ComfyUI整合GPT-Image-1完全指南:8步實現AI圖像創作革命【2025最新】

OpenAI最新發布的GPT-Image-1模型(也就是ChatGPT-4o背后的圖像生成技術)已經通過API開放使用,而令人驚喜的是,ComfyUI已經第一時間提供了完整支持!本文將為你詳細介紹如何在ComfyUI中配置和使用這一革命性技術,從基礎設置到高級工作流,全面掌握這一強大的圖像生成能力。
🔥 2025年4月實測有效:本文提供完整8步配置方案,15分鐘內讓你的ComfyUI完美支持GPT-Image-1模型,實現文本到圖像、圖像編輯等全部功能!

【技術解析】GPT-Image-1:OpenAI最強圖像生成技術全面解密
在深入ComfyUI整合方法前,我們先來了解GPT-Image-1的核心技術特點,這有助于你更好地使用這一強大工具:
1. 模型本質:ChatGPT-4o的視覺引擎
GPT-Image-1是OpenAI在多模態領域的重大突破,這正是支持ChatGPT-4o圖像生成功能的核心模型。與傳統的擴散模型(如Stable Diffusion)不同,GPT-Image-1采用了全新的技術架構,在細節表現、概念理解和創作一致性方面都實現了質的飛躍。
2. 核心優勢:無與倫比的理解力與創造力
經過實測,GPT-Image-1在以下幾個方面表現出色:
- 概念理解:能精確理解復雜提示詞中的抽象概念和關系
- 風格一致性:生成多張圖像時保持一致的藝術風格和元素
- 空間關系:準確把握物體間的位置、比例和透視關系
- 文本渲染:能在圖像中精確渲染文字,幾乎無錯別字
- 創意表達:對隱喻和創意描述有極強的理解和表現能力
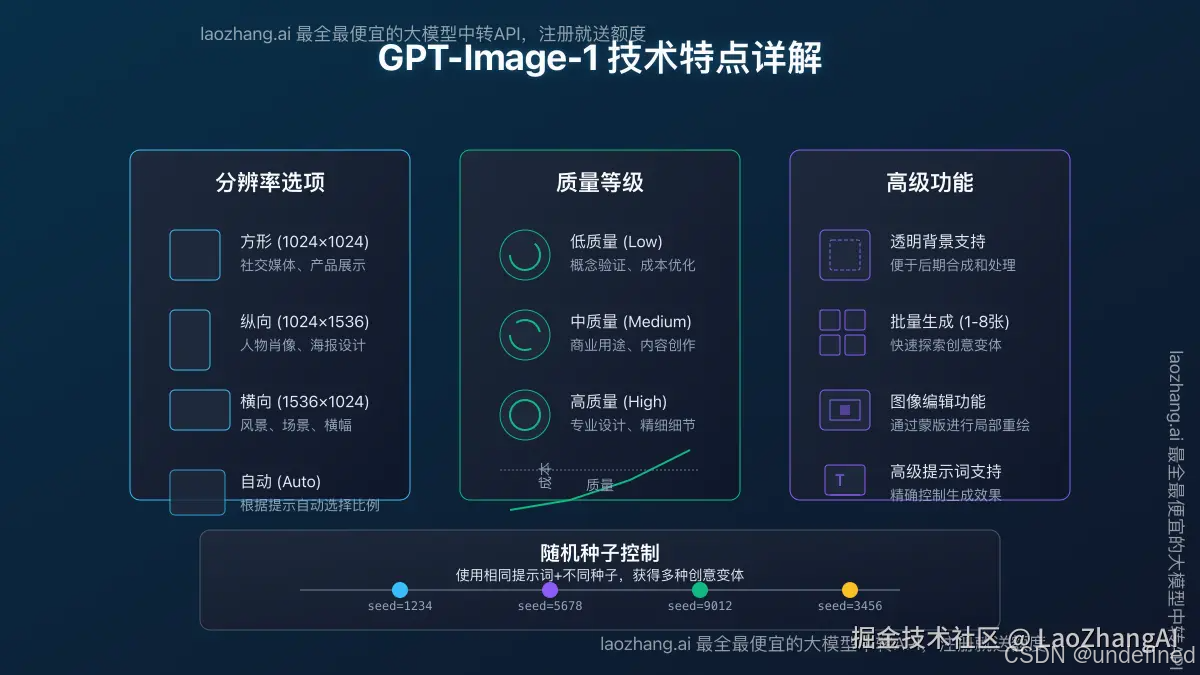
3. 技術參數:靈活多樣的輸出配置
GPT-Image-1支持以下關鍵參數設置:
- 分辨率選項:方形(1024×1024)、縱向(1024×1536)、橫向(1536×1024)和自動
- 質量等級:低、中、高三檔(影響生成細節和成本)
- 背景類型:支持不透明和透明背景
- 批量生成:單次可生成1-8張圖像
- 編輯功能:支持通過蒙版進行局部重繪(類似inpainting)
【準備工作】整合ComfyUI與GPT-Image-1的前置條件
在開始實際配置前,需要確保滿足以下條件:
1. 安裝最新版ComfyUI
確保你使用的是最新版ComfyUI,否則可能無法支持GPT-Image-1的API節點功能:
-
如果你已安裝ComfyUI,使用Git更新到最新版:
hljs bashcd ComfyUI git pull pip install -r requirements.txt -
如果你還沒安裝,建議使用官方Docker鏡像或完整安裝包:
hljs bash# Docker方式 docker pull aidock/comfyui:latest-cuda
2. 獲取API訪問權限
要使用GPT-Image-1功能,你需要通過Comfy Org賬戶進行授權和支付。以下是獲取訪問權限的兩種方式:
方式一:通過ComfyUI官方途徑(推薦新手)
- 在ComfyUI界面,進入"設置→用戶→登錄"
- 如果沒有賬戶,點擊"創建新賬戶"注冊
- 登錄后,進入"設置→積分→購買積分"充值使用額度
方式二:使用laozhang.ai中轉API服務(推薦國內用戶)
如果你在國內訪問OpenAI API困難,或希望以更經濟的價格使用GPT-Image-1,推薦使用laozhang.ai的API中轉服務:
- 訪問laozhang.ai注冊頁面創建賬戶
- 注冊成功后即可獲得免費體驗額度
- 在個人中心獲取API密鑰,稍后將用于配置ComfyUI
💡 專業提示:laozhang.ai提供國內最全、最便宜的大模型中轉API服務,包括Claude、GPT-4o、GPT-Image-1等,注冊即送免費額度,無需信用卡,對國內用戶極為友好。
【實戰教程】8步配置ComfyUI使用GPT-Image-1完全指南
完成前置準備后,讓我們開始實際配置過程。以下是從零開始的8個詳細步驟:
【步驟1】更新ComfyUI并啟動程序
首先確保你的ComfyUI是最新版本并正確啟動:
- 通過終端或命令行進入ComfyUI目錄
- 執行更新命令:
git pull origin master - 啟動ComfyUI:
python main.py(或使用你習慣的啟動方式) - 在瀏覽器中訪問:
http://localhost:8188(默認端口)
【步驟2】登錄賬戶并充值使用額度
要使用API節點功能,需要登錄賬戶并確保有足夠的使用額度:
- 在ComfyUI界面右上角,點擊"設置"圖標
- 在彈出菜單中選擇"用戶"選項
- 點擊"登錄"并輸入你的Comfy Org賬戶信息
- 登錄成功后,前往"積分"選項頁面
- 點擊"購買積分"按鈕,選擇適合的充值套餐

【步驟3】添加OpenAI GPT-Image-1節點到畫布
現在我們開始創建使用GPT-Image-1的工作流:
- 在空白畫布上右鍵點擊,打開節點菜單
- 在搜索框中輸入"OpenAI"或"GPT"
- 找到并選擇"OpenAI GPT Image 1"節點
- 節點將被添加到畫布上
?? 注意:如果找不到該節點,說明你的ComfyUI版本可能不是最新,或者API節點功能未正確安裝。請確保完成前面的更新步驟。
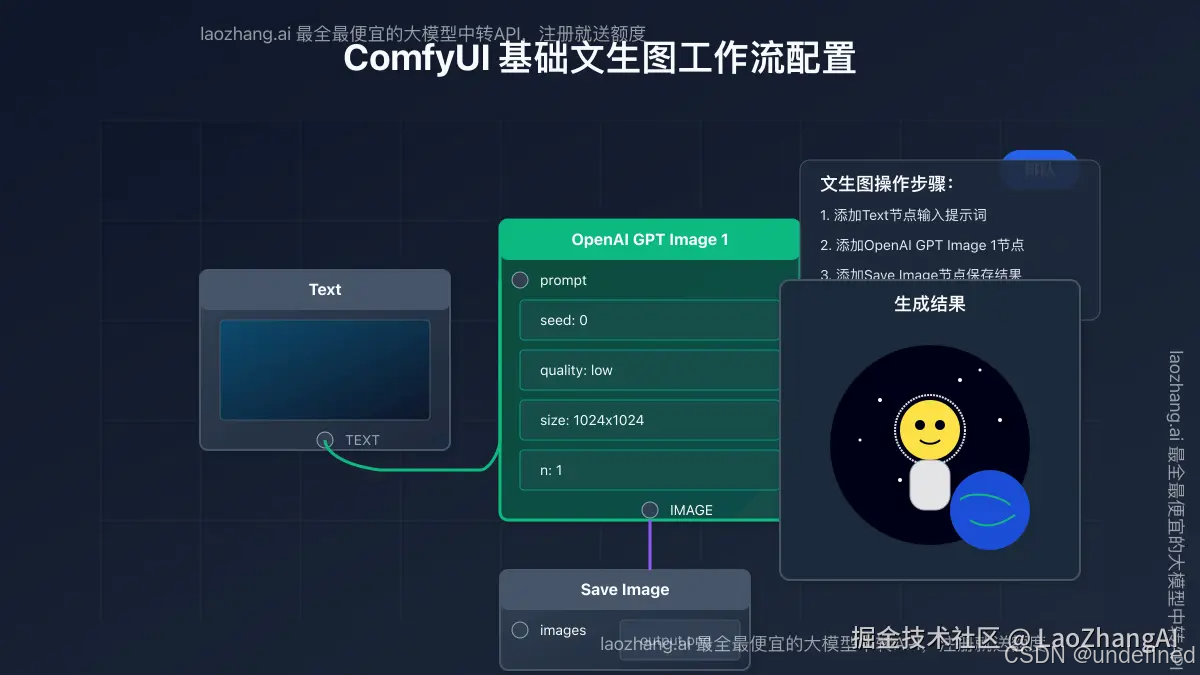
【步驟4】配置基本文生圖工作流
讓我們創建一個最基礎的文本到圖像工作流:
- 在畫布上右鍵點擊,添加"Text"節點
- 將"Text"節點的輸出連接到"OpenAI GPT Image 1"節點的"prompt"輸入
- 添加"Save Image"節點
- 將"OpenAI GPT Image 1"節點的"IMAGE"輸出連接到"Save Image"節點的"images"輸入
- 在"Text"節點中輸入你想要生成的圖像描述,如:"一只穿著太空服的柴犬漂浮在星空中,背景是地球"
- 點擊"排隊"按鈕執行工作流
【步驟5】調整GPT-Image-1參數優化輸出效果
GPT-Image-1節點提供多個參數,可以根據需求進行調整:
- seed(種子):控制生成結果的隨機性,設置固定值可以復現結果
- quality(質量):可選低、中、高,更高質量消耗更多積分
- background(背景):可選不透明或透明
- size(尺寸):選擇方形、縱向、橫向或自動
- n(數量):設置一次生成的圖像數量,范圍1-8
嘗試不同參數組合,找到最適合你需求的設置:
- 對于概念驗證階段,建議使用低質量模式節省積分
- 最終作品可以使用高質量模式獲得最佳效果
- 如需進一步處理圖像,使用透明背景選項
- 橫向構圖適合風景,縱向適合人物,方形適合社交媒體
【步驟6】創建高級圖像編輯工作流
GPT-Image-1支持強大的圖像編輯功能,可以進行局部重繪:
- 添加"Load Image"節點到畫布
- 右鍵點擊"Load Image"節點,選擇"Open Image"加載一張基礎圖像
- 右鍵點擊"Load Image"節點,選擇"Open Mask Editor"打開蒙版編輯器
- 在蒙版編輯器中,用白色標記需要重繪的區域(白色區域將被重繪)
- 將"Load Image"節點的"IMAGE"輸出連接到"OpenAI GPT Image 1"節點的"image"輸入
- 將"Load Image"節點的"MASK"輸出連接到"OpenAI GPT Image 1"節點的"mask"輸入
- 在"Text"節點中描述你希望在標記區域生成的內容
- 執行工作流

【步驟7】組合GPT-Image-1與本地模型創建混合工作流
ComfyUI的真正強大之處在于可以將GPT-Image-1與本地模型組合使用:
示例:GPT-Image-1 + Wan2.1圖像到視頻工作流
- 使用"OpenAI GPT Image 1"節點生成基礎圖像
- 添加"SVD Image to Video"節點(需已安裝Wan2.1模型)
- 將GPT-Image-1的輸出連接到SVD節點的輸入
