文章目錄
- 一、引言
- 二、系統架構設計
- 2.1、整體架構概覽
- 2.2、數據庫設計
- 2.3、后端服務設計
- 三、實戰:從零構建排行榜
- 3.1、開發環境準備
- 3.2、用戶與戰區 數據管理
- 3.2.1、MySQL 數據庫表創建
- 3.2.2、實現用戶和戰區數據的 CURD 操作
- 3.3、實時分數更新
- 3.4、排行榜查詢
- 3.5、數據同步服務實現
- 四、Demo 演示與成果展示
- 五、總結
摘要: 本文將通過構建一個模擬《王者榮耀》戰區排行榜的實戰項目,深入展示 CodeBuddy 作為“中國版 Cursor”的強大能力。探討如何利用 CodeBuddy 的智能代碼生成(Craft)、對話理解(Chat)以及數據庫控制平面(MCP)等核心功能,驅動 Redis 和 MySQL 雙引擎協同工作,實現高性能、高可用的排行榜系統。項目將涵蓋數據庫設計、數據同步機制、實時排名查詢、以及 CodeBuddy 在整個開發流程中的具體應用,為開發者提供一個 AI 輔助復雜系統開發的實戰范例。
一、引言
軟件開發領域,效率是衡量競爭力的關鍵指標之一。因此,人工智能(AI)編程工具應運而生,并迅速發展,比如 Cursor。從早期的代碼自動補全、語法檢查,到如今能夠理解自然語言需求、生成復雜代碼邏輯、甚至輔助系統設計的智能編程助手,AI 正在深刻地改變著開發者的工作方式。這些工具旨在解放開發者的雙手,讓他們能夠將更多精力投入到高價值的創意和架構設計上,從而顯著提升開發效率和軟件質量。
什么是 CodeBuddy ?
騰訊云代碼助手 CodeBuddy 是騰訊自主研發的 AI 編程輔助工具,旨在顯著提升開發工作效率。CodeBuddy 依托騰訊混元和 DeepSeek 混合模型驅動,為開發提供強大的 AI 編程能力。
CodeBuddy的官網地址: https://copilot.tencent.com
它不僅僅是一個簡單的代碼編輯器插件,而是集成了多項核心能力,旨在為中國開發者提供更貼合本土開發環境和習慣的智能輔助。
CodeBuddy 的核心能力包括:
-
Craft (智能代碼生成): 能夠理解開發者用自然語言描述的需求,并生成高質量、符合最佳實踐的代碼片段、函數甚至復雜的業務邏輯代碼。它內置了豐富的領域知識和代碼模式,能夠針對不同的技術棧生成相應的代碼。
-
Chat (智能對話與問答): 提供一個交互式的對話界面,開發者可以直接提問、尋求幫助、討論技術方案、 debug 代碼。CodeBuddy 能夠理解上下文,提供精準的解答和建議。
-
MCP (多模態控制平面): 這是一個關鍵特性,使得 CodeBuddy 能夠與各種開發工具和環境進行深度集成和交互,例如直接操作數據庫、調用命令行工具、與版本控制系統交互等。這使得 CodeBuddy 不僅僅是生成代碼,還能“執行”代碼和操作環境。
-
領域知識庫: CodeBuddy 內置了涵蓋前端、后端、移動開發、數據庫、算法、特定框架等廣泛領域的知識,使其能夠提供專業、準確的幫助。
支持多種編程語言和編輯器:
正是憑借這些強大的能力,CodeBuddy 可以稱為“中國版Cursor”。
本文將以《王者榮耀》戰區排行榜為模擬場景,詳細介紹如何利用 CodeBuddy 的各項智能能力,從零開始構建一個基于 Redis + MySQL 雙引擎驅動的排行榜系統 Demo。重點展示 CodeBuddy 如何在數據庫設計、核心業務邏輯實現(分數更新、排名查詢)、數據同步機制構建等關鍵環節提供智能輔助,幫助開發者更高效、更便捷地完成開發任務。通過這個實戰項目,親身體驗 CodeBuddy 作為智能開發伙伴的強大之處,并了解如何在實際項目中應用 AI 工具提升開發效率。

二、系統架構設計
構建一個高性能、高可用的排行榜系統,清晰合理的架構設計是成功的基石。這里將基于 Redis + MySQL 雙引擎驅動的《王者榮耀》戰區排行榜系統的架構設計,包括整體概覽、數據流轉、數據庫設計以及后端服務劃分。
2.1、整體架構概覽
排行榜系統采用分層架構,主要包括用戶端(模擬游戲客戶端)、后端服務層、以及數據存儲層(Redis 和 MySQL)。核心思想是將對實時性要求極高的排行榜讀寫操作放在內存數據庫 Redis 中,而將需要持久化、結構化存儲的用戶信息和歷史數據放在關系型數據庫 MySQL 中。一個獨立的數據同步服務負責在 Redis 和 MySQL 之間進行數據同步,保證數據的一致性。
系統的整體架構概覽圖:
圖 2-1 系統整體架構圖
架構圖上,游戲客戶端通過后端服務層的 API 與系統交互。后端服務層又細分為處理實時請求的“排行榜 API 服務”和負責數據同步的“數據同步服務”。排行榜 API 服務直接與 Redis 和 MySQL 交互,其中排行榜相關的實時讀寫主要針對 Redis,而用戶信息的讀取可能涉及 MySQL。數據同步服務則獨立運行,負責協調 Redis 和 MySQL 之間的數據流動。
數據流轉:
-
玩家分數更新流程: 將分數更新請求發送給后端服務 -> 后端服務(排行榜 API 服務)接收請求 -> 同時更新 Redis 中該玩家的總分和戰區分數(使用
ZINCRBY等命令) -> 異步或定期觸發將更新后的分數同步到 MySQL(通過數據同步服務) -> 后端服務響應客戶端。圖 2-2 玩家分數更新數據流
-
排行榜查詢流程: 查看全局榜或戰區榜 -> 發送查詢請求給后端服務 -> 后端服務(排行榜 API 服務)接收請求 -> 查詢 Redis 中對應的 Sorted Set 獲取排名數據(使用
ZREVRANGE等命令) -> 根據獲取到的用戶 ID,從 MySQL 查詢用戶昵稱、頭像等附加信息 -> 后端服務整合數據并響應客戶端。圖 2-3 排行榜查詢數據流
-
數據同步流程: 數據同步服務根據預設策略(如定時、增量)運行 -> 從 Redis 讀取需要同步的數據(如排行榜全量或增量變化) -> 將數據寫入 MySQL 的排行榜快照表或用戶分數表 -> 保證 Redis 和 MySQL 數據的一致性。
圖 2-4 數據同步數據流
2.2、數據庫設計
合理的數據庫設計是系統穩定運行的基礎,需要分別設計 MySQL 和 Redis 的數據結構。
MySQL 主要用于存儲基礎信息、戰區信息、歷史分數記錄以及排行榜快照,以保證數據的持久化和結構化管理。
用戶表 (users): 存儲玩家基本信息。
| 數據庫值 | 說明 |
|---|---|
id | 唯一ID (Primary Key) |
nickname | 用戶昵稱 |
current_zone_id | 當前所屬戰區ID (Foreign Key to zones) |
total_score | 用戶總分 (冗余字段,方便查詢,但以 Redis 為準) |
created_at | 創建時間 |
updated_at | 更新時間 |
CodeBuddy 輔助: 通過自然語言描述“需要一個用戶表,包含ID、昵稱、頭像URL、當前戰區ID和總分”,讓 CodeBuddy 生成對應的 CREATE TABLE 語句,并詢問 CodeBuddy 關于索引的建議(例如,在 current_zone_id 和 total_score 上創建索引)。
戰區信息表 (zones): 存儲戰區信息。
| 數據庫值 | 說明 |
|---|---|
id | 戰區唯一ID (Primary Key) |
name | 戰區名稱 (e.g., “北京市”, “上海市”) |
level | 戰區級別 (e.g., “市”, “省”) |
CodeBuddy 輔助: 通過自然語言描述“需要一個戰區信息表,包含ID、名稱和級別”,讓 CodeBuddy 生成 CREATE TABLE 語句。
排行榜快照表 (leaderboard_snapshots): 定期存儲 Redis 排行榜的快照,用于歷史查詢或系統恢復。
| 數據庫值 | 說明 |
|---|---|
id | 快照記錄ID (Primary Key) |
zone_id | 戰區ID (0表示全局榜) |
user_id | 用戶ID |
score | 用戶在該榜單的得分 |
rank | 用戶在該榜單的排名 |
snapshot_time | 快照生成時間 |
CodeBuddy 輔助: 通過自然語言描述“需要一個表存儲排行榜快照,記錄戰區、用戶、分數、排名和時間”,讓 CodeBuddy 生成 CREATE TABLE 語句,并詢問 CodeBuddy 如何高效地查詢歷史排名數據。
分數記錄表 (score_records): (可選)記錄玩家每一次分數變化的詳細信息,用于數據分析或回溯。
