一、軟件測試基礎面試題
1、闡述軟件生命周期都有哪些階段? 常見的軟件生命周期模型有哪些?
軟件生命周期是指一個計算機軟件從功能確定設計,到開發成功投入使用,并在使用中不斷地修改、增補和完善,直到停止該軟件的使用的全過程(從醞釀到廢棄的過程)
生命周期從收到應用軟供開始算起,到該軟件不再使用為止。
它有如下各方面的內容:
初始構思、需求分析、功能設計、內部設計、文檔計劃、測試計劃、文檔準備、集成、測 試、維護升級、再測試、逐步淘汰 (phase-out)、等等
常見的軟件生命周期模型:
瀑布模型,迭代式模型,快速原型模型,螺旋模型
2、什么是版本控制,常用的版本控制系統有哪些?
版本控制 (Revision control) 是一種軟件工程技巧,在在開發的過程中,確保由不同人所編輯的司一文件都得到更新及歷史記錄的保存。Git(讀音為/git/。)是一個開源的分布式版本控制系統,可以有效、高速的處理從很小到非常大的項目版本管理。?
Git 是 Linus Torvalds 為了幫助管理?Linux?內核開發而開發的一個開放源碼的版本控制軟件。?https://git-scm.com/docSVN 是 Subversion 的簡稱,是一個開放源代碼的版本控制系統,相較于 RCS、CVS,它采用了分支管理系統,它的設 計目標就是取代CVs .互聯網上很多版本控制服務已從CVs 遷Subversion移https://tortoisesvn.net/support.htm
3、簡述軟件測試與軟件開發之間的關系?
1.項目規劃階段:負責從單元測試到系統測試的整個測試階段的監控。
2.需求分析階段:確定測試需求分析、系統測試計劃的制定,評審后成為管理項目。測試需求分析是對產品生命周期中測試所需求的資源配置、每階段評判通過的規約,系統測試計劃則是依據軟件的需求規格說明書,制定測試計劃和設計相應的測試用例。
3.詳細設計和概要設計階段: 確保集成測試計劃和單元測試計劃完成。
4.編碼階段: 由開發人員進行自己負責部分的代碼的測試。在項目較大時,由專人進行編碼階段的測試任務
5.測試階段(單元、集成、系統測試) :?
依據測試代碼進行測試,并提交相應的測試狀態報告和測試結束報告開發和測試是一個有機的整體!在產品的發布之前,開發和測試是循環進行的, 測出的缺陷要經開發人員修改后繼續測試。在開發的同時測試經理開始編寫測試用例,測 試文檔要參考開發文檔,所以開發和測試是不可分割的,少了任何一個都不能開發出產品。從角色方面看,像理論和實驗的關系,開發人員通過自己的想象創造出一套思想,之 后測試人員再對它進行檢驗、證偽,開發人員再修改的過程從而不斷豐富產品。
從方法方 面看,是演繹和歸納的關系,一個要掌握大量的技術一個要不斷的從實例中學習。因這 兩方面的不司,所以開發和測試看上去做的工作很不一樣開發與測試是相輔相承、密不可分的,開發人員開發出新的產品后要通過測試判斷產 品是否完全滿足用戶的需求。如果發現缺陷,提交給開發人員進行修復,然后再轉交測試 人員進行回歸測試,直到產品符合需求規格說明。符合用戶需求的產品是開發和測試 共同努力的成果
4、請根據”V”模型分別概述測試人員在軟件的需求定
義階段、設計階段、編碼階段、系統集成階段的工作任務及其相應生成的文檔?
需求定義階段:根據項目需求提取測試需求 并形成測試需求文檔,根據提取的測試需求和項目計劃進行測試計劃的擬定,測試計劃文檔
設計階段: 根據測試需求擬訂測試方案并形成測試方案文檔,根據測試方案制定測試用例,并形成測試用例文檔
編碼階段:執行測試并完善測試用例文檔
系統集成階段:測試總結報告,階段問題統計報告,測試問題報告
5、W 模型的描述?
W 模型也稱之為雙V 模型,一個V 是開發的生命同期,另一個V 是測試的生命周期,W 模型與V模型有一個很大的不同,就是W 模型是一個并行的模型,V 模型是一個串行的模型,W 模型開始是從需求分析開始就開始了,而不是等到編碼完成后才開始。
并且測試階段的劃分更清楚,而不僅僅是單元測試、集成測試、系統測試,還包括前期的測試計劃、測試方案等內容,這更符合現在企業測試的流程。W 模型強調測試伴隨著整個軟件開發周期,而且測試的對象不僅僅是程序需求、設計等同樣要測試,也就是說,測試與開發是同步進行的。W 模型有利于盡早全面地發現問題。
從需求分析開始測試工程師就參與到項目的測試中,當需求分析完成后,測試工程師就需要參與到需求的驗證和確認活動中,并需要提供可測試性需求分析說明書,這樣可以盡早地發現需求階段的缺陷。同時,對需求的測試也有利子及時了解項目難度和測試風險,及早制定應對指施,這將顯著減少總體測試時間,加快項目進度。
但W 模型也存在局限性,需求、設計、編碼等活動被視為是串行的,同時,測試和開發活動也保持著一種線性的前后關系,上一階段完全結束,才可正式開始下一階段工作,這樣就無法支持迭代的開發模型。對于當前軟件開發復雜多變的情況,W 模型并不能解除測試管理面臨的床惑。
總之W 模型具有以下特征:
(1)測試階段戈分得更全面,不僅僅是單元測試、集成測試和系統測試,
(2)測試與開發是并行的,從需求測試就應該開始介入
(3)提出盡早測試的概念,這樣可以險低缺陷修復成本;
(4)測試對象不僅僅是程序,還包括需求或其他的相關文檔
6、編寫測試計劃的目的是?
使測試工作順利進行,使項目參與人員溝通更舒暢,使測試工作更加系統化
7、測試計劃編寫的六要素?
why一一為什么要進行這些測試
what一測試哪些方面,不同階段的工作內容
when一測試不同階段的起止時間
where一相應文檔,缺陷的存放位置,測試環境等
who一項目有關人員組成,安排哪些測試人員進行測試
how一如何去做,使用哪些測試工具以及測試方法進行測試。
8、項目版本執行過程中,測試人員如何把控測試進度?
在項目的系統測試過程中,測試負責人要及時了解測試進度,跟蹤 BUG 提交、修復及驗證情況以及系統的拷機情況。在開發初期階段,測試組執行BBFV 時,很多模塊、功能點的開發完成進度和原計劃會存在一定的偏差,就需要測試負責人動態的刷新WBS 計劃,根據實際的開發進度調整測試計劃。
在開發階段,存在版本編譯不出來導致無法測試,開發人員修復代碼太隨意導致版本穩定性反復,需求變更過大導致后端測試開發變更嚴重等現象,會導致測試工作無法正常進行。
就需要測試負責人及時反饋出來,根據項目本身的特點講行對應的處理。當測試進度出現延期時,要及時確認問題原因如果是問題協查導致,則需及時與研發人員進行溝通協商,看問題是否必須在測試環境進行排查,若為必現問題可與研發協商要求其在自己環境進行排查,若必須占用測試環境,則需及時調整測試計劃,若因此可能影響版本的發布,則應及時與 SE 確認。
若發現有較多BUG 未解決,則應主動聯系 SE 及研發人員召開BUG 會確定問題的解決時間。若發現有較多BUG未驗證,則應提醒項目組的測試人員及時進行驗證,對于一些拷機或非必現的BUG,建議測試人員在此 BUG 上現做拷機標記連續拷機一周未再復現的做關閉處理,若再次復現則繼續進行排查。疑難問題的跟控: 比較難復現的問題,怎么去嘗試復現。
比較難定位的問題,怎么驅動、反饋給SE,協調開發人員定位問題。比較難處理的問題,怎么跟控反饋進度等每天下班前確認拷機內容,每天上班第一件事需確認拷機結果,只有這樣才能保證拷機的效果,實現拷機的真正意義。
9、測試人員在軟件開發過程中的任務是什么?
尋找 Bug;避免軟件開發過程中的缺陷;衡量軟件的品質,關注用戶的需求。總的目標是:確保軟件的質量。
10、軟件缺陷有哪些?
