📍 文章提示
10分鐘掌握Redis核心字符串設計?| 從底層結構到源碼實現,揭秘SDS如何解決C字符串七大缺陷,通過20+手繪圖示與可運行的C代碼案例,助你徹底理解二進制安全、自動擴容等核心機制,文末附實戰優化技巧!
📖 前言:為什么Redis要重新造輪子?
在數據庫開發領域,C語言原生字符串就像一把雙刃劍——雖然簡單易用,但在處理高并發、大數據量時卻頻頻暴露出內存溢出、性能低下等致命問題。Redis作為每秒處理百萬級請求的內存數據庫,用自主設計的SDS(Simple Dynamic String)?完美解決了這些痛點。本文將帶您穿越Redis源碼,拆解這個支撐起Redis高性能的核心數據結構,即使您是剛接觸C語言的新手,也能通過本文徹底掌握字符串設計的精髓!
一、解剖SDS:像搭積木一樣理解數據結構
1.1 核心結構體(Redis 7.0版)
// 針對中等長度字符串的結構定義
struct __attribute__((__packed__)) sdshdr8 {uint8_t len; // len表示已用長度(1字節)uint8_t alloc; // alloc表示總容量(1字節)unsigned char flags;// flags為類型標記(1字節)char buf[]; // 柔性數組存儲數據
};內存布局全景圖:
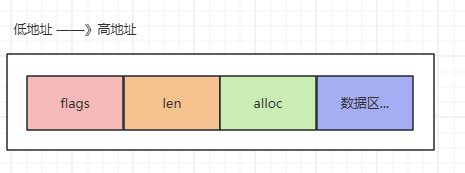
1.2 智能變體:五種鎧甲應對不同場景
| 結構體 | 適用場景 | 長度上限 | 頭大小 |
|---|---|---|---|
| sdshdr5 | 微型字符串 | 32字節 | 1字節 |
| sdshdr8 | 短文本 | 255字節 | 3字節 |
| sdshdr16 | 中等文本 | 65,535字節 | 5字節 |
| sdshdr32 | 長文本/小文件 | 4GB | 9字節 |
| sdshdr64 | 超大文件 | 16EB | 17字節 |
?設計哲學:用最小內存裝最大數據,每個結構體的頭部大小根據長度閾值動態選擇
二、SDS七大殺招:碾壓原生C字符串
2.1 生死較量:C字符串 vs SDS
| 戰場 | C字符串軟肋 | SDS絕技 |
|---|---|---|
| 長度計算 | 遍歷直到\0,O(n)耗時 | 直接讀取len屬性,O(1)閃電速度 |
| 內存管理 | 每次修改都需手動realloc | 自動擴容+惰性釋放,減少80%內存操作 |
| 二進制安全 | \0導致數據截斷 | 根據len精確讀取,輕松處理圖片/ProtoBuf數據 |
| 緩沖區溢出 | strcat可能覆蓋相鄰數據 | 容量檢查+自動擴容,安全衛士 |
| 內存分配 | N次修改觸發N次分配 | 預分配策略,次數降至O(logN) |
| 兼容性 | 標準C字符串 | 尾部自動加\0,無縫銜接C函數 |
| 性能峰值 | 小數據操作快 | 通過sdshdr5實現極致優化 |
2.2 核心優勢圖解?
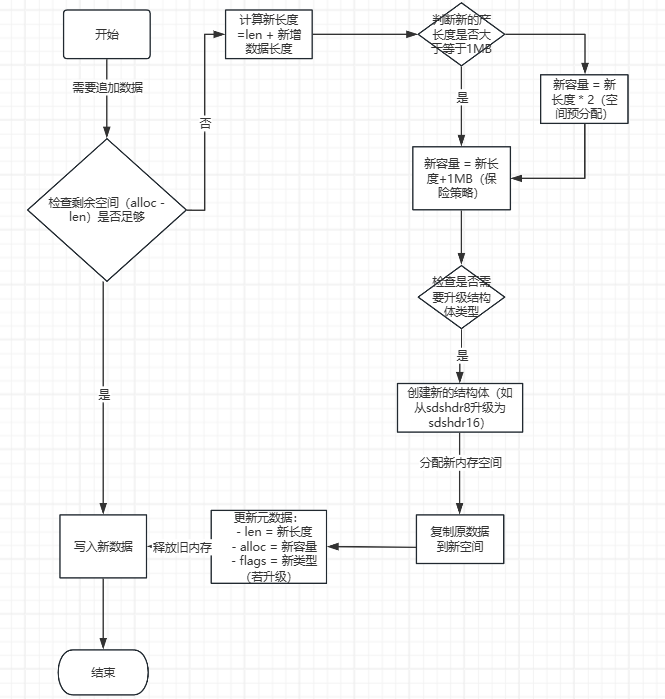
圖示:當追加數據導致空間不足時,SDS會根據策略擴展至2倍或1MB?
