文章目錄
- Redis的數據類型和內部編碼
- 單線程模型的工作過程
- Redis在處理命令時雖然是一個單線程模型,為啥效率那么高,速度快呢?
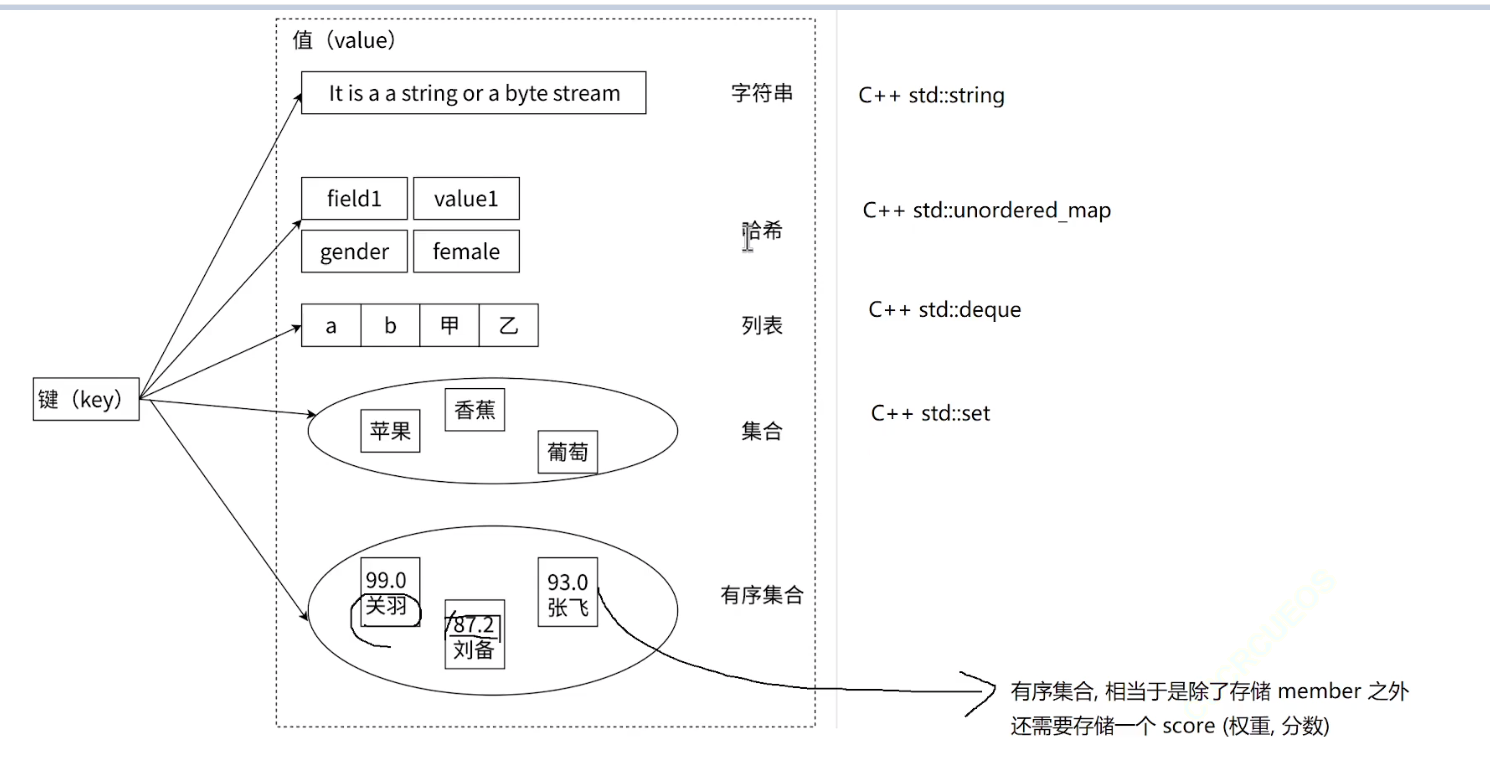