| 數據庫值 | 說明 |
|---|---|
id | 記錄ID (Primary Key) |
user_id | 用戶ID |
zone_id | 發生變化的戰區ID |
score_change | 分數變化量 |
new_total_score | 變化后的總分 |
change_time | 變化時間 |
game_id | 關聯的游戲局ID (Optional) |
CodeBuddy 輔助: 通過自然語言描述“需要一個表記錄每次分數變化,包括用戶、戰區、變化量、新總分和時間”,讓 CodeBuddy 生成 CREATE TABLE 語句,并討論如何處理大量寫入的性能問題(例如,批量插入)。
Redis 主要利用其內存特性和 Sorted Set 數據結構來實現高性能的實時排行榜。
全局排行榜:
- 數據結構: Sorted Set
- Key:
global_rank - Member: 用戶 ID (
user_id) - Score: 玩家總分 (
total_score)
CodeBuddy 輔助: 詢問 CodeBuddy “如何在 Redis 中實現一個全局排行榜,根據總分排序?”,CodeBuddy 會建議使用 Sorted Set,并解釋 ZADD, ZINCRBY, ZREVRANGE 等命令的使用。
戰區排行榜:
- 數據結構: Sorted Set
- Key:
zone_rank:{zone_id}(例如:zone_rank:1001代表 ID 為 1001 的戰區排行榜) - Member: 用戶 ID (
user_id) - Score: 玩家在該戰區的分數 (
zone_score)
CodeBuddy 輔助: 詢問 CodeBuddy “如何為每個戰區創建獨立的排行榜?”,CodeBuddy 會建議使用帶有戰區 ID 的 Key 前綴,并解釋如何管理多個 Sorted Set。
用戶當前分數:
- 數據結構: Hash 或 String
- Key:
user_score:{user_id} - Value (Hash): 存儲用戶的總分 (
total) 和各戰區的分數 (zone:{zone_id}),例如{ "total": 5000, "zone:1001": 1500, "zone:1002": 3500 }。 - Value (String): 僅存儲用戶總分,各戰區分數從戰區 Sorted Set 中獲取。取決于實際需求和查詢模式。
CodeBuddy 輔助: 詢問 CodeBuddy “如何快速獲取某個用戶的總分和各戰區分數?”,CodeBuddy 會分析 Hash 和 String 的優劣,并建議適合當前場景的數據結構。
2.3、后端服務設計
后端服務層負責處理來自客戶端的請求,并協調與數據庫的交互。將服務劃分為排行榜 API 服務和數據同步服務。
排行榜 API 服務: 這是直接面向游戲客戶端的服務,提供各種排行榜相關的接口。
API 接口示例:
POST /api/score/update: 玩家分數更新接口,接收用戶ID、戰區ID、分數變化量等參數。GET /api/leaderboard/global: 查詢全局排行榜接口,可接受分頁參數。GET /api/leaderboard/zone/{zone_id}: 查詢特定戰區排行榜接口,接受戰區ID和分頁參數。GET /api/user/{user_id}/rank/global: 查詢某個用戶在全局榜的排名和分數。GET /api/user/{user_id}/rank/zone/{zone_id}: 查詢某個用戶在特定戰區榜的排名和分數。GET /api/user/{user_id}/profile: 查詢用戶基本信息(可能需要從 MySQL 獲取)。
CodeBuddy 輔助: 通過自然語言描述“使用 Python Flask 框架,創建一個 /api/score/update 的 POST 接口,接收 user_id, zone_id, score_change 參數”,CodeBuddy 可以生成相應的路由和請求處理函數框架。
數據同步服務: 這是一個獨立的后臺服務,負責將 Redis 中的實時數據同步到 MySQL。同步策略可以是定時同步(例如每隔 5 分鐘)或基于事件/消息隊列的異步同步。
- 定時同步: 定時讀取 Redis 中所有或有變化的排行榜數據,批量更新或插入到 MySQL 的排行榜快照表。
- 增量同步: 利用 Redis 的持久化特性(AOF)或監聽 Redis 的 Key Space Notifications(如果數據量不大且對實時性要求更高),捕獲分數變化事件,然后將變化同步到 MySQL。或者在分數更新時,將同步任務放入消息隊列,由同步服務消費。
- 數據一致性: 需要考慮同步過程中的并發問題和數據丟失問題,可能需要引入版本號或時間戳來處理沖突。
CodeBuddy 輔助: 詢問 CodeBuddy “如何實現 Redis 到 MySQL 的數據同步?”,CodeBuddy 會介紹不同的同步策略,并提供實現思路和代碼片段。
除了核心的 Redis 和 MySQL 數據庫,構建這個系統還需要選擇合適的后端開發語言、Web 框架、以及可能的其他組件。
- 后端語言/框架: Python (Flask/Django), Java (Spring Boot), Go (Gin/Echo), Node.js (Express) 等。CodeBuddy 對多種主流語言和框架都有良好的支持。
- 消息隊列(可選): 如果需要實現異步的數據同步或解耦服務,可以考慮使用 Kafka, RabbitMQ 等消息隊列。
- 緩存(可選): 除了 Redis 用于排行榜,還可以使用 Redis 或 Memcached 作為通用的緩存層,緩存用戶基本信息等不經常變動的數據,減輕 MySQL 的壓力。
三、實戰:從零構建排行榜
前面簡單設計了系統的整體架構和數據庫結構。現在可以進入實際的編碼階段,將詳細介紹如何使用 CodeBuddy 實現排行榜系統的核心功能,包括用戶和戰區管理、實時分數更新、排行榜查詢以及數據同步。以 Python + Flask 作為后端開發的示例技術棧。
3.1、開發環境準備
在開始編碼之前,需要準備好開發環境。這包括安裝 Python、Flask 框架、Redis 客戶端庫(如 redis-py)、MySQL 驅動(如 mysql-connector-python 或 PyMySQL),以及配置好 Redis 和 MySQL 服務器。
可以通過 CodeBuddy 的 Chat 功能詢問如何安裝這些依賴庫,或者讓 CodeBuddy 生成一個 requirements.txt 文件。
向 CodeBuddy 提問:
在 Python 中安裝 Flask, redis-py 和 PyMySQL,請幫我生成一個包含 Flask, redis-py 和 PyMySQL 的 requirements.txt 文件內容。
CodeBuddy 經過思考后成功創建requirements.txt文件,內容如下:
Flask==2.3.2
redis==4.5.5
PyMySQL==1.0.3
SQLAlchemy==2.0.19
python-dotenv==1.0.0
安裝這些依賴,運行以下命令:
pip install -r requirements.txt
安裝完成后,可以繼續開發排行榜系統的其他組件。
3.2、用戶與戰區 數據管理
這部分主要涉及與 MySQL 數據庫的交互,實現用戶和戰區信息的創建、讀取、更新等操作。
3.2.1、MySQL 數據庫表創建
向 CodeBuddy 提問:
創建一個數據庫,并在當前數據庫中創建用戶表 (users),包含 id (主鍵), nickname, avatar_url, current_zone_id, total_score, created_at, updated_at 字段。
CodeBuddy 會自動生成init_db.sql文件,執行該文件來初始化數據庫,命令是:
mysql -u root -p < init_db.sql
如果系統沒有安裝MySQL,先執行下面的命令安裝(以Ubuntu系統為例):
sudo apt install mysql-server
對于WSL 環境,使用傳統 service 命令管理 MySQL:
# 啟動 MySQL
sudo service mysql start# 查看狀態
sudo service mysql status# 停止 MySQL