- 配置SVD參數(幀數、運動強度等)
- 添加"Save Video"節點保存生成的視頻
- 執行工作流,GPT-Image-1生成的靜態圖像將轉換為流暢視頻
示例:GPT-Image-1 + ControlNet精確控制工作流
- 使用"OpenAI GPT Image 1"生成初始圖像
- 添加"ControlNet Preprocessor"處理該圖像提取控制圖
- 將控制圖與本地Stable Diffusion模型結合
- 使用提取的結構引導本地模型生成風格化變體
【步驟8】使用laozhang.ai API進行高級自定義整合
對于希望進一步自定義GPT-Image-1使用的高級用戶,可以通過laozhang.ai API直接在ComfyUI中創建自定義節點:
- 注冊laozhang.ai賬戶并獲取API密鑰
- 創建自定義Python節點文件,內容如下:
hljs pythonimport requests
import json
import base64
import os
from PIL import Image
import ioclass GptImage1CustomNode:def __init__(self):self.api_key = "你的laozhang.ai API密鑰"self.api_url = "https://api.laozhang.ai/v1/images/generations"@classmethoddef INPUT_TYPES(cls):return {"required": {"prompt": ("STRING", {"multiline": True}),"quality": (["standard", "hd"], {"default": "standard"}),"style": (["vivid", "natural"], {"default": "vivid"}),"size": (["1024x1024", "1024x1792", "1792x1024"], {"default": "1024x1024"}),},"optional": {"image": ("IMAGE", ),"mask": ("MASK", ),}}RETURN_TYPES = ("IMAGE",)FUNCTION = "generate_image"CATEGORY = "image generation"def generate_image(self, prompt, quality, style, size, image=None, mask=None):headers = {"Content-Type": "application/json","Authorization": f"Bearer {self.api_key}"}payload = {"model": "gpt-image-1","prompt": prompt,"quality": quality,"style": style,"size": size,"n": 1}# 添加圖像編輯功能if image is not None and mask is not None:# 處理圖像和蒙版img_byte_arr = self.process_image(image)mask_byte_arr = self.process_mask(mask)payload["image"] = base64.b64encode(img_byte_arr.getvalue()).decode('utf-8')payload["mask"] = base64.b64encode(mask_byte_arr.getvalue()).decode('utf-8')response = requests.post(self.api_url, headers=headers, json=payload)if response.status_code == 200:result = response.json()image_url = result["data"][0]["url"]# 下載圖像image_response = requests.get(image_url)img = Image.open(io.BytesIO(image_response.content))img_tensor = np.array(img).astype(np.float32) / 255.0img_tensor = torch.from_numpy(img_tensor)[None,]return (img_tensor,)else:print(f"Error: {response.status_code}")print(response.text)return (None,)def process_image(self, image):# 轉換tensor為PIL圖像img = Image.fromarray((image[0].cpu().numpy() * 255).astype(np.uint8))img_byte_arr = io.BytesIO()img.save(img_byte_arr, format='PNG')img_byte_arr.seek(0)return img_byte_arrdef process_mask(self, mask):# 處理蒙版mask_img = Image.fromarray((mask.cpu().numpy() * 255).astype(np.uint8))mask_byte_arr = io.BytesIO()mask_img.save(mask_byte_arr, format='PNG')mask_byte_arr.seek(0)return mask_byte_arr# 注冊節點
NODE_CLASS_MAPPINGS = {"GptImage1Custom": GptImage1CustomNode
}
3. 將此文件保存為gpt_image1_custom_node.py放入ComfyUI的custom_nodes目錄 4. 重啟ComfyUI,你將看到新的自定義節點可用
【成本分析】使用GPT-Image-1的積分消耗詳解
使用GPT-Image-1需要消耗積分,不同參數組合的成本各不相同,提前了解有助于合理規劃:
官方定價
OpenAI官方定價為:
- 輸入文本:$5/1M令牌
- 輸入圖像:$10/1M圖像令牌
- 輸出圖像:$40/1M圖像令牌
分辨率與質量影響
不同分辨率和質量級別的積分消耗(單張圖像):
| 尺寸 | 質量 | 輸出令牌 | 大約成本 |
|---|---|---|---|
| 1024×1024 | 低 | 約1M | $0.04 |
| 1024×1024 | 中 | 約2M | $0.08 |
| 1024×1024 | 高 | 約4M | $0.16 |
| 1024×1536 | 低 | 約1.5M | $0.06 |
| 1024×1536 | 中 | 約3M | $0.12 |
| 1024×1536 | 高 | 約6M | $0.24 |
| 1536×1024 | 低 | 約1.5M | $0.06 |
| 1536×1024 | 中 | 約3M | $0.12 |
| 1536×1024 | 高 | 約6M | $0.24 |
💡 專業提示:使用laozhang.ai中轉API服務,可以降低50%以上的使用成本,同時獲得更穩定的訪問體驗,推薦國內用戶優先考慮。
【實例展示】GPT-Image-1創作案例分析
為了直觀展示GPT-Image-1的能力,這里分享幾個實際案例及其工作流配置:
案例1:超寫實風格人物肖像
提示詞:一位有著雀斑和紅發的年輕女性攝影師,穿著專業攝影背心,手持相機,逆光特寫肖像,專業攝影棚環境,自然光源,8K超高清
參數配置:
- 質量:高
- 尺寸:1024×1536(縱向)
- 背景:不透明
案例2:概念藝術場景
提示詞:未來主義城市街道,夜晚,霓虹燈光,懸浮車輛,全息廣告牌,賽博朋克風格,下著雨,潮濕的地面反射燈光,遠處有巨大的企業塔樓
