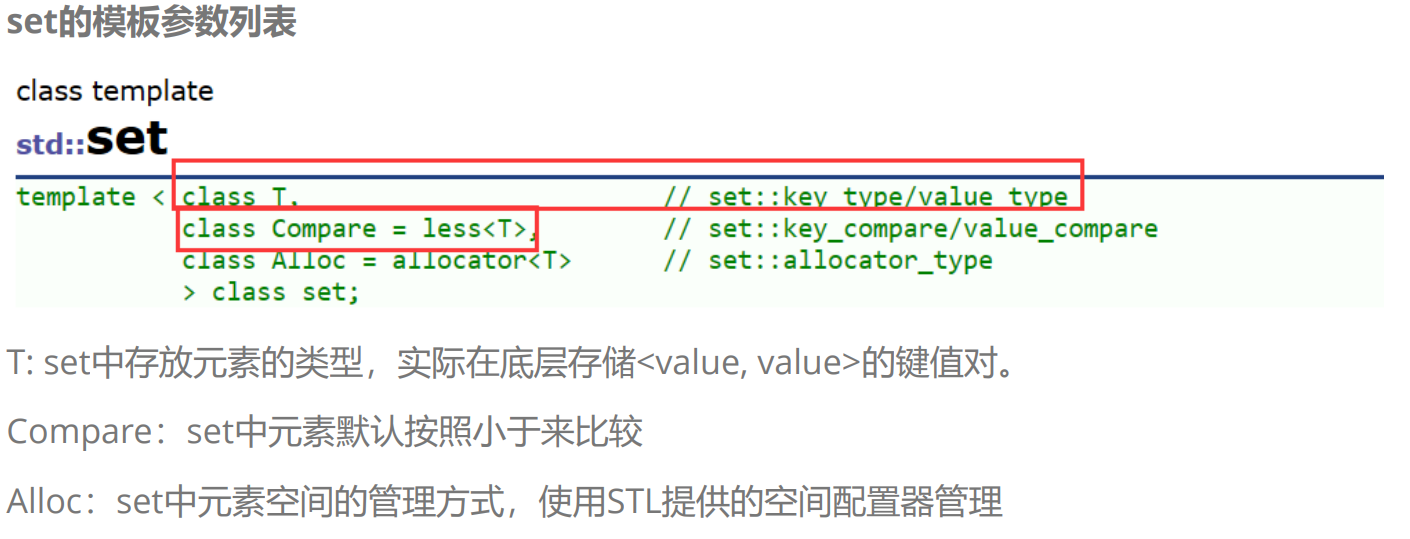
1. 關聯式容器
在初階階段,我們已經接觸過STL中的部分容器,比如:vector、list、deque、 forward_list(C++11)等,這些容器統稱為序列式容器,因為其底層為線性序列的數據結構,里面 存儲的是元素本身。那什么是關聯式容器?它與序列式容器有什么區別?
關聯式容器也是用來存儲數據的,與序列式容器不同的是,其里面存儲的是結構的 鍵值對,在數據檢索時比序列式容器效率更高。
2. 鍵值對
用來表示具有一一對應關系的一種結構,該結構中一般只包含兩個成員變量key和value,key代 表鍵值,value表示與key對應的信息。比如:現在要建立一個英漢互譯的字典,那該字典中必然 有英文單詞與其對應的中文含義,而且,英文單詞與其中文含義是一一對應的關系,即通過該應 該單詞,在詞典中就可以找到與其對應的中文含義。
3. 樹形結構的關聯式容器
根據應用場景的不桶,STL總共實現了兩種不同結構的管理式容器:樹型結構與哈希結構。樹型結 構的關聯式容器主要有四種:map、set、multimap、multiset。
這四種容器的共同點是:使 用平衡搜索樹(即紅黑樹)作為其底層結果,容器中的元素是一個有序的序列。下面一依次介紹每一 個容器。
3.1? set
set - C++ Reference
翻譯:
1. set是按照一定次序存儲元素的容器
2. 在set中,元素的value也標識它(value就是key,類型為T),并且每個value必須是唯一的。 set中的元素不能在容器中修改(元素總是const),但是可以從容器中插入或刪除它們。
3. 在內部,set中的元素總是按照其內部比較對象(類型比較)所指示的特定嚴格弱排序準則進行 排序。
4. set容器通過key訪問單個元素的速度通常比unordered_set容器慢,但它們允許根據順序對 子集進行直接迭代。
5. set在底層是用二叉搜索樹(紅黑樹)實現的。
注意:
1. 與map/multimap不同,map/multimap中存儲的是真正的鍵值對,set中只放 value,但在底層實際存放的是由構成的鍵值對。
2. set中插入元素時,只需要插入value即可,不需要構造鍵值對。
3. set中的元素不可以重復(因此可以使用set進行去重)。
4. 使用set的迭代器遍歷set中的元素,可以得到有序序列
5. set中的元素默認按照小于來比較
6. set中查找某個元素,時間復雜度為:log_2 n
?7. set中的元素不允許修改(為什么?)
