計算機視覺、自編碼器和生成對抗網絡(GAN)
- 自動編碼器
- Vanilla自動編碼器
- 使用 AE 生成新對象. 變分 AE (VAE)
- AE 條件
- GAN
- 理論
- 示例
- 下載并準備數據
- GAN模型
- 額外知識
課程計劃:
- 自動編碼器:
- 自動編碼器結構;
- 使用自動編碼器生成圖像;
- 條件自動編碼器;
- 生成對抗網絡:
- 生成對抗網絡結構;
- 練習:構建和訓練生成對抗網絡;
自動編碼器
Autoencoders
Vanilla自動編碼器
自動編碼器是一種神經網絡,它學習重建輸入信息。換句話說,它試圖產生與輸入完全相同的輸出:
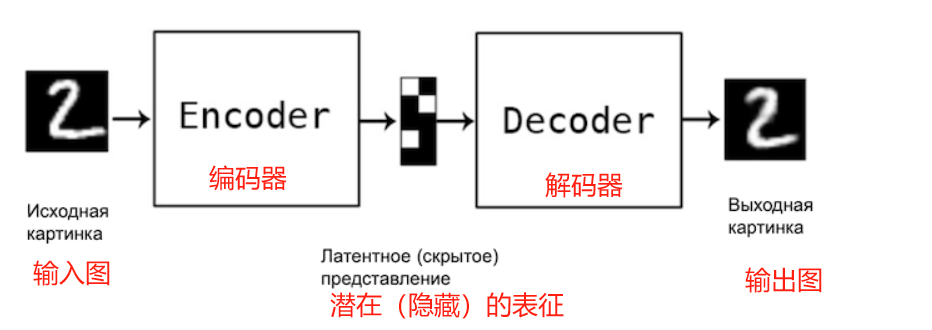
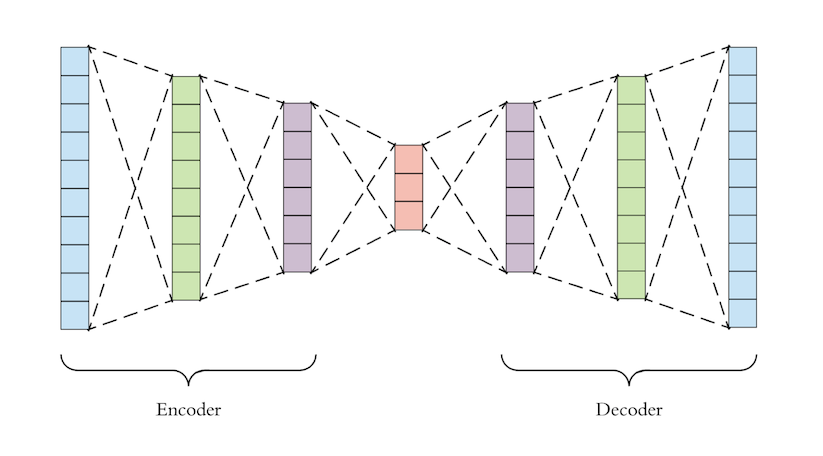
自動編碼器通常設計為向中間逐漸變細,即中間層的神經元數量遠小于網絡前層的神經元數量。這樣我們就得到了我們熟悉的編碼器-解碼器結構。
如果自動編碼器中間層的神經元數量與輸入層相同,那么在沒有額外限制的情況下,自動編碼器就毫無意義。它會學習id(身份)函數。
自動編碼器的用途:
- 數據壓縮和存儲,特別是圖像/視頻壓縮;
- 根據潛在表征對對象進行聚類;
- 查找相似對象(例如圖像);
- 生成新對象(例如圖像)。
- 查找數據中的異常;
- ……(可能還有更多 😃)。
自動編碼器 (AE) 采用自監督學習模式進行訓練。這意味著它無需數據標記即可進行訓練。
例如,如果我們想在人臉圖像數據集上訓練 AE,那么在每次訓練迭代中,我們會執行以下操作:
- 為 AE 輸入一張圖片;
- 將重建圖像作為 AE 的輸出;
- 計算重建圖像與輸入圖像之間的 MSE/BCE 質量指標;
- 使用反向傳播算法訓練 AE。
與分類/檢測/分割任務不同,AE 無需數據標記。
使用 AE 生成新對象. 變分 AE (VAE)
讓我們更詳細地討論如何使用自編碼器生成新物體。為了簡單起見,我們假設處理的是人臉圖像(其他類型的物體也一樣)。