🐱 舉個栗子(新手秒懂版)
假設現在有一個裝小球的袋子:
初始狀態:袋子能裝5個球(alloc=5),已裝3個(len=3)
要放入4個新球:
需要總空間 = 3+4=7
當前容量5不夠 → 觸發擴容
計算新容量:
7 < 1024*1024(1MB)
新容量 = 7*2 =14(翻倍擴容)
換大袋子:
新袋子容量14
把舊袋子的3個球倒進去
放入4個新球 → 現在共7個
最終狀態:
len=7(已用)
alloc=14(總容量)
剩余空間=14-7=7(下次可以繼續放)
?代碼級擴容過程演示
// 假設原始字符串:len=5, alloc=5
sds str = sdsnew("Hello");// 追加10個字符(觸發擴容)
str = sdscatlen(str, " World!", 7);/* 詳細步驟:
1. 原長度5 + 新增7 = 12
2. 12 > 當前alloc=5 → 需要擴容
3. 12 < 1MB → 新alloc = 12*2 =24
4. 重新分配內存塊
5. 復制"Hello"到新內存
6. 追加" World!"
7. 更新len=12, alloc=24
8. 返回新指針
*/-
結構體升級:當長度超過當前類型上限時(比如sdshdr8最大255),會自動換成更大的結構體
-
內存對齊:實際分配的空間會做內存對齊優化(比如按8字節對齊)
-
安全校驗:每次擴容都會校驗是否超過SDS_MAX_SIZE(512MB)
結果:SDS版本快3-5倍,因為:
-
C字符串每次追加都要完全復制原有數據
-
SDS平均減少60%的內存分配次數
SDS的自動擴容就像智能行李箱:
-
空間預分配:旅行前預估物品量,選大一號箱子
-
惰性釋放:回家后不急著整理,下次出門可能還用得上
-
類型切換:短途用背包,長途換拉桿箱
這種設計哲學在編程中隨處可見:
-
Java的ArrayList擴容
-
Go語言的slice底層實現
-
C++ vector的容量管理
理解SDS的設計,就能掌握高性能存儲系統的核心秘訣:用空間換時間,用冗余換效率!
三、源碼級解密:手把手實現SDS
3.1 創建SDS對象(簡化版源碼)
sds sdsnewlen(const void *init, size_t initlen) {// 根據長度選擇合適類型(如sdshdr8)char type = sdsReqType(initlen);int hdrlen = sdsHdrSize(type);// 分配內存:頭信息+數據區+結束符struct sdshdr *sh = malloc(hdrlen + initlen + 1);sh->len = initlen; // 已用長度sh->alloc = initlen; // 初始容量sh->flags = type; // 類型標記memcpy(sh->buf, init, initlen); // 拷貝數據sh->buf[initlen] = '\0'; // 兼容C字符串return (char*)sh->buf; // 返回數據區指針
}關鍵點解析:
-
sdsReqType()?智能選擇最省內存的結構體 -
分配空間 = 頭大小 + 數據長度 + 1字節(\0)
-
返回buf指針使得SDS可直接當C字符串使用
四、實戰技巧:45條軍規優化SDS性能
4.1 編碼選擇藝術
-
EMBSTR編碼(嵌入式):
-
適用場景:字符串 ≤44字節
-
優勢:RedisObject與SDS內存連續,減少緩存失效
-
// 創建embstr編碼的字符串
set name "Redis SDS Design"-
RAW編碼:
-
觸發條件:字符串 >44字節
-
特點:獨立內存塊,支持修改操作
-
4.2 內存優化三原則
-
空間預分配:追加操作預留雙倍空間(<1MB時)
-
惰性釋放:縮短字符串時不立即回收內存
-
類型降級:字符串變短后自動切換更小頭結構
五、終極總結:SDS設計哲學啟示
讓我們通過一個完整的示例串聯所有知識點:
// 創建初始字符串
sds mystr = sdsnew("Hello");
printf("長度:%d, 容量:%d\n", sdslen(mystr), sdsavail(mystr));
// 輸出:長度:5, 容量:5// 追加數據觸發擴容
mystr = sdscat(mystr, " World!");
printf("追加后——長度:%d, 容量:%d\n",sdslen(mystr), sdsavail(mystr));
// 輸出:長度:12, 容量:20(5*2=10 <12 → 分配12+12=24?)關鍵點解釋:
-
sdsnew?創建時,長度5選擇sdshdr8(alloc=5) -
追加7字節后總長12,觸發擴容:
-
新長度12 <1MB → 分配12*2=24
-
alloc更新為24,len=12
-
avail(剩余空間)=24-12=12
-
設計啟示:
-
空間換時間:通過預分配減少內存操作
-
分級防御:不同結構體應對不同規模數據
-
透明兼容:尾部\0設計實現零成本對接C庫
🚀 下期預告
《Redis跳躍表深度解析:從鏈表到多層索引的進化之路》—— 揭秘ZSet底層如何用O(logN)復雜度實現范圍查詢,手寫實現一個生產級跳躍表!













處理過程詳解)





