
筆記整理:李曉彤,浙江大學碩士,研究方向為大語言模型
論文鏈接:https://arxiv.org/pdf/2406.06027
發表會議:ACL 2024
1. 動機
多跳問答(Multi-Hop Question Answering, MHQA)技術近年來在自然語言處理領域引起了廣泛關注,尤其是在大規模語言模型(LLMs)用于問答任務的背景下。然而,面對復雜的多跳問題時,現有的LLMs表現不盡如人意,其主要原因在于:理解復雜問題所需的信息篩選和上下文聚合存在很大的挑戰。為了緩解這一問題,研究人員嘗試結合結構化知識圖譜(KG)來簡化信息,但這仍不足以應對復雜、多跳問題的挑戰,因為這些方法通常缺乏上下文依賴性和對查詢的具體化。因此,本文提出了一種超關系(Hyper-Relational)知識圖譜,以更有效地輔助LLMs進行多跳問答任務。
2. 貢獻
本文的主要貢獻有:
(1)?引入了一種新的多跳問答方法,通過將非結構化文本轉換為基于查詢產生的超關系知識圖譜來簡化信息處理。
(2)?實驗表明,該方法在多個數據集上顯著提升了多跳問答的性能。具體而言,在HotpotQA數據集上提升了18.7%和20%的EM分數,而在MuSiQue數據集上提升了26%和14.3%。
(3)?相較于現有技術(SoTA)方法,利用本文的查詢聚焦的超關系知識圖能夠減少67%的標記使用,從而提高信息效率。
3. 方法
該方法的關鍵思想是識別包含多跳問題答案的文檔子集,隨后從它們中提取上下文感知的結構化信息,進一步使用基于查詢的schema來完善信息,以保留與查詢相關的信息。
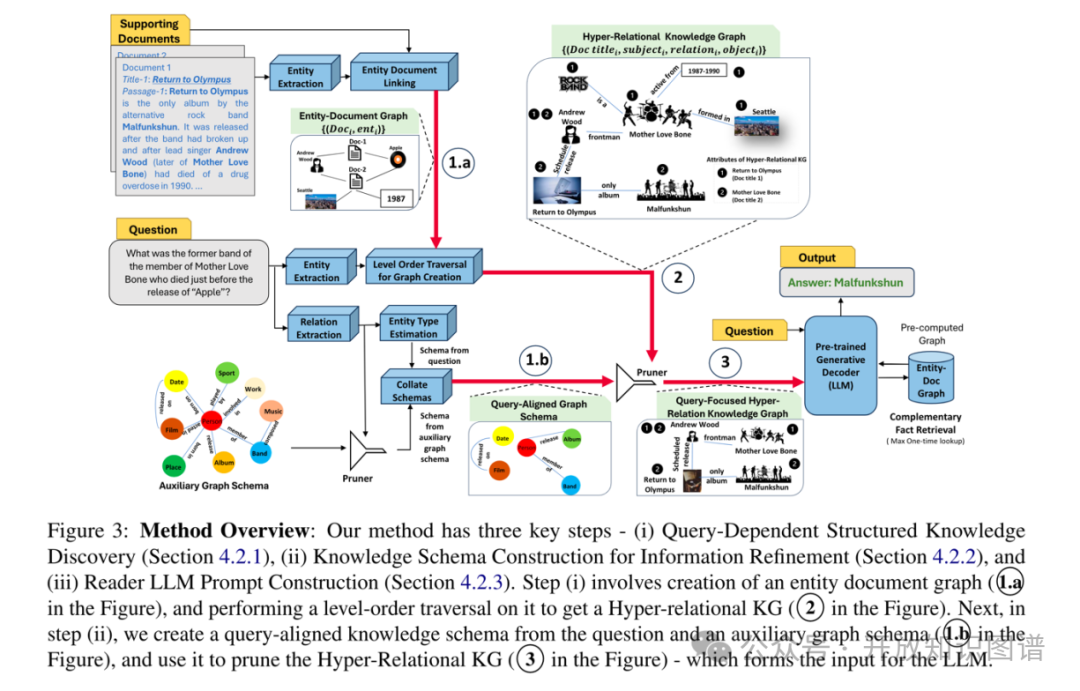
3.1?與查詢相關的結構化知識發現
從支持文檔中提取指定的實體。然后,在文檔和實體節點之間建立邊緣,形成了一個兩分圖,該圖捕獲了實體與它們出現的文檔之間的連接,通過層次遍歷來探索相關的潛在語義圖,并利用LLMs生成知識圖譜三元組,再將其轉換為超關系四元組。
3.2?信息精煉的知識架構構建
為了消除超關系圖中與檢索無關的信息,作者構建了一個與查詢對準的知識模式,圖模式使用兩個來源填充:通過識別推理查詢中的關系得出模式元素,然后使用LLMs估算每個關系中的主題和對象實體類型;使用其他領域特定的關系豐富了知識模式,以幫助多跳的推理。然后執行改進步驟中的完善步驟。根據問題和領域內的知識構建查詢對齊的知識架構,用其對超關系知識圖進行裁剪,保留與查詢相關的信息。