sudo service mysql stop
類似地,創建 zones 表。向 CodeBuddy 提問:
創建一個戰區信息表 (zones),包含ID、名稱和級別
CodeBuddy會更新 init_db.sql 文件,執行如下命令:
# 1. 備份現有數據庫(如有需要)
mysqldump -u root -p game_leaderboard > backup.sql# 2. 執行更新后的腳本
mysql -u root -p < init_db.sql# 3. 驗證表結構
mysql -u root -p -e "USE game_leaderboard; SHOW TABLES; DESCRIBE zones; DESCRIBE users;"
得到的數據庫表結構如下:
+----------------------------+
| Tables_in_game_leaderboard |
+----------------------------+
| users |
| zones |
+----------------------------+
+------------+-------------+------+-----+-------------------+-----------------------------------------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+-------------------+-----------------------------------------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(50) | NO | | NULL | |
| level | int | YES | | 1 | |
| created_at | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED |
| updated_at | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP |
+------------+-------------+------+-----+-------------------+-----------------------------------------------+
+-----------------+--------------+------+-----+-------------------+-----------------------------------------------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+--------------+------+-----+-------------------+-----------------------------------------------+
| id | int | NO | PRI | NULL | auto_increment |
| nickname | varchar(50) | NO | | NULL | |
| avatar_url | varchar(255) | YES | | NULL | |
| current_zone_id | int | YES | | 0 | |
| total_score | int | YES | | 0 | |
| created_at | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED |
| updated_at | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP |
+-----------------+--------------+------+-----+-------------------+-----------------------------------------------+
哦豁,好像忘記創建索引了,沒事,讓CodeBuddy幫我們創建。向CodeBuddy提問:
請在 users 表的 current_zone_id 字段上創建索引。
CodeBuddy會更新 init_db.sql 文。
最終 init_db.sql 文件內容如下:
-- 創建游戲排行榜數據庫
CREATE DATABASE IF NOT EXISTS game_leaderboard DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;USE game_leaderboard;-- 創建戰區信息表
CREATE TABLE IF NOT EXISTS zones (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50) NOT NULL COMMENT '戰區名稱',level INT DEFAULT 1 COMMENT '戰區級別',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新時間'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='戰區信息表';-- 創建用戶表
CREATE TABLE IF NOT EXISTS users (id INT AUTO_INCREMENT PRIMARY KEY,nickname VARCHAR(50) NOT NULL COMMENT '用戶昵稱',avatar_url VARCHAR(255) COMMENT '用戶頭像URL',current_zone_id INT DEFAULT 0 COMMENT '當前戰區ID',CONSTRAINT fk_user_zone FOREIGN KEY (current_zone_id) REFERENCES zones(id),total_score INT DEFAULT 0 COMMENT '總積分',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新時間'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用戶信息表';-- 在current_zone_id字段上創建索引
CREATE INDEX idx_user_zone ON users(current_zone_id);
執行如下命令完成更新:
# 如果之前執行過舊版本,建議先刪除舊表
mysql -u root -p -e "DROP TABLE IF EXISTS game_leaderboard.users, game_leaderboard.zones;"# 執行更新后的腳本
mysql -u root -p < init_db.sql# 驗證索引是否創建成功
mysql -u root -p -e "USE game_leaderboard; SHOW INDEX FROM users;"
索引創建成功:
+-------+------------+---------------+--------------+-----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+---------------+--------------+-----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| users | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
| users | 1 | idx_user_zone | 1 | current_zone_id | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL |
+-------+------------+---------------+--------------+-----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
3.2.2、實現用戶和戰區數據的 CURD 操作
使用 ORM (Object-Relational Mapping) 來簡化數據庫操作,例如 SQLAlchemy。CodeBuddy 可以幫生成 ORM 模型類和基本的 CURD 函數。