8. set中的底層使用二叉搜索樹(紅黑樹)來實現。
 關于set的使用就不多說了關鍵看一些我們之前沒見到的接口
關于set的使用就不多說了關鍵看一些我們之前沒見到的接口

set的拷貝代價很大但是搜索的代價很小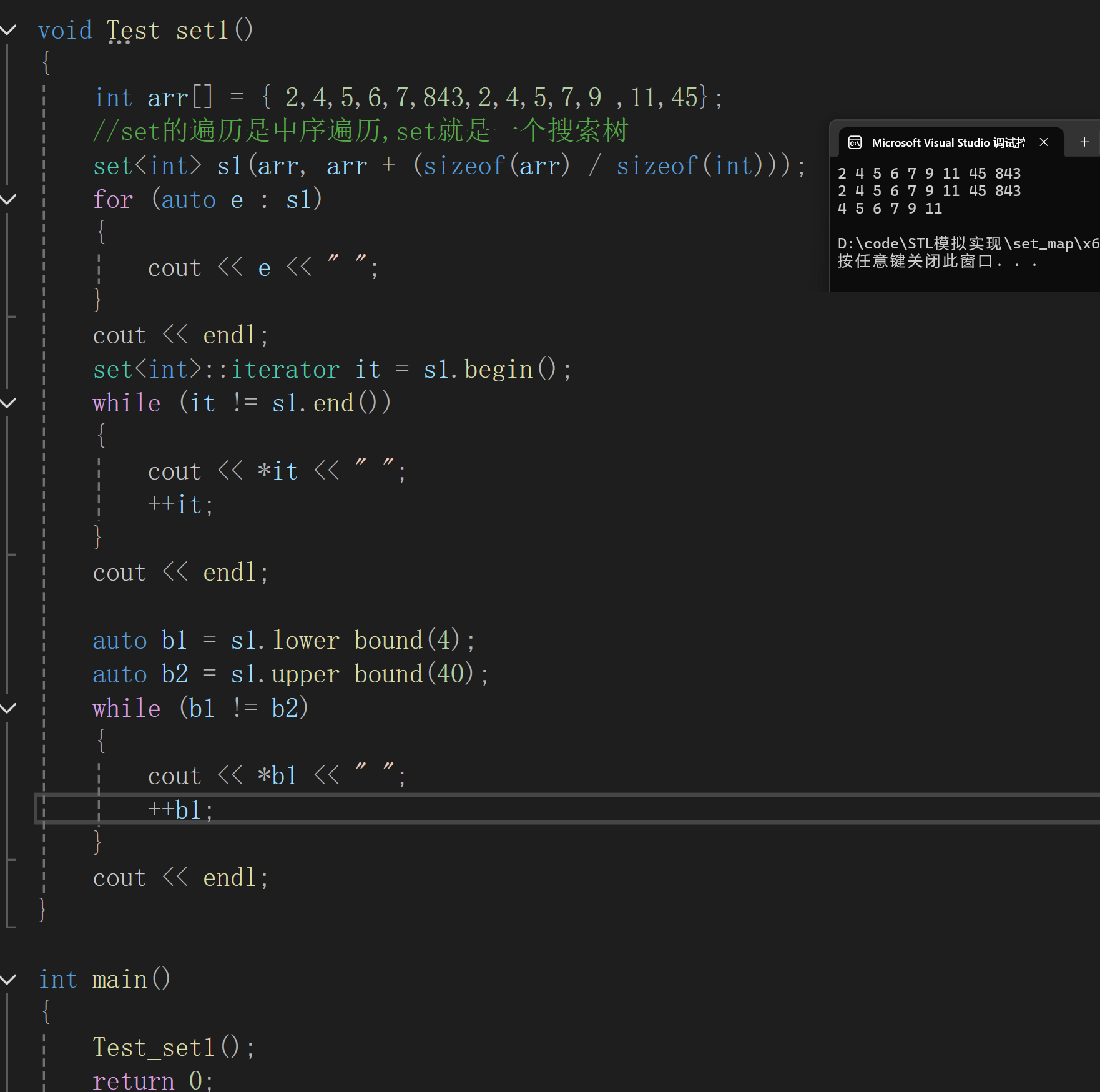
同時要注意這個lower_bound 和upper_bound? ?這兩個接口
這里是找這兩個區間的值
lower_bound(20)->就是找大于等于key = 25的節點
upper_bound(50)->就是找key>50的這個節點
這樣形成一個左閉右開的結構,才可以將我們給的區間里面的東西刪除完(迭代器里面的所有操作幾乎都是左閉右開的)
而這個count 和equal_range對于met是沒有什么意義的,應為set不允許重復,但是對于下面的multiset就很有意義了
3.2multiset
multiple:多樣的,其實這個multiset就是可以存儲重復的數據
multiset介紹multiset - C++ Reference


具體使用:
void Test_mutiset()
{int arr[] = { 2,4,5,6,7,843,2,4,5,7,9 ,11,45 };multiset<int> s1(arr, arr + (sizeof(arr) / sizeof(int)));for (const auto& e : s1){cout << e << " ";}cout << endl;//find查找(重復數據)返回中序的第一個multiset<int>::iterator it = s1.find(4);while (it != s1.end()){cout << *it << " ";++it;}cout << endl;cout << s1.count(2) << endl;pair<multiset<int>::iterator, multiset<int>::iterator> eq = s1.equal_range(2);while (eq.first != eq.second){cout << *(eq.first) << " ";++eq.first;}cout << endl;}這里的equal_range返回的是一個pair,我們一般用auto來接收,要不然要寫一大堆?