1)軟件未實現產品說明書要求的功能
2)軟件出現了產品說明書指明不應該出現的錯誤
3)軟件實現了產品說明書未提到的功能
4)軟件未實現產品說明書雖未明確提及但應該實現的目標
5)軟件難以理解、不易使用、運行緩慢或者從測試員的角度看最終用戶會認為不好
為了發現軟件產品中的各種缺陷,而對軟件產品進行驗證和確認的活動過程,此過程貫穿整個軟件開發生命周期。簡單的說,軟件測試是以發現錯誤為目的而執行的一個程序或系統的過程。
11、你如何理解軟件測試的目的?
-
驗證軟件需求和功能是否得到完整實現
-
驗證軟件是否可以發布
-
盡可能多的發現軟件中的bug
-
盡可能早的發現軟件中的bug
-
對軟件質量做出合理評估
-
預防下個版本可能出現的問題
-
預防用戶使用可能出現的問題
-
發現開發過程中的問題和風險
12、軟件測試有哪些原則?
-
所有測試的標準都是建立在用戶需求之上 。
-
合理控制測試深度與廣度,完全測試不可能,測試的投入與產出要均衡。
-
80-20原則,軟件中80%的bug可以在分析、設計與評審階段就能被發現與修正,16%的缺陷在系統的軟件測試中發現,最后剩下的4%是用戶長期使用的過程中才能暴露出來。
-
盡可能早的開展測試,越早發現錯誤,修改的代價越小。
-
發現錯誤較多的程序段,應進行更深入的測試。
-
軟件項目一啟動,軟件測試也就是開始,而不是等程序寫完,才開始進行測試 。
-
軟件開發人員即程序員應當避免測試自己的程序
-
嚴格執行測試計劃,排除測試的隨意性,以避免發生疏漏或者重復無效的工作
優秀測試人員應具備的素質:
1)溝通能力與表達能力?
2)好奇心與懷疑精神?
3)責任感與抗壓能力?
4)自信心,堅持自己的觀點
5)耐心與細心?
6)逆向思維的能力?
7)善于學習與總結?
8)團隊協作精神?
9)文檔編寫能力
優秀測試人員應具備的技能:
1)精通業務知識?
2)具備軟件編程能力,比如C,C++,JAVA等。
3)可以用腳本語言編寫小測試工具
4)主流操作系統應用與網絡知識,可以搭建測試環境?
5)熟練掌握各種數據庫知識?
6)精通軟件測試理論與方法?
7)掌握常用測試與開發工具的使用?
8)優秀的文檔編寫能力
13、說一說軟件測試的組織架構
1)項目型的測試組織:
測試人員作為項目組的固定成員,從頭到尾的跟著項目走
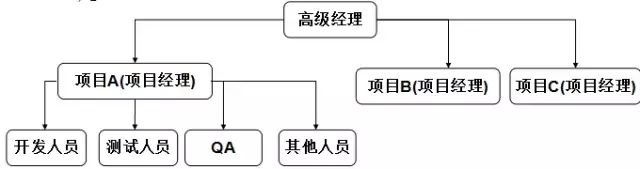
2)智能型的測試組織:
測試人員參與到項目中,是以獨立的測試部門委派的方式進入
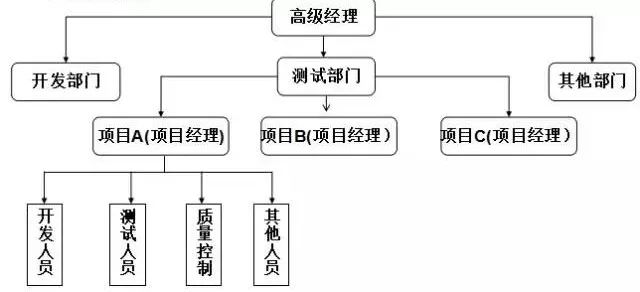
3)綜合型的測試組織:
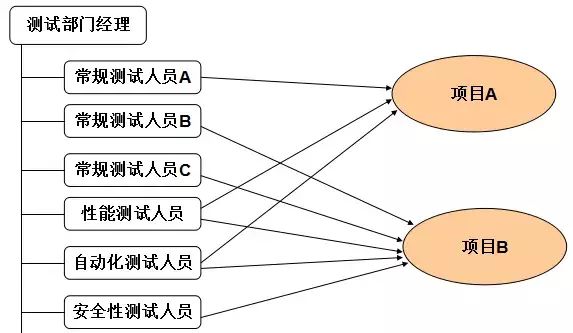
項目型與職能型的結構組合并加以改造而產生的。測試部門把測試人員,分為常規項目測試人員與專項測試人員。測試部門會把常規測試人員長期委派到項目組中,成為項目中的一員。專項測試人員,一般由性能測試工程師、自動化測試工程師、安全性測試工程師等組成。只有當項目發生專門需求測試時,測試部門才靈活把專項測試人員委派到各個項目組進行專項測試。
14、軟件測試常見分類有哪些?
1)按照是否執行被測試軟件來分:
靜態測試:是指不運行軟件,測試包括代碼檢查、靜態結構分析、代碼質量度量等,主要對軟件需求說明書、設計說明書、軟件源代碼進行檢查與分析。
動態測試:指通過運行被測程序,檢查運行結果與預期結果的差異,分析差異原因,并分析軟件運行效率、健壯性等性能。動態測試是目前公司主要的測試方式
2)按照測試技術分為黑盒測試和白盒測試:
黑盒測試:黑盒測試又叫功能測試或數據驅動測試,在完全不考慮程序內部結構和內部特性的情況下,通過軟件的外部表現來發現其缺陷和錯誤。
白盒測試:白盒測試也稱結構測試或邏輯驅動測試,它是按照程序內部的結構進行測試程序,通過測試來檢測產品內部邏輯是否按照設計規格說明書的規定正常進行,檢驗程序中的每條通路是否都能按預定要求正確工作。
3)按照測試手段來分:可以分為手工測試和自動化測試
4)按照過程階段來分:可以分為單元測試、集成測試、系統測試和驗收測試
單元測試:通過模塊(類/方法/函數)測試,使代碼達到設計要求 主要目的是針對編碼過程中可能存在的各種錯誤,例如用戶輸入驗證過程中的邊界值的錯誤。
集成測試:將經過單元測試的模塊逐步組裝成完整的程序。主要目的是檢查各單元與其它程序部分之間的接口是否存在問題,各模塊功能之間是否有影響。
系統測試:是將已經確認的軟件、計算機硬件、外設、網絡等其他元素結合在一起進行測試。系統測試是針對整個產品系統進行的測試,目的是驗證系統是否滿足了需求規格的定義,找出與需求規格不符或與之矛盾的地方 ,進行改正。
驗收測試:驗收測試是在軟件產品完成了單元測試、集成測試和系統測試之后,產品發布之前所進行的最后一次軟件測試活動,也稱為交付測試。通常由業務專家或用戶進行,以確認產品能真正符合用戶業務上的需要。
15、軟件開發流程和開發模型?
軟件生命周期:
計劃-》需求分析-》設計-》程序編寫-》測試-》運行/維護
軟件測試流程:
測試計劃-》需求分析-》測試用例-》測試用例執行-》提交bug-》回歸測試
瀑布模型:適用于需求很明確的項目,分階段向下進行,無法回溯
迭代模型:需求不明確,迭代版本系統
敏捷開發模型:
敏捷開發是一種以人為核心、迭代、循序漸進的開發方法。在敏捷開發中,軟件項目被切分成多個子項目,各個子項目的成果都經過測試,具備集成和可運行的特征。換言之,就是把一個大項目分為多個相互聯系,但也可獨立運行的小項目,并分別完成,在此過程中軟件一直處于可使用狀態。
測試驅動開發模型:先編寫測試代碼,再寫開發代碼
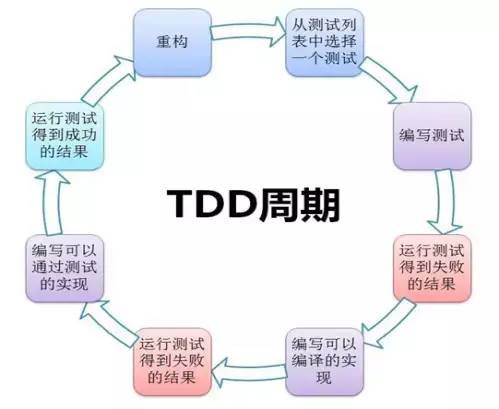
16、軟件測試模型有哪些?