3.3 LLM的提示構建
將裁剪后的超關系圖譜進行語言化處理,并根據與查詢的相關性排序,形成輸入提示。由于結構化信息提取是一個未解決的問題,因此在輸入圖中可能會遺漏一些相關的細節。為了減輕這種情況,作者還在提示構建中包含了一個驗步驟。如果LLM識別輸入圖中缺少有關特定命名實體集的事實,則指示它列出缺失的命名實體。重新從Entity-Document圖中獲取相應的文檔,并將它們與初始相關事實集成在一起。此過程不僅豐富了LLM的輸入,而且還確保檢索任何缺失的查詢信息,從而提高了系統響應的準確性。
4. 實驗
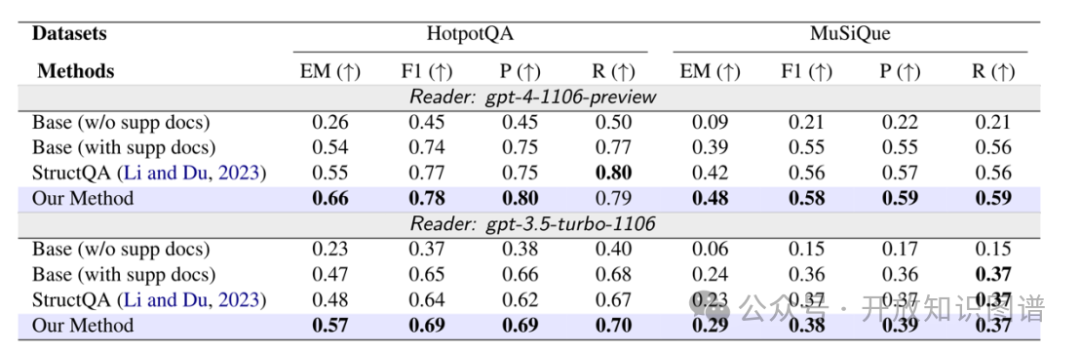
通過兩個基準數據集HotpotQA和MuSiQue的驗證,使用GPT-3.5、GPT-4等最先進的語言模型,證明了本文方法在多跳問答任務中的顯著優越性能。在主要的評價指標(EM、F1、Precision、Recall等)上,該方法在這些數據集上均取得了優于基線方法的結果。
同時,為了衡量LLM提供答案時的信心,還引入了“自知精確匹配”(Self-Aware EM)這一新的評價指標。實驗結果顯示,相較于其他基線方法,HOLMES方法在自知EM分數上具有更高的表現,在多個數據集和各種LLM模型中均實現了一致的改進。

5. 總結
本文提出了一種基于超關系知識圖譜的方法來提升多跳問答的效果,通過減小信息噪聲、對相關事實進行精煉及利用LLMs的強大推理能力來解決復雜的自然語言問題。通過一系列實驗驗證,該方法成功地在具有代表性的問答數據集中實現了先進的性能。此外,幾乎所有處理步驟都是零訓練的,使得該系統在沒有大量標注數據的情況下也能表現優異。總之,HOLMES方法為多跳問答任務提供了更為精確和高效的解決方案,標志著在該領域的一次顯著進步。未來的研究方向可能會圍繞增強模型的上下文理解能力及進一步減少信息處理的冗余展開。
OpenKG
OpenKG(中文開放知識圖譜)旨在推動以中文為核心的知識圖譜數據的開放、互聯及眾包,并促進知識圖譜算法、工具及平臺的開源開放。

點擊閱讀原文,進入 OpenKG 網站。












——向量存儲)




)

