https://github.com/QwenLM/Qwen3/blob/main/Qwen3_Technical_Report.pdf
節前放模型,大晚上的發技術報告。通義,真有你的~
文章目錄
- 預訓練
- 后訓練
- Long-CoT Cold Start
- Reasoning RL
- Thinking Mode Fusion
- General RL
- Strong-to-Weak Distillation
- 模型結構

先看下摘要里提到的幾個亮點:
-
包括Dense和Moe模型,參數量橫跨0.6B到235B。
Dense包括:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B。
Moe包括:- Qwen3-235B-A22B,235B 總參數和 22B 激活參數的大型MoE模型。
- Qwen3-30B-A3B,30B 總參數和 3B 激活參數的小型MoE模型。
-
把thinking和non-thinking模式集成在一個模型中。并且,只需要在提示詞中就能進行兩個模式的切換。
-
多語言支持,從29種到119種。
在Qwen3發布的當天,筆者就趕緊在自己的任務上嘗試了新發布的模型,就我的任務而言相比Qwen-2.5來說還是有比較明顯的提升的。終于等到技術報告發布了,趕緊來看看~
目錄:
- 預訓練
- 后訓練
- Long-CoT Cold Start
- Reasoning RL
- Thinking Mode Fusion
- General RL
- 模型結構
預訓練
在更大規模的數據上進行了預訓練,語言擴充到了119種,token數達到了36萬億!Qwen2.5則只有18萬億個。
怎么擴充到這么大規模的預訓練數據?
- 多模態的方案。使用微調后的Qwen2.5-VL提取PDF中的文本。
- 合成數據。使用Qwen2.5-Math和Qwen2.5-Coder合成數學、代碼領域的數據。
為了提高數據的質量和多樣性,開發了一個多語言的數據標注系統。使用該系統對訓練數據集進行了詳細的標注,覆蓋了多個維度,包括教育價值、領域、主題和安全性等。這些標注信息會被用于過濾和組合數據。
預訓練分成三個階段:
- General Stage,S1。
模型在 30 萬億個 token 上進行預訓練,上下文長度為 4K token。為模型提供了基本的語言技能和通用知識。 - Reasoning Stage,S2。
通過增加知識密集型數據(如 STEM、編程和推理任務)的比例來增強模型的推理能力,隨后模型又在額外的 5 萬億個 token 上進行了預訓練。 - Long Context Stage,最后階段。
使用高質量的長上下文數據將上下文長度擴展到 32K token,確保模型能夠有效地處理更長的輸入。這一階段的數據種,75%的樣本長度在16k-32k,25%在4k-16k。
