DIY AI & ML NLP — Tokenization & Text Similarity by Jacob Ingle in Data Science Collective
本文所使用的數據是在 Creative Commons license 下提供的。盡管我們已盡力確保信息的準確性和完整性,但我們不對數據的完整性或可靠性做任何保證。數據的使用符合相應許可條款,第三方使用時應遵守原始許可要求。
讀者被鼓勵查看與數據集相關的具體 Creative Commons license,以了解允許的使用、修改和署名要求的詳細信息。
系列文章回顧
向所有 DIY AI & ML 系列的讀者們問好!這是一段令人難以置信的旅程,我們才剛剛開始。如果你想查看到目前為止的任何文章,請見下方!
線性回歸
邏輯回歸
K-Means
決策樹
自然語言處理
你有沒有想過,生成式 AI 工具或大型語言模型背后究竟發生了什么?自然語言處理(NLP)是這些工具的核心,它使計算機能夠理解人類語言。換句話說,NLP 是連接人類交流和機器(如計算機)的橋梁。因此,它是任何生成式 AI 工具的重要組成部分。
在本文中,我們將構建一個簡單的 Python NLP 對象,它接受一組文檔,執行各種標準的 NLP 預處理技術,最后,允許終端用戶輸入新的文檔或文本,并從之前上傳的文檔組中提取最相似的文本。
分詞與預處理
每個機器學習管道、數據科學項目和探索性數據分析任務都需要數據清洗或預處理步驟,自然語言處理也不例外。當我開始學習 NLP 時,我記得被從表格數據轉換為實際單詞的格式所淹沒。了解這一點后,讓我們逐步分解 NLP 任務中清理文本數據的各個部分。
分詞將文本分解為更小的單元,如單個單詞或字符。讓我們來看一個例子,我們在一個句子上執行分詞:
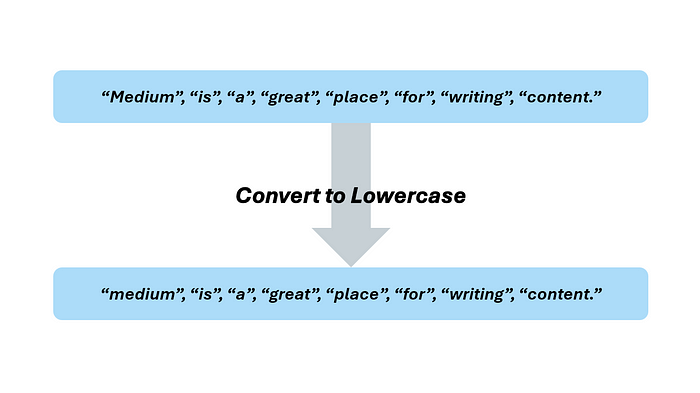
“Medium is a great place for writing content.”
分解成單個單詞或 tokens 后,它看起來像這樣:
“Medium”, “is”, “a”, “great”, “place”, “for”, “writing”, “content.”
開始將這段文本視為數據集中的一個觀測值,并將每個單詞視為一個二進制列。因此,對于這個句子,所有這些單詞的列都將為 1 或 True,對于所有其他單詞或 tokens,它將是 0 或 False。我有點超前了,但如果你是 NLP 新手,早點這樣思考會很有幫助。
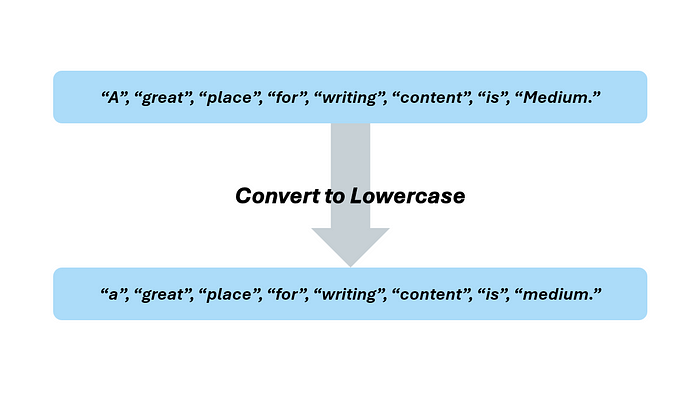
現在分詞步驟完成了,讓我們學習如何預處理文本數據。假設我們還有另一個句子,內容如下:
“A great place for writing content is Medium.”
