C++學習-入門到精通-【4】函數與遞歸入門
函數與遞歸入門
- C++學習-入門到精通-【4】函數與遞歸入門
- 一、 數學庫函數
- sqrt()
- ceil()
- cos()
- exp()
- fabs()
- floor()
- fmod()
- log()
- log10()
- pow()
- sin()
- tan()
- 總結
- 二、具有多個形參的函數定義
- 三、函數原型、函數簽名和實參的強制類型轉換
- 函數原型
- 函數簽名
- 實參類型強制轉換
- 四、C++標準庫
- 五、實例研究:隨機數生成
- 六、C++11的隨機數
- 七、存儲類別和存儲期
- 存儲期
- 八、作用域規則
- 語句塊作用域
- 函數作用域
- 全局命名空間作用域
- 函數原型作用域
- 九、函數調用堆棧和活動記錄
- 十、內聯函數
- 十一、引用和引用形參
- 十二、默認實參
- 十三、一元的作用域分辨運算符
- 十四、函數重載
- 編譯器如何區分重載的函數
- 十五、函數模板
- 十六、C++11——函數尾隨返回值類型
- 十七、遞歸
- 十八、遞歸與迭代
一、 數學庫函數
頭文件向用戶提供了一系列的數學函數。
sqrt()
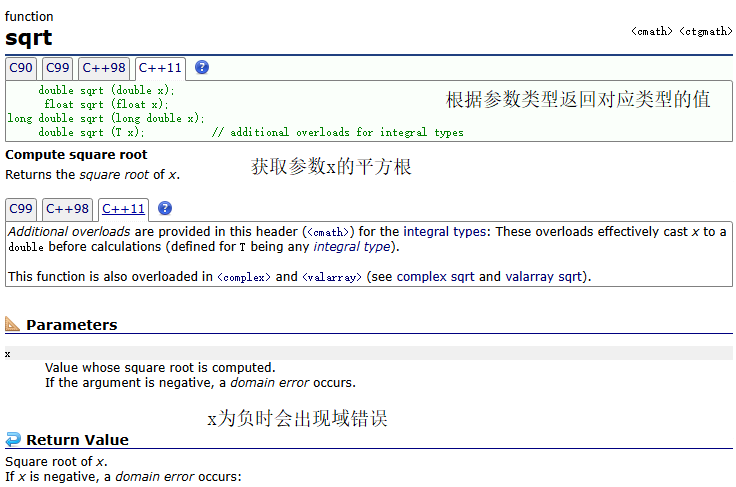
示例:

使用負數作為sqrt的參數時

ceil()
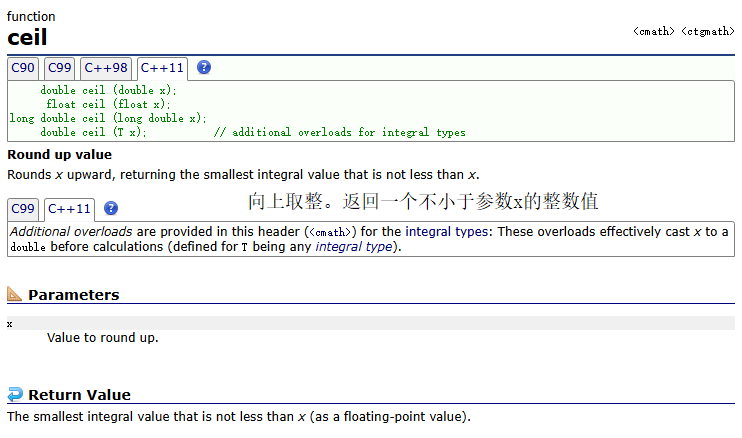
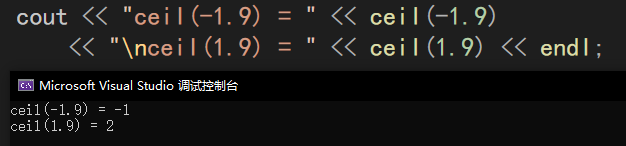
示例:
cos()
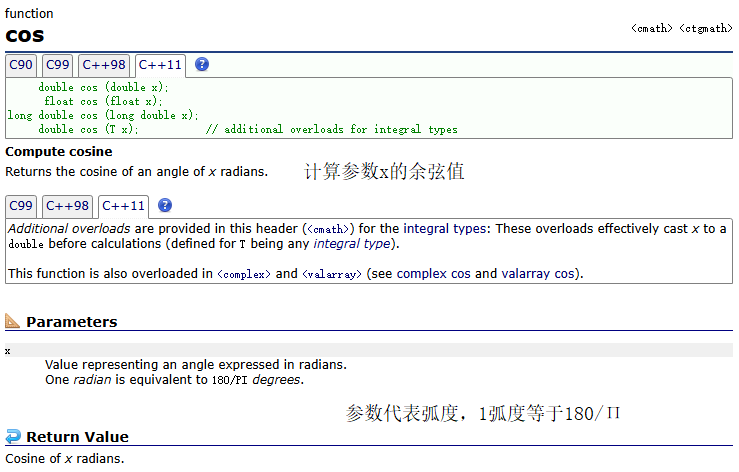
示例:
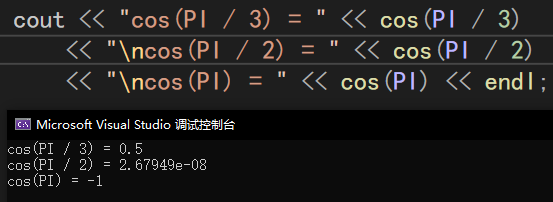
因為設置的PI的數值是一個近似值,所以cos(PI/2)得到的是一個0的近似值。
exp()
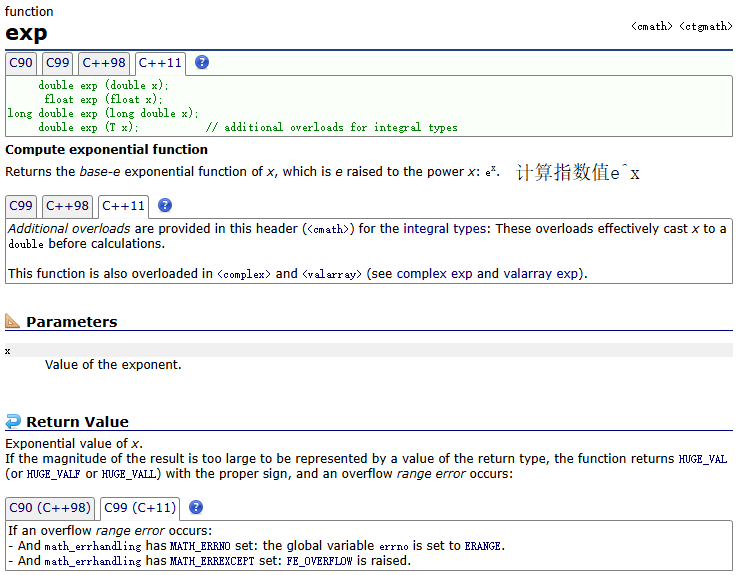
示例:
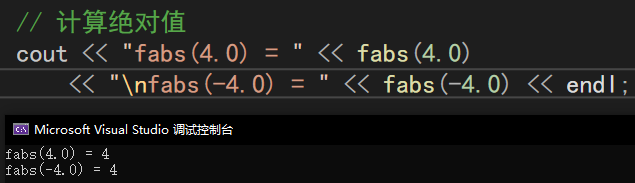
fabs()
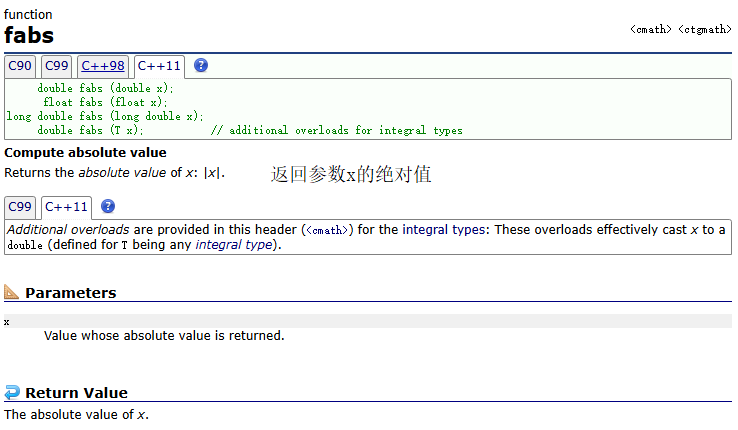
示例:
floor()
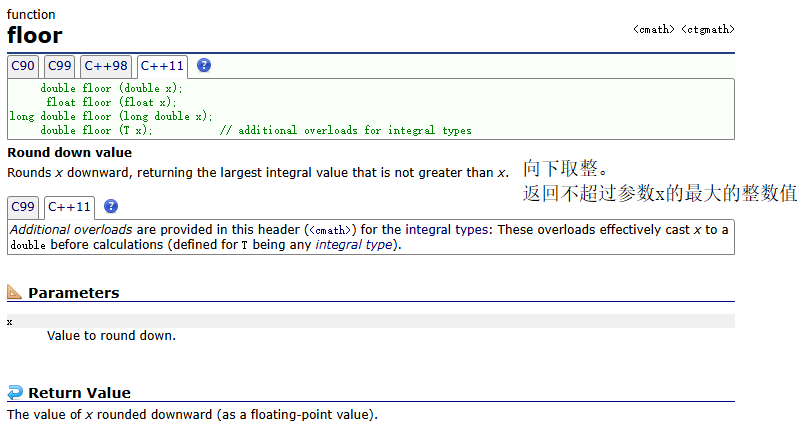
示例:
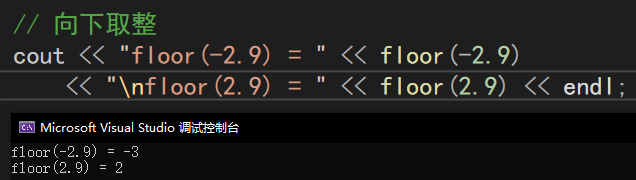
fmod()
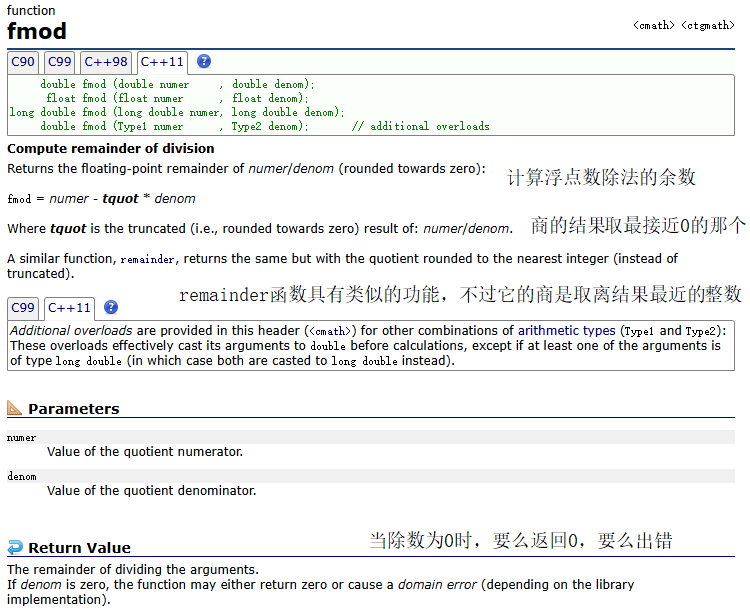
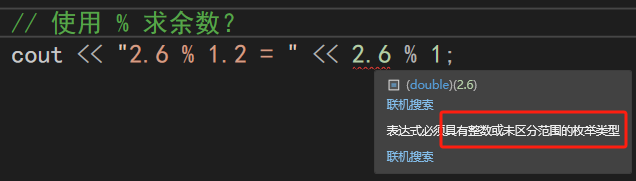
大家可能會存在這樣的疑問,求余數為什么不使用取模操作符
%呢?
接下來就介紹為什么:
可以看到操作符%的兩邊操作數是不接受浮點數的,只接收整形類型的表達式。
函數使用示例:
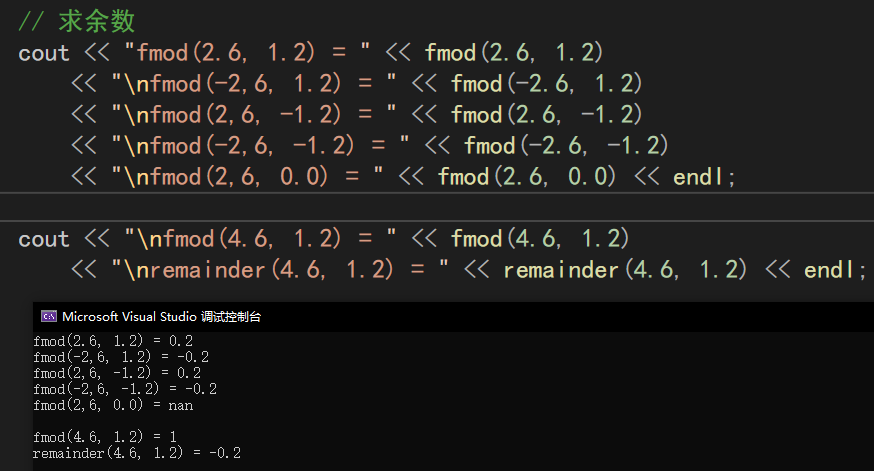
在上面的結果中可以得到,2.6 / 1.2 可以取兩個結果——2和3,2更接近0,所以商取2,得到的余數為0.2;-2.6 / 1.2可以取兩個結果——-2和-3,-2更接近0,所以商取-2,得到的余數為-0.2;
而remainder函數取的商的原則是使得除法的結果更接近0,所以在4.6 / 1.2的兩個結果——3和4之間選擇了4,因為4.8比3.6更接近4.6。
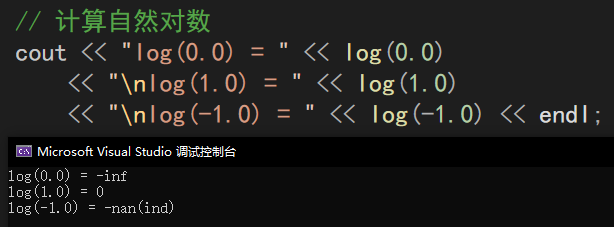
log()
示例:
log10()
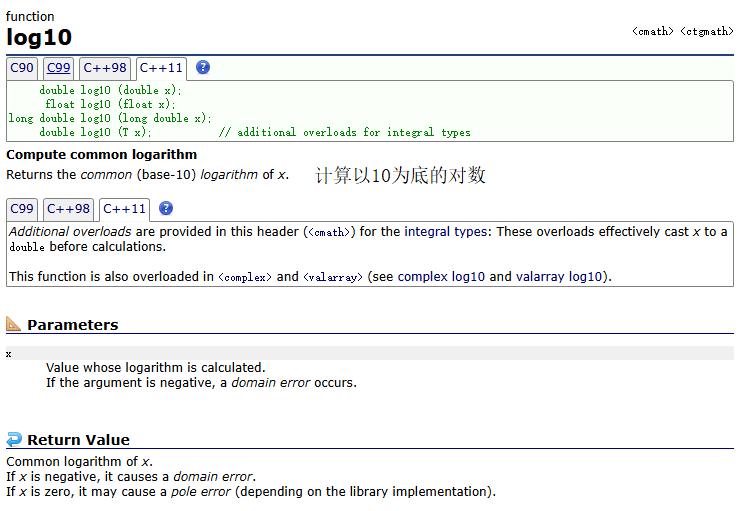
示例:
pow()
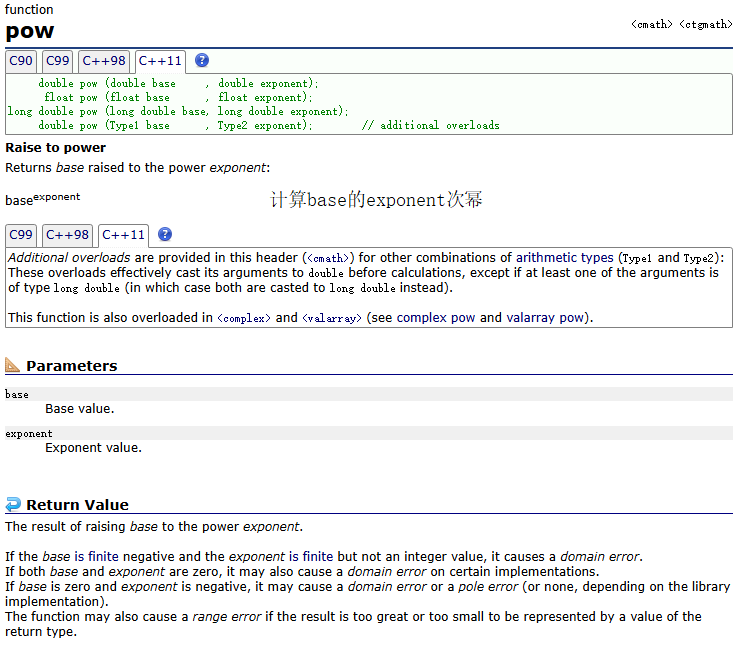
示例:
sin()
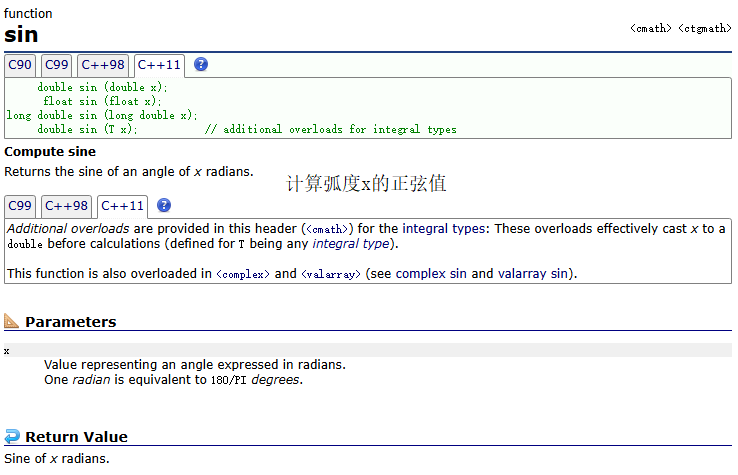
示例:
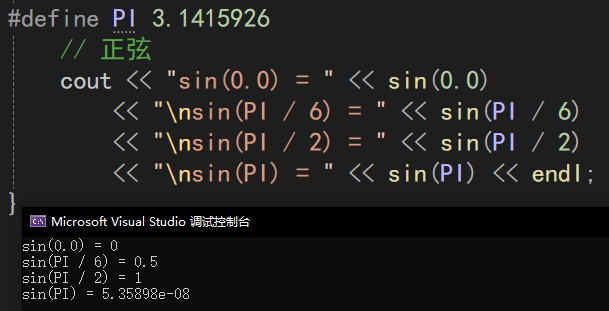
tan()
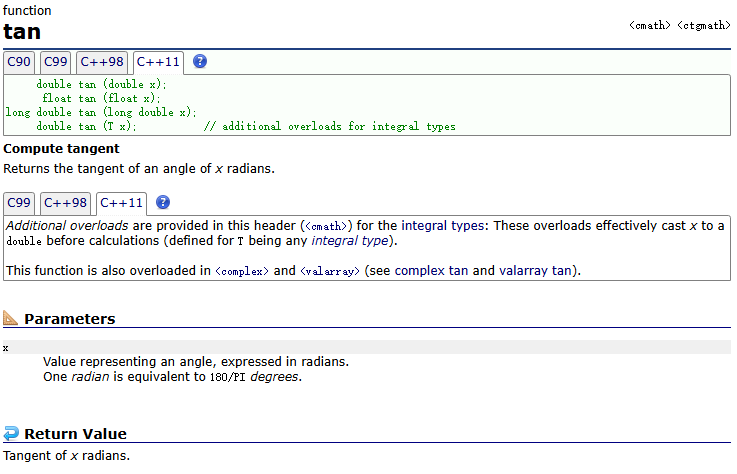
示例:
總結
| 函數 | 描述 | 示例 |
|---|---|---|
| sqrt(x) | 計算x的平方根 | sqrt(9.0) = 3.0 |
| pow(x, y) | 計算x的y次冪 | pow(2.0, 3.0) = 8.0 |
| ceil(x) | 向上取整 | ceil(6,6) = 7.0 |
| floor(x) | 向下取整 | floor(6.6) = 6.0 |
| fabs(x) | 取x的絕對值 | fabs(-2.0) = 2.0 |
| fmod(x, y) | 求x/y的余數(商取更接近0的值) | fmod(2.6, 1.2) = 0.2 |
| exp(x) | 計算e的x次冪 | exp(1.0) = e,(e是自然常數) |
| log(x) | 計算以e為底x的對數 | log(e) = 1.0 |
| log10(x) | 計算以10為底x的對數 | log10(10.0) = 1.0 |
| cos(x) | 計算弧度x的余弦值 | cos(PI / 3) = 0.5 |
| sin(x) | 計算弧度x的正弦值 | sin(PI /6) = 0.5 |
| tan(x) | 計算弧度x的正切值 | tan(PI / 4) = 1 |
二、具有多個形參的函數定義
GradeBook.h
#include <string>class GradeBook
{
public:explicit GradeBook(std::string);void setCourseName(std::string);std::string getCourseName() const;void displayMessage() const;void inputGrades();void displayGradeReport() const;int maximum(int, int, int) const;
private:std::string CourseName;int maximumGrade;
};
GradeBook.cpp
#include "GradeBook.h"
#include <iostream>using namespace std;// 構造函數