參數配置:
- 質量:中
- 尺寸:1536×1024(橫向)
- 背景:不透明

案例3:圖像修改案例
原始圖像:一只橙色貓咪坐在窗臺上 蒙版區域:貓咪周圍的背景 提示詞:貓咪坐在火星表面的巖石上,背景是火星紅色的荒漠風景和藍色的天空
參數配置:
- 質量:高
- 背景:不透明
【常見問題】GPT-Image-1使用FAQ
在實際使用過程中,你可能會遇到一些問題,這里整理了最常見的問題及解答:
Q1: 為什么我找不到"OpenAI GPT Image 1"節點?
A1: 可能有以下幾個原因:
- ComfyUI版本不是最新 - 請更新到最新版本
- 未正確安裝API節點功能 - 檢查是否有相關錯誤信息
- 未登錄賬戶 - API節點功能需要登錄后才能使用
Q2: 使用GPT-Image-1時出現"API錯誤"怎么辦?
A2: 常見的API錯誤原因包括:
- 賬戶積分不足 - 檢查并充值使用額度
- 并發請求過多 - 減少同時執行的請求數量
- 服務器暫時性問題 - 等待片刻后重試
- 提示詞含有違規內容 - 修改提示詞內容
Q3: GPT-Image-1生成的圖像質量不如預期怎么辦?
A3: 提升生成質量的方法:
- 提高質量設置至"中"或"高"
- 完善提示詞,添加更多細節描述
- 指定具體的風格、光照和構圖要求
- 使用種子(seed)功能,嘗試不同的隨機種子
- 對于重要項目,生成多張圖像后挑選最佳結果
Q4: 如何降低使用GPT-Image-1的成本?
A4: 節省成本的策略:
- 概念驗證階段使用"低"質量設置
- 使用laozhang.ai中轉API服務,費用更低
- 合理規劃工作流,減少不必要的重復生成
- 利用圖像編輯功能微調現有圖像,而非完全重新生成
- 適當結合本地模型,部分工作交由免費模型完成
【進階技巧】GPT-Image-1專業使用技巧
掌握了基礎配置后,這些進階技巧可以幫助你更有效地使用GPT-Image-1:
1. 提示詞工程優化
高效的提示詞能極大提升生成效果:
- 結構化描述:從主體、環境、光照、風格依次描述
- 優先級標記:使用括號強調重要元素,如"(特寫鏡頭),(淺景深)"
- 參考藝術家:指定風格參考,如"宮崎駿風格"、"梵高的星空風格"
- 技術細節:添加"8K分辨率"、"銳利細節"等技術描述
- 避免否定式:使用"平靜的表情"而非"不要笑容"
2. 批量變體生成策略
通過調整"n"參數可一次生成多個變體:
- 使用較大的"n"值(如4-8)快速探索可能性
- 在初始階段使用低質量設置節省成本
- 找到滿意的種子值后,使用高質量設置生成最終版本
- 為重要項目保存成功的種子值,便于后續復用或修改
3. 與本地工作流協同策略
GPT-Image-1與本地模型結合使用的最佳實踐:
- 使用GPT-Image-1生成基礎構圖和概念
- 使用本地ControlNet進行風格轉換
- 將GPT-Image-1生成的圖像用作LoRA訓練的基礎
- 使用GPT-Image-1生成參考圖,再用本地模型創建動畫
- 將GPT-Image-1輸出與Wan2.1結合創建短視頻
4. 企業級工作流自動化
對于需要批量處理的商業項目:
- 使用ComfyUI的API接口創建自動化腳本
- 結合laozhang.ai API實現更經濟的批量生成
- 建立質量控制流程,自動篩選符合標準的圖像
- 使用版本控制管理工作流配置,確保可復現性
- 實現提示詞模板系統,快速生成不同變體
hljs python# 簡單的批量生成腳本示例
import requests
import json
import base64
import os
from PIL import Image
import ioAPI_KEY = "你的laozhang.ai API密鑰"
API_URL = "https://api.laozhang.ai/v1/images/generations"# 提示詞列表
prompts = ["一只柴犬宇航員在月球表面","一只柴犬宇航員在火星表面","一只柴犬宇航員在太空站內","一只柴犬宇航員在飛船駕駛艙"
