0.前言
阿里巴巴于2025年5月14日正式開源了其最新的AI視頻生成與編輯模型——通義萬相Wan2.1-VACE。這一模型是業界功能最全面的視頻生成與編輯工具,能夠同時支持多種視頻生成和編輯任務,包括文生視頻、圖像參考視頻生成、視頻重繪、局部編輯、背景延展以及視頻時長延展等全系列基礎生成和編輯能力。


下面詳細給大家介紹一下它的技術和能力亮點。
1.核心技術與能力亮點
-
全面可控的生成能力****全面可控的生成能力
通義萬相2.1-VACE 支持對視頻生成進行細粒度控制,可基于多種控制信號生成內容,包括:-
人體姿態光流
-
結構保留
-
空間運動
-
色彩渲染
同時,它還支持基于主體和背景參考的視頻生成。
-
-
強大的局部與全局編輯能力
- 局部編輯:可指定視頻中的局部區域進行元素替換、添加或刪除。
- 時間軸編輯:給定任意視頻片段,可通過首尾幀補全生成完整視頻。
- 空間擴展:支持視頻擴展生成,典型應用包括視頻背景替換 —— 在保持主體不變的前提下,根據文本提示更換背景。

-
多形態信息輸入
為解決專業創作者面臨的 “僅用文本提示難以精準控制元素一致性、布局、運動和姿態” 的局限,One2.1V 在 2.1 模型基礎上進一步升級,成為集成文本、圖像、視頻、掩碼和控制信號的統一視頻編輯模型:- 圖像輸入:支持參考圖像(物體相關)或視頻幀輸入。
- 視頻輸入:可通過擦除部分內容、局部編輯或擴展等操作實現視頻重生成。
- 掩碼輸入:用戶可通過 0/1 二進制信號指定編輯區域。
- 控制信號輸入:支持深度圖、光流布局、灰度圖、線稿和姿態等信號。

-
統一的模型架構
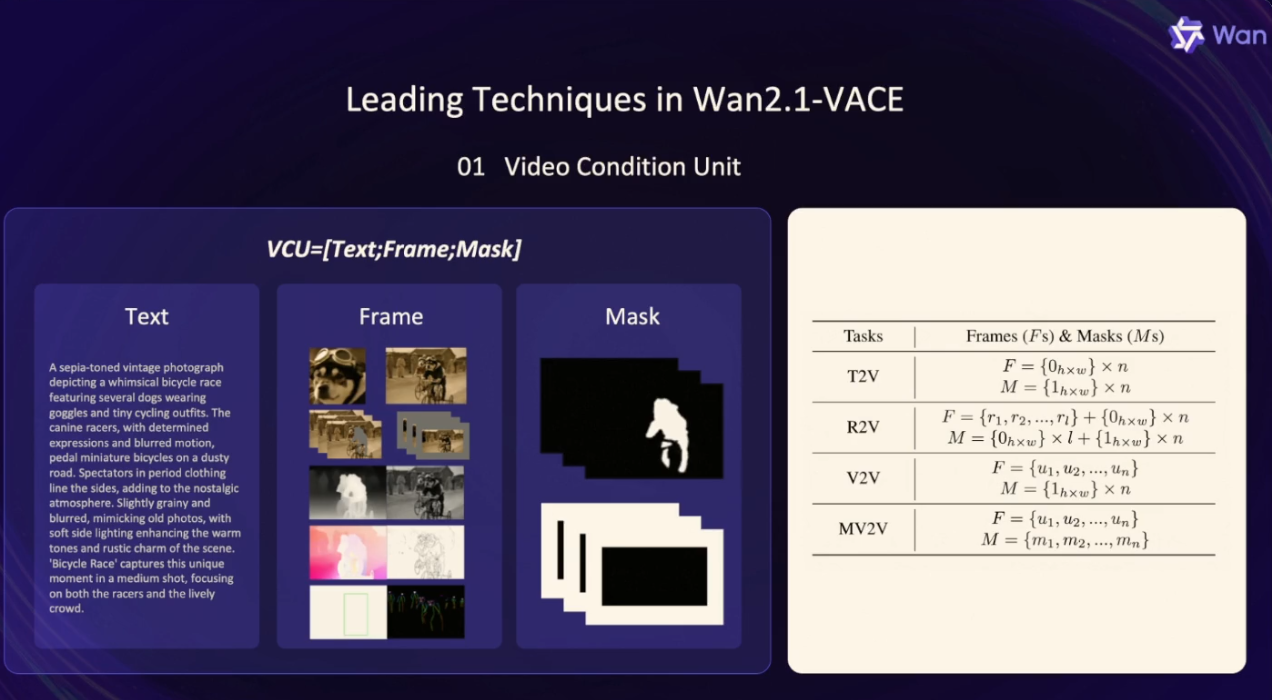
其核心技術突破在于采用單一模型處理傳統需要多個 “專業模型” 的任務,這得益于動態輸入模塊和繼承自 2.1 模型的強大視頻生成能力。這意味著,圖像參考(元素一致性)、視頻重創作(姿態遷移、運動 / 結構控制、色彩重渲染)、局部編輯(主體重塑 / 移除、背景 / 時長擴展)等功能均可通過 通義萬相2.1-VACE實現。視頻條件單元 VCU
通義萬相團隊深入分析和總結了文生視頻、參考圖生視頻、視頻生視頻,基于局部區域的視頻生視頻4大類視頻生成和編輯任務的輸入形態,提出了一個更加靈活統一的輸入范式:視頻條件單元 VCU
多模態輸入的token序列化FINE-TUNING
