大家讀完就覺得有幫助記得關注和點贊!!!
摘要
我們解決了在無約束環境中進行全身人體識別的問題。這個問題出現在諸如IARPA高空和遠距離生物識別與身份識別(BRIAR)計劃等監視場景中,其中生物識別數據是在長距離、高角度以及不利的大氣條件下(例如,湍流和高風速)捕獲的。為此,我們提出了FarSight,一個統一的端到端人體識別系統,它集成了跨越面部、步態和體型模態的互補生物特征線索。FarSight整合了四個核心模塊中的新型算法:多目標檢測和跟蹤、識別感知視頻恢復、模態特定生物特征編碼以及質量引導的多模態融合。這些組件旨在在退化的圖像條件、大的姿勢和尺度變化以及跨域差距下協同工作。在BRIAR數據集上的大量實驗證明了FarSight的有效性,BRIAR數據集是用于遠程、多模態生物識別的最全面的基準之一。與我們的初步系統[1]相比,該系統在1:1驗證準確率(TAR@0.1% FAR)上實現了34.1%的絕對增益,在閉集識別(Rank-20)上實現了17.8%的提升,并在開集識別錯誤(FNIR@1% FPIR)上實現了34.3%的降低。此外,FarSight在2025 NIST RTE視頻人臉評估(FIVE)中進行了評估,該評估在BRIAR數據集上進行標準化的人臉識別測試。這些結果確立了FarSight作為在具有挑戰性的現實條件下進行操作性生物識別的最先進解決方案的地位。
索引詞—全身生物特征識別,大氣湍流緩解,生物特征編碼,多模態融合,開放集生物特征識別,人臉識別,步態識別,體型識別
1 引言
在遠距離和高視角下進行的無約束生物特征識別對于各種應用至關重要,包括執法、邊境安全、廣域監控和公共媒體分析[2]–[4]。在現有方法中,全身生物特征識別[1],[5]–[9]已成為該領域的核心,因為它捕捉了豐富的解剖和行為特征組合——例如面部外觀、步態和體型——與單模態系統相比,它對遮擋、退化和模態損失具有更強的抵抗力。盡管全身識別系統具有潛力,但在現實場景中部署此類系統在技術上仍然具有挑戰性。高性能系統不僅必須包含穩健的多模態生物特征建模,還必須支持以下模塊:
精確的人員檢測與跟蹤、低質量圖像增強、大氣湍流緩解以及用于處理不可靠數據的自適應融合策略。
為了開發和評估滿足這些需求的生物識別系統,必須能夠訪問反映真實世界監控條件全部復雜性的數據集。IARPA 高空和遠距離生物識別與身份識別 (BRIAR) 計劃1 是朝著這個方向共同努力[8],[9],旨在促進生物識別系統的開發,使其能夠在這些不受約束的場景中可靠地執行。圖 1 展示了 BRIAR 全身圖像捕獲場景,包括受控的室內注冊集合和具有挑戰性的室外探測集合。這些場景模擬了人員識別中面臨的真實世界挑戰,包括:(i) 由遠距離捕獲(高達 1000 米)和大氣湍流引起的低質量視頻幀,折射率結構常數范圍從 Cn2 = 10?17 到 10?14 m?2/3; (ii) 來自高達 400 米高度的升高平臺(無人機)的大偏航角和俯仰角(高達 50?);(iii) 由于低視覺質量而導致的功能集退化,其中瞳孔間距 (IPD) 在 15–100 像素之間;(iv) 開放集搜索的復雜性,其中必須將探測圖像與包含干擾項的圖庫進行匹配;以及 (v) 由 lim 引起的顯著域間隙
?https://www.iarpa.gov/research-programs/briar
有限的訓練數據和真實世界條件的多樣性。
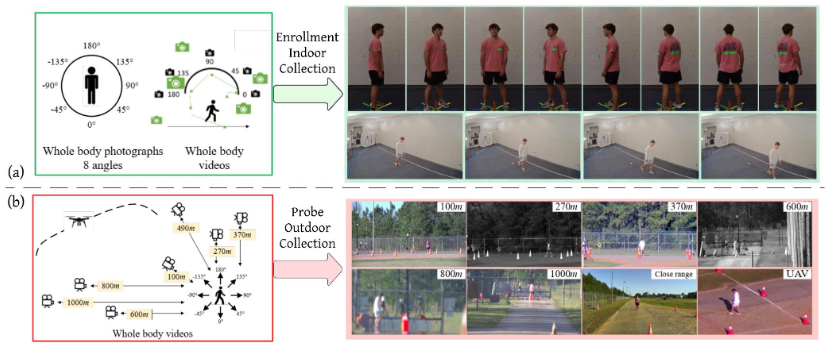
圖 1:IARPA BRIAR 全身圖像捕獲場景示意圖。(a) 注冊室內采集:在受控條件下從多個視角捕獲的高質量靜態圖像和視頻。(b) 探測室外采集:在室外環境中以不同的距離和仰角捕獲的視頻,具有大氣湍流等挑戰性因素。這些設置反映了遠程生物識別中遇到的真實世界條件。已獲得拍攝對象許可,允許在出版物中使用圖像。
為了應對不受約束的遠距離生物特征識別所帶來的挑戰,我們提出了FarSight,一個集成的端到端系統,旨在利用多模態生物特征線索進行穩健的行人識別。FarSight結合了面部、步態和體型模態,以確保即使在個體線索不可靠或退化的情況下也能保持識別性能。該系統包含四個緊密耦合的模塊,每個模塊都解決了識別流程中的一個關鍵組成部分:
(1)一個多目標檢測和跟蹤模塊,能夠在動態、雜亂和低分辨率條件下準確地定位視頻序列中的個體。
(2)一個識別感知的視頻恢復模塊,通過聯合優化圖像質量和生物特征保真度來減輕視覺退化——特別是由于湍流和遠距離模糊造成的退化。
(3)一個生物特征編碼模塊,利用大型視覺模型和特定于模態的架構設計的最新進展,為每個模態提取穩健的表示。
(4)一個質量引導的多模態融合模塊,自適應地整合跨模態的分數,同時考慮可變的輸入質量和部分觀測。
我們系統的初步版本[1]先前已在IEEE/CVF計算機視覺應用冬季會議(WACV 2024)上發表。在這一基礎上,我們大幅升級了每個模塊,以提高在驗證、閉集識別和開集搜索任務中的識別性能。目前的系統還整合了關鍵的架構增強功能,以支持更低的延遲、更少的內存使用和更高的可擴展性。下面,我們總結了更新后的FarSight系統中每個模塊引入的主要改進:
?多目標檢測與跟蹤:我們的初步
系統[1]采用了一種基于R-CNN的聯合人體-面部檢測器[10],[11],該檢測器缺乏對多目標跟蹤的支持,并且表現出較高的推理延遲。為了解決這些局限性,我們引入了兩個關鍵升級:首先,我們采用了一個雙檢測器框架,使用BPJDet[12]進行粗略的人體-面部定位,然后通過YOLOv8[13]進行驗證,以減少誤報。這種替換提高了檢測精度和運行時效率。其次,我們開發了PSR-ByteTrack,這是一種基于ByteTrack[14]構建的增強型多目標跟蹤器。PSR-ByteTrack通過引入一種基于補丁的檢索機制來緩解諸如ID切換、碎片化軌跡和小目標再識別失敗等問題,該機制在內存中維護特定于主體的外觀特征。
? 識別感知視頻恢復:我們介紹了門控循環湍流緩解(GRTM)網絡,這是一種新穎的基于視頻的恢復模型,專為遠距離、湍流退化的圖像設計。使用輕量級分類器有選擇地觸發恢復,從而減少不必要的計算并避免潛在的特征失真。該系統的一個關鍵貢獻是其緊密集成的恢復-識別協同優化框架,該框架將識別目標直接集成到恢復訓練過程中,引導模型增強對身份判別至關重要的特征。
? 生物特征(面部、步態和體型)特征編碼:我們對每個特定模態的模型進行升級,采用與任務對齊的架構改進和訓練策略,以應對遠距離、無約束生物特征識別的挑戰。i) 面部:我們提出 KP-RPE [15],一種關鍵點相關的相對位置編碼技術,可顯著改善對未對齊和低質量面部圖像的處理。ii) 步態:我們引入 BigGait [16],這是第一個基于
大型視覺模型(LVM)。該方法從特定任務先驗知識轉向通用視覺知識,從而提高了在各種條件下的步態識別能力。iii) 身體形狀:我們提出了CLIP3DReID [17],通過將語言描述與視覺感知協同集成,顯著增強了身體匹配能力。該方法利用預訓練的CLIP模型來開發具有區分性的身體表征,從而有效地提高了識別準確率。
?質量引導的多模態融合:我們提出質量評估器(QE),這是一種評估模態質量的通用方法,以及一種由模態特定質量權重引導的可學習的分數融合方法,稱為質量引導的分數融合專家混合模型(QME),以提高分數融合性能。
? 開放集搜索:我們引入了一種新的訓練策略[18],該策略明確地納入了非配對主體。這種方法使訓練目標與開放集條件對齊,從而使模型能夠區分已注冊身份和未知身份。因此,它顯著提高了開放集識別的準確性,同時也通過更好的泛化能力增強了封閉集性能。
? 系統集成:我們整合了若干系統級增強功能,包括:i) 自動化多GPU容器化,使每個GPU能夠獨立處理客戶端請求;以及 ii) 支持多主體探針視頻,允許單個輸入生成多個主體跟蹤條目。
總而言之,我們提出的FarSight系統的貢獻包括:
采用基于雙YOLO的檢測方法,結合我們的PSR-ByteTrack,實現穩健、準確和低延遲的多目標檢測和跟蹤。
一個物理信息驅動的視頻恢復模塊(GRTM),它顯式地對大氣湍流進行建模,并集成了一個任務驅動、識別感知的優化框架,以增強保持身份的圖像質量。
針對面部、步態和體型的有效特征編碼,并由大型視覺模型框架增強。
該方法整合了一種新穎的開放集搜索和多模態特征融合方法,顯著提高了各種場景下的識別性能。
依照API規范的更新,實現可擴展的系統集成,該集成具有自動化的每GPU多處理能力,并支持多被試探針處理。