向 CodeBuddy 提問:
使用 SQLAlchemy,為 users 表創建一個 ORM 模型類。
CodeBuddy 會創建SQLAlchemy ORM模型文件models.py。
from datetime import datetime
from sqlalchemy import Column, Integer, String, ForeignKey, TIMESTAMP
from sqlalchemy.sql import func
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationshipBase = declarative_base()class Zone(Base):"""戰區信息模型"""__tablename__ = 'zones'id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(50), nullable=False, comment='戰區名稱')level = Column(Integer, default=1, comment='戰區級別')created_at = Column(TIMESTAMP, server_default=func.now(), comment='創建時間')updated_at = Column(TIMESTAMP, server_default=func.now(), onupdate=func.now(), comment='更新時間')class User(Base):"""用戶信息模型"""__tablename__ = 'users'id = Column(Integer, primary_key=True, autoincrement=True)nickname = Column(String(50), nullable=False, comment='用戶昵稱')avatar_url = Column(String(255), nullable=True, comment='用戶頭像URL')current_zone_id = Column(Integer, ForeignKey('zones.id'), default=0, comment='當前戰區ID')total_score = Column(Integer, default=0, comment='總積分')created_at = Column(TIMESTAMP, server_default=func.now(), comment='創建時間')updated_at = Column(TIMESTAMP, server_default=func.now(), onupdate=func.now(), comment='更新時間')# 定義與Zone的關系zone = relationship("Zone", backref="users")def __repr__(self):return f"<User(id={self.id}, nickname='{self.nickname}')>"
繼續向 CodeBuddy 提問:
使用 SQLAlchemy,編寫一個函數來根據用戶 ID 查詢用戶信息。
使用 SQLAlchemy,編寫一個函數來向 users 表插入一條新用戶記錄。
user_service.py文件成功創建。
from sqlalchemy.orm import Session
from models import User
from typing import Optional, Dict, Any
from sqlalchemy.exc import SQLAlchemyErrordef get_user_by_id(session: Session, user_id: int) -> Optional[User]:"""根據用戶ID查詢用戶信息參數:session: SQLAlchemy會話對象user_id: 要查詢的用戶ID返回:User對象(如果找到)或None(如果用戶不存在)"""try:# 使用session.query查詢,可以添加.filter等鏈式調用user = session.query(User).filter(User.id == user_id).first()return userexcept Exception as e:# 記錄錯誤日志(實際項目中應該使用logging模塊)print(f"查詢用戶時發生錯誤: {e}")return Nonedef create_user(session: Session, user_data: Dict[str, Any]) -> Dict[str, Any]:"""創建新用戶記錄參數:session: SQLAlchemy會話對象user_data: 包含用戶信息的字典,應有以下鍵:- nickname: 用戶昵稱(必需)- avatar_url: 頭像URL(可選)- current_zone_id: 戰區ID(可選,默認為0)- total_score: 總積分(可選,默認為0)返回:字典包含:- 'success': 操作是否成功- 'user': 新用戶對象(成功時)- 'error': 錯誤信息(失敗時)"""if not user_data.get('nickname'):return {'success': False, 'error': '昵稱不能為空'}try:new_user = User(nickname=user_data['nickname'],avatar_url=user_data.get('avatar_url'),current_zone_id=user_data.get('current_zone_id', 0),total_score=user_data.get('total_score', 0))session.add(new_user)session.commit()session.refresh(new_user)return {'success': True,'user': new_user,'message': f'用戶 {new_user.nickname} 創建成功,ID: {new_user.id}'}except SQLAlchemyError as e:session.rollback()return {'success': False,'error': f'數據庫錯誤: {str(e)}'}類似地,為 zones 表生成 ORM 模型和 CURD 函數。太多了,這里就補貼上傳的代碼了。
3.3、實時分數更新
這是排行榜系統的核心功能之一,要求分數更新能夠快速反映到排行榜中。首先更新 Redis 中的數據,然后通過某種機制觸發同步到 MySQL。
當玩家分數發生變化時,需要更新全局排行榜和所屬戰區排行榜中的分數。
邏輯:
- 接收玩家 ID、戰區 ID 和分數變化量。
- 使用 Redis 的
ZINCRBY命令原子性地增加全局排行榜 (global_rankSorted Set) 中該玩家的分數。 - 使用 Redis 的
ZINCRBY命令原子性地增加戰區排行榜 (zone_rank:{zone_id}Sorted Set) 中該玩家的分數。 - (可選)更新用戶分數 Hash 或 String 存儲中的總分和戰區分數。
- 觸發數據同步機制(例如,將用戶 ID 和更新后的分數放入一個待同步隊列或直接調用同步服務接口)。
向 CodeBuddy 提問:
使用 redis-py 庫,如何原子性地增加 Redis Sorted Set 中一個成員的分數?
編寫一個 Python 函數update_score(user_id, zone_id, score_change),使用 redis-py 更新全局排行榜和指定戰區排行榜中的分數。
在分數更新后,需要確保這些變化最終同步到 MySQL。這里采用一個簡單的異步觸發機制,將需要同步的用戶信息放入一個隊列(例如,一個 Redis List 或一個簡單的 Python 列表,在實際場景應使用消息隊列)。數據同步服務會消費這個隊列。
邏輯: 在 update_score 函數中,分數更新 Redis 成功后,將 user_id 加入一個 Redis List,例如 sync_queue。
向 CodeBuddy 提問:
使用 redis-py 庫,如何將一個元素添加到 Redis List 的末尾?
