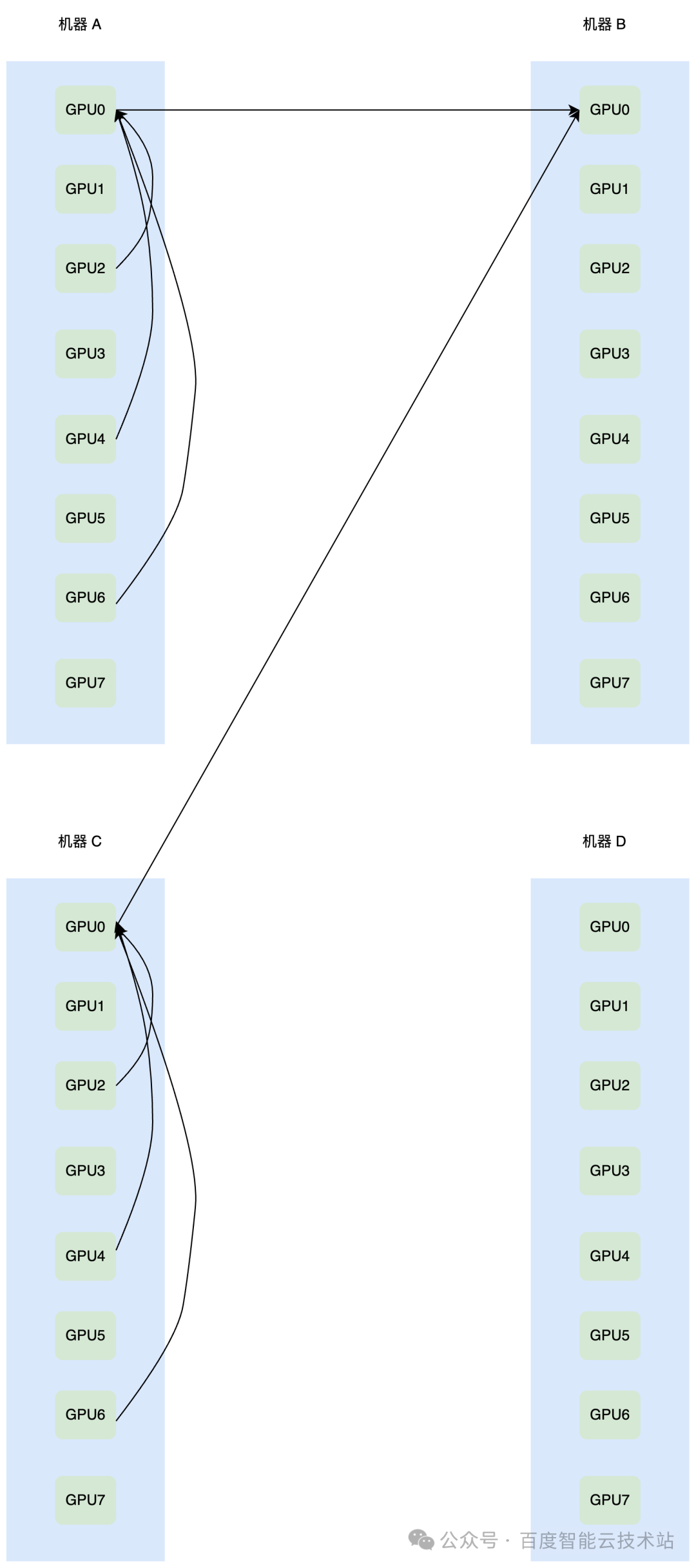
因此無論 Alltoall 的算子實現方式如何,網絡上的多打一都無法避免。此時如果網絡側的擁塞控制算法的配置不合理,對擁塞過于敏感,就會產生降速,進而對整體吞吐造成影響。
- 推理訓練任務中非 Alltoall 流量的干擾
除此之外,如果集群內還存在其他流量,例如訓練任務 DP(數據并行)之間的 AllReduce 或者 ReduceScatter 或者 AllGather,或者 PD(Prefill-Decode)之間的 KV Cache 傳輸,也會對 Alltoall 的流量造成影響,從而進一步降低推理引擎的整體吞吐。
因此無論是端側網卡的配置,或者是交換機的配置,都需要針對 Alltoall 這種多打一 incast 流量做針對性優化,同時盡量避免集群內其他流量對 Alltoall 流量造成影響。
針對這種情況,我們給出的解決方案如下:
- 在隊列管理層面,通過端側網卡將 EP 的流量做專門的優先級配置,將 Alltoall 流量導入到高優先級隊列。其他訓練的流量,比如 AllReduce 等使用低優先級隊列。
- 在資源層面,在端側網卡和交換機的高優先級隊列上,預留更多的 buffer,分配更高比例的帶寬,優先的保證高優先級隊列的流量。
- 在擁塞控制算法配置層面,高優先級隊列關閉 ECN 標記功能,讓 DCQCN 算法對 Alltoall 流量微突發造成的擁塞不做出反應,從而解決 incast 問題造成的降速。
在經過端側網卡和網側交換機配合調整后,可以保障 Alltoall 通信流量的通信帶寬和傳輸時延,實現訓推任務的互不干擾,并有效的緩解 incast 流量帶來的非預期的降速而造成的性能抖動。
經過測試,在我們部署的推理服務中,Alltoall 過程的整體通信時延有 5% 的降低。
2.2.2. ? ?DCN 支持彈性 RDMA 實現 KV Cache 滿帶寬傳輸
在 PD 分離式推理系統中,還存在 PD 之間 KV Cache 傳輸的流量。相比 Alltoall 雖然他的帶寬需求不算大,但為了避免二者的流量互相干擾,通常我們會讓?KV Cache 的傳輸流量單獨走 DCN 網絡,使其與 Alltoall 的流量完全隔離開。
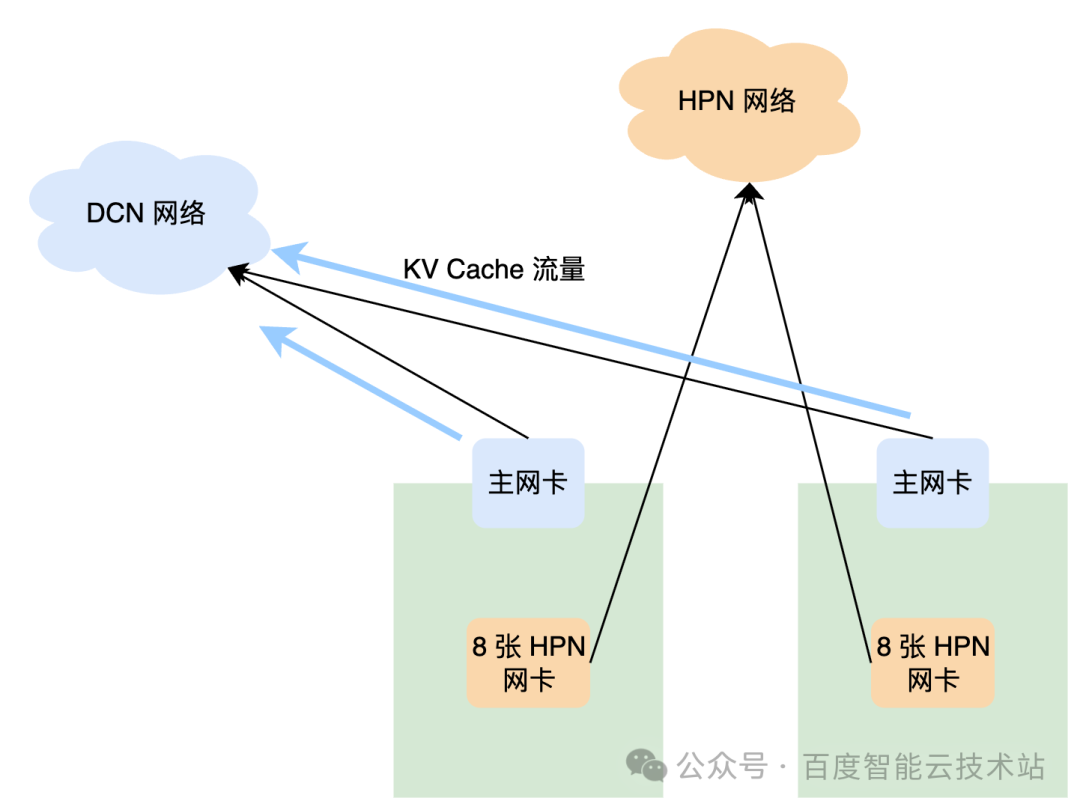