V模型:反映了測試與開發階段之間一一對應的特點,測試在開發之后,出錯后回歸測試量大
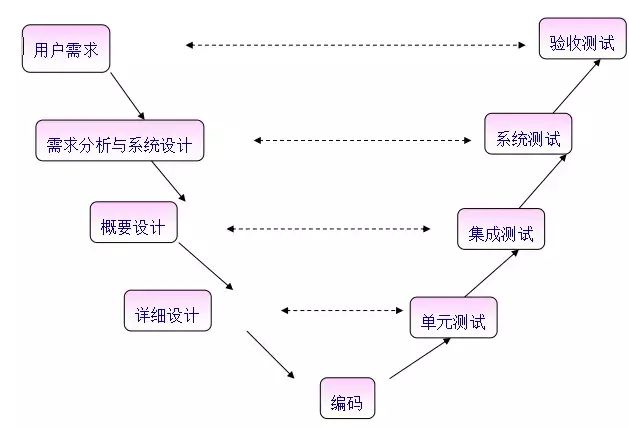
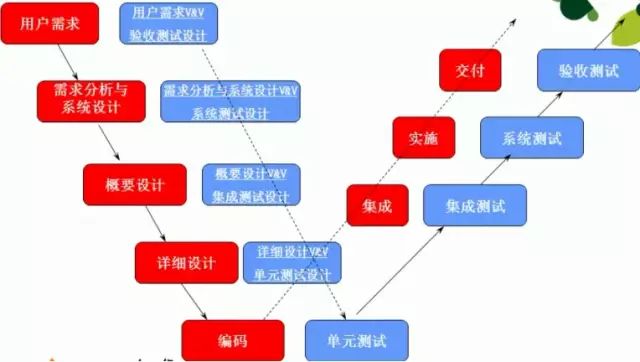
W模型:測試伴隨整個開發周期,測試與開發同步進行,有利于盡早發現問題
H模型:軟件測試活動完全獨立,與其他流程并行
二、WEB功能測試面試題
1、Student-coures-Studentcourse表關系如下:
student(sno,sname,age,sdept)學生表
course(cno,cname,teacher)課程表
Studentcourse(sno,cno,grade)選課表寫出sql語句:
·查詢所有課程都及格的學生號和姓名·查詢平均分不及格的課程號和平均成績
找出各門課程的平均成績,輸出課程號和平均成績
找出沒有選擇c2課程的學生信息
2、請說出XHTML和HTML的區別
1、文檔頂部doctype聲明不同,xhtml的doctype頂部聲明中明確規定了xhtml DTD的寫法;
2.?html元素必須正確嵌套,不能亂;3、屬性必須是小寫的;
4、屬性值必須加引號;
5、標簽必須有結束,單標簽也應該用“/”來結束掉;
3、很多網站不常用table iframe這兩個元素,知道原因嗎
因為瀏覽器頁面渲染的時候是從上至下的,而table和iframe這兩種元素會改變這樣渲染規則,他們是要等待自己元素內的內容加載完才整體渲染。用戶體驗會很不友好。
4、jpg和png格式的圖片有什么區別?
jpg是有損壓縮格式,png是無損壓縮格式。所以,相同的圖片,jpg體積會小。
比如我們一些官網的banner圖,一般都很大,所以適合用jpg類型的圖片。
但png分8位的和24位的,8位的體積會小很多,但在某些瀏覽器下8位的png圖片會有鋸齒。
5、簡述—下src與href的區別
瀏覽器會識別href引用的文檔并行下載該文檔,并且不會停止對當前文檔的處理
當瀏覽器解析到src引|用時,會暫停瀏覽器的渲染,直到該資源加載完畢。這也是將js腳本放在底部而不是頭部的原因。
6、:before和::before區別?
單冒號(t)用于CSS3偽類,雙冒號(:)用于CSS3偽元素。
對于CSS2之前已有的偽元素,比如:before,單冒號和雙冒號的寫法::before作用是一樣的。
7、如何理解HTML結構的語義化?
所謂標簽語義化,就是指標簽的含義。語義化的主要目的就是讓大家直觀的認識標簽(markup)和屬性(attribute)的用途和作用,對搜索引擎友好,有了良好的結構和語義我們的網頁內容便自然容易被搜索引擎抓取,這種符合搜索引擎收索規則的做法,網站的推廣便可以省下不少的功夫,而且可維護性更高,因為結構清晰,十分易于閱讀。這也是搜索引擎優化SEO重要的一步。
8、常見的視頻編碼格式有幾種?視頻格式有幾種?
視頻格式:MPEG-1、MPEG-2和MPEG4 、AVl .RM、ASF和WMV格式
視頻編碼格式:H.264、MPEG-4、MPEG-2.WMA-HD以及VC-1
9、JS中null, undefined的區別?
null表示一個對象被定義了,但存放了空指針,轉換為數值時為0。
undefined表示聲明的變量未初始化,轉換為數值時為NAN。
typeof(null) - object;
typeof(undefined) - undefined
10、什么是sql注入,什么是跨站腳本,什么是跨站請求偽造?
SQL注入攻擊是注入攻擊最常見的形式(此外還有OS注入攻擊( Struts 2的高危漏洞就是通過OGNL實施OS注入攻擊導致的)),當服務器使用請求參數構造SQL語句時,惡意的SQL被嵌入到SQL中交給數據庫執行。SQL注入攻擊需要攻擊者對數據庫結構有所了解才能進行,攻擊者想要獲得表結構有多種方式:
- 如果使用開源系統搭建網站,數據庫結構也是公開的(目前有很多現成的系統可以直接搭建論壇,電商網站,雖然方便快捷但是風險是必須要認真評估的);
- 錯誤回顯(如果將服務器的錯誤信息直接顯示在頁面上,攻擊者可以通過非法參數引發頁面錯誤從而通過錯誤信息了解數據庫結構,Web 應用應當設置友好的錯誤頁,一方面符合最小驚訝原則,一方面屏蔽掉可能給系統帶來危險的錯誤回顯信息);
- 盲注。防范SQL注入攻擊也可以采用消毒的方式,通過正則表達式對請求參數進行驗證,此外,參數綁定也是很好的手段,這樣惡意的SQL會被當做SQL的參數而不是命令被執行,JDBC中的PreparedStatement 就是支持參數綁定的語句對象,從性能和安全性上都明顯優于Statement。
xss (Cross Site Script,跨站腳本攻擊)是向網頁中注入惡意腳本在用戶瀏覽網頁時在用戶瀏覽器中執行惡意腳本的攻擊方式。跨站腳本攻擊分有兩種形式:
反射型攻擊(誘使用戶點擊一個嵌入惡意腳本的鏈接以達到攻擊的目標,目前有很多攻擊者利用論壇、微博發布含有惡意腳本的URL就屬于這種方式)
持久型攻擊(將惡意腳本提交到被攻擊網站的數據庫中,用戶瀏覽網頁時,惡意腳本從數據庫中被加載到頁面執行,QQ郵箱的早期版本就曾經被利用作為持久型跨站腳本攻擊的平臺)。
CSRF 攻擊(Cross Site Request Forgery,跨站請求偽造)是攻擊者通過跨站請求,以合法的用戶身份進行非法操作(如轉賬或發帖等)。CSRF的原理是利用瀏覽器的Cookie或服務器的Session ,盜取用戶身份,其原理如下圖所示。防范CSRF的主要手段是識別請求者的身份,主要有以下幾種方式:
- 在表單中添加令牌(token) ;
- 驗證碼;
- 檢查請求頭中的Referer (前面提到防圖片盜鏈接也是用的這種方式)。
令牌和驗證都具有一次消費性的特征,因此在原理上一致的,但是驗證碼是一種糟糕的用戶體驗,不是必要的情況下不要輕易使用驗證碼,目前很多網站的做法是如果在短時間內多次提交一個表單未獲得成功后才要求提供驗證碼,這樣會獲得較好的用戶體驗。
三、APP測試面試題
(1)基礎篇
1、請介紹一下,APP測試流程?
APP測試流程與web測試流程類似,分為如下七個階段:
1.根據需求說明書編寫測試計劃;
2.制定測試方案,主要是測試任務、測試人員和測試時間的分配;
3.測試準備,包括搭建測試環境,準備測試數據,確定測試方法;
4.測試用例的設計與編寫,進行用例評審及補充完善;
5.執行測試時首先進行冒煙測試,然后對主功能流程進行測試,包括客戶端的單個功能模塊,及功能業務邏輯功能交互,回歸測試;
6.提交測試結果,包括測試用例,測試計劃;
7.日常維護性測試;

APP測試周期可根據項目的開發周期來確定測試時間,一般測試時間為兩三周,根據項目情況以及版本質量可適當縮短或延長測試時間。
2、APP測試需要提前準備哪些測試資源?