修改update_score函數,在更新 Redis 后,將user_id添加到sync_queueList 中。
CodeBuddy 解釋zincrby命令的使用并提供代碼:
最終的代碼內容:
import redis
from typing import Unionclass RedisRanking:def __init__(self, host='localhost', port=6379, db=0):"""初始化Redis連接"""self.redis = redis.Redis(host=host, port=port, db=db, decode_responses=True)def increment_member_score(self, key: str, member: str, increment: Union[int, float] = 1) -> float:"""原子性地增加Sorted Set成員的分數參數:key: Sorted Set的鍵名member: 成員標識increment: 要增加的分數(默認為1)返回:增加后的新分數"""try:# ZINCRBY是原子操作new_score = self.redis.zincrby(key, increment, member)return float(new_score)except redis.RedisError as e:print(f"Redis操作失敗: {e}")raisedef bulk_increment_scores(self, key: str, member_scores: dict) -> bool:"""原子性地批量增加多個成員的分數參數:key: Sorted Set的鍵名member_scores: {成員: 增加分數}的字典返回:操作是否成功"""try:# 使用pipeline確保原子性with self.redis.pipeline() as pipe:for member, increment in member_scores.items():pipe.zincrby(key, increment, member)pipe.execute()return Trueexcept redis.RedisError as e:print(f"批量操作失敗: {e}")return Falsedef update_score(self,user_id: str, zone_id: str,score_change: Union[int, float],max_queue_size: int = 10000) -> bool:"""更新全局和戰區排行榜分數,并將用戶ID添加到同步隊列參數:user_id: 用戶IDzone_id: 戰區IDscore_change: 分數變化值(可正可負)max_queue_size: 同步隊列最大長度(可選)返回:操作是否成功"""try:with self.redis.pipeline() as pipe:# 更新全局排行榜pipe.zincrby("global_leaderboard", score_change, user_id)# 更新戰區排行榜pipe.zincrby(f"zone_leaderboard:{zone_id}", score_change, user_id)# 將用戶ID添加到同步隊列末尾pipe.rpush("sync_queue", user_id)# 可選: 限制隊列長度if max_queue_size > 0:pipe.ltrim("sync_queue", -max_queue_size, -1)pipe.execute()return Trueexcept redis.RedisError as e:print(f"更新排行榜失敗: {e}")return False3.4、排行榜查詢
排行榜查詢是用戶最常進行的操作。主要從 Redis 中獲取排名數據,然后從 MySQL 中獲取用戶的附加信息。
查詢 Redis 排行榜數據, 邏輯:
- 全局榜: 使用 Redis 的
ZREVRANGE命令,根據分數倒序獲取global_rankSorted Set 中指定范圍(分頁)的成員(用戶 ID)及其分數。 - 戰區榜: 使用 Redis 的
ZREVRANGE命令,根據分數倒序獲取zone_rank:{zone_id}Sorted Set 中指定范圍的成員(用戶 ID)及其分數。 - 查詢個人排名: 使用 Redis 的
