一、存儲引擎
1. MySQL體系結構
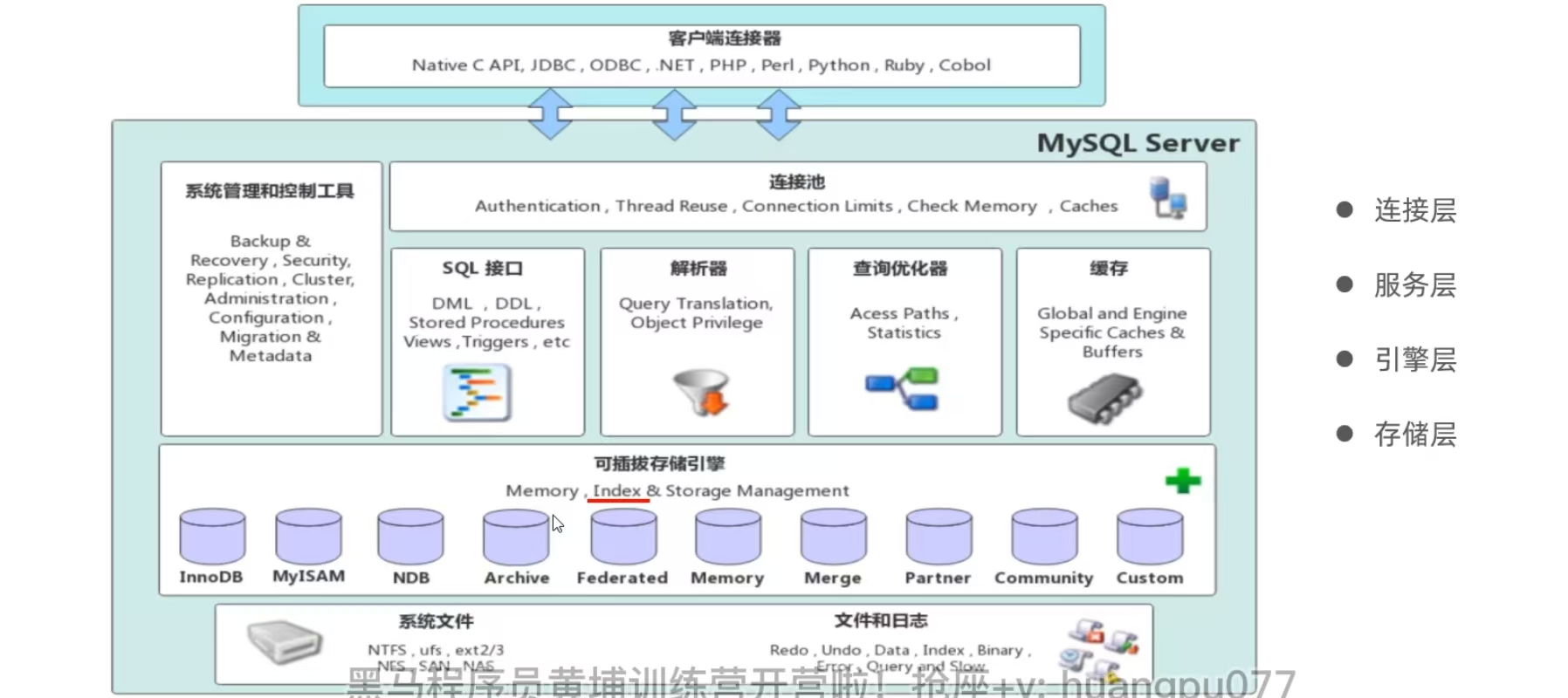
連接層:
?最上層是一些客戶端和鏈接服務,主要完成一些類似于連接處理、授權認證、及相關的安全方案。服務器也會為安全接入的每個客戶端驗證它所具有的操作權限
服務層:
第二層架構主要完成大多數的核心服務功能,如SQL接口,并完成緩存的查詢,SQL的分析和優化,部分內置函數的執行。所有跨存儲引擎的功能也在這一層實現,如過程、函數等
引擎層:
存儲引擎真正的負責了MySQL中數據的存儲和提取,服務器通過API和存儲引擎進行通信。不同的存儲引擎具有不同的功能,這樣我們可以根據的需要,來選取合適的存儲引擎
存儲層:
主要是將數據存儲在文件系統之上,并完成與存儲引擎的交互
2. 存儲引擎簡介
存儲引擎就是存儲數據、建立索引、更新/查詢數據等技術的實現方式。存儲引擎是基于表的,而不是基于庫的,所以存儲引擎也可被成為表類型。
查看所有的存儲引擎:
show engines;
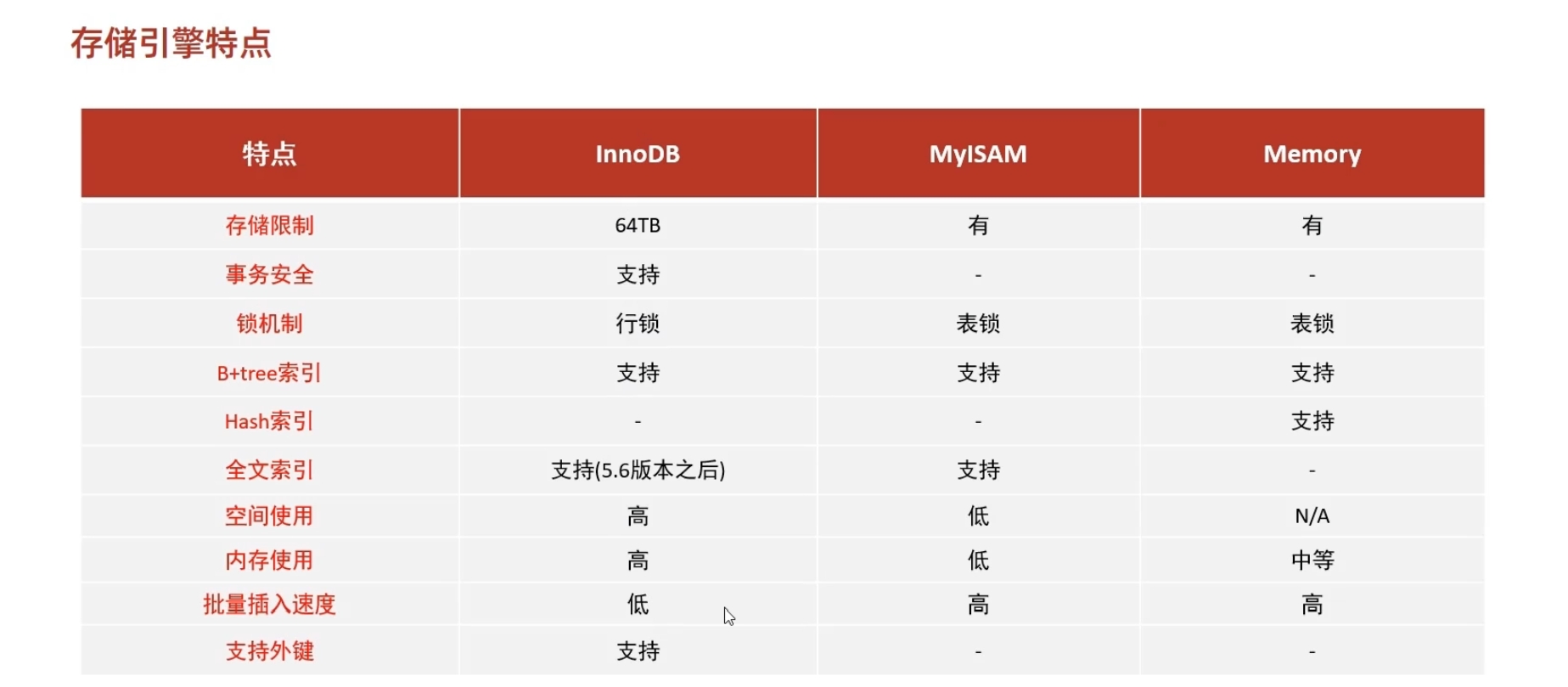
3. 存儲引擎特點
InnoDB
InnoDB是一種兼顧高可靠性和高性能的通用存儲引擎,在mysql5.5之后,InnDB是默認的mysql存儲引擎。
特點:
- DML操作遵循ACID模型,支持事務;
- 行級鎖,挺高并發訪問性能;
- 支持外鍵FOREIGN KEY約束,保證數據的完整性和正確性;
文件:
xxx.ibd:xxx代表的是表名,innodb引擎的每張表都會對應一個這樣的一個表空間文件(.ibd),存儲該表的表結構(frm、sdi)、數據和索引。參數:innodb_file_per_table開啟時,是這樣的
ibd2sdi xxx.ibd? ?#可以查看表結構,在文件所在目錄執行此命令
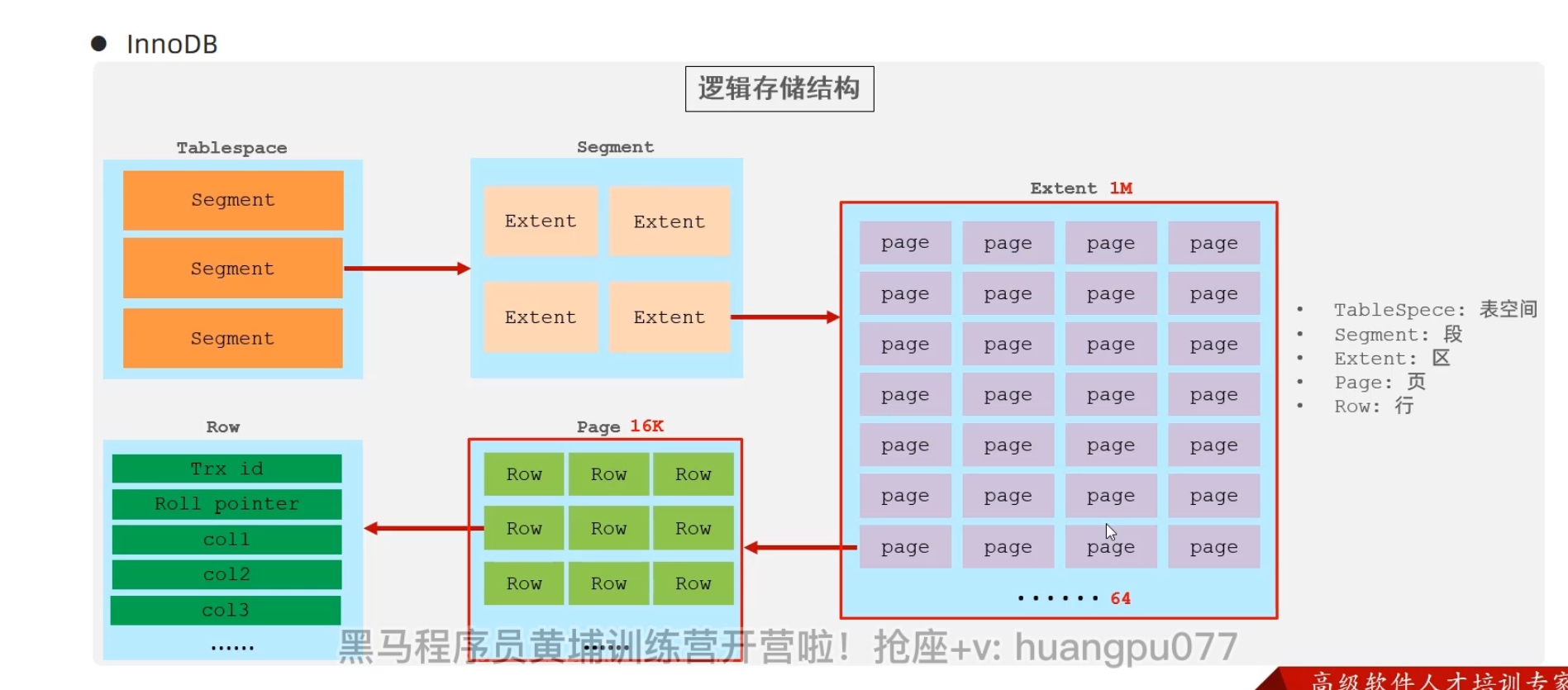
邏輯存儲結構:
MyISAM
是mysql早期默認的存儲引擎,對應目錄文件有.myd(存放數據)、.myi(索引)、.sdi(表結構)后綴的
特點:
- 不支持事務,不支持外鍵
- 支持表鎖,不支持行鎖
- 訪問速度快
Memory
Memory引擎的表數據是存儲在內存中的,由于收到硬件問題、或斷電問題的影響,只能將這些表作為臨時表或緩存使用。
特點:
- 訪問速度快
- hash索引(默認)
文件:
xxx.sdi:存儲表結構信息
4. 存儲引擎選擇
在選擇存儲引擎時,應該根據應用系統的特點選擇合適的存儲引擎。對于復雜的應用系統,還可以根據實際情況選擇多種存儲引擎進行組合。
- InnoDB:是mysql的默認存儲引擎,支持事務、外鍵。如果應用對事務的完整性有比較高的要求,在并發條件下要求數據的一致性,數據操作除了插入和查詢之外,還包含很多的更新、刪除操作,那么InnoDB存儲引擎是比較合適的選擇
- MyISAM:如果應用是以讀操作和插入操作為主,只有很少的更新和刪除操作,并且對事務的完整性、并發性不是很高,那么選擇這個引擎是非常合適的。用mongodb替代