具體要準備的測試資源,根據實際項目來,可以從以下幾個方面出發:
1.IOS設備、Android設備(選取市面上主流手機產品);
2.支付寶/銀聯支付的項目,需要提前申請支付寶/銀聯賬戶等等;
3.有秒殺專題的題目,需要規劃秒殺時間表;
4.有優惠券使用的項目,需要添加優惠券數據;
3、APP測試和Web測試的區別?
單純從功能測試的層面上來講的話,APP 測試、web 測試在流程和功能測試上是沒有區別的。
相同點:
1.同樣的測試用例設計方法;
2.同樣的測試方法:都會依據原型圖或效果圖檢查UI;
3.測試頁面載入和翻頁的速度、登錄時長、內存是否溢出等;
4.測試應用系統的穩定性;
不同點:
1.系統結構方面
-
web項目,b/s架構,基于瀏覽器的;web測試只要更新了服務器端,客戶端就會同步更新。
-
app項目,c/s結構的,必須要有客戶端;app 修改了服務端,則客戶端用戶所有核心版本都需要進行回歸測試一遍。
2.性能方面
-
web項目 需監測 響應時間、CPU、Memory;
-
app項目 除了監測 響應時間、CPU、Memory外,還需監測 流量、電量等;
3.兼容性方面
-
web項目:瀏覽器(火狐、谷歌、IE等);操作系統(Windows7、Windows10、Linux等)。
-
app項目:設備系統:iOS(ipad、iphone)、Android(三星、華為、聯想等) 、Windows(Win7、Win8)、OSX(Mac);手機設備可根據 手機型號、分辨率、屏幕尺寸不同。
4.測試工具方面
- 自動化工具:APP 一般使用 Appium; Web 一般使用 Selenium;
- 性能測試工具:APP 一般使用Monkey、 JMeter; Web 一般使用 LR、JMeter;
4、相對于 Web 項目,APP有哪些專項測試
1)干擾測試:中斷,來電,短信,關機,重啟等。
2)弱網絡測試(模擬2g、3g、4g、5g,wifi網絡狀態以及丟包情況);網絡切換測試(網絡斷開后重連、3g切換到4g、5g/wifi 等)。
3)安裝、更新、卸載,中斷、前后臺切換。
-
安裝:需考慮安裝時的中斷、弱網、安裝后刪除安裝文件,全新安裝、升級安裝、第三方工具安裝等情況;
-
卸載:需考慮第三方工具卸載、直接卸載卸,載后是否刪除app相關的文件;
-
更新:分強制更新、非強制更新、增量包更新、斷點續傳、弱網狀態下更新;
-
中斷:來電中斷、短信中斷、鬧鐘中斷、手機鎖定、手機斷電、手機死機;
4)界面操作:關于手機端測試,需注意手勢,橫豎屏切換,多點觸控,前后臺切換。
5)安全測試:安裝包是否可反編譯代碼、安裝包是否簽名、權限設置,例如訪問通訊錄等。
6)邊界測試:可用存儲空間少、沒有SD卡/雙SD卡、飛行模式、系統時間有誤、第三方依賴(QQ、微信登錄)等。
7)權限測試:設置某個App是否可以獲取該權限,例如是否可訪問通訊錄、相冊、照相機等。
5、Android手機和IOS手機,系統有什么區別?
1.兩者運行機制不同:IOS采用的是沙盒運行機制,安卓采用的是虛擬機運行機制。
IOS 沙盒運行機制:
-
每個程序都有自己的虛擬地址空間。所以,程序之間不能進行訪問。
-
默認只會將應用的最后運行數據,記錄在RAM里面。
Android 虛擬機運行機制:
-
所有的應用程序都是運行在虛擬機中,用戶界面其實是由虛擬機傳遞的,并且通過虛擬機,Android的任何程序都就可以輕松訪問其他程序文件。
-
所有的Android的應用程序都是運行在RAM里面的,所以會發現有時候Android用著用著就開始有點卡頓。
2.兩者后臺制度不同:IOS中任何第三方程序都不能在后臺運行;安卓中任何程序都能在后臺運行,直到沒有內存才會關閉。
3.IOS中用于UI指令權限最高,安卓中數據處理指令權限最高。
6、IOS和Android的APP測試有什么區別?
1.物理按鍵:Android長按home鍵呼出應用列表和切換應用,然后右滑則終止應用;iOS所有的返回上一層,只能靠頁面功能實現。
2.多分辨率測試:Android端20多種;IOS較少。
3.手機操作系統:Android較多,IOS較少且不能降級,只能單向升級;新的IOS系統中的資源庫不能完全兼容低版本中的IOS系統中的應用,低版本IOS系統中的應用調用了新的資源庫,會直接導致閃退。
4.操作習慣:Android,Back鍵是否被重寫,測試點擊Back鍵后的反饋是否正確;應用數據從內存移動到SD卡后能否正常運行等。
5.push測試:Android點擊home鍵,程序后臺運行時,此時接收到push,點擊后喚醒應用,此時是否可以正確跳轉;IOS點擊home鍵關閉程序和屏幕鎖屏的情況(紅點的顯示)。
6.安裝卸載測試:Android可以通過手機自帶的應用市場或者是第三方的手機助手進行下載,下載和安裝的平臺和工具和渠道比較多;IOS主要有app store,iTunes和testflight下載。
7.升級測試:可以被升級的必要條件:新舊版本具有相同的簽名;新舊版本具有相同的包名;有一個標示符區分新舊版本(如版本號)。
8.支付方式:對于一些有內購功能的APP,Android直接調用第三方支付渠道完成支付;IOS需要先在APP store里綁定支付方式,然后通過APP store去完成支付操作。
9.消息推送機制:Android使用第三方或者自建平臺進行消息推送;IOS的消息推送渠道由蘋果官方提供。
7、介紹一個APP抓包工具?
一般用Fiddler,主要用來做app抓包使用,先在Fiddler客戶端做好各項配置,端口設置為8888;然后在手機上設置代理,就可以抓包,主要看的是服務器返回的值、還能夠修改傳入參數、傳出的參數、模擬網絡延時,構造不同場景。
8、APP日志如何抓取?
-
可以使用adb命令:adb logcat | find "com.sankuai.meituan" >d:\test.txt
-
也可以用ddms抓取,手機連上電腦,打開ddms工具;
-
或者在Android Studio開發工具中,打開DDMS;
9、常用的adb命令有哪些?
1.查看幫助手冊列出所有的選項說明及子命令:
adb help
2.獲取設備列表及設備狀態:
adb devices
3.安裝應用:adb install 路徑\xx.apk, 安裝應用;adb install -r 重新安裝。
adb install
adb install -r
4.獲取設備的狀態,設備的狀態有 device , offline , unknown3種,其中device:設備正常連接,offline:連接出現異常,設備無響應,unknown:沒有連接設備。
adb get-state
5.卸載應用:adb uninstall <包名>, 后面的參數是應用的包名,區別于 apk 文件名。
adb uninstall
6.將 Android 設備上的文件或者文件夾復制到電腦本地:adb pull <遠程路徑> <本地路徑>, 如復制 Sdcard 下的 pull.txt 文件到 D 盤:adb pull sdcard/pull.txt d:\,重命名:adb pull sdcard/pull.txt d:\rename.txt。
adb pull
7.推送本地文件至 Android 設備:adb push <本地路徑> <遠程路徑>, 如推送 D 盤下的 ITester.txt 至 Sdcard:adb push d:\ITester.txt sdcard/ (注意sdcard 后面的斜杠不能少)。
adb push
8.結束和啟動adb服務:adb kill-server?/adb start-server , 結束 adb 服務/啟動 adb 服務,通常兩個命令一起用,設備狀態異常時使用 kill-server,運行 start-server 進行重啟服務。
adb kill-server
adb start-server
9.打印及清除系統日志:adb logcat , 打印 Android 的系統日志 ;adb logcat -c,清除日志。
adb logcat
adb logcat -c
10.查找包名/活動名
adb logcat | findstr START
10、adb三個組件是指?
ADB作為一個客戶端/服務器架構的命令行工具,主要由3個部分組成。
-
adb clent(客戶端):可以通過它對Android應用進行安裝、卸載及調試。
-
adb service(服務器):管理客戶端到Android設備上abd后臺進程的連接,負責管理client和damon進行通信。
-
adb daemon(守護進程):運行在Android設備上的adb后臺進程。
(2)進階篇
1、介紹一下Android四大組件?