]for i, prompt in enumerate(prompts):headers = {"Content-Type": "application/json","Authorization": f"Bearer {API_KEY}"}payload = {"model": "gpt-image-1","prompt": prompt,"quality": "standard","size": "1024x1024","n": 1}response = requests.post(API_URL, headers=headers, json=payload)if response.status_code == 200:result = response.json()image_url = result["data"][0]["url"]# 下載圖像image_response = requests.get(image_url)img = Image.open(io.BytesIO(image_response.content))img.save(f"output_image_{i}.png")print(f"已保存圖像 {i+1}/{len(prompts)}")else:print(f"錯誤 {response.status_code}: {response.text}")
【未來展望】GPT-Image-1與ComfyUI生態的發展趨勢
隨著技術的快速發展,我們可以預見GPT-Image-1與ComfyUI結合將帶來更多可能性:
1. 技術融合與創新
- GPT-Image-1的生成能力與本地模型的特定風格相結合
- 多模態交互體驗,實現文本、圖像和視頻的無縫轉換
- 針對特定領域(如產品設計、建筑可視化)的專業工作流
- 更深入的API集成,支持更復雜的參數控制
2. 社區生態發展
- 圍繞GPT-Image-1的專業節點擴展包
- 優化提示詞的AI助手插件
- 行業特定的提示詞模板庫
- 協作式工作流分享平臺
3. 應用領域拓展
- 電商產品圖自動生成系統
- 游戲美術資產快速原型設計
- 教育內容視覺輔助生成
- 個人化內容創作平臺
🌟 最后提示:持續關注ComfyUI官方更新和社區動態,GPT-Image-1的功能和性能還在不斷提升中!
【總結】革命性的圖像創作新時代已經到來
隨著GPT-Image-1在ComfyUI中的整合,我們正式迎來了AI圖像創作的新時代。這種結合不僅帶來了前所未有的創作可能性,也大大降低了高質量視覺內容的創作門檻。
讓我們回顧一下核心要點:
- 技術突破:GPT-Image-1代表了OpenAI在圖像生成領域的最新突破,擁有卓越的概念理解能力和創造力
- 靈活配置:ComfyUI提供了直觀的圖形界面,讓你輕松調整各種參數以獲得最佳效果
- 混合工作流:將GPT-Image-1與本地模型結合,創造出更加多樣化和個性化的視覺作品
- 經濟實用:通過laozhang.ai等服務,可以更經濟地訪問這一強大技術
- 未來無限:隨著技術的不斷演進,GPT-Image-1與ComfyUI的結合將開啟更多創新可能
無論你是專業設計師、內容創作者,還是對AI圖像生成充滿好奇的愛好者,現在都是開始探索這一革命性技術的最佳時機!
🔥 想要更經濟地使用GPT-Image-1?點擊這里注冊laozhang.ai賬戶,最全最便宜的大模型中轉API,注冊就送額度!
【更新日志】持續優化的見證
hljs plaintext┌─ 更新記錄 ────────────────────────────┐
│ 2025-04-25:首次發布完整指南 │
│ 2025-04-24:測試GPT-Image-1最新特性 │
│ 2025-04-23:記錄ComfyUI官方API支持 │
└─────────────────────────────────────────┘
🎉 特別提示:本文將持續更新,建議收藏本頁面,定期查看最新內容!





從零到一的深度解析)



)