對BRIAR數據集(協議v5.0.1)進行全面評估,并通過2025年NIST RTE視頻人臉評估(FIVE)[19]進行獨立驗證,證實了FarSight在真實條件下運行的生物特征識別方面的最先進性能。
2 相關工作
全身人體識別。全身人體識別整合了多種生物特征,如面部、步態和體型,以在具有挑戰性的場景中實現最先進的識別精度。這種整體方法與傳統生物識別系統形成鮮明對比,后者通常側重于單一模態[20]–[28]。通過整合多種模態,FarSight克服了單個特征的局限性,同時利用了它們的互補優勢。例如,當面部識別在嚴重的姿勢變化和不良光照條件下會遇到困難時,步態分析可能會受到行走速度和服裝變化的影響。類似地,體型提供了持續的線索,但可能會因服裝和姿勢的變化而改變。最近的研究[1],[5],[6]越來越多地采用整合檢測、圖像恢復和生物特征分析的整體系統。然而,許多現有系統仍然依賴于在受限數據集上訓練的相對小規模網絡,并且未能充分利用不同生物特征模態和系統組件之間的潛在協同作用。這促使我們開發一個集成系統,該系統在整個識別流程中進行聯合優化。我們的工作建立在這一趨勢之上,通過將大型視覺模型、任務感知恢復、開放集訓練和自適應多模態融合整合到一個可擴展的端到端系統中,并在真實世界環境中進行評估。
湍流成像的物理建模。大氣湍流是遠程和高空人員識別中圖像退化的主要來源,嚴重影響視覺清晰度和生物識別準確性。這一挑戰需要逼真的模擬方法,以支持訓練產生穩健的識別系統,并支持開發有效的恢復算法。模擬技術范圍廣泛——從基于計算光學的物理模型[29](以計算成本為代價提供高保真度),到基于計算機視覺的方法[30](優先考慮效率但通常缺乏物理基礎)。中間方法包括基于亮度函數的模擬[31]和基于學習的技術[32],盡管后者與運行時約束不同,尤其是在深度學習設置中[33]。為了平衡真實性和效率,我們采用了一種基于Zernike多項式表示的隨機相位畸變的湍流模型。我們的方法通過將數值導出的卷積核應用于清晰圖像并注入白噪聲來合成湍流效應,從而產生逼真的退化觀測結果。
用于生物特征識別的圖像恢復。生物特征識別依賴于從各種視覺輸入中提取魯棒特征。當圖像質量欠佳時,恢復技術可以提高圖像的保真度,進而提高識別性能。然而,這些方法可能會通過臆造特征而無意中改變身份,或者通過引入偽影而降低準確性。此外,傳統的恢復流程通常針對諸如PSNR或SSIM等感知指標進行優化,這些指標不能很好地反映識別準確率[34]–[37]。在大氣湍流下,重建已被發現是有益的[38]。雖然這些努力主要依賴于單幀數據,但多幀湍流緩解可以帶來更穩定和可靠的恢復[39],[40]。相比之下,FarSight引入了一個確定性的多幀恢復框架,該框架與生物特征識別準確率目標共同優化。該策略將恢復與識別準確率顯式對齊,在減輕視覺幻覺風險的同時,保留身份特征。
行人檢測與追蹤。在多個幀中檢測和關聯行人對于開發精確的行人識別系統至關重要。早期方法[41],[42]使用基于R-CNN的檢測器,該檢測器具有多個頭部,用于獨立的身體和面部檢測,然后是一個匹配模塊。BFJDet [11]提出了一個框架,用于轉換任何單階段或雙階段檢測器以支持身體和面部檢測。最近,PairDETR [43]使用受DETR啟發的二分框架來匹配身體和面部邊界框。FarSight [1]使用Faster R-CNN [44]來聯合檢測人體和面部。由于實時檢測算法的最新進展,特別是YOLO系列[13],[45]–[47],BPJDet開發了一種使用YOLOv5 [45]的聯合檢測算法和一個關聯解碼來匹配身體和面部。Farsight利用BPJDet作為主要檢測器,并使用YOLOv8 [13]來消除錯誤的身體檢測。
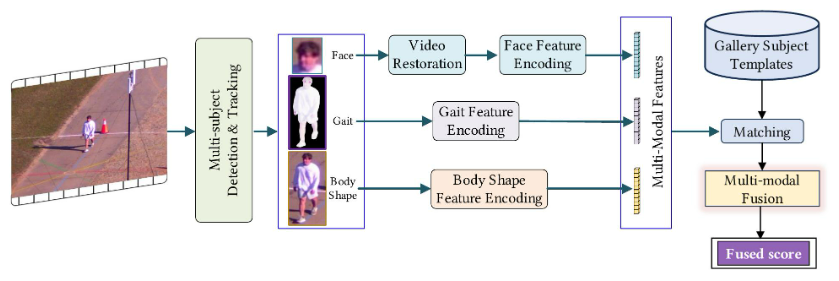
圖 2:所提出的 FarSight 系統概述,該系統包含四個模塊:(i)多目標檢測與跟蹤;(ii)識別感知圖像恢復;(iii)面部、步態和體型的模態特定編碼;以及(iv)質量引導的多模態生物特征融合。
通過關聯(邊界框或分割掩碼)進行跟蹤是一種成熟的多目標跟蹤方法 [14], [48]–[50]。在關聯范式下,ByteTrack [14] 緩存低置信度的邊界框,從而為高置信度和低置信度的檢測提供準確的跟蹤器。由于其在多目標跟蹤方面的出色性能,我們使用 ByteTrack 作為我們的基礎跟蹤器,并配備了具有外觀感知能力的基于補丁的后處理技術,以實現準確的 track-id 分配,從而實現穩健的行人識別。
多模態生物特征融合。分數層融合是多模態生物特征識別系統中一種廣泛使用的方法,其中來自個體模態(如面部、步態或體型)的相似度分數被組合起來,以形成最終的個人識別決策。傳統技術包括基于歸一化的方法(例如,Z-score、Min-Max),然后進行均值、最大值或最小值分數融合[51]。基于似然比的方法[52]也被提出,以提供概率可解釋性。盡管這些融合方法很簡單,但它們通常無法解釋模態特異性的可靠性或輸入中動態的質量變化。一個關鍵的挑戰在于確定真實世界中個體內部差異下的最佳模態對齊和加權。最近的一些工作已經轉向特征層融合[53],結合跨模態(例如,面部和步態)的信息,以利用跨模態相關性。然而,這些方法可能受到表示不兼容或缺乏對缺失模態的魯棒性的影響。為了解決這些局限性,我們的方法引入了一種質量引導的分數融合框架,該框架根據探針的估計質量動態地權衡每個模態的貢獻。
開放集生物特征搜索。開放集搜索是全身生物特征識別系統中的一項關鍵需求,其中探針必須與已注冊的主體進行匹配(如果存在),或者如果未在圖庫中注冊,則將其拒絕。盡管其具有重要的實際意義,但先前在全身生物特征識別方面的大部分工作都集中在封閉集識別上,而很少關注顯式建模開放集動態。一種常見的基線是極值機(EVM)[54],它估計探針屬于每個圖庫主體的可能性,并拒絕低置信度的匹配。在我們的工作[18]中,我們引入了一種訓練策略,該策略通過在訓練期間納入非配對身份來顯式模擬開放集條件。訓練和評估之間的這種對齊提高了泛化能力,并提高了在開放集和封閉集場景中的性能。
3 提出的方法
3.1 FarSight系統概述
如圖2所示,所提出的FarSight系統由四個緊密集成的模塊組成:多目標檢測與跟蹤、識別感知圖像恢復、模態特定特征編碼(面部、步態和體型)以及質量引導的多模態融合模塊。這些組件在一個統一的端到端框架內進行協調,旨在解決第節中概述的現實挑戰。1——即遠距離捕獲、姿勢變化、圖像質量下降和域偏移。
該系統針對可擴展性和效率進行了優化,可處理約 99,000 張靜態圖像和 12,000 個視頻軌道,同時在使用 NVIDIA RTX A6000 GPU 的情況下,在 1080p 視頻上保持 7.0 FPS 的端到端處理速度。它支持動態批量大小調整以進行 GPU 資源管理,并通過基于 Google RPC 構建的 API 與外部系統通信。視頻輸入通過配置文件指定,提取的生物特征以 HDF5 格式導出,用于下游評估和評分。識別流程始于人員檢測和跟蹤。對于每個軌跡片段,裁剪后的幀被傳遞到步態和體型編碼器。同時,面部區域在進入面部編碼器之前會進行修復,以減輕退化。每個探針包含單個視頻片段,而圖庫注冊(由多個視頻和靜態圖像組成)被聚合為每個模態的單個特征向量。
3.2 多目標檢測與跟蹤
3.2.1 行人檢測
為了在無約束的設置下實現可靠的主體定位,我們采用了一種雙檢測器策略,該策略結合了BPJDet [12]和YOLOv8 [13],以實現穩健的身體-面部檢測。BPJDet作為主要檢測器,獨立預測身體和面部邊界框,并通過計算內部IoU(定義為候選身體-面部對之間的交集與面部邊界框面積之比)來關聯它們。
在開發過程中,我們觀察到BPJDet在存在干擾對象(例如,交通錐或機器人裝置)時偶爾會產生假陽性,這對下游生物特征編碼產生負面影響。為了緩解這個問題,我們引入了一個使用YOLOv8 [13]的驗證步驟。具體而言,只有當YOLOv8也檢測到置信度閾值為0.7的相應人體時,才會保留來自BPJDet的檢測結果。此交叉驗證步驟可顯著減少假陽性,而不會影響召回率。在進行人體-面部檢測之后,使用我們下文描述的PSR-ByteTrack跟蹤器,在各個幀中對對象進行時間關聯。
