摘要
圖像transformer(Image Transformer)最近在自然圖像理解方面取得了顯著進展, 無論是使用監督(ViT、DeiT等)還是自監督(BEiT、MAE等)預訓練技術。在本文中,我們提出了DiT,一種自監督預訓練的文檔圖像transformer模型,利用大規模未標記的文本圖像進行文檔AI任務的訓練。由于缺乏人工標注的文檔圖像,迄今為止并不存在任何監督的對應模型,因此該方法至關重要。我們將DiT作為骨干網絡,應用于各種基于視覺的文檔AI任務,包括文檔圖像分類、文檔布局分析、表格檢測以及OCR文本檢測。實驗結果表明,自監督預訓練的DiT模型在這些下游任務中取得了新的最先進的結果,例如文檔圖像分類(91.11 → 92.69)、文檔布局分析(91.0 → 94.9)、表格檢測(94.23 → 96.55)和OCR文本檢測(93.07 → 94.29)。代碼和預訓練模型可以在https://aka.ms/msdit獲取。
CCS概念
? 計算方法 → 計算機視覺
關鍵詞
文檔圖像transformer、自監督預訓練、文檔圖像分類、文檔布局分析、表格檢測、文本檢測、OCR
以下是第一部分“Introduction”的翻譯:
1 引言
自監督預訓練技術在過去幾年已經成為文檔AI的事實標準做法[10],其中圖像、文本和布局信息通常使用統一的transformer架構[2, 19, 21, 25, 28, 32, 33, 38, 41–44, 48]聯合訓練。在所有這些方法中,預訓練文檔AI模型的典型流程通常從基于視覺的理解開始,例如光學字符識別(OCR)或文檔布局分析,這仍然在很大程度上依賴于具有人工標注訓練樣本的監督計算機視覺骨干模型。盡管在基準數據集上取得了良好的結果,但這些視覺模型在實際應用中往往面臨由于領域轉移和訓練數據中的模板/格式不匹配而導致的性能差距。這種準確性回退[26, 46]對預訓練模型及下游任務也產生了重要影響。因此,研究如何利用自監督預訓練來增強文檔圖像理解的骨干網絡是不可避免的,這能夠更好地促進不同領域的通用文檔AI模型。
圖像transformer[3, 9, 12, 13, 17, 31, 36, 47]最近在自然圖像理解方面取得了巨大成功,包括分類、檢測和分割任務,無論是在ImageNet上的監督預訓練,還是自監督預訓練。與CNN基于預訓練的模型相比,預訓練的圖像transformer模型在相似的參數規模下能夠實現可比甚至更好的性能。然而,對于文檔圖像理解,目前沒有像ImageNet這樣的常用大規模人工標注基準,這使得大規模監督預訓練變得不切實際。盡管弱監督方法已被用于創建文檔AI基準數據集[26, 27, 45, 46],這些數據集的領域通常來自共享相似模板和格式的學術論文,這些與實際世界中的文檔(如表格、發票/收據、報告等)存在差異,見圖1所示。這可能導致通用文檔AI問題的結果不盡如人意。因此,使用來自通用領域的大規模未標記數據對文檔圖像骨干網絡進行預訓練至關重要,這能夠支持多種文檔AI任務。

