今天的最后一篇 車道線檢測系列結束
CLRKDNet:通過知識蒸餾加速車道檢測
摘要:道路車道是智能車輛視覺感知系統的重要組成部分,在安全導航中發揮著關鍵作用。在車道檢測任務中,平衡精度與實時性能至關重要,但現有方法往往顧此失彼。為此,我們提出了一種簡化的模型 CLRKDNet,可在檢測精度與實時性能之間取得平衡。最先進的模型 CLRNet 在多個數據集上均展現出卓越的性能,但由于其采用了特征金字塔網絡(FPN)和多層檢測頭架構,計算開銷較大。我們的方法簡化了 FPN 結構與檢測頭,并重新設計了這兩種架構,同時引入了一種新穎的師生蒸餾過程以及一系列新的蒸餾損失函數。這一組合方法可將推理時間最多縮短 60%,同時保持與 CLRNet 相當的檢測精度。這種在精度與速度之間的戰略性平衡,使 CLRKDNet 成為自動駕駛應用中實時車道檢測任務的可行解決方案。代碼和模型可在以下網址獲取:
https://github.com/weiqingq/CLRKDNet。
一、引言
車道檢測是智能交通(包括自動駕駛和高級駕駛輔助系統(ADAS))的關鍵組成部分。車道是道路交通的基本要素,劃分了車輛行駛路徑,有助于實現更安全、更順暢的駕駛條件。檢測方法主要分為基于模型和基于特征兩類。基于模型的方法利用預定義的車道模型,將車道識別視為參數估計問題,這有助于降低對噪聲的敏感性,并減少對大面積局部圖像區域的依賴。相比之下,基于特征的方法將圖像中的單個點分類為車道點或非車道點,依賴于邊緣梯度、寬度、強度和顏色等特定特征。然而,這種方法需要清晰的車道邊緣和強烈的顏色對比才能準確檢測。這兩種方法都遵循類似的步驟序列:感興趣區域(ROI)提取、圖像預處理、特征提取和車道擬合。隨著深度學習技術的出現,傳統車道檢測方法大多被更先進的端到端深度學習方法所取代。這些現代方法消除了手動特征工程的需求,增強了檢測系統的魯棒性和有效性。當代車道檢測技術可分為四類:基于分割的方法、基于參數曲線的方法、基于關鍵點的方法和基于錨點的方法。基于分割的方法將車道檢測視為語義分割任務;基于參數曲線的方法使用曲線參數建模車道,通過參數回歸進行檢測;基于關鍵點的方法將車道檢測視為關鍵點估計問題,隨后進行整合;最后,基于錨點的方法使用線形錨點,回歸這些預定義錨點的采樣點偏移量。盡管深度學習技術在車道檢測方面取得了相當大的進展,但仍有進一步提升的空間。車道線通常在圖像中延伸很長的像素段,并且在局部尺度上具有與路面明顯不同的特征,這凸顯了提取全局和局部特征以實現準確檢測的必要性。在 Zheng 等人的論文中,介紹了交叉層 refinement 網絡(CLRNet),利用高級語義特征和低級細節特征。它首先使用高級特征進行粗略定位,然后通過細節特征進行 refinement,以實現精確的車道定位。ROIGather 模塊通過將 ROI 車道特征與整個特征圖鏈接起來,進一步捕獲廣泛的全局上下文信息,與以往方法相比顯著提升了檢測性能。然而,CLRNet 的復雜性,包括其特征金字塔網絡(FPN)和多個檢測頭,增加了推理時間,阻礙了自動駕駛車輛所需的實時性能。為此,我們開發了 CLRKDNet,旨在減少推理時間的同時保持精度。CLRKDNet 簡化了 FPN 架構,采用簡化的特征聚合網絡,并減少了檢測頭的數量,從而消除了迭代 refinement 過程。該模型以 CLRNet 為教師模型,引入了一種新穎的知識蒸餾程序,以提升簡化的學生模型的性能,并抵消失敗檢測精度的潛在下降。這種多層蒸餾包括中間特征層、先驗嵌入和檢測頭 logits,確保 CLRKDNet 在顯著更快的速度下實現與 CLRNet 相當的檢測精度。更多詳細信息,請參見第三部分的方法部分。我們通過對 CULane 和 TuSimple 數據集進行廣泛實驗來驗證所提方法的改進,并報告了這兩個數據集上的最新結果。此外,全面的消融研究證實了框架中每個組件的有效性。我們的主要貢獻總結如下:
-
我們通過簡化 CLRNet 中的特征增強模塊并減少檢測頭的數量,顯著提高了計算效率,使推理速度最多提高了 60%。
-
我們提出了一種新穎的知識蒸餾技術,其中簡化的學生模型 CLRKDNet 利用教師模型 CLRNet 的中間特征層、先驗嵌入和最終檢測頭 logits 來提升其車道檢測能力。
-
我們在多個車道檢測數據集上進行了廣泛的實驗,以驗證所提方法 CLRKDNet 的有效性,并進行了全面的消融研究,以驗證每個模塊對模型性能的貢獻。
二、相關工作
(一)車道檢測
-
基于分割的方法 :基于分割的方法將車道檢測視為像素級分類任務,將車道線區域與背景分開。例如,SCNN 利用語義分割框架和消息傳遞機制來改善車道檢測中的空間關系,但其實時應用受到速度限制。同樣,RESA 通過實時特征聚合模塊提升性能,但由于像素級處理,計算需求仍然較高。
-
基于錨點的方法 :基于錨點的方法依賴預定義的線或行錨點來引導車道檢測。Line-CNN 和 LaneATT 使用帶注意力機制的線錨點來提高準確性和效率。相反,行錨點方法如 UFLD 和 CondLaneNet 具有簡單和快速的優點,但在復雜場景中由于難以準確識別初始車道點而可能表現不佳。CLRNet 及其擴展工作提出了一種跨層優化的車道檢測網絡,使用高級特征檢測車道線,并利用低級特征調整車道線位置。
(二)知識蒸餾
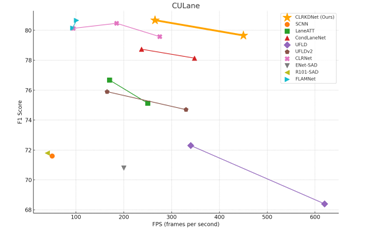
知識蒸餾涉及將復雜且通常笨重的模型的見解轉移到更緊湊、計算效率更高的模型,從而提升小型模型的性能和泛化能力。該技術最初由 Hinton 等人在 2015 年提出。多年來,它發展出許多方法,包括采用軟標簽和定制損失函數來優化學習過程。在計算機視覺中,知識蒸餾顯著提升了小型模型在目標檢測、圖像分類和分割等各種任務中的能力。在車道檢測領域,Hou 等人引入了自注意力蒸餾(SAD),采用自上而下和層次化的注意力蒸餾來增強表示學習和模型效能。值得注意的是,我們的蒸餾方法優于 SAD,在 CULane 數據集上的 F1 分數比其高出近 10 個百分點。
三、方法
(一)CLRKDNet
-
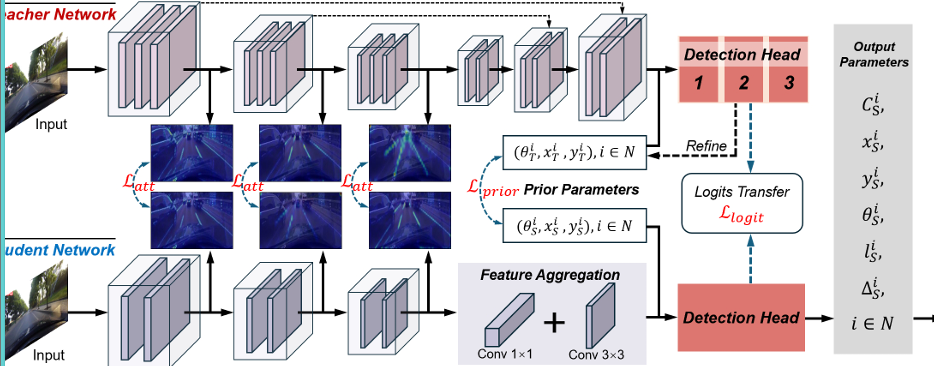
教師模型 :我們的方法采用復雜的 CLRNet 架構作為教師模型,它集成了 ResNet 或 DLA 等穩健的主干網絡。這種集成使主干網絡能夠提取深度特征,然后由特征金字塔網絡(FPN)處理,生成不同分辨率(包括輸入圖像尺寸的 1/8、1/16 和 1/32)的多尺度特征圖,從而全面表示全局內容和局部細節。CLRNet 通過配置具有可學習參數(xi,yi,θi)的先驗來啟動車道檢測,其中(xi,yi)定義起始坐標,θi 是相對于 x 軸的方向。符號 i 表示 M 個先驗中的一個,M 表示先驗的總數。這些先驗對于識別潛在車道路徑至關重要,通過在不同尺度的各種卷積層和全連接層中進行處理。如圖 2 所示,這種多層處理生成分類和回歸輸出以調整先驗。模型經過三次 refinement 循環,這些調整利用更高分辨率的特征圖重新校準先驗。交叉注意力機制在整個過程中整合上下文信息,最終精確計算多個水平行的 x 坐標以描繪車道路徑。為應對車道檢測的復雜性,CLRNet 采用全面的損失函數 L,結合 smooth L1 進行先驗 refinement,focal loss 進行分類,以及交叉熵損失進行分割。此外,專門設計的 LineIoU 損失函數專門增強車道預測的交并比(IoU)度量,提升模型精度。