3.3map
講之前先學習一下pair
pair - C++ Reference
這個pair其實就是一個類(我們也喜歡叫鍵值對),里面有first和second兩個位置可以存儲數據,這就方便了,在key_value
(map)里面我們就把這兩個放到pair里面,這樣對于一個函數返回的時候返回一個pair也方便
map - C++ Reference
翻譯:
1. map是關聯容器,它按照特定的次序(按照key來比較)存儲由鍵值key和值value組合而成的元 素。
2. 在map中,鍵值key通常用于排序和惟一地標識元素,而值value中存儲與此鍵值key關聯的 內容。鍵值key和值value的類型可能不同,并且在map的內部,key與value通過成員類型 value_type綁定在一起,為其取別名稱為pair: typedef pair value_type;
3. 在內部,map中的元素總是按照鍵值key進行比較排序的。
4. map中通過鍵值訪問單個元素的速度通常比unordered_map容器慢,但map允許根據順序 對元素進行直接迭代(即對map中的元素進行迭代時,可以得到一個有序的序列)。
5. map支持下標訪問符,即在[]中放入key,就可以找到與key對應的value。
6. map通常被實現為二叉搜索樹(更準確的說:平衡二叉搜索樹(紅黑樹))。

map的插入就比較繁瑣,(單參數才能接受隱式類型轉化)

void Test_map()
{map<string,string> dict;//插入的方法pair<string, string> p1("insert", "插入");dict.insert(p1);dict.insert(pair<string,string>("right", "右邊"));dict.insert(make_pair("sort", "排序"));dict.insert({ "queue","隊列" });auto it = dict.begin();while (it != dict.end()){//pair沒有重載*所以打印的時候就訪問first,second//cout << (*it).first << ":" <<(*it).second << endl;cout << it->first << ":" << it->second << endl;++it;}cout << endl;