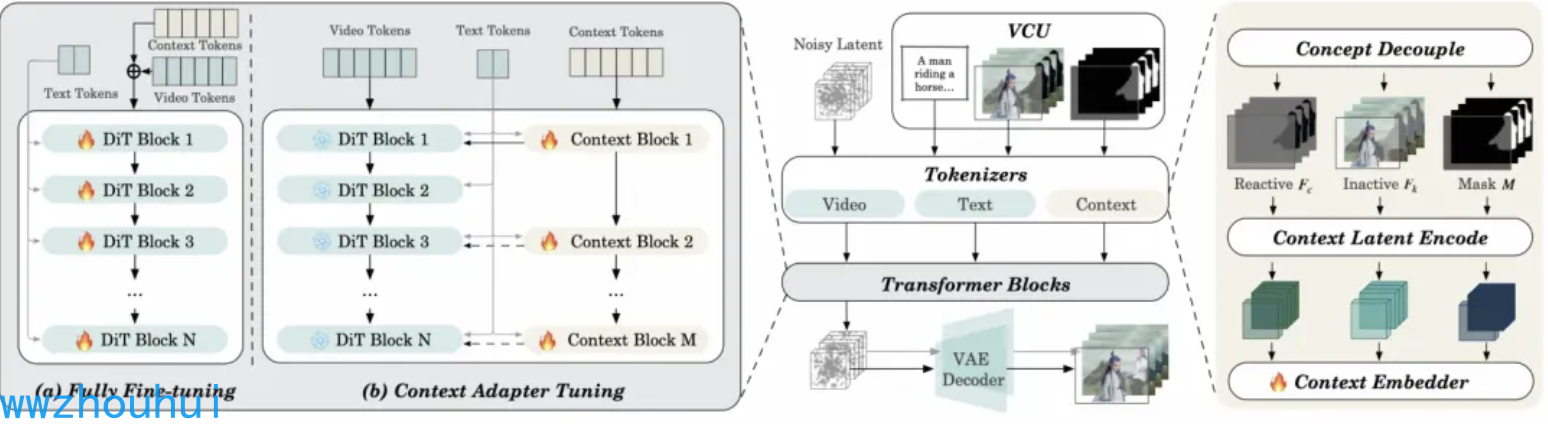
在多模態輸入處理中,token 序列化是 Wan2.1 視頻擴散 Transformer 架構精準解析輸入信息的關鍵環節,而 VACE 成功攻克了這一難題。其處理流程可分為概念解耦、編碼轉換與特征融合三個核心步驟。
在概念解耦階段,VACE 針對 VCU 輸入的 Frame 序列,創新性地將圖像元素按性質拆分。對于需保留原始視覺信息的 RGB 像素,以及承載控制指令等需重新生成的像素內容,分別構建可變幀序列與不變幀序列,為后續處理奠定基礎。
進入編碼轉換環節,三類序列分別經歷專屬編碼路徑。可變幀序列與不變幀序列借助 VAE(變分自編碼器),轉化為與 DiT 模型噪聲維度匹配、通道數為 16 的隱空間表征;mask 序列則通過變形與采樣技術,編碼為時空維度統一、通道數達 64 的特征向量,實現不同模態數據的規范化表達。
最終的特征融合步驟,VACE 將 Frame 序列與 mask 序列的隱空間特征深度整合,并通過可訓練參數模塊,精準映射為適配 DiT 模型的 token 序列,成功搭建起多模態輸入與 Transformer 架構之間的高效信息橋梁。
-
無縫的任務組合能力
