開設此專題,目的一是梳理文獻,目的二是分享知識。因為筆者讀研期間的研究方向是單卡上的顯存優化,所以最初思考的專題名稱是“顯存突圍:深度學習模型訓練的 GPU 內存優化之旅”,英文縮寫是 “MLSys_GPU_Memory_Opt”。該專題下的其他內容:
- 【筆記】深度學習模型訓練的 GPU 內存優化之旅①:綜述篇
- 【筆記】深度學習模型訓練的 GPU 內存優化之旅②:重計算篇
- 【筆記】深度學習模型訓練的 GPU 內存優化之旅③:內存交換篇
- 【筆記】深度學習模型訓練的 GPU 內存優化之旅④:內存交換與重計算的聯合優化篇
本文是該專題下的第 5 篇文章,梳理并分享與內存分配技術相關的高水平論文(截至 2025 年 3 月 19 日,一共 6 篇論文。另外,之前系列中也有關于內存分配技術的論文,這里不再包含),具體內容為筆者的論文閱讀筆記。說明:
- 內存分配策略 (memory allocation strategies) 又可分為靜態內存分配 (static memory allocation, SMA) 和動態內存分配 (dynamic memory allocation, DMA),關于經典的內存分配策略可以參考:Memory Allocation Strategies - gingerBill;
- 本文二級標題的內容格式為:[年份]_[會刊縮寫]_[會刊等級/版本]_[論文標題];
- 筆者不評價論文質量,每篇論文都有自己的側重,筆者只記錄與自己研究方向相關的內容;
- 論文文件在筆者的開源倉庫 zhulu506/MLSys_GPU_Memory_Opt 中,如有需要可自行下載;
- 英文論文使用 DeepSeek 進行了翻譯,如有翻譯不準確的地方還請讀者直接閱讀英文原文;
文章目錄
- 1) 2018_arXiv:1804.10001_v1_Profile-guided memory optimization for deep neural networks
- 2) 2023_NeurIPS_A會_Coop: Memory is not a Commodity
- 3) 2023_ICML_A會_MODeL: Memory Optimizations for Deep Learning
- 4) 2023_arXiv:2310.19295_v1_ROAM: memory-efficient large DNN training via optimized operator ordering and memory layout
- 5) 2024_ASPLOS_A會_GMLake: Efficient and Transparent GPU Memory Defragmentation for Large-scale DNN Training with Virtual Memory Stitching
- 6) 2024_ISMM_內存領域_A Heuristic for Periodic Memory Allocation with Little Fragmentation to Train Neural Networks
1) 2018_arXiv:1804.10001_v1_Profile-guided memory optimization for deep neural networks
因為該工作是在深度學習框架 Chainer 上實現的,為了方便,筆者將其稱為 Chainer-Opt。Chainer-Opt 啟發了后續很多工作,包括 ROAM、HMO 等。Chainer-Opt 對訓練和推理都有效。