Android四大基本組件:Activity、BroadcastReceiver廣播接收器、ContentProvider內容提供者、Service服務。
-
Activity:應用程序中,一個Activity就相當于手機屏幕,它是一種可以包含用戶界面的組件,主要用于和用戶進行交互。一個應用程序可以包含許多活動,比如事件的點擊,一般都會觸發一個新的Activity。
-
BroadcastReceiver廣播接收器:應用可以使用它對外部事件進行過濾只對感興趣的外部事件(如當電話呼入時,或者數據網絡可用時)進行接收并做出響應。廣播接收器沒有用戶界面。然而,它們可以啟動一個activity或serice 來響應它們收到的信息,或者用NotificationManager來通知用戶。通知可以用很多種方式來吸引用戶的注意力──閃動背燈、震動、播放聲音等。一般來說是在狀態欄上放一個持久的圖標,用戶可以打開它并獲取消息。
-
ContentProvider內容提供者:內容提供者主要用于在不同應用程序之間實現數據共享的功能,它提供了一套完整的機制,允許一個程序訪問另一個程序中的數據,同時還能保證被訪問數據的安全性。只有需要在多個應用程序間共享數據時才需要內容提供者。例如:通訊錄數據被多個應用程序使用,且必須存儲在一個內容提供者中。它的好處:統一數據訪問方式。
-
Service服務:是Android中實現程序后臺運行的解決方案,它非常適合去執行那些不需要和用戶交互而且還要長期運行的任務(一邊打電話,后臺掛著QQ)。服務的運行不依賴于任何用戶界面,即使程序被切換到后臺,或者用戶打開了另一個應用程序,服務仍然能夠保持正常運行,不過服務并不是運行在一個獨立的進程當中,而是依賴于創建服務時所在的應用程序進程。當某個應用程序進程被殺掉后,所有依賴于該進程的服務也會停止運行(正在聽音樂,然后把音樂程序退出)。
2、Activity生命周期?
生命周期即活動從開始到結束所經歷的各種狀態,從一個狀態到另一個狀態的轉變,從無到有再到無,Activity本質上有四種狀態:
-
運行(Active/Running):Activity處于活動狀態,此時Activity處于棧頂,是可見狀態,可以與用戶進行交互。
-
暫停(Paused):當Activity失去焦點時,或被一個新的非全面屏的Activity,或被一個透明的Activity放置在棧頂時,Activity就轉化為Paused狀態。此刻并不會被銷毀,只是失去了與用戶交互的能力,其所有的狀態信息及其成員變量都還在,只有在系統內存緊張的情況下,才有可能被系統回收掉。
-
停止(Stopped):當Activity被系統完全覆蓋時,被覆蓋的Activity就會進入Stopped狀態,此時已不在可見,但是資源還是沒有被收回。
-
系統回收(Killed):當Activity被系統回收掉,Activity就處于Killed狀態。
如果一個活動在處于停止或者暫停的狀態下,系統內存缺乏時會將其結束(finish)或者殺死(kill)。這種非正常情況下,系統在殺死或者結束之前會調用onSaveInstance()方法來保存信息,同時,當Activity被移動到前臺時,重新啟動該Activity并調用onRestoreInstance()方法加載保留的信息,以保持原有的狀態。
在上面的四中常有的狀態之間,還有著其他的生命周期來作為不同狀態之間的過渡,用于在不同的狀態之間進行轉換。
3、請介紹一下,Android SDK中自帶的幾個工具?
有如下幾個工具:
-
ddms:Dalvik Debug Monitor Service,是 Android 開發環境中的Dalvik[虛擬機]調試監控服務。
-
monkey:Android中的一個命令行工具,可以運行在模擬器里或實際設備中。它向系統發送偽隨機的用戶事件流(如按鍵輸入、觸摸屏輸入、手勢輸入等),實現對正在開發的應用程序進行壓力測試。
-
uiautomator:UIAutomator是Eclipse自帶的用于UI自動化測試工具,可仿真APP上的單擊、滑動、輸入文本等操作。
-
monitor:同uiautomator
-
adb:ADB的全稱為Android Debug Bridge,就是起到調試橋的作用。通過ADB我們可以在Eclipse中方面通過DDMS來調試Android程序,就是debug工具。
4、你所了解的APP測試工具?
APP自動化測試工具:
-
Appium
-
Airtest
-
uiautomator2(python)
APP穩定性測試工具:
-
Monkey
-
MonkeyRunner
-
Maxim
-
UICrawler
APP性能測試工具:
-
Perfdog
-
SoloPi
APP弱網測試&抓包工具:
-
Fiddler
-
Charles
APP兼容性測試工具:
-
TestIn
-
騰訊優測
-
百度MTC
-
阿里MQC
APP安全測試工具:
-
OWASP ZAP
-
Drozer
-
MobSF
-
QARK
5、介紹一下冷啟動、暖啟動、熱啟動、首屏啟動?
APP啟動會發生多個事件,測試人員需要知道整個環節是否出現問題,需要了解到具體是哪個環節存在問題:
-
冷啟動:當進程不存在的時候,從進程創建開始到界面的展示的過程;
-
暖啟動:有一部分資源已經存在,進程存在,相對于熱啟動要消耗更多資源。當用戶退出應用程序時,進程還會存在,暖啟動相較于冷啟動只是少了進程的創建;
-
熱啟動:大部分資源都在,只是應用之間的切換;
-
首屏啟動:第一屏加載完整;
標準:
-
冷啟動:需要5秒甚至更長;
-
暖啟動:需要2秒甚至更長;
-
熱啟動:需要1.5秒甚至更長;
整個啟動過程可以用adb工具進行分析,利用adb logcat獲取啟動數據,或者錄屏,使用ffmpeg拆幀分析。
adb logcat
首先定義一個變量,這個變量填寫用到的包名。
package=com.xueqiu.android
清除緩存數據:
adb shell pm clear $package
停止進程:
adb shell am force-stop $package
通過以上命令就做好了冷啟動的環境,下面啟動app并獲取數據。啟動App
adb shell am start -S -W $package/.view.WelcomeActivityAlias
-S表示啟動之前先停止應用進程
-W是表示等待對應的activity啟動完成
獲取數據:
bash adb logcat |grep -i displayed
獲取的時間如下:

6、談談對冷啟動的理解?
應用的啟動可以分為冷啟動,熱啟動和溫啟動,而啟動最慢、耗時最長的就是冷啟動。
冷啟動開始時,系統會依次執行三個任務去啟動APP:
-
加載和啟動應用程序;
-
APP啟動后,立即創建一個空白的啟動Window;
-
創建APP的進程;
在這三個任務執行后,系統創建了應用進程,那么應用進程接下來會執行下一步:
-
創建APP對象;
-
開啟一個主線程;
-
創建啟動頁的Activity;
-
加載View;
-
布局view到屏幕;
-
進行初始繪制顯示視圖;
當應用進程完成初始繪制之后,系統進程用啟動頁的Activity來替換當前顯示的空白Window,這個時刻用戶就可以使用App了。
四、接口測試常見面試題
1、請描述下HTTP接口?
了解HTTP接口首先需要知道HTTP是什么。
HTTP的全稱為:HyperText Transfer Protocol,即超文本傳輸協議 。百度百科中對HTTP協議的解釋是http是一個簡單的請求-響應協議,通常運行在TCP之上。它指定了客戶端可能發送給服務器什么樣的消息及會得到什么樣的響應。請求和響應消息的頭以ASCII碼形式給出;而消息內容則具有一個類似MIME的格式。
所以HTTP是工作于 客戶端/服務端架構之上的。通常情況下,常用的web服務器有Apache服務器、 IIS服務器等等。?
OSI模型中的七層結構見下圖,而HTTP是屬于應用層,定義應用程序的功能 。
用戶通過URL向HTTP服務端發送請求,HTTP服務器經過一系列的算法處理請求后再把相應的結果返回給用戶(即瀏覽器)。

2、GET接口與 POST接口分別有什么特點,有什么區別?
GET接口是從指定的資源中獲取數據的,參數通過URL發送
POST是把需要處理的數據提交到指定的資源 POST的參數不能通過URL發送,只能從請求的的消息主體中發送。
3、HTTP1.1版本中有哪些請求方法?
1.0版本中有三種方法即GET POST HEAD。?
http1.1版本中新增了OPTIONS DELETE PUT CONNECT TRACE5種請求方法.
