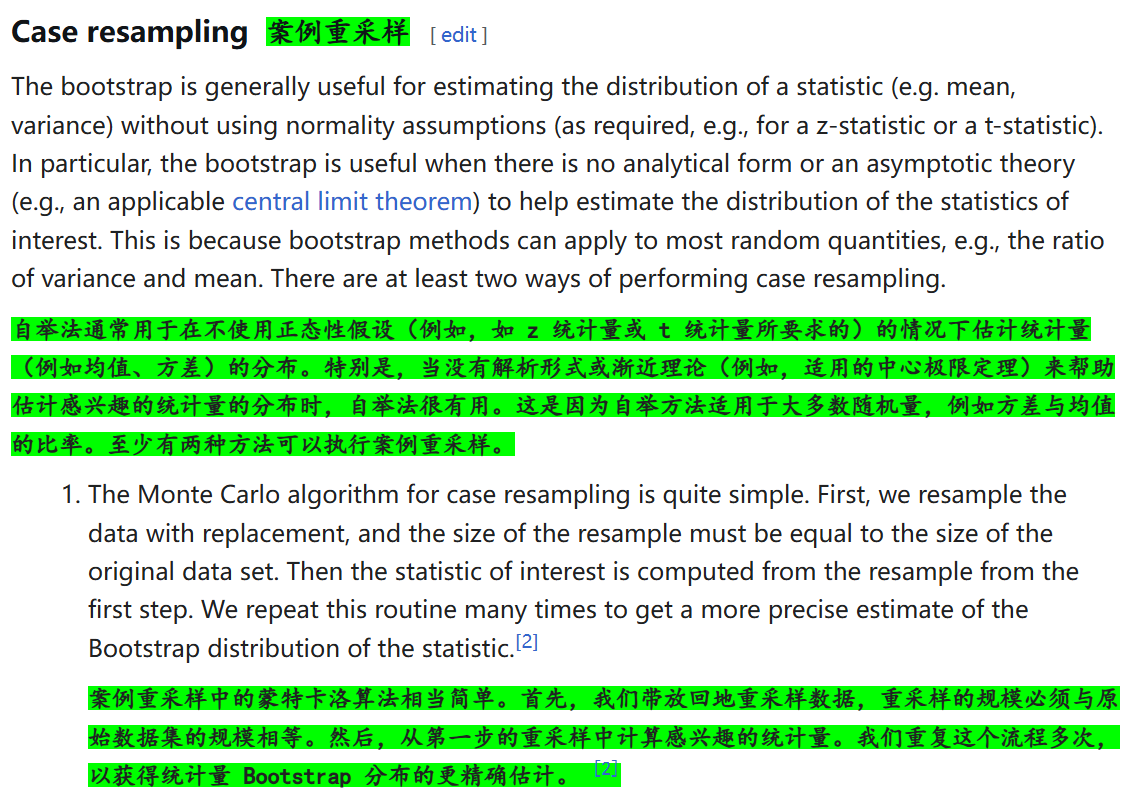
一,概念

一言以蔽之:從訓練集中有放回的均勻抽樣——》本質就是有放回抽樣;
自助法(bootstrap)是一種通過從數據集中重復抽樣來估計統計量分布的非參數方法。它可用于構建假設檢驗,當對參數模型的假設存在懷疑,或者基于參數模型進行統計推斷不可行、計算標準誤差需要復雜公式時,自助法可作為替代方案。
說的更嚴謹點,就是隨機可置換抽樣(random sampling with replacement)