分詞后,它將讀作:
“A”, “great”, “place”, “for”, “writing”, “content”, “is”, “Medium.”
從人類交流的角度來看,這兩個文本幾乎完全相同,并且傳達了相同的信息。然而,NLP 是關于構建人類交流和計算機之間的橋梁,計算機可能會將這些句子視為完全不同。你正在構建的 NLP 應用程序或工具的最終產品將決定你需要對文本進行何種預處理。我們將在本文中創建一個相似度模型,因此我們要確保用于訓練該模型的文本是經過適當預處理的。
第一步是將所有內容轉換為小寫。注意單詞 “a” 在每個陳述中都被用作一個單詞。然而,在一個句子中它被大寫,而在另一個句子中是小寫。通過將所有內容轉換為小寫,計算機或 NLP 模型將理解這些是同一個標記的兩個實例,而不是兩個不同的標記。
作者提供的圖片
作者提供的圖片
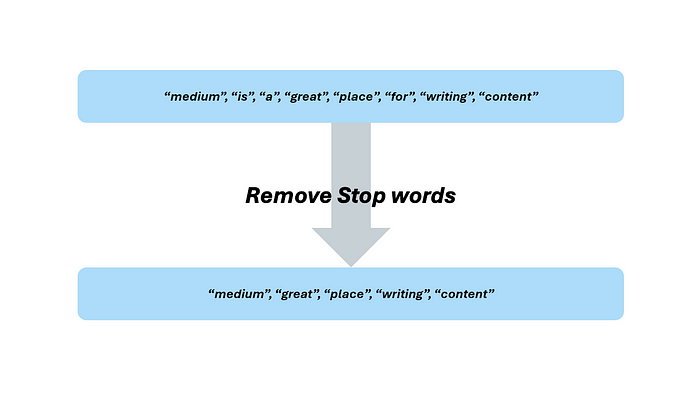
你是否已經開始像 NLP 實踐者那樣思考了?換句話說,你是否已經開始理解我們所看到的與計算機所看到的之間的聯系,以及它如何適用于我們的相似性引擎?想想我們可以在數據中去除的噪聲。對于 NLP 來說,去除噪聲的最常見技術是去除在大多數文本中出現的填充詞或常見詞。我們稱這些為“停用詞”。注意,這一步可能非常主觀。然而,有許多開源庫允許你下載一個停用詞列表,你可以在你的 NLP 應用程序中使用。本著從頭開始構建我們的對象的精神,我們將創建我們自己的停用詞列表。為什么我們應該關心去除停用詞?將停用詞視為在數據集中每個觀測值中都出現且沒有明顯模式的數據點。如果數據集中的每個觀測值都有這樣一個沒有明顯模式的目標的數據點,那么它只會為我們的模型增加噪聲,甚至可能阻礙它。在 NLP 應用程序中,停用詞也不例外。
作者提供的圖片
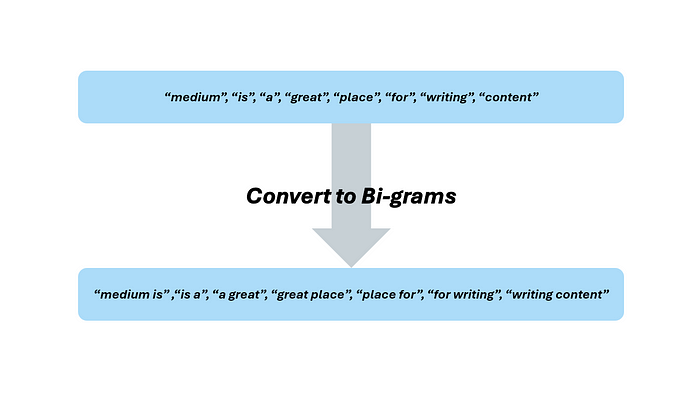
讓我們繼續一個更高級的文本數據預處理方法:創建 n-grams。回到停用詞,你應該總是去除它們嗎?這取決于你的數據上下文和你的 NLP 模型。有時,停用詞可能會根據它們在文本行中的位置提供必要的上下文。
目前,我們的數據將是順序無關的。換句話說,將我們的分詞文本輸入模型會將多個句子中的同一個單詞的多個實例視為相同,不管它在句子中的使用方式和位置如何。為了捕捉這些細微差別,我們可以將標記轉換為 n-grams。例如,假設我們想要捕捉我們正在處理的句子中的每個兩個單詞的短語,更正式地說,就是二元組(bigrams)。我添加了停用詞,看看包含它們的分詞文本在應用二元組后會是什么樣子。
