作者:IvanCodes
日期:2025年5月7日
專欄:Hadoop教程
一、Hadoop 1.X 概述
(一)概念
Hadoop 是 Apache 開發的分布式系統基礎架構,用 Java 編寫,為集群處理大型數據集提供編程模型,是海量數據存儲與計算的開源框架。狹義指Hadoop軟件,廣義代表大數據生態。Hadoop 1.x 含兩大核心:MapReduce 和 HDFS。HDFS 負責分布式存儲,MapReduce 負責數據計算。
(二)特點


- 可擴展性:能處理PB級數據,通過增減節點靈活伸縮。
- 高容錯性:數據副本機制,部分節點故障不影響系統可用性。
- 成本效益:開源,運行于普通硬件,降低軟硬件成本。
- 高效性:MapReduce并行處理,計算向數據移動,減少網絡開銷。
- 靈活性:支持多種數據格式(結構化、半結構化、非結構化)。
- 可移植性:基于Java,可部署于多平臺(本地、云)。
- 社區支持:龐大活躍的開源社區,資源豐富。
- 生態豐富:圍繞Hadoop有眾多工具(Hive, Pig, HBase, Spark等)。
(三)工作原理
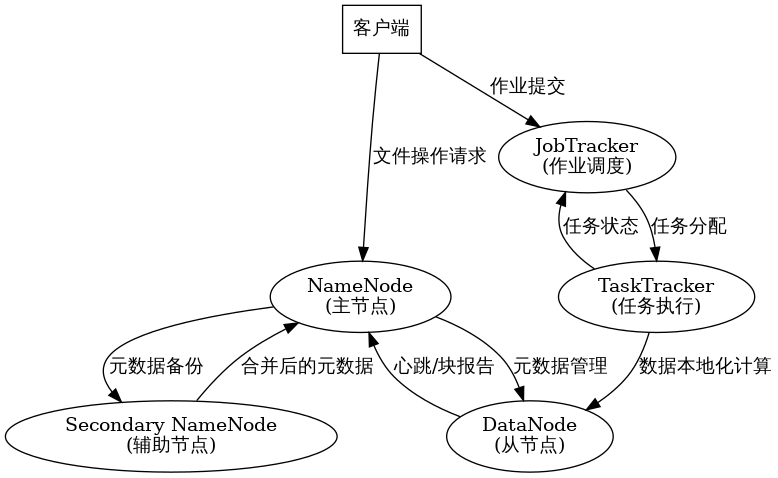
Hadoop 1.x 采用主從架構。核心進程包括:NameNode (HDFS主)、DataNode (HDFS從)、JobTracker (資源管理與作業調度)、TaskTracker (執行任務)。用戶提交作業后,JobTracker 調度并將任務分配給TaskTracker。數據存儲于HDFS,NameNode管理元數據,DataNode存儲實際數據塊。
(四)發展歷史

