大家好!我是我不是小upper~
今天咱們來聊聊數據增強 —— 這個在機器學習領域堪稱 “數據魔法” 的實用技術!
在深度學習的世界里,數據就像模型的 “養分”。數據的質量和數量,直接決定了模型最終能達到的 “高度”。當數據不足時,模型很容易陷入 “學不透徹” 的困境,甚至出現嚴重的過擬合問題,就像只背答案卻不理解原理的學生,換道題就不會做了。而數據增強,正是解決這一難題的關鍵 —— 它能以巧妙的方式 “擴充” 數據集,讓模型在有限的數據基礎上,也能獲得更豐富的學習素材。
打個形象的比方:如果想讓小朋友真正認識 “貓”,只給他看一張照片顯然不夠。這張照片里的貓或許是橘色的,正趴在陽光下,角度也很固定。這樣一來,小朋友可能會誤以為 “貓都是橘色、趴著且在陽光下的樣子”。但如果給他展示不同角度、毛色、姿態的貓,再搭配昏暗、明亮等各種光線條件下的照片,他就能快速掌握 “貓” 這個概念的本質特征。
數據增強的核心思路,就藏在這個簡單的例子里:通過對原始數據進行多樣化的變換,人為創造出更多具有差異性的樣本,讓模型在學習過程中接觸到更廣泛的 “數據變化”。這樣一來,模型不僅能記住數據表面的特征,還能挖掘出內在規律,從而提升泛化能力,在面對新數據時表現得更加穩健!
在機器學習與深度學習領域,數據增強已成為提升模型性能的關鍵技術之一。接下來,我們將從作用、常見方法、原理詳解三個維度,深入剖析數據增強技術,結合具體案例與公式,幫助大家全面理解其背后的邏輯。
一、數據增強的核心作用
1. 有效增加數據量
在實際項目中,收集大規模高質量的原始數據往往面臨成本高、難度大等問題。數據增強技術通過對原始數據進行各種變換操作,能從有限的樣本中擴展出大量新樣本。例如,對于僅有 100 張圖片的圖像數據集,通過水平翻轉、旋轉等增強操作,可將數據集擴充至數百甚至上千張,極大緩解數據稀缺問題。
2. 顯著提高模型泛化能力
模型的泛化能力指的是在面對未見過的數據時,模型依然能保持良好的預測效果。數據增強通過人為引入數據的多樣性,讓模型接觸到更多不同形態的數據樣本。例如,在圖像識別任務中,對訓練圖像進行亮度、對比度調整,模型能學習到圖像在不同光照條件下的特征,從而在測試階段遇到類似變化的圖像時,也能準確識別。
3. 大幅減少過擬合風險
過擬合是指模型在訓練數據上表現優異,但在測試數據上卻表現不佳,即模型過度 “記憶” 了訓練數據的特征,而未學習到數據的通用規律。數據增強通過增加數據的多樣性,迫使模型學習更具普適性的特征,避免模型 “死記硬背” 訓練數據。例如,在文本分類任務中,對文本進行同義詞替換、語序調整等增強操作,能使模型學習到文本的語義本質,而非僅僅記住特定的詞語組合。
二、常見的數據增強方法
數據增強方法會根據數據類型的不同而有所差異,下面我們分別介紹圖像、文本和音頻數據的常用增強方法。
1. 圖像數據增強方法
- 翻轉操作:包括水平翻轉和垂直翻轉。例如,將一張貓的圖片進行水平翻轉,得到一張新的貓的圖片,貓的朝向發生了變化,但依然屬于貓這個類別。
- 幾何變換:
- 旋轉:將圖像圍繞中心旋轉一定角度,如 90°、180° 等。
- 縮放:對圖像進行放大或縮小操作,可分為等比例縮放和非等比例縮放。
- 平移:將圖像在水平或垂直方向上進行移動,模擬圖像在不同位置的場景。
- 裁剪與添加噪聲:
- 裁剪:從圖像中裁剪出部分區域作為新樣本,包括隨機裁剪和中心裁剪等方式。
- 加噪聲:向圖像中添加高斯噪聲、椒鹽噪聲等,模擬圖像在實際采集過程中受到的干擾。
- 顏色調整:
- 調整亮度和對比度:通過改變圖像的亮度和對比度,使圖像變亮、變暗或增強色彩鮮明度。
- 顏色擾動:對圖像的色調、飽和度和明度進行隨機調整,豐富圖像的顏色表現。
- 仿射變換:包括平移、旋轉、縮放和錯切等組合變換,通過矩陣運算實現對圖像的線性變換,保持圖像的幾何結構關系。
2. 文本數據增強方法
- 同義詞替換:在句子中找到合適的詞語,用其同義詞進行替換。例如,將 “今天天氣很好” 替換為 “今天天氣很棒”,句子語義基本不變,但詞語表達發生了變化。
- 隨機插入或刪除詞語:
- 插入:在句子中隨機插入一些無關緊要的詞語,如 “的”“了”“在” 等,增加文本的多樣性。
- 刪除:隨機刪除句子中的某些詞語,測試模型對信息缺失的魯棒性。
- 改變句子結構:通過調整句子的語序、使用不同的句式(如主動句變被動句)等方式,在保持語義的前提下改變文本的表達方式。例如,“我吃了蘋果” 改為 “蘋果被我吃了” 。
3. 音頻數據增強方法
- 改變語速或音調:
- 改變語速:加快或減慢音頻的播放速度,使音頻時長發生變化,同時語音頻率也相應改變。
- 改變音調:調整音頻的音高,使聲音變高或變低,模擬不同人說話的音調差異。
- 添加背景噪聲:向音頻中混入各種背景噪聲,如嘈雜的人聲、風聲、機器聲等,模擬音頻在實際環境中的采集情況。
- 剪切、拼接音頻段:
- 剪切:從音頻中截取部分片段作為新樣本,可用于模擬音頻的局部內容。
- 拼接:將不同的音頻片段組合在一起,創造出新的音頻樣本,如將兩段不同的音樂片段拼接成一段新的音樂。
三、原理詳解
1. 學習任務的基本數學建模
在監督學習中,模型的目標是從給定的數據集中學習一個映射函數?,其中:
?表示輸入空間,可以是圖像、文本、音頻等不同類型的數據。
?表示輸出空間,通常為分類標簽(如 “貓”“狗”)或回歸值(如預測的房價數值)。
訓練集由?n?個樣本組成,表示為:
,
其中??是輸入樣本,
?是對應的標簽。
模型的學習目標是通過最小化期望風險(Expected Risk)?來優化自身參數,期望風險的定義為:
其中,L?是損失函數,用于衡量模型預測值??與真實標簽?y?之間的差異;
?是數據的真實分布。
然而,在實際應用中,數據的真實分布??往往是未知的,因此通常使用經驗風險(Empirical Risk)?
?來替代期望風險,經驗風險的計算公式為:
?
即通過計算訓練集中所有樣本的損失函數平均值,來近似模型在真實數據上的表現。
2. 數據增強的引入:數學視角
數據增強的核心思想是構造一個增強變換?T,對原始數據進行變換,同時保持標簽不變或遵循一定的變換規則。以圖像分類任務為例,對于原始圖像樣本?x?及其標簽?y,數據增強后的樣本表示為?,且標簽仍為?y,即:
從數學角度看,數據增強可以理解為構造一個新的數據分布?,以模擬原始分布?
?的變化形式。新的數據分布可表示為:
?其中:
?是增強變換的集合,包含各種數據增強操作(如旋轉、裁剪等)。
?是對變換的采樣分布,通常采用均勻分布或高斯分布,表示從增強變換集合中選擇某種變換的概率。
?是狄拉克函數,用于確保增強后的樣本?
?與其對應的標簽?