GradeBook::GradeBook(string name):maximumGrade(0) // 使用列表初始化器將數據成員maximumGrade初始化為0
{setCourseName(name); // 使用set成員函數初始化數據成員CourseName
}// set成員函數,設置數據成員CourseName的值
void GradeBook::setCourseName(string name)
{// 檢查參數的有效性// 課程名不超過25個字符合法if (name.size() <= 25){CourseName = name;}else // 異常處理{CourseName = name.substr(0, 25); // 截斷處理,取name的前25個字符賦值給課程名// 輸出錯誤信息cerr << "Name \"" << name << "\" is exceeds maximum length(25).\n"<< "Limitng CourseName to first 25 characters.\n" << endl;}
}// get成員函數,獲取數據成員CourseName
string GradeBook::getCourseName() const
{return CourseName;
}// 打印歡迎信息
void GradeBook::displayMessage() const
{cout << "Welcome to the Grade Book of " << getCourseName() << "!" << endl;
}// 輸入三個成績,并判斷最大值
void GradeBook::inputGrades()
{int grade1{0}, grade2{0}, grade3{0};// 判斷輸入成績的有效性do{cout << "Enter the first Grade:>";cin >> grade1;if (grade1 < 0){cerr << "The Grade should be greater than 0." << endl;}} while(grade1 < 0);do{cout << "Enter the second Grade:>";cin >> grade2;if (grade2 < 0){cerr << "The Grade should be greater than 0." << endl;}} while (grade2 < 0);do{cout << "Enter the third Grade:>";cin >> grade3;if (grade3 < 0){cerr << "The Grade should be greater than 0." << endl;}} while (grade3 < 0);maximumGrade = maximum(grade1, grade2, grade3);
}int GradeBook::maximum(int grade1, int grade2, int grade3) const
{int max = grade1;if (grade2 > max){max = grade2;}if (grade3 > max){max = grade3;}return max;
}// 打印最大成績
void GradeBook::displayGradeReport() const
{cout << "Maximum of Grades entered: " << maximumGrade << endl;
}
test.cpp
#include <iostream>
#include "GradeBook.h"using namespace std;int main()
{GradeBook myGradeBook("CS1201 C++ Programming");myGradeBook.displayMessage();myGradeBook.inputGrades();myGradeBook.displayGradeReport();
}
運行結果:
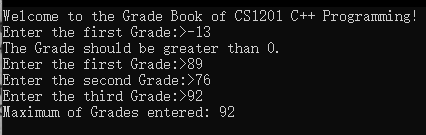
注意:函數參數列表中的,并不是逗號表達式的逗號。逗號表達式是運算順序是從左到右,但是函數實參的求值順序是由使用的編譯器決定的,但是C++標準保證了被調用的函數在執行前,所有函數實參都已經賦值。
三、函數原型、函數簽名和實參的強制類型轉換
函數原型
函數原型(也稱為函數聲明)告訴編譯器函數的名字、函數返回數據的類型、函數預期接收的參數的個數和順序以及這些參數的類型。(不包含函數體)
在頭文件中的就是GradeBook類中成員函數的原型。
函數定義也是一種函數原型,如果要在函數定義之前就使用這個函數,必須在此之前包含這個函數的原型。
函數簽名
函數簽名包括函數名和參數部分(比函數原型少了返回類型)。
在同一作用域中的函數必須有不同的函數簽名。這使得C++中可以使用函數重載(后續章節介紹)。
實參類型強制轉換
在調用函數時,可能出現實參類型與形參不匹配的情況。程序在執行時會將實參類型強制轉換為形參的類型。比如,一個形參類型的int類型的函數,在使用double類型的實參時,仍能正常工作。
在這種情況下發生的類型轉換就是所謂的隱式類型轉換。
C++中規定了基本數據類型之間可以進行隱式類型轉換,升級規則是空間小的類型可以轉換成占空間大的類型,比如,int類型轉換為double類型;同樣的大類型也可以轉換為小類型,不過在這種情況下,會對大類型的值進行截斷處理,這樣才能將數據放入小類型的空間中。不過這種截斷操作可能會對函數的執行結果產生影響。
四、C++標準庫
C++標準庫包含許多部分,每個部分都有自己的頭文件。頭文件中包含了形成標準庫各個部分的相關函數的函數原型。頭文件中還包含了各種各樣的類類型和函數的定義,以及這些函數需要的變量。這些頭文件負責預處理階段的“接口”處理工作。
| C++標準庫頭 | 文件說明 |
|---|---|
| <iostream> | 包含C++標準輸入和輸出函數的函數原型 |
| <iomanip> | 包含格式化數據流的流操縱符的函數原型 |
| <cmath> | 包含數學庫函數的函數原型 |
| <cstdlib> | 包含數轉換為文本、文本轉換為數、內存分配、隨機數及其他各種工具函數的函數原型 |