在 DCN 網絡的設計上,為了保證?KV Cache?流量的傳輸帶寬,其網絡架構收斂比采用 1:1。端側網卡支持彈性 RDMA,使用 RDMA 協議保證?KV Cache?的高性能傳輸。
在傳輸庫層面,百度智能云使用自研的高性能?KV Cache RDMA 傳輸庫,其接口設計與框架層深度定制,支持上層框架分層傳輸,也支持多層?KV Cache?的批量傳輸,便于在框架層做計算與傳輸的 overlap。
通過以上設計優化,KV Cache 傳輸在主網卡可以用滿帶寬,傳輸時間可以完全被計算 overlap 住,不成為推理系統的瓶頸。
2.3. ? ?提高推理服務組件的網絡通信效率
在有了高帶寬低時延的網絡基礎設施的基礎上,如何用好網絡基礎設施,是推理服務軟件層面需要重點考慮的事情。
在我們對 PD 分離推理服務的 profile 分析當中,發現了一些影響網絡通信效率的關鍵因素。
2.3.1. ? ?Alltoall 算子的通信效率
目前社區開源的 DeepEP 已經給出了推理系統中 dispatch 和 combine 過程的 Alltoall 高性能的算子的實現,且性能表現優異。
對于 Prefill 來說,由于輸入的 batch size 較大,Alltoall 通信算子的同號卡傳輸階段為了平衡顯存資源和性能,采用分 chunk 傳輸的方式,發送和接收會循環使用一小塊顯存,并對每次 RDMA 發送以及機內 NVLink 傳輸的 token 數做了限制。
通過實際觀測網卡的傳輸帶寬,發現其并沒有被打滿。在此基礎上,我們對網絡傳輸的顯存的大小,以及每一輪發送接收的最大 token 數等配置,針對不同的 GPU 芯片,做了一些精細化的調整,使之在性能上有進一步的提升。通過優化,DeepEP 的傳輸性能有大概 20%?的性能提升,網絡帶寬已經基本被打滿。
對于 Decode 來說,DeepEP 的實現是多機之間的 EP 通信,不區分機內和機間,一律采用網絡發送。這樣做的考慮是為了機內傳輸也不消耗 GPU 的 SM 資源,完成網絡發送后算子即可退出。在網絡傳輸的時間內做計算,完成后再調用 Alltoall 的接收算子,以此來實現計算和通信的 overlap。但這樣做的缺點是機內的 NVLink 的帶寬并沒有被高效的利用起來,網絡傳輸的數據量會變大。