- MEMORY:將所有數據保存在內存中,訪問速度快,通常用于臨時表及緩存。MEMORY的缺陷就是對表的大小有限制,太大的表無法緩存在內存中,而且無法保障數據的安全性。用redis替代
二、索引
1. 索引概述
索引(index)是幫助MySQL高效獲取數據的數據結構(有序)。在數據之外,數據庫系統還維護著滿足特定查找算法的數據結構,這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查找算法,這種數據結構就是索引。

2. 索引結構
MySQL的索引是在存儲引擎層實現的,不同的存儲引擎有不同的結構,主要包含以下幾種:

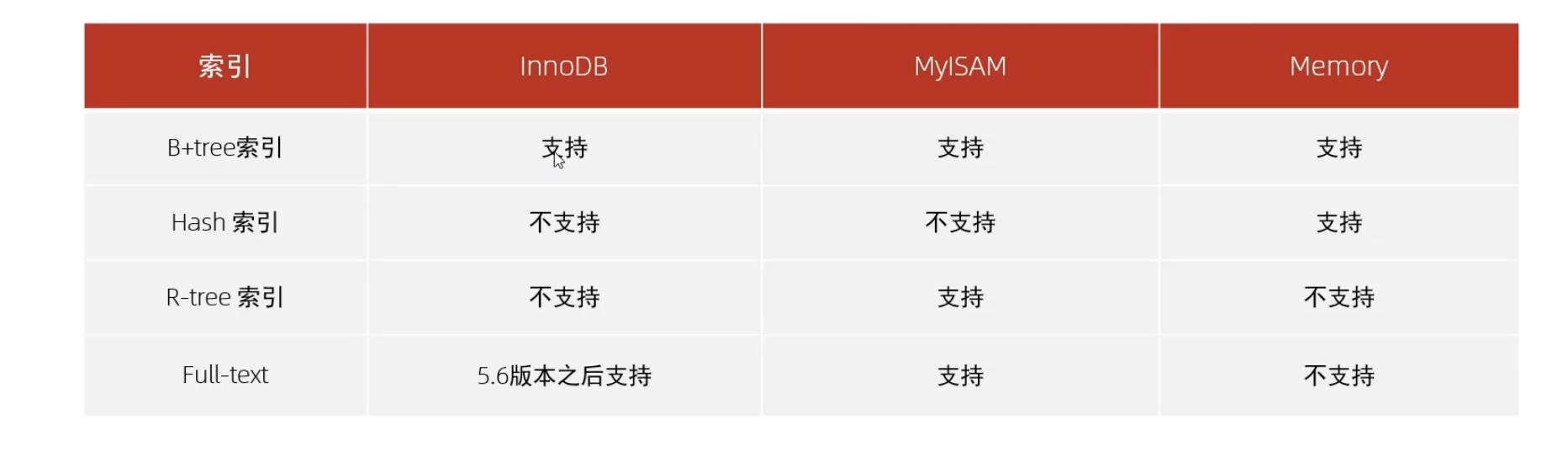 ?我們平常所說的索引,如果沒有特別指明,都是指B+樹結構組織的索引。
?我們平常所說的索引,如果沒有特別指明,都是指B+樹結構組織的索引。
二叉樹缺點:順序插入時,會形成一個鏈表,查詢性能大大降低。大數據量情況下,層級較深,檢索速度慢。
紅黑樹:比不平衡二叉樹好一點,但是,大數據量情況下,層級較深,檢索速度慢。
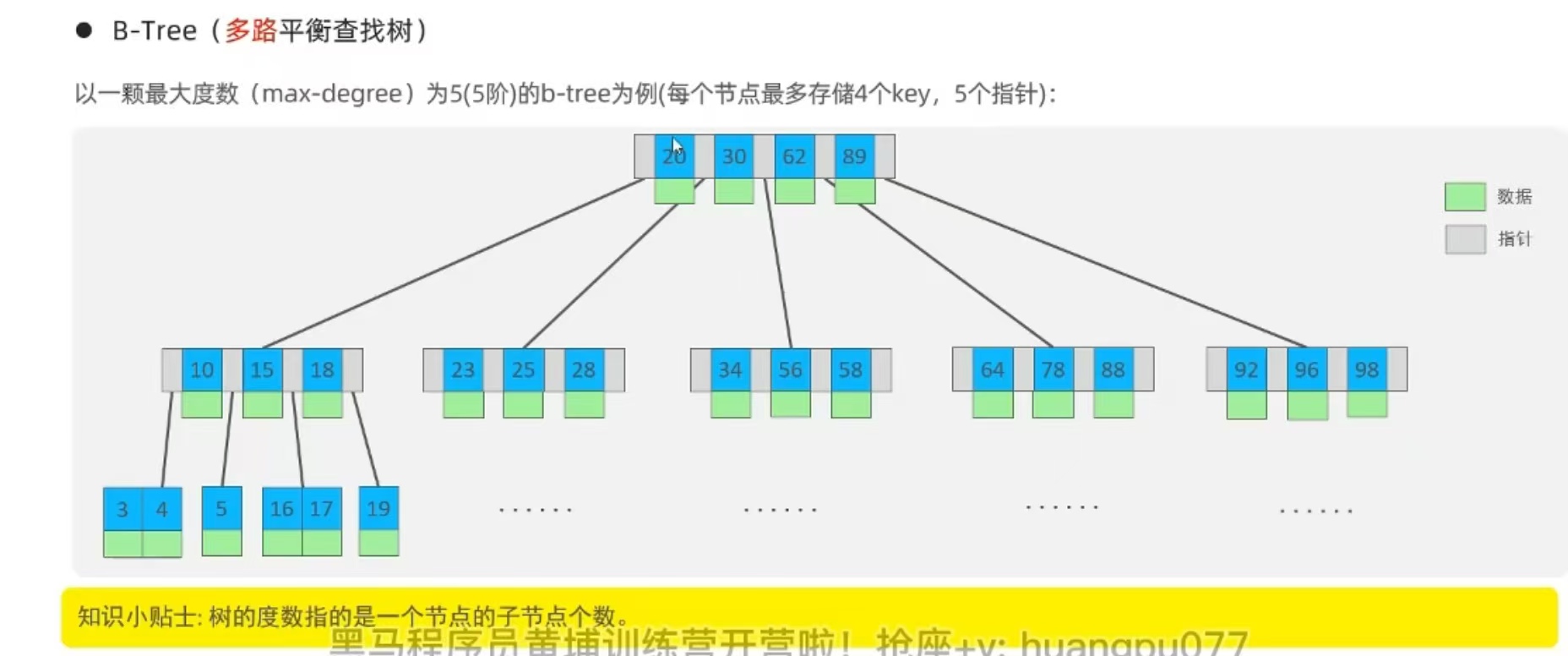
B-Tree(多路平衡查找樹)?
?B+Tree
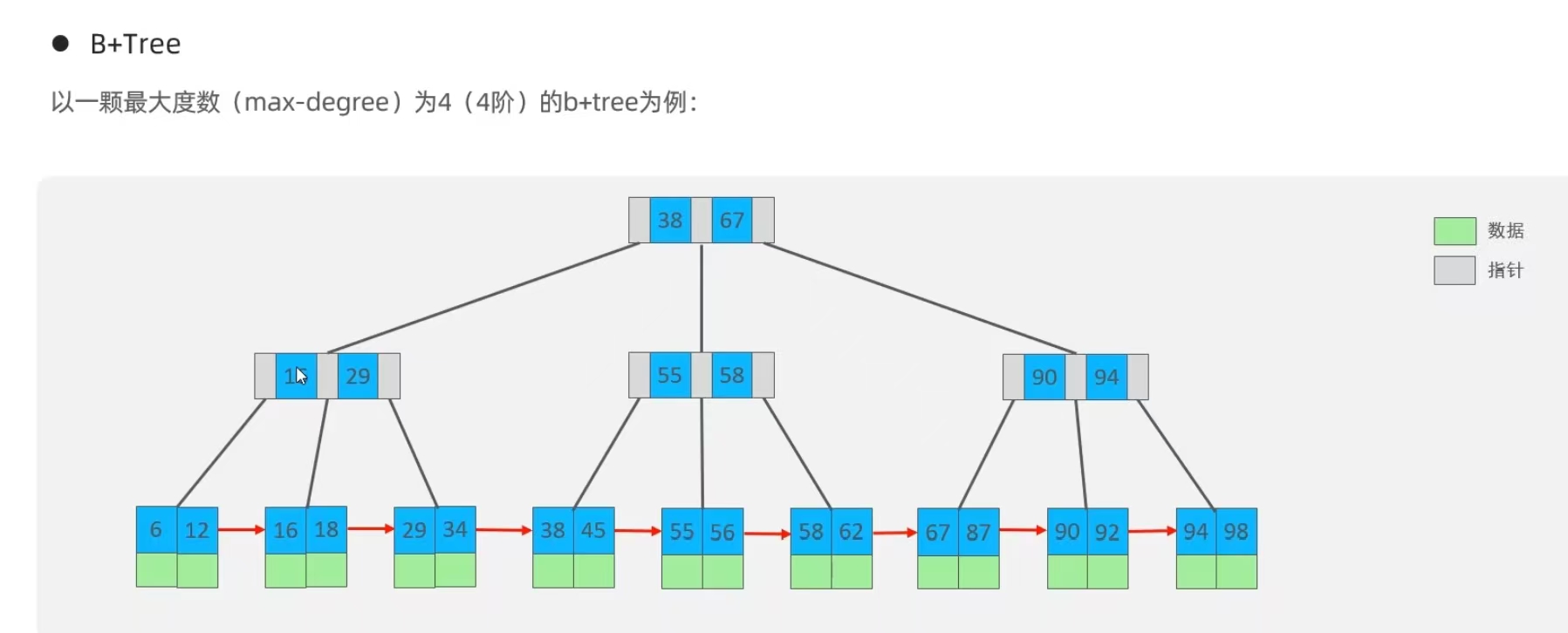
相對于B-Tree區別:
1)所有的數據都會出現在葉子節點
2)葉子節點形成一個單向鏈表
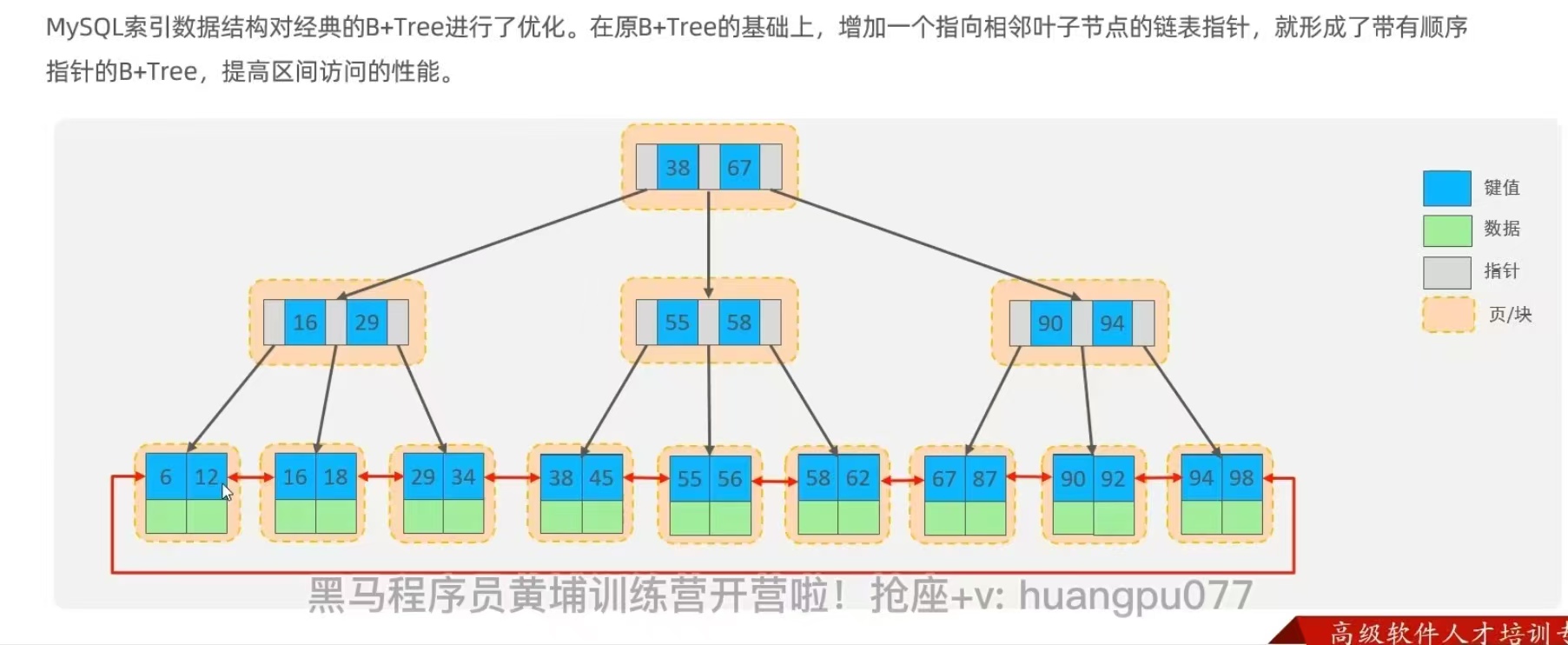
MySQL索引數據結構對經典的B+Tree進行了優化。在原有B+Tree的基礎上,增加一個指向相鄰葉子節點的鏈表指針,就形成了帶有順序指針的B+Tree,提高區間訪問的性能。
Hash結構
哈希索引就是采用一定的hash算法,將鍵值換算成新的hash值,映射到對應的槽位上,然后存儲在hash表中。如果兩個(或多個)鍵值,映射到一個相同的槽位上,他們就產生了hash沖突(也稱為hash碰撞),可以通過鏈表來解決。
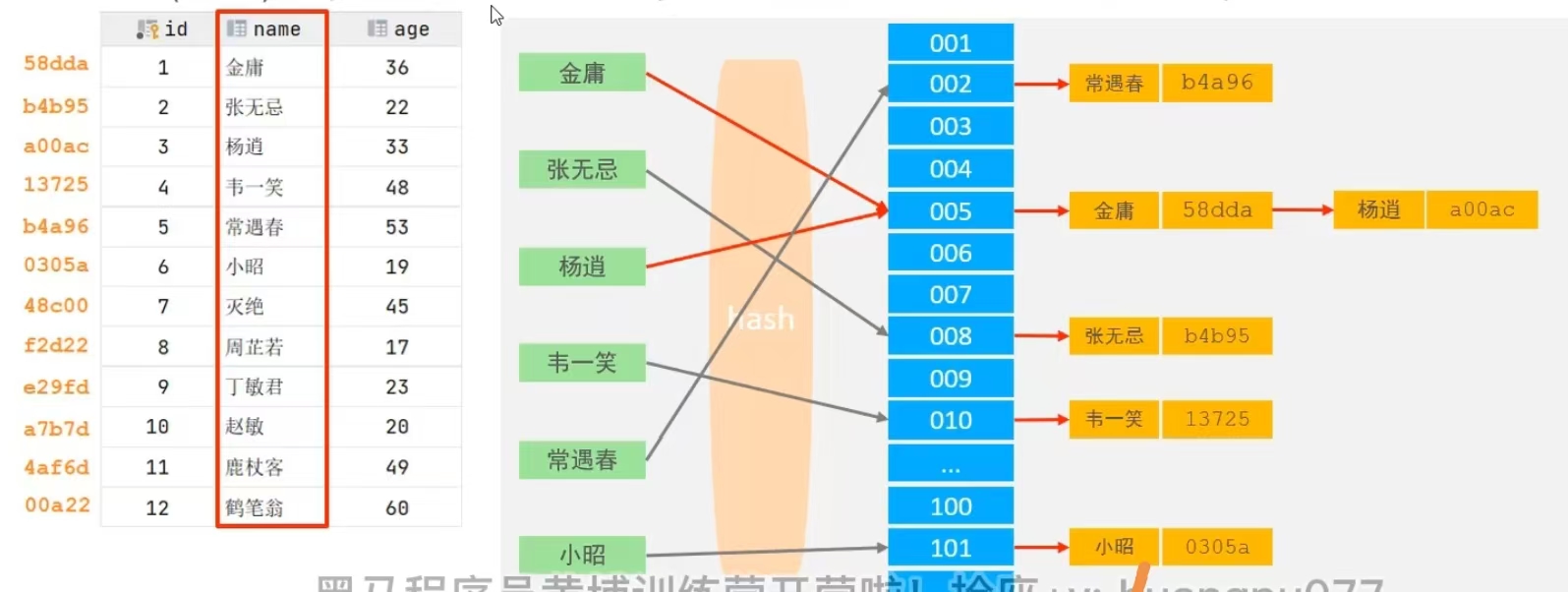
如上圖所示:id是主鍵,現在我們要為name字段創建一個哈希索引的數據結構,將算出這張表每行數據的哈希值,拿到name字段的所有值,通過哈希函數計算每個name值落在哪個哈希表的槽位上,同時解決哈希沖突。
?哈希索引特點:
- ?哈希索引只能用于等值比較,不支持范圍查詢
- 無法利用索引完成排序操作
- 查詢效率高,通常只需要一次檢索就可以了(不存在哈希沖突的情況下),效率通常要高于B+Tree索引
在MySQL中,支持hash索引的是Memor引擎,而InnoDB中具有自適應hash功能,hash索引是存儲引擎根據B+Tree索引在指定條件下自動構建的。
面試題:為什么InnoDB存儲引擎中選擇使用B+Tree索引結構?