動機:盡管擴展神經網絡似乎是提高準確性的關鍵,但這伴隨著高昂的內存成本,因為在訓練和推理的傳播過程中,需要存儲權重參數和中間結果(如激活值、特征圖等)。這帶來了幾個不理想的后果。首先,在訓練深度神經網絡(DNN)時,我們只能使用較小的 mini-batch 以避免內存耗盡的風險,因此收斂速度會變慢。其次,使用如此龐大的 DNN 進行推理可能需要在部署環境中使用大量計算設備。第三,更嚴重的是,神經網絡的設計靈活性受到限制,以便 DNN 能夠適應底層設備的內存容量。在 GPU 和邊緣設備上,這種高內存消耗問題尤為嚴重,因為與 CPU 相比,它們的內存容量更小,且擴展性有限。
總結:Chainer-Opt 在一次迭代中分析內存使用情況,并利用該分析結果來確定內存分配方案,從而在后續迭代中最小化峰值內存使用。Chainer-Opt 使用混合整數規劃 (mixed integer programming, MIP) 求解小規模動態存儲分配問題的最優解。Chainer-Opt 將動態存儲分配問題視為二維矩形裝箱問題 (two-dimensional rectangle packing problems) 的特例,使用基于 Best-fit 的啟發式算法來尋找大規模動態存儲分配問題的近似最優解。
摘抄:
- 由于深度神經網絡(DNN)消耗大量內存,內存管理的需求逐漸顯現。許多深度學習框架(如 Theano、TensorFlow 和 Chainer)采用基于內存池和垃圾回收的動態 GPU 內存分配方式。內存池是由未使用的內存塊組成的集合。
- 在接收到 GPU 內存請求時,這些框架會從內存池中找到一個合適大小的內存塊,
- 或者如果池中沒有合適的塊,則從物理內存中分配,并用引用計數對其進行管理。
- 當垃圾回收機制回收該內存塊時,該塊會返回到內存池。
- 通常,內存分配可以被視為一個二維條帶裝箱問題(two dimensional strip packing problem, 2SP)。該問題要求在固定寬度的容器內放置一組矩形物品,同時最小化容器的高度。一個內存塊可以對應一個矩形物品,其分配時間對應寬度,內存大小對應高度。
圖表:
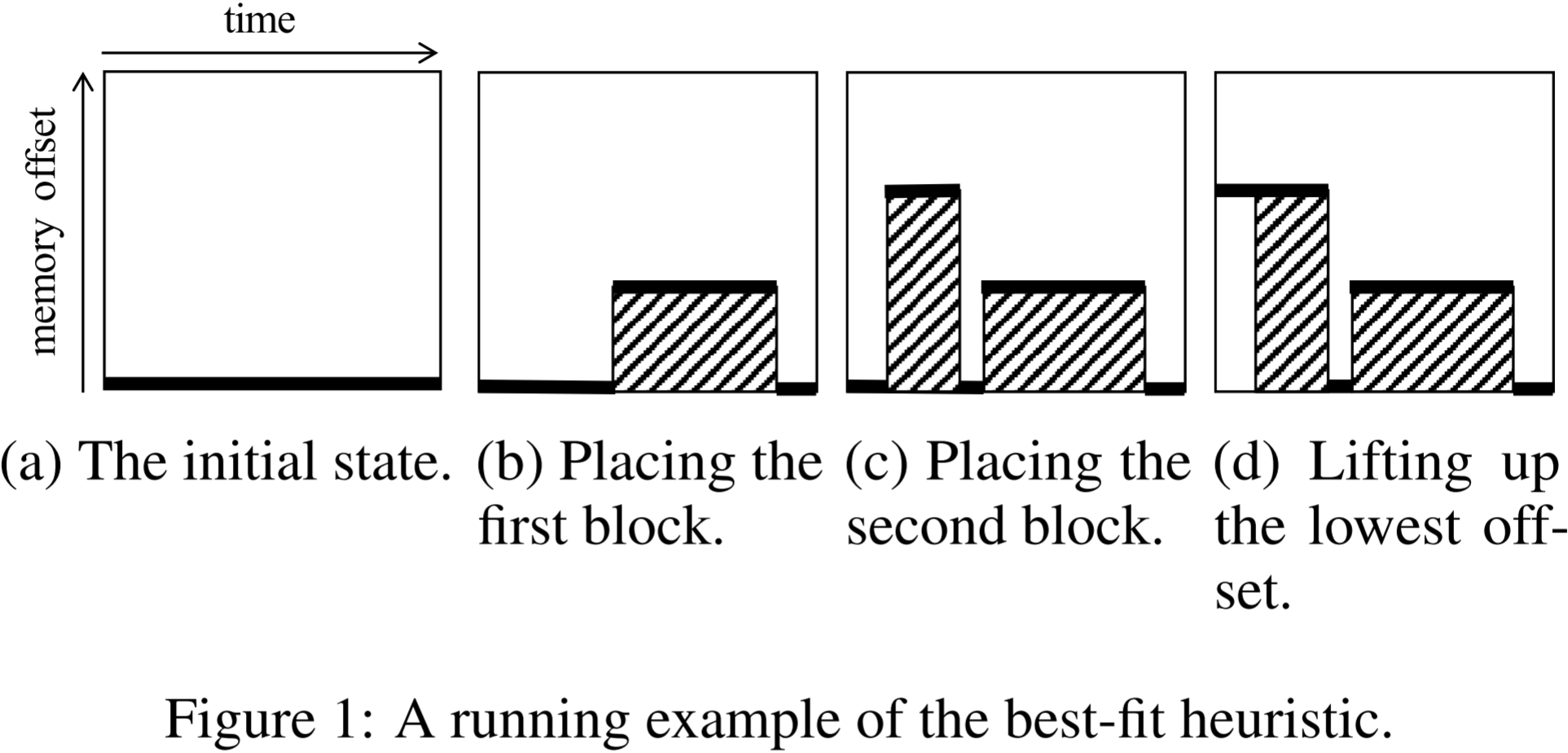
在本文中,我們研究一個特殊情況,即所有內存塊的分配時間都是固定的輸入。該問題也被稱為動態存儲分配問題(Dynamic Storage Allocation,DSA),是一個典型的 NP 難問題。
我們的目標是在矩形區域內放置所有內存塊,使得頂部的內存塊盡可能低。該啟發式算法重復執行兩個操作,直到所有內存塊都被放置完畢:
- 選擇一個偏移量 (offset),
- 搜索一個可以放置在該偏移量 (offset) 處且不會與已放置的內存塊發生沖突的內存塊。
我們通過圖 1 所示的示例說明該啟發式算法的工作方式。
- 在圖 1 中,x 軸和 y 軸分別表示時間和內存偏移量。
- 在算法的初始階段(圖 1a),由于尚未放置任何內存塊,因此我們選擇偏移量為零。
- 當搜索可放置的內存塊時,我們總是在可以放置的候選塊中選擇生存期最長的一個。在圖 1 的示例中,我們選擇了生存期最長的內存塊并將其放置(圖 1b)。
- 放置后,會產生三個候選內存偏移量(圖 1 中的粗線,我們稱之為偏移線 (offset lines))。當存在多個偏移量時,我們總是選擇最小的一個(如果存在多個相同的最小偏移量,則選擇最左側的一個)。
- 接下來,我們為所選的偏移量搜索一個內存塊并進行放置(圖 1c)。
- 如果沒有可放置的內存塊,我們會通過與相鄰的最低偏移線合并來“抬升”該偏移線(如圖 1d 所示,如果相鄰偏移線的偏移量相同,則合并所有相鄰的線),然后再次選擇偏移量并搜索內存塊。
該啟發式算法的計算時間復雜度在內存塊數量的平方范圍內。