為此,我們提出了DiT,一種自監督預訓練的文檔圖像transformer模型,用于通用文檔AI任務,且不依賴于任何人工標注的文檔圖像。受最近提出的BEiT模型[3]的啟發,我們采用了類似的預訓練策略,使用文檔圖像作為輸入。輸入的文本圖像首先被調整為224 × 224的大小,然后圖像被切分成一系列16 × 16的圖塊,這些圖塊作為輸入傳遞給圖像transformer。與BEiT模型不同,后者的視覺token來源于DALL-E中的離散VAE[34],我們重新訓練了離散VAE(dVAE)模型,使用大規模的文檔圖像,以便生成的視覺token更加與文檔AI任務相關。預訓練目標是基于腐蝕的輸入文檔圖像,使用BEiT中的掩蔽圖像建模(Masked Image Modeling, MIM)來恢復dVAE的視覺token。通過這種方式,DiT模型不依賴于任何人工標注的文檔圖像,而是僅利用大規模未標記數據來學習文檔圖像內各個圖塊之間的全局關系。
我們在四個公開的文檔AI基準數據集上評估了預訓練的DiT模型,包括用于文檔圖像分類的RVL-CDIP數據集[16]、用于文檔布局分析的PubLayNet數據集[46]、用于表格檢測的ICDAR 2019 cTDaR數據集[15],以及用于OCR文本檢測的FUNSD數據集[22]。實驗結果表明,預訓練的DiT模型超越了現有的監督和自監督預訓練模型,并在這些任務上達到了新的最先進水平。
本文的貢獻總結如下:
- 我們提出了DiT,一種自監督預訓練的文檔圖像transformer模型,可以利用大規模未標記的文檔圖像進行預訓練。
- 我們將預訓練的DiT模型作為骨干網絡,應用于多種文檔AI任務,包括文檔圖像分類、文檔布局分析、表格檢測以及OCR文本檢測,并取得了新的最先進結果。
- 代碼和預訓練模型公開可用,網址為 https://aka.ms/msdit。
2 相關工作
圖像transformer(Image Transformer)最近在計算機視覺問題上取得了顯著進展,包括分類、目標檢測和分割等。[12]首次將標準transformer直接應用于圖像,修改最少。他們將圖像切分為16 × 16的圖塊,并將這些圖塊的線性嵌入序列作為輸入提供給名為ViT的transformer。ViT模型在圖像分類任務中進行了監督訓練,并超越了ResNet基準。[36]提出了數據高效的圖像transformer和通過注意力蒸餾的DeiT,它僅依賴于ImageNet數據集進行監督預訓練,并且與ViT相比,取得了最先進的結果。[31]提出了一種層次化的transformer,其表示通過移動窗口計算。移動窗口方案通過將自注意力計算限制在不重疊的局部窗口中,帶來了效率,同時也允許跨窗口連接。
除了監督預訓練的模型,[8]訓練了一種序列transformer,稱為iGPT,用于自回歸地預測像素,而不考慮2D輸入結構的知識,這是圖像transformer自監督預訓練的首次嘗試。此后,圖像transformer的自監督預訓練成為計算機視覺領域的熱門話題。[7]提出了DINO,它使用自蒸餾技術對圖像transformer進行預訓練,并且無需標簽。[9]提出了基于Siamese網絡的MoCov3,用于自監督學習。最近,[3]采用了類似BERT的預訓練策略,首先將原始圖像轉換為視覺token,然后隨機掩蔽一些圖像塊并將它們輸入骨干transformer。類似于掩蔽語言建模,他們提出了一個掩蔽圖像建模任務作為預訓練目標,并取得了最先進的性能。[47]提出了一個自監督框架iBOT,它可以通過在線tokenizer執行掩蔽預測。在線tokenizer可以與MIM目標共同學習,并且不需要預先訓練tokenizer的多階段流水線。