從總體中獲取樣本,再從樣本中重采樣獲取重樣本,即總體-樣本-重樣本的處理路線;
注意,從樣本到重樣本的重采樣,通常需要確保重采樣的大小和原本樣本的大小一致(通常要求重采樣的樣本大小與原始樣本大小相同)——
數據使用完備性,盡可能使用上所有的數據,另外一方面因為最終的目的是為了估計總體中的某個參數,也就是說無論是重樣本還是樣本,最終目的都是為了估計最上游總體中的某個參數,方法都是基于重樣本或者是樣本的統計量的估計。
所以一般要求重采樣的樣本大小與原始樣本大小相同,目的是為了保證重采樣樣本能夠盡可能地反映原始樣本的分布特征,從而使得基于重采樣樣本得到的統計量的估計更加準確和可靠。如果重采樣樣本大小與原始樣本大小不同,可能會導致估計結果出現偏差。
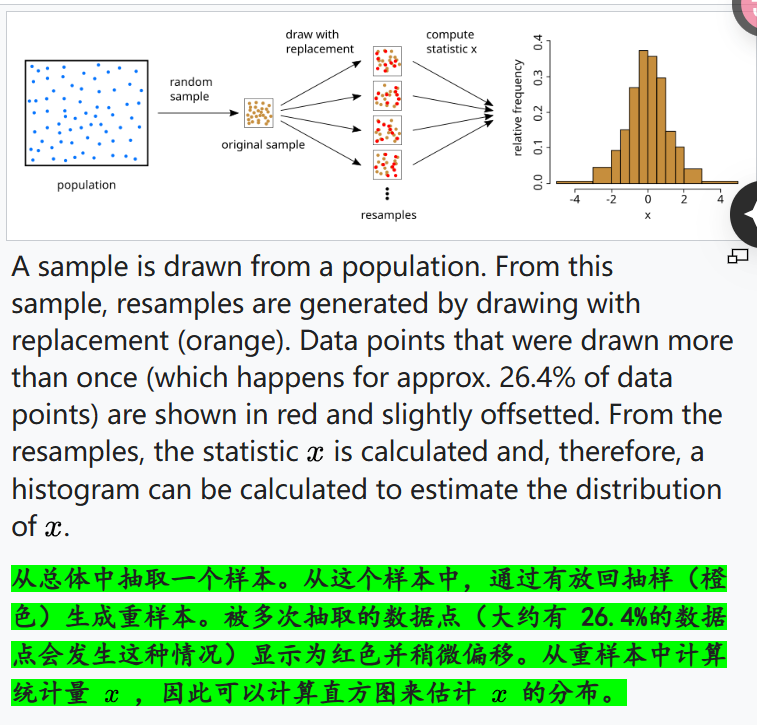
道理其實很簡單:如果我的樣本比如說是長度為1000的字符序列(比如說是長度為1000的氨基酸序列),那么我每次重采樣,就需要從這個長度為1000的字符序列中重新采樣生成長度為1000的一個樣,這才是一個樣;
我可以是采樣原始氨基酸序列前100個字符重復10次;或者是重復后200個字符5次;
總之每個字符的選擇都是有放回的采樣采得的,然后一共采了1000個原始氨基酸序列長度個字符,這樣才是一個樣;
然后我需要按照這種采樣規則采樣n次,這就是bootstrap。
如果要嚴謹一點的、數學一點的定義:





自助法的基本原理

自助法的評估機制


自助法通過模擬重采樣數據的經驗分布 來近似原始數據的真實分布 ,并利用已知的 來評估推斷的準確性。如果 是 的合理近似,那么就可以通過評估 的推斷質量來推斷 的推斷質量。這種方法為在有限樣本數據下進行統計推斷提供了一種有效的途徑。
————》
當然,嵌套了兩層的近似,從總體-原始樣本-重采樣,總會有點概念上的迷惑,比如說近似傳遞性的證明是否嚴謹等?
我們需要更清晰地區分總體、樣本和重樣本,再次對以上內容進行復述;
總體、樣本和重樣本的定義
- 總體(Population)

- 樣本(Sample)

樣本分布對總體分布的近似就是一般初學者大一學的概率論中的統計推斷、參數估計部分;
我們對于不同的總體,抽樣獲取的樣本,也會有一個對應的分布。
- 重樣本(Bootstrap Sample)

自助法的核心邏輯

詳細解釋
- 類比推斷過程


- 評估
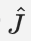 的準確性
的準確性

- 推斷
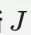 的質量
的質量

總的來說

——》
在這個表述下,我們對近似的傳遞性,會自然而然的有一個疑問:
我有一個問題,這里是從樣本中有放回抽樣得到樣本分布的一個近似,那么樣本分布又可能是總體分布的一個近似,那么這里的重采樣獲取的經驗分布豈不是對總體分布近似的近似?
這種疑問的產生是因為數學嚴謹性要求自然產生的疑問,某種程度上這么理解是正確的。
自助法(bootstrap)確實是從樣本中有放回地抽樣,以得到樣本分布的一個近似,而這個樣本分布本身又是總體分布的一個近似。因此,通過重采樣得到的經驗分布可以被視為對總體分布的近似的近似。
為了更清楚地解釋這一點,我們可以從以下幾個方面來理解:
- 樣本分布與總體分布:樣本分布是根據從總體中抽取的樣本數據計算得到的分布,它試圖近似總體分布。由于樣本量有限,樣本分布可能無法完全準確地反映總體分布,但隨著樣本量的增加,樣本分布通常會越來越接近總體分布。
- 重采樣與經驗分布:在自助法中,我們從原始樣本中有放回地抽取多個重采樣樣本,每個重采樣樣本的大小與原始樣本相同。然后,我們根據每個重采樣樣本計算出一個經驗分布。這個經驗分布是基于重采樣樣本的,因此它是對樣本分布的一個近似。
- 近似的近似:由于樣本分布本身是總體分布的近似,而經驗分布又是樣本分布的近似,因此經驗分布可以被視為對總體分布的近似的近似。盡管存在這種雙重近似,但自助法在很多情況下仍然能夠提供對總體分布的可靠估計,特別是當原始樣本量較大時。
- 自助法的有效性:自助法的有效性依賴于樣本分布與總體分布之間的相似性,以及重采樣樣本與原始樣本之間的相似性。如果樣本量足夠大,樣本分布通常能夠較好地近似總體分布,而重采樣樣本也能夠較好地近似原始樣本,從而使得經驗分布成為對總體分布的一個合理近似。
綜上所述,雖然經驗分布是總體分布的近似的近似,但自助法通過重采樣和利用樣本分布的相似性,仍然能夠提供對總體分布的有效估計。這種方法在統計學中被廣泛使用,特別是在樣本量有限或總體分布未知的情況下。