統一模型的一大優勢是天然支持自由組合各種基礎功能,無需為每種獨特功能單獨訓練新模型。典型組合場景包括:- 結合圖像參考與主體重塑,實現視頻物體替換。
- 結合運動控制與幀參考,控制靜態圖像的姿態。
- 結合圖像參考、幀參考、背景擴展與時長擴展,將靜態風景圖轉化為橫版視頻,并可添加參考圖像中的元素。

? 上面給大家展示了模型的能力, 效果到底如何呢?下面手把手帶大家在魔搭社區部署和搭建,我們感受一下把。
2.模型部署
模型社區啟動資源
? 登錄魔搭社區https://modelscope.cn/
? 
搜索模型 通義萬相2.1-VACE-1.3B
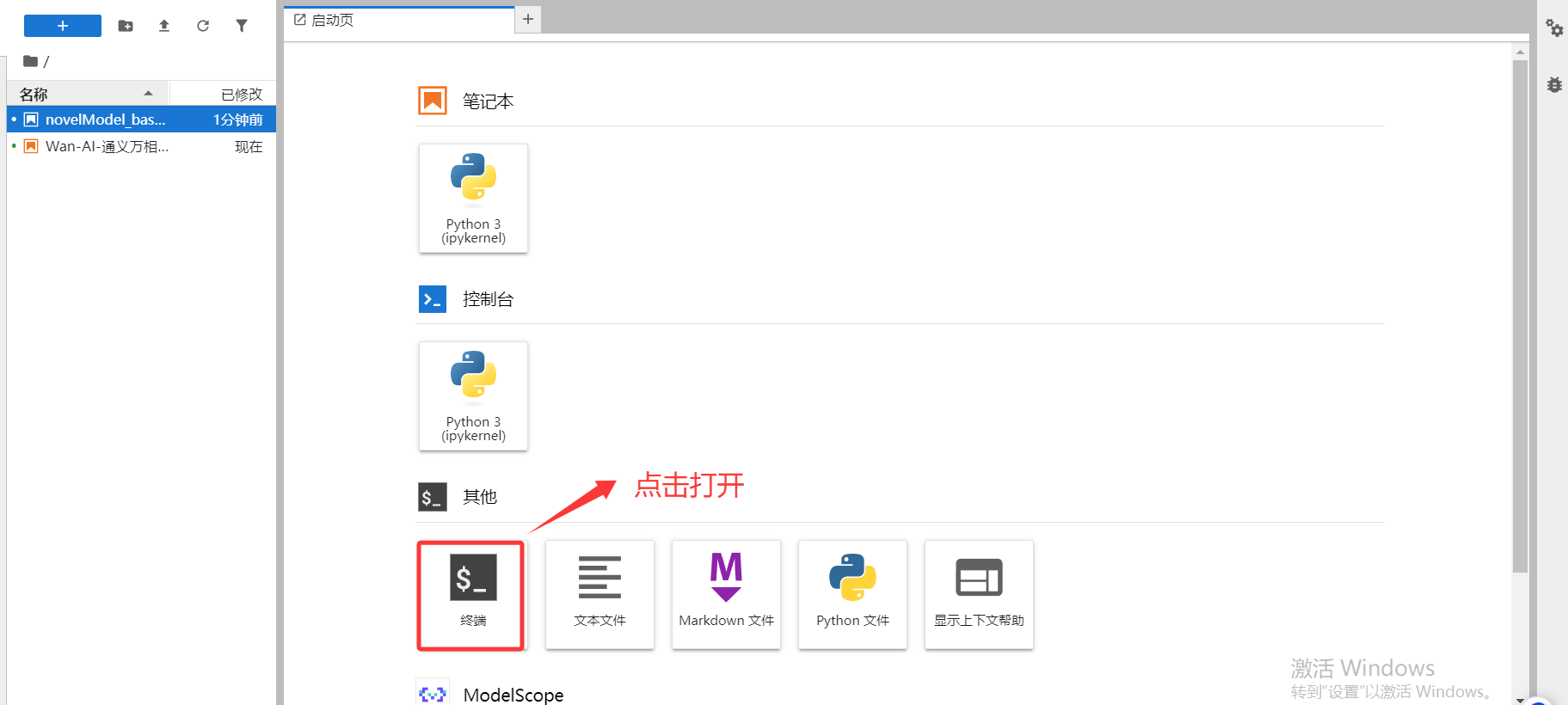
我們點擊右上角nodebook快速開發- 使用魔搭平臺提供的免費實例
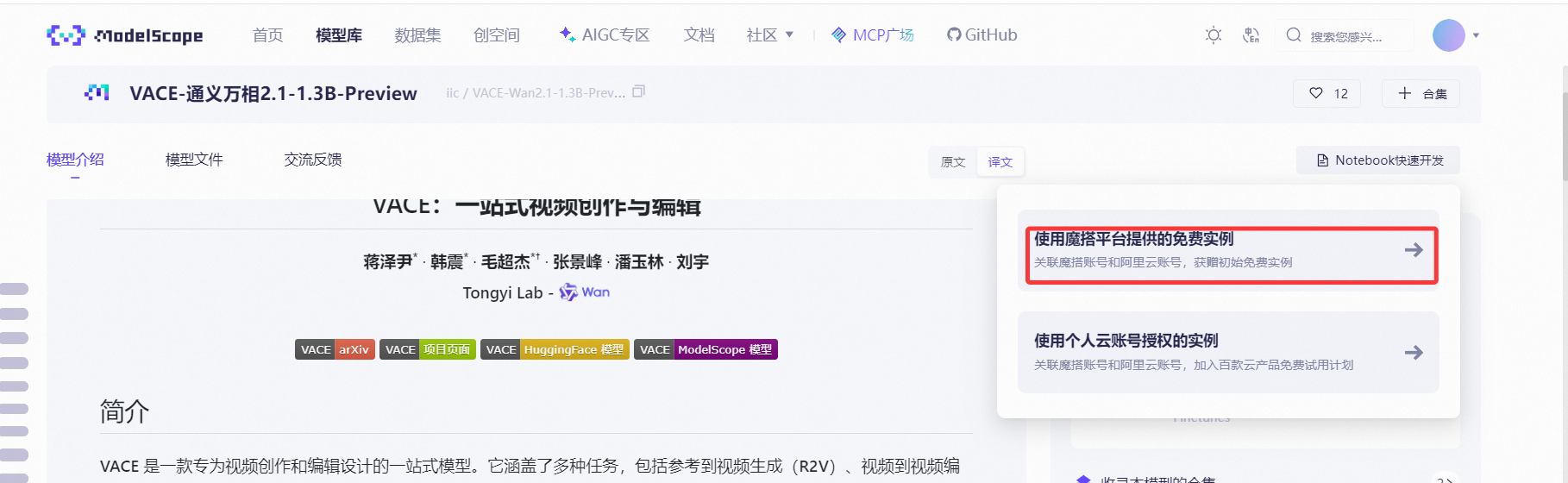
這里我們選擇PAI-DSW,選擇GPU環境,點擊啟動按鈕等待服務器分配資源
啟動按鈕點擊后,我們稍等幾分鐘
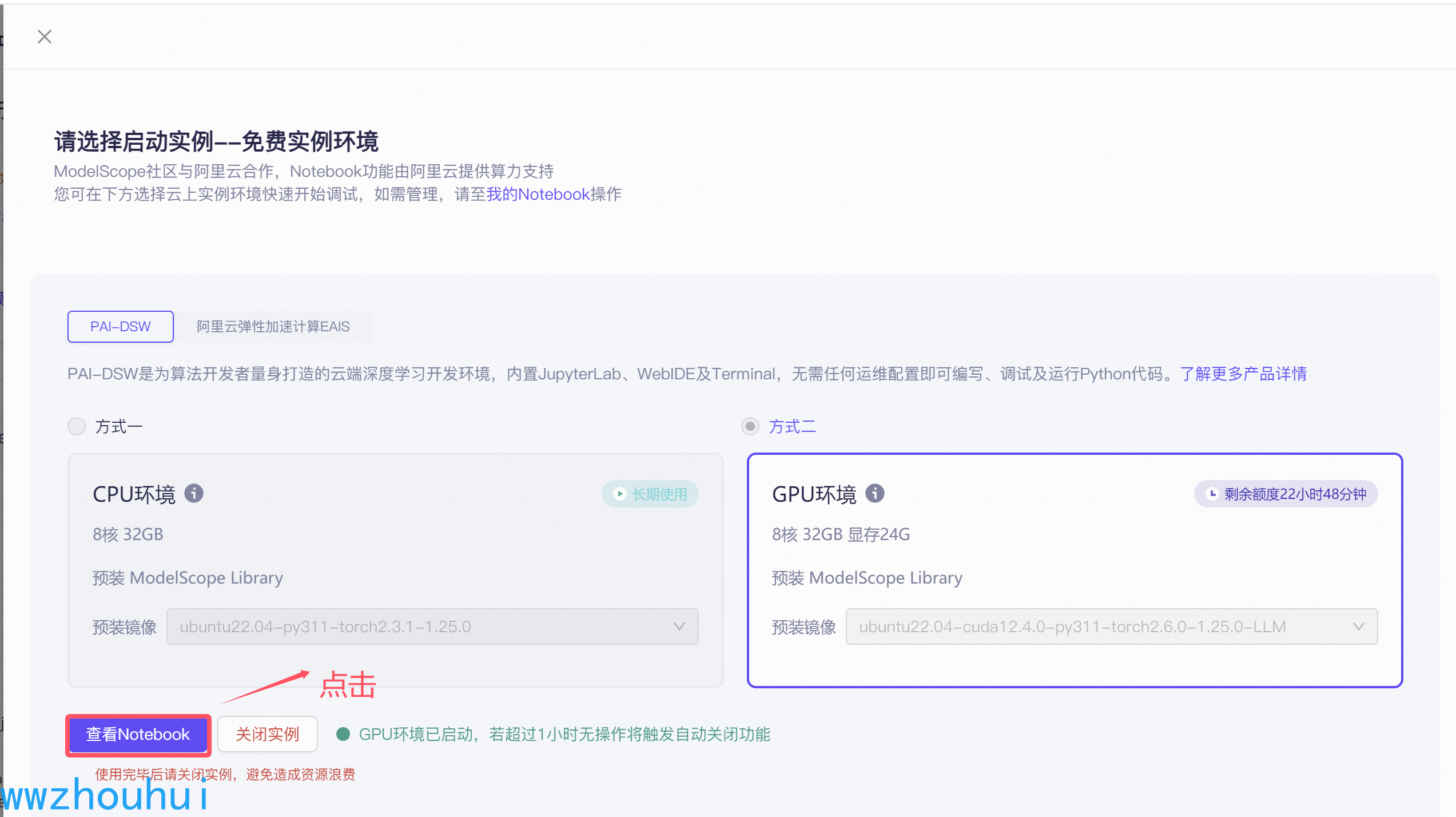
啟動完成后我們點擊查看nodebook進入調試界面
模型下載
