目錄
回溯法理論基礎
回溯法
回溯法的效率
用回溯法解決的問題
如何理解回溯法
回溯法模板
LeetCode 77. 組合
回溯算法的剪枝操作
LeetCode 216.組合總和III
LeetCode 17.電話號碼的字母組合
回溯法理論基礎
回溯法
回溯法也可以叫做回溯搜索法,它是一種搜索的方式。回溯一般與遞歸相輔相成,并在遞歸后進行使用。回溯法是一種暴力搜索方法,你可以想象你現在在走迷宮,當你走到一個死路后,是否需要回退,而回退的這個過程就是回溯。
回溯法的效率
正如上面所說,回溯法是暴力搜索方法,其本質是窮舉,窮舉所有可能,然后選出我們想要的答案。如果想讓回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是窮舉的本質。
用回溯法解決的問題
那么既然回溯法并不高效為什么還要用它呢? 因為沒得選,一些問題能暴力搜出來就不錯了,撐死了再剪枝一下,還沒有更高效的解法。
那什么問題適合用回溯法進行解決?
- 組合問題:N個數里面按一定規則找出k個數的集合
- 切割問題:一個字符串按一定規則有幾種切割方式
- 子集問題:一個N個數的集合里有多少符合條件的子集
- 排列問題:N個數按一定規則全排列,有幾種排列方式
- 棋盤問題:N皇后,解數獨等等
需要特別說明下組合和排列的問題,組合是沒有順序的,排列是有順序,比如一對男女朋友,這是一個組合,但你問到他們之間誰先表白,這就變成排列了。
如何理解回溯法
回溯法解決的問題都可以抽象為樹形結構。
因為回溯法解決的都是在集合中遞歸查找子集,集合的大小就構成了樹的寬度,遞歸的深度就構成了樹的深度。有遞歸,就必須要有終止條件,所以必然是一棵高度有限的樹(N叉樹)。
回溯法模板
回溯法也有模板,在將其模版前,復習下遞歸的模板。
- 終止條件
- 遞歸順序
- 輸入參數和輸出參數
回溯法模板。
1.回溯函數終止條件
既然回溯可以抽象為樹形結構,那么也像遞歸二叉樹那樣存在終止條件。什么時候達到了終止條件,樹中就可以看出,一般來說搜到葉子節點了,也就找到了滿足條件的一條答案,把這個答案存放起來,并結束本層遞歸。
回溯函數終止條件偽代碼如下:
if (終止條件) {存放結果;return;
}2.回溯搜索的遍歷過程