吞吐量優化。雖然BPJDet和YOLOv8的樸素集成是準確的,但由于冗余的預處理,引入了計算瓶頸。兩種檢測器共享相似的輸入轉換,導致冗余的CPU操作和次優的GPU利用率。為了解決這個問題,我們實現了兩個關鍵的優化:(i)一個統一的預處理流程,以消除檢測器之間的共享步驟;(ii)一個GPU高效的流程,從而減少CPU負載。這些改進在單個GPU上實現了5倍的吞吐量提升,而沒有影響檢測精度。
3.2.2 人員跟蹤
對于多目標跟蹤,我們以ByteTrack算法[14]為基礎,該算法采用兩階段關聯機制——首先關聯高置信度檢測結果,然后關聯低置信度檢測結果。雖然ByteTrack在一般條件下表現良好,但我們觀察到其在遠距離監控設置中存在兩個主要限制:(i)遮擋期間頻繁的ID切換,以及(ii)當重新識別暫時離開并重新進入場景的主體時,出現碎片化的軌跡。為了解決這些問題,我們引入了基于塊相似性檢索的ByteTrack(PSR-ByteTrack),這是一個基于塊的后處理框架,它使用基于外觀的重識別來改進ByteTrack的輸出。
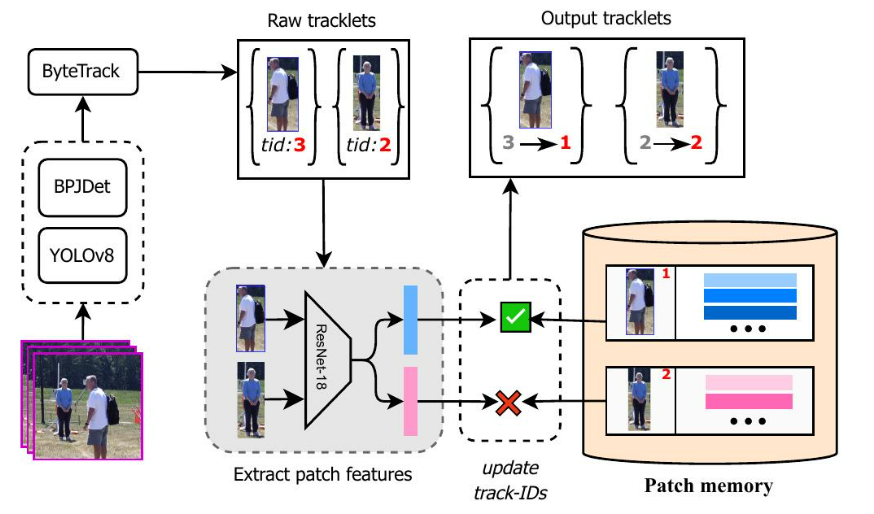
圖 3:FarSight 中多目標檢測和跟蹤的概述。一種雙檢測器方法結合了用于身體-面部定位的 BPJDet [12] 和用于抑制假陽性的 YOLOv8 [13]。然后使用 PSR-ByteTrack [14] 跨幀關聯檢測到的目標,該方法通過基于補丁相似性的檢索和軌跡 ID 校正來改進 ByteTrack 的輸出。這確保了在遮擋、目標重入和遠距離退化情況下的持續跟蹤。
如圖3所示,我們維護一個補丁記憶庫,其中每個條目對應于一個跟蹤ID,并包含來自身體補丁的ResNet-18 [55]編碼的特征。流程如下:(i)使用身體檢測從ByteTrack獲得初始軌跡。(ii)對于每個新的檢測,如果關聯的跟蹤ID在記憶庫中尚不存在,則我們存儲其補丁特征。(iii)每隔
N
幀,追加新的補丁以考慮時間外觀變化。(iv)對于每個傳入的補丁,我們計算與記憶庫中存儲的特征的均方誤差(MSE),并分配具有最低誤差的跟蹤ID,前提是相似度超過預定義的閾值。(v)與所有現有條目的相似度較低的檢測被視為新對象,并分配新的ID。
3.3 識別感知視頻修復
3.3.1 大氣湍流建模與仿真 大氣湍流造成的圖像退化是遠程人臉識別中的一個關鍵挑戰,它引入了空間和時間上變化的模糊。這種失真的嚴重程度受到傳播距離、相機參數和湍流強度的影響 [56],[57]。為了訓練在這種條件下具有魯棒性的模型,我們使用基于澤尼克多項式湍流模擬的無退化圖像對進行合成 [33],[58],[59],應用于靜態 [60] 和動態 [61] 場景 [62]。我們的模擬涵蓋了一系列湍流強度(例如,D/r0 ∈ [1, 10]) 和相機配置(例如,f-數、傳感器尺寸),提供了與 FarSight 真實世界采集對齊的各種訓練數據。
3.3.2 GRTM網絡和選擇性恢復 為了增強嚴重大氣畸變下的面部圖像,我們設計了一種高效的門控循環湍流緩解(GRTM)網絡,該網絡基于最先進的視頻湍流緩解框架DATUM [40]。為了提高效率和魯棒性,我們移除了[40]中的光流對齊,因為它需要大量的計算資源,并且可能會引入偽影,從而損害下游的識別任務。為了進一步減少恢復偽影可能造成的負面影響,我們采用了一個在真實視頻及其恢復對上訓練的視頻分類器,以指示恢復是否可能提高識別性能。
3.3.3 恢復與識別的協同優化 傳統的恢復模型通常優化通用的視覺指標(例如,PSNR、SSIM),這些指標與生物識別的目標不一致,并且可能會產生改變身份的幻覺特征。為了克服這個問題,我們提出了一個恢復-識別協同優化框架,如圖4所示。該框架采用教師-學生配置,其中凍結的教師模型提供高質量的視覺參考,而學生模型經過微調,以共同優化視覺保真度和身份保持。
形式上,此協同訓練過程的組合優化目標定義如下:
![]()
其中Ldistill是蒸餾損失,通過最小化教師和學生修復模型輸出之間的距離來保持原始的修復能力,從而有效地保持修復圖像的視覺質量和真實感。同時,Ladaface[21]將特定于生物特征的人臉分類損失引入到協同訓練過程中。該組件明確地引導修復模型增強有助于提高身份區分能力的面部特征。
所提出的聯合優化策略使得每個恢復和對齊的幀都能在視覺質量和身份保持方面得到評估。通過迭代反饋,恢復模型學習優先考慮對準確生物特征識別至關重要的視覺特征,同時抑制可能引入歧義或身份漂移的細節。與強調感知吸引力的傳統方法相比,我們的方法確保恢復不僅在視覺上連貫,而且還經過優化以提高識別性能。
3.4 基于大型視覺模型的增強型生物特征編碼
3.4.1 面部
傳統的面部識別模型通常難以提取有意義的面部特征,特別是由于它們依賴于正確對齊的面部圖像。為了解決這一局限性,我們引入了關鍵點相對位置編碼(KP-RPE)[15]機制,該機制直接操縱視覺Transformer(ViT)模型中的注意力機制。通過編碼面部關鍵點的相對位置,KP-RPE增強了模型對未對齊和未見幾何仿射變換的魯棒性。
相對位置編碼 (RPE)。相對位置編碼 (RPE) 最早于 [63] 中提出,并在 [64]、[65] 中得到改進,它對序列相對位置信息進行編碼,以增強自注意力機制。與絕對位置編碼不同,RPE 考慮輸入元素之間的相對空間關系,使其特別適用于視覺和語言任務。改進的自注意力機制將相對位置嵌入?RQ ij、RK ij和?RV ij納入查詢-鍵交互中,其中每個?Rij都是一個可學習的向量,用于編碼第 i 個查詢和第 j 個鍵或值之間的相對距離。這些嵌入允許基于序列相對距離而不是固定位置來調整注意力分數。已經探索了各種距離度量,例如量化的歐幾里得距離。來計算這些關系 [66]、[67]。
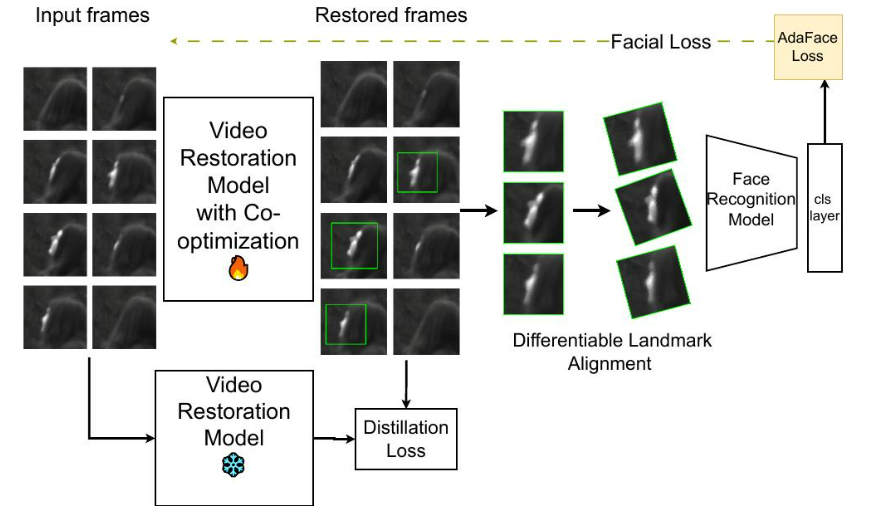
圖 4:所提出的恢復-識別協同優化框架的訓練流程。孿生模型和我們的人臉識別模型之間的蒸餾損失有助于我們定義人臉識別模型的損失。如圖所示,并非所有幀都可能有檢測結果,只有具有檢測結果的幀才會在?Ladaface中使用。
關鍵點相對位置編碼(KP-RPE)通過將關鍵點信息納入位置偏置矩陣?Bij中,從而改進了傳統的RPE。矩陣?Bij被定義為關鍵點的函數:Bij = F(P)[d(i, j)],而不是使距離函數 d(i, j) 顯式地依賴于關鍵點,因為這會由于預計算約束而限制效率。函數 F(P) 將關鍵點轉換為可學習的偏移表,確保注意力機制能夠根據關鍵點相關的關系進行調整。最終的公式通過允許偏移函數相對于查詢-鍵位置和關鍵點,從而增強了標準RPE。這使得RPE能夠依賴于圖像內容的位置,從而使模型對不對齊具有魯棒性。在圖 5 中,我們提供了KP-RPE的說明。
3.4.2 步態
傳統的步態識別方法主要依賴于由監督學習驅動的多個上游模型來提取顯式的步態特征,例如輪廓和骨骼點。我們打破了這一趨勢,推出了BigGait [16] 方法,該方法利用強大的大型視覺模型 (LVM) 生成的通用知識來取代傳統的步態表示。如圖 6 所示,我們設計了三個分支,以無監督的方式從 LVM 中提取與步態相關的表示。這種前沿的步態方法在域內和跨域評估中均實現了最先進的性能。
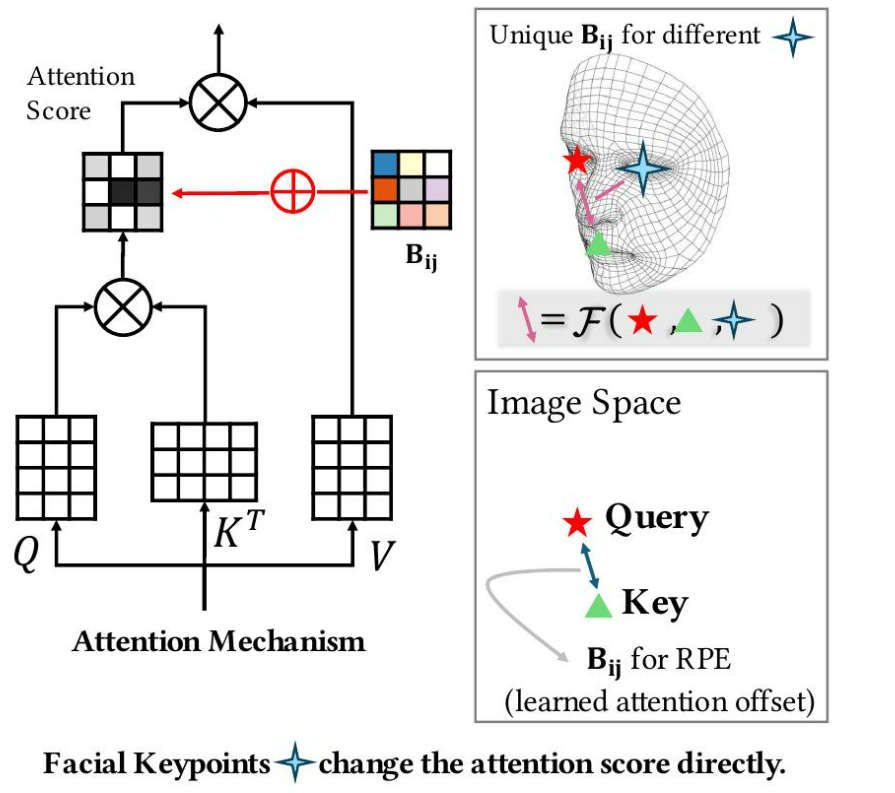
圖 5:關鍵點相對位置編碼 (KP-RPE) 的說明 [15]。在標準 RPE 中,注意力偏移偏差是基于查詢?
Q和鍵?K之間的距離計算的。在 KP-RPE 中,RPE 機制通過結合面部關鍵點位置得到進一步增強,從而使 RPE 能夠動態調整到圖像的方向和對齊方式。
BigGait 并行處理輸入 RGB 視頻的所有幀。為了保持準確的身體比例,它應用了一種 Pad-and-Resize 技術,在將每個檢測到的身體區域輸入到上游模型之前,將其調整大小為 448 × 224 像素。上游 DINOv2 [68] 是一個可擴展的 ViT 主干網絡,選擇 ViT-S/14 (21M) 和 ViT-L/14 (302M) 用于 BigGait-S 和 BigGait-L。調整大小后的 RGB 圖像被分割成 14 × 14 的圖像塊,從而產生維度為 32 × 16 的標記化向量。如圖 6 所示,
f1、f2、f3和 f4 是由 ViT 主干網絡的各個階段生成的特征圖,其對應的語義層次結構從低到高。我們將這四個特征圖沿通道維度連接起來,形成?fc。形式上,特征圖?f4和?fc通過 MaskAppearance 和 Denoising 分支進行處理。
掩碼分支。此分支充當一個自編碼器,生成前景掩碼以使用?f4:抑制背景噪聲。