我們進入nodebook調試界面看到下面的界面
接下來我們需要把模型權重下載下來。
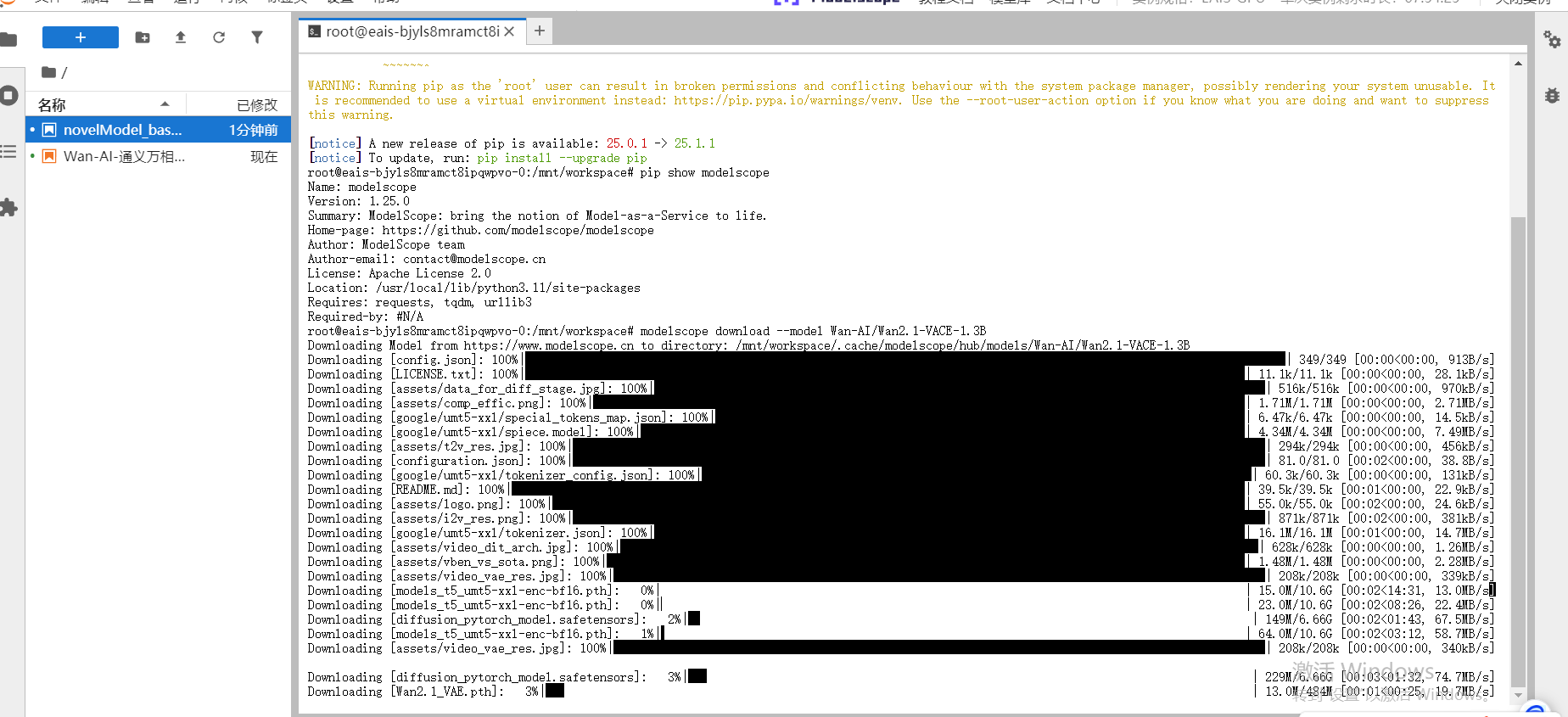
我們打開一個終端命令
在shell窗口中,我們輸入下面命令下載模型權重
pip install modelscope
modelscope download --model Wan-AI/Wan2.1-VACE-1.3B --local_dir /mnt/workspace/Wan2.1-VACE-1.3B
模型推理
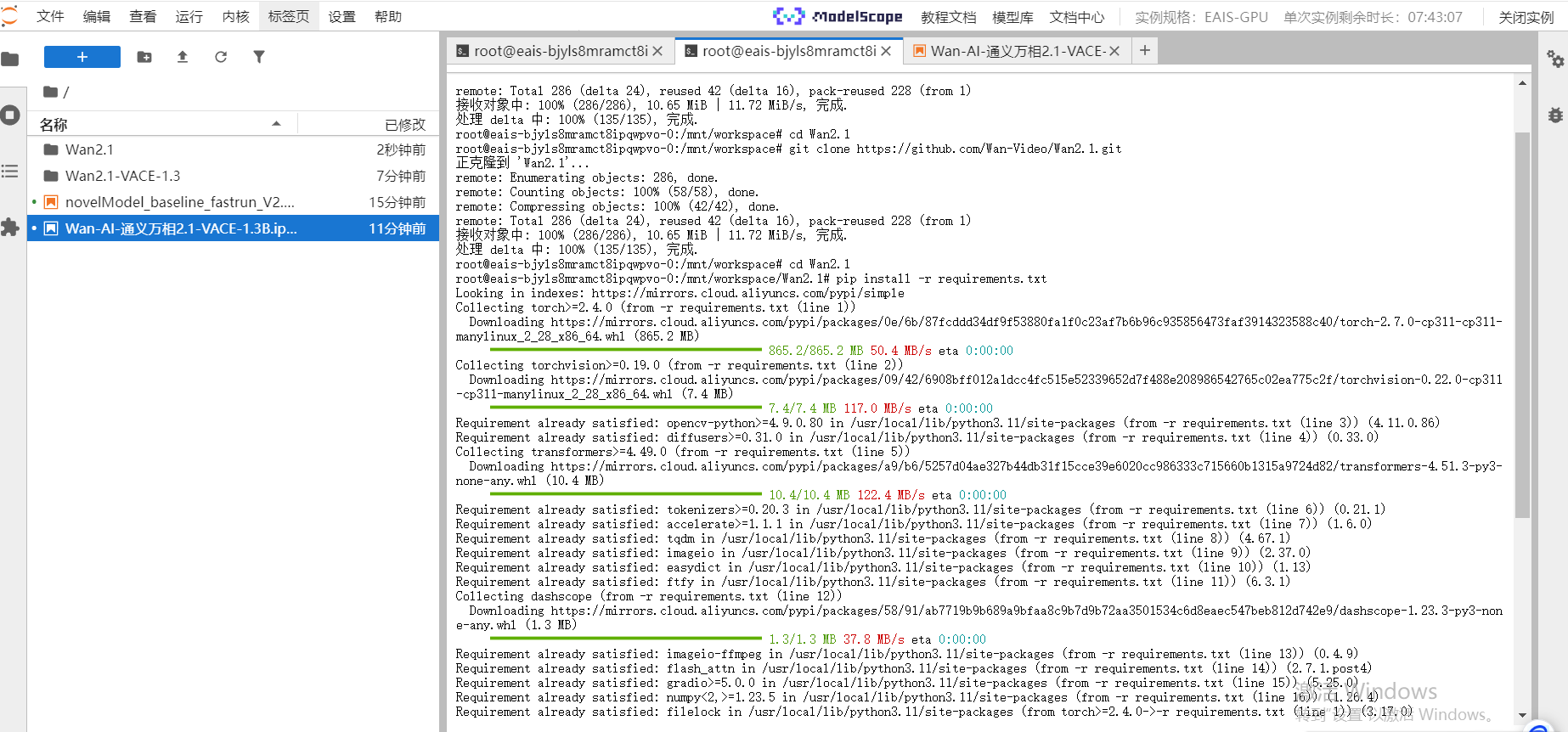
接下來我們在github上下載模型推理代碼,我們在shell窗口輸入如下命令
git clone https://ghfast.top/https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1

接下來我們安裝一下模型推理依賴
pip install -r requirements.txt
pip install torch==2.5.1 torchvision==0.20.1 --index-url https://download.pytorch.org/whl/cu124