-
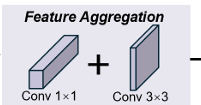
學生模型 :CLRKDNet 是 CLRNet 的簡化版本,旨在滿足自動駕駛應用對實時性的高要求,同時管理車道檢測性能。它利用 CLRNet 的先進網絡設計,包括其主干網絡和檢測頭機制,但在架構上進行了顯著優化以提高效率。在特征增強部分,CLRNet 通過 FPN 整合多尺度語義豐富的特征,而我們的 CLRKDNet 部署了一個輕量級特征聚合網絡以減輕計算負擔。如圖 2 所示,該網絡專門設計用于壓縮從主干網絡提取的特征的通道大小,增強特征的表示質量而不增加計算負擔。這一創新不僅大幅減少了權重參數數量,還縮小了計算占用空間,使特征集成過程更快速。CLRKDNet 的檢測頭也經過了效率優化。與 CLRNet 的多個檢測頭和可學習先驗(需要大量計算資源進行迭代 refinement)不同,我們的 CLRKDNet 采用單個檢測頭與固定先驗集。該單檢測頭利用一組靜態先驗,不進行昂貴的迭代 refinement 過程。圖 3 展示了單檢測頭的結構。實驗分析表明,這種簡化使 CLRKDNet 的推理速度最多提高了 60%,而評估分數僅略有下降。通過知識蒸餾進一步補償了由于簡化架構導致的檢測性能下降。我們提出的知識轉移方法利用從教師模型 CLRNet 的中間層蒸餾出的見解,以及先驗和檢測頭的最終輸出。通過這種多階段蒸餾過程,我們的 CLRKDNet 模型以較低的計算成本接近 CLRNet 設定的基準。
-
二)注意力圖蒸餾
-
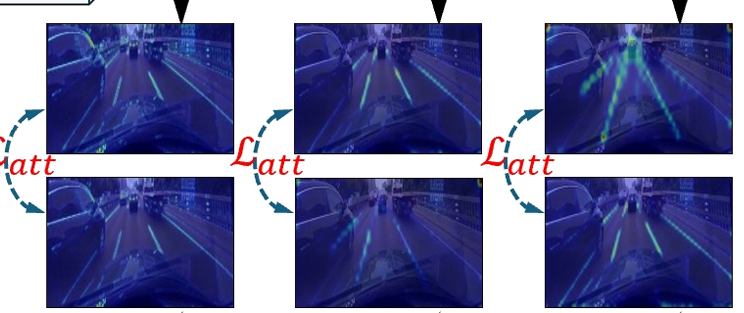
激活注意力轉移 :在車道檢測模型中,知識蒸餾通過基于激活的注意力機制實現。對于卷積神經網絡的第 n 層,我們提取激活輸出,表示為 An ∈ RCn×Hn×Wn,其中 Cn、Hn 和 Wn 分別對應激活張量的通道數、高度和寬度。為了將教師模型的知識蒸餾到學生模型,我們從這些激活張量中生成空間注意力圖。這些圖作為濃縮表示,突出顯示模型認為輸入圖像中最關鍵的區域。通過應用映射函數 Gsump(An)= ΣCn j=1 |An,j|p,其中 An,j 表示 An 在通道維度上的第 j 個切片,p > 1,來蒸餾這些注意力圖。參考其他文獻,我們選擇 p = 2 以加強關注最顯著的特征,從而引導學生模型的注意力方向,類似于教師模型的方向。圖 2 展示了這一注意力圖蒸餾過程。在整個訓練階段,學生模型的注意力圖逐漸調整以匹配教師模型的注意力圖,并通過損失函數最小化差異。
-
注意力轉移損失 :在車道檢測模型中,注意力圖的蒸餾通過注意力轉移損失函數量化,該函數專門測量學生模型和教師模型注意力圖之間的差異。對于集合 N(表示每個教師 - 學生激活層對的索引)中索引為 n 的每一層,首先將學生模型的注意力圖 ASn 和教師模型的注意力圖 ATn 轉換為向量形式,分別表示為 QS n 和 QT n。這些向量形式是通過將激活張量應用映射函數 G 并將得到的注意力圖重塑為向量產生的。 Latt = Σn∈N ||QS n / ||QS n||2 ? QT n / ||QTn||2||p 其中 QS n = vec(G(ASn))和 QT n = vec(G(ATn))分別是學生模型和教師模型第 n 對注意力圖的向量化形式。||?||2 表示 ?2 范數,用于標準化每個向量化的注意力圖,確保損失計算不受注意力圖尺度的影響,僅關注其模式。參數 p 設置為 2,與注意力圖計算中使用的二次映射函數 G 一致,這已被證明可以有效促進知識轉移。