其中E和D表示線性卷積層,其卷積核大小為1 × 1,輸出通道的維度分別為2和384。然后,使用前景掩碼m來屏蔽fc中的背景區域,從而產生前景分割特征fm:
![]()
其中“·”表示乘法運算符。
外觀分支。該分支從fm:中提取身體形狀特征。
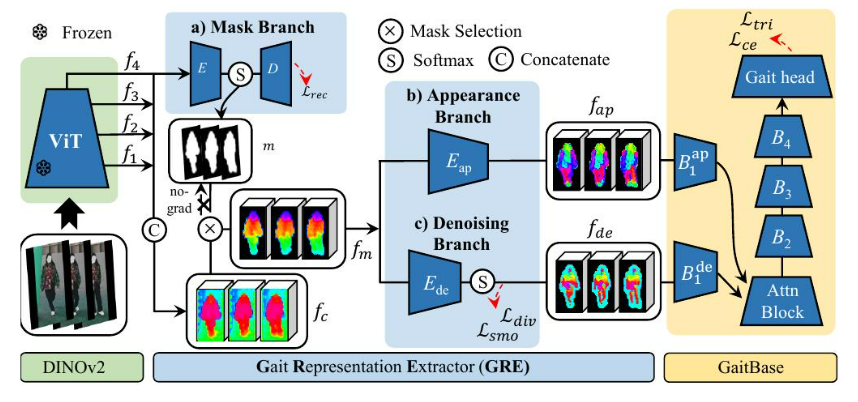
圖 6:BigGait [16] 的工作流程。我們采用 DINOv2 [68] 作為上游模型來生成特征圖:
f1、f2、f3、f4,這些特征圖來自 ViT 主干網絡的不同階段,具有從低到高的語義層級結構。步態表示提取器 (GRE) 包含三個分支,分別用于背景去除、特征轉換和去噪。改進的 GaitBase 用于步態度量學習。
![]()
其中?Eap是一個線性卷積層,具有 1 × 1 的卷積核和?C的輸出通道維度。
去噪分支。為了抑制高頻紋理噪聲并獲得類似骨骼的步態特征,該分支采用了平滑度損失
Lsmo和多樣性損失Ldiv。具體而言,平滑度損失為:
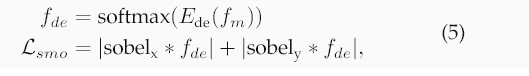
其中Ede包含一個非線性塊,該塊由一個1 × 1卷積、批歸一化、GELU激活以及隨后的另一個1 × 1卷積組成。多樣性損失為:
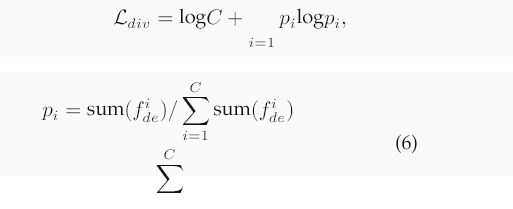
其中fdei表示第i個通道的激活圖,而pi是第i個通道的激活比例,相對于所有通道的總激活。常數項
(logC)表示最大熵,包含該項是為了防止負損失。最后,我們使用注意力權重融合fap和fde
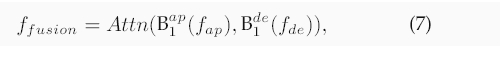
其中Attn是一個注意力模塊,遵循[69],并且ffusion將被送入GaitBase [22]。
3.4.3 身體形態
為了克服諸如衣著和顏色等基于外觀的屬性的局限性,我們引入了 CLIP3DReID [17],這是一種顯著增強人體形狀特征編碼的新方法。如圖 7 所示,該方法利用預訓練的 CLIP 模型進行知識蒸餾,整合語言描述與視覺感知,以實現穩健的行人識別。CLIP3DReID 自動使用語言描述符標記人體形狀,采用最優傳輸來對齊局部視覺特征與來自 CLIP 語言輸出的形狀感知令牌,并將全局視覺特征與來自 CLIP 圖像編碼器和 3D SMPL 身份空間的特征同步。這種整合在行人重識別(ReID)中實現了最先進的結果。