在上面我們提到了,回溯法一般是在集合中遞歸搜索,集合的大小構成了樹的寬度,遞歸的深度構成的樹的深度。
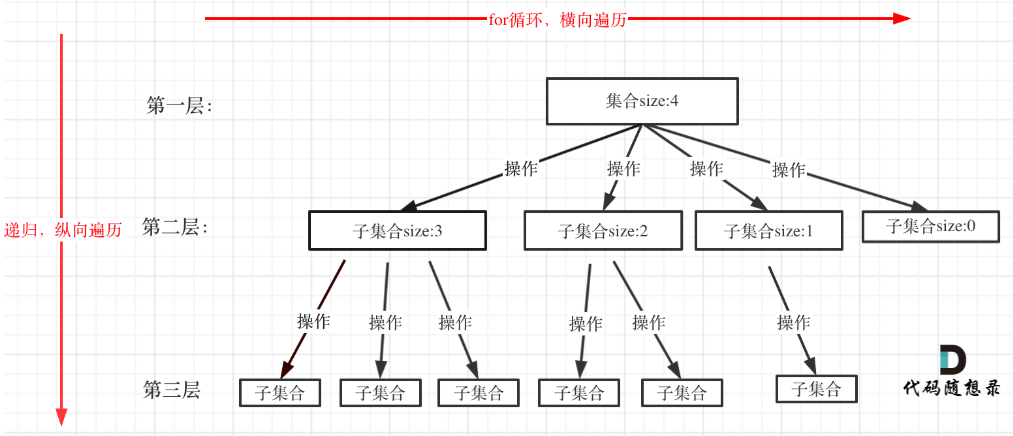
上圖是特意舉例集合大小和孩子的數量是相等的。size為4的集合有4個子集合。
回溯函數遍歷過程偽代碼如下:
for (選擇:本層集合中元素(樹中節點孩子的數量就是集合的大小)) {處理節點;backtracking(路徑,選擇列表); // 遞歸回溯,撤銷處理結果
}for循環就是遍歷集合區間,可以理解一個節點有多少個孩子,這個for循環就執行多少次。
backtracking這里自己調用自己,實現遞歸。
大家可以從圖中看出for循環可以理解是橫向遍歷,backtracking(遞歸)就是縱向遍歷,這樣就把這棵樹全遍歷完了,一般來說,搜索葉子節點就是找的其中一個結果了。
3.回溯函數模板返回值以及參數
回溯算法中函數返回值一般為void。
回溯算法需要的參數可不像二叉樹遞歸的時候那么容易一次性確定下來,所以一般是先寫邏輯,然后需要什么參數,就填什么參數。
回溯函數偽代碼如下:
void backtracking(參數)回溯算法模板框架如下:
void backtracking(參數) {if (終止條件) {存放結果;return;}for (選擇:本層集合中元素(樹中節點孩子的數量就是集合的大小)) {處理節點;backtracking(路徑,選擇列表); // 遞歸回溯,撤銷處理結果}
}涉及回溯算法的題都可以基于上述模板進行實現,回溯算法模板 +?題目特性?→?解決回溯算法問題
LeetCode 77. 組合
為什么要用回溯算法,你用兩個for循環也可以做到,第一個循環從左到右逐個遍歷,第二個從第一個循環的下標的下一個位置開始遍歷,這樣的話也可以做到,時間復雜度是O(),那如果是k越大呢?此時不就需要更多個循環了嗎,那此時時間復雜度就是
,顯然時間復雜度太高。
回溯方法的做法其實就是用遞歸來替代循環。
思路:
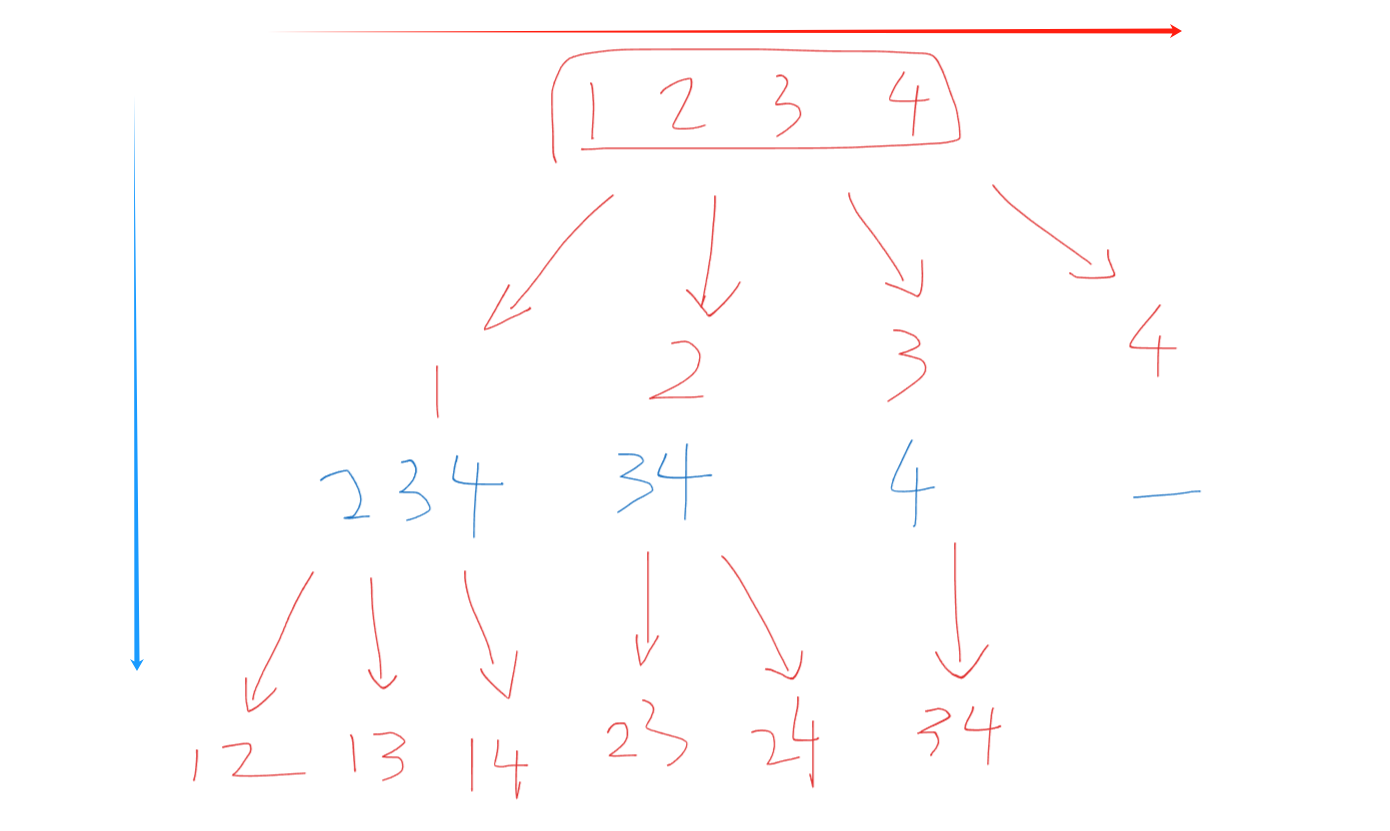
- 通過for循環橫向遍歷起始處理節點(紅箭頭)
- 通過遞歸深度遍歷可能出現的組合(藍箭頭)
- 遞歸后進行回溯
- 當組合長度 == k?時,為終止條件