4、HTTP響應消息由哪些部分組成?
響應消息包括狀態行,消息報頭和響應正文
5、HTTP某個狀態碼的含義(如:304代表什么)或是XX狀態碼頭的含義
1xx表示請求已接收 ,繼續處理
2xx 請求成功接收
3xx 重定向 ,需要進一步操作
4xx 請求錯誤 ,屬于客戶端錯誤
5xx 請求合法,但服務器無法處理,屬于服務端錯誤?
常見的狀態碼見下圖:

6、你怎么理解RPC接口,有什么作用?
RPC 的全稱為:Remote Procedure Call Protocol即遠程過程調用協議。
RPC通過網絡從遠程的服務器上請求服務無需了解底層技術協議 。RPC采用的是客戶端/服務端模式,RPC的作用是開發方便、直接,安全性高,特別是在一些大型項目中,內部的子系統及接口比較多的情況下,采用網絡分布式的多個APP開發更加容易 。
7、RPC的工作流程是怎樣的?
下圖為RPC的工作流程:

8、請描述下RPC的各個核心部件
Remoting 網絡通信框架 實現了消息機制 RPC遠程過程調用 ,支持集群,負載均衡? Registry服務目錄框架
9、接口測試的流程
接口測試流程也與公司要求、項目性質有所區別,可以適當增減節點。
閱讀接口文檔(接口文檔形式各個公司不同)
設計接口測試用例
準備測試環境、測試工具及測試數據
執行測試
提交缺陷報告,回歸測試
編寫測試報告
10、你之前使用過的接口測試工具有哪些
postman、jmeter、RESTClient、loadrunner、SoapUI等
本人常用的有postman、jmeter
postman使用操作非常簡單,支持測試case的管理 ,文件上傳、響應驗證以及環境參數管理還可以批量運行
jmeter是一款免費開源的輕量工具,可以用來做簡單的壓力測試,也可以自己寫接口腳本驗證。
11、調用HTTP接口時如何獲取到HTTPClient庫?
使用maven管理的話可以加入GroupId及 ArtifactID均為 commons-httpclient的依賴即可。
12、你之前怎么做RPC接口測試,有哪些準備工作?
接口調用客戶端依賴包 配置接口遠程服務端的Consumer Provider 編寫RPC接口測試腳本。
13、說說HTTP單接口測試與 RPC接口測試的特點
RPC接口編寫測試腳本時是需要導入JAR包,并且配置好Consumer。Http單接口測試是提交數據的方式 ,常用的提交數據方式有application/x-www-form-urlencoded ?? multipart/form-data
14、針對你之前做的項目中簡單描述下日志工具是怎么配置的
以maven為例,首先,需要引入Log4j,在CLASSPATH目錄下建立一個文件log4j.properties,然后使用API輸出日志

15、GIT代碼版本控制工具的常用命令
第一次從Git下載新代碼:git clone xx.git “下載目錄”
從遠程倉庫克隆:git clone “url”
添加目錄:git ?add ?“要添加的目錄”
提交:commit
查看所有的本地分支:git branch
查看所有的遠程分支:git branch -r
新建分支:git branch 新建分支名稱
切換分支:git checkout ?切換分支名稱
合并分支:git merge 要合并的分支
查看git狀態:git status
查看當前文件與上次時的區別:git diff 文件名
查看提交日志:git log
回退到上一個版本:git reset
刪除版本庫的文件:git rm 文件名
16、簡要說明JUnit的測試框架
JUnit是用Java語言編寫的單元測試框架,使用JUnit進行測試前需要先繼承TestCase類。應用比較多的領域有重構和極限編程。
17、TestNG常用的annotation關鍵字的含義
@Test 標記一個類或方法?
@BeforeSuite被@BeforeSuite注解的方法,會在所有測試運行之前運行。
@AfterSuite被@AfterSuite注解的方法,會在所有測試運行之后運行。
@BeforeTest被@BeforeTest注解的方法,在測試執行之前運行。
@AfterTest被@AfterTest注解的方法,在測試執行之后運行。
@BeforeClass被@BeforeClass注解的方法會在當前類的第1個測試方法運行前運行。
@AfterClass被@AfterClass注解的方法會在當前類的第1個測試方法調用后運行。
@BeforeMethod被@BeforeMethod注解的方法,會在每個測試方法調用之前運行。
@AfterMethod被@AfterMethod注解的方法會在每個測試方法調用后運行。
18、TestNG常用的斷言方法
assertTrue判斷是否為True
assertFalse判斷是否為false
assertNull判斷是否為null
assertNotNull判斷是否不為null
assertSame判斷引用地址是否相同
assertNotSame判斷引用地址是否不同
19、TestNG多線程測試時的annotation如何使用
invocationCount \threadPoolSize
20、TestNG怎么導出測試報告?
TestNG自帶了導出測試報告的功能 ,但可讀性較差,可以用maven下載ReportNG的依賴并在pom.xml中進行配置。也可以使用插件。
五、自動化測試面試真題
(1)編程語法題
1 、 python 有哪些數據類型
-
python 數據類型有很多,基本數據類型有整型(數字)、字符串、元組、列表、字典和布爾類型等
2 、怎么將兩個字典合并
-
調用字典的 update 方法,合并 2 個字典。
3 、 json.l python 如何將 json 寫到文件里?
-
loads() 是將字符串轉化為字典
-
json.load()是將文件打開從字符串轉換成數據類型
-
json.dumps () 是將字典轉化為字符串
-
json.dump()是將數據類型轉換成字符串并存儲在文件中
4 、 __init__ 和 __new__ 區別?
-
__new__是在實例創建之前被調用的,因為它的任務就是創建實例然后返回該
實例對象,是個靜態方法。
-
__init__是當實例對象創建完成后被調用的,然后設置對象屬性的一些初始值,通常用在初始化一個類實例的時候。是一個實例方法。
5 、什么是可變、不可變類型?
-
可變數據類型:列表 list 和字典 dict;
-
不可變數據類型:整型 int、浮點型 float、字符串型 string 和元組 tuple
6 、 mysql 注入點,用工具對目標站直接寫入一句話,需要哪些條件?
mysql?寫入一句話需要具備
-
1.secure-file-priv='',即:my.ini 文件,打開找到 secure-file-priv 參數改空
-
2.當前用戶具備 root 權限
-
3.已獲取到應用程序的絕對路徑,且目錄可以進行文件寫入操作。?
7 、 python 深淺拷貝的區別
-
對于不可變數據來說深淺拷貝的結果一致會重新創一個數據的副本。淺拷貝對于
可變類型來說只會拷貝其元素的引用。
-
深拷貝對于可變元素來說會遞歸的整個重新創建一個原數據的副本。
8 、 python 為什么使用 *args 和 **kwargs
如果我們不確定要往函數中傳入多少個參數,或者我們想往函數中以列表和元組
的形式傳參數時,那就使用*args;如果我們不知道要往函數中傳入多少個關
鍵詞參數,或者想傳入字典的值作為關鍵詞參數時,那就要使用**kwargs。args
和 kwargs 這兩個標識符是約定俗成的用法,你當然還可以用*bob 和**billy,
但是這樣就不太專業。
9 、重寫和重載有什么區別?
-
重寫:用在類的繼承當中。子類對父類的同名方法,進行重寫。在子類同名方法
內部,如果要延用父類的方法,可以使用 super 調用。
-
重載:用在類當中,對于同一個方法名,支持不同類型的參數,支持不同數量的
-
參數。由于 python 的函數本身就對參數不作類型限定,也有*args 和**kwargs
支持不定長度參數。
10 、 python 實現 get 數據庫的表?你是怎么實現的?
python 當中對于不同數據庫,都有不同的第三庫來實現連接和數據庫操作。
比較熟悉的是對 mysql 的操作。使用的是 pymysql 這個第三方庫。第一步是建立
數 據 庫 連 接 ;第 二 步 調 用 execute 方 法 執 行 sql 語 句 , 第 三 步 使 用
fetchone,fetchall,fetchmany 去獲取不同條數的結果。
11 、對象 ( 實例 ) 方法,類方法,靜態方法的定義有何不同?分別適用于什么場
景?