二叉樹會變成鏈表,紅黑樹層級多。
- 相對于二叉樹,層級更少,搜索效率高
- 對于B-Tree,無論是葉子節點還是非葉子節點,都會保存數據,若一頁的容量固定,這樣導致一頁中存儲的鍵值減少,指針跟著減少 ,要同樣保存大量數據,只能增加樹的高度,導致性能降低
- 相對hash索引,B+Tree支持范圍匹配及排序操作;
3. 索引分類

?在InnoDB存儲引擎中,根據索引的存儲形式,又可以分為以下兩種:
 ?聚集索引選取規則:
?聚集索引選取規則:
- 如果存在主鍵,主鍵索引就是聚集索引
- 如果不存在主鍵,將使用第一個唯一索引作為聚集索引
- 如果表沒有主鍵,或沒有合適的唯一索引,則InnoDB會自動生成一個rowid作為隱藏的聚集索引
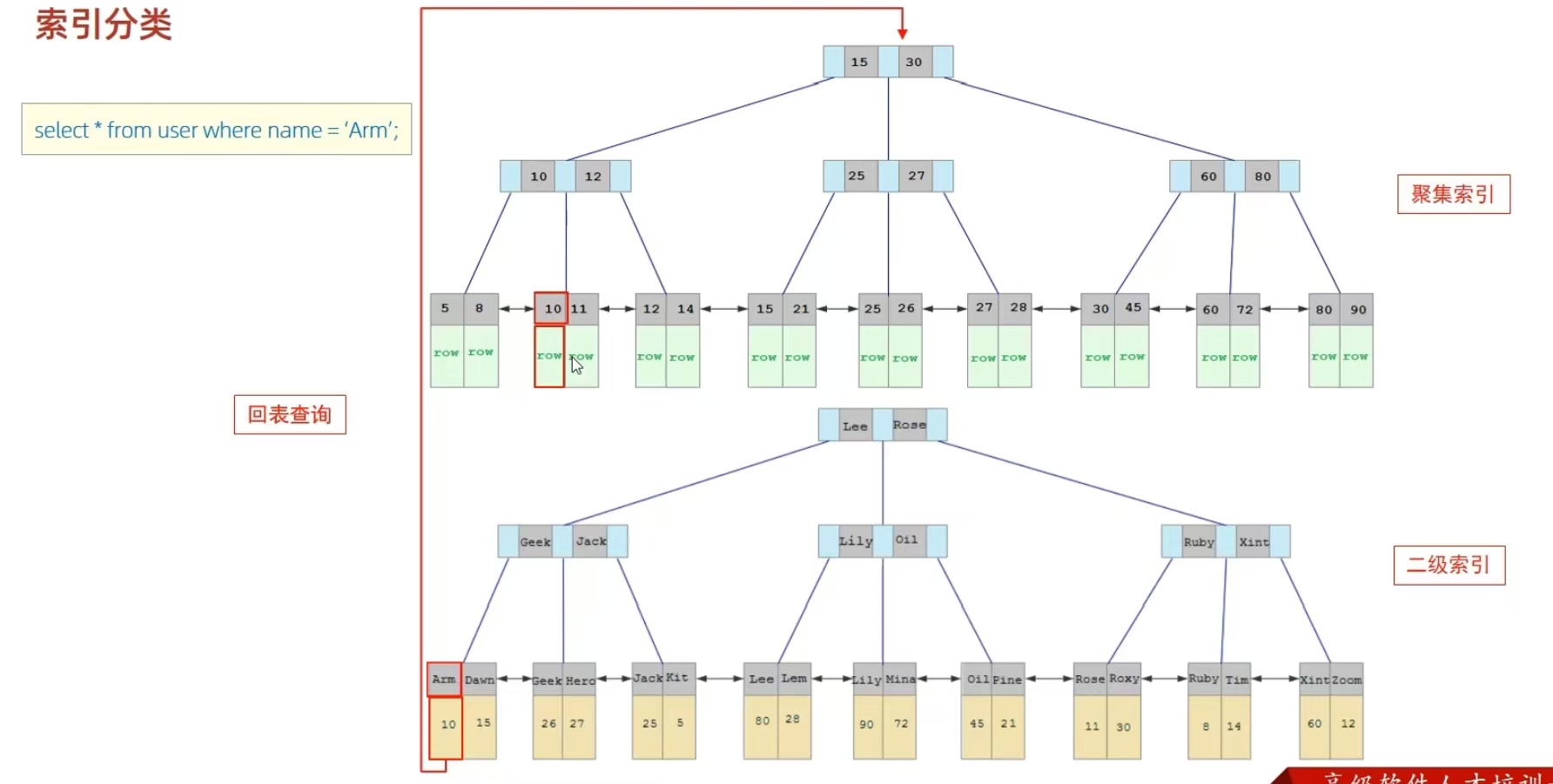
執行一條sql語句(select * from user where name='Arm';)的順序:首先走二級索引找到'Arm',然后找到葉子節點,找到對應的主鍵值,然后拿著主鍵值在聚集索引中找到那一行的數據。這一過程稱為回表查詢。
?思考1:以下sql語句,哪個執行效率高?為什么?
select * from user where id=10;
select * from user where name='Arm';
備注:id為主鍵,name字段創建的有索引;
第一條效率高,因為第二條還需要回表查詢
??思考2:InnoDB主鍵索引的B+Tree高度是多高?
假設:一行數據大小為1k,一頁中可以存儲16行這樣的數據。InnoDB的指針占用6個字節的空間,主鍵即使為bigint,占用字節數為8.
高度為2:
n*8+(n+1)*6=16*1024,算出n約為1170
1171*16=18736
高度為3:
1171*1171*16=21939856
4. 索引語法
4.1創建索引
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);
4.2查看索引
SHOW INDEX FROM table_name;
4.3刪除索引
DROP INDEX index_name?ON table_name;
5. SQL性能分析
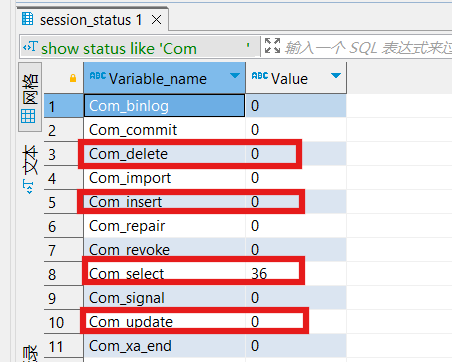
5.1?查看執行頻率
MySQL 客戶端連接成功后,通過 show [session|global] status 命令可以提供服務器狀態信息。通過以下指令,可以查看當前數據庫的INSERT、update、delete、select的訪問頻次
show status like 'Com_______';
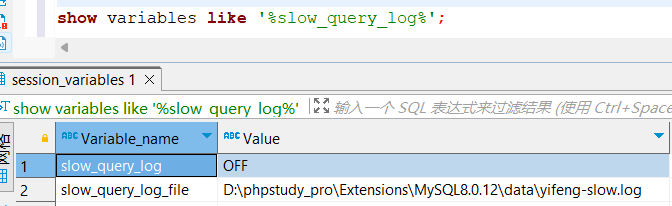
5.2?慢查詢日志
慢查詢日志記錄了所有執行時間超過指定參數(long_query_time,單位:秒,默認10秒)的所有SQL語句的日志。
show variables like '%slow_query_log%';
MySQL的慢查詢日志默認沒有開啟,需要在MySQL的配置文件(/etc/my.cnf linux)window系統在my.ini中配置如下信息:
linux
#開啟MySQL慢日志查詢開關
slow_query_log=1
#設置慢日志的時間為2秒,SQL語句執行時間超過2秒,就會視為慢查詢,記錄慢查詢日志
?slow_query_time=2
windows
#開啟MySQL慢日志查詢開關
slow_query_log=ON
#設置慢日志的時間為5秒,SQL語句執行時間超過2秒,就會視為慢查詢,記錄慢查詢日志
long_query_time=5
也可以執行sql語句,開啟慢查詢,不過臨時生效,mysql重啟后就會失效?
set global slow_query_log='ON';?
set global slow_query_log_file='D:\\kpdata\\DataBase\\Data\\mysql.log';
配置完畢之后,通過以下指令重新啟動?MySQL服務器進行測試,查看慢日志文件中記錄的信息D:\phpstudy_pro\Extensions\MySQL8.0.12\data\yifeng-slow.log。
5.3 profile詳情
通過查看慢查詢日志,可以找到耗時長的sql,但是并不能定位問題。
show?profiles能夠在做sql優化時幫助我們了解時間都耗費到哪里去了。通過have_profiling參數,能夠看到當前mysql是否支持profiles操作:
show variables like '%profil%';
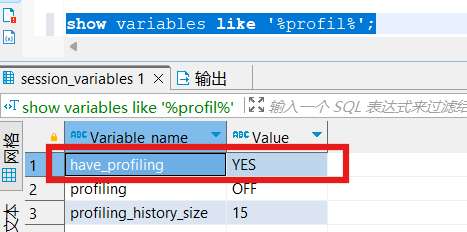
默認profiling是關閉的,可以通過set語句在session/global級別開啟profiling:
set profiling=1;
然后就可以執行一系列的業務SQL的操作,通過以下指令查看指令的執行耗時:
#查看每一條sql的耗時基本情況
show profiles;
#查看指定query_id的SQL語句各個階段的耗時情況
show profile for query query_id
#查看指定query_id的SQL語句CPU的使用情況?