后訓練
四階段的后訓練流程,以對齊人類偏好和下游任務。
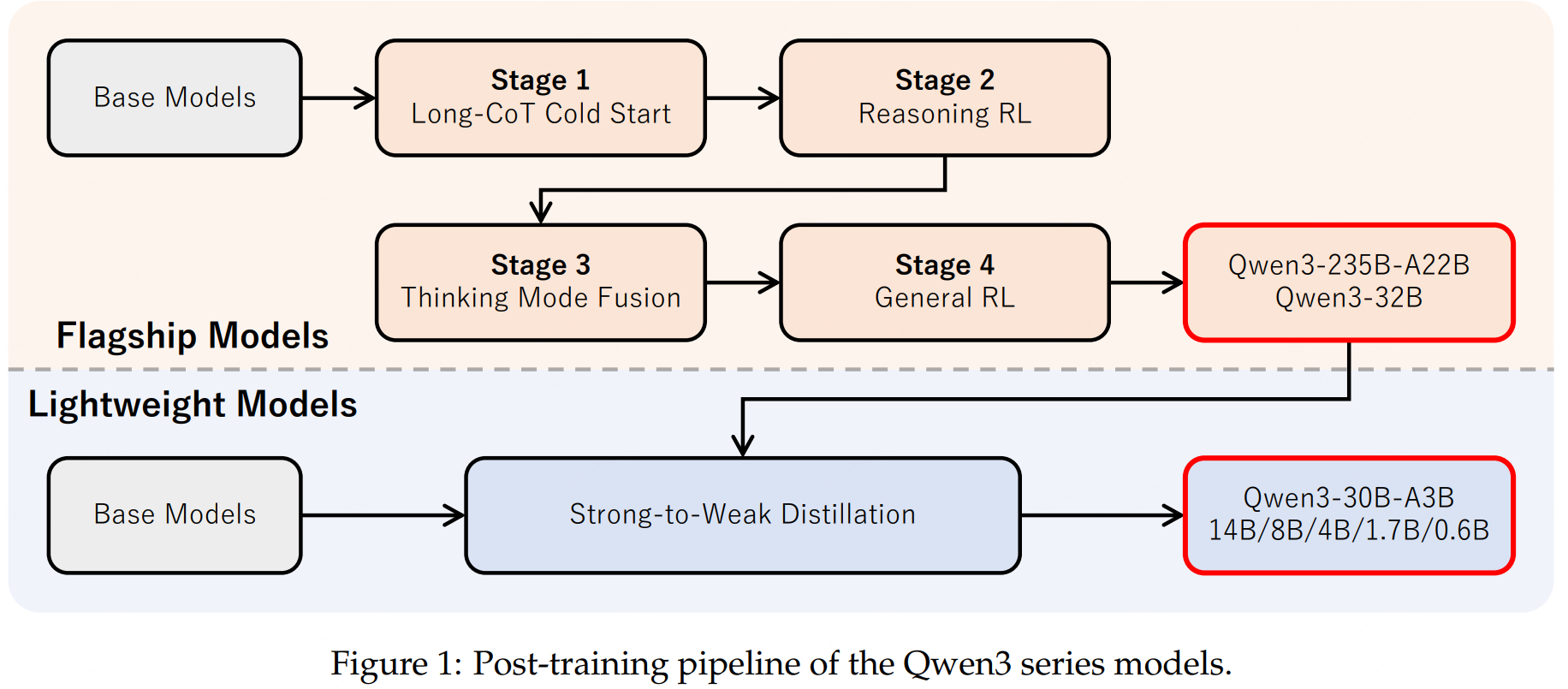
- Long-CoT Cold Start,長思維鏈冷啟動。
使用多樣的的長思維鏈數據進行微調,涵蓋了數學、代碼、邏輯推理和 STEM 問題等多種任務和領域,在為模型配備基本的推理能力。 - 長思維鏈強化學習。
大規模強化學習,利用基于規則的獎勵來增強模型的探索和鉆研能力。 - 思維模式融合。
在一份包括長思維鏈數據和常用的指令微調數據的組合數據上對模型進行微調,將非思考模式整合到思考模型中。通過一個token(/no_think)來進行模式的切換。 - 通用強化學習。
在包括指令遵循、格式遵循和 Agent 能力等在內的 20 多個通用領域的任務上應用了強化學習,以進一步增強模型的通用能力并糾正不良行為。
另外,可以看到,Qwen3-235B-A22B和Qwen3-32B是按照上面四階段的后訓練流程訓的,其他模型則是在這兩個的基礎上蒸餾出來的。看看每個階段的一些重點。
Long-CoT Cold Start
使用的數據,包括數學、代碼、邏輯推理和STEM,數據集里的每個問答樣本都有參考答案、代碼樣本都配備測試樣例。
數據怎么怎么構造的?嚴格的兩階段的過濾過程:query過濾和response過濾。
-
query過濾。
- 使用Qwen2.5-72B-Instruct識別并過濾那些難以驗證的query,例如包含多個子問題或通用文本生成的query。
- 此外,還過濾了Qwen2.5-72B-Instruct無需cot就能正確回答的問題,以確保數據集中只包含需要深度推理的問題。
- 并且使用Qwen2.5-72B-Instruct標注了每個query的領域,以確保數據領域的均衡。
-
response過濾。
- query過濾后,使用QwQ-32B為每個query生成多個候選響應。
- 對于QwQ-32B無法生成正確解決方案的查詢,由人工標注員評估響應的準確性。進一步的篩選標準包括移除最終答案錯誤、重復過多、明顯猜測、思考與總結內容不一致、語言混用或風格突變、以及可能與驗證集項目過于相似的響應。
Reasoning RL
這一階段的數據必須滿足的要求:
- 在上一階段沒有使用過。
- 對于冷啟動模型是可以學習的。
- 要有挑戰性。
- 覆蓋廣泛的子領域。
最終收集了3995(才這么點數據?🤔)個query-verfier pair進行GRPO訓練。
在訓練策略上,通過控制模型的熵(即模型輸出的不確定性)來平衡探索和利用。熵的增加或保持穩定對于維持穩定的訓練過程至關重要。
Thinking Mode Fusion
這一階段的目標是實現對推理行為的管理和控制,即think和no-think的切換,通過SFT實現,并且設計了chat template融合兩種模式。
SFT數據怎么構建的?