使用 AE 生成新圖像:
- 在我們的人臉數據集上訓練 AE;
- 去掉編碼器部分,只留下解碼器部分;
- 將所需大小的隨機數字向量輸入到解碼器部分的輸入中,在輸出端,我們將得到一張從未見過的人臉新圖像。
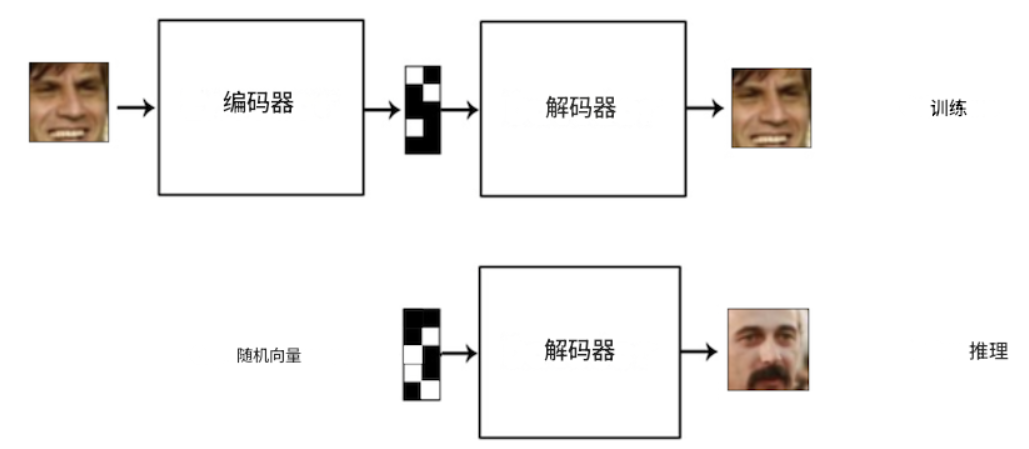
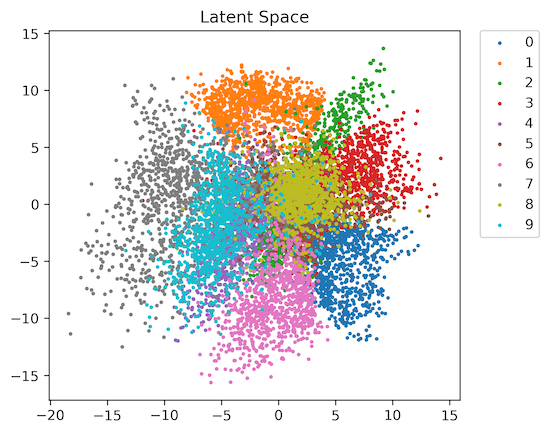
然而,常規(“原始”)AE 無法實現這樣的效果。問題在于,它的潛在空間非常稀疏:并非空間中的每個點都對應一張真實的圖片。
潛在空間看起來大致如下:

為了使自動編碼器(AE)的潛在空間向量能夠真正生成新的對象,我們需要強制自動編碼器學習一個更連貫、更緊湊的潛在空間。
一種方法是指定潛在空間向量應該對應的分布。也就是說,對向量在潛在空間中的間距添加一個約束。
這種自動編碼器被稱為變分自動編碼器(VAE)。它的潛在空間大致如下:
AE 條件
我們已經意識到 VAE 可以用來生成新對象。讓我們來討論一下如何生成不僅僅是任何新對象,而是具有給定屬性的對象。
其思路是這樣的:在訓練過程中,解碼器輸入會輸入一個編碼屬性以及潛在向量。例如,假設我們想要學習如何生成特定種族的人臉。假設我們只有 4 種種族類型。我們使用獨熱編碼對它們進行編碼:每種種族類型對應一個長度為 4 的向量,由 0 和 1 組成。解碼器輸入會輸入一個潛在向量,該向量與該種族的獨熱向量連接在一起。
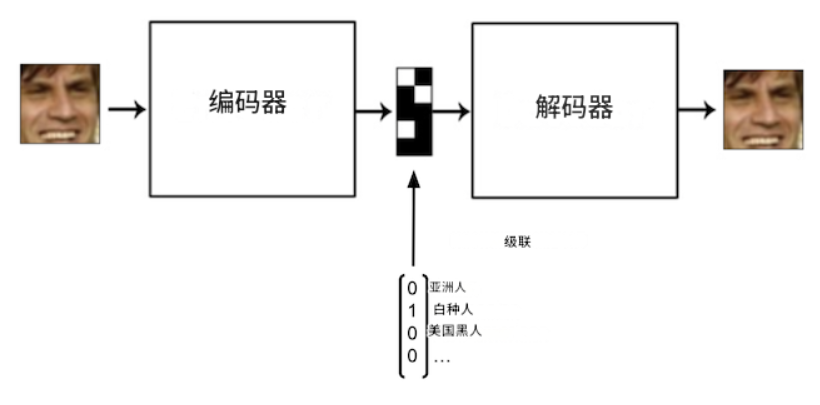
不僅可以將條件向量饋送到第一個解碼器層的輸入,還可以將其饋送到其所有層的輸入。還可以將條件向量饋送到編碼器層的輸入。
問題:原始自動編碼器用于什么任務的訓練?
GAN
理論
GAN —— Generative adversarial Network —— 生成對抗網絡。該架構于 2014 年發明,專門用于生成新圖像(當然,GAN 不僅可以用來生成圖像,還可以生成其他對象)。
讓我們思考一下:如何訓練神經網絡生成新物體?
