特征降維------特征組合(以SVD為例)
知識點回顧:
奇異值的應用:
- 特征降維:對高維數據減小計算量、可視化
- 數據重構:比如重構信號、重構圖像(可以實現有損壓縮,k 越小壓縮率越高,但圖像質量損失越大)
- 降噪:通常噪聲對應較小的奇異值。通過丟棄這些小奇異值并重構矩陣,可以達到一定程度的降噪效果。
- 推薦系統:在協同過濾算法中,用戶-物品評分矩陣通常是稀疏且高維的。SVD (或其變種如 FunkSVD, SVD++) 可以用來分解這個矩陣,發現潛在因子 (latent factors),從而預測未評分的項。這里其實屬于特征降維的部分。
作業:嘗試利用svd來處理心臟病預測,看下精度變化
對于任何矩陣,均可做等價的奇異值SVD分解?A=UΣV?,對于分解后的矩陣,可以選取保留前K個奇異值及其對應的奇異向量,重構原始矩陣,可以通過計算Frobenius 范數相對誤差來衡量原始矩陣和重構矩陣的差異。
- U矩陣:描述行之間的關系,列向量來自AA?的特征向量,而AA?計算的是行之間的相似性(因為A的每一行代表一個樣本)
- Σ矩陣:告訴我們哪些模式最重要(奇異值越大越重要,是按降序排列的)
- V?矩陣:描述列之間的關系,列向量來自A?A的特征向量,而A?A計算的是列之間的相似性(因為A的每一列代表一個特征)
應用:結構化數據中,將原來的m個特征降維成k個新的特征,新特征是原始特征的線性組合,捕捉了數據的主要方差信息,降維后的數據可以直接用于機器學習模型(如分類、回歸),通常能提高計算效率并減少過擬合風險。
ps:在進行 SVD 之前,通常需要對數據進行標準化(均值為 0,方差為 1),以避免某些特征的量綱差異對降維結果的影響。
具體說說通過奇異值來降維,本質上通過數學變換創造新特征,這種方法是許多降維算法(如 PCA)和數據處理技術的基礎,具體三步搞定:
- 分解:對原始矩陣A做SVD得到?A?= UΣV?
- 篩選:選擇前k個奇異值(如何選k見下方規則)
- 固定數量法(最簡單):直接指定保留前k個(如k=10),適用于對數據維度有明確要求時
- 能量占比法(最常用):計算奇異值平方和(總能量),選擇使前k個奇異值平方和占比>閾值(如95%)
- 拐點法(可視化判斷):奇異值下降曲線明顯變平緩的點作為k
- 重構:用U的前k列、Σ的前k個值、V?的前k行重構近似矩陣?A??= U?Σ?V??
1.初步理解
下面用一個簡單的矩陣實現SVD降維
import numpy as np# 創建一個矩陣 A (5x3)
A = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9],[10, 11, 12],[13, 14, 15]])
print("原始矩陣 A:")
print(A)# 進行 SVD 分解
U, sigma, Vt = np.linalg.svd(A, full_matrices=False)
print("\n奇異值 sigma:")
print(sigma)# 保留前 k=1 個奇異值進行降維
k = 1
U_k = U[:, :k] # 取 U 的前 k 列,因為要保持行數不變
sigma_k = sigma[:k] # 取前 k 個奇異值
Vt_k = Vt[:k, :] # 取 Vt 的前 k 行,因為要保持列數不變# 近似重構矩陣 A,常用于信號or圖像篩除噪聲
A_approx = U_k @ np.diag(sigma_k) @ Vt_k
print("\n保留前", k, "個奇異值后的近似矩陣 A_approx:")
print(A_approx)# 計算近似誤差
error = np.linalg.norm(A - A_approx, 'fro') / np.linalg.norm(A, 'fro')
print("\n近似誤差 (Frobenius 范數相對誤差):", error)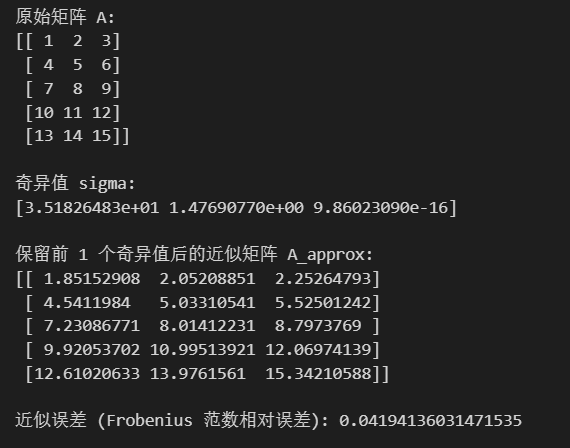
這里的Frobenius 范數相對誤差的計算方式有點難理解,舉一個更簡單的例子說明一下:

2.實際運用到數據集里
難點就是對于測試集要用訓練集相同的SVD分解規則,即相同的變換

import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 設置隨機種子以便結果可重復
np.random.seed(42)# 模擬數據:1000 個樣本,50 個特征
n_samples = 1000
n_features = 50
X = np.random.randn(n_samples, n_features) * 10 # 隨機生成特征數據
y = (X[:, 0] + X[:, 1] > 0).astype(int) # 模擬二分類標簽# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"訓練集形狀: {X_train.shape}")
print(f"測試集形狀: {X_test.shape}")# 對訓練集進行 SVD 分解
U_train, sigma_train, Vt_train = np.linalg.svd(X_train, full_matrices=False)
print(f"Vt_train 矩陣形狀: {Vt_train.shape}")# 選擇保留的奇異值數量 k
k = 10
Vt_k = Vt_train[:k, :] # 保留前 k 行,形狀為 (k, 50)
print(f"保留 k={k} 后的 Vt_k 矩陣形狀: {Vt_k.shape}")# 降維訓練集:X_train_reduced = X_train @ Vt_k.T
X_train_reduced = X_train @ Vt_k.T
print(f"降維后訓練集形狀: {X_train_reduced.shape}")# 使用相同的 Vt_k 對測試集進行降維:X_test_reduced = X_test @ Vt_k.T
X_test_reduced = X_test @ Vt_k.T
print(f"降維后測試集形狀: {X_test_reduced.shape}")# 訓練模型(以邏輯回歸為例)
model = LogisticRegression(random_state=42)
model.fit(X_train_reduced, y_train)# 預測并評估
y_pred = model.predict(X_test_reduced)
accuracy = accuracy_score(y_test, y_pred)
print(f"測試集準確率: {accuracy}")# 計算訓練集的近似誤差(可選,僅用于評估降維效果)
X_train_approx = U_train[:, :k] @ np.diag(sigma_train[:k]) @ Vt_k
error = np.linalg.norm(X_train - X_train_approx, 'fro') / np.linalg.norm(X_train, 'fro')
print(f"訓練集近似誤差 (Frobenius 范數相對誤差): {error}")
收獲心得:
SVD降維的難點就是數學關系以及維度轉換后是否正確,線性代數要學好啊,唉
@浙大疏錦行



![class path resource [] cannot be resolved to absolute file path](http://pic.xiahunao.cn/class path resource [] cannot be resolved to absolute file path)
、位圖的實現和布隆過濾器的介紹)

)

)





-多線程和多進程淺析)

)


