SWiRL:數據合成、多步推理與工具使用
在大語言模型(LLMs)蓬勃發展的今天,其在復雜推理和工具使用任務上卻常遇瓶頸。本文提出的Step-Wise Reinforcement Learning(SWiRL)技術,為解決這些難題帶來曙光。它通過創新的合成數據生成和強化學習方法,顯著提升模型表現,快和我一同深入探究這項技術的奧秘吧!
論文標題
Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use
來源
arXiv:2504.04736v2 [cs.AI] + https://arxiv.org/abs/2504.04736
PS: 整理了LLM、量化投資、機器學習方向的學習資料,關注同名公眾號 「 亞里隨筆」 即刻免費解鎖
文章核心
研究背景
大語言模型(LLMs)在自然語言處理領域成果斐然,展現出強大的能力,像Gemini 2、Claude 3等模型不斷涌現,為該領域帶來諸多突破。然而,它們在處理復雜任務時卻面臨困境。當遇到需要多步推理和工具使用的任務,如多跳問答、數學解題、編碼等,LLMs往往表現不佳。同時,傳統的強化學習方法,像RLHF、RLAIF等,主要針對單步優化,難以應對多步任務中復雜的推理和工具調用需求。因此,如何提升LLMs在多步推理和工具使用方面的能力,成為當前亟待解決的問題 。
研究問題
-
傳統強化學習(RL)方法,如RLHF、RLAIF等,主要聚焦于單步優化,難以應對多步任務中復雜的推理和工具調用需求。
-
多步推理過程中,中間步驟的錯誤容易導致最終結果錯誤,如何保證模型在整個推理鏈條上的準確性,并有效從錯誤中恢復,是一大挑戰。
-
在多步任務中,模型需要學會合理分解問題、適時調用工具、準確構造工具調用指令等,現有方法在這些方面的指導和優化能力不足。
主要貢獻
1. 提出SWiRL方法:創新地提出了Step-Wise Reinforcement Learning(SWiRL),這是一種針對多步優化場景的合成數據生成和離線RL方法,有效提升模型在多步推理和工具使用任務中的能力。