最簡單的想法:創建一個神經網絡,輸入一個特定大小的隨機向量,并輸出一張生成的圖像:
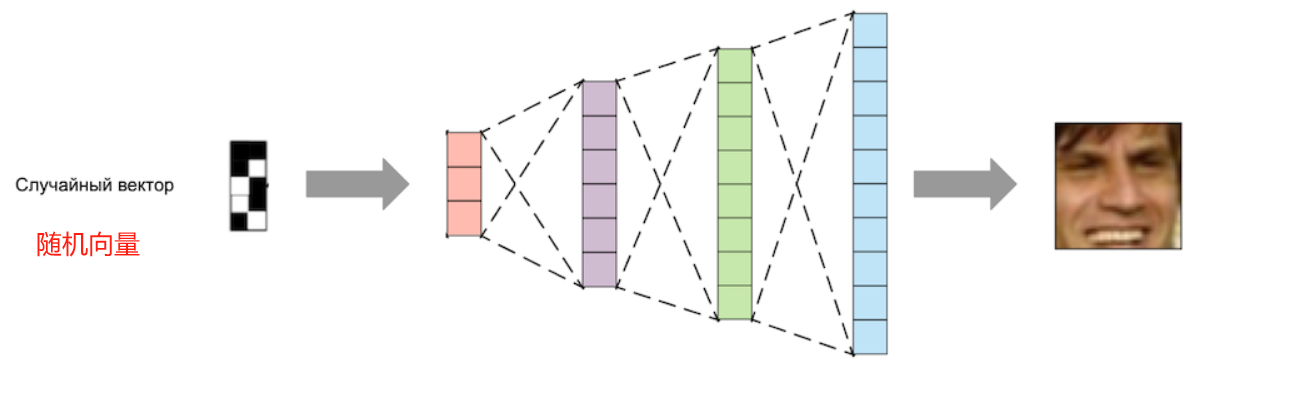
這個想法的問題在于如何訓練這樣的網絡。如果你在訓練過程中將隨機向量輸入到輸入中,并將網絡輸出與訓練數據集中的圖片進行比較,這樣的網絡將學會只生成訓練數據集中的圖片。這幾乎沒什么用 =)
我希望在訓練數據集有限的情況下,教會神經網絡生成不同的人臉,即使是神經網絡在訓練過程中沒有識別的人臉(即不在訓練數據中的人臉)。
如何做到這一點?其中一個想法是 GAN——生成對抗網絡。
它的工作原理如下:
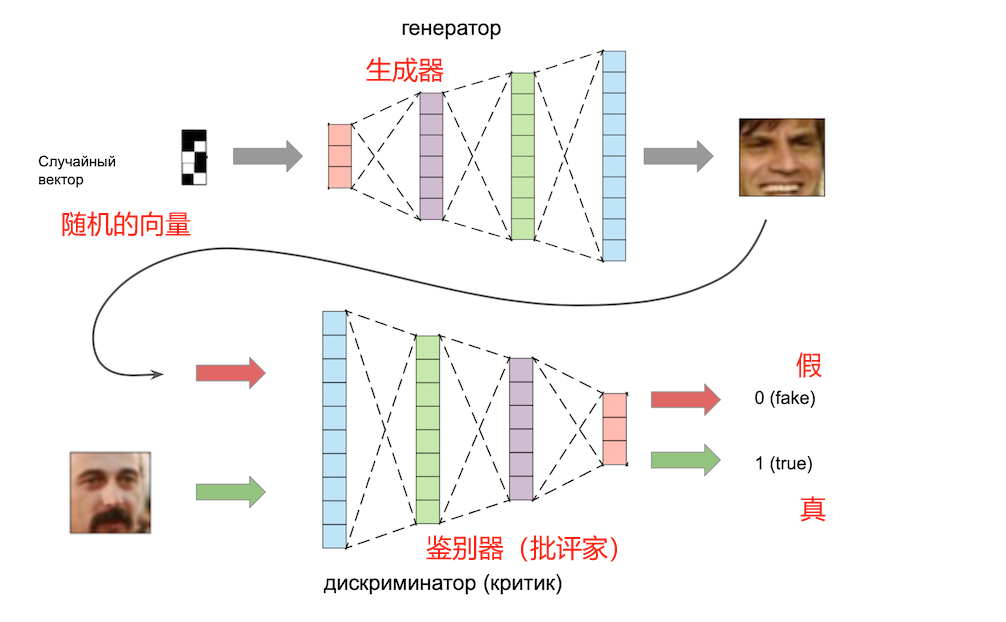
該模型由兩個獨立的神經網絡組成:一個生成器和一個鑒別器。生成器以隨機向量作為輸入,輸出一張圖像。鑒別器以圖像作為輸入,輸出一個答案:這張圖片是真的還是假的(由生成器生成)。
生成器和鑒別器一起訓練。鑒別器幫助生成器學習生成各種圖像,而不僅僅是訓練數據集中的圖像。
 .
.