此處目的是為了獲取均值這個統計量變異性的一個概念,也就是變異性的一個認知,說白了其實就是想構建這個均值的分布,也就是知道這個均值統計量的取值區間,類似于我們光估計出來均值=10不夠,我們還想知道10±1或者±多少。
總的來說:自舉法是為了推導一些非常復雜的統計量(比如說是協方差或者是分位數)的分布,比如說計算該統計量的標準誤(標準誤差SE)和置信區間(CI)的方法。


Bootstrapping不提供通用的有限樣本保證,它的運用基于很多統計學假設,因此假設的成立與否會影響采樣的準確性。(這個也是數學的魅力所在,在定義中的限制,就是顯而易見的缺點,需要滿足相應的統計學假設)



bootstrap自助法類型:

我們可以從排列組合(中學)的隔板法問題中推導出來理論上精確的重采樣有多少種組合:




注意這里之所以用2n-1個位置,是因為我們允許某個樣本(比如說第i個樣本)不被采樣到,這是有放回采樣的定義自然而然推導獲得的是;

參考:https://blog.csdn.net/mingyuli/article/details/81223463

二,實踐舉例
1,估計樣本均值的分布:


2,回歸

具體例子:使用重采樣估計回歸模型的穩健性
假設我們有一個簡單的線性回歸問題,研究廣告投入(解釋變量 X)與產品銷售額(響應變量 Y)之間的關系。數據集包含100個觀測值,每行代表一個時間段的廣告投入和對應的銷售額。
數據集示例
| 廣告投入 X | 銷售額 Y |
|---|---|
| 10 | 150 |
| 20 | 200 |
| 30 | 250 |
| … | … |
| 100 | 500 |
使用案例重采樣的過程



3,貝葉斯自助法:

4,平滑自舉:

5,參數自助法:

6,重采樣殘差:

7,高斯過程回歸自助法:
涉及到隨機過程等相關概念




8,野自助法/隨機擾動自助法:
處理異方差性(heteroscedasticity)問題,即數據中不同觀測值的方差不相等的情況;
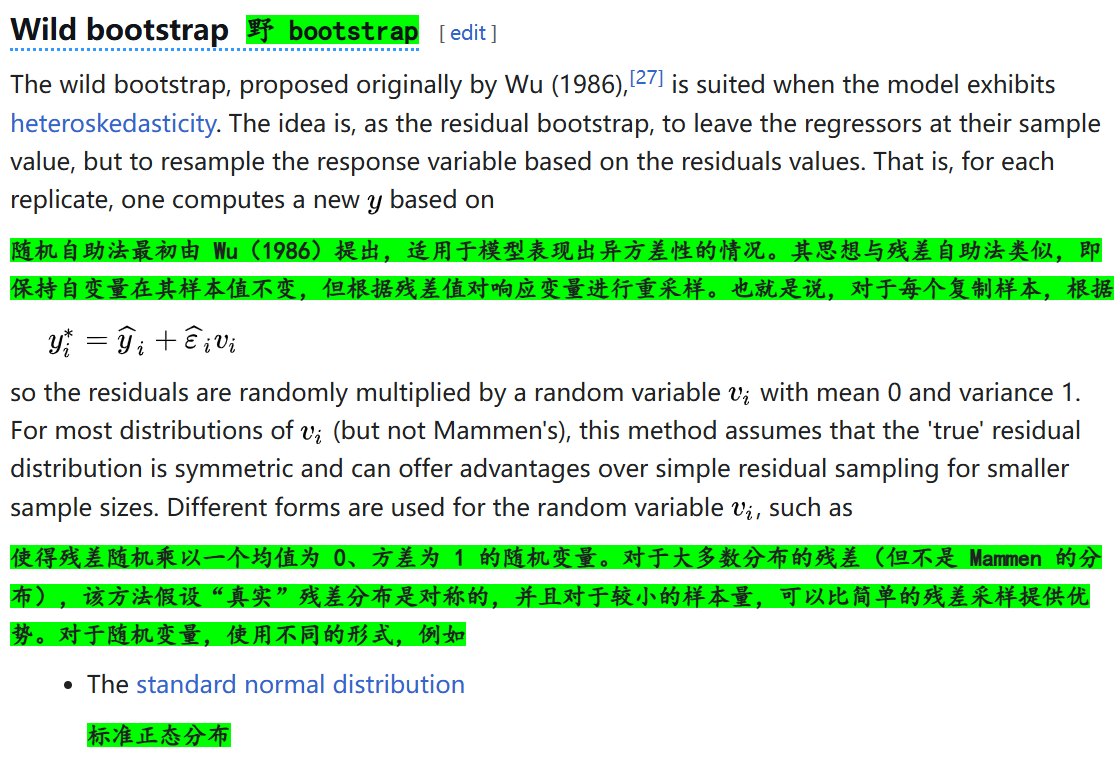