作者提供的圖片
現在,單詞的順序很重要了!這種增加的復雜性可以捕捉文本數據中的細微差別,使我們的相似性引擎更加精確。我們甚至可以將文本轉換為三元組(trigrams)、四元組(quadragrams)等。注意,這可能會使你的 NLP 應用程序或模型變得復雜、計算成本高昂,甚至冗余。因此,一些 NLP 庫中有內置邏輯,規定只有當 n-gram 在一定比例的文檔中存在時,才能創建它。這種效率確保你不會執行任何冗余的預處理。我在這里談論去除停用詞和創建 n-grams 也不是巧合。這兩種技術的預處理順序將顯著影響你的模型。
詞袋模型(Bag-of-Words Model, BOW)
我們可以開始構建人類語言和計算機之間的橋梁了。我們回顧了清理文本數據的技術,現在將把它轉換成計算機可以理解的格式。
詞袋模型 是將文本建模成計算機或應用程序可以理解的最簡單方式。它只是查看文檔集合(也稱為 語料庫)中的所有唯一標記,并將每個文檔轉換為語料庫中每個標記的計數集合。讓我們來看一個假設的例子,語料庫包含三個文檔。

作者提供的圖片
首先,讓我們從這些文檔中提取所有唯一的標記,這也就是所謂的 詞匯表。

接下來,我們將每個文檔轉換為一個 詞袋 向量。為此,我們取詞匯表,并為文檔和詞匯表中都出現的每個單詞標記 1,否則為 0 。這個過程應該與對分類數據進行虛擬編碼或獨熱編碼非常相似。
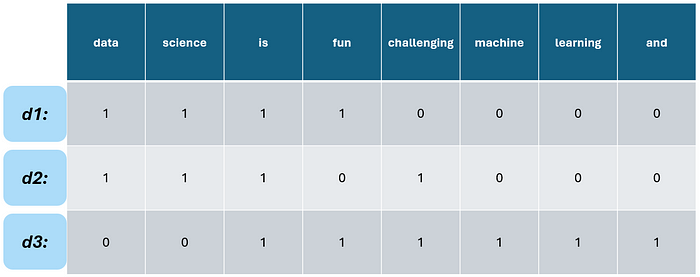
僅此而已。這應該與對分類數據進行虛擬編碼或獨熱編碼非常相似。
余弦相似度
在創建我們的對象之前,是時候討論我們相似性引擎的核心數學原理了,即 余弦相似度。它通過計算兩個向量之間的夾角的余弦值來衡量兩個向量之間的相似度。在我們將文本轉換為 詞袋 向量之前,這聽起來可能會更瘋狂一些。余弦相似度 是衡量文本相似度的絕佳選擇,因為它可以讓我們感受到文檔之間的相似性,而不管一個文檔是否比另一個大得多。它有助于捕捉提供相似上下文或總體信息的相似文檔。余弦相似度 的分數范圍從 -1 到 1,其中 1 表示最相似,0 表示沒有相似性,-1 表示兩個文檔完全相反,我應該指出,使用 TF-IDF 分數計算的詞袋向量中這種情況很少見。讓我們來看看兩個向量 A 和 B 之間的余弦相似度公式。
cos ? ( θ ) = A ? B ∥ A ∥ ∥ B ∥ \cos(\theta) = \frac{A \cdot B}{\|A\| \|B\|} cos(θ)=∥A∥∥B∥A?B?