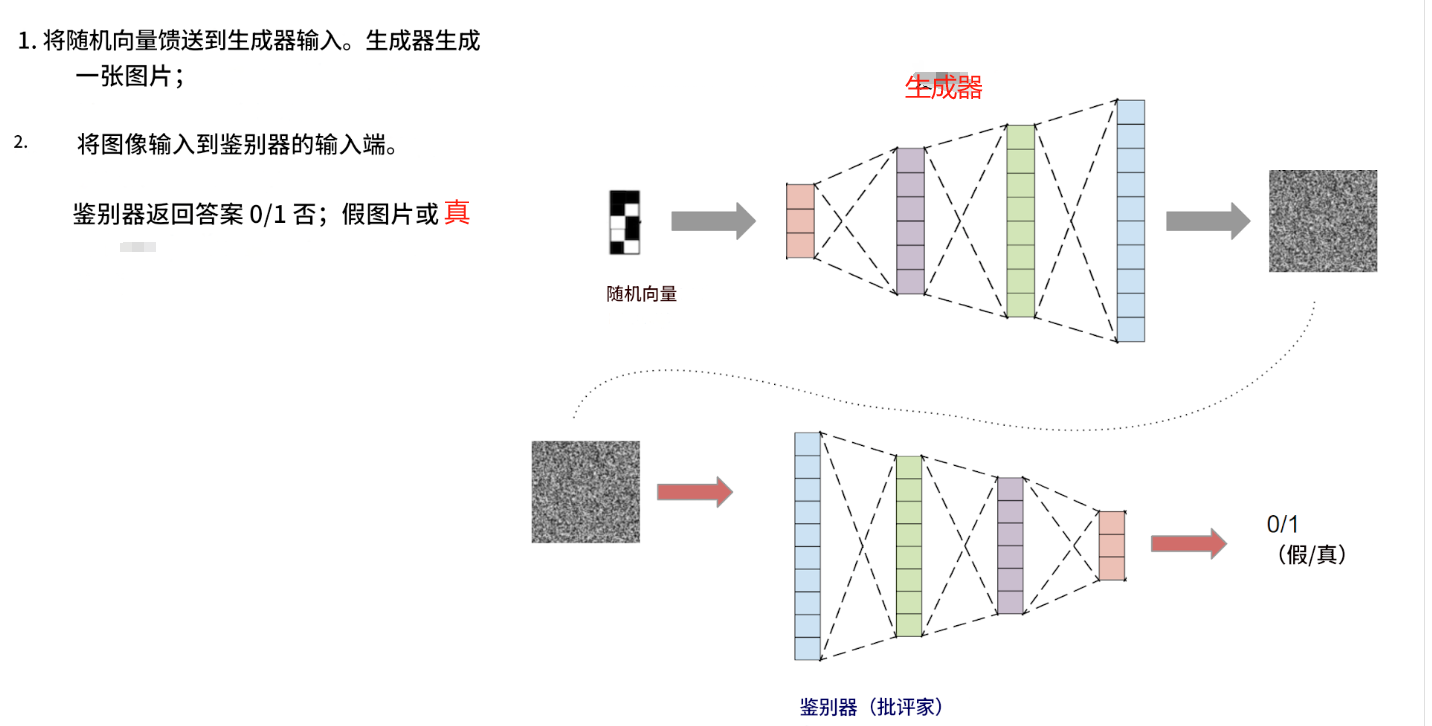
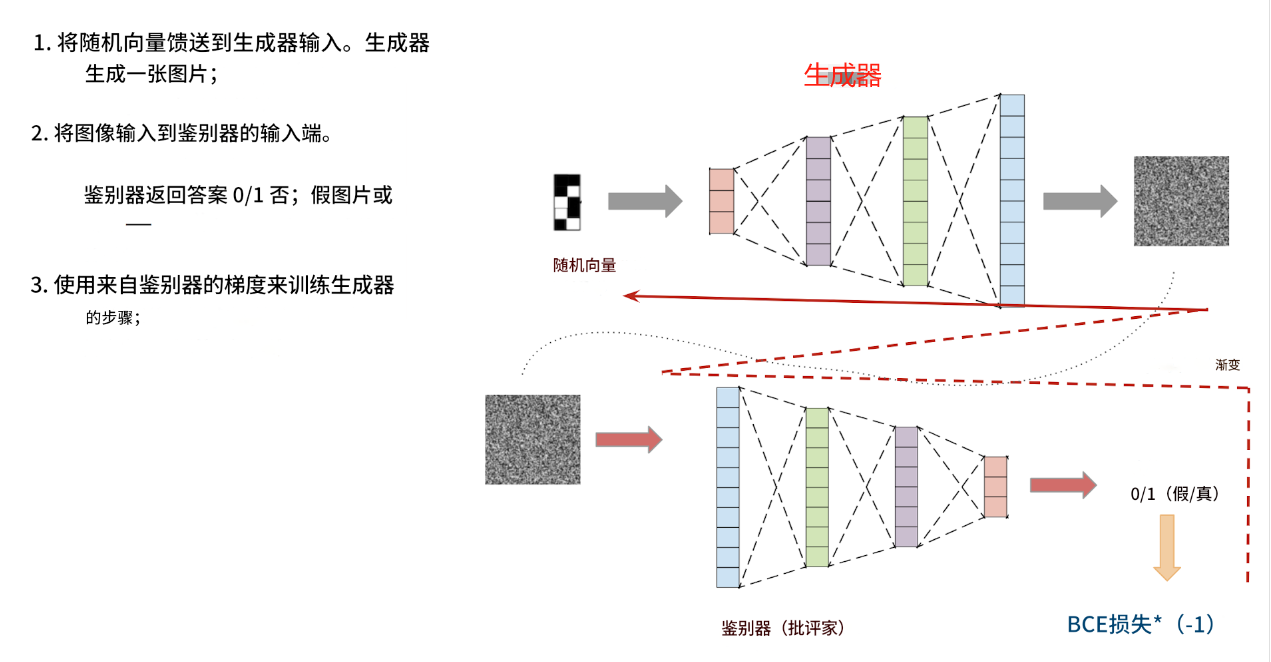
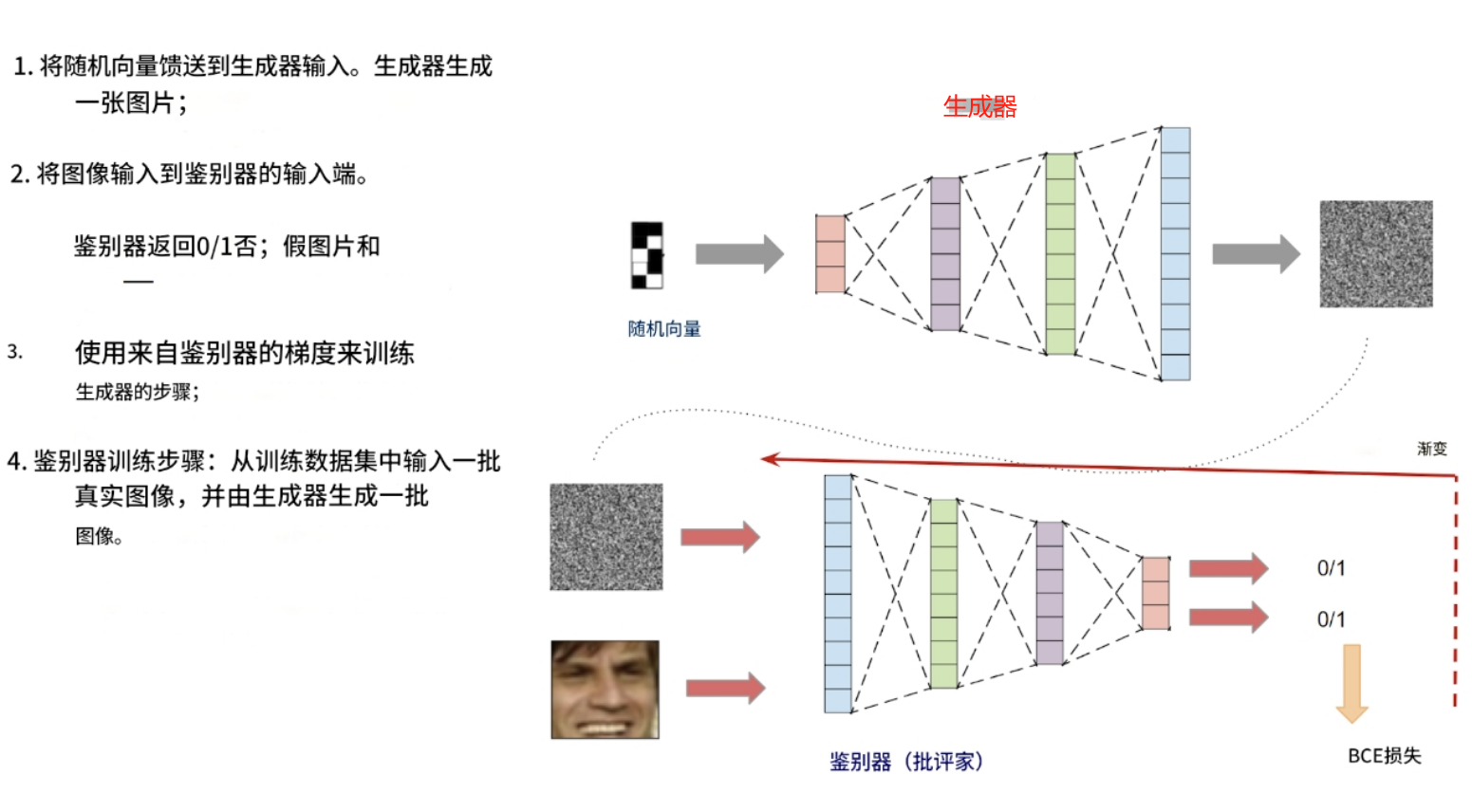
這一切的關鍵在于:鑒別器能夠快速學會區分生成器生成的圖片和真實圖片(來自訓練數據集)。之后,在生成器訓練階段,生成器會學習自適應,生成鑒別器無法再區分的圖片。之后,鑒別器會學習區分生成器生成的新圖片和真實圖片。之后,生成器會再次學習生成更好的圖片。如此反復。
這是生成器和鑒別器之間的對抗。
GAN 有一些缺點:
- GAN 訓練起來相當困難。你需要選擇合適的生成器和鑒別器架構:這樣鑒別器就不會比生成器“聰明”太多(學會對圖片進行分類的速度不會比生成器學會生成圖片的速度快太多)。反之亦然:鑒別器也不應該比生成器“笨”太多,否則生成器將無法接收到良好的訓練信號。
- 在 GAN 生成器中使用 BatchNorm 時應格外謹慎。BatchNorm 會均衡批次中所有元素的分布,因此同一批次中生成的所有圖像可以具有相似的特征。
使用 BatchNorm 生成示例:

- GAN 通常存在一種崩潰模式:生成器開始針對任何隨機輸入向量生成大致相同的圖像。有許多技術可以減少這種影響,并使生成器的生成更加多樣化。崩潰模式的示例如下:

示例
讓我們教 GAN 生成人臉。我們將使用 LFW 數據集
我們導入必要的庫:
import numpy as np
import os
from PIL import Image
import matplotlib.pyplot as plt
from IPython.display import clear_outputimport torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoaderfrom torchvision import transformsdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
輸出:
device(type=‘cuda’)
下文將介紹如何下載和準備數據。所有代碼與上面 AE 練習中的代碼類似。如果您之前未下載過此筆記本中的數據,則需要取消注釋并運行本節中的單元格。
下載并準備數據
!pip install deeplake==3.0
import deeplake
ds = deeplake.load('hub://activeloop/lfw')
dataloader = ds.pytorch(num_workers = 1, batch_size=1, shuffle = False)
import tqdm
from tqdm.auto import tqdm as tqdm
import PIL
faces = []
for b in tqdm(dataloader):faces.append(PIL.Image.fromarray(b['images'][0].detach().numpy()))
輸出:

class Faces(Dataset):def __init__(self, faces):self.data = facesself.transform = transforms.Compose([transforms.CenterCrop((90, 90)),transforms.Resize((64, 64)),transforms.ToTensor(),# transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])def __getitem__(self, index):x = self.data[index]return self.transform(x).float()def __len__(self):return len(self.data)