看到上面的畫面我們就完成推理代碼python依賴包的安裝。
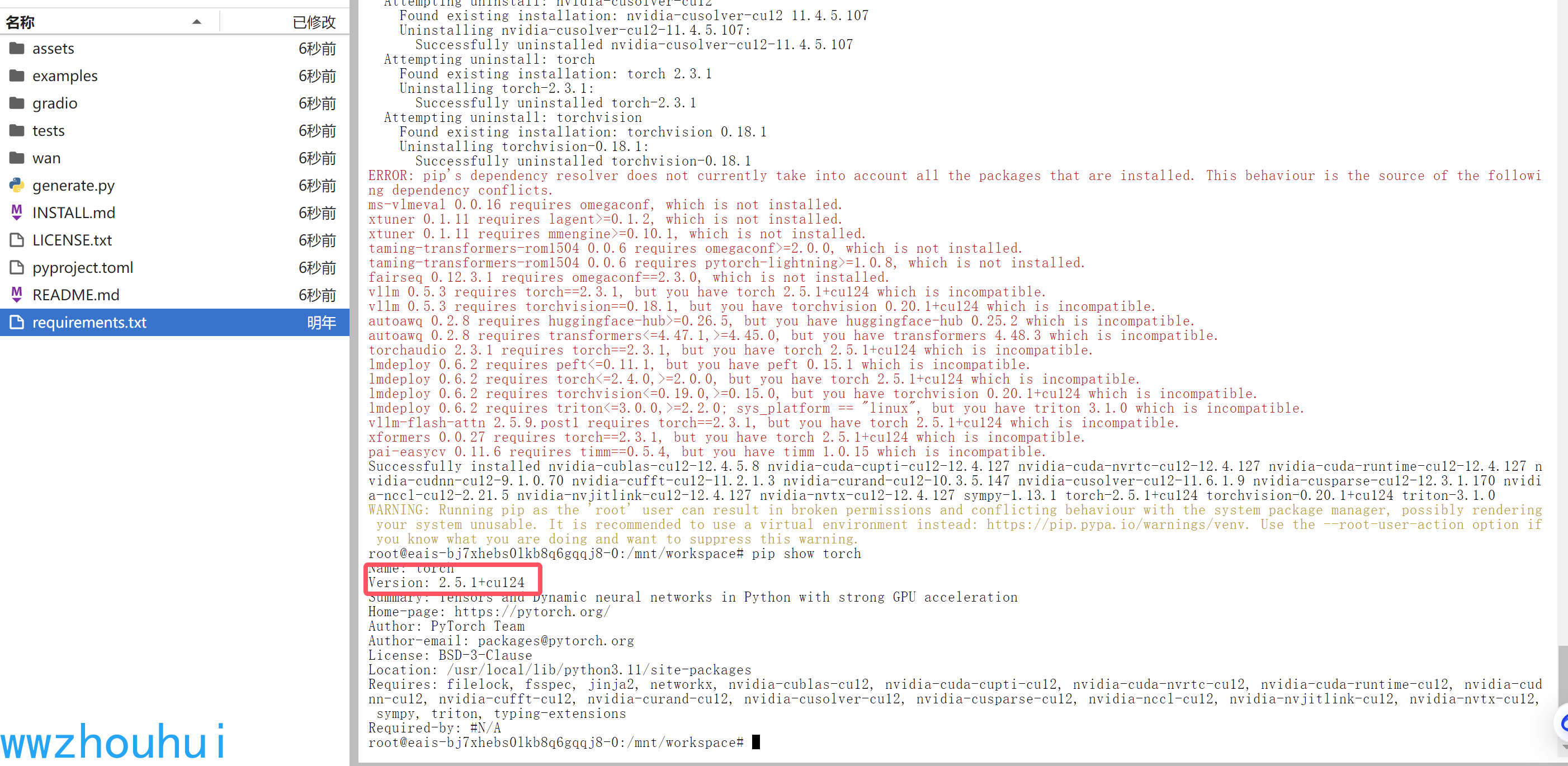
檢查一下torch
pip show torch
cli inference
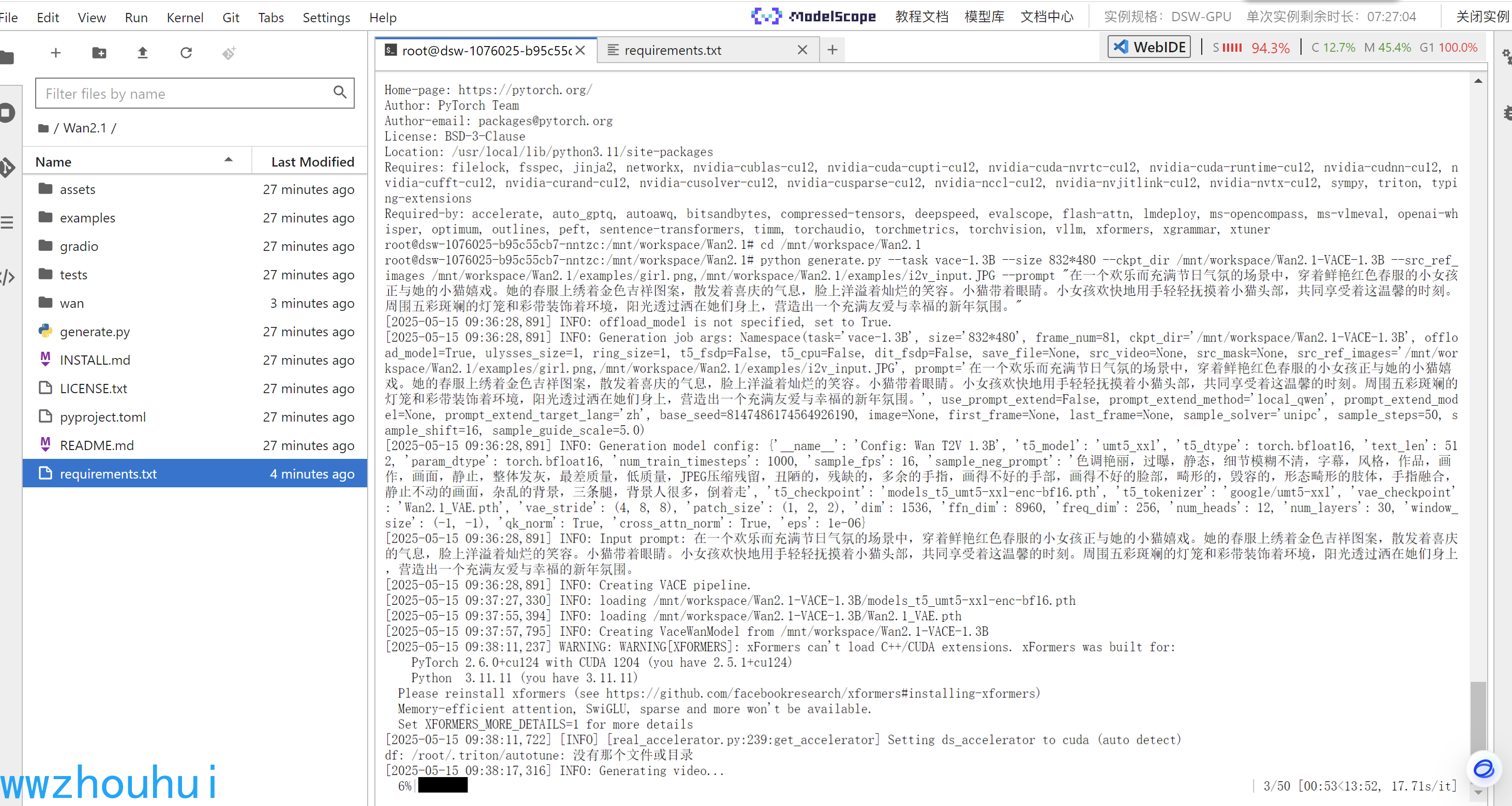
接下來來我們使用cli 命令行測試驗證一下模型是否能夠推理成功
cd /mnt/workspace/Wan2.1
python generate.py --task vace-1.3B --size 832*480 --ckpt_dir /mnt/workspace/Wan2.1-VACE-1.3B --src_ref_images /mnt/workspace/Wan2.1/examples/girl.png,/mnt/workspace/Wan2.1/examples/i2v_input.JPG --prompt "在一個歡樂而充滿節日氣氛的場景中,穿著鮮艷紅色春服的小女孩正與她的小貓嬉戲。她的春服上繡著金色吉祥圖案,散發著喜慶的氣息,臉上洋溢著燦爛的笑容。小貓帶著眼睛。小女孩歡快地用手輕輕撫摸著小貓頭部,共同享受著這溫馨的時刻。周圍五彩斑斕的燈籠和彩帶裝飾著環境,陽光透過灑在她們身上,營造出一個充滿友愛與幸福的新年氛圍。"