| <ctime> | 包含處理時間和日期的函數原型和類型 |
| <array>,<vector>,<list>,<forward_list>,<deque>,<queue>,<stack>,<map>,<unordered_map>,<unordered_set>,<set>,<bitset> | 這些頭文件包含了實現C++容器的類 |
| <cctype> | 包含測試字符特定屬性(比如字符是否是數字字符或者標點符號)的函數原型和用于將小寫字母轉換成大寫字母,將大寫字母轉換成小寫字母的函數原型 |
| <cstring> | 包含C風格字符串處理函數的函數原型 |
| <typeinfo> | 包含運行時類型識別(在執行時確定數據類型)的類 |
| <exception>,<stdexcept> | 這兩個頭文件包含用于異常處理的類 |
| <memory> | 包含被C++標準庫用來向C++標準庫容器分配內存的類和函數 |
| <fstream> | 包含執行由磁盤文件輸入和向磁盤文件輸出的函數的函數原型 |
| <string> | 包含C++標準庫的string類的定義 |
| <sstream> | 包含執行從內存字符串輸出和向內存字符串輸入的函數的函數原型 |
| <functional> | 包含C++標準庫算法所用的類和函數 |
| <iterator> | 包含訪問C++標準庫容器中的數據的類 |
| <algorithm> | 包含操作C++標準庫容器中數據的函數 |
| <cassert> | 包含為輔助程序調試而添加診斷的宏 |
| <cfloat> | 包含系統的浮點數長度限制 |
| <climits> | 包含系統的整數長度限制 |
| <cstdio> | 包含C風格標準輸入和輸出庫函數的函數原型 |
| <locale> | 包含流處理通常所用的類和函數,用來處理不同語言自然形式的數據(例如,貨幣格式、排序字符串、字符表示,等等) |
| <limits> | 包含為各計算機平臺定義數字數據類型限制的類 |
| <utility> | 包含被許多C++標準頭文件所用的類和函數 |
五、實例研究:隨機數生成
#include <iostream>
#include <cstdlib>
#include <iomanip>using namespace std;int main()
{int i{0};// 生成20個隨機數for (i = 0; i < 20; i++){// 設置輸出格式,每次輸出占10個字符寬,左對齊cout << setw(10) << left << ((rand() % 6) + 1);}}
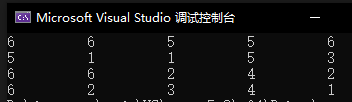
可以看到這里確實生成了20個隨機數,但是當我們再次執行這個程序時會發現,生成的隨機數是相同的。
所以rand函數生成的其實是偽隨機數。

所以為了將上述的隨機數生成器進行隨機化,我們可以在每次程序執行時調用srand函數設置一個種子,每次調用使用的種子都應該不一樣,也就是說這個種子其實也是一個“隨機數”。那么這不是陷入了一個為了生成隨機數而需要的一個隨機數的死循環中了嗎?
沒錯,所以我們并不是使用一個隨機數來作為rand函數的種子,而是使用一個永遠不可能相同的一個量——時間。

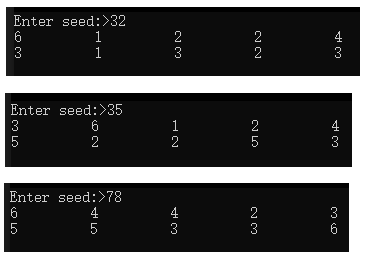
每次程序執行都由用戶輸入一個數作為隨機數生成的種子
#include <iostream>
#include <cstdlib>
#include <iomanip>using namespace std;int main()
{int i{0};// 提示用戶輸入一個數作為此次程序生成隨機數使用的種子unsigned int seed{0};cout << "Enter seed:>";cin >> seed;srand(seed);// 生成10個隨機數for (i = 0; i < 10; i++){// 設置輸出格式,每次輸出占10個字符寬,左對齊cout << setw(10) << left << ((rand() % 6) + 1);}cout << "\n";
}
使用頭文件中的時間函數,獲取當前時間,將該時間作為種子
#include <iostream>
#include <cstdlib>
#include <iomanip>
#include <ctime>using namespace std;int main()
{srand(static_cast<unsigned int>(time(NULL)));for (int i = 0; i < 10; i++){cout << setw(10) << left << (1 + rand() % 6);}cout << "\n";
}

注意:使用生成隨機數的種子在每次執行程序中只需要設置一次(一般在main函數中設置)。
下面使用time函數作為種子,寫一個使用隨機數的程序——“擲雙骰”的骰子游戲
規則如下:

#include <iostream>
#include <iomanip>
#include <cstdlib>
#include <ctime>using namespace std;// 給出擲兩個骰子的函數原型
unsigned int rollDice();int main()
{// 使用枚舉類型來保存游戲的狀態// 游戲有3種狀態:// 1. 贏 - WON// 2. 輸 - LOST// 3. 游戲繼續 - CONTINUEenum Status { WON, LOST, CONTINUE};// 定義一個枚舉類型的變量用來保存當前游戲的狀態Status status{CONTINUE}; // 初始化為游戲繼續狀態// 設置隨機數生成的種子 - 以當前時間作為種子srand(static_cast<unsigned int>(time(NULL)));// 定義一個變量保存擲骰子的結果int sumOfDice{0}; // 初始化為0// 定義一個變量保存玩家的目標點數int myPoint{0};// 第一次擲骰子sumOfDice = rollDice();// 進行游戲狀態判定switch (sumOfDice){// 玩家勝利case 7:case 11:status = WON; // 更改游戲狀態break;// 玩家失敗case 2:case 3:case 12:status = LOST; // 更改游戲狀態break;// 游戲繼續default:status = CONTINUE;myPoint = sumOfDice; // 設置玩家的目標點數cout << "Point is " << myPoint << "!