}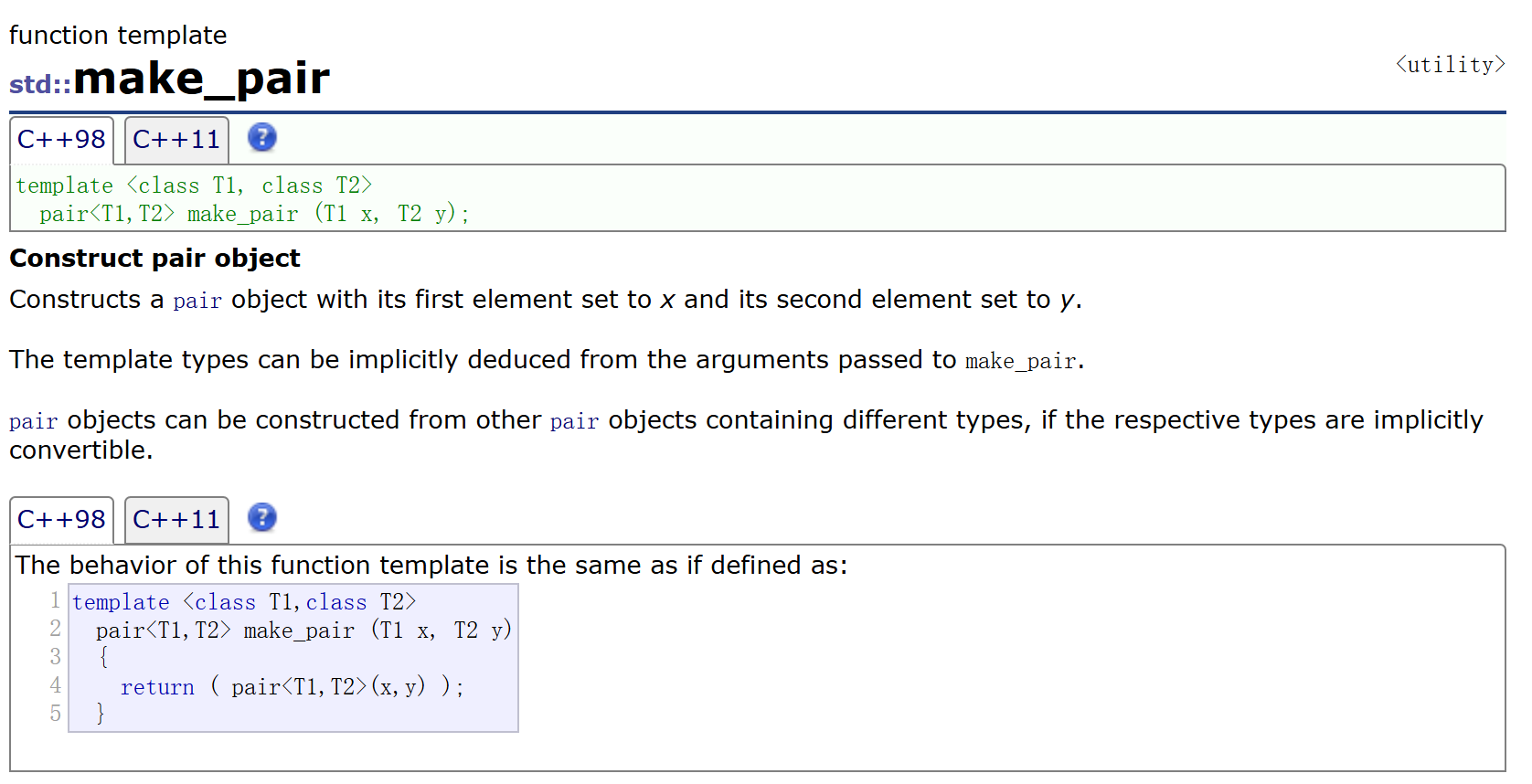
第三種也是比較常用的這個就是一個庫里面的一個函數,方便構造
最后一種插入方法其實就是隱式類型轉換
這里是c++11支持的,而c++98不支持
要注意:map和set里面的key都不能修改,因為改了話就改變了搜索樹的結構
set:直接將迭代器全搞為const迭代器,但是map不敢這樣搞,因為map要允許修改value
map:用pair來存(類模板)數據。
map的這個重載括號非常有用



【總結】
1. map中的的元素是鍵值對
2. map中的key是唯一的,并且不能修改
3. 默認按照小于的方式對key進行比較
4. map中的元素如果用迭代器去遍歷,可以得到一個有序的序列
5. map的底層為平衡搜索樹(紅黑樹),查找效率比較高O(log?N)
6. 支持[]操作符,operator[]中實際進行插入查找。
3.4multimap
multimap - C++ Reference

而這個multimap的插入就不會返回pair,顯然也沒有重載[],因為key可以重復,你如果還能返回
引用,返回的是誰的引用呢?(有很多數據冗余的)
3.5改進之前做的題
20. 有效的括號 - 力扣(LeetCode)
class Solution {
public:bool isValid(string s) {stack<char> st;map<char,char> matchMap;matchMap['('] = ')';matchMap['{'] = '}';matchMap['['] = ']';for(auto ch:s){if(matchMap.count(ch)){st.push(ch);}else{if(st.empty()){return false;}if(matchMap[st.top()]==ch){st.pop(); }elsereturn false;}}if(st.empty()){return true;}elsereturn false;}
};這樣就可以很方便控制比較邏輯?