圖 7:所提出的 CLIP3DReID [17] 概述,其由基于 CLIP 的語言身體形狀標注、來自 CLIP 的雙重蒸餾以及 3D 重建的正則化組成。將這三個模塊整合到行人 ReID 框架中,使我們能夠學習具有區分性的身體形狀特征。
形式上,對于每個包含B個訓練樣本的小批量數據,記為{(Ii, yi, Li)}B i=1,輸入包括人體圖像Ii,圖像的身份標簽yi,以及一組描述體型的語言描述符Li。我們將預訓練且凍結的CLIP教師文本和圖像編碼器分別表示為EL和EI。我們優化的重點是學生的視覺編碼器,表示為E。

![]()


源于CLIP的雙重提煉。CLIP3DReID采用了一種雙重
CLIP模型文本和圖像組件的蒸餾方法。這涉及到使用最優傳輸對齊學生編碼器的視覺特征與CLIP生成的語言描述。這種對齊優化了學習過程,使學生編碼器能夠內化領域不變的特征,這些特征對于在不同條件下保持一致的識別性能至關重要。
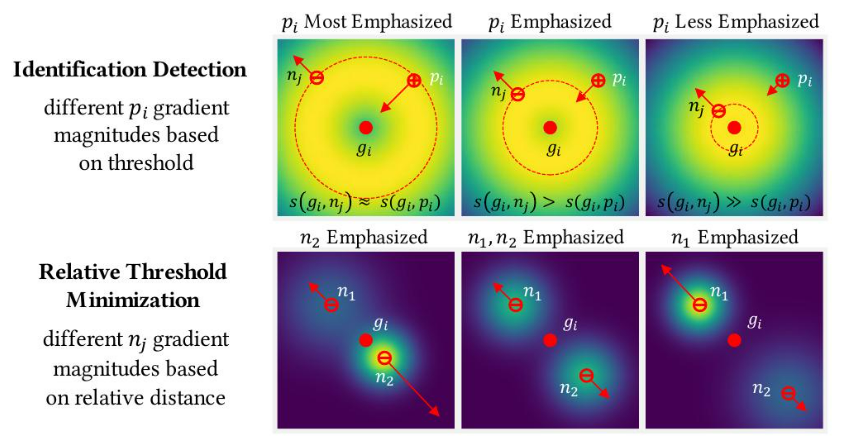
圖 8:所提出的開放集損失 [18] 的可視化。Rτdet 的情況如圖頂行所示,閾值由非匹配樣本?
nj?確定。梯度 ?Lopen/?pi 在其與圖庫?gi的距離和與?nj的距離相似時具有最大幅度。對于相對閾值最小化,如圖底行所示,隨著非匹配樣本?n2遠離圖庫,其梯度減小。而?n1保持在相同位置,其梯度增加,因為它比?n2更接近?gi。關于真值分數的梯度適應于非匹配分數,而關于非匹配分數的梯度適應于其他非匹配分數。
3D重建正則化。如圖7所示,我們采用了一種新穎的3D重建正則化方法,該方法利用從SMPL模型導出的合成人體形狀。該技術強調學習跨不同領域的不變特征,從而顯著提高我們模型的泛化能力。合成網格圖像及其生成的語言描述符用于進一步完善模型辨別和重建精確人體形狀的能力
3.4.4 開放集搜索

如圖8所示,我們處理三種類型的錯誤:(1)未能以閾值τ檢測到已配對的探針,(2)未能在前r個位置中識別出已配對的探針,以及(3)為未配對的探針分配了非常高的相似度分數。
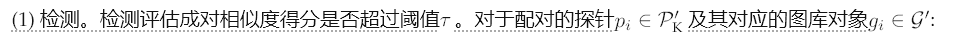
![]()
![]()
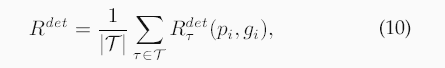
![]()

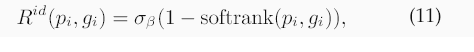

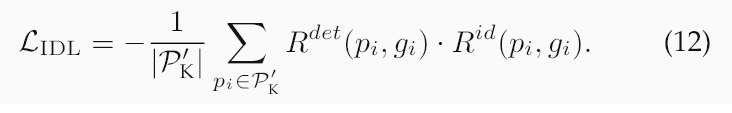
此損失會懲罰檢測和識別方面的失敗。(3)相對閾值最小化。為了減少假陽性,我們使用其加權平均值來懲罰較高的未配對分數:
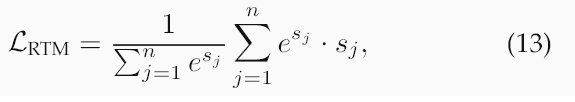
![]()
![]()
其中λ控制著權衡。這種表述使優化與開放集評估相一致,從而降低閾值,并利用非匹配的分數幅度進行穩健的特征學習。
為了優化模型以區分評估過程中圖庫中的近距離數據和探測中的遠距離數據,我們對三元組損失進行如下修改。在標準三元組損失中,近距離和遠距離數據都可以作為錨點、正樣本和負樣本。我們對此進行了調整,限制近距離數據僅作為錨點,而遠距離數據則專門用作正樣本和負樣本。
3.5 質量引導的多模態融合

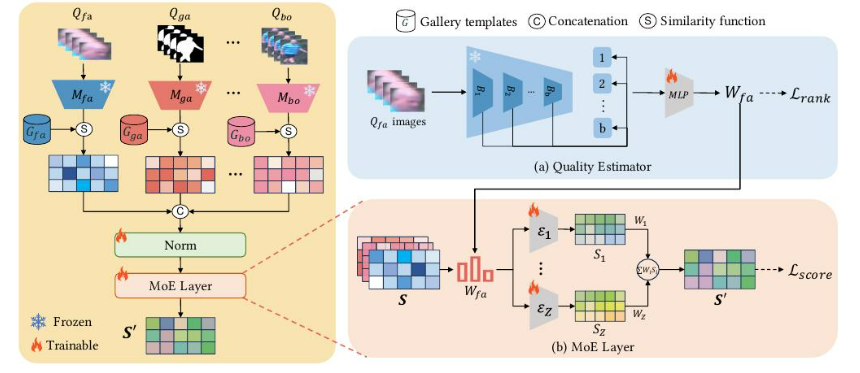



(c) 混合畫廊統計
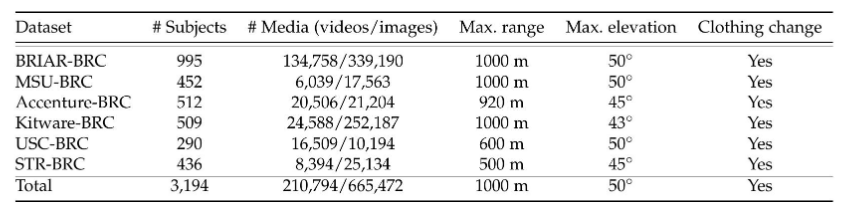
表1:BRIAR研究集合(BRC)訓練數據集概述,包括政府集合訓練集(BRIAR-BRC)以及來自五個不同的BRIAR執行團隊(MSU、Accenture、Kitware、USC和STR)的貢獻。

圖 10:應用 PSR-ByteTrack 前后跟蹤性能的比較。在較早的幀(第 110 幀)中,我們可以看到探針中有三個對象。在遮擋之后(第 220 幀),在第 240 幀中可以明顯看出 ByteTrack 存在 ID 切換的問題。然而,我們的 PSR + ByteTrack 跟蹤器能夠正確地將邊界框與適當的對象相關聯,從而減輕了 ID 切換的問題。