基于視覺的文檔AI 通常指利用計算機視覺模型進行文檔分析的任務,例如OCR(光學字符識別)、文檔布局分析和文檔圖像分類。由于該領域缺乏大規模人工標注的數據集,現有的方法通常基于使用ImageNet/COCO數據集預訓練的ConvNets模型。然后,這些模型會繼續用任務特定的標注樣本進行訓練。據我們所知,預訓練的DiT模型是第一個用于基于視覺的文檔AI任務的大規模自監督預訓練模型。同時,它也可以進一步用于文檔AI的多模態預訓練。
3 文檔圖像transformer(DiT)
在本節中,我們首先介紹DiT的架構和預訓練過程。接著,我們描述DiT模型在不同下游任務中的應用。
3.1 模型架構
沿用ViT [12],我們使用標準的Transformer架構 [37] 作為DiT的骨干網絡。我們將文檔圖像分割成不重疊的圖塊,并獲得一系列圖塊嵌入。加上1D位置嵌入后,這些圖像圖塊被傳入一系列多頭注意力機制的Transformer塊。最后,我們將Transformer編碼器的輸出作為圖像圖塊的表示,如圖2所示。
3.2 預訓練
受到BEiT [3] 的啟發,我們使用掩蔽圖像建模(MIM)作為我們的預訓練目標。在此過程中,圖像分別作為圖像圖塊和視覺tokens進行表示。在預訓練過程中,DiT接受圖像圖塊作為輸入,并通過輸出表示來預測視覺tokens。
像自然語言中的文本token一樣,圖像也可以通過圖像tokenizer表示為一系列離散的token。BEiT使用來自DALL-E [34] 的離散變分自編碼器(dVAE)作為圖像tokenizer,該模型在包括4億張圖像的大型數據集上進行訓練。然而,天然圖像與文檔圖像之間存在領域不匹配,這使得DALL-E的tokenizer不適用于文檔圖像。因此,為了獲得更適合文檔圖像領域的離散視覺token,我們在IIT-CDIP [24] 數據集上訓練了一個dVAE,該數據集包含4200萬張文檔圖像。
為了有效地預訓練DiT模型,我們在給定圖像圖塊序列的情況下,隨機掩蔽輸入的子集,并用特殊的token [MASK]表示。DiT編碼器通過線性投影嵌入掩蔽圖塊序列,并添加位置嵌入,接著通過一系列Transformer塊進行上下文化處理。模型需要預測來自掩蔽位置的視覺token索引。與預測原始像素不同,掩蔽圖像建模任務要求模型預測通過圖像tokenizer獲得的離散視覺token。
3.3 微調
我們在四個文檔AI基準測試上微調了模型,包括用于文檔圖像分類的RVL-CDIP數據集、用于文檔布局分析的PubLayNet數據集、用于表格檢測的ICDAR 2019 cTDaR數據集,以及用于文本檢測的FUNSD數據集。這些基準數據集可以形式化為兩種常見任務:圖像分類和目標檢測。
圖像分類:
對于圖像分類,我們使用平均池化來聚合圖像圖塊的表示。接下來,我們將全局表示傳入一個簡單的線性分類器。
目標檢測:
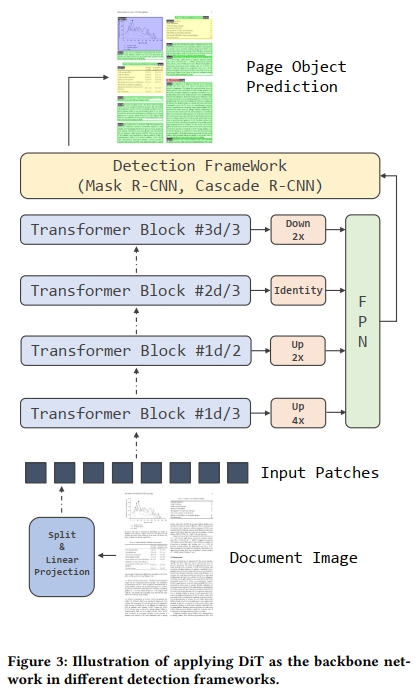
對于目標檢測,如圖3所示,我們利用Mask R-CNN [18] 和Cascade R-CNN [5] 作為檢測框架,并使用基于ViT的模型作為骨干網絡。我們的代碼基于Detectron2 [39] 實現。根據[14, 29],我們在四個不同的Transformer塊上使用分辨率修改模塊,將單尺度ViT適應為多尺度FPN。設𝑑為總塊數,1𝑑/3塊通過2×2轉置卷積模塊進行4倍上采樣,步幅為2。對于1𝑑/2塊的輸出,我們使用一個單步幅2的2×2轉置卷積進行2倍上采樣。2𝑑/3塊的輸出不做額外操作。最后,3𝑑/3塊的輸出通過步幅為2的2×2最大池化進行2倍下采樣。
4 實驗
4.1 任務
我們在此簡要介紹第3.3節中提到的數據集。
RVL-CDIP:RVL-CDIP [16] 數據集包含400,000張灰度圖像,分為16個類別,每個類別有25,000張圖像。數據集包括320,000張訓練圖像,40,000張驗證圖像和40,000張測試圖像。16個類別包括{信件、表格、電子郵件、手寫、廣告、科學報告、科學出版物、規格、文件夾、新聞文章、預算、發票、演示文稿、問卷、簡歷、備忘錄}。評估指標是整體分類準確率。
PubLayNet:PubLayNet [46] 是一個大規模的文檔布局分析數據集。該數據集通過自動解析PubMed XML文件構建了超過360,000張文檔圖像。生成的注釋涵蓋了典型的文檔布局元素,如文本、標題、列表、圖形和表格。模型需要檢測分配元素的區域。我們使用按類別的和總體的平均精度(MAP)@交并比(IoU)[0.50:0.95]作為評估指標。
ICDAR 2019 cTDaR:cTDaR數據集 [15] 包含兩個任務,包括表格檢測和表格結構識別。在本文中,我們專注于Track A,其中提供了帶有一個或多個表格注釋的文檔圖像。該數據集包含兩個子集,一個用于檔案文檔,另一個用于現代文檔。檔案子集包括600張訓練圖像和199張測試圖像,展示了各種各樣的表格,包括手繪的會計賬本、證券交易清單、火車時刻表、生產普查等。現代子集包含600張訓練圖像和240張測試圖像,包含不同種類的PDF文件,如科學期刊、表單、財務報表等。數據集包含中英文文檔,格式多樣,包括掃描文檔圖像和數字出生格式。評估該任務的指標是精度、召回率和F1分數,這些值是根據模型排名輸出相對于不同交并比(IoU)閾值計算的。我們分別使用IoU閾值為0.6、0.7、0.8和0.9計算這些值,并將它們合并為最終的加權F1分數:
w F 1 = 0.6 F 1 0.6 + 0.7 F 1 0.7 + 0.8 F 1 0.8 + 0.9 F 1 0.9 0.6 + 0.7 + 0.8 + 0.9 w F 1 = \frac { 0 . 6 F 1 _ { 0 . 6 } + 0 . 7 F 1 _ { 0 . 7 } + 0 . 8 F 1 _ { 0 . 8 } + 0 . 9 F 1 _ { 0 . 9 } } { 0 . 6 + 0 . 7 + 0 . 8 + 0 . 9 } wF1=0.6+0.7+0.8+0.90.6F10.6?+0.7F10.7?+0.8F10.8?+0.9F10.9??