2. 實現跨數據集泛化:SWiRL展現出強大的泛化能力,在不同的多跳問答和數學推理數據集上都取得了優異成績。例如,在HotPotQA數據集上訓練的SWiRL模型,在GSM8K數據集上的零樣本性能相對提升了16.9% 。
3. 分析數據過濾策略:深入分析了多步推理和工具使用場景中合成數據過濾策略的影響,發現基于過程過濾的數據能讓模型學習效果最佳,且模型能從包含錯誤最終答案的軌跡中學習,這與傳統監督微調(SFT)方法不同。
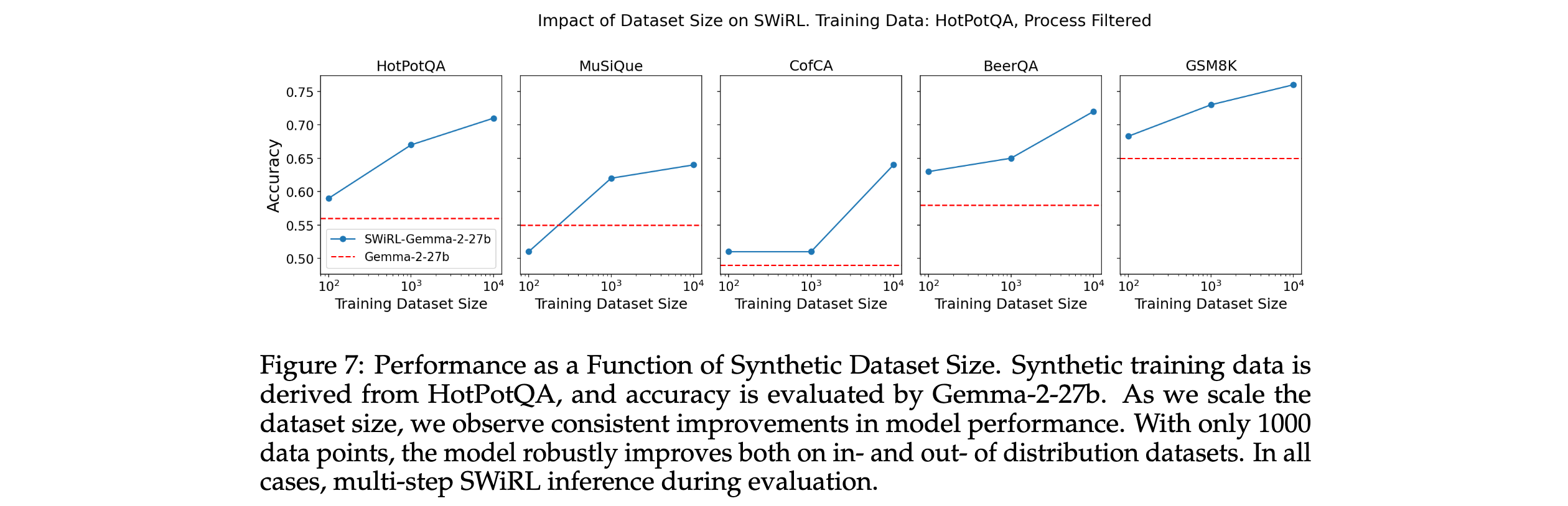
4. 探索模型和數據集規模影響:研究了訓練數據集大小和模型大小對SWiRL性能的影響,發現即使只有1000條軌跡也能顯著提升模型性能,且較大模型在SWiRL訓練下的泛化能力更強。
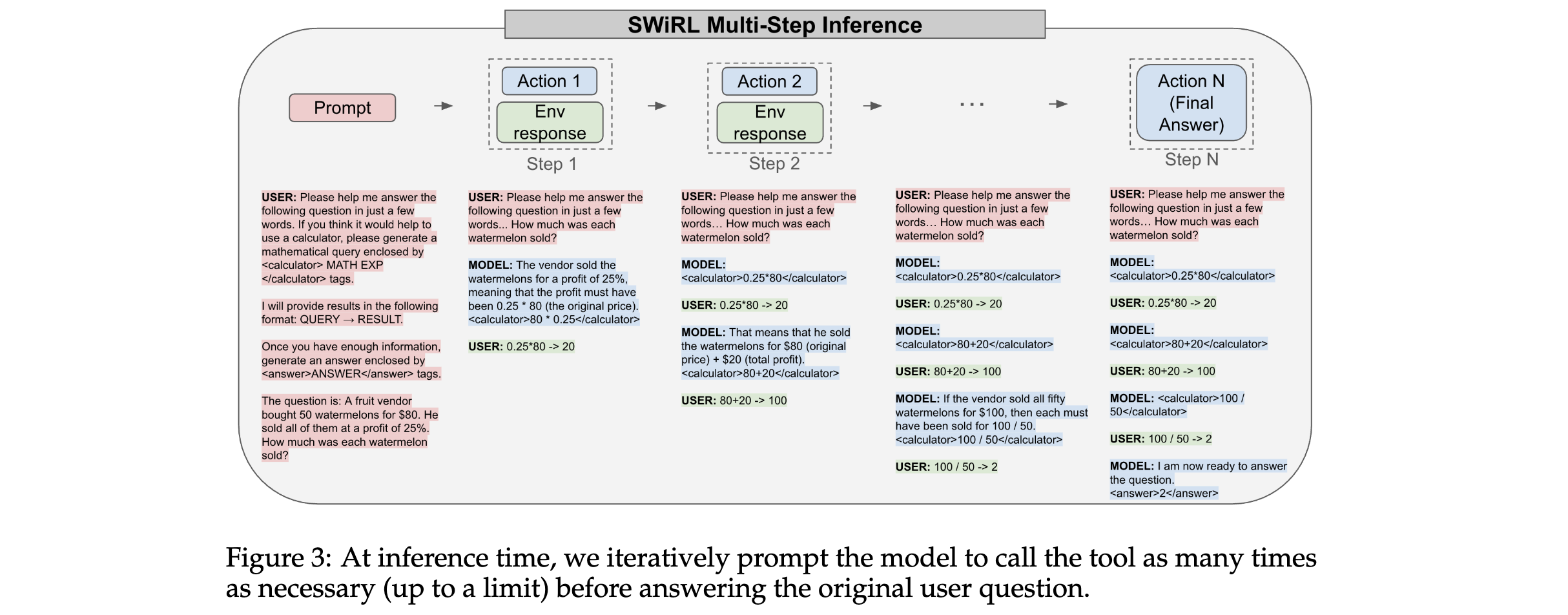
方法論精要
1. 核心算法/框架:SWiRL分為兩個階段。第一階段是合成數據生成與過濾,通過迭代提示模型生成多步推理和工1具使用的軌跡,并對其進行不同策略的過濾;第二階段是基于這些合成軌跡,使用逐步強化學習方法優化生成式基礎模型。