(a)探針統計

(b)簡單畫廊統計

表 2:BRIAR V5.0.1 評估協議:探測圖像和圖庫統計信息。雖然混合圖庫最初旨在更具挑戰性,但在 V5.0.1 中,它通常會產生更高的性能,因為它包含高質量的證件照式裁剪圖像。相比之下,簡單圖庫更好地反映了無約束的真實世界注冊。
4 個實驗
所有實驗均在使用 PyTorch 2.2.2 的可配置容器化環境中進行。我們使用 8 個 NVIDIA RTX A6000 GPU(每個 48 GiB VRAM),部署在配備 AMD EPYC 7713 64 核或 Intel Xeon Silver 4314 32 核處理器的雙路服務器上。
BRIAR數據集和協議。我們使用完整的IARPA BRIAR數據集[8]進行實驗,其中包括所有五個生物特征政府收集數據集(BGC1–5)。這些數據集涵蓋了廣泛的條件——不同的距離(高達1000米),升高的視角(高達50?)),以及多樣的環境(城市、半結構化和開放場地)——使其非常適合評估無約束的全身生物特征識別。除了政府收集的數據外,BRIAR數據集還包含了來自五個BRIAR執行團隊在其各自地點貢獻的訓練數據:Accenture、Kitware、MSU、USC和STR。每個BGC數據集被劃分為BRC(訓練)和BTC(測試)子集。表1總結了所有六個來源的訓練數據,總共包含3,194個獨特的對象。
訓練數據:面部、步態和體型的特征編碼模型分別使用針對每種模態定制的不同數據集進行訓練:
面部模型:如表1詳述,訓練利用來自所有BGC集合的BRS子集,涵蓋來自3,194個不同對象的數百萬張圖像和視頻幀的數據。我們進一步使用WebFace12M數據集[71]來擴充此集合。
步態和體型模型:除了來自所有 BGC 集合的 BRS 子集外,步態和體型模型的訓練還整合了 CCGR [72] 和 CCPG [73] 數據集。這些額外的公共領域數據集增強了我們的模型在各種真實條件下準確編碼步態和體型特征的能力。
測試數據:我們的評估采用了BRIAR測試集(BTS),與評估協議V5.0.1(EVP 5.0.12)對齊,并在表2中詳細說明。該子集有條不紊地組織成圖庫和探測數據集,以滿足我們在測試框架中的特定角色。圖庫旨在評估識別能力,由兩種不同的設置組成:圖庫1和圖庫2。探測數據集是
2. EVP 5.0.1 包含兩種圖庫配置:簡單和混合。除非另有說明,否則我們使用簡單圖庫設置報告結果,這是 BRIAR 評估中常用的標準配置。
分為控制和處理兩種情景。控制類別包括來自BGC視頻的片段,在這些片段中,面部或身體身份最容易識別,作為評估基線算法性能的基準。相反,處理類別包含識別面部或身體特征更具挑戰性的片段,反映了BRIAR協議設想的主要評估條件。這些類別(控制和處理)中的每一個都進一步細分為“包含面部”和“限制面部”兩種情景。“包含面部”情景側重于評估面部識別能力,而“限制面部”情景用于評估身體和步態識別,或所有三種生物識別模式的多模態融合的性能。
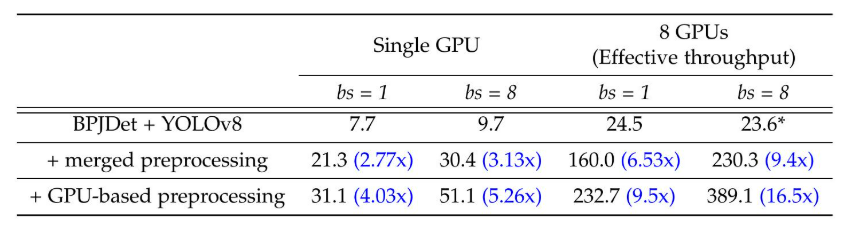
表 3:數字表示在分辨率為 896×1536 的情況下處理單對象探針視頻時實現的平均幀率(FPS)。測量是在 NVIDIA A100-80GB GPU 上進行的,批次大小(bs)為 1 和 8。優化包括合并冗余預處理并將預處理移至 GPU。最后一行顯示,基于 GPU 的預處理在單個 GPU 上可實現高達 5.26 倍的加速,在 8 個 GPU 上可實現 16.5 倍的加速。*由于 CPU 爭用,8 個 GPU 上基線的吞吐量略有下降。
包含人臉控制:包含可見人臉,其頭部高度至少為20像素,從地面水平拍攝,近距離小于75米。
面部包含處理:包含具有相同像素要求的可見面部,這些面部是從長距離或高角度捕獲的,包括無人機。
面部受限控制:包含面部被遮擋、分辨率低或因其他原因無法使用的數據,這些數據是從地面近距離拍攝的。
面部受限處理:與上述類似,但從長距離或高角度(包括無人機)捕獲。
對于部分實驗,我們還報告了在評估協議V4.2.0(EVP 4.2.0)下的結果——它是V5.0.1的一個子集——其中評估僅限于早期的數據發布(例如,BGC1和BGC2)。這允許進行傳統基準測試,并與先前發布的基線進行直接比較。
評估指標。遵循BRIAR項目目標指標[74],我們使用以下指標評估我們的系統:驗證(TAR@0.01% FAR)、封閉集識別(Rank-20 準確率)和開放集識別(FNIR@1% FPIR),從而能夠全面檢查FarSights在各種設置下的性能。
基線。對于人員識別評估,我們以多個基準系統來衡量我們的系統,以便將性能置于上下文中。首先,我們將當前的FarSight與原始的FarSight系統[1](稱為FarSight 1.0)進行比較,以突出顯示我們更新框架中引入的改進。其次,我們報告來自2025年NIST RTE視頻人臉評估(FIVE)[19]的獨立驗證結果,該評估使用BRIAR數據集提供人臉識別系統的標準化評估。在此評估中,我們的系統將與另一個表現最佳的IARPA BRIAR團隊以及該領域的兩個領先商業生物識別系統進行比較。
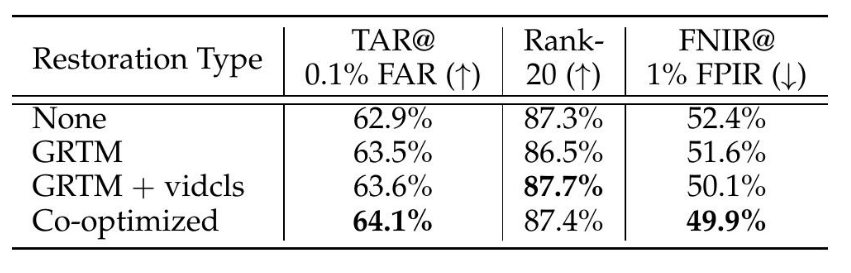
表 4:在 EVP 4.2.0 簡化協議上使用包含面部的處理探針集(來自 367 個受試者的 7,642 條軌跡)和圖庫 1(184 個受試者,4,970 個視頻,77,591 張靜態圖像和 490 個干擾項)的面部識別結果。各列報告以下性能:1:1 驗證(TAR@0.1% FAR),1:N 封閉集識別(Rank-20)和 1:N 開放集識別(FNIR@1% FPIR)。“GRTM”指的是我們的門控循環湍流緩解恢復模型,“vidcls”添加了一個基于視頻的分類器來跳過不必要的恢復,而“Co-optimized”表示與識別損失的聯合訓練。
4.1 評估與分析
4.1.1 檢測與跟蹤
PSR-ByteTrack 的有效性。我們對 ByteTrack 框架 [14] 的增強在處理多主體探測方面產生了顯著改進,特別是在減少身份切換錯誤方面。如圖 10 所示,在第 110 幀的初始跟蹤顯示了三個不同的主體。到第 220 幀,發生了一個具有挑戰性的遮擋,其中邊界框重疊。因此,在第 240 幀,ByteTrack 遭受了 ID 切換錯誤,而我們的 PSR-ByteTrack 由于基于外觀的軌跡 ID 校正后處理,在整個序列中保持了正確的主體-邊界框關聯。
檢測期間的優化吞吐量。我們在一臺NVIDIA A100-80G超平面上,使用分辨率為896 × 1536的單對象探針測試我們對管道的改進。如表3所示,我們觀察到我們的系統優化具有雙重優勢。首先,正如預期的那樣,我們觀察到吞吐量隨著每次更新迭代而增加。在批量大小為8的單個GPU的情況下,我們觀察到在合并冗余預處理步驟后速度提高了3.13倍,隨后基于GPU的預處理速度提高了5.26倍。其次,我們觀察到將預處理轉移到GPU具有減輕CPU瓶頸的額外效果,從而實現了幾乎線性的吞吐量擴展。在此,線性擴展是指問題規模的增加與吞吐量的增加之間的線性相關性,從而證明不存在任何顯著的瓶頸。這不僅提高了檢測-跟蹤子模塊的吞吐量,而且還釋放了CPU內核,供FarSight系統中的其他子模塊使用。
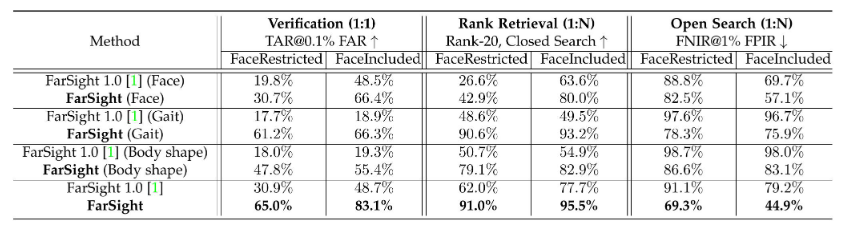
表5:在BRIAR評估協議V5.0.1上的人員識別結果,比較了FarSight(當前系統)與我們之前的系統FarSight 1.0在各個生物特征模態(面部、步態、體型)及其融合方面的表現。最后一行(FarSight)表示使用我們的質量引導融合策略對所有三種模態進行融合。FaceIncluded指的是面部可見的探測片段(頭部高度≥20像素),而FaceRestricted則排除了由于遮擋、距離或分辨率等原因導致面部不可見的片段。結果基于Treatment Probe Set(424個受試者,1,619個視頻軌跡,1,339個視頻,362,210幀)和Simple Gallery配置(424個受試者,675個干擾項,99,007張靜止圖像,12,264個軌跡,6,975,748幀)。指標表示1:1驗證(TAR@0.1% FAR),1:N封閉集檢索(Rank-20)和1:N開放集識別(FNIR@1% FPIR)。
4.1.2 湍流緩解與圖像恢復
我們通過分析我們提出的復原策略對大氣湍流下人臉識別的影響來評估其有效性,如表4所示。
基線。我們的系統在沒有任何修復的情況下處理未經校正的視頻幀。這產生了62.9%的TAR@0.1% FAR,87.3%的Rank-20準確率,以及52.4%的FNIR@1% FPIR,從而確立了我們的基線。
基于物理的復原。我們的門控循環湍流緩解(GRTM)模型在三個指標中的兩個上有所改進——將TAR提高到63.5%(從62.9%),并將FNIR降低到51.6%。雖然Rank-20略微下降到86.5%(從87.3%),但驗證增益表明其對湍流引起的失真具有更好的魯棒性。
選擇性激活的恢復。當GRTM與視頻分類器(GRTM + vidcls)結合使用時,該分類器僅在被認為有益時才觸發恢復,結果進一步提高到63.6%的TAR和50.1%的FNIR,Rank20恢復到87.7%。
實施范圍。為了管理計算成本,修復僅應用于填充的面部裁剪區域,而非完整的視頻幀。此策略確保專注于最具身份信息的區域,同時保持運行時效率。盡管此分析針對人臉識別,但如果需要,該協同優化框架可以推廣到其他模態。
4.1.3 人員識別性能
以下結果基于完整的FarSight系統,該系統整合了所有關鍵模塊,包括開放集搜索和質量引導的多模態融合。每種生物識別模態——面部、步態和體型——都顯示出比之前的系統(即FarSight 1.0 [1])有顯著的性能提升。我們使用BRIAR評估協議v5.0.1評估了它們的各自貢獻,并在表5中總結了這些發現。
面部。更新后的面部特征編碼模塊在所有指標上都取得了顯著的改進。與EVP 5.0.1的面部包含處理集上的FarSight 1.0 [1] 相比,所提出的FarSight將驗證TAR@0.1% FAR從48.5%提高到66.4%,Rank-20識別從63.6%提高到80.0%,并且FNIR@1% FPIR的開放集性能從69.7%降至57.1%。這些提升反映了KP-RPE增強的視覺Transformer [15] 和我們識別感知的恢復模塊的影響。
步態。步態特征編碼模塊在包含面部的處理集上表現出最顯著的改進,這得益于BigGait [16] 模型的引入。驗證性能從18.9%提高到66.3% (TAR@0.1% FAR),Rank-20識別率從49.5%上升到93.2%,FNIR@1% FPIR從96.7%下降到75.9%。這些結果反映了該模型利用大型視覺模型提取魯棒步態特征的增強能力,尤其是在具有挑戰性的跨域條件下。
體型。體型特征編碼模塊在包含面部的處理集上也表現出顯著的增益。驗證(TAR@0.1% FAR)從19.3%提高到55.4%,而Rank-20識別率從54.9%提高到82.9%。FNIR@1% FPIR從98.0%顯著下降到83.1%,表明在開放集場景中可靠性得到提高。這些改進主要歸功于CLIP3DReID [17]模型,該模型融合了語言線索和視覺表示,并利用3D感知監督來增強身體特征學習。

