Scaled Dot-Product Attention是Transformer架構的核心組件,也是現代深度學習中最重要的注意力機制之一。本文將從原理、實現和應用三個方面深入剖析這一機制。
1. 基本原理
Scaled Dot-Product Attention的本質是一種加權求和機制,通過計算查詢(Query)與鍵(Key)的相似度來確定對值(Value)的關注程度。其數學表達式為:
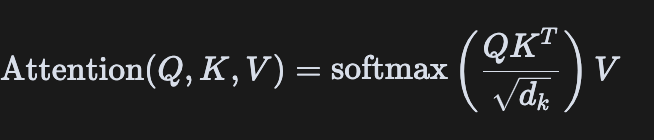
這個公式包含幾個關鍵步驟:
- 計算相似度:通過點積(dot product)計算Query和Key的相似度,得到注意力分數(attention scores)
- 縮放(Scaling):將點積結果除以 d k \sqrt{d_k} dk??進行縮放,其中 d k d_k dk?是Key的維度
- 應用Mask(可選):在某些情況下(如自回歸生成)需要遮蓋未來信息
- Softmax歸一化:將注意力分數通過softmax轉換為概率分布
- 加權求和:用這些概率對Value進行加權求和
2. 為什么需要縮放(Scaling)?
縮放是Scaled Dot-Product Attention區別于普通Dot-Product Attention的關鍵。當輸入的維度 d k d_k dk?較大時,點積的方差也會變大,導致softmax函數梯度變得極小(梯度消失問題)。通過除以 d k \sqrt{d_k} dk??,可以將方差控制在合理范圍內。
假設Query和Key的各個分量是均值為0、方差為1的獨立隨機變量,則它們點積的方差為 d k d_k dk?。通過除以 d k \sqrt{d_k} dk??,可以將方差歸一化為1。
3. 代碼實現解析
讓我們看看PyTorch中Scaled Dot-Product Attention的典型實現:
def scaled_dot_product_attention(query, key, value, mask=None, dropout=None):# 獲取key的維度d_k = query.size(-1)# 計算注意力分數并縮放scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)# 應用mask(如果提供)if mask is not None:scores = scores.masked_fill(mask == 0, float('-inf'))# 應用softmax得到注意力權重attn = F.softmax(scores, dim=-1)# 應用dropout(如果提供)if dropout is not None:attn = dropout(attn)# 加權求和return torch.matmul(attn, value), attn
這個函數接受query、key、value三個張量作為輸入,可選的mask用于遮蓋某些位置,dropout用于正則化。
4. 張量維度分析
假設輸入的形狀為:
- Query: [batch_size, seq_len_q, d_k]
- Key: [batch_size, seq_len_k, d_k]
- Value: [batch_size, seq_len_k, d_v]
計算過程中各步驟的維度變化:
- Key轉置后: [batch_size, d_k, seq_len_k]
- Query與Key的點積: [batch_size, seq_len_q, seq_len_k]
- Softmax后的注意力權重: [batch_size, seq_len_q, seq_len_k]
- 最終輸出: [batch_size, seq_len_q, d_v]
5. 在Multi-Head Attention中的應用
Scaled Dot-Product Attention是Multi-Head Attention的基礎。在Multi-Head Attention中,我們將輸入投影到多個子空間,在每個子空間獨立計算注意力,然后將結果合并:
class MultiHeadAttention(nn.Module):def __init__(self, h, d_model, dropout=0.1):super().__init__()assert d_model % h == 0self.d_k = d_model // hself.h = hself.linears = clones(nn.Linear(d_model, d_model), 4)self.attn = Noneself.dropout = nn.Dropout(dropout)def forward(self, query, key, value, mask=None):if mask is not None:mask = mask.unsqueeze(1)nbatches = query.size(0)# 1) 投影并分割成多頭query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)for l, x in zip(self.linears, (query, key, value))]# 2) 應用注意力機制x, self.attn = scaled_dot_product_attention(query, key, value, mask, self.dropout)# 3) 合并多頭結果x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)return self.linears[-1](x)
6. 實際應用場景
Scaled Dot-Product Attention在多種場景下表現出色:
- 自然語言處理:捕捉句子中詞與詞之間的依賴關系
- 計算機視覺:關注圖像中的重要區域
- 推薦系統:建模用戶與物品之間的交互
- 語音處理:捕捉音頻信號中的時序依賴
7. 優勢與局限性
優勢:
- 計算效率高(可以通過矩陣乘法并行計算)
- 能夠捕捉長距離依賴關系
- 模型可解釋性強(可以可視化注意力權重)
局限性:
- 計算復雜度為O(n2),對于長序列計算開銷大
- 沒有考慮位置信息(需要額外的位置編碼)
- 對于某些任務,可能需要結合CNN等結構以捕捉局部特征
8. 總結
Scaled Dot-Product Attention是現代深度學習中的關鍵創新,通過簡單而優雅的設計實現了強大的表達能力。它不僅是Transformer架構的核心,也啟發了眾多后續工作,如Performer、Linformer等對注意力機制的改進。理解這一機制對于掌握現代深度學習模型至關重要。
通過縮放點積、應用softmax和加權求和這三個簡單步驟,Scaled Dot-Product Attention成功地讓模型"關注"輸入中的重要部分,這也是它能在各種任務中取得卓越表現的關鍵所在。
##9、Scaled Dot-Product Attention應用案例
敬請關注下一篇







)



--多點觸控)
)



)
21/6=3.5)
)
)