ZREVRANK命令獲取某個用戶在 Sorted Set 中的排名(從 0 開始),然后根據排名計算實際名次。使用ZSCORE命令獲取用戶的分數。
向 CodeBuddy 提問:
使用 redis-py 庫,如何獲取 Redis Sorted Set 中分數最高的 N 個成員?
使用 redis-py 庫,如何查詢某個成員在 Redis Sorted Set 中的排名和分數?
編寫函數來實現全局榜和戰區榜的分頁查詢,以及查詢個人排名和分數的功能。
需要實現以下幾個功能:
-
獲取Sorted Set中分數最高的N個成員(ZREVRANGE)
-
查詢成員的排名(ZREVRANK)和分數(ZSCORE)
-
分頁查詢功能(ZREVRANGE + offset)
-
封裝為全局榜和戰區榜的查詢方法
從 MySQL 獲取用戶附加信息: 從 Redis 獲取到用戶 ID 和分數后,需要根據用戶 ID 從 MySQL 的 users 表中查詢用戶的昵稱、頭像等信息,以便在排行榜界面展示。
邏輯:
- 從 Redis 查詢結果中提取用戶 ID 列表。
- 使用 SQL 的
IN子句或多次查詢,根據用戶 ID 列表批量從users表中查詢用戶信息。 - 將從 Redis 和 MySQL 獲取的數據進行整合。
向 CodeBuddy 提問:
使用 SQLAlchemy,如何根據一個用戶 ID 列表批量查詢 users 表?
修改排行榜查詢函數,在獲取 Redis 數據后,添加從 MySQL 查詢用戶信息的邏輯,并將兩部分數據整合。
3.5、數據同步服務實現
數據同步服務是一個獨立的后臺進程,負責消費待同步隊列,并將 Redis 中的最新數據同步到 MySQL。
邏輯:
- 循環監聽或定時檢查
sync_queueRedis List。 - 從隊列中取出待同步的用戶 ID。
- 根據用戶 ID,從 Redis 中獲取該用戶的最新總分和各戰區分數(可能需要查詢
user_score:{user_id}Hash 或各個zone_rank:{zone_id}Sorted Set)。 - 根據獲取到的分數,更新 MySQL 中
users表的total_score字段。 - (可選)根據同步策略,更新或插入到
leaderboard_snapshots表。 - 處理同步過程中的異常和并發問題。
向 CodeBuddy 提問:
使用 redis-py 庫,如何從 Redis List 的頭部取出一個元素?
如何編寫一個簡單的 Python 腳本,循環從 Redis List 中讀取用戶 ID,并打印出來?
使用 SQLAlchemy,如何根據用戶 ID 更新 users 表的 total_score 字段?
幫助構建數據同步服務的核心邏輯代碼,包括從 Redis 讀取、從 Redis 獲取最新分數、更新 MySQL 等步驟。處理批量同步和錯誤重試。
生成服務代碼:
import redis
from typing import List, Dict, Optional
from sqlalchemy.orm import Session
from models import User
import time
from datetime import datetimeclass DataSyncService:def __init__(self, redis_conn, db_session):"""初始化同步服務參數:redis_conn: Redis連接實例db_session: SQLAlchemy會話"""self.redis = redis_connself.db = db_sessionself.batch_size = 100 # 每次同步的批量大小self.max_retries = 3 # 最大重試次數self.retry_delay = 1 # 重試延遲(秒)def _get_sync_queue(self) -> List[str]:"""從Redis同步隊列獲取待處理用戶ID"""try:# 獲取并清空當前批次user_ids = self.redis.lrange("sync_queue", 0, self.batch_size-1)if user_ids:self.redis.ltrim("sync_queue", len(user_ids), -1)return [uid.decode() if