因此,百度智能云通過在 GPU 算子內使用 CE 引擎做異步拷貝,在不占用 GPU SM 資源的情況下,也能實現機內 NVLink 帶寬的高效利用,同時不影響計算和通信的 overlap。
2.3.2. ? ?動態冗余專家編碼,保證 EP 負載均衡
EP 專家之間如果出現處理 token 不均衡的情況,將會導致 Alltoall 通信算子的不同 SM 之間,以及不同 GPU 的通信算子之間,出現負載不均的情況,導致的結果就是整體通信時間會被拉長。
由于 EP 專家之間的負載均衡是推理服務引擎提升吞吐的非常重要的一環,經過百度智能云的大規模的線上實踐的經驗來看,靜態冗余專家并不能很好的保證專家均衡。因此我們專門適配了針對 batch size 級別的動態冗余專家,把專家均衡度(max token/avg token)基本控制在了 1.2 以下,不會出現明顯的「快慢卡」的情況。
2.3.3. ? ?極致優化雙流效果,整體吞吐進一步提升
通信和計算 overlap,隱藏通信的開銷,一直都是推理服務,或者大模型訓練中,非常重要的課題。
在百度智能云的實踐中,我們在線上大規模的推理服務中開啟了雙流。為了盡量隱藏掉通信的開銷,達到最好的 overlap 的效果,除了做 EP 之間的專家均衡以外,對計算算子也做了針對性的優化,例如對計算算子和通信算子 kernel launch 的順序做合理排布,對二者所需的 SM 資源做合理的分配,避免出現計算算子占滿 SM 導致通信算子 launch 不進去的情況,盡可能的消滅掉 GPU 間隙的資源浪費。通過這些優化,整體的吞吐可以提升 20% 以上。
3. ? ?總結
百度智能云在大規模 PD 分離式推理基礎設施優化的實踐中,充分展現了網絡基礎設施、通信組件與上層業務特征深度融合的重要性。這種融合不僅是技術層面的創新,更是對實際業務需求的深刻理解和響應。


![[system-design] ByteByteGo_Note Summary](http://pic.xiahunao.cn/[system-design] ByteByteGo_Note Summary)


:混合檢索之混合搜索)
)
)
------ 圖像腐蝕and圖像膨脹)


:一文詳解three.js中的著色器Shader)



:結構化編程)
)