圖 11:封閉集驗證中成功和失敗的示例。每對圖像顯示了一個探測圖像(右)及其匹配的圖庫圖像(左),以及相似度得分。匹配是根據 0.79 的閾值進行評估的,該閾值對應于 0.1% 的錯誤接受率 (FAR)。所示圖像已獲得主題出版許可。
多模態融合。雖然每種模態都顯示出顯著的個體改進,但當融合時,它們的互補優勢變得更加明顯。在我們的完整系統設置中,FarSight 在 Face-Included Treatment 數據集上實現了 83.1% 的 TAR@0.1% FAR,95.5% 的 Rank-20 準確率和 44.9% 的 FNIR@1% FPIR,顯著優于原始的 FarSight 1.0。
搜索結果的例證。為了進一步說明我們系統的優勢和局限性,我們提供了封閉集和開放集行人識別結果的定性示例。如圖11和圖12所示,我們包括了真實匹配和冒名頂替匹配中具有代表性的成功和失敗案例。這些例子展示了系統如何在距離、高度和服裝變化等不同條件下處理身份匹配。值得注意的是,成功的匹配表現出很強的視覺相似性和對齊性,而失敗的案例通常涉及具有挑戰性的視角或模糊的外觀。
獨立驗證:NIST FIVE 2025。為了評估在標準化測試下的泛化能力,FarSight的性能在2025年NIST RTE視頻人臉評估(FIVE)[19]中進行了獨立報告。該評估使用EVP 5.0.1混合圖庫進行,采用1:N開放集設置,圖庫中每個對象使用單張正面靜態圖像。如表6所示,FarSight實現了最佳的FNIR@1% FPIR(32%),優于兩個商業系統——Sugawara-2(66%)和Azumane-2(53%)——以及STR(54%),后者與MSU是IARPA BRIAR計劃第三階段中剩余的兩個表現者團隊。這些由NIST直接報告的結果,進一步驗證了FarSight在具有操作挑戰性的場景下的穩健性。

圖 12:開放集識別中成功和失敗的例子。每對圖像包括一個探針圖像(右)和排名最高的圖庫匹配圖像(左),以及匹配排名和相似度得分。使用 1.16 的開放集閾值來區分接受的匹配和拒絕的匹配。所示圖像已獲得主題出版許可。