9,塊自助法**Block bootstrap**




三,拓展
1,統計量的選擇

2,自助置信區間——》從自助分布中推導置信區間

我們先討論理想的構造自助置信區間的方法,或者說應該滿足的性質:


偏差、不對稱性和置信區間:

場景設定
假設我們有一個班級,班級里學生的數學考試成績是我們感興趣的總體。我們想估計這個班級的平均成績,但只有一部分學生的成績樣本。
1. 偏差(Bias)
假設我們從班級中隨機抽取了10個學生的成績作為樣本,樣本平均成績是75分。但實際上,班級的總體平均成績是80分。這種情況下,樣本平均數(75分)和總體平均數(80分)之間的差異(-5分)就是偏差。
用數學公式表示:
[ \text{Bias} = \text{樣本估計值} - \text{總體真實值} ]
[ \text{Bias} = 75 - 80 = -5 ]
偏差的來源:
- 樣本可能不具有代表性。比如,我們可能不小心抽到了一些成績較低的學生。
- 樣本量太小,導致估計不夠準確。
2. 不對稱性(Asymmetry)
假設我們用自助法(Bootstrap)來估計班級平均成績。我們從樣本中重復抽樣(有放回)1000次,每次抽10個成績,計算每次抽樣的平均值,得到一個自助法分布。
如果這個分布是對稱的,比如:
- 一半的自助樣本平均值在70分到75分之間,
- 另一半在75分到80分之間,
那么這個分布是對稱的。
但如果分布不對稱,比如:
- 大多數自助樣本平均值集中在70分到75分之間,
- 只有少數在75分到80分之間,
那么這個分布就是不對稱的。
不對稱性的直觀理解:
- 想象一個鐘形曲線,如果它左右兩邊是對稱的,那么它就是對稱分布;如果它偏向一側,比如右邊更高,左邊更低,那么它就是不對稱的。
3. 置信區間(Confidence Intervals)
假設我們想估計班級平均成績的95%置信區間。置信區間是一個范圍,我們有95%的信心認為總體平均成績在這個范圍內。
情況1:對稱分布
如果自助法分布是對稱的,我們可以用百分位數法來計算置信區間。比如,我們取自助樣本平均值的第2.5百分位數和第97.5百分位數作為置信區間的上下限。
假設自助樣本平均值的分布如下:
- 第2.5百分位數是72分,
- 第97.5百分位數是78分,
那么95%置信區間就是[72, 78]。
情況2:不對稱分布
如果自助法分布是不對稱的,百分位數法可能不適用。因為百分位數法假設分布是對稱的,而不對稱分布會導致置信區間估計不準確。
比如,假設自助樣本平均值的分布如下:
- 大多數集中在70分到75分之間,
- 只有少數在75分到80分之間,
如果還用百分位數法,可能會得到一個偏向較低值的置信區間,比如[71, 76],但實際上總體平均成績可能更高。
通俗易懂的總結
- 偏差:樣本估計值和總體真實值之間的差異。比如我們用樣本平均成績估計總體平均成績,但估計值和真實值不一樣。
- 不對稱性:自助法分布的形狀。如果分布左右不對稱,說明數據更傾向于一邊,這種情況下用百分位數法計算置信區間可能會出問題。
- 置信區間:一個范圍,我們有較高信心(如95%)認為總體參數在這個范圍內。如果分布對稱,可以用百分位數法;如果不對稱,可能需要其他方法。
我們一般遇到的都是正態分布或者是t分布等對稱分布,如果我們使用自助法抽樣獲取的某個統計量也符合對稱的分布,那么我們其實確實是可以使用百分位數來表征置信區間,注意,此處只是表征。
我想一個很容易被搞混的點,就是很多人容易搞混置信區間的置信指標α,或者說置信水平1-α,
與該置信區間的覆蓋度,以及所謂假設檢驗中經常提及的上下α分位點的概念等。
為什么要考慮分布是否對稱呢,F檢驗的時候用的也是F分布的上下5%分位數區間?(看,這里我們很容易搞混這個概念)。也不對,F分布使用的是上下分位點,分位點實際使用的是概率的覆蓋所定義的,并不是分位數所定義的,確實是這樣的。
從定義上講,置信區間所覆蓋的范圍本質上就是從概率定義的,所以我們很容易將概率頻率,再降級為相應的分位數。
我們說上α分位點,或者說下α分位點,但是我們不常說上α分位數或者是下α分位數。
1. 為什么分布的對稱性很重要?
在統計推斷中,對稱性是一個重要的假設,因為它影響置信區間的構建和解釋。具體來說:
- 對稱分布的優勢:
- 如果一個分布是對稱的(例如正態分布),那么分布的中位數和均值是相同的,且分布的上下尾部是對稱的。這意味著我們可以使用簡單的百分位數方法來構建置信區間。例如,對于一個對稱分布,95%的置信區間可以通過取分布的2.5%和97.5%百分位數來定義。
- 對稱分布使得估計量的偏差(Bias)更容易被識別和校正,因為偏差通常表現為分布中心的偏移。
- 非對稱分布的問題:
- 如果分布是非對稱的(例如卡方分布或某些自助法分布),使用百分位數方法構建置信區間可能會導致區間估計不準確。因為非對稱分布的尾部不對稱,簡單地取百分位數可能導致區間覆蓋概率不正確。
- 非對稱分布的置信區間需要更復雜的調整方法,例如使用偏差校正的自助法(Bias-Corrected and Accelerated, BCA)置信區間。
2. F檢驗中的分位數和分位點
- F檢驗的背景:
- F檢驗用于比較兩個方差是否相等,或者在方差分析(ANOVA)中檢驗多個組的均值是否相等。
- F檢驗的統計量遵循F分布,F分布是非對稱的,其形狀取決于分子和分母的自由度。
- F分布的分位點:
- 在F檢驗中,我們通常使用F分布的上下分位點來構建置信區間或臨界值。例如,對于一個95%的置信區間,我們會找到F分布的0.025分位點和0.975分位點。
- 這些分位點是通過F分布的概率密度函數(PDF)或累積分布函數(CDF)計算得到的,而不是簡單地取分布的百分位數。
- 分位數與分位點的區別:
- 分位數:是指將數據分成具有相等概率的連續區間的點。例如,中位數是50%分位數,它將數據分成兩部分,每部分的概率為50%。
- 分位點:是指分布函數的反函數在特定概率值處的取值。例如,F分布的0.025分位點是指F分布的累積分布函數等于0.025時對應的值。
3. 為什么F檢驗中使用分位點而不是分位數?
- F分布的非對稱性:
- F分布是非對稱的,因此不能簡單地使用百分位數方法來定義置信區間。例如,F分布的0.025分位點和0.975分位點并不對稱地分布在分布的中位數周圍。
- 使用分位點可以確保置信區間的覆蓋概率是正確的,即使分布是非對稱的。
- 概率覆蓋的定義:
- 在F檢驗中,我們關心的是置信區間的覆蓋概率,即區間包含真實參數的概率。分位點是通過分布的概率密度函數或累積分布函數計算得到的,能夠更準確地反映這種概率覆蓋。
- 而簡單地使用百分位數可能會忽略分布的非對稱性,導致區間估計不準確。
總結
- 對稱性的重要性:對稱分布使得置信區間的構建更簡單,因為可以使用百分位數方法。非對稱分布則需要更復雜的調整方法。
- F檢驗中的分位點:F分布是非對稱的,因此使用分位點而不是分位數來定義置信區間,以確保覆蓋概率的準確性。
3,自助置信區間的構建方法