\n"; // 打印玩家的目標點數break;}// 將一個非左值放在判斷是否相等的左邊有利于程序的健壯性// 判斷游戲狀態是否是繼續while (CONTINUE == status) {// 擲骰子sumOfDice = rollDice();// 判斷游戲狀態if (sumOfDice == myPoint){status = WON;}else if (7 == sumOfDice) // 點數為7,玩家輸{status = LOST;}}if (WON == status){cout << "Player wins" << endl;}else{cout << "Player loses" << endl;}
}unsigned int rollDice()
{// 定義兩個變量保存擲得的骰子數unsigned int die1{0};unsigned int die2{0};die1 = 1 + (rand() % 6); // 6面的骰子die2 = 1 + (rand() % 6); // 定義變量保存骰子數之和unsigned int sum = die1 + die2;// 打印擲骰子結果cout << "Player rolled: " << die1 << " + " << die2 << " = " << sum << endl;return sum;
}
運行結果:

枚舉常量的值是整型常量,但是給枚舉類型變量賦值時不可以用等同于枚舉常量的整數值替代,這樣會出現編譯錯誤。
因為不同枚舉類型中枚舉常量的標識符可能是相同的,在同一程序中使用這些枚舉類型會導致命名沖突和邏輯錯誤。為了消除此類問題,C++11中引入了所謂的作用域限定的枚舉類型,這種類型用關鍵字enum class或enum struct來聲明。
例如:
enum class Statuc { WON, LOST, CONTINUE }; // or enum struct Status { WON, LOST, CONTINUE };
現在要引用一個作用域限定的枚舉常量,就必須像Statuc::WON一樣,用作用域限定的枚舉類型名加上作用域分辨運算符::來限定該常量。
于是這樣就能將不同枚舉類型中相同的標識符區分開來。
默認情況下,枚舉類型的枚舉常量隱含的整數類型為int類型,不過C++11中允許程序員顯式指定枚舉類型所隱含的整數類型。方式是在枚舉類型名后加一個冒號:再跟上指定的整數類型。
例如:
enum class Status : unsigned int { WON, LOST, CONTINUE };
六、C++11的隨機數
根據CERT提供的信息,rand函數不具有“良好的統計特性”并且是可預測的,這使得使用rand函數的程序安全性較弱。C++11中提供了許多類來表示各種不同的隨機數生成引擎和配置。
其中引擎實現一個產生偽隨機數的隨機數生成算法,而一個配置控制一個引擎產生的值的范圍、這些值的類型和這些值的統計特性。
下面我們使用默認的引擎default_random_engine和默認的配置uniform_int_distribution來生成隨機數,其中后者在指定的值的范圍內均勻的生成偽隨機數。
#include <iostream>
#include <iomanip>
#include <random>
#include <ctime>using namespace std;int main()
{unsigned int i = 0;default_random_engine engine(static_cast<unsigned int>(time(NULL)));uniform_int_distribution<unsigned int> randomInt(1, 6);for (i = 1; i <= 10; i++){cout << setw(10) << left << randomInt(engine);if (i % 5 == 0){cout << endl;}}
}
運行結果:

在上面中<unsigned int>表示uniform_int_distribution是一個類模板(只有類模板在聲明一個變量時,才需要指定類型)。在這種情況下尖括號對<>中可以指定任何的整數類型。之后會詳細介紹如何創建類模板,現在只需要模仿例子中的語法來使用這個類模板即可。
七、存儲類別和存儲期
到目前為止,我們所看到的程序中使用標識符作為變量名和函數名。變量的屬性包括名字、類型、規模大小和值。實際上,程序中的標識符還有其他的屬性,包括存儲類別、作用域和鏈接。
C++中提供5種存儲類型說明符:auto、register、extern、mutable和static,它們決定變量的存儲期。
存儲期
標識符的存儲期決定了其在內存中存在的時間,換言之存儲期就是這個標識符的生命周期。有些標識符存在的時間短,有些標識符可以重復創建和銷毀,還有一些標識符在整個程序執行過程中一直存在。這一節先討論兩種存儲期:靜態的(static)和自動的(auto)。
作用域
標識符的作用域是指標識符在程序中可以被引用的范圍。有些標識符在整個程序中都能被引用,有些只能在程序的某個部分引用。在本文的后面章節會詳細介紹標識符的作用域。
鏈接
標識符的鏈接決定了標識符是只在聲明它的源文件中可以被識別,還是在編譯后鏈接在一起的多個文件可以識別。標識符的存儲類型用于確定存儲類型和鏈接。
存儲期
存儲類別說明符可以分為4種存儲期:自動存儲期、靜態存儲期、動態存儲期、線程存儲期。本節僅討論前兩種;
動態分配的變量才有動態存儲期,C++允許程序在執行過程中為變量分配額外的空間,這被稱為動態存儲分配。線程存儲期是在多線程中應用中使用。
局部變量和自動存儲期
具有自動存儲期的變量包括:
- 局部變量;
- 函數的形參;
- 用register聲明的局部變量或函數形參;