這個任務進一步要求模型將現代子集和檔案子集合并為一個整體,以獲得最終的評估結果。

FUNSD。FUNSD [22] 是一個帶有噪聲的掃描文檔數據集,標注了三個任務:文本檢測、光學字符識別(OCR)文本識別和表單理解。本文聚焦于 FUNSD 的任務 #1,旨在檢測掃描表單文檔中的文本邊界框。FUNSD 包含 199 個完全標注的表單,包含 31,485 個詞,其中訓練集包含 150 個表單,測試集包含 49 個表單。評估指標為在 IoU@0.5 下的精度、召回率和 F1 分數。
4.2 設置
預訓練設置。我們在 IIT-CDIP 測試集 1.0 [24] 上對 DiT 進行了預訓練。我們通過將多頁文檔拆分為單頁文檔來預處理數據集,獲得了 4200 萬個文檔圖像。我們還在訓練過程中引入了隨機裁剪(random resized cropping)來增強訓練數據。我們使用與 ViT base 相同的架構訓練 DiT-B 模型:一個 12 層的 Transformer,隱藏層大小為 768,注意力頭數為 12。前饋網絡的中間大小為 3072。我們還訓練了一個更大的版本 DiT-L,包含 24 層,隱藏層大小為 1024,注意力頭數為 16,前饋網絡的中間大小為 4096。
dVAE 分詞器。BEiT 借用了由 DALL-E 訓練的圖像分詞器,但該分詞器與文檔圖像數據并不匹配。因此,我們充分利用了 IIT-CDIP 數據集中的 4200 萬個文檔圖像,訓練了一個文檔 dVAE 圖像分詞器,以獲得視覺標記。與 DALL-E 圖像分詞器類似,文檔圖像分詞器具有 8192 的字典維度,圖像編碼器包含三層。每一層由一個步長為 2 的二維卷積和一個 ResNet 塊組成。因此,分詞器最終的降采樣因子為 8。在這種情況下,給定一個 112×112 的圖像,最終得到一個與 14×14 輸入補丁對齊的 14×14 離散標記圖。

我們從開源的 DALL-E 實現中實現了我們的 dVAE 代碼庫,并使用包含 4200 萬文檔圖像的整個 IIT-CDIP 數據集訓練了 dVAE 模型。新的 dVAE 分詞器通過結合 MSE 損失(用于重建輸入圖像)和困惑度損失(用于增加量化代碼本表示的使用)進行訓練。輸入圖像的大小為 224×224,我們以 5e-4 的學習率和 1e-10 的最小溫度訓練分詞器,訓練 3 個周期。我們通過從下游任務中重建文檔圖像樣本,比較我們的 dVAE 分詞器與原始的 DALL-E 分詞器,結果如圖 4 所示。我們從文檔布局分析數據集 PubLayNet 和表格檢測數據集 ICDAR 2019 cTDaR 中采樣圖像。經過 DALL-E 和我們分詞器的重建后,DALL-E 的圖像分詞器難以區分線條和標記的邊界,但我們 dVAE 的圖像分詞器更接近原始圖像,邊界更加銳利和清晰。我們確認,較好的分詞器能產生更準確的標記,能夠更好地描述原始圖像。