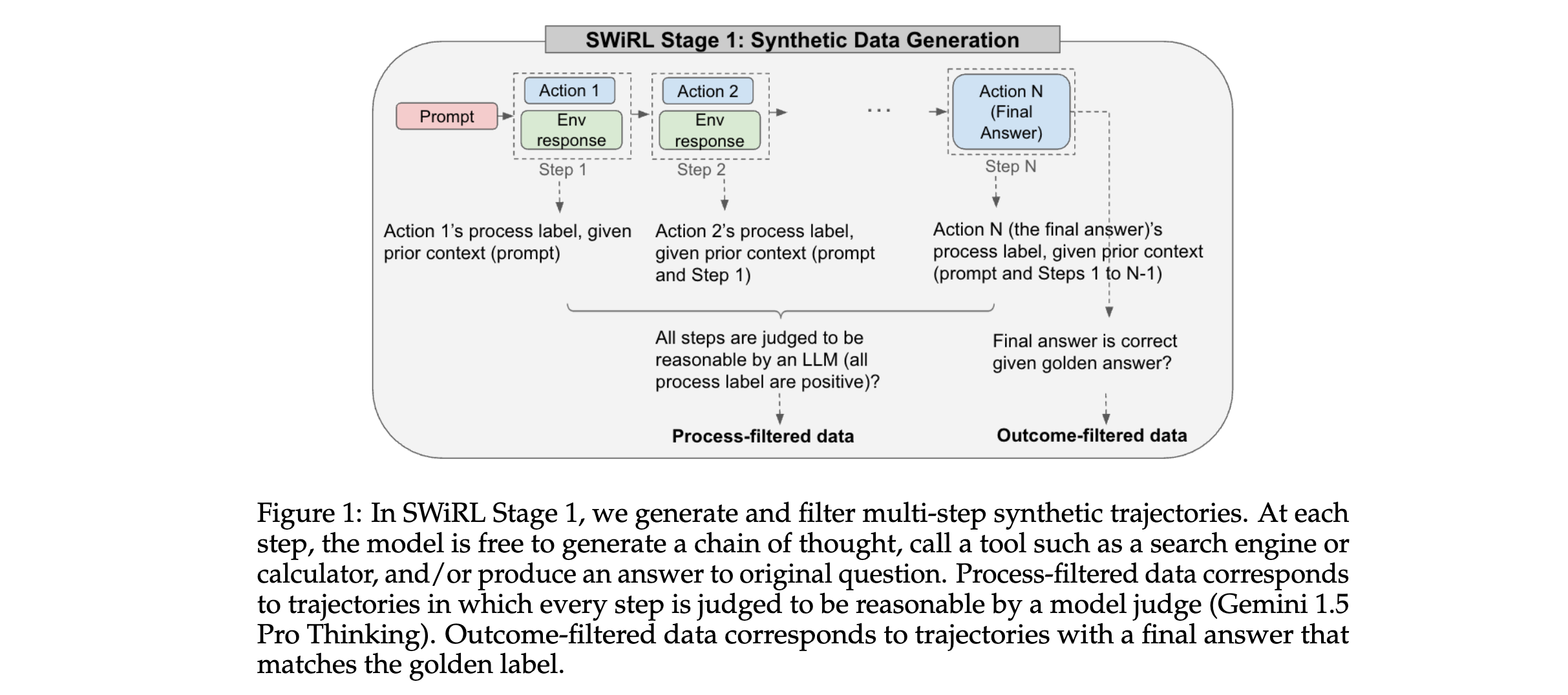
2. 關鍵參數設計原理:在逐步強化學習階段,目標函數是期望的逐步獎勵之和 J ( θ ) = E s ~ T , a ~ π θ ( s ) [ R ( a ∣ s ) ] J(\theta)=E_{s \sim T, a \sim \pi_{\theta}(s)}[R(a | s)] J(θ)=Es~T,a~πθ?(s)?[R(a∣s)] 。其中, π θ \pi_{\theta} πθ? 是由 θ \theta θ 參數化的基礎模型,通過SWiRL進行微調; T T T 表示合成多步軌跡中的所有狀態集合;獎勵信號 R ( a ∣ s ) R(a | s) R(a∣s) 由生成式獎勵模型(如Gemini 1.5 Pro)評估,根據給定上下文 s s s 下生成響應 a a a 的質量來確定。

3. 創新性技術組合:將合成數據生成、多步推理和工具使用相結合,通過迭代生成多步軌跡并轉換為多個子軌跡,在子軌跡上進行合成數據過濾和RL優化。這種方法能夠在每一步推理后給予模型直接反饋,使模型學習更具上下文感知能力。