這樣的變量在程序執行到定義它們的語句塊時被創建,它們只能在定義它們的語句塊中使用,在程序離開該語句塊之后,這些變量就會被銷毀。這種具有自動存儲期的變量可以簡稱為自動變量。自動變量只存在于其定義所在的函數體中離它最近的花括號對{}之內,當它是一個函數的形參時,它在整個函數的都存在。局部變量默認情況下都具有自動存儲期。
寄存器變量
程序的機器語言版本中的數據一般都是加載到寄存器中處理的。因為在程序的執行過程中會將內存中的數據拿到寄存器中處理,將要處理的數據放入寄存器中,可以避免數據從內存加載到寄存器中的開銷。當我們在聲明一個變量時,認為它會經常被使用,就可以把它聲明成一個寄存器變量,雖然編譯器并不一定會將其設為寄存器變量。
下面是一個聲明寄存器變量的例子:
register unsigned int counter = 1;
這個例子中,建議將一個unsigned int類型的變量counter放入計算機的一個寄存器中。
注意:關鍵字register只能和局部變量或函數形參一起使用
提示:現在的編譯器是非常智能的,通常并不需要程序員顯式的將一個變量聲明成寄存器變量,編譯器可以識別頻繁使用的變量,并自行決定將它們放到寄存器中。
靜態存儲期
關鍵字extern和static為函數和具有靜態存儲期的變量的聲明標識符。具有靜態存儲期的變量在程序開始執行起直到程序執行結束都一直存在于內存中。在遇到這種變量時就對它進行一次性初始化。對于函數而言,程序執行開始時函數名就已經存在。然而, 即使函數名和變量在程序一開始執行就存在,并不意味著這些標識符在整個程序中都可以使用。存儲期和作用域(標識符可以使用的地方)是獨立的問題。本文的后續部分會進行說明。
具有靜態存儲期的標識符
有兩種具有靜態存儲期的標識符,一種是聲明在外部的標識符(全局變量),另一種是用存儲類別說明符static聲明的局部變量。全局變量是通過把變量放在任何類或函數定義的外部來創建的。全局變量在整個程序中保存它們的值。全局變量和全局函數可以被源文件中任何位于其聲明或定義之后的任何函數引用。
靜態局部變量
使用關鍵字static聲明的局部變量僅被其聲明所在的函數所知。但是與自動變量不同的是,當函數退出調用時,這個靜態局部變量并不會銷毀,而是會繼續存在于內存中,下次再調用這個函數,該靜態局部變量的值與上次結束時的值相同。舉個例子:
#include <iostream>using namespace std;void test();int main()
{cout << "First test:";test();cout << "Second test:";test();
}void test()
{static int i = 0;cout << i++ << endl;
}
運行結果:
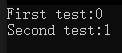
可以看到在第一次調用test之后局部變量i的值變成了1,第二次調用時,輸出的結果也是1,并沒有再對i進行初始化。
八、作用域規則
程序中可以使用標識符的范圍就是該標識符的作用域。例如在一個語句塊中聲明了一個局部變量,這個局部變量只能在這個語句塊中使用,這個語句塊就是該局部變量的作用域。下面我們會討論4個作用域:語句塊作用域、函數作用域、全局命名空間作用域和函數原型作用域。在更之后的章節中還會介紹另兩種作用域:類作用域、命名空間作用域。
語句塊作用域
在一個語句塊中聲明的標識符具有語句塊作用域。該標識符的作用域開始于標識符的聲明處,結束于標識符聲明所在語句塊的結束右花括號處。局部變量具有語句塊作用域,函數形參同樣具有語句塊作用域。任何語句塊都能包含變量聲明。當語句塊是嵌套的,且內層語句塊中一個標識符與外層語句塊中的一個標識符有相同的名字時,在內層語句塊中使用該名字引用的標識符是內層的標識符,外層語句塊的標識符對它而言是隱藏的。
舉個例子:
#include <iostream>using namespace std;int main()
{int a = 3;{int a = 6;cout << "a = " << a << endl;}
}
運行結果:
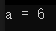
而聲明為static的局部變量同樣具有語句塊作用域,雖然它具有靜態存儲期,從程序開始執行開始就一直存在,但是這影響它的作用域。(存儲期不會影響標識符的作用域)。
提示:因為外層和內層語句塊中存在同名的標識符時,在內層語句塊中引用該標識符是引用的內層的標識符,當程序員想要引用外層的標識符時,就會產生邏輯錯誤,所以不要使用同名的標識符。
函數作用域
標簽,也就是像start:之類的后跟一個冒號的標識符,或者是switch語句中的case標簽,是唯一的具有函數作用域的標識符,標簽可以用在它們出現的函數內的任何地方,但是不能在函數體之外引用。
全局命名空間作用域
聲明在任何函數或者類之外的標識符都具有全局命名空間作用域。這種標識符對于從其聲明處開始直到文件結尾處為止出現的所有函數都是已知的,即“可訪問的”。位于函數之外的全局變量、函數定義和函數原型都具有全局命名空間作用域。
函數原型作用域
具有函數原型作用域的唯一標識符是那些用在函數原型形參列表中的標識符。通常函數原型是不需要形參名的,只需要它們的類型。函數原型的形參列表中出現的名字會被編譯器忽略。所以用在函數原型中的標識符可以在程序的任何地方無歧義的利用。
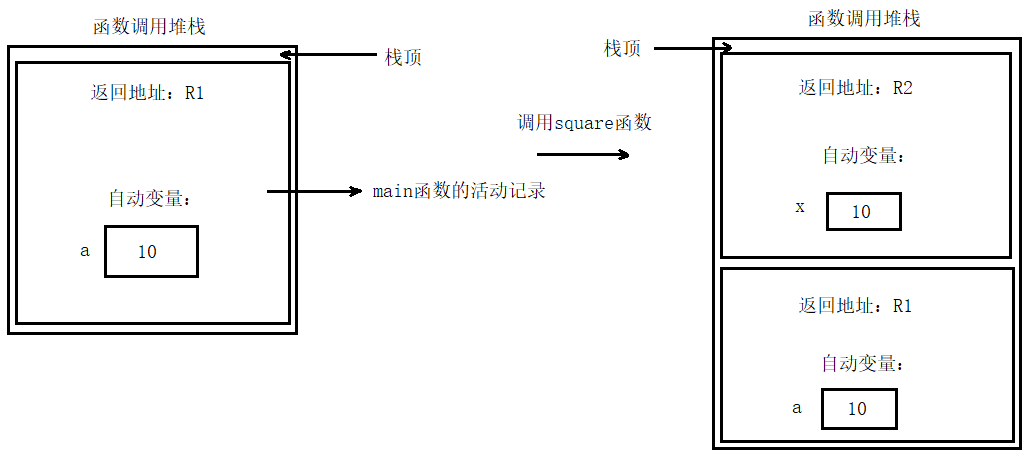
九、函數調用堆棧和活動記錄
函數調用堆棧
調用每個函數時,可能會依次調用其他函數,而且所調用的函數也可能調用其他函數,這一切都發生在任何函數返回之前。每個函數都必須將控制權返回給調用它的函數。因此,必須用某種方法記錄每個函數把控制權返回給調用它的函數時所需要的返回地址。函數調用堆棧就是處理這些信息的理想數據結構。這種數據結構具有先進后出的特性非常符合函數調用的邏輯。每當一個函數調用另一個函數時,就會有一個數據項被壓入堆棧中。這個數據項被稱為一個堆棧結構或者一條活動記錄,包含了被調用函數返回到調用函數所需的返回地址,還包含了一些附加信息。當一個函數調用結束返回到調用它的函數時,該函數的堆棧結構就會彈出,并將控制權轉到該結構中的返回地址處。
自動變量和堆棧結構
大多數函數都會有自動變量——形參和聲明在函數內部的局部變量。這些自動變量在函數執行時存在,在函數執行結束后被銷毀。在調用時存在,返回時銷毀,這和堆棧結構的特性相似,所以堆棧結構是一個保存這類信息的理想位置。
堆棧溢出