在獲得預訓練數據和圖像分詞器后,我們以 2048 的批次大小、1e-3 的學習率、10K 的 warmup 步數和 0.05 的權重衰減訓練 DiT 500K 步。Adam [23] 優化器的 𝛽1 和 𝛽2 分別為 0.9 和 0.999。我們在 DiT 的預訓練中采用了隨機深度 [20],深度率為 0.1,并禁用了 dropout,和 BEiT 預訓練相同。我們還在 DiT 的預訓練中應用了塊級掩碼,40% 的補丁被掩蓋,像 BEiT 一樣。
在 RVL-CDIP 上的微調
我們在 RVL-CDIP 上評估了預訓練的 DiT 模型和其他圖像骨干網絡,用于文檔圖像分類。我們對圖像 Transformer 進行了 90 個周期的微調,批次大小為 128,學習率為 1e-3。在所有設置中,我們使用 RandomResizedCrop 操作將原始圖像調整為 224 × 224。
在 ICDAR 2019 cTDaR 上的微調
我們在 ICDAR 2019 數據集上評估了預訓練的 DiT 模型和其他圖像骨干網絡,用于表格檢測。由于物體檢測任務的圖像分辨率要比分類任務大得多,因此我們將批次大小限制為 16。對于檔案和現代子集,學習率分別設置為 1e-4 和 5e-5。在初步實驗中,我們發現直接使用檔案子集中的原始圖像進行微調 DiT 會導致次優性能,因此我們應用了 OpenCV [4] 實現的自適應圖像二值化算法來二值化圖像。圖 5 中展示了該預處理的示例。在訓練過程中,我們應用了 DEFT [6] 中使用的數據增強方法,作為多尺度訓練策略。具體來說,輸入圖像以 0.5 的概率裁剪成一個隨機矩形補丁,然后再次調整大小,使得最短邊至少為 480 像素,最多為 800 像素,最長邊不超過 1333 像素。
在 PubLayNet 上的微調
我們在 PubLayNet 數據集上評估了預訓練的 DiT 模型和其他圖像骨干網絡,用于文檔布局分析。與 ICDAR 2019 cTDaR 數據集類似,批次大小為 16,基礎版的學習率為 4e-4,大版本的學習率為 1e-4。我們還使用了 DETR [6] 中的數據增強方法。
在 FUNSD 上的微調
我們使用相同的目標檢測框架對預訓練的 DiT 模型和其他骨干網絡進行微調,處理 FUNSD 中的文本檢測任務。在文檔布局分析和表格檢測中,我們使用錨框大小 [32, 64, 128, 256, 512],因為檢測區域通常是段落級別的。與文檔布局分析不同,文本檢測的目標是定位文檔圖像中的較小物體,通常是單詞級別。因此,在檢測過程中,我們使用錨框大小 [4, 8, 16, 32, 64]。批次大小設置為 16,基礎版的學習率為 1e-4,大版本的學習率為 5e-5。
我們選擇的圖像骨干模型作為基線,其參數量與我們的 DiT-B 相當。包括兩種類型:CNN 和圖像 Transformer。對于基于 CNN 的模型,我們選擇 ResNext101-32×8d [40]。對于圖像 Transformer,我們選擇 DeiT [36]、BEiT [3] 和 MAE [17] 的基礎版,這些模型是在 ImageNet-1K 數據集上預訓練的,輸入尺寸為 224×224。我們重新運行了所有基線模型的微調。