-
python 中,類中定義的普通函數就是對象方法,對象方法中的第一個形參一般
會定義為`self`,表示調用的對象本身,當對象調用對象方法時會被隱式的傳遞
給這個形參。所以當函數需要用到對象或對象的屬性時一般會將其定義為對象方
法。
-
類方法定義時,需要使用裝飾器`classmethod`進行裝飾,類方法中的第一個形
參一般會定義為`cls`,表示類本身。當對象調用或類調用類方法時,類會被隱
式的傳遞給這個形參。所以當函數需要用到類或者類的屬性時一般會將其定義為
類方法。
-
靜態方法定義時,需要使用裝飾器`staticmethod`進行裝飾,其他與普通函數沒
有區別。一般會將一些與對象和類無關的工具函數定義為靜態方法,方便調用。
12 、 SQL 連表查詢,去重查詢,查詢重復的數據?
兩表查詢:SELECT 字段 1,字段 2,字段 3,…… FROM 表名 1 INNER JOIN 表名 2ON 關聯條件;去重查詢:SELECT distinct ...;查詢重復的數據:select 列名 from 表名 group by 列名 having count(列名) > 1;
AI寫代碼AI寫代碼AI寫代碼AI寫代碼
13 、 python 的單例模式?
-
單例模式是:確保類有且只有一個對象被創建為唯一對象提供訪問點,令其可被全局訪問控制共享資源的并行訪問
-
具體實現方式可以通過模塊導入、裝飾器、控制 __new__方法 等等。
14 、什么是 PEP 8 ?
-
EP 8 代表 Python Enhancement Proposal,它可以定義為幫助我們提供有關如何編寫 Python 代碼的指南的文檔。它基本上是一組規則,指定如何格式化
-
Python 代碼獲得最大的可讀性。它由?Guido van Rossum、Barry Warsaw 和Nick Coghlan 于 2001 年編寫
15 、 PO 模式的封裝原則有哪一些?
公共方法表示頁面提供的服務。比如把登錄封裝成 login 方法,搜索操作封裝成?search 方法,注冊操作封裝成 register 方法。
-
盡量不要暴露頁面的內部,比如頁面的 HTML, 頁面的上下結構
-
一般不做斷言,做到頁面邏輯和測試邏輯的分離。
-
方法返回 self 或者其他 PageObjects,也可以是元素屬性等。
-
不需要封裝整個頁面行為,用到什么邏輯封裝什么邏輯
-
同一操作如果出現不同結果,可以用不同的方法表示。比如登錄成功有跳轉,登錄失敗報錯,登錄未授權,?
(2)編碼題
1 、冪的遞歸,計算 x 的 n 次方,如:3 的 4 次方 為 3*3*3*3=81
# 遞歸的方式def mi(x, n):if n == 0:return 1else:return x*mi(x, n-1)print(mi(3, 4))非遞歸的方式:def mix(x,n):result = 1for count in range(n):result *= xreturn resultprint(mi(3,4))
AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼
2 、統計列表(list )中每個元素出現的次數
# 統計列表(list)中每個元素出現的次數lista = [1, 2, 3, 4, 12, 22, 15, 44, 3, 4, 4, 4, 7, 7, 44, 77, 100]new_dict = {}for item in lista:if item not in new_dict.keys():new_dict[item] = lista.count(item)print(new_dict)
AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼
3 、 ['abc13','abv89'] 這種列表,打印最大長度的共同的前綴,列表元素個數不確定
def test_str(iterable):return_str=''for i in zip(*iterable):if len(set(i))==1:return_str +=i[0]else:breakprint(return_str)return return_str
AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼
4 、對 list 去重并找出列表 list 中的重復元素
from collections import Counter #引入 Countera = [1, 2, 3, 3, 4, 4]b = dict(Counter(a))print(b)print ([key for key,value in b.items() if value > 1]) #只展示重復元素print ({key:value for key,value in b.items() if value > 1}) #展現重復元素和重復次數
AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼
5 、已知一個隊列 [1, 3, 6, 9, 7, 3, 4, 6]
1. 按從小到大排序
2. 按從大大小排序
3. 去除重復數字
a = [1, 3, 6, 9, 7, 3, 4, 6]# 1.sort 排序,正序a.sort()print(a)#?2.sort?倒序a.sort(reverse=True)print(a)# 3.去重b = list(set(a))print(b)
AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼
6 、任選語言完成雙向冒泡排序算法程序([8,6,4,3,9,1,2,5,7] 升序)
def cocktail_sort(arr):n = len(arr)start = 0end = n - 1swapped = Truewhile swapped:# 正向冒泡,找到最大元素放到后面swapped = Falsefor i in range(start, end):if arr[i] > arr[i + 1]:arr[i], arr[i + 1] = arr[i + 1], arr[i]swapped = True# 如果沒有元素進行交換,則排序完成if not swapped:break# 在反向冒泡之前,重新標記 swapped 為 Falseswapped = Falseend -= 1# 反向冒泡,找到最小元素放到前面for i in range(end - 1, start - 1, -1):if arr[i] > arr[i + 1]:arr[i], arr[i + 1] = arr[i + 1], arr[i]swapped = Truestart += 1return arr# 測試排序算法arr = [8, 6, 4, 3, 9, 1, 2, 5, 7]sorted_arr = cocktail_sort(arr)print(sorted_arr)
AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼
(3)自動化基礎能力評估
1 、 python 列表和字典的區別,列表和元組的區別?
-
列表是有序的,字典是無序的。列表通過索引獲取、字典通過 key 獲取。
-
列表是可變的,可以修改、添加、刪除其中的元素,但是元組是不可變的,不能修改、添加、刪除其中的元素。
-
對于一個元素的元組,必須要在元素后加逗號,而列表不需要。
2 、 Python 用到的庫
-
-
單元測試框架:unittest pytest
-
操作 mysql 數據庫:pymysql
-
http 請求庫:requests
-
web 自動化:selenium
-
處理日志:logging
-
json 數據提取和 json 文件讀寫:json,jsonpath
-
pyyaml:yaml 文件讀寫
-
3 、 unittest 和 pytest 區別?
-
-
pytest 是第三方庫,基于 unittest 的擴展框架,比 unittest 更簡潔,高效
-
pytest 有豐富的插件系統
-
pytest 的夾具使用更加靈活
-
pytest 可以很方便的過濾用例
-
4 、 python 當中如何操作數據庫 ?
-
-
python 不同的數據庫,都有對應的第三方庫。比如 mysql 數據庫有 pymysql庫,oracle?數據庫有 cx_Oracle
-
安裝成功第三方庫后,代碼中將包導進來 ·接下來就是連接數據庫,提供數據庫的服務器地址、端口號、訪問的用戶名和密碼、數據庫名稱,通過調用對應的方法去連接
-
連接成功之后,調用執行 sql 語句的方法去操作數據庫
-
操作完成之后,釋放數據庫連接
-
5 、 jmeter 或 postman 實現多接口關聯測試 ? 怎么做關聯 ?
6 、接口自動化的斷言怎么做
7 、如果需要用自動化測刪除接口,斷言怎么做
8 、做自動化的過程中如何處理驗證碼
-
-
讓開發屏蔽驗證碼,邀請開發處理,在測試環境,預發和正式環境恢復
-
讓開發設置一個萬能驗證碼,使用復雜的其他人無法猜到的驗證碼
-
基于圖像識別,破解驗證碼
-
9 、自動化測試用例如何編寫
自動化測試本質是測試,是用自動化手段,替代部分手工測試。
-
自動化測試用例,源自功能測試用例,都應包含前置/后置,步驟,斷言。
-
自動化用例設計原則,與功能用例一致。
-
自動化用例需要自行解決:環境依賴問題。比如手工測試時,遇到前置條件不滿足,手工去準備前置條件再測試。
-
自動化用例斷言要明確:將手工測試看到的期望效果,轉成代碼。
-
自動化用例需要考慮重復執行不受影響。
考慮好以上 5 點,使用工具或者代碼的測試框架編寫即可。
10 、 pytest 的前置實現有哪幾種方式?
11 、 Appium 都有哪些啟動方式
12 、 web ui 自動化中顯式等待、隱式等待有什么區別
相同點:都是智能等待,在一定時間范圍內不斷查找元素,一旦找到立刻執行后續代碼,沒找到就會一直查找到超時為止
不同點:
-
顯式等待:顯示等待是單獨針對某個元素,設置一個等待時間,設置一個查詢間隔時間,在等待時間內會按照設置的間隔時間對該元素進行查找,超過設置的等待時間尚未出現則拋異常;顯示等待必須在每個需要等待的元素前面進行聲明
-
隱式等待:隱式等待是全局的是針對所有元素,設置一個等待時間,在設置的等待時間內,程序會不停檢測頁面元素是否全部加載完成,加載完成則繼續向下,超過設置的等待時間尚未出現則拋異常;隱式等待只需要聲明一次,聲明之后對整個 drvier 的生命周期都有效不用重復聲明;程序會一直等待整個頁面加載完成
13、 有沒有遇到元素定位不到情況?如何處理的?