堆棧也是一種計算機資源,資源總是會存在上限,也就是說堆棧空間是會用完的。如果發生太多的函數調用,堆棧資源被使用完了,不能將相應的函數活動記錄保存到堆棧中,這時就會發生堆棧溢出錯誤。
下面我們對一個例子進行分析:
#include <iostream>using namespace std;int square(int);int main()
{int a = 10;cout << "a = " << a << endl;a = square(a);cout << "a = " << a << endl;
}int square(int x)
{return x * x;
}
十、內聯函數
從上面的函數調用堆棧中可以看到通過函數來實現它實現的功能是會帶來額外的開銷的——函數的調用及返回。當一些函數所實現的功能非常簡單時,這些開銷與實現功能消耗的開銷就相差無幾甚至更多,這里就可以使用內聯函數。在函數定義中把限定符inline放在函數返回類型前面,可以建議編譯器在合適的時候在函數被調用的地方生成函數體代碼的副本——將函數代碼復制過來,以避免函數的調用。這種行為會導致程序代碼變得比較龐大。
提示:對內聯函數進行修改之后,要求程序重新進行編譯,才可以實裝修改。注意,這與宏的替換是不同的,宏的替換是在預處理階段進行的,而內聯函數的替換是在編譯階段進行,它需要進行語法分析,確保類型安全,并且內聯函數的替換并不一定會發生,編譯器會自行決定是否進行替換,在函數聲明時使用inline關鍵字只是“建議”將這個函數設成內聯函數。
十一、引用和引用形參
在許多編程語言中都會有按值傳遞和按址傳遞(或稱為按引用傳遞)這兩種函數形參傳遞方式。其中,按值傳遞會先在函數調用堆棧中創建一個實參值的副本,然后將副本傳遞給被調用的函數。對于副本的修改并不會影響實參的值。
提示:當使用按值傳遞的方式傳遞一個很大的變量時,創建該變量的副本會產生較大的開銷。
引用傳參
在C++中有兩種按引用傳遞的方式,第一種就是引用傳參,另一種是使用指針實現的按引用傳參。
引用形參是函數調用相應實參的別名。為了指明一個函數參數是按引用傳遞的需要在形參的類型后面跟上一個&;例如:int &a,這條語句可以讀作,“a是對一個int類型對象的引用”。
注意與C語言進行區分,引用是C++中新引入的概念,在C語言中是使用指針來實現這種行為的,但是,由于指針存在空指針、野指針、懸空指針等問題,且使用時需要使用*,->等符號,所以在C++中引入了更簡潔的引用操作。引用在底層可能也是使用指針實現的,不過在某些情況下,由編譯器優化可能會更安全。
由于對實參的引用是可以對原來的值進行修改的,為了使用了引用形參的函數不會修改對應實參的值,可以使用const進行修飾,const放在類型的前面。
例如:const int& a;,這條語句表明a是一個int類型對象的引用,且無法通過別名a修改它對應的值。
注意1:
引用與指針不同的是,引用必須在它們的聲明中完成初始化,且在初始化之后,引用綁定的對象無法再進行修改,要與指針進行區分。
注意2:
與指針相同,雖然函數可以返回引用,但是要注意不要返回一個函數的自動變量的引用,因為當函數返回之后,函數中定義的自動變量會被銷毀,此時返回的引用就變成了一個“虛懸引用”。
十二、默認實參
當重復調用函數時對特定的形參一直采用相同的實參。在這種情況下就可以對這個形參指定默認實參,即傳遞給該形參一個默認值。當程序在調用函數時,對于有默認實參的形參省略了對應的實參時,編譯器就會重寫這個函數調用,并且插入那個實參的默認值。
默認實參必須是形參列表中最靠右邊的實參。當調用具有2個及以上的默認實參的函數時,當省略的實參不是最右邊的實參,那么它后面的實參也會使用默認實參代替。
默認形參必須在函數名第一次出現時指定,通常是在函數原型中,如果因為函數定義也作為了函數原型而省略了函數原型,那么應該在函數頭部中指定默認實參。
默認值可以是任何表達式,包括常量、全局變量、或者函數調用。默認實參也可用于內聯函數。
下面給出一個使用默認實參的例子:
#include <iostream>using namespace std;// 函數原型中可以省略形參名
//unsigned int boxVolume(unsigned int = 1, unsigned int = 1, unsigned int = 1);
// 為了增強可讀性,在聲明函數原型時,可以包含形參名
unsigned int boxVolume(unsigned int length = 1, unsigned int width = 1, unsigned int height = 1);int main()
{// 第一次調用,全部使用默認實參cout << "The default box volume is " << boxVolume() << endl;// 第二次調用,高度和寬度使用默認實參cout << "\nThe volume of a box with length 10,\n"<< "width 1 and height 1 is " << boxVolume(10) << endl;// 第三次調用,高度使用默認實參cout << "\nThe volume of a box with length 10,\n"<< "width 5\nand height 1 is " << boxVolume(10, 5) << endl;// 第四次調用cout << "\nThe volume of a box with length 10,\n"<< "width 5\nand height 3 is " << boxVolume(10, 5, 3) << endl;
}unsigned int boxVolume(unsigned int length, unsigned int width, unsigned int height)
{return length * width * height;
}
運行結果:
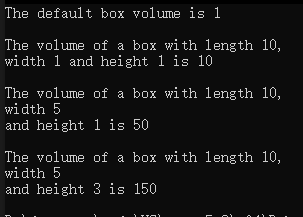
從下圖中可以看出不存在中間參數使用默認實參,右邊使用指定實參的情況。

十三、一元的作用域分辨運算符
前面我們提到了全局變量和局部變量是可能出現同名的情況的,在局部變量的作用域中使用這個標識符我們會訪問到局部變量,全局變量對于這片作用域是被“隱藏”起來的。那么我們要如何在這個作用域中訪問到這個全局變量呢?使用一元的作用域分辨運算符::。下面給出它的使用例子。