百分位數法構造置信區間:這個方法實際上是很常用的,首先從代碼實踐上操作很簡單,因為python的numpy或者是R的tidyverse中對于數組/array計算分位數的API很容易調用(也就是調包,自己寫函數很簡單)。
所以我們說寫簡單的包或者是函數,調包調庫def不是很難,難的是數學嚴謹性,也就是應用的條件。

當然了,此處還是需要注意前面已經提到的問題,就是當自助分布是對稱的,并且以觀察到的統計量為中心的時候,這種自助法估計真實總體參數的置信區間(用重采樣的分位數去估計推導)才是比較合適的。
1. 估計分位數參數時,自助抽樣得到的中位數分布是否對稱?
簡短回答:
通常情況下,自助法得到的中位數分布并不一定是嚴格對稱的,但是如果原始數據“不是嚴重偏斜”,當樣本量不是特別小的時候,自助分布往往“近似對稱且集中在觀測中位數附近”。但如果原始數據特別偏斜(比如90%的點都擠在一邊),則自助中位數分布也會偏斜,不能保證一定對稱。
詳細解釋與舉例:
舉例1(數據分布接近對稱):
- 假設你的原始數據是
[2, 3, 4, 5, 6],中位數是4。 - 用自助法重復抽樣后,每一組都算中位數,得到一大堆“自助中位數”。
- 你會發現這些自助中位數大部分也集中在4的附近,分布近似對稱——這時候用百分位法效果好。
舉例2(數據強偏斜):
- 如果原始數據是
[1, 1, 1, 1, 10],中位數是1。 - 自助重抽時,大部分樣本的中位數仍然是1,只在極少數時候抽到比較多10時,中位數才變成10。這時自助分布極度偏斜(大多數1,個別出現10),就很不對稱。
- 如果你直接用bootstrap分布的2.5%和97.5%分位數,得到的置信區間將“嚴重低估”或者“不能如實反映實際分布的不確定性”。
結論:
自助中位數分布是否對稱,取決于原始數據分布。如果樣本偏態、不均勻,bootstrap分布也往往偏斜。這時百分位法的置信區間未必可靠,建議使用偏差校正類的改進方法(比如BCa),特別是樣本量不大或分位數落在分布的“偏斜端”時。
2. 分位數和概率可以對應嗎?分位數區間為何不等于概率置信區間?
這是bootstrap置信區間常見誤解。
分位數和概率的基本關系:
- 分位數的定義:第p百分位數就是分布中有p比例數據點小于等于它。比如0.975分位數=97.5%的bootstrap統計量小于它。
- 概率置信區間:在bootstrap自助法里,用p和1-p分位數圍出來的區間,在bootstrap分布下,覆蓋被估計的統計量的概率大約是(1-2p)。
疑惑來源與本質:
- 理論上,如果自助分布與真實抽樣分布等價、對稱并以觀測統計量為中心,那么用分位數構造置信區間,和直覺上的概率置信區間基本一致。(比如bootstrap均值是對稱、集中的)
- 但如果分布偏斜,觀測統計量未必正好落在中心,那么用bootstrap分位數構造的區間,實際置信水平和你期望的不完全一致。也就是,置信區間中包含真實參數的概率不再等于你用的百分比。
舉個極端例子:
- 你的自助分布大多數“擠在一側”,那你得到的“95%區間”可能有95%的自助統計量落在區間內,但這個區間對應原參數的實際置信概率可能遠低于95%。
為什么會這樣?
- 分位數只是把自助統計量本身排序后的排名,不等同于對真實未知參數的概率分布排序。
- 只有分布對稱、以觀測統計量為中心時,這兩者才近似等價。
- 一旦分布偏斜,區間邊界和實際參數脫鉤;也可能區間包含觀測統計量的概率達不到設定的95%等。
總結與建議
- Bootstrap中位數分布是否對稱,視原始樣本分布和樣本量而定,并不保證天然對稱,實際常常偏斜,需具體檢驗。
- 分位數與置信區間的概率只有在分布對稱、以觀測統計量為中心時才近似等價;一旦偏斜就不準。
- 如果估計分位數參數,且分布明顯偏斜,建議使用:
- 偏差校正加加速法(BCa, bias-corrected accelerated)
- 或者用“基本自助法”(basic bootstrap),校準中心和分布形狀
一句話總結:
百分位數法的核心假設是bootstrap分布“對稱+居中”,否則分位數和真實置信概率不等價,區間易失真。


注:以上結論僅供參考,實際分析時,需要繪制bootstrap自助參數的分布形狀


如果是數學一點的表述:

4,與其他重采樣方法的關系:我們重點理解其和交叉驗證CV的關系

在統計學習也就是機器學習中,經常和bootstrap一起提到的就是cross validation即CV交叉驗證(一般是數據集劃分+模型驗證部分會涉及到)。


上面說的是只是一次抽樣中可能產生的偏差,如果一次抽樣,抽樣樣本無限大(也就是N或者是d無限大),我們實際上通過抽樣劃分出來的數據是有偏差的:也就是說如果我們只是有放回的重采樣1次+采樣樣本量很大,相當于我們只是劃分了63.2%的訓練集,然后再用這63.2%的數據之外的作為驗證集去驗證模型,其實就相當于是63.2:36.8的數據集劃分了(近似于6:4),
然后我們再不斷重復這個重采樣也就是劃分過程,不斷地進行64劃分CV。
和CV不同的是,我們每次64劃分中的6和4是不定的,也就是變動的
1. 自助法(Bootstrap)的基本原理
自助法是一種基于有放回抽樣的統計方法,主要用于估計模型的性能或評估模型的穩健性。它的核心思想是從原始數據集中有放回地抽取樣本,生成新的數據集(稱為“自助樣本集”),并基于這些自助樣本集進行分析。
2. .632自助法的具體過程
在.632自助法中,具體步驟如下:
- 生成訓練集:從原始數據集(包含d個樣本)中,有放回地隨機抽取d次,生成一個新的訓練集。由于是有放回抽樣,某些樣本可能會被重復抽取,而有些樣本可能一次也沒有被抽到。
- 生成驗證集:那些在訓練集中沒有被抽到的樣本,自然就形成了驗證集(也稱為測試集)。根據前面的數學推導,當樣本數量足夠大時,大約有36.8%的樣本會進入驗證集,而63.2%的樣本會進入訓練集。
- 模型訓練與驗證:使用生成的訓練集訓練模型,然后在驗證集上評估模型的性能。
3. 與交叉驗證的區別
- 交叉驗證:
- 原理:將原始數據集劃分為若干個互不重疊的子集,每次用其中一部分作為驗證集,其余部分作為訓練集,重復多次,最后取平均性能。
- 優點:充分利用了所有數據,每個樣本都有機會被用作驗證集。
- 缺點:計算成本較高,尤其是當數據集較大或模型訓練時間較長時。
- .632自助法:
- 原理:通過有放回抽樣生成訓練集和驗證集,每次抽樣得到的訓練集和驗證集是隨機的。
- 優點:計算成本相對較低,因為每次只需要生成一個訓練集和一個驗證集,適合大規模數據集。
- 缺點:驗證集的樣本數量較少(約占36.8%),可能導致驗證結果的方差較大。
4. 應用場景
.632自助法常用于以下場景:
- 模型評估:當數據集較大且計算資源有限時,.632自助法可以快速評估模型的性能。
- 模型選擇:通過多次自助抽樣,比較不同模型的性能,選擇最優模型。
- 特征選擇:評估特征對模型性能的影響,選擇重要特征。
5. 總結
.632自助法是一種利用自助法劃分訓練集和驗證集的方法,它通過有放回抽樣生成訓練集和驗證集,并利用數學推導保證了驗證集的樣本比例約為36.8%。它與交叉驗證不同,更注重計算效率,適合大規模數據集的快速模型評估。
總的來說,兩者的異同在于:
交叉驗證法
采用無放回的隨機采樣方式,從數據集D中抽出部分數據作為訓練集T,另外一部分作為測試集T’,并重復若干次隨即劃分過程,以每次劃分對應的測試評估的均值作為評估結果(交叉便體現在重復若干次隨機劃分過程中兩個數據集間數據的交叉)。
自助法
采用有放回的隨機抽樣方法,在保持訓練集T與數據集D規模一致的條件下,從數據集D中抽出有重復的數據作為訓練集T,剩下沒有被抽中的數據作為測試集T’。
相同點:
交叉驗證法和自助法都是隨機采樣法。它們作為人工智能中評估模型的方法,根據一定規則從數據集D中劃分訓練集和測試(驗證)集,從而評價模型在數據集上的表現,便于我們選擇合適的模型。
不同點:
正如上面所述,這兩種方法最大的不同點在于每次劃分過程中每個樣本點是否只有一次被劃入訓練集或測試集的機會。下面將針對這方面詳細展開論述:
交叉驗證法采用的是無放回的隨機采樣方式,這種方式可以保持數據分布的一致性條件,并嚴格劃分訓練集與測試集的界限,從而增強測試評估的穩定性和可靠性。
自助法主要面向數據集同規模的劃分問題。其采用的是有放回的隨機抽樣方法,可以使得得到的模型更為穩健,解決了交叉驗證法中模型選擇階段和最終模型訓練階段的訓練集規模差異問題;但訓練集T和原始數據集D中數據的分布未必相一致,因此對一些對數據分布敏感的模型選擇并不適用。