作者提供的圖片
在分子中,我們取兩個向量的點積,在分母中,我們取兩個向量的模的乘積。

在這個假設的例子中,我們可以看到,根據余弦相似度指標,兩個向量 A 和 B 非常相似;換句話說,它們的方向幾乎相同。
DIYSimilarityEngine 類
盡管這個對象的名字如此,但大多數方法將致力于分詞、預處理文本數據以及構建袋裝詞向量。通常,這些步驟是在構建一些基于 NLP 的模型之前通過其他庫和框架完成的。然而,將這些步驟整合到同一個對象中是實用的。我應該指出,常見的 NLP 預處理框架,如 nltk 和 spacy,將提供比你在這里看到的更高級的技術,因為我的目標是在基礎水平上展示這些,以便讀者能夠獲得堅實的基礎。
import pandas as pd
import re
import math
from collections import Counterclass DIYSimilarityEngine:def __init__(self, ngram_n=1, stopwords=None):self.ngram_n = ngram_nself.stopwords = set(stopwords) if stopwords else set(['the', 'is', 'at', 'which', 'on', 'a', 'an', 'and', 'in', 'it', 'of', 'to', 'with', 'as', 'for', 'by'])self.documents = []self.vocabulary = set()self.bow_vectors = []
_preprocess 和 _generate_ngrams 方法
我們的前兩個方法對文檔列表中的每個文檔進行預處理和分詞。注意,創建 n-grams 的方法是在預處理方法中調用的。注意調用的順序。首先,將文本轉換為小寫,去除標點符號,執行分詞,最后,將標記轉換為 n-grams,它們仍然是標記。始終在去除你認為是噪聲的文本(如停用詞)之后,將文本轉換為 n-grams。
def _preprocess(self, text):# 將文本轉換為小寫text = text.lower()# 去除標點符號text = re.sub(r'[^\w\s]', '', text)# 分詞tokens = text.split()# 去除停用詞tokens = [t for t in tokens if t not in self.stopwords]if self.ngram_n > 1:# 如果需要,生成 n-gramstokens = self._generate_ngrams(tokens, self.ngram_n)return tokensdef _generate_ngrams(self, tokens, n):# 生成 n-gramsreturn ['_'.join(tokens[i:i+n]) for i in range(len(tokens)-n+1)]
_build_vocabulary、_vectorize 和 fit 方法
這兩個方法基于現在分詞后的文檔列表構建一個唯一的標記集合;同樣,這也就是我們袋裝詞模型的 詞匯表。有了 詞匯表,_vectorize 方法利用 collections 庫中的 Counter 方法為分詞后的文檔構建一個袋裝詞向量,該文檔以 1 和 0 的列表形式表示。
這兩個方法和 _preprocess 方法一起在 fit 方法中使用,以將模型的詞匯表分配給詞匯表屬性,并將所有的袋裝詞向量分配給其屬性。
def _build_vocabulary(self, tokenized_docs):vocab = set()for tokens in tokenized_docs:vocab.update(tokens)return sorted(vocab)def _vectorize(self, tokens, vocab):tf = Counter(tokens)return [tf[word] for word in vocab]def fit(self, documents):self.documents = documentstokenized = [self._preprocess(doc) for doc in documents]self.vocabulary = self._build_vocabulary(tokenized)self.bow_vectors = [self._vectorize(tokens, self.vocabulary) for tokens in tokenized]