#include <iostream>using namespace std;// 全局變量
int a = 10;int main()
{// 與全局變量同名的局部變量int a = 100;cout << "a = " << a << endl;cout << "::a = " << ::a << endl;
}
運行結果:
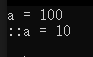
提示:
在引用全局變量時總是使用::可以使得程序更加容易理解,且更不容易出錯。
十四、函數重載
前面我們提到了在同一作用域中函數的函數簽名是不能相同的,所以在C++中我們可以定義多個名字相同的函數,只要它們的函數簽名不相同即可。這種特性被稱為函數重載。當調用一個重載函數時,編譯器通過檢查函數調用中的實參數目、類型和順序來選擇恰當的函數。
函數重載通常用于創建執行相似任務、但是作用于不同的數據類型的具有相同名字的多個函數。
下面是一個使用重載函數的例子:
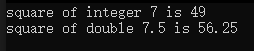
#include <iostream>using namespace std;int square(int);
double square(double);int main()
{cout << square(7) << endl;cout << square(7.5) << endl;
}int square(int x)
{cout << "square of integer " << x << " is ";return x * x;
}double square(double x)
{cout << "square of double " << x << " is ";return x * x;
}
運行結果:
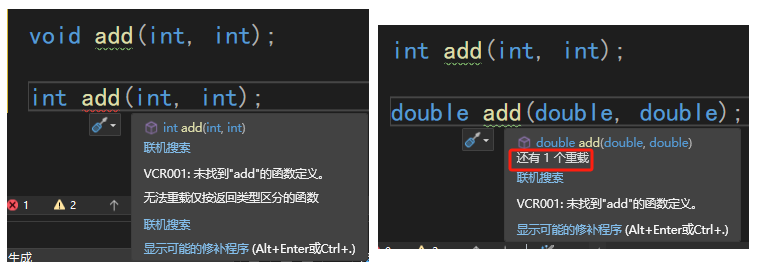
編譯器如何區分重載的函數
重載的函數通過它們的簽名來區分。簽名由函數名和參數部分組成。編譯器會對每個函數的標識符利用它的形參類型進行編碼(有時也稱為名字改編或名字裝飾),以便能夠實現類型安全的的鏈接。類型安全的鏈接保證調用正確的重載函數,并且保證實參類型和形參類型相符合。
下面給出一個Cpp代碼經過GUN g++編譯器編譯的程序。
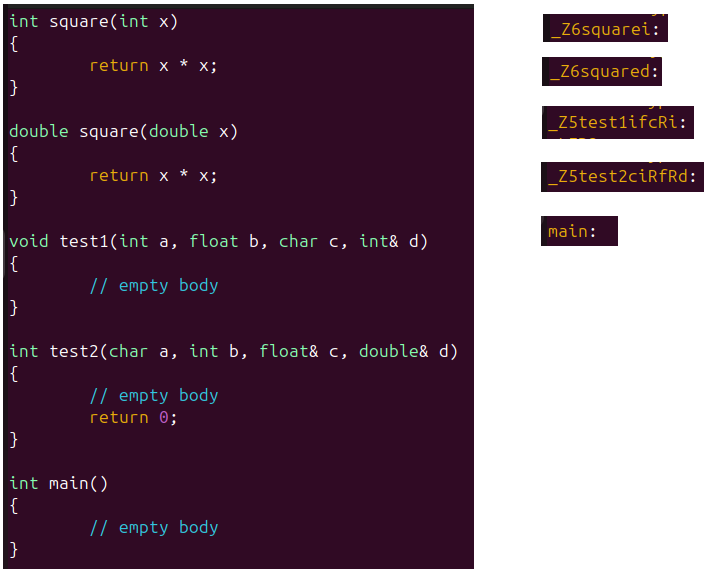
左邊是Cpp程序代碼,右邊的經過編譯后生成的匯編語言代碼,它們是改編后的名字。
除main函數之外,每個改編之后的名字都是由一個下劃線_開始,后跟字母Z、一個數字和函數名。字母Z后面的數字表示函數名的長度,函數square的長度是6所以前面兩個重載的square函數的改編之后的Z字母后面是6。
在函數名之后跟著該函數的形參列表的編碼。在test1中,i表示int類型,f表示float類型,c表示char類型,Ri表示int&類型(R表示引用)。
main函數是無法重載的。
提示:
調用一個具有默認實參的函數時省略實參,其形式可能與調用另一個重載的函數一樣,這樣會產生編譯錯誤。比如,一個函數指定了沒有參數,另一個重載的函數,給出了所有的默認實參。當試圖在一次調用中不傳入任何參數,此時就會導致編譯錯誤,因為編譯器無法區分使用的哪個版本的函數。
十五、函數模板
重載函數通常用于執行相似的操作,這些操作涉及作用于不同數據類型上的不同程序邏輯。如果對于每種數據類型程序邏輯和操作都是相同的,那么使用函數模板可以使重載執行起來更加緊湊和方便。程序員需要編寫單個函數模板定義。只有在這個函數模板中提供了實參類型,C++就會自動生成獨立的函數模板特化來恰當的處理每種類型的調用。如此,定義了一個函數模板其實相當于定義了一整套重載的函數。
所有的函數模板都是由template關鍵字開頭,后面跟一對尖括號<>,這是函數模板的模板形參列表,數量可以大于1。模板形參列表中每個形參(通常稱為形式類型形參)由關鍵字typename或class(它們是同義詞)開頭。
形式類型形參是基本類型或用戶自定義類型的占位符。這些占位符用于指定函數形參的類型、指定函數的返回類型,以及在函數定義體內聲明變量。函數模板的定義與其他函數的定義一樣,只是使用形式類型形參作為實際數據類型的占位符。
下面給出一個定義函數模板的例子:
maximum.h
使用template關鍵字表明這是一個函數模板,形式類型形參列表中只有一個形式類型形參,所以整個函數中只可以使用一種類型(每個形式類型形參在一次特化中只能代表一種類型)。
函數模板中函數的返回值和三個參數的類型都用T來表示
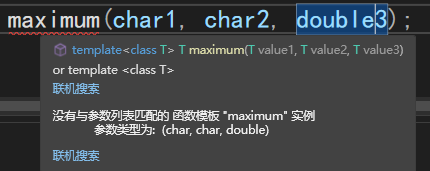
template <typename T> // or template <class T>T maximum(T value1, T value2, T value3)
{T maximumValue = value1;if (value2 > maximumValue){maximumValue = value2;}if (value3 > maximumValue){maximumValue = value3;}return maximumValue;
}
test.cpp
#include <iostream>
#include "maximum.h"using namespace std;int main()
{int int1{0}, int2{0}, int3{0};cout << "Enter three integer values:";cin >> int1 >> int2 >> int3;cout << "The maximum integer value is " << maximum(int1, int2, int3) << endl;double double1{ 0 }, double2{ 0 }, double3{ 0 };cout << "Enter three double values:";cin >> double1 >> double2 >> double3;cout << "The maximum double value is " << maximum(double1, double2, double3) << endl;char char1{ 0 }, char2{ 0 }, char3{ 0 };cout << "Enter three char values:";cin >> char1 >> char2 >> char3;cout << "The maximum char value is " << maximum(char1, char2, char3) << endl;