四,code實現
此處以python實現為主,我們考慮
首先按步驟分解我們的問題:
(1)從原始樣本中有放回的抽取一定數量的樣本:
因為是隨機抽樣+有放回,使用numpy中的np.random.choice函數
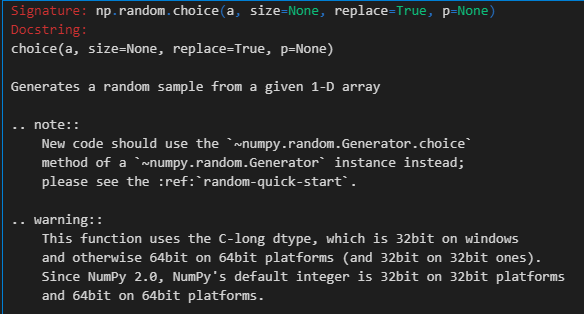
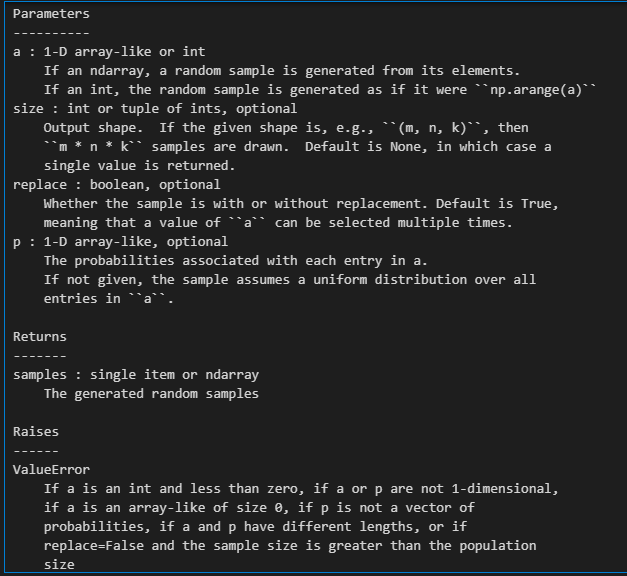
我們只需要關注其中的參數size(一般為原始樣本的尺寸size)、replace(True,即有放回抽樣);
注意上面只是1次抽樣,返回的也是一個ndarray對象;
我們可以通過for循環進行多次抽樣:
for iter in range(num_of_bootstrap):
(2)根據抽出的樣本計算給定的統計量:
即自助統計量,比如說我們此處以中位數為例,numpy中可以調用median
(3)重復上述抽樣操作N次,得到N個統計量,見(1)
(4)構造置信區間,使用百分位數法:
在python中計算一個多維數組的任意百分比分位數,此處的百分位是從小到大排列,只需用np.percentile即可(至于百分位數的問題,還是參考前面的說法)
下面是我的一個草稿代碼:
def bootstrap_X(n_bootstrap,sample:list[float],real_param_to_test,alpha=0.05):"""Args:n_bootstrap: 自助法抽樣的次數sample: 需要進行自助法抽樣的樣本數據,此處設置為list浮點數列表類型real_param_to_test: 需要進行置信區間估計(顯著性判斷)的真實數據,比如說某個待檢測樣本的均值、方差、中位數、相關系數等alpha: 置信水平,默認值為0.05Fun:1,進行自助法抽樣,返回一個包含n_bootstrap次抽樣結果的列表;每次抽樣計算一個統計量,此處命名為X,可以是均值、方差、中位數、相關系數等,比如說bootstrap_of_median函數,此處統一使用“X”指代2,利用百分位數法構造該參數X(比如說上面X指代median中位數)的置信區間;比如說置信水平為α,則使用(1-α/2)的百分位數和α/2的百分位數來構造置信區間,即α*100/2%和(1-α/2)*100%分位數;3,返回置信區間的下限和上限;4,順便我們可以判斷一下某個真實樣本的參數數據(真實數據)是否在置信區間內,即是否顯著,即real_param_to_test是否在置信區間內;"""import numpy as npfrom scipy import stats# 注意下面都是以X代稱需要估計的統計量bootstrap_X = [] # 存儲自助法抽樣獲取的多次抽樣結果,比如說是bootstrap_medianfor i in range(n_bootstrap):bootstrap_sample = np.random.choice(sample,size=len(sample),replace=True)bootstrap_X.append(np.X(bootstrap_sample)) # np.X指代任何python實現中能夠計算指標X的api函數,比如說均值用np.mean,中位數用np.median等ci_lower = np.percentile(bootstrap_X, alpha * 100 / 2) # 置信區間下限ci_upper = np.percentile(bootstrap_X, (1 - alpha / 2) * 100) # 置信區間上限# 下面是判斷真實數據是否在置信區間內,即是否顯著 is_significant = not (ci_lower <= real_param_to_test <= ci_upper)# 或者我們也可以使用# result = False if ci_lower <= observation_param <= ci_upper else Truereturn ci_lower, ci_upper, is_significant# 也可以return result如果是在一個真實的機器學習例子中:
假設我們有樣本數據X和標簽y,以scikit-learn的分類器為例:
import numpy as np