show profile cpu for query query_id
5.4?explain執行計劃
通過以上步驟查詢到效率低的 SQL 語句后,可以通過 EXPLAIN或者 DESC命令獲取 MySQL如何執行 SELECT 語句的信息,包括在 SELECT 語句執行過程中表如何連接和連接的順序。
語法:
#直接在select語句之前加上關鍵字explain/desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 條件;

| 字段 | 含義 |
|---|---|
| id | select查詢的序列號,是一組數字,表示的是查詢中執行select子句或者是操作表的順序(id相同,執行順序從上到下;id不同,值越大,越先執行)。若多表查詢,才可以看見效果 |
| select_type | 表示 SELECT 的類型,常見的取值有 SIMPLE(簡單表,即不使用表連接或者子查詢)、PRIMARY(主查詢,即外層的查詢)、UNION(UNION 中的第二個或者后面的查詢語句)、SUBQUERY(子查詢中的第一個 SELECT)等 |
| table | 輸出結果集的表 |
| type | 表示表的連接類型,性能由好到差的連接類型為(null---> system(系統表) ---> const(唯一索引) -----> eq_ref ------> ref(非唯一索引) -------> ref_or_null----> index_merge ---> index_subquery -----> range -----> index(用了索引,但是會遍歷整個索引樹) ------> all ) |
| possible_keys | 表示查詢時,可能使用的索引 |
| key | 表示實際使用的索引 |
| key_len | 索引中使用的字節數,該值為索引字段最大可能長度,并非實際使用長度,在不損失精確性的前提下,長度越短越好 |
| rows | 必要要執行查詢的行數,在innodb引擎的表中,是一個估值,可能并不是準確的 |
| filtered | 表示返回結果的行數占需讀取行數的百分比,filtered的值越大越好 |
| extra | 執行情況的說明和描述 |
6. 索引使用
6.1 驗證索引效率
6.2?最左前綴法則
如果索引了多列(聯合索引),要遵守最左前綴法則。最左前綴法則指的是查詢從索引的最左列開始,并且不跳過索引中的列。如果跳躍某一列,索引將部分失效(后面的字段索引失效)
6.3?索引失效情況一
- 索引列運算,不要在索引列上進行運算操作,否則索引將失效,若substring函數
- 字符串不加引號,字符串類型字段使用時,不加引號,索引將失效
- 模糊查詢,如果僅僅是尾部模糊匹配,索引不會失效。如果是頭部模糊匹配,索引失效
6.4?索引失效情況二
- or連接的條件。用or分割開的條件,如果or前的條件中的列有索引,而后面的列中沒有索引,那么涉及的索引不會被用到。所以or連接的條件字段都必須建立索引
- 數據分布影響,如果mysql評估使用索引比全表更慢,則不用索引。查詢出來的數據占全表的絕大多數,is null或is not null走不走索引,跟數據分布有關系
6.5?SQL提示
SQL提示,是優化數據庫的一個重要手段,簡單來說,就是在SQL語句中加入一些人為的提示來達到優化操作的目的
use?index:
explain select * from tb_seller use index(idx_seller_name) where name = '小米科技';
ignore index:
explain select * from tb_seller ignore index(idx_seller_name) where name = '小米科技';
force index:
explain select * from tb_seller force index(idx_seller_name) where name = '小米科技';
6.6?覆蓋索引
盡量使用覆蓋索引(查詢使用了索引,并且需要返回的列,在該索引中已經全部能夠找到,也就是查詢的列都是索引),減少select *。
通過測試,使用覆蓋索引的執行計劃的Extra對應的是【Using where;Using index】,而索引沒有覆蓋時,Extra對應的是【Using index condition】,毫無疑問,前者效率高
知識補充:
Using index condition:查找使用了索引,但是需要回表查詢數據
Using where;Using index:查找使用了索引,但是需要的數據都在索引列中能找到,所以不需要回表查詢數據
6.7?前綴索引
當字段類型為字符串(varchar、text等)時,有時候需要索引很長的字符串,這會讓索引變得很大,查詢時,浪費大量的磁盤IO,影響查詢小i率。此時可以只將字符串的一部分前綴,建立索引,這樣可以大大節約索引空間,從而提高索引效率。
語法:create index idx_xxx on table_name(column(n));??n:要提取字符串的前n個字符建立索引