138. 隨機鏈表的復制 - 力扣(LeetCode)
之前我們用c語言寫過
c語言的思路:
1拷貝節點鏈接到原鏈表的后面
2拷貝節點的random是源節點random指向的節點
3拷貝節點解下來 鏈接成一個新的鏈表 原鏈表恢復
之前就是先處理random指針,通過將拷貝節點放到原節點后面,就可以知道原節點random指針指向的節點的下一個就是拷貝節點random指向的那一個
有了map我們可以將Node*用map存起來
就是用一個map存節點(k)和拷貝節點(v)
那么k->random ==v->random,就可以鏈接上了
這一步很妙(k->random在map里面肯定可以找到拷貝節點的random)
class Solution {
public:Node* copyRandomList(Node* head) {//拷貝節點map<Node*,Node*> matchMap;Node* copyhead=nullptr;Node* copytail=nullptr;Node* cur = head;while(cur){if(copyhead==nullptr){copyhead = copytail = new Node(cur->val);}else{copytail->next = new Node(cur->val);copytail = copytail->next;}matchMap[cur]=copytail;cur = cur->next;}//處理randomcur = head;Node* copy = copyhead;while(cur){if(cur->random ==nullptr){copy->random = nullptr;}else{copy->random = matchMap[cur->random];}cur = cur->next;copy = copy->next;}return copyhead;}};代碼量大大減少!
349. 兩個數組的交集 - 力扣(LeetCode)
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {set<int> s1(nums1.begin(),nums1.end());set<int> s2(nums2.begin(),nums2.end());vector<int> v1,v2;vector<int> ret;for(const auto& e:s1){v1.push_back(e);}for(const auto& e:s2){v2.push_back(e);}size_t c1 = 0;size_t c2 = 0;while(c1!=v1.size() && c2!=v2.size()){if(v1[c1]<v2[c2]){c1++;}else if(v1[c1]>v2[c2]){c2++;}else{ret.push_back(v1[c1]);c1++;c2++;}}return ret;}
};同時還可以求兩個數組的交? 差? 并? 原理都是一樣的?
692. 前K個高頻單詞 - 力扣(LeetCode)
這題一看就是兩個排序,一個是頻率一個是字典序
1 用優先級隊列
2我們用map,k為字典,v為次數,全部入map后,k為唯一的
(1)我們將數據導出來
sort 不能對map排序,因為map不是隨機迭代器(快排里面有三數取中)
(2)數據導出來之后,string是按照字典序排序的 (map中序導出來(注意導出來的是pair))這時候就用sort去按照頻率排序,當然pair里面重載了比較但是他是先比較first的大小再比較second的大小,且升降序是一樣的,這樣就與我們的要求不同了,我們希望頻率是降序,string是升序,而且先比較頻率(second)那么我們可以用仿函數自己控制比較邏輯
還有一點,這里涉及排序的穩定性的問題,就是排序后改不改變其他元素的相對順序,從之前快排的實現我們可以知道,快排是不穩定的,那么排序后就會改變string的相對順序,這里庫里面提供了一個穩定的stable_sort,這個是穩定的可以用
或者我們可以想一個其他的方法
class Solution {
public:struct Greater{//這里我們控制sort的比較邏輯bool operator()(const pair<string,int>& p1,const pair<string,int>& p2){return p1.second>p2.second ||(p1.second==p2.second && p1.first<p2.first);}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> countMap;for(const auto& e:words){countMap[e]++;} vector<pair<string,int>> v1;for(const auto &e: countMap){v1.push_back(e);}stable_sort(v1.begin(),v1.end(),Greater());這里注意,我們已經控制比較邏輯,可以用不穩定的sortvector<string> v2;for(size_t i = 0;i<k;i++){v2.push_back(v1[i].first);}return v2;}
};


