isinstance(uid, bytes) else uid for uid in user_ids]except redis.RedisError as e:print(f"獲取同步隊列失敗: {e}")return []def _get_redis_scores(self, user_ids: List[str]) -> Dict[str, float]:"""從Redis獲取用戶最新分數"""try:with self.redis.pipeline() as pipe:for user_id in user_ids:pipe.zscore("global_leaderboard", user_id)scores = pipe.execute()return {user_id: float(score) if score is not None else Nonefor user_id, score in zip(user_ids, scores)}except (redis.RedisError, TypeError) as e:print(f"獲取Redis分數失敗: {e}")return {}def _update_mysql_users(self, user_scores: Dict[str, float]) -> int:"""批量更新MySQL用戶分數"""if not user_scores:return 0updated_count = 0try:# 獲取需要更新的用戶ID列表user_ids = [int(uid) for uid in user_scores.keys()]# 批量查詢用戶users = self.db.query(User).filter(User.id.in_(user_ids)).all()# 創建用戶映射user_map = {user.id: user for user in users}# 批量更新for user_id, score in user_scores.items():user_id_int = int(user_id)if user_id_int in user_map and score is not None:user = user_map[user_id_int]user.total_score = scoreuser.updated_at = datetime.now()updated_count += 1self.db.commit()return updated_countexcept Exception as e:self.db.rollback()print(f"更新MySQL失敗: {e}")return 0def sync_batch(self) -> Dict[str, int]:"""執行一批數據同步返回:包含同步結果的字典:{'total': 總處理數量,'updated': 成功更新數量,'retries': 重試次數}"""result = {'total': 0, 'updated': 0, 'retries': 0}for attempt in range(self.max_retries):# 獲取待同步用戶user_ids = self._get_sync_queue()if not user_ids:breakresult['total'] = len(user_ids)# 獲取最新分數user_scores = self._get_redis_scores(user_ids)# 更新MySQLupdated = self._update_mysql_users(user_scores)result['updated'] = updatedif updated == len(user_ids):break # 全部成功則退出重試result['retries'] += 1time.sleep(self.retry_delay)return resultdef continuous_sync(self, interval: int = 5):"""持續同步數據"""print(f"啟動數據同步服務,間隔: {interval}秒")while True:try:batch_result = self.sync_batch()if batch_result['total'] > 0:print(f"同步完成: 處理={batch_result['total']}, "f"更新={batch_result['updated']}, "f"重試={batch_result['retries']}")time.sleep(interval)except KeyboardInterrupt:print("停止數據同步服務")breakexcept Exception as e:print(f"同步服務異常: {e}")time.sleep(interval)