為了確保上一步得到的模型的性能不被SFT影響,thinking的數據是使用第一階段的query在第二階段的模型上做拒絕采樣得到的。non-thinking的數據則是精心篩選(具體怎么做的沒有細說)的涵蓋大量任務的數據,例如代碼、數學、指令跟隨、多語言任務、創意寫作、問答和角色扮演等。對于non-thinking的數據,通過自動生成的checklist來評估響應的質量。
兩類數據的模板:
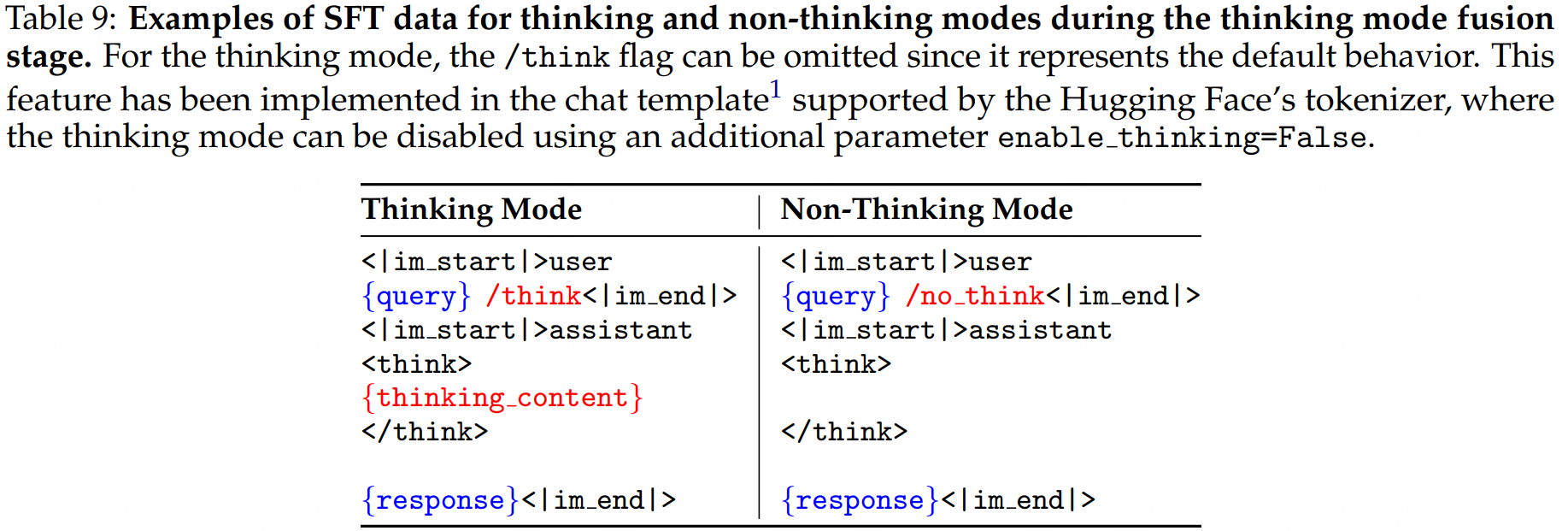
默認情況下是開啟think模式的,為此還在訓練數據中添加了一些不包含/think的帶思考過程的樣本。
此外,還通過訓練實現了模型生成時自動進行預算控制(Thinking Budget)。一種具體的情況——不完整的思考過程下也能正常回答問題。在推理時,用戶可以指定一個budget,當模型的思考過程達到了指定的閾值時,則手動停止思考過程,并插入停止思考的指令,讓模型直接開始回答問題。

General RL
重點在獎勵的設計上,覆蓋了20種不同的任務。一共有三種類型的獎勵:
- Rule-based Reward。
- Model-based Reward with Reference Answer。用Qwen2.5-72B-Instruct對模型的回答和參考答案進行打分。
- Model-based Reward without Reference Answer。對于沒有標準答案的樣本,利用偏好數據訓練了一個打分模型對模型回答打分作為標量獎勵。