-
-
頁面加載元素過慢,添加等待時間
-
頁面有 frame 框架頁,需要先跳轉入 frame 框架再定位
-
可能該元素是動態元素,定位方式要優化,可以使用部分元素定位或通過父節點或兄弟節點定位。
-
可能識別了元素,但是不能操作,比如元素不可用,不可寫等。需要使用js 先把前置的操作完成,
-
元素定位的表達式寫錯了。
-
14 、請盡可能多的列出自動化的元素定位方式,以及你最喜歡的定位方式?
web 自動化的定位方式:
1、通過 id:find_element_by_id2、通過 name 屬性:find_element_by_name3、通過 class 屬性:find_element_by_name4、通過標簽名:find_element_by_tag_name5、通過文本定位鏈接標簽:find_element_by_link_text6、通過文本部分匹配,定位鏈接標簽:find_element_by_partial_link_text7、通過 xpath 定位:find_element_by_xpath8、css 選擇器定位:find_element_by_css_selector最常用的:id,xpath 和 css 這三種
AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼AI寫代碼
15 、如果同一個瀏覽器打開兩個窗口,要用 selenium 里面哪個指令進行切換?
1、窗口切換??2、iframe?切換?3、alert?切換AI寫代碼
16 、 App 自動化有做過嗎?知道用到哪些技術框架嗎?
-
-
做過,app 自動化主要使用的開源框架 appium,結合測試框架 pytest,還有 PO設計思想,共同搭建了 app 自動化測試框架。
-
17 、 ui 自動化出現的異常,以及出現這些異常后你是如何處理的?
-
-
元素定位失敗異常,處理方式為檢查元素定位表達式,添加等待;
-
定位超時異常,檢查定位方式,檢查是否有 iframe ;
-
元素無法交互,檢查是否定位到正確元素。
-
18 、什么是 PO 模式,什么是 page factory ?
-
PO 模式是 page object model 的縮寫,顧名思義, 是一種設計模式,把每個頁面當成一個頁面對象,頁面層寫定位元素方法和頁面操作方法,實現腳本的page 和真實的網站頁面 Map 起來,一對應起來PO 模式業務代碼和測試代碼被分開,降低耦合性維護成本低,減少代碼冗余?
19?、簡述 selenium 的原理
selenium 涉及到三個組件的通訊,分別是
-
-
瀏覽器
-
webdriver
-
client
-
client 負責通過對應的編程語言函數發送請求給 webdriver
client 其實并不知道瀏覽器是怎么工作的,但是 driver 知道,在 selenium 啟動以后,driver 其實充當了服務器的角色,跟 client 和瀏覽器通信,client根據 webdriver 協議發送請求給 driver,driver 解析請求,并在瀏覽器上執行相應的操作,并把執行結果返回給 client。這就是 selenium 工作的大致原理。
20?、 UI 自動化測試用例在運行過程中經常會出現不穩定的情況,也就是說這次可以通過,下次就沒有辦法通過了,如何去提升用例的穩定性?
-
1. 界面上無法預測的彈框。頁面上經常會根據用戶行為推送或者彈出動態的信息,比如版本更新,消息通知,推薦產品等等,當這些彈框出現以后,原來的頁面元素會被遮擋,無法被定位,此時可能會造成自動化測試腳本運行錯誤。
-
2. 頁面元素的動態變化;主要有兩方面的變化,第一方面,前端需求經常發生變化導致前端代碼頻繁修改,當前端頁面變化以后可能會造成之前的元素無法被定位;第二方面,頁面可能會根據用戶的狀態和等級展示不同的頁面,或者是這一次訪問的數據和下一次會不同。
-
3. 隨機的頁面延遲造成控件識別失敗;受限于網絡環境和設備狀態,自動化代碼每次運行時可能會產生隨機的超時處理。
-
4. 測試數據變更。ui 測試每個用例的測試步驟會有很大的區別,他們不能共享同一套代碼邏輯,當測試數據變更時,如果不能及時更新自動化代碼,會造成腳本執行出錯等問題。
(4)自動化項目實戰能力評估
1 、介紹一下你的自動化測試框架?
我的框架主要根據分層思想設計了幾個獨立模塊:
-
模塊一:主要存放通用業務代碼,比如接口訪問,數據庫操作,excel 操作,等
-
模塊二:主要負責用例收集和用例執行,生成測試報告。
-
模塊三:主要負責存放測試用例數據。通常是使用 excel, yaml, 等通用數據格式。
-
模塊四:主要存放測試用例方法和測試邏輯相關代碼。這里會調用模塊的通用方法。
2 、講一下在工作中怎么做的自動化測試?
-
-
a. 根據自動化測試特性整理需求
-
b. 根據優先級,和公司人員狀況制定自動化測試計劃
-
c. 制定自動化測試執行方案
-
d. 自動化測試用例設計或從功能測試用例中挑選適合的用例
-
e. 自動化腳本的開發
-
f. 自動化測試執行,生成報告
-
3 、自動化測試框架至少包含哪些核心模塊。
-
-
基礎方法
-
數據驅動
-
PO 分層
-
接口分層
-
接口數據管理
-
異常處理 - 工具包
-
配置
-
日志收集
-
測試報告
-
4 、框架中的接口參數傳遞怎么做的?是否有優化,第三庫有沒有用到,方法是什么?
-
框架當中接口參數傳遞主要涉及 2 部分:一是數據生成或者提取,二是替換。在框架當中,數據從響應結果提取用的 jsonpath,提取表達式直接寫在 excel 當中,提取之后存儲到變量類 Data 當中,作為它的類屬性。
-
替換時,則直接訪問 Data 類的類屬性,將其值拿到并替換。在 excel 中要替換的標志為#value#。因為會存在有多個要替換的值,所以用正則表達式來查找到所有要替換的標識,然后全部替換。
-
用到第三方庫的話,一個是 jsonpath,一個是 re
5 、拿到一個項目,怎么衡量這個項目做接口自動化還是 UI 自動化?
1、不管什么項目都可以做接口自動化
2、偏公司內部人員使用的管理平臺無需做 UI 自動化,對外用戶的可以考慮做
UI 自動化
6?、框架的數據庫驗證在你 excel 中 check_sql 放的是什么,你如何做比對?
-
check_sql 中存放的是一個列表,列表的成員是字典,字典有 3 個 key,一個是sql 語句,第二個是期望結果,第三個是 sql 的查詢方式(查詢總條數/查詢值)在收到響應結果以后,會遍歷 check_sql 中的列表,將每一個字典取出來,執行sql 語句查詢結果 ,并與期望結果做比較。
7 、自動化測試中,測試用例的執行是怎么讓他按照你寫的用例一條一條執行的?
在我的項目接口自動化中,我用?pytest 框架。
一個接口的用例,我的用例數據是寫在 excel 當中,在編寫時就是按照順序寫的,從 excel 讀取出來使用數據驅動 方式就是按照 excel 中的順序;
多個接口的用例,因為我是一個接口一個 py 測試文件,所以我在 py 測試文件命名中用 00-99 數字按順序編寫的。
8、Login 這些用例數據是在哪里取的?excel 嗎?用到什么方法?什么第三方庫?
具體公司的業務:業務怎么開展 項目的介紹?( 或者簡單介紹最熟悉的項目介紹:)
主要考察 2 個方面:一是表達能力和業務的熟悉度。二是做的項目復雜度如何,是否能勝任復雜項目的測試工作。
一般是根據自己的業務來回答。最好是能講出有挑戰性有難度或者復雜的業務場景。面試官不一定聽得懂,但是他覺得復雜挺難的就可以。
最后感謝每一個認真閱讀我文章的人,禮尚往來總是要有的,雖然不是什么很值錢的東西,如果你用得到的話可以直接拿走:

這些資料,對于做【軟件測試】的朋友來說應該是最全面最完整的備戰倉庫,這個倉庫也陪伴我走過了最艱難的路程,希望也能幫助到你!凡事要趁早,特別是技術行業,一定要提升技術功底。

)
------ 圖像腐蝕and圖像膨脹)


:一文詳解three.js中的著色器Shader)



:結構化編程)
)