def plot_gallery(images, n_row=3, n_col=6, from_torch=False):"""Helper function to plot a gallery of portraits"""if from_torch:images = [x.data.numpy().transpose(1, 2, 0) for x in images]plt.figure(figsize=(1.5 * n_col, 1.7 * n_row))plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)for i in range(n_row * n_col):plt.subplot(n_row, n_col, i + 1)plt.imshow(images[i])plt.xticks(())plt.yticks(())plt.show()
dataset = Faces(faces)# dataset[0] 是對 __getitem__(0) 方法的調用
img = dataset[0]print(img.shape)# 繪制圖像及其分割蒙版
plot_gallery(dataset, from_torch=True)
輸出:

train_size = int(len(dataset) * 0.8)
val_size = len(dataset) - train_sizeg_cpu = torch.Generator().manual_seed(8888)
train_data, val_data = torch.utils.data.random_split(dataset, [train_size, val_size], generator=g_cpu)train_loader = torch.utils.data.DataLoader(train_data, batch_size=16, shuffle=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=16, shuffle=False)
GAN模型
讓我們分別聲明鑒別器和生成器模型。
鑒別器模型是一個用于圖像二分類的常規卷積網絡:
class Discriminator(nn.Module):def __init__(self):super().__init__()# in: 3 x 64 x 64self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(64)# out: 64 x 32 x 32self.conv2 = nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(128)# out: 128 x 16 x 16self.conv3 = nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1, bias=False)self.bn3 = nn.BatchNorm2d(256)# out: 256 x 8 x 8self.conv4 = nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1, bias=False)self.bn4 = nn.BatchNorm2d(512)# out: 512 x 4 x 4self.conv5 = nn.Conv2d(512, 1, kernel_size=4, stride=1, padding=0, bias=False)# out: 1 x 1 x 1self.flatten = nn.Flatten()self.sigmoid = nn.Sigmoid()def forward(self, x):x = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = F.relu(self.bn3(self.conv3(x)))x = F.relu(self.bn4(self.conv4(x)))x = self.conv5(x)x = self.flatten(x)x = self.sigmoid(x)return x
生成器模型也是一個卷積神經網絡,其輸出必須與數據集中的圖像具有相同的維度:
class Generator(nn.Module):def __init__(self, latent_size):super().__init__()# in: latent_size x 1 x 1self.convT1 = nn.ConvTranspose2d(latent_size, 512, kernel_size=4, stride=1, padding=0, bias=False)self.bn1 = nn.BatchNorm2d(512)# out: 512 x 4 x 4self.convT2 = nn.ConvTranspose2d(512, 256, kernel_size=4, stride=2, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(256)# out: 256 x 8 x 8self.convT3 = nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1, bias=False)self.bn3 = nn.BatchNorm2d(128)# out: 128 x 16 x 16self.convT4 = nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1, bias=False)self.bn4 = nn.BatchNorm2d(64)# out: 64 x 32 x 32self.convT5 = nn.ConvTranspose2d(64, 3, kernel_size=4, stride=2, padding=1, bias=False)self.tanh = nn.Tanh()# out: 3 x 64 x 64def forward(self, x):x = F.relu(self.bn1(self.convT1(x)))x = F.relu(self.bn2(self.convT2(x)))x = F.relu(self.bn3(self.convT3(x)))x = F.relu(self.bn4(self.convT4(x)))x = self.convT5(x)x = self.tanh(x)return x
我們將輸入生成器以生成圖像的隨機向量的大小設置為 128:
latent_size = 128
讓我們引入一個固定的噪聲向量,以便在網絡訓練過程中我們可以跟蹤生成器輸出在這個固定向量上的變化:
fixed_latent = torch.randn(64, latent_size, 1, 1, device=device)
現在讓我們開始訓練 GAN. 訓練算法如下:
-
訓練鑒別器:
- 拍攝真實圖像并賦予其標簽 1
- 使用生成器生成圖像并賦予其標簽 0
- 將分類器訓練成兩類
-
訓練生成器:
- 使用生成器生成圖像并賦予其標簽 0
- 使用鑒別器預測圖像是否真實
from IPython.display import clear_output
from torchvision.utils import make_grid# 用于對圖像進行反規范化的函數
stats = (0.5, 0.5, 0.5), (0.5, 0.5, 0.5)
def denorm(img_tensors):return img_tensors * stats[1][0] + stats[0][0]# 用于繪制圖像生成器生成結果的函數
# 在我們的固定噪聲向量上
def show_samples(latent_tensors):fake_images = generator(latent_tensors)fig, ax = plt.subplots(figsize=(8, 8))ax.set_xticks([]); ax.set_yticks([])ax.imshow(make_grid(denorm(fake_images[:64].cpu().detach()), nrow=8).permute(1, 2, 0))plt.show()# GAN的直接學習函數
def train(models, opts, loss_fns, epochs, train_loader, val_loader, batch_size=64):# Losses & scoreslosses_g = []losses_d = []real_scores = []fake_scores = []for epoch in range(epochs):# 打印當前epochprint('* Epoch %d/%d' % (epoch+1, epochs))# 使用來自 train_loader 的圖像來訓練網絡models["discriminator"].train()models["generator"].train()# 用于存儲損失值和準確率指標的數組# 網絡訓練期間的鑒別器loss_d_per_epoch = []loss_g_per_epoch = []real_score_per_epoch = []fake_score_per_epoch = []for i, X_batch in enumerate(train_loader):X_batch = X_batch.to(device)# 1. 