前綴長度:可以根據索引的選擇性來決定,而選擇性是指不重復的索引值(基數)和數據表的記錄總數的比值,索引選擇性越高則查詢效率越高,唯一索引的選擇性是1,這是最好的索引選擇性,性能也是最好的。
根據這個原則的做法:先查看根據要做前綴索引的字段的總數,然后再查看那個字段去重之后的數量,計算比值【select count(email) from tb_user; select count(distinct email) from tb_user;】
前綴索引的查詢流程:傳入的字段截取之后,進行查詢,也需要回表查詢,回表之后,找到那條記錄,其中索引值匹配,匹配成功才返回當前記錄
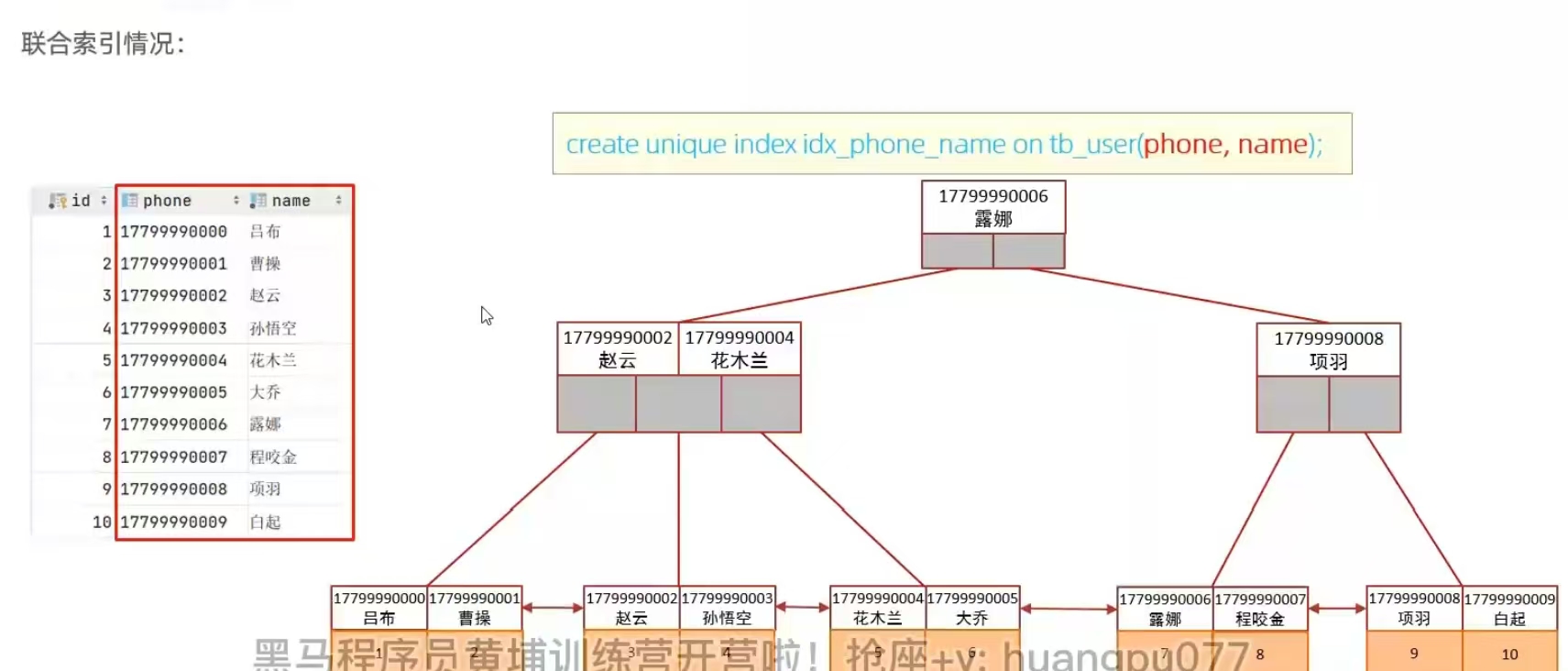
6.8?單列&聯合索引
單列索引:一個索引只包含單個列
聯合索引:一個索引包含了多個列
推薦使用聯合索引:多條件聯合查詢時,mysql優化器會評估哪個字段的索引效率更高,然后自行選擇。經測試,聯合索引效率高(因為一般不需要回表查詢)
聯合索引的數據結構和查詢流程:
7. 索引設計原則
- 針對于數據量大,且查詢比較頻繁的表建立索引
- 針對于常作為查詢條件(where)、排序(order by)、分組(group by)操作的字段建立索引
- 盡量選擇區分度高的列作為索引,盡量建立唯一索引,區分度越高,使用索引的效率越高
- 如果是字符串類型的字段,字段的長度較長,可以針對字段的特點,建立前綴索引
- 盡量使用聯合索引,減少單列索引,查詢時,聯合索引很多時候可以覆蓋索引,節省存儲空間,避免回表,提高查詢效率
- 要控制索引的數量,索引并不是多多益善,索引越多,維護索引結構的代價就越大,會影響增刪改的效率
- 如果索引不能存儲NULL值,請在創建表時使用NOT NULL約束它。當優化器知道每列是否包含NULL值時,它可以更好地確定哪個索引更有效地用于查詢
三、SQL優化
1. 插入數據
insert優化
1)批量插入
原始:
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');優化后:
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
2)手動提交事務
start transaction;
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');
commit;
3)主鍵有序插入
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');
insert into tb_test values(4,'Tim');
insert into tb_test values(5,'Rose');
?4)大批量插入數據
如果一次性需要插入大批量數據,使用Insert語句插入性能較低,此時可以使用load指令進行插入。
#客戶端連接服務端時,加上參數--local-infile
mysql?--local-infile -u root -p
#設置全局參數local_infile為1,開啟從本地加載文件導入數據的開關
set global local_infile=1;
#執行load指令將準備好的數據,加載到表結構中
load data local infile? '/地址'? into table 表名? fields terminated by '.' lines terminated? by '\n';
2. 主鍵優化
數據組織方式:在innodb存儲引擎中,表數據都是根據主鍵順序組織存放的,這種存儲方式的表稱為索引組織表(index organized table IOT)
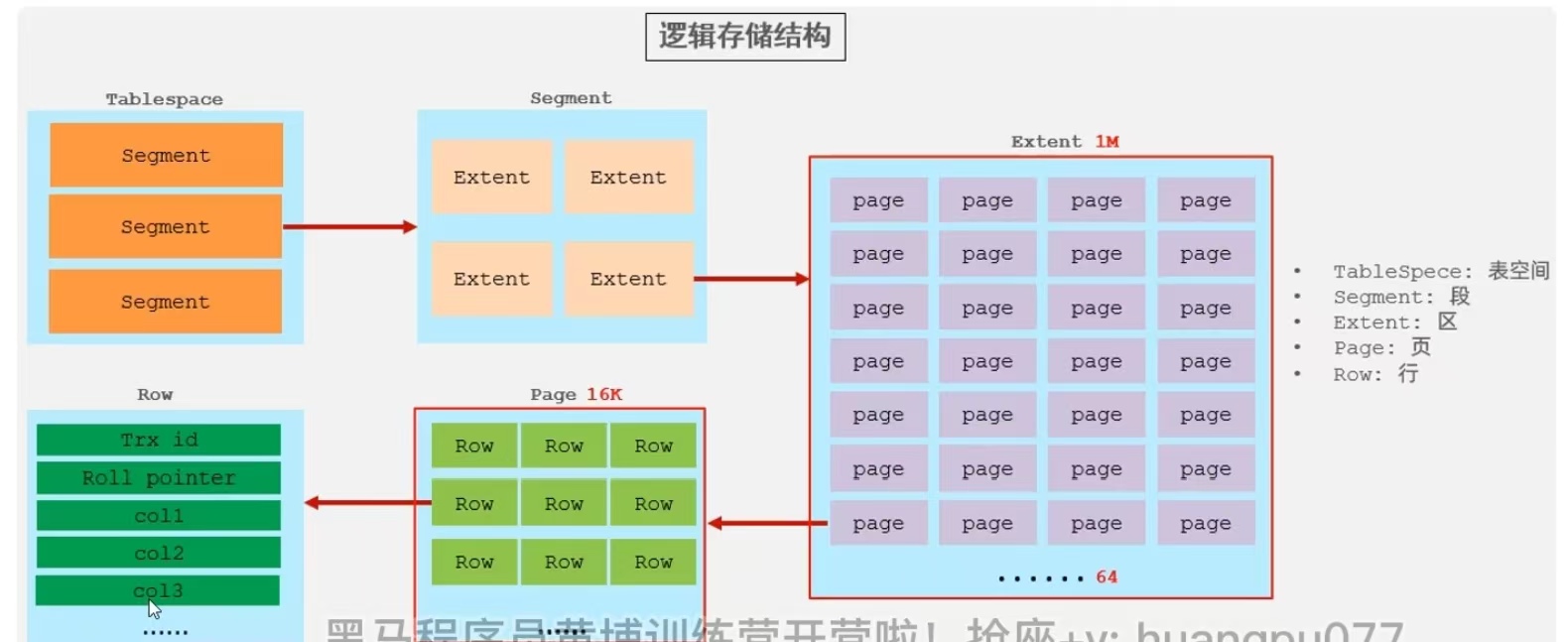
頁分裂: 頁可以為空,也可以填充一半,也可以填充100%。每個頁包含了2-N行數據(如果一行數據過多,會行溢出),根據主鍵排序。假如主鍵是亂序排列的,有新數據進來,首先發現自己應該去的那個頁放不下了,然后就將前面的那些數據放入新開辟的頁中,自己緊隨其后,然后頁之間重新鏈接。

 ?頁合并:當刪除一行記錄時,實際上記錄并沒有被物理刪除,只是記錄被標記為被刪除并且它的空間變得允許被其他記錄聲明使用。當頁中刪除的記錄達到MERGE_THRESHOLD(默認為頁的50%),innodb會開始尋找最靠近的頁(前或后)看看是否可以將兩個頁合并以優化空間使用。
?頁合并:當刪除一行記錄時,實際上記錄并沒有被物理刪除,只是記錄被標記為被刪除并且它的空間變得允許被其他記錄聲明使用。當頁中刪除的記錄達到MERGE_THRESHOLD(默認為頁的50%),innodb會開始尋找最靠近的頁(前或后)看看是否可以將兩個頁合并以優化空間使用。

 ?主鍵設計原則:
?主鍵設計原則:
- 滿足業務需求的情況下,盡量降低主鍵的長度
- 插入數據時,盡量選擇順序插入(亂序插入會發生頁分裂),選擇使用AUTO_INCREMENT自增主鍵。
- 盡量不要使用UUID做主鍵或者時其他自然主鍵(太長),如身份證號