程序運行加載模型,第一次運行會比較慢一點。
推理結束
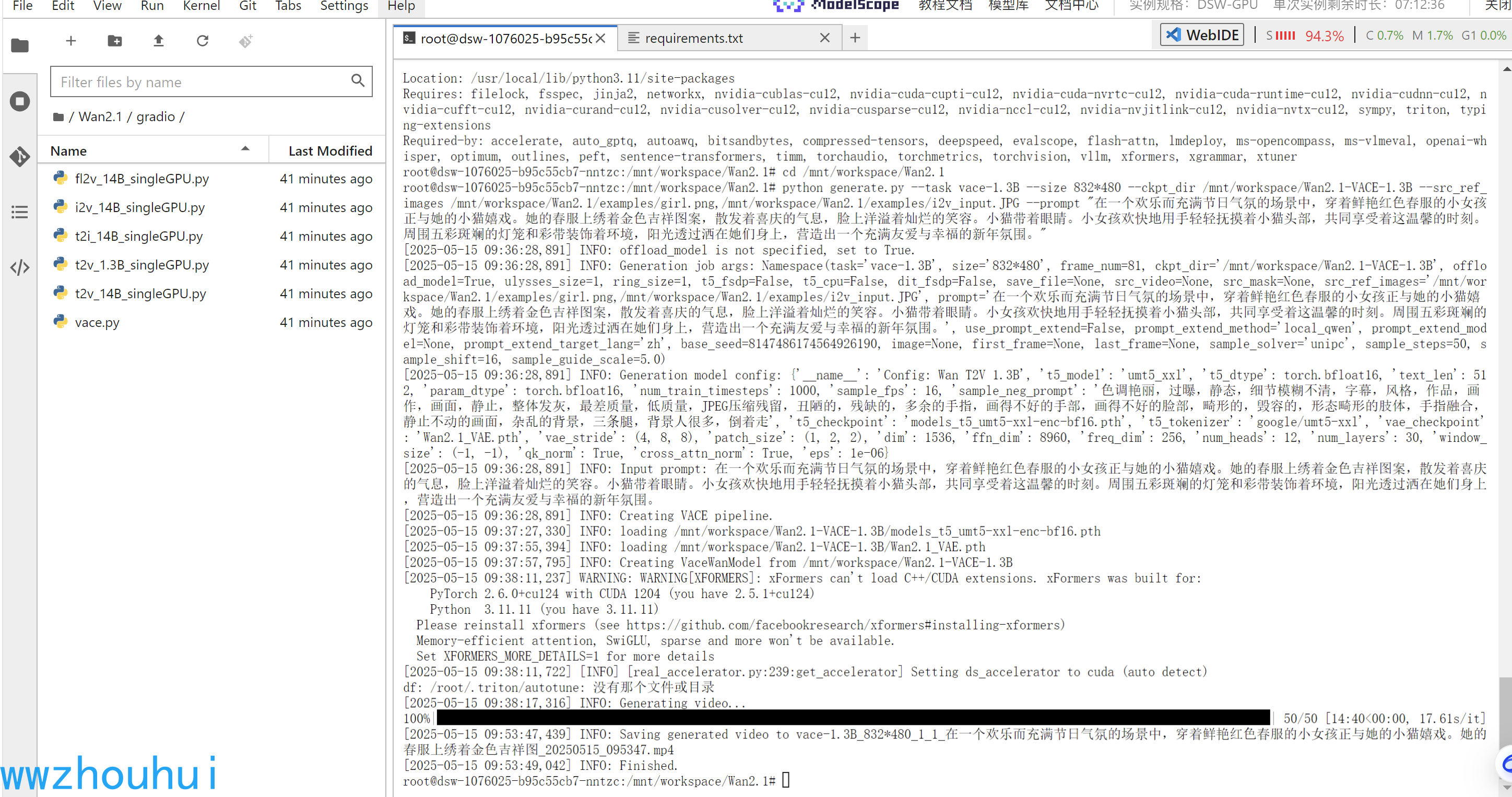
完成推理后我們看一下視頻生成的效果

手有點脫離身體,不過確實把小女孩和貓合成在一個視頻里面,哈哈。
gradio inference
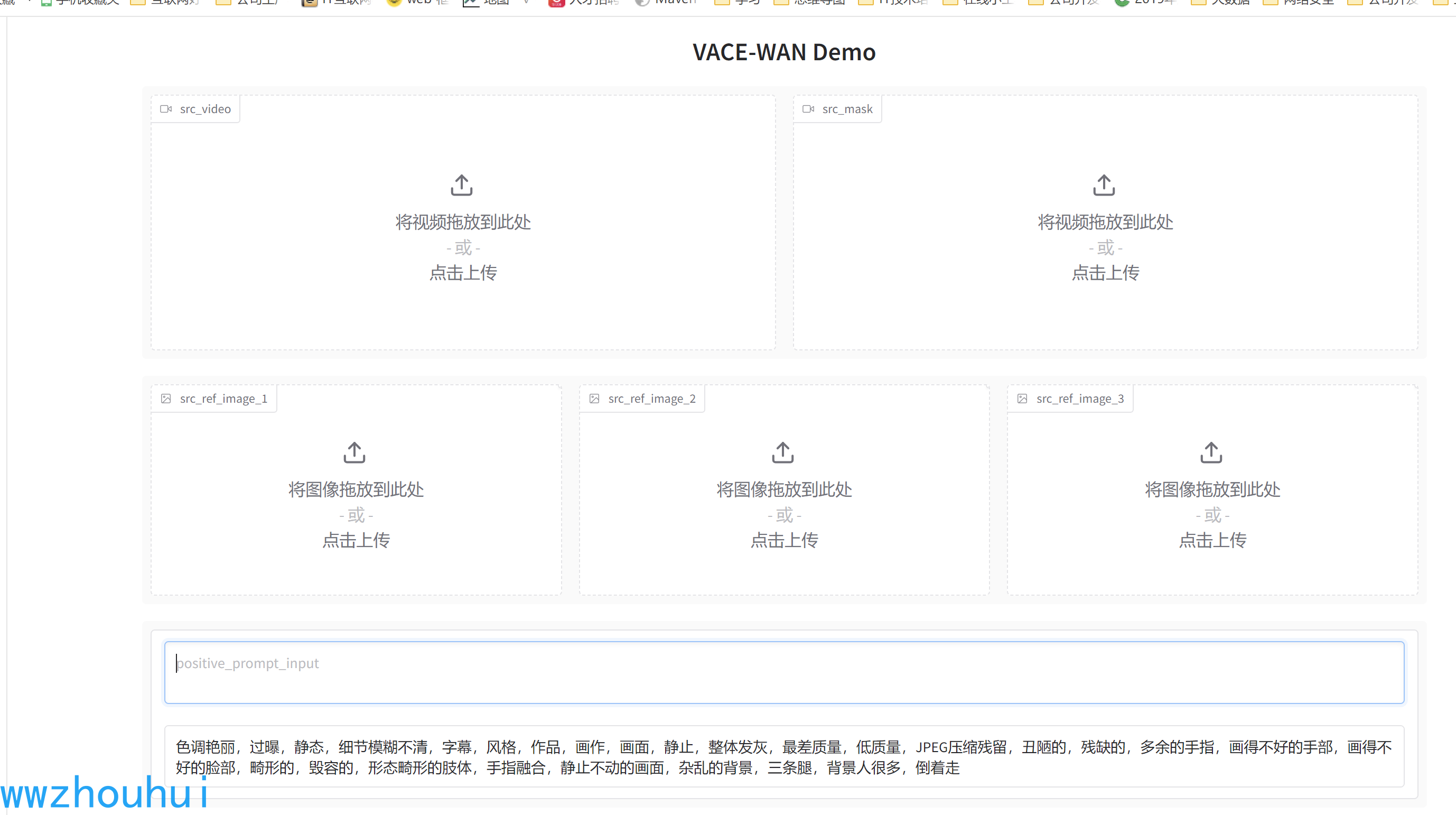
接下來我們使用gradio web頁面的方式實現模型推理
cd /mnt/workspace/Wan2.1
python gradio/vace.py --ckpt_dir /mnt/workspace/Wan2.1-VACE-1.3B
頁面啟動完成
頁面打開(我們借用官方的提供的gradio,頁面有點丑)
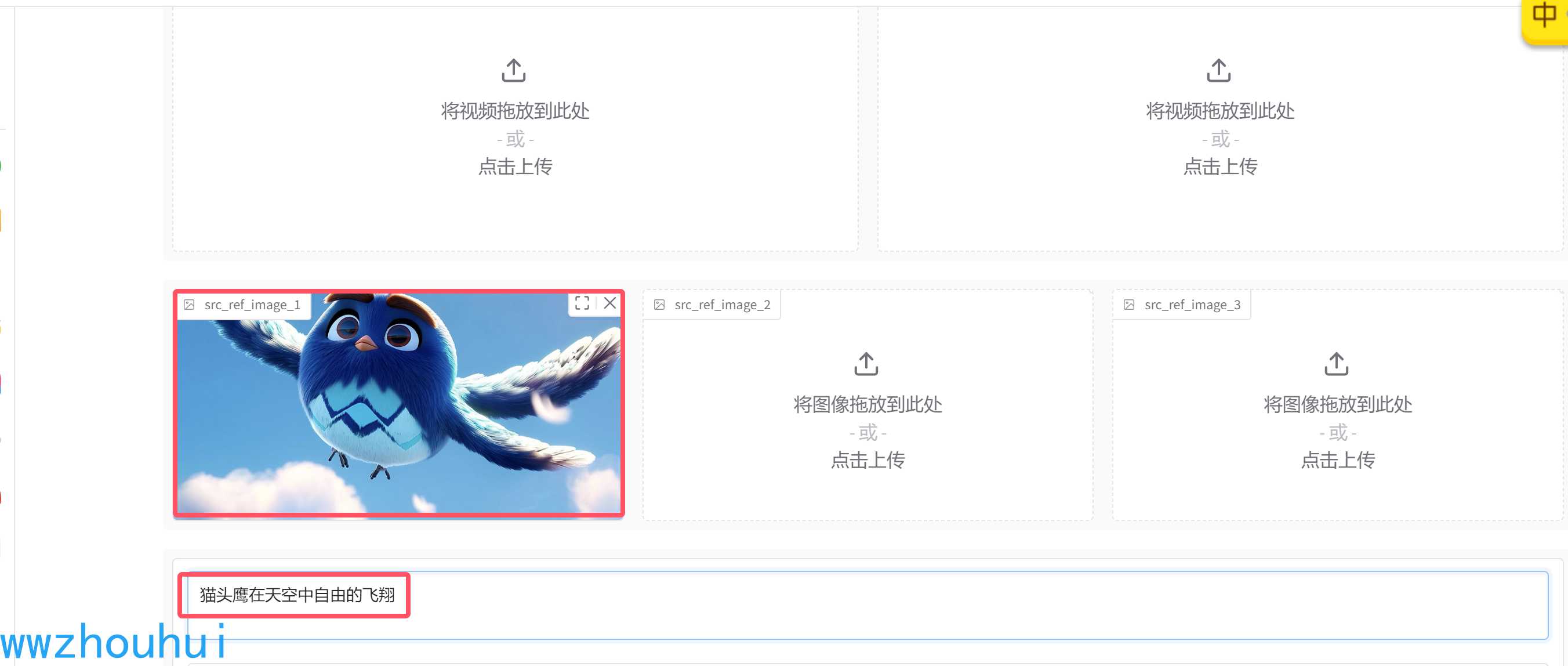
先測試一個簡單,上傳一個貓頭鷹飛翔的圖片 ,圖片的長設置832 寬度設置480
貓頭鷹在天空中自由的飛翔
生成的效果