?保持一致性。
這一過程體現了 “局部平滑假設”:在局部區域內,對數據進行小幅度的擾動(即增強變換)不應改變其標簽。例如,對一張貓的圖像進行小角度旋轉,圖像內容依然屬于 “貓” 這個類別,標簽保持不變。
3. 泛化誤差分析中的作用
數據增強的重要目標之一是提升模型的泛化能力,即降低模型在未知數據上的泛化誤差。泛化誤差定義為模型在真實分布上的期望風險與在訓練集上的經驗風險之差:
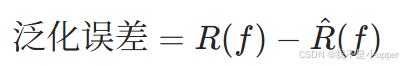
當數據增強被合理設計時,它可以從以下幾個方面降低泛化誤差:
- 增加樣本多樣性:通過引入更多不同形態的數據樣本,使模型能夠學習到更廣泛的數據特征,從而更好地適應真實數據分布。
- 增強模型魯棒性:讓模型對輸入空間的小擾動具有更強的適應性。例如,在圖像數據中添加噪聲進行增強,訓練后的模型在面對實際場景中帶有噪聲的圖像時,依然能夠準確識別。
- 促使模型學習平滑函數:數據增強促使模型在決策邊界附近學到更平滑的函數。例如,在分類任務中,通過對邊界附近的樣本進行增強,模型能夠更準確地區分不同類別,避免決策邊界過于復雜導致過擬合。
這些效果與機器學習中的穩定性理論密切相關。如果數據增強能夠使學習算法在對輸入進行小擾動時,輸出不發生顯著變化(即模型穩定),根據學習穩定性理論,模型的泛化誤差界將更小。
定義模型對輸入擾動的敏感度為:
其中,?是輸入?x?的擾動,
?是擾動的幅度限制。
數據增強的目標是通過設計合適的變換?T,使得敏感度??盡可能小,即:
這意味著數據增強促使學習算法具備更高的局部一致性,在輸入發生小幅度變化時,模型輸出保持穩定,從而有效降低泛化誤差,提升模型的泛化能力。
四、完整案例
這里,咱們以 PyTorch 框架為基礎,結合 CIFAR-10 圖像分類任務,全面展示數據增強的實際應用
包括:
-
多種圖像增強方法的組合與實現
-
增強前后圖像的可視化對比
-
模型訓練過程中的性能對比分析
-
算法優化建議與實驗結果
代碼實現
包括數據加載、增強、可視化、模型訓練與評估等步驟。
1. 導入必要的庫
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import time這里導入了 PyTorch 及其視覺庫?torchvision?用于數據處理和模型搭建;matplotlib?和?seaborn?用于可視化;numpy?處理數組;time?用于計算訓練耗時。?
2. 設置設備?
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}") 這里導入了 PyTorch 及其視覺庫?torchvision?用于數據處理和模型搭建;matplotlib?和?seaborn?用于可視化;numpy?處理數組;time?用于計算訓練耗時。
3. 定義數據增強策略
# 訓練集增強
train_transform = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomRotation(15),transforms.RandomCrop(32, padding=4),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])# 測試集不進行增強
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])- 訓練集增強:
RandomHorizontalFlip():以 50% 的概率水平翻轉圖像,模擬同一物體的左右視角差異。例如,將一張面向左側的汽車圖像翻轉后,變為面向右側,讓模型學習物體的對稱性。RandomRotation(15):在 -15° 到 15° 之間隨機旋轉圖像,模擬拍攝時角度的微小偏差,增強模型對旋轉的魯棒性。RandomCrop(32, padding=4):先在圖像邊緣填充 4 個像素,再隨機裁剪出 32×32 的區域。這模擬了拍攝時物體在畫面中的不同位置,讓模型學會識別部分遮擋的物體。ColorJitter(...):隨機調整圖像的亮度、對比度、飽和度和色調,模擬不同光照條件和色彩風格。例如,將明亮的圖像變暗,或將鮮艷的顏色調淡,訓練模型適應復雜的光照環境。ToTensor():將 PIL 圖像轉換為 PyTorch 張量,并將像素值歸一化到 [0, 1]。Normalize((0.5,), (0.5,)):對圖像進行標準化,將像素值調整為均值 0、標準差 1,加速模型訓練時的收斂速度。
- 測試集不增強:僅進行張量轉換和標準化,確保測試數據與真實場景一致,避免人為引入偏差。
4. 加載數據集
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=test_transform)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=128, shuffle=False)從本地或遠程下載 CIFAR-10 數據集,分別構建訓練集和測試集,并使用?DataLoader?按批次加載數據。訓練集打亂數據順序(shuffle=True),幫助模型學習更具泛化性的特征;測試集保持順序不變,確保評估結果的一致性。
5. 可視化增強前后的圖像
# 獲取一批圖像
dataiter = iter(train_loader)
images, labels = next(dataiter)# 定義類別標簽
classes = ('plane', 'car', 'bird', 'cat', 'deer','dog', 'frog', 'horse','ship', 'truck')# 顯示圖像
def imshow(img):img = img / 2 + 0.5 # 反標準化npimg = img.numpy()plt.figure(figsize=(10, 4))plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.title("Augmented Images")plt.axis('off')plt.show()# 顯示前16張圖像
imshow(torchvision.utils.make_grid(images[:16]))
上述代碼是隨機選取了一批訓練圖像,通過?imshow?函數將張量轉換回圖像格式并可視化。觀察增強后的圖像,你會發現同一類別的圖像呈現出豐富的變化,如顏色、角度和位置差異,這為模型提供了更多學習樣本。?