鑒別器訓練步驟。# 清除鑒別器梯度opts["discriminator"].zero_grad()# 1.1 真實圖片出現虧損# 我們將批次 X_batch 中的真實圖像輸入到鑒別器的輸入中real_preds = models["discriminator"](X_batch)# 鑒別器對這些圖像的正確響應應該是一個由 1 組成的向量real_targets = torch.ones(X_batch.size(0), 1, device=device)# 我們在一批真實圖像上計算鑒別器損失值real_loss = loss_fns["discriminator"](real_preds, real_targets)cur_real_score = torch.mean(real_preds).item()# 1.2 因假圖片而蒙受損失# 讓我們生成虛假圖像。為此,我們生成一個大小為 (batch_size, latent_size, 1, 1) 的隨機噪聲向量,并將其輸入到生成器中。latent = torch.randn(batch_size, latent_size, 1, 1, device=device)# 我們得到一批隨機向量的生成器輸出fake_images = models["generator"](latent)# 我們將來自批次 X_batch 的假圖像輸入到鑒別器的輸入中fake_preds = models["discriminator"](fake_images)# 鑒別器對這些圖像的正確響應應該是一個零向量fake_targets = torch.zeros(fake_images.size(0), 1, device=device)# 計算一批假圖像上的鑒別器損失值fake_loss = loss_fns["discriminator"](fake_preds, fake_targets)cur_fake_score = torch.mean(fake_preds).item()real_score_per_epoch.append(cur_real_score)fake_score_per_epoch.append(cur_fake_score)# 1.3 更新鑒別器權重:執行梯度下降步驟loss_d = real_loss + fake_lossloss_d.backward()opts["discriminator"].step()loss_d_per_epoch.append(loss_d.item())# 2. 生成器訓練步驟# 清理生成器梯度opts["generator"].zero_grad()# 讓我們生成虛假圖像。為此,我們生成一個大小為 (batch_size, latent_size, 1, 1) 的隨機噪聲向量,并將其輸入到生成器中。latent = torch.randn(batch_size, latent_size, 1, 1, device=device)# 我們得到一批隨機向量的生成器輸出fake_images = models["generator"](latent)# 我們將來自批次 X_batch 的假圖像輸入到鑒別器的輸入中preds = models["discriminator"](fake_images)# 我們將這些圖片的“正確”答案向量設置為 1 的向量targets = torch.ones(batch_size, 1, device=device)# 計算預測和目標之間的損失loss_g = loss_fns["generator"](preds, targets)# 更新生成器權重loss_g.backward()opts["generator"].step()loss_g_per_epoch.append(loss_g.item())# 每 100 