四、Demo 演示與成果展示
已經構建了一個基于 Redis 和 MySQL 雙引擎驅動的《王者榮耀》戰區排行榜系統的核心功能。現在可以通過一個簡單的 Demo 演示來展示系統的實際運行效果。
安裝和啟動redis:
sudo apt install redis-server # (如果未安裝)
redis-server --version
sudo service redis-server start # 啟動
sudo service redis-server stop # 停止(如果需要)
sudo service redis-server restart # 重啟(如果需要)
安裝依賴:
pip install -r requirements.txt
配置環境變量,復制.env.example文件為.env,并根據實際情況修改配置:
cp .env.example .env
# 編輯.env文件,修改數據庫和Redis連接信息
初始化數據庫:
mysql -u root -p < init_db.sql
啟動應用:
# 啟動所有服務(API服務和數據同步服務)
./run.sh
# 或
./run.sh all# 只啟動API服務
./run.sh api# 只啟動數據同步服務
./run.sh sync
數據同步服務負責在Redis和MySQL之間同步排行榜數據,確保數據一致性。默認同步間隔為5分鐘,可通過.env文件中的SYNC_INTERVAL參數調整。
圖 4-1 分數更新與同步演示流程
圖 4-2 排行榜查詢演示流程
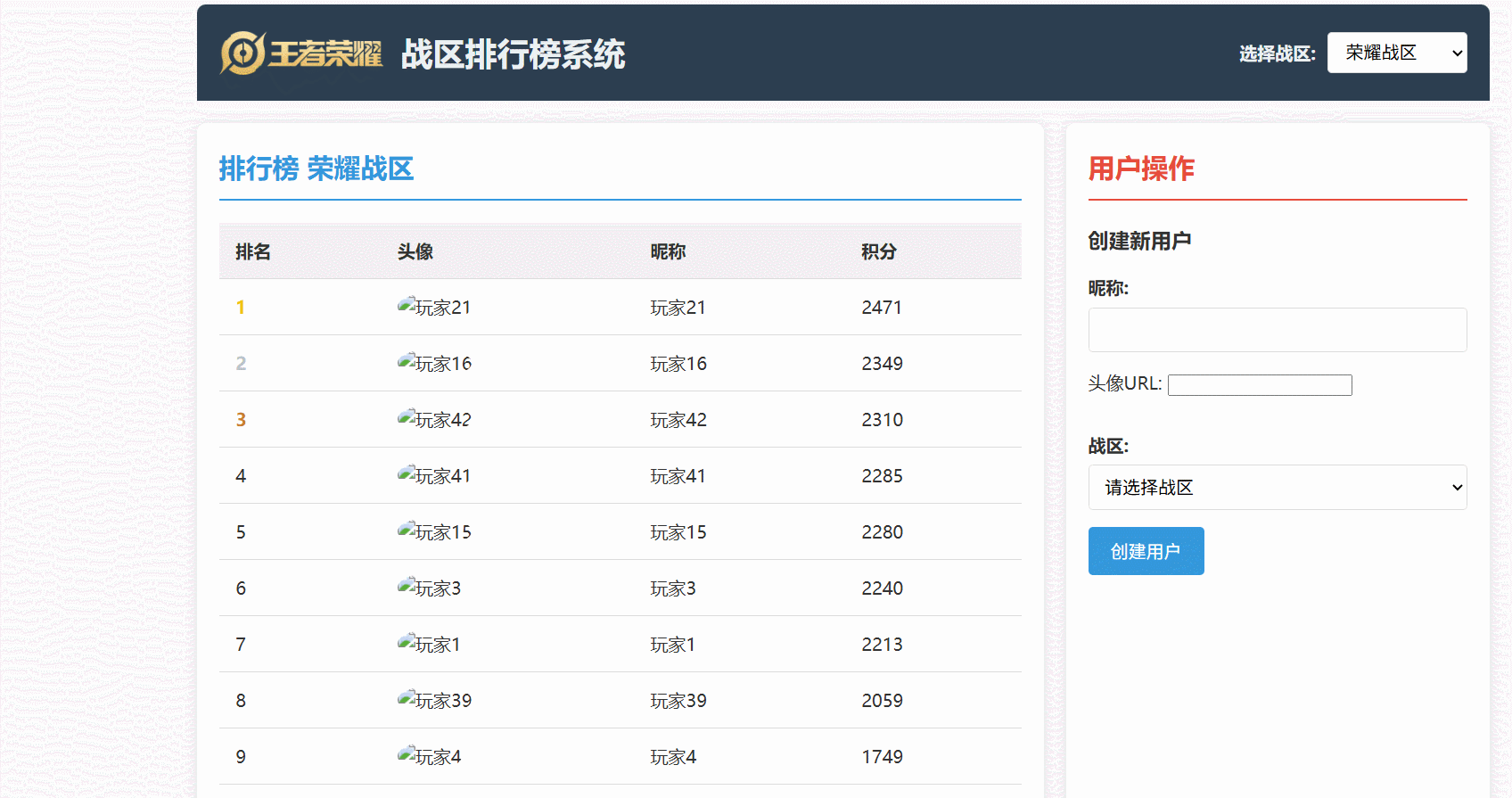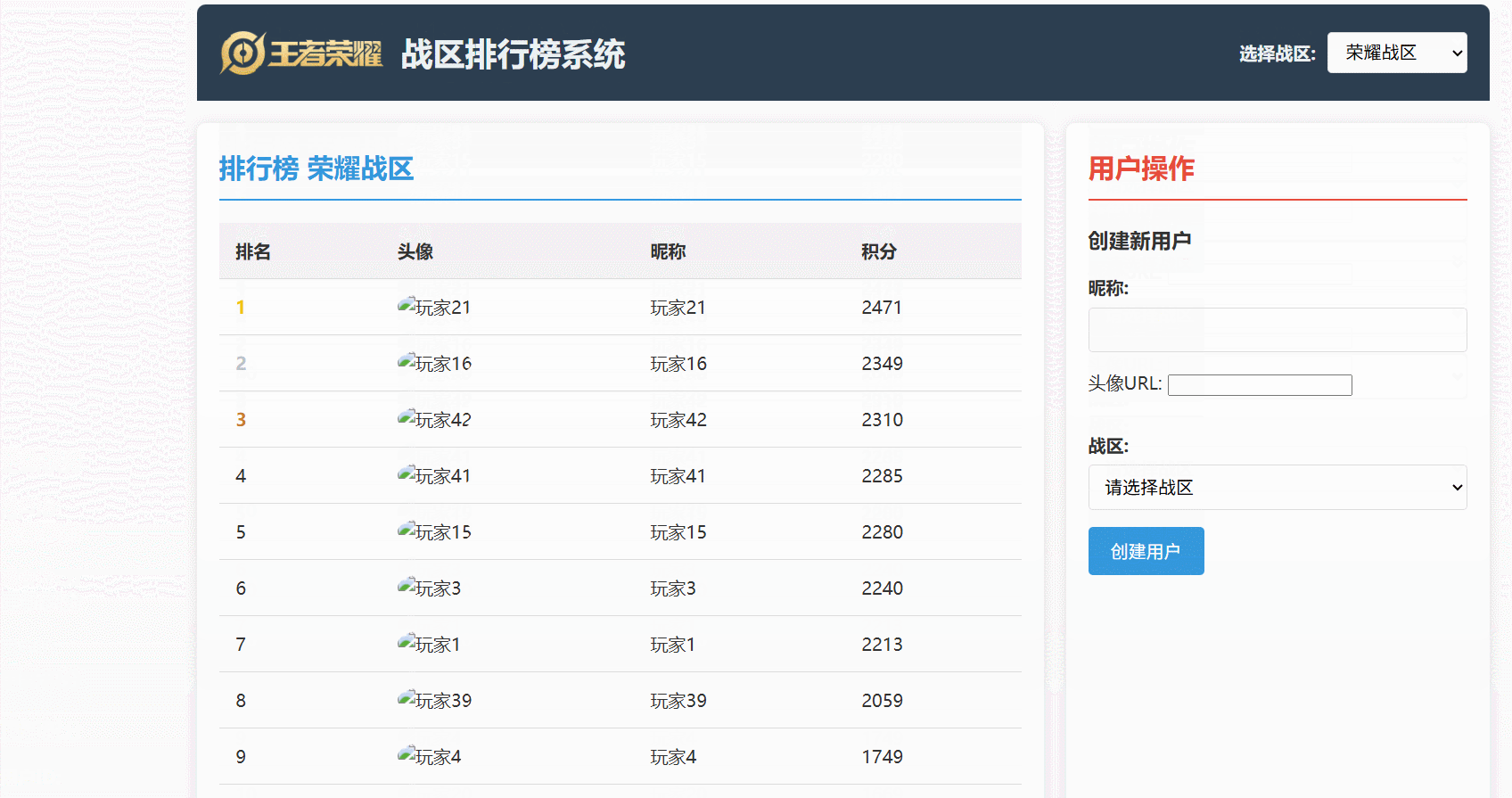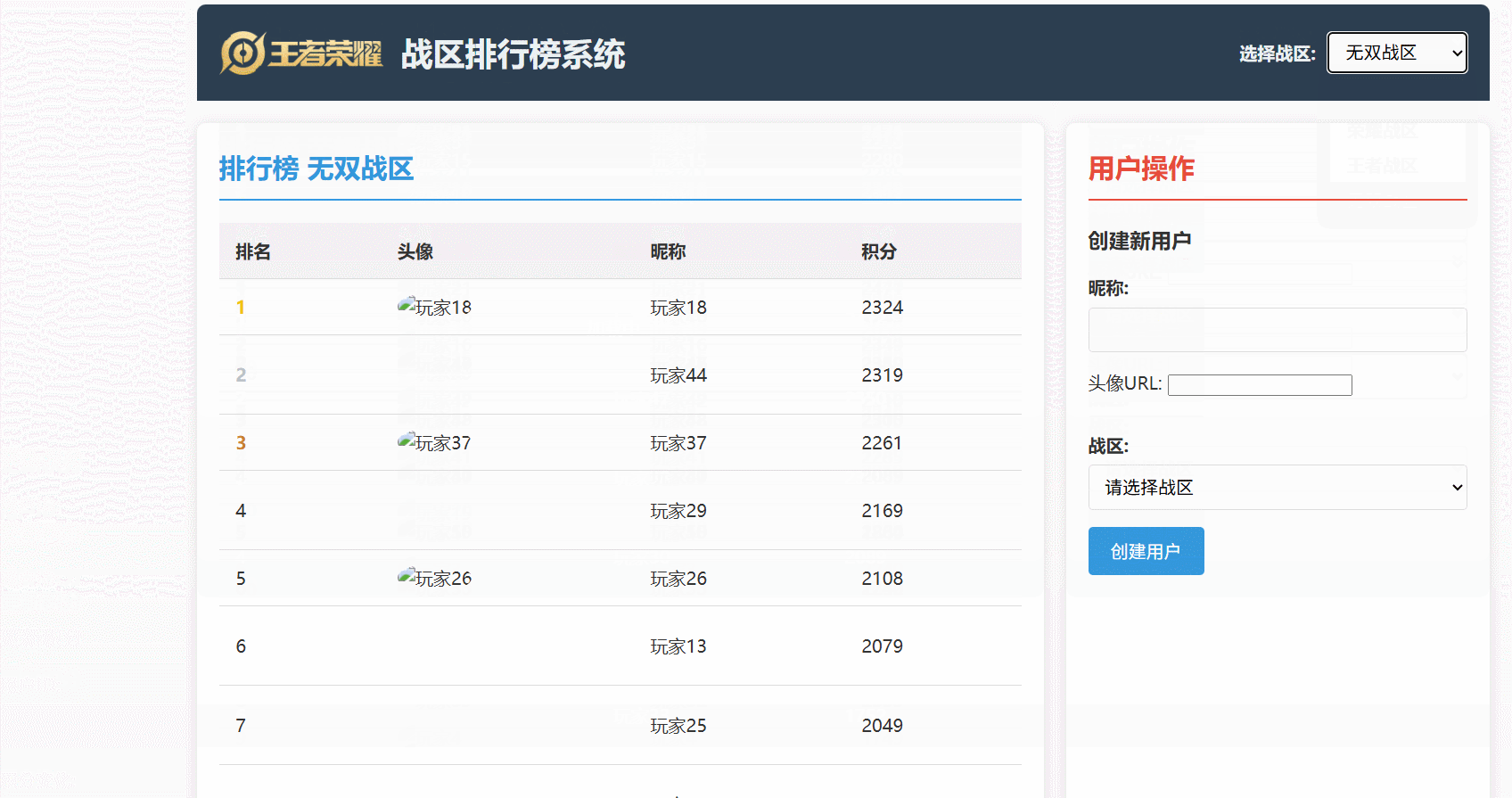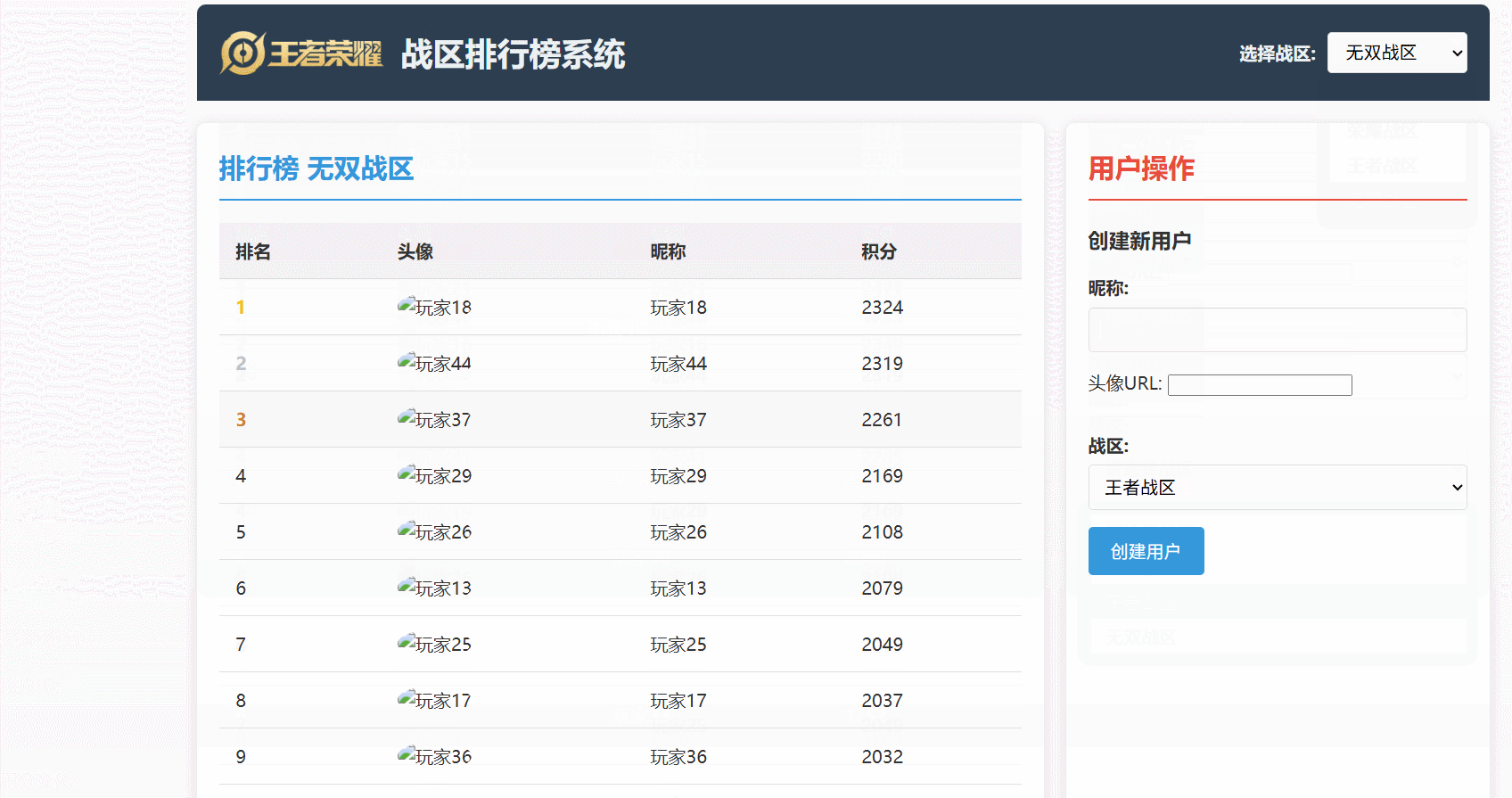
可以直觀地看到:
- 玩家分數更新后,Redis 中的排行榜數據能夠幾乎實時地反映變化。
- 排行榜查詢能夠快速地從 Redis 獲取排名數據,并結合 MySQL 的用戶信息進行展示。
- 數據同步機制確保了 Redis 和 MySQL 之間的數據最終一致性。
最后看一下運行效果:
項目代碼已更新到GitHub:https://github.com/LongTengFly/Python。
通過利用 CodeBuddy 的智能輔助能力,在相對較短的時間內完成了這個雙引擎驅動的排行榜系統的核心功能開發。CodeBuddy 極大地減少了編寫樣板代碼的工作量,使得開發者能夠更專注于業務邏輯的實現和架構的優化。
雖然核心功能已經實現并得到演示,但一個生產級別的排行榜系統還需要進一步的優化和擴展:
- 對高并發場景下的 Redis 和 MySQL 讀寫進行性能調優,例如連接池管理、批量操作、索引優化等。
- 引入更 robust 的數據同步機制,如基于消息隊列的最終一致性方案,處理同步過程中的各種異常情況。
- 考慮 Redis 集群、MySQL 讀寫分離、后端服務水平擴展等。
- 更多排行榜類型: 支持周榜、月榜、好友榜等。
五、總結
已經完成了排行榜系統的架構設計、核心功能開發并在本地進行了簡單的 Demo 演示,重點在 CodeBuddy 在這些環節中的輔助作用。
本文闡述了如何利用CodeBuddy構建一個基于Redis和MySQL雙引擎的《王者榮耀》戰區排行榜系統。從架構設計、數據庫選型、核心功能開發,到Demo演示,全面覆蓋項目生命周期。重點展示了CodeBuddy在代碼生成、技術咨詢、問題排查等方面的強大輔助能力,顯著提升了開發效率。










)
![[案例四] 智能填寫屬性工具(支持裝配組件還有建模實體屬性的批量創建、編輯)](http://pic.xiahunao.cn/[案例四] 智能填寫屬性工具(支持裝配組件還有建模實體屬性的批量創建、編輯))
)



)