6. 定義卷積神經網絡
import torch.nn as nn
import torch.nn.functional as Fclass SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3, padding=1) # 輸入通道數3,輸出通道數32,卷積核大小3self.pool = nn.MaxPool2d(2, 2) # 池化層,窗口大小2self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.fc1 = nn.Linear(64 * 8 * 8, 512) # 全連接層self.fc2 = nn.Linear(512, 10) # 輸出層,10個類別def forward(self, x):x = self.pool(F.relu(self.conv1(x))) # 卷積 -> ReLU -> 池化x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 64 * 8 * 8) # 展平x = F.relu(self.fc1(x))x = self.fc2(x)return x- 卷積層:
conv1?和?conv2?通過卷積操作提取圖像的局部特征,增加通道數以捕捉更復雜的信息。 - 池化層:
pool?采用最大池化,降低圖像尺寸,減少計算量,同時保留主要特征。 - 全連接層:
fc1?和?fc2?將卷積層輸出的特征向量映射到 10 個類別,輸出最終的分類結果。
7. 訓練模型
net = SimpleCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)num_epochs = 10
train_losses = []
test_losses = []
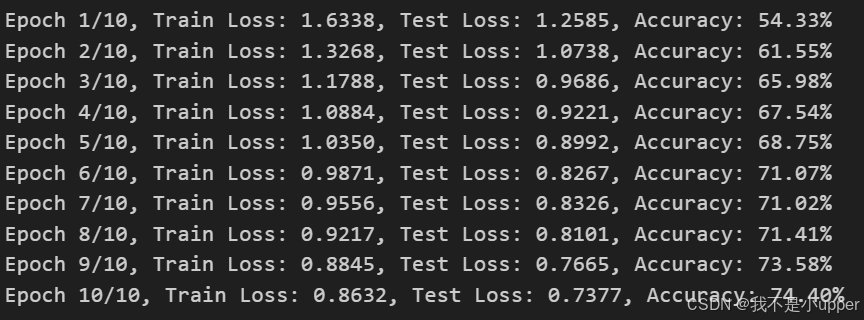
test_accuracies = []for epoch in range(num_epochs):net.train()running_loss = 0.0for inputs, labels in train_loader:inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()train_losses.append(running_loss / len(train_loader))# 測試集評估net.eval()correct = 0total = 0test_loss = 0.0with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = net(inputs)loss = criterion(outputs, labels)test_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()test_losses.append(test_loss / len(test_loader))accuracy = 100 * correct / totaltest_accuracies.append(accuracy)print(f"Epoch {epoch+1}/{num_epochs}, "f"Train Loss: {train_losses[-1]:.4f}, "f"Test Loss: {test_losses[-1]:.4f}, "f"Accuracy: {accuracy:.2f}%")- 初始化模型、損失函數和優化器:使用?