4.3 結果
RVL-CDIP
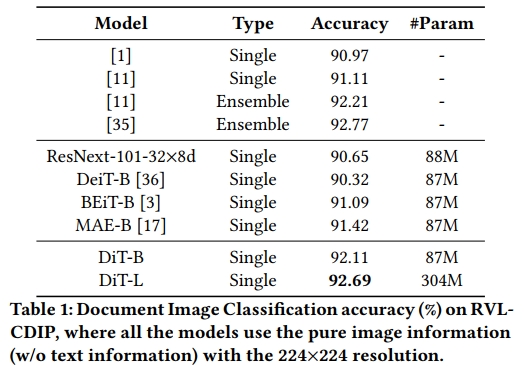
表格 1 顯示了在 RVL-CDIP 數據集上的文檔圖像分類結果。為了進行公平比較,表中方法僅使用數據集中的圖像信息。DiT-B 顯著優于所有選定的單模型基線。由于 DiT 與其他圖像 Transformer 基線共享相同的模型結構,因此較高的得分表明我們的文檔特定預訓練策略的有效性。更大的版本 DiT-L 在單模型設置下與之前的 SOTA 集成模型得分相當,這進一步突顯了它在文檔圖像建模上的能力。
PubLayNet
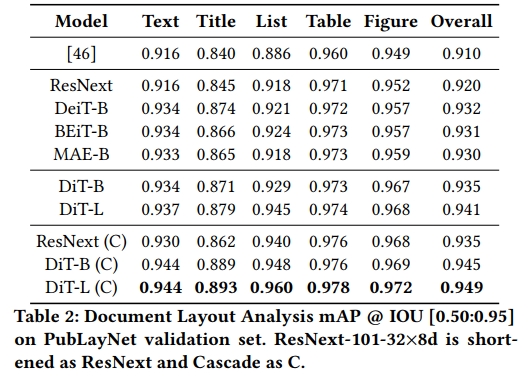
表格 2 顯示了在 PubLayNet 數據集上的文檔布局分析結果。由于該任務具有大量的訓練和測試樣本,并且需要對常見文檔元素進行綜合分析,因此清楚地展示了不同圖像 Transformer 模型的學習能力。可以觀察到,DeiT-B、BEiT-B 和 MAE-B 明顯優于 ResNeXt-101,而 DiT-B 更強于這些強大的圖像 Transformer 基線。根據結果,改進主要來自列表和圖形類別,并且在 DiT-B 的基礎上,DiT-L 提供了更高的 mAP 分數。我們還調查了不同目標檢測算法的影響,結果表明更先進的檢測算法(在我們的案例中為 Cascade R-CNN)可以將模型性能提升到更高的水平。我們還將 Cascade R-CNN 應用于 ResNeXt-101-32×8d 基線,結果表明 DiT 在基礎版和大版設置下,分別超越了其 1% 和 1.4% 的絕對得分,表明 DiT 在不同檢測框架下的優勢。
ICDAR 2019 cTDaR
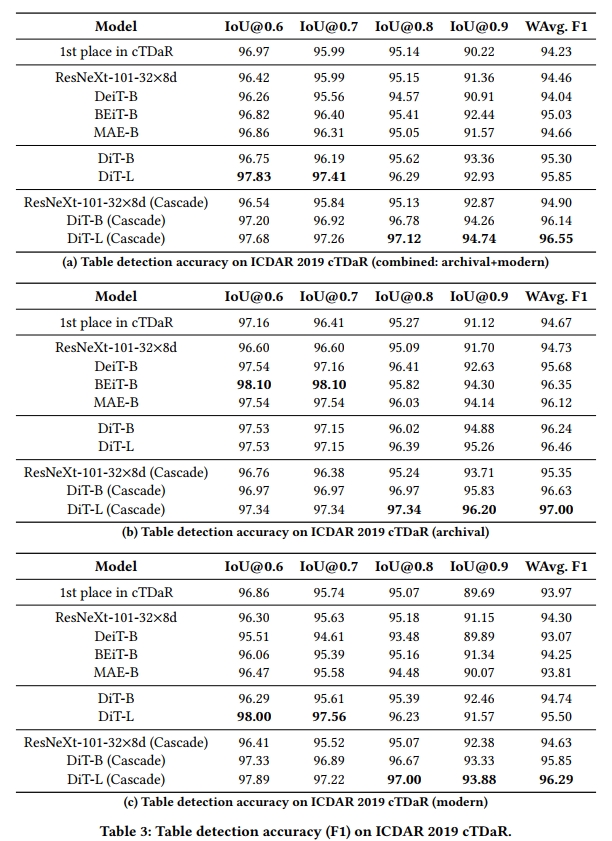
表格 3 顯示了在 ICDAR 2019 cTDaR 數據集上的表格檢測結果。該數據集相對較小,旨在評估低資源場景下模型的少樣本學習能力。我們首先分別分析模型在檔案子集和現代子集上的性能。在表格 3b 中,DiT 超越了除 BEiT 外的所有基線。這是因為在 BEiT 的預訓練中,它直接使用了 DALL-E 的 dVAE,后者是在包含 400M 圖像的龐大數據集上訓練的,并且包括多種顏色。而 DiT 的圖像分詞器是用灰度圖像訓練的,可能對于帶有顏色的歷史文檔圖像不夠充分。在將 Mask R-CNN 替換為 Cascade R-CNN 后,我們也觀察到類似于 PubLayNet 設置的改進,DiT 仍然顯著超越其他基線。類似的結論也適用于表格 3c 中的現代子集。我們進一步將兩個子集的預測結合成一個單一集合。結果如表格 3a 所示,DiT-L 在所有 Mask R-CNN 方法中取得了最高的 wF1 分數,展示了 DiT 在不同文檔類別中的多樣性。值得注意的是,IoU@0.9 的指標明顯更好,這意味著 DiT 具有更好的細粒度目標檢測能力。在所有三個設置下,我們通過最佳模型和 Cascade R-CNN 檢測算法,將 SOTA 結果提升了超過 2%(從 94.23 提升到 96.55)的絕對 wF1 分數。