特別的,這一階段訓練了模型的Agent的能力,在RL的Rollout時,允許模型和外部環境進行多輪的交互。
Strong-to-Weak Distillation
前面的這四個階段使用來訓Qwen3-235B-A22B和Qwen3-32B的,其余的小模型都是在這個階段蒸餾得到的。蒸餾時有兩個階段:
-
Off-policy Distillation。
使用強模型(Qwen3-32B或Qwen3-235B-A22B)在思考模式和非思考模式下的生成,將這些輸出作為弱模型的訓練目標。 -
On-policy Distillation。
在思考和非思考模式下,從弱模型中采樣,通過最小化弱模型和強模型輸出之間的KL散度對弱模型進行微調。
感覺論文種講的不是很清楚。
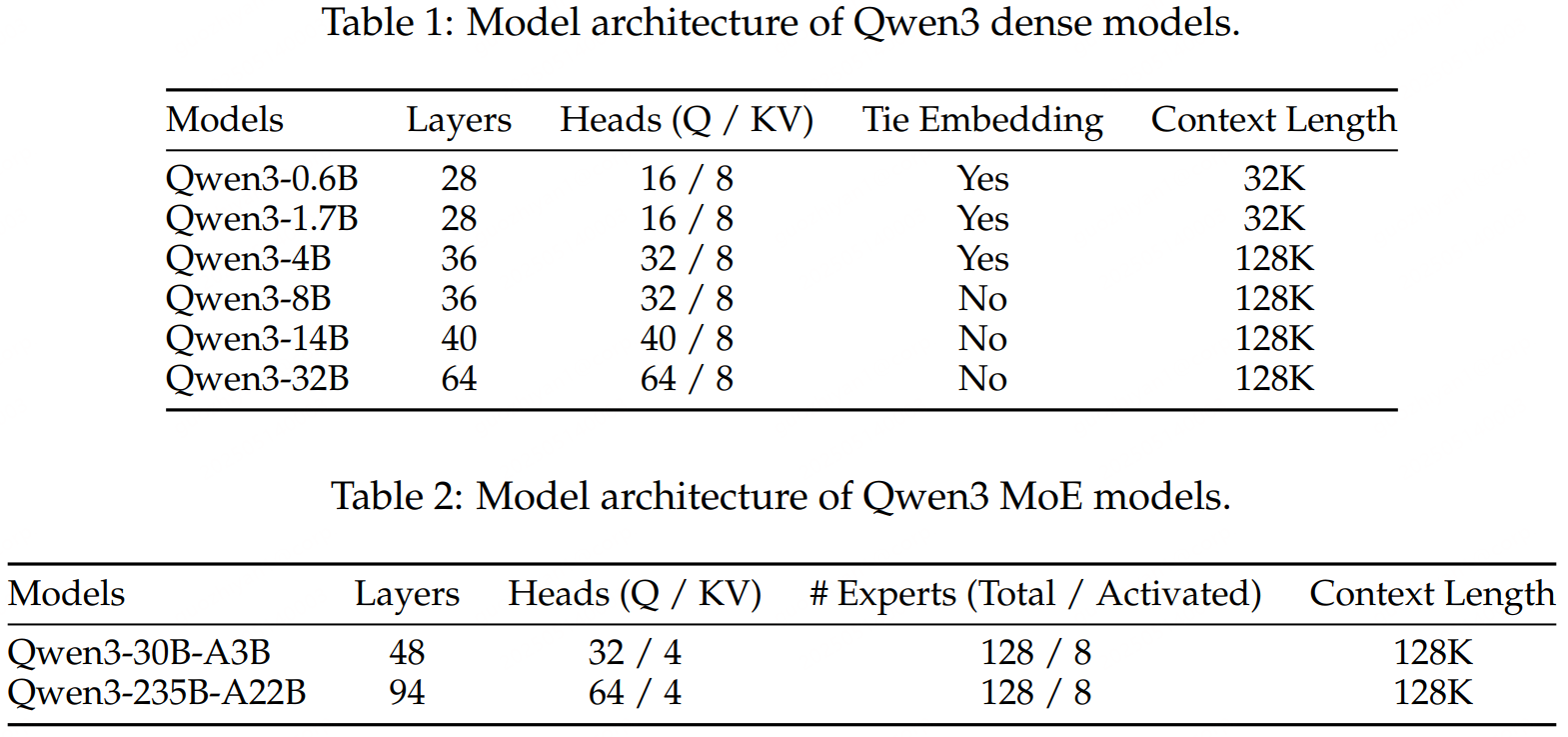
模型結構
Dense模型與Qwen2.5的模型結構類似,包括使用了GQA、SwiGLU、RoPE、RMSNorm和pre-normalization。不同之處:去除了QKV-bias、引入了QK-Norm。MoE模型的基礎架構和Qwen3 Dense是一樣的。
Dense和MoE的模型架構如下所示:


】Eureka單個服務端的搭建(含源代碼)(三))








)


Docker容器詳細講義)