CrossEntropyLoss?計算分類損失,Adam?優化器更新模型參數。 - 訓練循環:每個 epoch 中,模型在訓練集上進行前向傳播、計算損失、反向傳播更新參數,并記錄訓練損失;在測試集上評估模型性能,計算測試損失和準確率。
8. 繪制訓練過程圖表
epochs = range(1, num_epochs + 1)plt.figure(figsize=(12, 5))# 繪制損失曲線
plt.subplot(1, 2, 1)
plt.plot(epochs, train_losses, 'bo-', label='Train Loss')
plt.plot(epochs, test_losses, 'ro-', label='Test Loss')
plt.title('Loss over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()# 繪制準確率曲線
plt.subplot(1, 2, 2)
plt.plot(epochs, test_accuracies, 'go-', label='Test Accuracy')
plt.title('Test Accuracy over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()plt.tight_layout()
plt.show()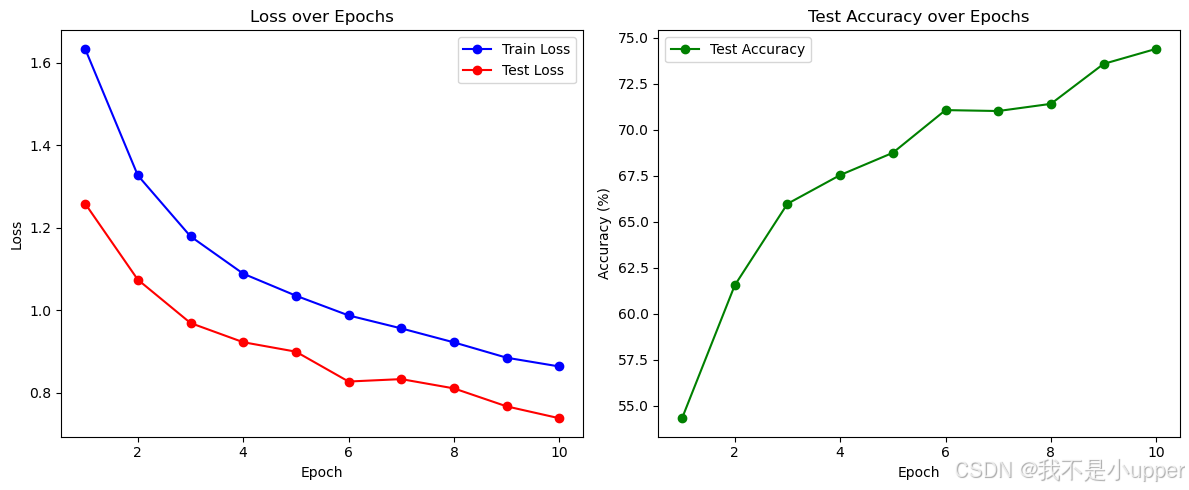
通過可視化訓練和測試損失、測試準確率隨 epoch 的變化,直觀展示模型的學習過程和性能提升效果。
結果與分析
1. 數據增強策略解讀
- 提升數據多樣性:通過水平翻轉、旋轉、裁剪和顏色調整,訓練集圖像呈現出豐富的變化,模擬了現實場景中物體的不同姿態、光照和位置。
- 降低過擬合風險:增強后的數據迫使模型學習更通用的特征,避免記憶訓練數據的細節,從而提高泛化能力。
2. 模型結構解析
SimpleCNN 雖然結構簡單,但通過卷積層提取圖像特征,池化層降維,全連接層分類,在 CIFAR-10 數據集上已能取得較好的效果。結合數據增強,模型性能進一步提升。
3. 訓練結果分析
觀察繪制的圖表,你會發現:
- 損失曲線:訓練損失逐漸下降,測試損失也隨之降低,且兩者差距較小,說明模型未出現嚴重過擬合。
- 準確率曲線:測試準確率隨訓練進行穩步提升,最終達到較高水平,驗證了數據增強對模型泛化能力的積極作用。
數據增強策略深度解析
- RandomHorizontalFlip():該策略以 50% 的概率對圖像進行水平翻轉操作,模擬現實中物體左右視角的變化情況。比如在行人檢測任務中,行人可能從左側或右側進入畫面,通過水平翻轉,能讓模型學習到同一物體不同方向的特征,避免因只見過單一方向的圖像而產生識別偏差。
- RandomRotation(15):此策略會在 [-15°, 15°] 的角度范圍內對圖像進行隨機旋轉。在實際場景中,拍攝角度不可能完全一致,這種旋轉操作能夠增強模型對物體不同傾斜角度的識別能力。例如在車牌識別任務里,車輛停放角度的不同可能導致車牌出現一定程度的傾斜,經過旋轉增強的訓練數據,能讓模型更好地適應此類情況,提升旋轉魯棒性。
- RandomCrop(32, padding=4):首先在圖像邊緣填充 4 個像素,然后隨機裁剪出 32x32 的區域。這一操作模擬了拍攝時物體在畫面中位置的偏移,也模擬了部分遮擋的情況。在花卉識別任務中,花朵可能不會始終處于畫面正中間,通過隨機裁剪,模型可以學習到不同位置和部分遮擋下花卉的特征,提高對復雜場景的適應能力。