4. 實驗驗證方式:選擇了五個具有挑戰性的多跳問答和數學推理數據集,包括HotPotQA、MuSiQue、CofCA、BeerQA和GSM8K。基線方法選取了當前一些先進的語言模型,如GPT-4、GPT-3.5、Gemini 1.0 Pro等。通過對比在這些數據集上的性能,評估SWiRL的有效性。
實驗洞察
在實驗環節,研究團隊對SWiRL展開了多維度探究,獲得了一系列關鍵發現。
1. 性能優勢:SWiRL在多個復雜任務數據集上表現卓越。在GSM8K數學推理數據集上,相比基線方法,其相對準確率提升21.5%;HotPotQA多跳問答數據集提升12.3%;CofCA數據集提升14.8%;MuSiQue數據集提升11.1%;BeerQA數據集提升15.3%。這表明SWiRL能顯著增強模型在多步推理和工具使用任務中的表現,遠超傳統方法。
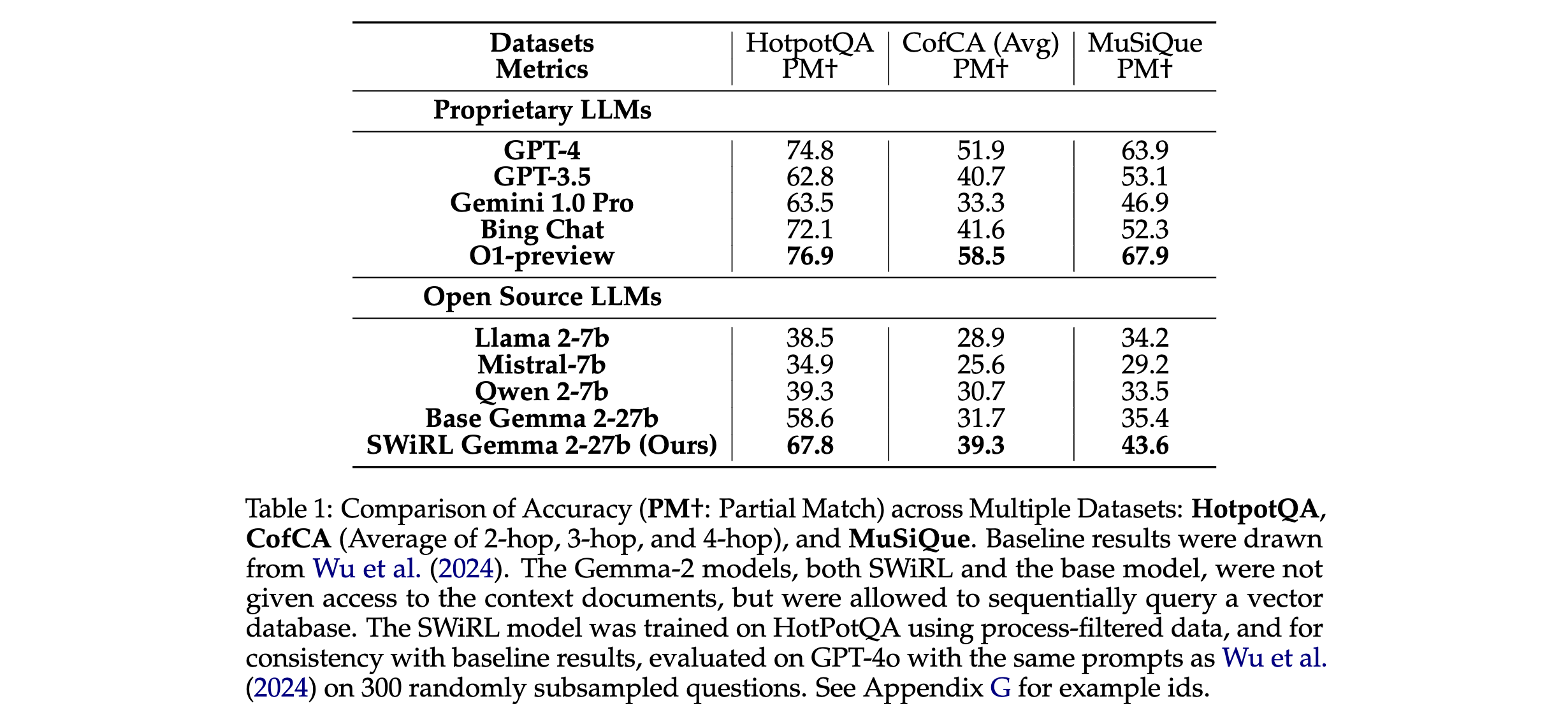
