《DriveMM: All-in-One Large Multimodal Model for Autonomous Driving》2024年12月發表,來自中山大學深圳分校和美團的論文。
????????大型多模態模型(LMM)通過整合大型語言模型,在自動駕駛(AD)中表現出卓越的理解和解釋能力。盡管取得了進步,但當前的數據驅動AD方法往往專注于單個數據集和特定任務,忽視了它們的整體能力和泛化能力。為了彌合這些差距,我們提出了DriveMM,這是一種通用的大型多模式模型,旨在處理各種數據輸入,如圖像和多視圖視頻,同時執行廣泛的AD任務,包括感知、預測和規劃。最初,該模型經過課程預訓練,以處理各種視覺信號并執行基本的視覺理解和感知任務。隨后,我們增強和標準化了各種與AD相關的數據集,以微調模型,從而為自動駕駛提供了一個一體化的LMM。為了評估總體能力和泛化能力,我們對六個公共基準進行了評估,并在一個看不見的數據集上進行了零樣本傳輸,其中DriveMM在所有任務中都實現了最先進的性能。我們希望DriveMM能夠成為現實世界中未來端到端自動駕駛應用的有前景的解決方案。
1.?研究背景與問題
自動駕駛(AD)領域的數據驅動方法通常專注于單一數據集和特定任務(如目標檢測、路徑規劃),導致模型泛化能力不足。現有大型多模態模型(LMMs)雖在視覺-語言任務中表現優異,但缺乏對復雜駕駛場景的全面理解和多任務協同能力。本文提出DriveMM,一個全合一的多模態模型,旨在統一處理多種數據輸入(圖像、視頻、多視角數據)并執行感知、預測、規劃等多樣化任務,同時提升泛化能力。
2.?核心貢獻
-
全合一多模態模型(DriveMM):
支持多傳感器輸入(單/多視角圖像、視頻、LiDAR),通過視角感知提示區分數據來源(如不同攝像頭視角),并整合感知、預測、規劃任務。 -
綜合基準測試:
首次提出涵蓋6個公共數據集、4種輸入類型、13項任務的評估框架,覆蓋復雜駕駛場景。 -
課程學習方法:
分階段訓練(語言-圖像對齊→單圖像預訓練→多能力預訓練→駕駛微調),逐步提升模型處理復雜數據的能力。 -
數據增強與標準化:
利用GPT-4o擴展問答對的多樣性,統一不同數據集的標注格式(如目標位置標準化為0-100范圍),促進多數據集協同訓練。
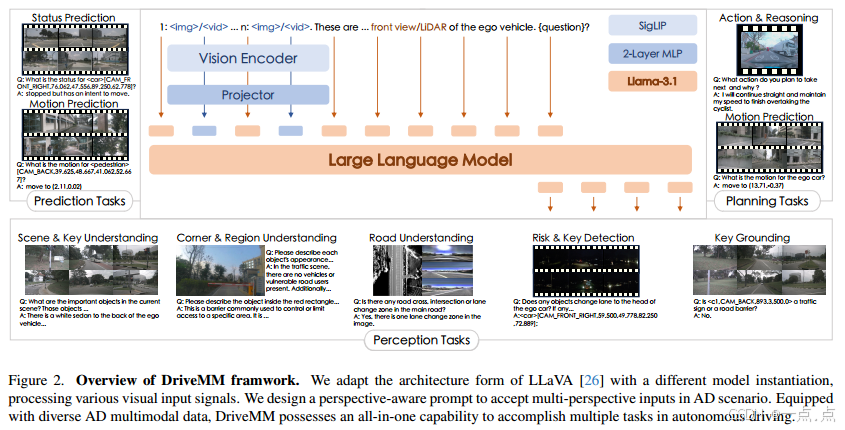 ?3.?方法論
?3.?方法論
-
模型架構:
-
視覺編碼器(SigLIP):處理多模態輸入(圖像、視頻、LiDAR投影的BEV/范圍視圖)。
-
投影器(2層MLP):將視覺特征映射到語言模型的詞嵌入空間(LLaMA-3.1)。
-
視角感知提示:通過占位符(
<image>/<video>)和視角標簽(如CAM.BACK)增強模型對空間關系的理解。
-
-
數據策略:
-
多源數據整合:包括通用多模態數據(LCS-558K、COCO)、感知數據(COCO、nuScenes)和自動駕駛數據(CODA-LM、DriveLM等)。
-
問答增強:利用GPT-4o生成多樣化問答對,將開放式問題轉為多選題,提升模型泛化能力。
-
-
訓練流程:

分四階段逐步提升能力:-
語言-圖像對齊:凍結視覺編碼器和語言模型,僅訓練投影器。
-
單圖像預訓練:優化整體模型參數,增強單圖像理解。
-
多能力預訓練:引入視頻、多視角數據,提升時空推理能力。
-
駕駛微調:在6個自動駕駛數據集上聯合微調,實現多任務協同。
-
4.?實驗結果
-
性能優勢:
DriveMM在6個數據集(CODA-LM、MAPLM、DriveLM等)的13項任務中均達到SOTA,平均性能提升顯著(如Nulnstruct任務提升26.17%)。 -
泛化能力:
在零樣本遷移測試(BDD-X數據集)中,DriveMM的GPT-Score(43.10)遠超單數據集訓練的專家模型(最高39.67)。 -
消融實驗驗證:
-
視角感知提示:提升多視角數據任務性能(如DriveLM、Nulnstruct)。
-
問答增強與標準化:顯著改善數據多樣性受限的任務(如CODA-LM)。
-
多數據集聯合訓練:相比單數據集訓練,混合訓練平均性能提升1-5%。
-
5.?創新與局限性
-
創新點:
-
首次提出全合一自動駕駛LMM,統一多任務、多數據輸入。
-
視角感知提示機制和課程學習方法為多模態模型設計提供新思路。
-
-
局限性:
-
實際道路測試尚未驗證,需進一步部署驗證。
-
模型參數量大(基于LLaMA-3.1 8B),計算成本較高。
-
6.?應用前景
DriveMM為端到端自動駕駛系統提供了高效的多任務解決方案,可適配不同傳感器配置(攝像頭、雷達),適用于城市道路、高速公路等多種場景。未來可結合實時控制模塊,進一步探索其在動態決策中的潛力。
如果此文章對您有所幫助,那就請點個贊吧,收藏+關注 那就更棒啦,十分感謝!!!



