總而言之,Redis提供的哈希表容器并不一定真的是真的哈希表,而是在特點的場景下,用別的容器去實現,為了保證時間復雜度符合承諾(就是為了高效)
Redis的數據類型和內部編碼
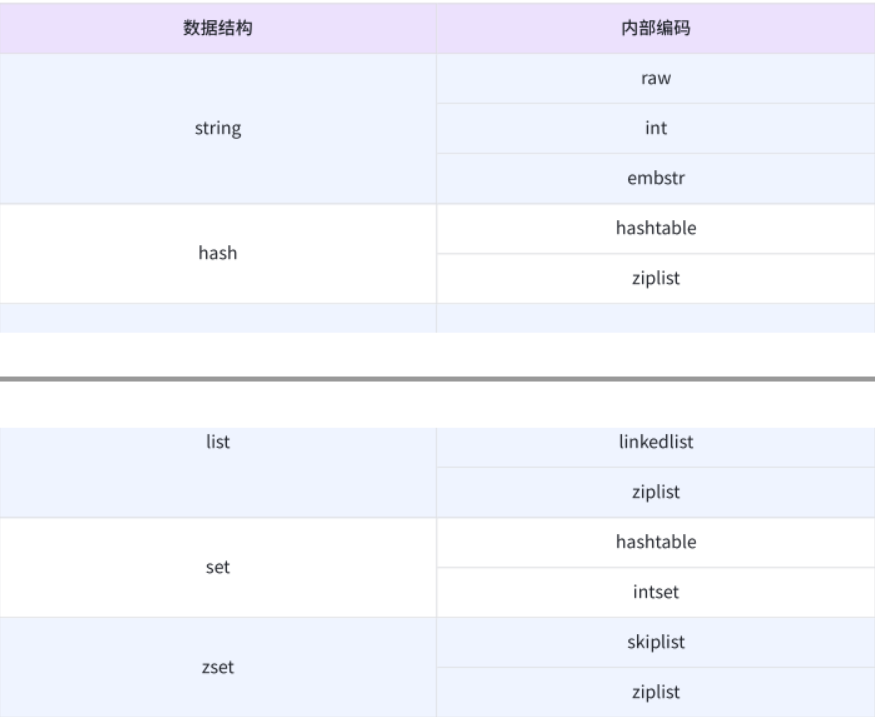
string
(由于只學過C++,這里只站在C++的角度理解Redis中的數據結構
- raw:最基本的字符串,底層就是持有一個char數組(C++)。
- int:當value是一個整數時,此時redis可能用int來保存。
- embstr:針對短字符串進行的特殊優化。
以上內部編碼方式Redis會自動適應,在使用時感知不到。
hash:
- hashtable:雖然有可能實現方式不太一樣,但是整體的思想跟C++的哈希表是一樣的。
- ziplist:壓縮列表,在哈希表元素較少的時候,可能優化成ziplist壓縮列表,就能夠節省空間。因為元素較少,所以遍歷的時候仍然能視為O(1)的時間復雜度。
為啥要壓縮,為啥要節省時間呢?
因為在key特別多的情況下,如果key對應的value都是哈希表,則對應的hash也特別多,但是每個hash又不大的情況下,就可以將這些hash壓縮,讓整體占用內存更少。
list:
- linkedlist:鏈表,就是數據結構中熟悉的那個鏈表,包括單鏈表,雙鏈表。
- ziplist:如果元素個數少,就用壓縮列表實現,因為節省空間,如果元素個數多,那就會用鏈表。
從redis3.2版本開始,引入了新的實現方式:quicklist,這個就同時兼顧了linkedlist和ziplist的優點。
可以認為quicklist就是一個鏈表,鏈表的每個元素是ziplist。這樣的折中方案把空間和效率都兼顧了。
所以quicklist就比較像C++的deque。
set:
- hashtable:這個跟前面那個講解一樣,看上面那個即可。
- intset:針對特定場景的優化:比如集合中都是一個整數,就優化成intset
zset:
-
skiplist:跳表。在鏈表的筆試題中,有一道題叫做:“復雜鏈表的復制”,除了有一個next指向下一個節點外,還有一個Random節點指向其他隨機節點。這里的跳表同理,每個節點上有多個指針域的指向,巧妙的搭配這些指針域的指向,就能做到查找時的時間復雜度O(logN)
-
ziplist:看上面的解釋
通過object encoding key來查看key對應的value的編碼方式。
比如:
set key1 1
object encoding key1,可以得到key1對應的value的編碼方式是int
單線程模型的工作過程

Redis在處理命令時雖然是一個單線程模型,為啥效率那么高,速度快呢?
(這里不是說Redis是單線程,雖然在早期版本確實是單線程,但是在后面的版本中,Redis引入了多線程來保證網絡IO,持久化等,但是處理命令時,仍然是單獨開一個線程專門處理的)
(面試題)(說Redis快的參照物是關系型數據庫:MySQL等)
- 1.redis訪問內存,MySQL訪問硬盤。
- 2.redis的核心功能比數據庫的核心功能簡單。比如針對插入刪除,數據庫的各種約束(主鍵約束,外鍵約束),在插入時,會先判斷在不在,判斷完成后,還得找個位置插入。這樣同樣又會有消耗。
- 3.單線程模型避免了不必要的線程競爭開銷。Redis的每個基本操作都是短平快的,就是簡單地操作內存,沒多大消耗CPU,就算搞個多線程提升不大(具體得看業務場景)。
- 4.處理網絡IO時,使用了epoll的I/O多路復用。一個線程可以管理多個socket,對TCP來說,當客戶端到來時,都要給該客戶端設置一個socket,并且在很多情況下,大部分客戶端的通信并沒有那么頻繁,而是僅僅有少量客戶端是活躍的。但是在傳統的IO時,是為一個客戶端創建一個線程專門服務的。而大部分客戶端只發了幾次數據就不活躍了。此時線程也會被阻塞住,而線程創建,銷毀,調度都是消耗性能的操作。所以使用I/O多路服用,讓一個線程同時監聽處理多個socket,大大提高了效率。(但是,一個線程監聽多個socket是只有當這些socket只有少量是活躍的時候才能這樣做。否則這些socket如果同時非常活躍,就可能導致線程忙不過來。打游戲+和女朋友打電話的例子)
)


)

![56.[前端開發-前端工程化]Day03-webpack構建工具](http://pic.xiahunao.cn/56.[前端開發-前端工程化]Day03-webpack構建工具)




![[machine learning] Transformer - Attention (一)](http://pic.xiahunao.cn/[machine learning] Transformer - Attention (一))