表6:2025年NIST RTE視頻人臉評估(FIVE)的FNIR@1% FPIR結果[19],使用BRIAR EVP 5.0.1協議和混合圖庫(424個對象,679個干擾項,62,382張靜態圖像,22,134個軌跡,820萬幀)以及處理探針集(424個對象,1,619個視頻軌跡,1,339個視頻,362,210幀)進行評估。結果報告的是1:N開放集識別任務,每個對象注冊一張正面靜態圖像。
4.1.4 消融研究
為了更好地理解FarSight系統中各個組件的貢獻,我們進行了消融實驗,重點關注兩個核心創新:(1)步態模塊中的開放集損失公式;(2)多模態融合框架。
開放集損失在步態特征編碼模塊中的影響。我們將開放集損失公式僅應用于FarSight中的步態模態。表7比較了在使用EVP 4.2.0協議下,有和沒有提出的開放集損失的步態模塊的性能。包含開放集損失在4個評估指標中的3個上帶來了可衡量的改進。最值得注意的是,驗證性能(TAR@0.1% FAR)在面部受限場景中提高了5.7%,在面部包含場景中提高了3.2%。雖然Rank-20保持不變,但FNIR@1% FPIR降低了2.3%,反映了對未知身份的魯棒性有所提高。這些結果驗證了使用模擬開放集條件進行訓練的有效性。
多模態融合策略評估。我們通過與FarSight中使用的簡單分數級融合進行比較,進一步評估我們提出的質量引導專家混合(QME)融合策略的貢獻。表8報告了EVP 4.2.0簡化協議在包含面部和限制面部條件下的結果。我們基于QME的融合方法提高了驗證性能(TAR)和開放集魯棒性(FNIR),優于基線。值得注意的是,在包含面部的設置中,FNIR@1% FPIR提高了6.2%。這些提升突出了使用質量感知融合和模態特定權重優于簡單分數聚合的有效性。
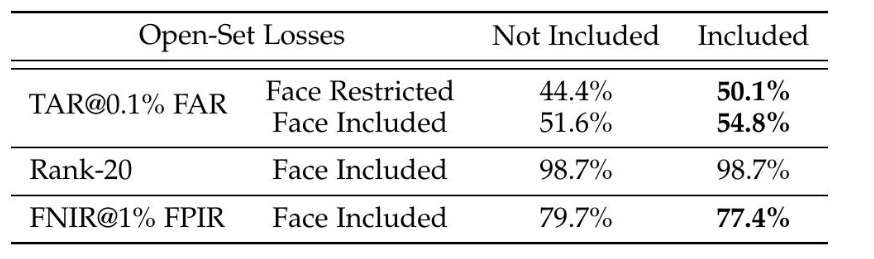
表 7:開放集損失函數在步態模塊中對 EVP 4.2.0 的影響。
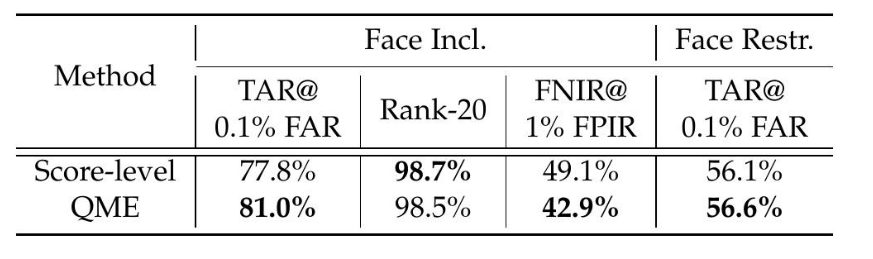
表 8:EVP 4.2.0 上多模態融合策略的比較。“QME”(質量引導的專家混合)指的是我們提出的方法,該方法基于 FarSight 中學習到的質量權重自適應地融合模態分數。
4.1.5 FarSight的公開訓練版本
為了促進可重復性并方便更廣泛的社區參與,我們推出了FarSight Public,這是我們的系統的一個版本,它僅在來自MSU-BRC數據集的公開可用數據上進行訓練和評估。該數據集是IARPA BRIAR計劃的一部分,可在3處訪問。MSU-BRC數據集總共包含452個受試者(表1)。對于此基準測試,我們將數據劃分為不相交的訓練和測試設置。訓練集由來自MSU-BRC版本2的228個受試者組成,而測試集由來自MSU-BRC版本1的109個受試者組成。我們定義了一個名為MSU 1.0的評估協議,其中包括從626個探測視頻中提取的2,496個探測片段。圖庫包含1,309個不同的視頻和11,815張靜態圖像,其中包含111個干擾身份,以模擬開放集條件。為了模擬服裝變化,探測和圖庫媒體使用了不同的服裝。
盡管MSU-BRC不如完整的BRIAR數據集那樣多樣化或具有挑戰性,但它為外部驗證提供了一個結構良好且易于訪問的基準。我們在此訓練集上重新訓練整個FarSight系統,并使用定義的MSU 1.0協議評估其性能。表9總結了包含面部的治療子集的結果。FarSight Public在各種模態中表現出強大的性能,尤其是在身體形狀和融合模塊方面具有很高的準確性。
4.2 系統效率
模板大小。模板大小指的是每個受試者為了生物特征匹配而生成和存儲的數據量。表10總結了FarSight系統中每種模態的存儲需求。(i)面部:對于面部特征編碼,每個模板包含一個513維向量。前512維代表核心身份特征,而最后一維存儲面部質量評分。假設使用32位浮點精度,則原始存儲需求約為0.002 MB。(ii)步態:每個步態模板包含一個8192維特征向量,導致原始存儲大小為0.031 MB。(iii)體型:體型表示被編碼為一個2048維向量,原始存儲大小為0.008 MB。(iv)組合:當所有三種模態——面部、步態和體型——都成功注冊時,總原始特征大小約為0.041 MB。雖然這個原始大小反映了未壓縮的數據表示,但實際部署通常涉及額外的元數據、索引結構和壓縮機制。為了估計實際的存儲需求,我們通過將已部署圖庫的總磁盤空間除以已注冊模板的數量來計算平均磁盤大小。這產生了0.041 MB的有效模板大小,證實了該系統適用于可擴展的部署。
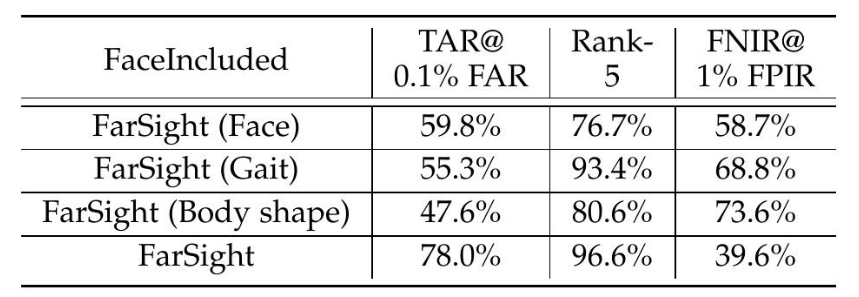
表 9:在 MSU-BRC 數據集上使用 MSU 1.0 協議的 FarSight 公開結果(包含面部的處理子集)。探針集包含來自 626 個視頻的 2496 條軌跡,涉及 109 個受試者。圖庫包含 1309 個視頻和 11815 張帶有配對樣本的靜態圖像,以及 111 個干擾身份用于開放集評估。指標反映了 1:1 驗證(TAR@0.1% FAR)、1:N 封閉集識別(Rank-5)和 1:N 開放集識別(FNIR@1% FPIR)。由于圖庫規模較小,我們報告 Rank-5 而不是 Rank-20。

表10:每種模態和組合特征表示的模板大小。
處理速度。我們的FarSight系統的速度,總結在表11中,在受控條件下進行評估,以衡量模塊級和系統級的效率。雖然該系統在部署期間被設計為異步和并發運行,但出于基準測試的目的,每個組件都以串行方式獨立評估,以隔離性能特征。我們使用具有代表性的樣本視頻進行此評估,包括2400幀1080p和1200幀4K視頻,每組視頻均來自四個不同的對象。修復有選擇地應用于檢測到的面部區域。因此,沒有檢測到人臉的幀自然會減少修復和人臉識別模塊的負載。此外,修復模塊包含一個輕量級分類器,當認為修復不太可能提高識別率時,該分類器會繞過不必要的處理。
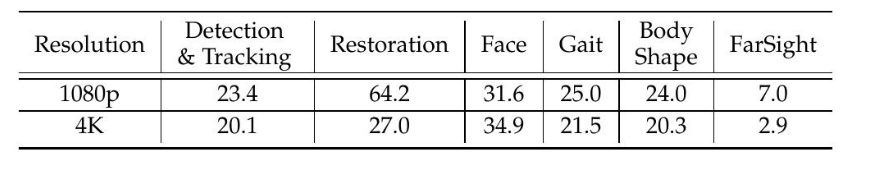
表11:FarSight的模塊化處理速度,以每秒幀數(FPS)為單位,針對1080p和4K分辨率的探測視頻。最后一列反映了所有模塊并行運行時的有效吞吐量。所有基準測試均在8個NVIDIA RTX A6000 GPU(每個48 GiB VRAM)上使用PyTorch 2.2.2在容器化環境中進行。
4.3 未來研究
視頻修復與協同優化。在我們的協同優化策略成功的基礎上,我們計劃將其擴展到其他模態(例如,步態、體型),探索修復和識別目標之間的自適應平衡,并整合不確定性估計以防止身份幻覺。我們還旨在設計輕量級的實時架構,適用于在操作環境中的邊緣部署。
檢測與追蹤。我們計劃將追蹤任意點(TAP)模型[75]整合到FarSight流程中。通過提供跨幀的密集運動對應關系,TAP可以增強對細粒度時空特征的建模,尤其有利于在遮擋或快速運動下的步態分析。
生物特征編碼。為了改進基于視頻的人員識別,我們計劃提出一種新的框架,該框架能夠自適應地融合面部、體型、外觀和步態線索。該系統利用雙輸入門控機制和混合專家設計,將根據視頻內容動態地確定特征流的優先級,從而提高在各種場景中的識別魯棒性。
多模態融合。我們的目標是進一步探索模態內部和模態之間的分數級融合策略。具體而言,我們計劃研究基于深度學習的個體模態融合(例如,多個面部模型),并開發一種更通用的、可學習的路由網絡,以取代基于固定質量的融合權重。這種方法可以提高面部識別和整體系統適應性。
5 結論
我們提出了FarSight,一個用于在遠距離、無約束條件下進行全身生物特征識別的端到端系統。通過將基于物理的建模與深度學習相結合,貫穿四個集成模塊——包括檢測、識別感知恢復、模態特定編碼和質量引導融合——FarSight解決了湍流、姿態變化和開放集識別等關鍵挑戰。FarSight在BRIAR數據集上進行了評估,并經過2025年NIST RTE FIVE基準的獨立驗證,在驗證、封閉集和開放集任務中均實現了最先進的性能。具體而言,與初步系統相比,我們的系統將1:1驗證準確率(TAR@0.1% FAR)提高了34.1%,封閉集識別率(Rank-20)提高了17.8%,并將開放集識別錯誤率(FNIR@1% FPIR)降低了34.3%。該系統高效,滿足模板大小約束,并包含一個基于發布數據訓練的可復現的公開版本。FarSight為現實應用中下一代生物特征識別提供了堅實的基礎。




)

詳解)

)

)







開篇、服務劃分)