- 起源:源于Nutch搜索引擎項目擴展性需求。受Google的GFS和MapReduce論文啟發,Nutch開發者實現了HDFS和MapReduce,后剝離成Hadoop。
- 發展:2006年Apache Hadoop項目啟動,雅虎大力支持。 2008年成Apache頂級項目,Cloudera成立推動商業化。后續生態日漸繁榮,眾多公司開始應用。
二、Hadoop 1.X 核心組件
(一)HDFS
1. 概念
HDFS (Hadoop分布式文件系統)是Hadoop數據存儲的基礎。它高度容錯,運行于廉價硬件,通過流式數據訪問支持高吞吐量,適合大型數據集。
2. 特點
- 大文件存儲:適合TB、PB級大文件。
- 分塊存儲:大文件切塊(默認64M),多副本(默認3個)存不同機器,提高讀寫效率和容錯性。
- 流式訪問:“一次寫入,多次讀取”,不支持文件隨機修改,僅支持追加。
- 廉價硬件:可在普通PC搭建集群。
- 高容錯:副本機制確保節點故障時數據不丟失。
3. 工作原理
HDFS采用Master-Slave架構,含一個NameNode(主)和多個DataNode(從)。
- NameNode:管理文件系統命名空間(元數據:文件名、目錄、塊位置等),控制客戶端訪問。元數據存內存并持久化到磁盤(fsimage, edits log)。
- DataNode:實際存儲文件數據塊及校驗和。向NameNode注冊并周期性發送心跳和塊報告。
- Secondary Namenode:輔助NameNode,定期合并fsimage和edits log,減輕NameNode壓力,可能減少宕機時數據丟失。
4. 發展歷史
HDFS 的設計思想 深受 Google 的分布式文件系統 GFS 的啟發。如前所述,Nutch 項目的核心開發者 Doug Cutting 等人借鑒 GFS 的理念實現了 HDFS,并將其作為 Hadoop 不可或缺的一部分。在 Hadoop 的整個發展過程中,HDFS 也經歷了持續的改進和優化,以不斷提高其性能、可靠性和可擴展性。
(二)MapReduce
1. 概念
MapReduce是分布式計算框架,第一代離線數據計算引擎,處理TB、PB級數據。核心思想是計算分Map和Reduce兩階段。
2. 特點
- 分而治之:Map階段并行局部處理,Reduce階段并行全局匯總。
- 移動計算:計算程序移至數據節點,減少網絡I/O。
3. 工作原理
- 輸入切片:文件邏輯切片(InputSplit),每Split一Map Task。
- Map階段:Map Task處理輸入數據,輸出中間鍵值對。
- Shuffle階段:Map中間結果 復制、排序、分組到Reduce Task。
- Reduce階段:Reduce Task匯總相同key的中間值,輸出最終結果。
4. 發展歷史
MapReduce 的思想根源于 Google 在 2004年發表的著名論文《MapReduce: Simplified Data Processing on Large Clusters》。在 Hadoop 1.x 版本中,MapReduce 不僅承擔了分布式數據計算的核心角色,其內部的 JobTracker 組件還同時負責了集群的資源管理和作業調度。這種設計使得 MapReduce 框架顯得比較臃腫,并且限制了 Hadoop 集群只能運行 MapReduce 類型的任務。從 Hadoop 2.x 版本開始,官方對 MapReduce 的功能進行了拆分,引入了獨立的資源管理框架 YARN。此后,MapReduce (通常稱為 MapReduce on YARN 或 MRv2) 僅專注于其作為分布式數據計算引擎的核心職責。
三、Hadoop 1.X 組件關聯分析
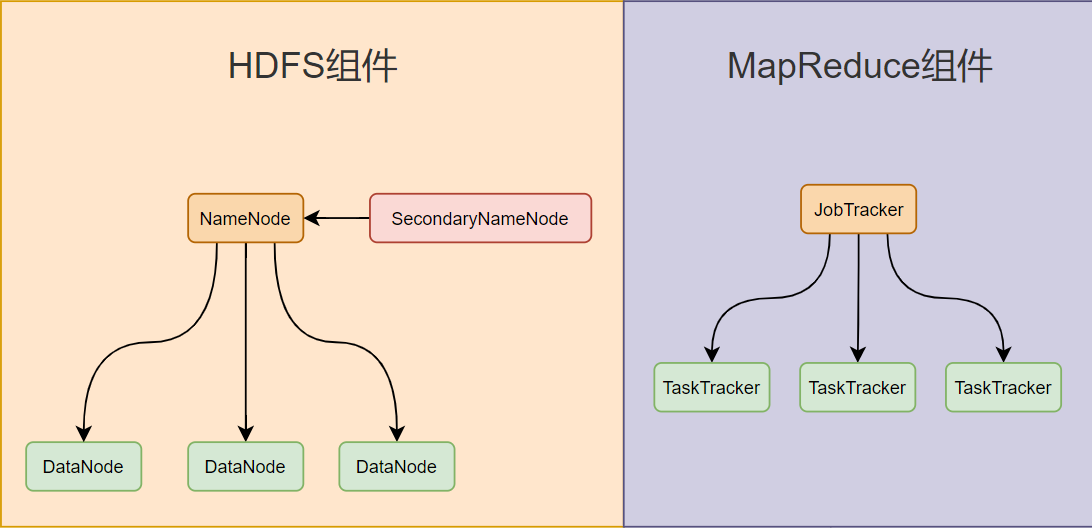
(一)組件關聯圖說明
(二)協同工作機制
HDFS和MapReduce在Hadoop1.X中緊密協作。
HDFS為MapReduce提供數據存儲。NameNode提供元數據,DataNode存儲數據塊。MapReduce的Map Task從DataNode讀取數據。
MapReduce利用HDFS數據進行計算。Map Task局部處理,Reduce Task全局匯總。JobTracker負責資源管理和作業調度,將任務分配給TaskTracker,考慮數據本地性。
例如,日志分析:日志存HDFS。MapReduce作業啟動,JobTracker將Map Task分配到數據節點。Map Task局部分析。Shuffle后,Reduce Task匯總,結果寫回HDFS。
四、Hadoop 1.X 與其他版本的對比
Hadoop 1.x vs Hadoop 2.x
- YARN引入:最核心區別。Hadoop 2.x引入YARN,分離資源管理與計算,支持多種計算框架(Spark等),不再局限于MapReduce。
- 存儲與容錯:Hadoop 2.x支持糾刪碼,比1.x的3副本方案更節省存儲。
- 單點故障:Hadoop 1.x的NameNode和JobTracker存在單點故障。Hadoop 2.x引入HA機制解決此問題,提高集群可靠性。

處理過程詳解)












)