- ColorJitter(...):該策略可以隨機調整圖像的亮度、對比度、飽和度和色調,能夠模擬不同光照條件和色彩風格。比如在街景識別中,白天和夜晚的光照差異巨大,陰天和晴天的色彩風格也不同,通過顏色擾動,模型能夠學習到在各種光照和色彩變化下物體的特征,增強對光照變化的適應能力。
- ToTensor():將 PIL 格式的圖像轉換為 Tensor 格式,同時把像素值歸一化到 [0,1] 區間。這是深度學習框架處理圖像數據的標準格式轉換,歸一化操作能使數據分布更符合模型訓練的要求,方便后續的計算和處理。
- Normalize((0.5,), (0.5,)):對圖像進行標準化處理,使得圖像的均值為 0,標準差為 1。在模型訓練過程中,標準化后的數據能夠讓梯度更新更加穩定,加速模型的收斂速度,減少訓練所需的時間和計算資源。
模型結構深度剖析
SimpleCNN 模型采用經典的卷積神經網絡架構,由兩個卷積層和兩個全連接層構成,這種簡潔的結構非常適合像 CIFAR - 10 這樣的基礎圖像分類任務。
- conv1:作為模型的第一層卷積層,它的輸入通道數為 3,對應彩色圖像的 RGB 三個通道。輸出通道數為 32,意味著經過卷積操作后,會提取出 32 種不同的圖像特征。卷積核大小為 3x3,使用填充(padding)操作保持圖像尺寸不變,這樣可以保證在提取特征的過程中,圖像邊緣的信息不會丟失,讓模型能夠充分利用圖像的所有信息。
- pool:最大池化層的窗口大小為 2x2,它的主要作用是對卷積層輸出的特征圖進行下采樣。通過選取每個 2x2 區域內的最大值,不僅可以降低數據維度,減少計算量,還能突出圖像中最顯著的特征,提高模型的計算效率和特征表達能力。
- conv2:第二層卷積層的輸入通道數為 32,即上一層卷積層輸出的特征圖數量。輸出通道數增加到 64,進一步提取更復雜、更抽象的圖像特征。同樣采用 3x3 的卷積核,繼續對圖像進行特征提取和變換。
- fc1(全連接層 1):該層接收上層經過卷積和池化操作后展平的向量,其維度為 64×8×8。通過全連接操作,將這些特征映射到 512 維的特征空間中。同時使用 ReLU 激活函數,它能夠引入非線性因素,打破數據之間的線性關系,讓模型學習到更復雜的函數映射,提高模型的表達能力。
- fc2(全連接層 2):作為模型的最后一層,它將上一層輸出的 512 維特征向量映射到 10 個類別的得分(logits)。這 10 個得分將作為 softmax 函數的輸入,softmax 函數會將這些得分轉換為屬于每個類別的概率,從而實現圖像的分類任務。
雖然 SimpleCNN 網絡結構相對簡單,但通過合理的數據增強策略與之配合,在 CIFAR - 10 數據集上能夠獲得較為理想的分類效果,是初學者學習卷積神經網絡和數據增強技術的絕佳范例。
總結
在圖像領域的深度學習任務中,數據增強已經成為不可或缺的關鍵預處理步驟。它通過對原始訓練數據進行多樣化的變換操作,極大地豐富了數據的多樣性。這種多樣性能夠讓模型接觸到更多不同形態的圖像數據,從而提升模型對各種圖像擾動的抵抗能力,即增強模型的魯棒性。
數據增強的另一個重要作用是有效緩解模型的過擬合問題。當訓練數據有限時,模型容易過度學習訓練數據中的特定特征,導致在測試數據上表現不佳。而數據增強通過擴充數據集,使模型能夠學習到更具普遍性的特征,增強模型的泛化能力,讓模型在面對未見過的數據時也能做出準確的預測。特別是在數據量不足或存在類別不平衡問題時,數據增強更是提升模型性能的關鍵手段,能夠顯著提高模型的準確性和穩定性,為深度學習模型的成功應用奠定堅實基礎。







---1)
 1)