from sklearn.base import clone
from sklearn.metrics import accuracy_scoredef bootstrap_632(X, y, model, metric=accuracy_score, n_iterations=100):'''.632自助法評估模型性能參數:X, y : 原始樣本和標簽, X為(n_samples, n_features)的ndarray,y為(n_samples,)的ndarraymodel : 已實現fit/predict接口的sklearn模型metric : 性能度量函數,如accuracy_score等n_iterations : 自助法抽樣次數返回:.632自助法估計的得分'''n_samples = X.shape[0]scores_in = [] # 訓練集分數scores_out = [] # 留出(測試集)分數for _ in range(n_iterations):# 有放回隨機采樣訓練集索引train_idx = np.random.choice(n_samples, size=n_samples, replace=True)# 檢驗集為未被選中的樣本test_idx = np.setdiff1d(np.arange(n_samples), train_idx)model_ = clone(model)model_.fit(X[train_idx], y[train_idx])# 訓練集得分score_in = metric(y[train_idx], model_.predict(X[train_idx]))scores_in.append(score_in)# 檢驗集得分if len(test_idx) > 0:score_out = metric(y[test_idx], model_.predict(X[test_idx]))else:# 若某次抽樣所有樣本都被抽中,則檢驗集為空,跳過score_out = np.nanscores_out.append(score_out)# 取所有非nan的測試集分數平均scores_out = np.array(scores_out)mean_score_in = np.nanmean(scores_in)mean_score_out = np.nanmean(scores_out)# .632法則組合訓練集與檢驗集得分final_score = 0.368 * mean_score_in + 0.632 * mean_score_outreturn final_score# 使用示例
if __name__ == "__main__":from sklearn.datasets import load_irisfrom sklearn.tree import DecisionTreeClassifierX, y = load_iris(return_X_y=True)model = DecisionTreeClassifier(random_state=42)score = bootstrap_632(X, y, model, metric=accuracy_score, n_iterations=300)print(".632自助法評估得分:", score)訓練集樣本有重復,檢驗集為未被采樣的樣本。
每次實驗如檢驗集為空,則該次得分記為NaN,整體均值時跳過。
.632法則最終得分為:
final_score = 0.368 × 訓練集得分均值 + 0.632 × 檢驗集得分均值
metrics可更換為需要的其它評估指標。
參考:
https://en.wikipedia.org/wiki/Bootstrapping_(statistics)
http://taggedwiki.zubiaga.org/new_content/5c318780fb5bb20ff852e11a72b52b5f
https://www.math.pku.edu.cn/teachers/lidf/docs/statcomp/html/_statcompbook/sim-bootstrap.html








---1)
 1)