(三)檢測頭上的知識轉移
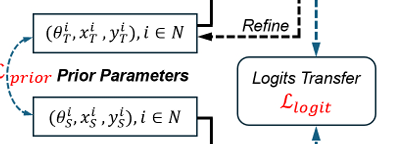
在注意力圖蒸餾過程之后,我們旨在進一步提高檢測精度并縮小模型之間的差距。為此,我們提出了一種用于檢測頭的雙重蒸餾程序,包括先驗嵌入蒸餾和 logits 蒸餾。這些機制確保 CLRKDNet 盡管架構簡化,仍能有效保留教師模型 CLRNet 的復雜檢測能力。先驗嵌入蒸餾使學生模型的先驗與教師模型的精煉輸出對齊,而 logits 蒸餾則測量并最小化輸出 logits 的差異,引導 CLRKDNet 的預測盡可能接近 CLRNet 的預測。先驗嵌入蒸餾:CLRNet 和 CLRKDNet 都使用嵌入先驗初始化其檢測頭,這些先驗定義了車道線的幾何參數,包括初始坐標(xi,yi)和相對于 x 軸的方向 θi。這些先驗和由主干網絡和特征融合網絡生成的特征圖引導 ROI 模塊為每個車道像素準確收集附近的特征。這一收集過程結合全局內容和豐富的語義信息,確保全面的檢測能力。雖然 CLRNet 在其檢測頭的各個層中迭代地精煉這些先驗,但 CLRKDNet 直接使用一組這些先驗進行檢測輸出。通過比較學生模型的初始先驗和教師模型的精煉先驗之間的嵌入來完成這些先驗的蒸餾。具體而言,嵌入被格式化為 [M,3] 維度的張量,其中 M 表示初始先驗的數量,使用 L2 范數損失函數進行比較: Lprior = ΣM i=1 ||Pi S ? Pi T ||2 其中,Pi S 和 Pi T 分別表示學生模型和教師模型的第 i 個先驗向量,每個向量都包含初始坐標和方向(xi,yi,θi)。這種 L2 范數比較測量每對對應先驗之間的歐幾里得距離,有效使 CLRKDNet 的靜態先驗與 CLRNet 的動態精煉先驗對齊。這種對齊確保學生模型從與教師模型迭代過程輸出相當的精煉水平開始,有效彌合了兩種模型在動態精煉能力上的差距。Logit 蒸餾:Logit 蒸餾關注檢測頭的最終輸出,在將模型輸出轉換為預測線之前。如圖 3 所示,這些 logits 包括分類分數和幾何特征,例如起始坐標(xi,yi)、方向 θi、車道長度 li 以及預測車道與車道先驗之間的水平偏移差 ?xi。Logit 蒸餾過程包括將學生模型檢測頭的邏輯輸出與教師模型的邏輯輸出進行比較,并計算均方誤差(MSE)以測量和最小化它們之間的差異。這種損失確保 CLRKDNet 的簡化檢測頭(缺乏 CLRNet 的多個精煉階段)仍能產生高精度的輸出。MSE 對大差異敏感,特別有效微調學生模型的輸出以盡可能接近教師模型的輸出,從而補償了迭代精煉層的缺失。這種特定損失表示為: Llogit = 1/M ΣM i=1 [(xi S ? xi T )2 + (yi S ? yi T )2 + (θi S ? θi T )2 + (li S ? li T )2 + (?xi S ? ?xi T )2] 其中 M 是先驗的數量。xi S,yi S,θi S,li S,?xi S 是學生模型檢測頭的幾何輸出,包括起始坐標、方向、長度和水平差異。xi T,yi T,θi T,li T,?xi T 是教師模型的相應輸出。
損失函數





】Eureka單個服務端的搭建(含源代碼)(三))








)


Docker容器詳細講義)