_cosine_similarity 和 most_similar 方法
這兩個方法是我們對象的核心,但如果沒有之前的預處理,它將一無是處。記住,在調用 most_similar 方法之前,必須先將語料庫擬合到對象中。這個方法接受一個新文檔,對其進行預處理,然后利用 _cosine_similarity 方法來確定語料庫中哪些文檔最相似,通過返回一個列表,其中包含最相似的前三個文檔及其相關的余弦相似度分數,以便用戶能夠了解它們的相似程度。
def _cosine_similarity(self, vec1, vec2):# 計算兩個向量的點積dot_product = sum(a*b for a, b in zip(vec1, vec2))# 計算向量的模norm1 = math.sqrt(sum(a*a for a in vec1))norm2 = math.sqrt(sum(b*b for b in vec2))if norm1 == 0 or norm2 == 0:return 0.0return dot_product / (norm1 * norm2)def most_similar(self, query, top_n=3):# 對查詢文本進行預處理query_tokens = self._preprocess(query)# 將查詢文本轉換為袋裝詞向量query_vector = self._vectorize(query_tokens, self.vocabulary)# 計算查詢向量與語料庫中每個文檔向量的余弦相似度similarities = [(i, self._cosine_similarity(query_vector, bow_vector))for i, bow_vector in enumerate(self.bow_vectors)]# 按相似度降序排序similarities.sort(key=lambda x: x[1], reverse=True)# 返回最相似的前 top_n 個文檔及其相似度分數return [(self.documents[i], sim) for i, sim in similarities[:top_n]]
現實世界應用:尋找最佳工作
無論當前就業市場的狀況如何,了解一個人憑借其技能和經驗最有可能獲得哪些工作機會總是有益的,特別是對于數據科學家和類似職業。使用我們的相似性引擎對象,我們將對其進行測試,通過創建一個概述個人經驗和技能集的假設文檔,并使用來自 Kaggle 的 2023 數據科學家職位描述數據集 來查看哪個工作最匹配。
讓我們先為一個有五年數據分析師經驗的候選人編寫描述和技能集:
經驗豐富的數據分析師,擁有 5 年通過數據驅動的決策制定提供可操作見解的經驗。熟練掌握 SQL、Excel 和 Tableau、Power BI 等可視化工具,具有扎實的 Python 高級分析基礎。證明了設計和自動化報告儀表板、進行統計分析以及跨職能合作以支持業務戰略的能力。擅長識別趨勢、優化流程以及以清晰、有影響力的方式傳達復雜發現。
讓我們先初始化對象的一個實例,并擬合 Jobs 數據集中的職位描述。
nlp = DIYSimilarityEngine(ngram_n=3)
data = pd.read_csv('Jobs.csv')
docs = list(data['description'])
nlp.fit(docs)
現在,讓我們找出候選人最有可能獲得面試或錄用的工作,理論上。
summary = """
經驗豐富的數據分析師,擁有 5 年通過數據驅動的決策制定提供可操作見解的經驗。
熟練掌握 SQL、Excel 和 Tableau、Power BI 等可視化工具,具有扎實的 Python 高級分析基礎。
證明了設計和自動化報告儀表板、進行統計分析以及跨職能合作以支持業務戰略的能力。
擅長識別趨勢、優化流程以及以清晰、有影響力的方式傳達復雜發現。
"""
_ = nlp.most_similar(summary)
most_similar_doc = _[0][0]
data[data['description'] == most_similar_doc]

這個結果得出了 0.06 的相似度分數!說實話,這并不理想,如果你仔細閱讀職位描述并與候選人的總結進行比較,你會發現許多技能是匹配的。然而,一旦你看到這份工作需要很多小眾的職責和背景,差異就相當明顯了。如何改進呢?我們很容易說模型或預處理需要更多的細節,但也可以認為候選人的總結越詳細越好。、

)












——向量存儲)




)