手撕Code
class Solution(object):def combine(self, n, k):""":type n: int:type k: int:rtype: List[List[int]]"""self.result = [] ## 二維數組self.path = []self.backtracking(n, k, 1)return self.resultdef backtracking(self, n, k, start_index):"""n 記錄需要處理到的最大數字k 記錄需要輸出的數組數目start_index 記錄當前處理的數字, 遍歷范圍是1到n"""### 終止條件if len(self.path) == k:# self.result.append(self.path) ### 這里是將指針給append了,self.path的內容是一直在變的,如果你將指針append的話,上一輪的遞歸的結果并沒有進行保存,因為上一輪指向的數組已經變了。self.result.append(list(self.path))return### 遞歸邏輯for _ in range(start_index, n+1): ### 左閉右開self.path.append(start_index) ### 當前處理節點。處理同一層的邏輯self.backtracking(n, k, start_index + 1) ### 遞歸,往深度遍歷。self.path.pop() ### 遞歸后進行回溯start_index += 1 ### 處理完當前節點后,處理下一個節點易錯點:
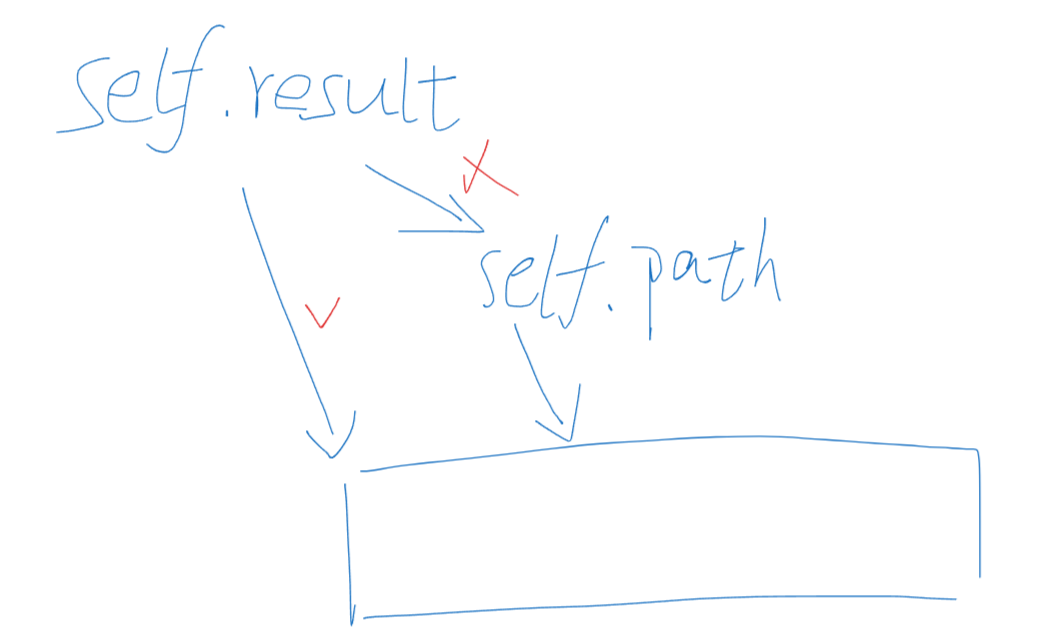
不能是self.result.append(self.path) ,這部分append只是當前self.path指針所指向的當前數組元素,如果self.path當前指向的數組是[1,3],上一輪self.result已經將[1,2]給存進去了,此時如果你要將[1,3]數組進行append,你應該append是這個數組,而不應該是這個指針,即你想要的結果是[ [1,2], [1,3] ],如果你是append這個指針的話,只會添加當前指針指向的數組,因為你存儲的其實是指向當前數組的指針,即[ self.path, self.path ],再進行下一輪的append操作后,其實你獲取的是[ [1,3], [1,3] ]。指針指向的是不斷在變的數組,如果你存指針的話,最終的self.result只會是存儲操作完畢后該指針下的元素,沒有記錄整個過程。