2. 泛化能力驗證:SWiRL展現出良好的跨任務泛化性。在HotPotQA數據集訓練的模型,在GSM8K上零樣本性能相對提升16.9%;反之,在GSM8K訓練的模型,在HotPotQA上性能提升9.2%。這意味著SWiRL訓練的模型能將在某一任務中學到的多步推理和工具使用能力,有效遷移到其他不同類型任務中。
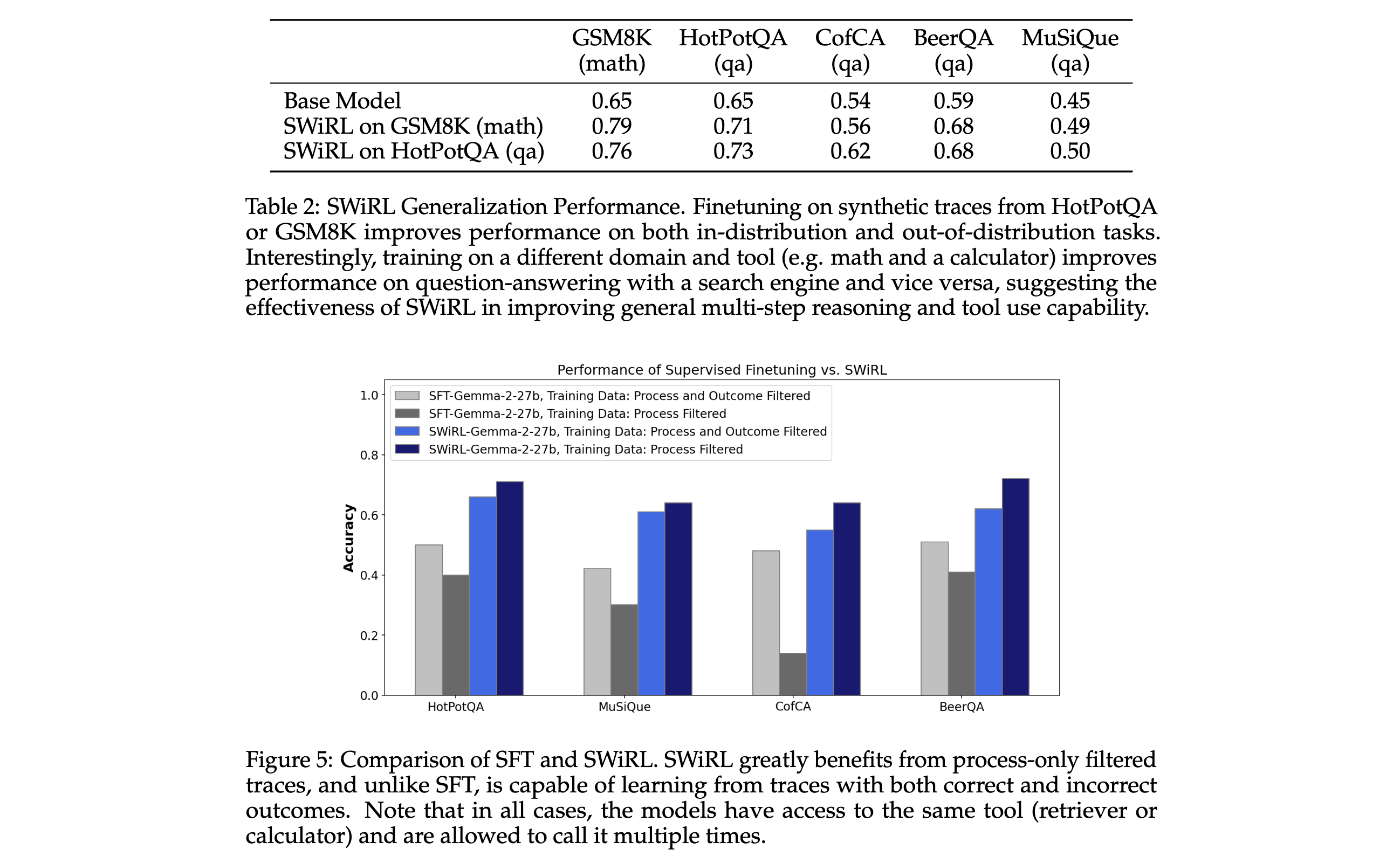
3. 數據過濾策略影響:通過對不同數據過濾策略的研究發現,僅進行過程過濾的數據能讓模型達到最佳性能。雖然傳統觀點認為基于結果正確性過濾數據能提升性能,但實驗表明,SWiRL從包含正確和錯誤最終答案的過程過濾數據中學習效果更好,而基于結果過濾的數據(除MuSiQue數據集外)反而降低了模型性能。
4. 數據集和模型大小的影響:實驗發現,增加訓練數據集規模能持續提升SWiRL模型性能。即使只有1000條軌跡,模型在多個數據集上也能取得顯著進步。此外,較大模型(如Gemma-2-27b)在SWiRL訓練下的泛化能力更強,而較小模型(Gemma-2-2b和9b)雖在域內有一定提升,但泛化能力相對較弱。











)





)