次訓練迭代,我們將輸出指標的當前值# 并繪制圖像生成器生成的結果# 來自固定的隨機向量if i%100 == 0:# Record losses & scoreslosses_g.append(np.mean(loss_g_per_epoch))losses_d.append(np.mean(loss_d_per_epoch))real_scores.append(np.mean(real_score_per_epoch))fake_scores.append(np.mean(fake_score_per_epoch))# Log losses & scores (last batch)print("Epoch [{}/{}], loss_g: {:.4f}, loss_d: {:.4f}, real_score: {:.4f}, fake_score: {:.4f}".format(epoch+1, epochs,losses_g[-1], losses_d[-1], real_scores[-1], fake_scores[-1]))# Show generated imagesclear_output(wait=True)show_samples(fixed_latent)return losses_g, losses_d, real_scores, fake_scores
最后,我們將聲明模型、優化器、損失并訓練模型:
generator = Generator(latent_size).to(device)
discriminator = Discriminator().to(device)models = {'generator': generator,'discriminator': discriminator
}criterions = {"discriminator": nn.BCELoss(),"generator": nn.BCELoss()
}lr = 0.0002
optimizers = {"discriminator": torch.optim.Adam(models["discriminator"].parameters(),lr=lr, betas=(0.5, 0.999)),"generator": torch.optim.Adam(models["generator"].parameters(),lr=lr, betas=(0.5, 0.999))}losses_g, losses_d, real_scores, fake_scores = train(models, optimizers, criterions, 10, train_loader, val_loader)
輸出:

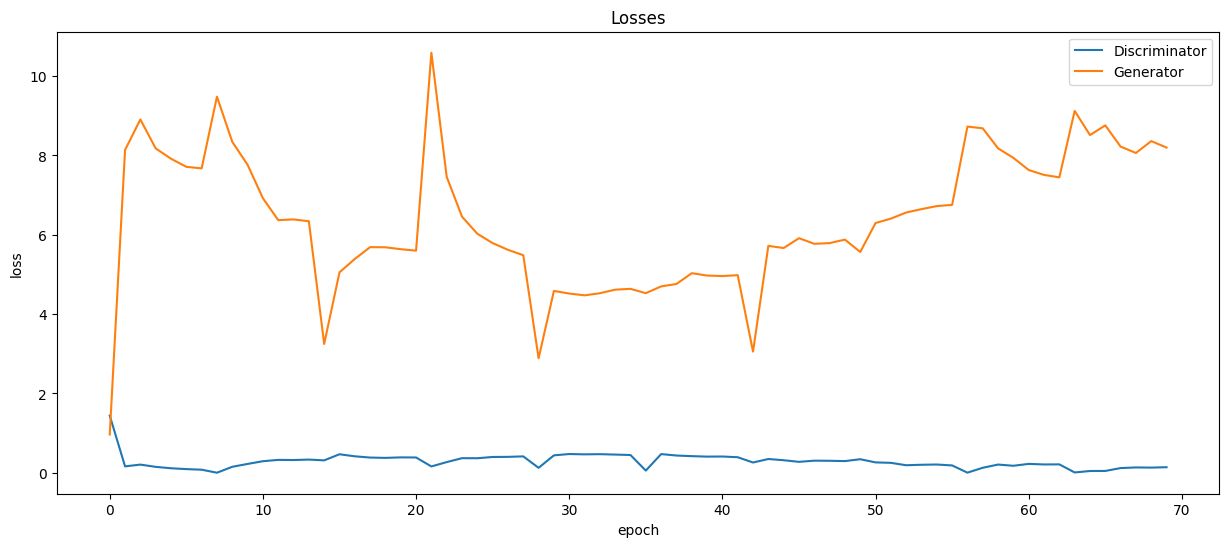
讓我們直觀地看到網絡訓練期間生成器的損失和準確度指標的變化圖:
plt.figure(figsize=(15, 6))
plt.plot(losses_d, '-')
plt.plot(losses_g, '-')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['Discriminator', 'Generator'])
plt.title('Losses');
輸出:
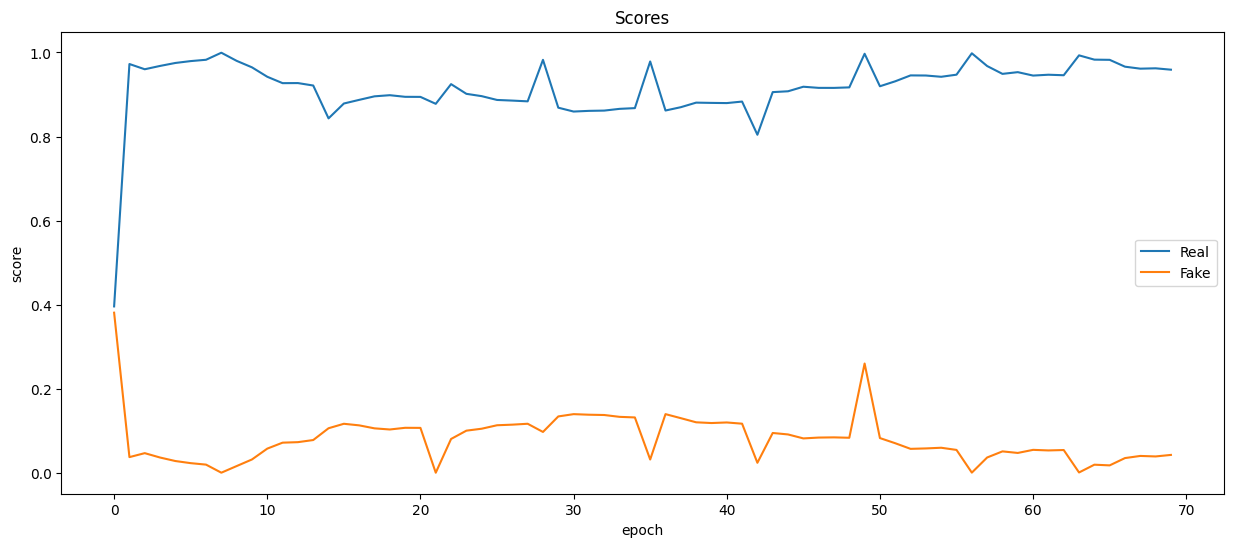
plt.figure(figsize=(15, 6))plt.plot(real_scores, '-')
plt.plot(fake_scores, '-')
plt.xlabel('epoch')
plt.ylabel('score')
plt.legend(['Real', 'Fake'])
plt.title('Scores');
輸出:
額外知識
-
深度學習學校的一系列關于自動編碼器的課程:
-
講座:生成模型和自動編碼器;
-
研討會:自動編碼器;
-
研討會:VAE;
-
深度學習學校的一系列關于生成對抗網絡的課程:
-
講座:生成模型。生成對抗網絡;
-
研討會:GAN
-
已完成關于不同類型自編碼器(Vanilla AE、VAE、條件 VAE)的筆記 及相關解釋
-
關于 VAE 的英文文章,其中包含對相關工作思路和數學公式的詳細解釋















AOP參數攔截)