- 業務操作時,盡量避免對主鍵的修改
3. order by優化
Using filesort:通過表的索引或全表掃描,讀取滿足條件的數據行,然后在排序緩沖區sort buffer中完成排序操作,所有不是通過索引直接返回排序結果的排序都叫filesort排序
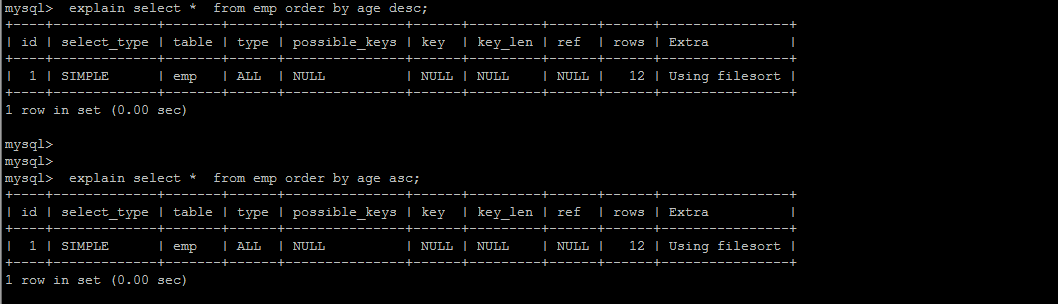
Using index:通過有序索引順序掃描直接返回有序數據,這種情況即為using index,不需要額外排序,操作效率高
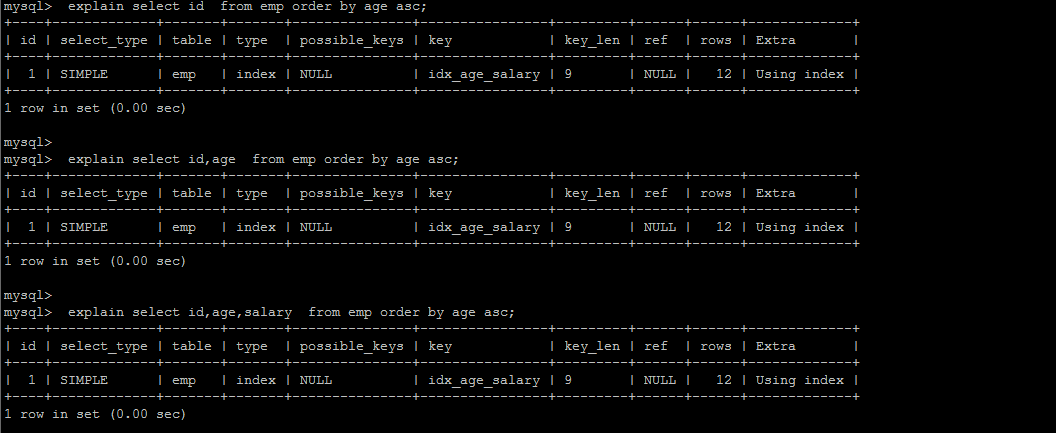
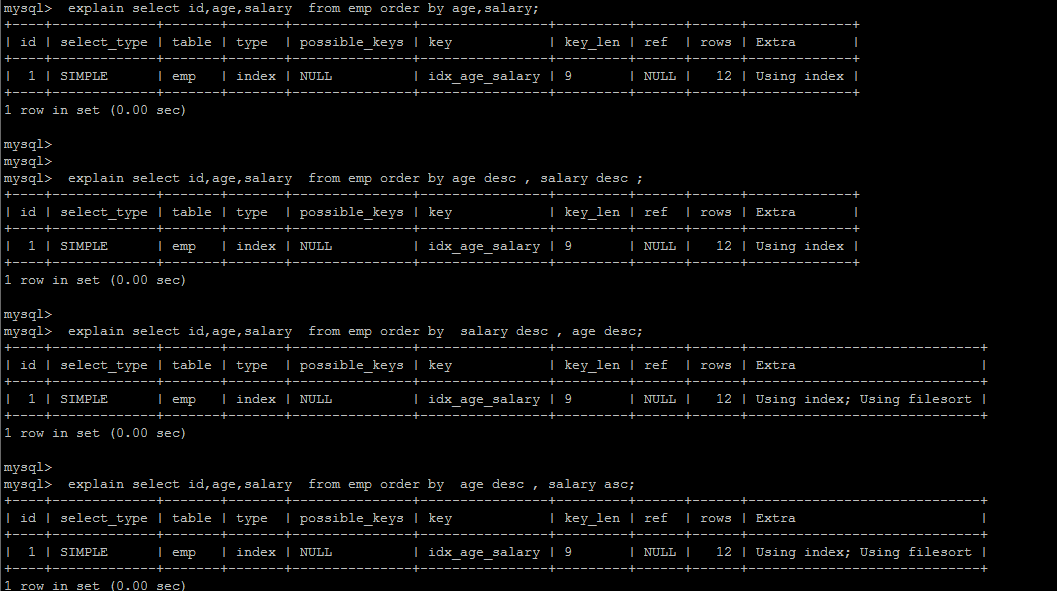
假如排序時,一個字段升序,一個字段降序,因為默認是升序排列嘛,extra肯定會出現filesort,如想要額外開銷直接沒有filesort, 可以創建索引,自定義升序和降序
#根據age、phone進行一個升序,一個降序
explain select id, age, phone from tb_user order by age asc, phone desc;
#創建索引
create index idx_user_age_phone_ad on tb_user(age asc, phone desc);
#根據age、phone進行一個升序,一個降序
explain select id, age, phone from tb_user order by age asc, phone desc;
一切的前提都是使用了覆蓋索引的前提下,假設索引沒有覆蓋,那么肯定還會出現?filesort
優化:
- 根據排序字段建立合適的索引,多字段排序時,也遵循最左前綴法則
- 盡量使用覆蓋索引
- 多字段排序,一個升序一個降序,此時需要注意聯合索引在創建時的規則(ASC,DESC)
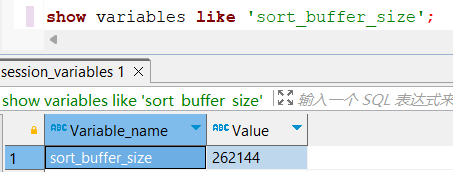
- 如果不可避免的出現filesort,大數據量排序時,可以適當增大排序緩沖區大小sort_buffer_size(默認256K)
4. group by優化
- 在分組操作時,可以通過索引來提高效率
- 分組操作時,索引的使用也是滿足最左前綴法則的
5. limit優化
一個常見又非常頭疼的問題就是limit 2000000,10,此時需要mysql排序前2000010記錄,僅僅返回2000000-2000010的記錄,其他記錄丟棄,查詢排序的代價非常大。
優化思路:一般分頁查詢時,通過創建覆蓋索引能夠比較好地提高性能,可以通過覆蓋索引加子查詢形式進行優化。
explain select * from tb_test t, (select id from tb_test order by id llimit 2000000,10) a
where t.id = a.id?
6. count優化
- MyISAM引擎把一個表的總行數存在了磁盤上,因此執行count(*)的時候會直接返回這個數,效率很高
- innodb引擎就麻煩了,它執行count(*)的時候,需要把數據一行一行地從引擎里面讀出來,然后累計計數
- 優化思路:自己計數
count的幾種用法:
- count()時一個聚合函數,對于返回的結果集,一行行的判斷,如果count函數的參數不是NULL,累計值就加1,否則不加。最后返回累計值
- 用法:count(*)、count(主鍵)、count(字段)、count(1)
- count(主鍵):innodb引擎會遍歷整張表,把每一行的主鍵Id值都取出來,返回給服務層。服務層拿到主鍵后,直接按行進行累加(主鍵不可能為null)
- count(字段):沒有not null約束(innodb引擎會遍歷整張表把每一行的字段值都取出來,返回給服務層,服務層判斷是否為null,不為null,計數累加);有not null約束(innodb引擎會遍歷整張表把每一行的字段值都取出來,返回給服務層,直接進行計數累加)
- count(1):innodb引擎遍歷整張表,但不取值。服務層對于返回的每一行,放一個數字“1”進去,直接按行進行累加。
- count(*):innodb引擎并不會把全部字段取出來,而是專門做了優化,不取值,服務層直接按行進行累加
按照效率排序的話:count(字段) <count(主鍵) < count(1) 約等于count(*),盡量使用count(*)
7. update優化
首先開啟事務,根據非索引字段進行更新,事務未提交之前,其余事務是不能操作這張表的,是因為條件不是索引字段,啟用的是表鎖。
優化思路:innodb的行鎖是針對索引加的鎖,不是針對記錄加的鎖,并且該索引不能失效,否則會從行鎖升級為表鎖。
圖像與通道拼接函數-----水平拼接(橫向連接)兩個輸入矩陣(GMat 類型)函數concatHor())

![[Verilog]跨時鐘域數據傳輸解決方案](http://pic.xiahunao.cn/[Verilog]跨時鐘域數據傳輸解決方案)









)