FUNSD(文本檢測)
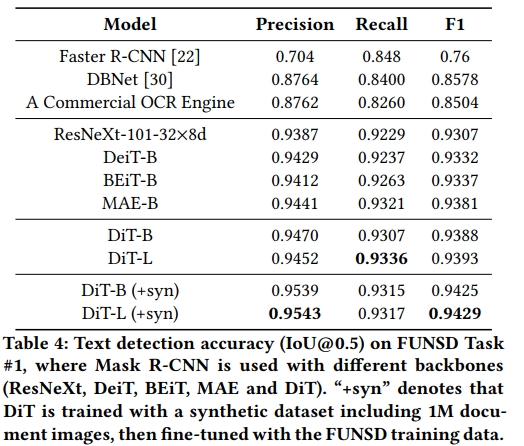
表格 4 顯示了在 FUNSD 數據集上的文本檢測結果。由于 OCR 的文本檢測一直是長期存在的實際問題,我們從一個流行的商業 OCR 引擎中獲取了按字檢測的結果,以設置一個高水平的基準。此外,DBNet [30] 是一個廣泛使用的文本檢測模型,用于在線 OCR 引擎,我們還使用 FUNSD 訓練數據對預訓練的 DBNet 模型進行了微調,并評估了其準確性。兩者在 IoU@0.5 上都達到了約 0.85 的 F1 分數。接下來,我們使用 Mask R-CNN 框架來比較不同的骨干網絡(CNN 和 ViT),包括 ResNeXt-101、DeiT、BEiT、MAE 和 DiT。結果顯示,由于先進的模型設計和更多的參數,基于 CNN 和 ViT 的文本檢測模型顯著優于基線模型。我們還觀察到,DiT 模型相比其他模型取得了新的 SOTA 結果。最后,我們進一步用包含 100 萬個文檔圖像的合成數據集訓練 DiT 模型,最終 DiT-L 模型取得了 0.9429 的 F1 分數。
5 結論與未來工作
本文提出了 DiT,一個自監督的基礎模型,用于通用的文檔 AI 任務。DiT 模型通過大規模未標注的文檔圖像進行預訓練,這些圖像涵蓋了各種模板和格式,非常適合不同領域下游的文檔 AI 任務。我們在多個基于視覺的文檔 AI 基準數據集上評估了預訓練的 DiT,包括表格檢測、文檔布局分析、文檔圖像分類和文本檢測。實驗結果表明,DiT 在各方面超越了幾種強大的基線模型,并取得了新的 SOTA 性能。我們將公開預訓練的 DiT 模型,以促進文檔 AI 研究。
對于未來的研究,我們將使用更大規模的數據集對 DiT 進行預訓練,進一步推動文檔 AI 中的 SOTA 結果。同時,我們還將 DiT 集成到多模態預訓練中,作為視覺豐富的文檔理解的基礎模型,例如下一個基于布局的模型如 LayoutLM,其中統一的基于 Transformer 的架構可能足以同時處理 CV 和 NLP 應用中的文檔 AI。

)
![【原創開發】無印去水印[特殊字符]短視頻去水印工具[特殊字符]支持一鍵批量解析](http://pic.xiahunao.cn/【原創開發】無印去水印[特殊字符]短視頻去水印工具[特殊字符]支持一鍵批量解析)
 -- qemu-arm使用)
)

??:無需假設分布的統計推斷工具)
)
)

)




)
圖像與通道拼接函數-----水平拼接(橫向連接)兩個輸入矩陣(GMat 類型)函數concatHor())

![[Verilog]跨時鐘域數據傳輸解決方案](http://pic.xiahunao.cn/[Verilog]跨時鐘域數據傳輸解決方案)