}
運行結果:
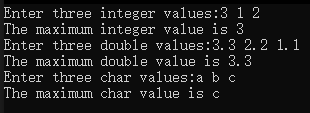
可以看到在上面的test.cpp中我們直接使用了maximum函數,并沒有對不同類型進行特化,這就歸功于在maximum.h中定義的函數模板。
十六、C++11——函數尾隨返回值類型
C++11的一個新特性就是函數的尾隨返回值類型。為了指定尾隨返回值類型,需要將關鍵字auto放在函數名之前,并且在函數的形參列表之后加上->以及返回值類型。
這個新特性對于一些返回值類型比較復雜的情況很有幫助。例如:
int (*getFunction(char, int))(int, int);
這段代碼如果大家是第一次見估計人肯定是懵懵的,這都是些什么鬼啊。
這是一個函數的函數原型。它有兩個參數,類型分別是char和int,它的返回值是一個函數指針,這個函數指針指向一個有兩個int類型的參數、返回值類型為int的函數。
先找到getFunction這個標識符,它左邊與
*結合,右邊與()結合,()的優先級比*更高,所以該標識符先與()結合形成一個函數。()中的內容是該函數的參數列表,這個函數有兩個參數,第一個參數類型為char類型,第二個參數類型為int類型。
剩余部分都是該函數的返回值類型,函數簽名首先與*結合,所以該該函數的返回值類型是一個指針類型。剩下的部分就是指針指向的類型;
int (int, int)是一個函數,返回值類型是int,有兩個int類型的參數。
讓我們使用尾隨返回值類型來聲明這個函數原型試試看:
auto getFunction(char, int) ->int (*)(int, int);
這樣是不是就一目了然了。
該特性的更多用途還需要大家在編程中逐漸體會。
十七、遞歸
遞歸函數是直接或者間接地(通過另一個函數)調用自己的函數。注意C++標準文檔中規定,main函數在一個程序中不應當被其他函數調用或遞歸調用自身。
調用遞歸函數實際上為了解決問題。這種函數只知道如何解決最簡單的情況,或者基本情況。如果調用函數是為了解決基本情況,那么它就會簡單的返回一個結果。如果調用函數是為了解決一個復雜的情況,那么它通常會將問題分成兩個概念性的部分:一部分是函數知道如何去做的,另一部分是函數不知道如何處理的。為了使遞歸可以解決問題,后一部分必須和原來的問題相似,且規模更小或更簡單一點。因此函數可以調用一個全新的副本去解決這個新的更小的問題——這就是遞歸調用,也稱遞歸步驟。遞歸步驟通常包括關鍵字return,因為它的結果會與函數知道如何解決的一部分組合起來,從而得到可以返回給調用者的結果。
下面我們來看一個例子:
階乘
迭代的階乘:int factorial = 1; for(int count = n; count >= 1; count--) {factorial *= count; }遞歸的階乘:
int Factorial(int n) {if(1 == n || 0 == n){return 1;}return n * Factorial(n - 1); }
利用遞歸實現斐波那契數列
#include <iostream>using namespace std;int fibonacci(int n)
{if (1 == n || 0 == n){return n;}return (fibonacci(n - 1) + fibonacci(n - 2));
}int main()
{for (int i = 0; i <= 10; i++){cout << "fibonacci(" << i << ") = " << fibonacci(i) << endl;}cout << "fibonacci(20) = " << fibonacci(20) << endl;cout << "fibonacci(30) = " << fibonacci(30) << endl;cout << "fibonacci(40) = " << fibonacci(40) << endl;
}
運行結果:
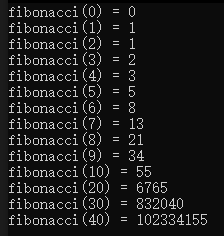
但是如果大家嘗試執行了這段代碼應該會發現,在執行fibonacci(40)時明顯是隔了一段時間。這是因為遞歸實現的Fibonacci的函數,每級遞歸都會使函數的調用的次數加倍。所以在實現一些可以使用迭代實現的算法盡量不要使用遞歸實現。
十八、遞歸與迭代
現在對遞歸與迭代進行一些比較:
- 迭代和遞歸都是基于控制語句的:迭代使用循環結構,遞歸使用選擇結構;
- 迭代和遞歸都涉及循環:迭代顯式的使用循環結構,遞歸通過重復的函數調用實現循環;
- 迭代和遞歸均包括終止條件測試:迭代在循環繼續條件不滿足時停止,遞歸在達到基本情況時終止;
- 采用計數器控制的循環的迭代和遞歸都是逐步達到終止的:迭代修改計數器直到計算器的值使循環繼續條件不滿足,遞歸產生比原來的問題更簡單的問題直到達到基本情況;
- 迭代和遞歸都可能無限進行:如果循環繼續測試一直為真,則循環會一直進行下去。如果遞歸步驟不能通過遞歸歸結到基本情況,就會導致無限遞歸;
遞歸的不足
遞歸存在許多不足之處。它需要進行多次函數調用,這勢必會增加許多開銷(調用函數)。這樣不僅會消耗處理器的時間,還會消耗內存空間。每個遞歸調用都會創建函數變量的一份副本,這會占用相當量的內存空間。而迭代通常發生在一個函數內,因此沒有重復的函數調用的開銷和額外的內存分配。
那么為什么還要使用遞歸呢?









)


)

![56.[前端開發-前端工程化]Day03-webpack構建工具](http://pic.xiahunao.cn/56.[前端開發-前端工程化]Day03-webpack構建工具)




![[machine learning] Transformer - Attention (一)](http://pic.xiahunao.cn/[machine learning] Transformer - Attention (一))