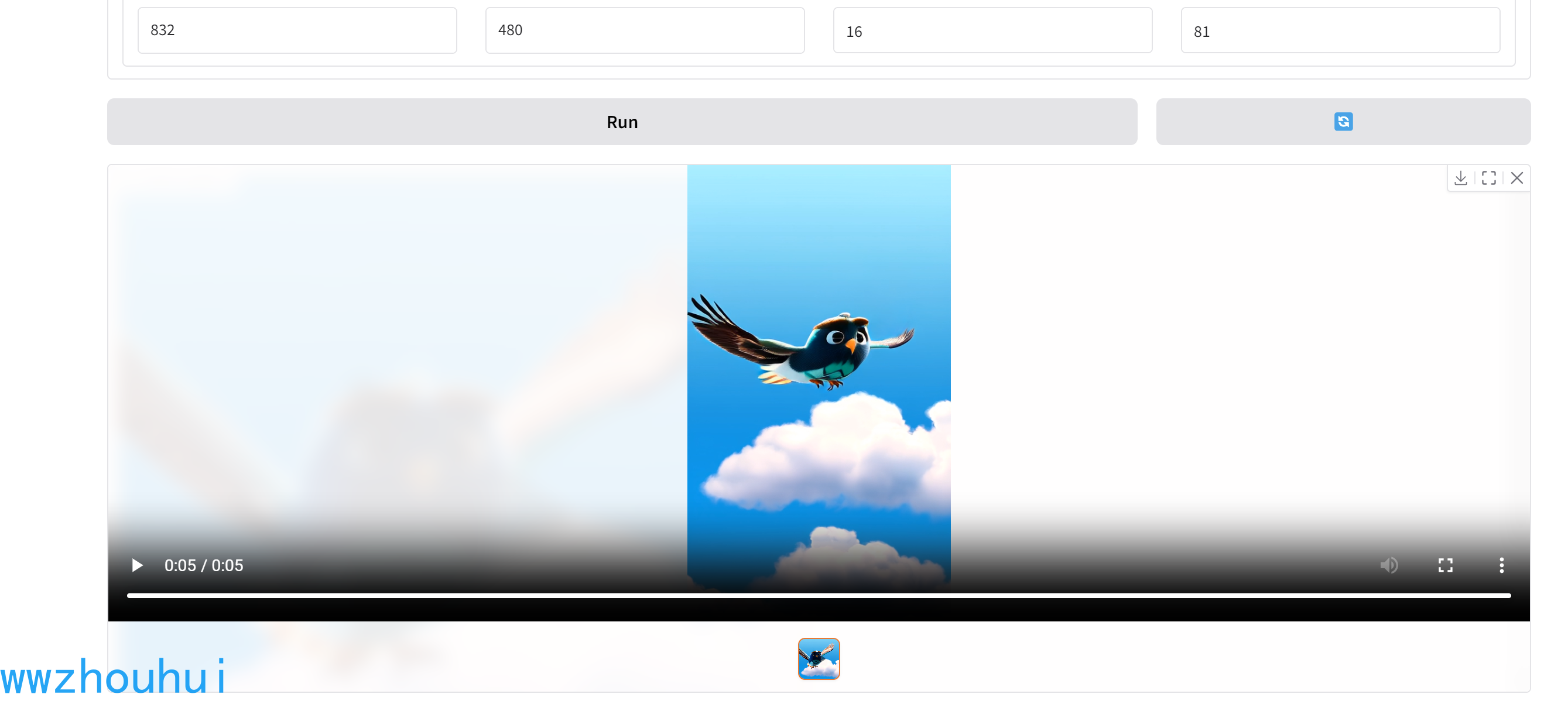
? 以上我們用2種方式實現了基于Wan2.1-VACE模型的推理。從提供的DEMO和模型的代碼里面來看有不少好玩的東西。由于我這里用了魔搭社區免費GPU算力,實現的推理效果可能和官方宣傳有點差異。但是我測試下來總體還可以,由于時間關系也沒有做詳細的測試。
3.總結:
今天主要帶大家了解了阿里巴巴于 2025 年 5 月 14 日開源的 AI 視頻生成與編輯模型 —— 通義萬相 Wan2.1-VACE,并詳細介紹了其部署和推理過程。該模型具有全面可控的生成能力、強大的局部與全局編輯能力、多形態信息輸入、統一的模型架構以及無縫的任務組合能力等亮點,是業界功能最全面的視頻生成與編輯工具。由于時間關系,本次測試未進行詳細的對比和評估。不過,從模型的功能和提供的 DEMO 來看,通義萬相 Wan2.1-VACE 具有很大的應用潛力,能夠為視頻生成和編輯領域帶來新的可能性。感興趣的小伙伴可以按照本文步驟去嘗試,探索該模型更多的應用場景。今天的分享就到這里結束了,我們下一篇文章見。
#WanVACE









】Eureka單個服務端的搭建(含源代碼)(三))








)