總結:當你在終止條件 if len(self.path) == k: 中執行 self.result.append(self.path) 時,你并沒有將 self.path 當前的內容復制一份,而是將 self.path 這個列表對象本身的引用添加到了 self.result 中。
回溯算法的剪枝操作
體現在for循環范圍的限制。如還是組合問題,現在k變了,變為4。
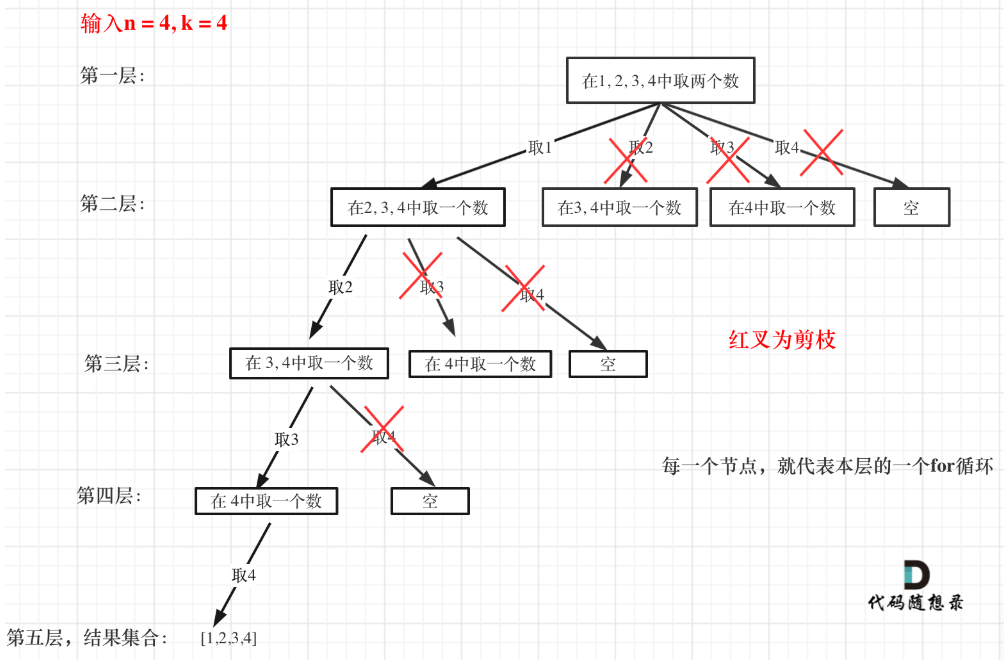
那么我們可以看到由于元素只有4個,因此只有從元素1開始的遍歷才能得到最終符合數目為k的組合,而其他子樹的遍歷是不需要的,因為肯定數目是不符合的。那如果k是3呢?是不是只有從1開始和從2開始進行遍歷才是有效的,且其子遍歷中,有些分支也可以進行去掉,從而減少遍歷的操作,這是與通過多個循環暴力搜索法相比所體現出的優勢。
那要如何優化以實現剪枝呢?其實答案就體現在for循環范圍的控制。優化過程如下:
i = start_index,表示處理節點的起始位置。
- 已經選擇的元素個數:path.size();
- 所需需要的元素個數為: k - path.size();
- 列表中剩余元素(n-i) >= 所需需要的元素個數(k - path.size())
- 在集合n中至多要從該起始位置 : i <= n - (k - path.size()) + 1,開始遍歷。
根據3得到的是 i <= n - (k - path.size()) ,為什么要+1?因為包括起始位置,我們要是一個左閉的集合。
這個優化條件 i <= n - (k - path.size()) + 1 實際上是在說: "當前的起始位置 i 必須小于或等于這樣一個值:從這個值開始,到最大的元素 n 結束,能夠恰好湊齊我們所需要的 k - path.size() 個元素,并且還考慮到起始位置 i 本身也算一個元素。"? ? ? ??
n-i 是?指包含起始位置之后的列表元素個數,當n-i = k -?path.size()時,此時有臨界條件,i = n - (k - path.size),這表示i為這個值時,當前元素+后續元素剛好是符合k -?path.size()的。但我們要的臨界條件是i到了什么值時,后續遍歷操作可以不用執行,因此要加1,1是表明i = n - (k - path.size)時,后序的元素可以進行遍歷,再往后的就不用了。
舉個例子,n = 4,k = 3, 目前已經選取的元素為0(path.size為0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。表示最大的符合條件在當第二個元素開始時。因此,從2開始。
class Solution(object):def combine(self, n, k):""":type n: int:type k: int:rtype: List[List[int]]"""self.result = [] ## 二維數組self.path = []self.backtracking(n, k, 1)return self.resultdef backtracking(self, n, k, start_index):"""n 記錄需要處理到的最大數字k 記錄需要輸出的數組數目start_index 記錄當前處理的數字, 遍歷范圍是1到n"""### 終止條件if len(self.path) == k:# self.result.append(self.path) ### 這里是將指針給append了,self.path的內容是一直在變的,如果你將指針append的話,上一輪的遞歸的結果并沒有進行保存,因為上一輪指向的數組已經變了。self.result.append(list(self.path))returnfor _ in range(start_index, (n -(k-len(self.path))+1) +1): ### 剪枝操作self.path.append(start_index) self.backtracking(n, k, start_index + 1) self.path.pop() start_index += 1 LeetCode 216.組合總和III
思路
- 與LeetCode組合類似,只不過這里是求和,判斷是否有滿足數目的path == sum
- 思路基本一致,注意循環中不要忘了對start_index進行修改。
手撕Code
class Solution(object):def combinationSum3(self, k, n):""":type k: int:type n: int:rtype: List[List[int]]"""self.result = []self.path = []self.nums = []for i in range(1,10):self.nums.append(i) ### 創建一個數組用于存儲用于遍歷的數字self.backtracking(0, k, n)return self.resultdef backtracking(self, start_index, k, n):if len(self.path) == k:sum = 0for i in range(len(self.path)):sum += self.path[i]if sum == n:self.result.append(list(self.path))returnfor _ in range(start_index, len(self.nums)-(k-len(self.path)) +1):self.path.append(self.nums[start_index])self.backtracking(start_index+1, k, n)self.path.pop()start_index += 1LeetCode 17.電話號碼的字母組合
思路1 ——?樸實無華
- 分級處理思想,之前操作是都是在同一個數組內,現在是多個數組,那只要修改回溯函數對應的輸入和處理方法就行。具體地,輸入兩個數組,第一個數組進行橫向遍歷,第二個數據進行遍歷。為什么在一個集合里使用start_index,是為了實現去重操作;在多個集合的操作,多個集合無交集的情況下,直接從0開始遍歷,不用考慮去重操作。
- 針對k=2時,傳入兩個數組就可以直接處理。而針對k=3,需要將k=2時的處理結果拿出來后,作為新的數組,與第三個數組輸入到回溯函數中,從而實現k=3的計算邏輯。
- k=4也是類似,就是逐步將前面的輸出結果作為新的輸入與下一個進行計算。
上述這種思路,跟用循環進行實現沒什么區別了,沒體現回溯的特點。另外,在處理數字為1的時候要注意,字符串不是像數組那般可以進行修改,因此當遇到1時,直接跳過就行,可以用一個new_digits來存儲對舊digits進行判斷修改后的結果。
class Solution(object):def letterCombinations(self, digits):""":type digits: str:rtype: List[str]"""### 采用一個Hashmap存儲對應數字和字母的關系### 對輸入的數字進行判斷已獲得其對應的字母hash_map = dict()hash_map[2] = ['a','b','c']hash_map[3] = ['d','e','f']hash_map[4] = ['g','h','i']hash_map[5] = ['j','k','l']hash_map[6] = ['m','n','o']hash_map[7] = ['p','q','r', 's']hash_map[8] = ['t','u','v']hash_map[9] = ['w','x','y', 'z']### 構造一個函數,第一個數組作為橫向遍歷,第二個數組作為縱向遍歷self.result = []self.path = [] k = len(digits)# left = right = 0 #### python中的字符串是無法直接修改的,因此碰到1的話,應該是選擇跳過,而不是進行修改# while right < k: # if digits[left] != '1':# left += 1# right += 1# elif digits[left] == '1':# right += 1# digits[left] = digits[right] cur = 0digits_list = []while cur < k:if digits[cur] != '1':digits_list.append(digits[cur])cur += 1new_digits = ''.join(digits_list)k = len(new_digits)if k == 0:return self.resultif k == 1:return hash_map[int(digits[0])]first_str = hash_map[int(digits[0])]second_str = hash_map[int(digits[1])]if k == 2:self.backtracking(0, first_str, second_str, k)if k == 3:self.backtracking(0, first_str, second_str, 2)first_second_str = list(self.result)self.result = []third_str = hash_map[int(digits[2])]self.backtracking(0, first_second_str, third_str, 2)if k == 4:self.backtracking(0, first_str, second_str, 2)first_second_str = list(self.result)self.result = []third_str = hash_map[int(digits[2])]first_str = self.backtracking(0, first_second_str, third_str, 2)first_second_third_str = list(self.result)self.result = []forth_str = hash_map[int(digits[3])]self.backtracking(0, first_second_third_str, forth_str, 2)return self.resultdef backtracking(self, start_index, first_str, second_str, k):"""first_str : 第一個字符串數組,橫向遍歷second_str : 第二個字符串數組,深度遍歷k : path的長度 == digits.length"""if len(self.path) == k:path_str = ''.join(self.path)self.result.append(path_str)returnfor _ in range(start_index, len(first_str)):self.path.append(first_str[start_index])self.backtracking(0, second_str, None, k)self.path.pop()start_index += 1 思路2:
- 關鍵還是在對回溯的理解,回溯的結構可以抽象成一顆樹,在單個集合中,你是將單個元素分到樹的每一層中。現在是多個集合,其實也就是把單個集合分到樹的每一層中。
- 在了解上述思想后,我們就可以設計index了,index表示的是digits的長度,其長度決定了有幾個集合,有N個集合就決定了有N-1個回溯遞歸的深度(因為第一個是橫向遍歷)。
Code
class Solution(object):def letterCombinations(self, digits):""":type digits: str:rtype: List[str]"""self.letterMap = [ ### 一個一維數組,數字的大小剛好對應去在數組中去獲得該數字對應字符串的下標"", # 0"", # 1"abc", # 2"def", # 3"ghi", # 4"jkl", # 5"mno", # 6"pqrs", # 7"tuv", # 8"wxyz" # 9]self.result = []self.path = []new_digits = []for dig in digits: ### 判斷數字是否在[2,9]之內,如果有不存在的需要進行刪除if dig != '1' or dig != '0':new_digits.append(dig)new_digits = "".join(new_digits)length = len(new_digits) ### 數字的長度index = 0 ### 樹的深度if length == 0:return self.resultself.backtracking(index, new_digits, length)return self.resultdef backtracking(self, index, new_digits, length):if index == length:self.result.append("".join(list(self.path)))return ### 終止條件cur = int(new_digits[index]) ### 當前處理的數字cur_str = self.letterMap[cur] ### 當前處理的數字 對應的字符串for i in range (len(cur_str)):self.path.append(cur_str[i])self.backtracking(index+1, new_digits, length)self.path.pop()# index += 1 注意,在self.path.pop()之后,index不需要+1,與start_index進行區分開來。start_index + 1是為了獲得一個數組中后續的元素。而在不同的集合中,你index是操作不同集合,index為0傳進后是第一層,如何往下進行深度遍歷操作,已經在index+1作為輸入參數進行輸入時已經確定了,后序遞歸結束時,重新執行for循環,進行橫向遍歷,再一步遞歸去深度遍歷。





)


)








--異常處理,命名空間,多繼承與虛繼承)

免費證書的技術指南)