2) 2023_NeurIPS_A會_Coop: Memory is not a Commodity
Coop 是 Oneflow 在工程實踐中針對 DTR 帶來的碎片化問題開展的優化,適用于動態計算圖,實現了張量分配和張量重計算的協同優化。
動機:現有的張量重計算技術忽略了深度學習框架中的內存系統,并隱含地假設不同地址上的空閑內存塊是等價的,但這一假設只有在所有被驅逐的張量是連續的情況下才成立。在這一錯誤假設下,非連續的張量會被驅逐,驅逐無法形成連續內存的張量會導致內存碎片化。這導致嚴重的內存碎片化,并增加了潛在重計算的成本。
總結:DTR 會驅逐無法形成連續內存的張量,導致嚴重的內存碎片化。為了解決該問題,Coop 提出了一種滑動窗口 (sliding window) 算法,確保驅逐的張量在地址上都是連續的。具體地說,Coop 將所有張量按內存地址排序并存儲在列表中來跟蹤它們的狀態,使用兩個指針表示滑動窗口的起點和終點,通過在列表中移動窗口,并不斷比較窗口內張量的啟發式成本總和,找到一組連續的張量,使其總內存大于所需內存且驅逐成本最低,窗口內的張量將被驅逐。另外,為了優化張量內存布局,從而進一步降低重計算成本,Coop 還提出了低成本張量劃分 (cheap tensor partitioning) 和可重計算就地操作 (recomputable in-place)。具體地說,Coop 將驅逐成本相近的張量聚類到相同的位置,從而增加了驅逐一組連續低成本張量的可能性。此外,Coop 觀察到 in-place 主要發生在不可驅逐的模型參數更新過程中。為了防止這些張量將整個內存池劃分成不連續的內存塊,Coop 先將參數張量分配到內存池的兩端,并在更新時重用其內存,從而最大程度地降低了內存碎片化的發生率。
摘抄:
- 內存分配器(Memory allocator)是深度學習(DL)系統中的重要組成部分。所有已知的 DL 系統(如 PyTorch、TensorFlow 和 MXNet)都配備了專屬的內存分配器,以實現細粒度內存管理(fine-grained memory management)并避免與操作系統(OS)通信的開銷。相比于先進的 CPU 內存分配器(如 mimalloc 和 jemalloc),DL 框架中的內存分配器設計更為簡單。
- 通常,在 DL 框架中,當張量被銷毀時,其內存不會歸還給 OS,而是被插入到分配器的空閑列表中,并與相鄰地址的內存塊合并。當用戶請求大小為 S S S 的張量內存時,分配器會嘗試將該張量放置在大小大于或等于 S S S 的空閑塊的最左側。如果所有空閑塊的大小都小于 S S S,則分配器會向 OS 申請新的內存,即使所有空閑塊的總大小可能大于 S S S。這些未被利用的空閑塊稱為內存碎片(memory fragments)。
- 在每次迭代中,由順序操作生成的張量往往會從內存池的最左側開始被連續分配。
- 此外,內存分配器可以利用硬件的頁表(page table),將非連續的內存塊在**虛擬內存(virtual memory)**的視角下重新組合成連續的內存塊。研究表明,這種方法能夠減少 CPU 端的內存碎片。(但是 NVIDIA GPU 的驅動程序不開源)。
- 內存碎片指的是由于尺寸較小且零散分布,無法用于張量分配的內存塊。這一問題影響所有深度神經網絡(DNN)訓練,但在張量重計算過程中尤為嚴重,因為重計算會導致更頻繁的內存重組。
- 現有張量重計算方法無法解決該問題的根本原因在于,它們并不強調生成連續的空閑內存塊。此外,它們的啟發式方法往往會使問題更加嚴重。大多數重計算方法為了減少遞歸重計算,會懲罰驅逐由順序操作生成的張量。例如,在 DTR 的啟發式方法中,張量的預估開銷是基于其鄰域計算的(即依賴于當前張量或依賴其重計算的張量)。懲罰順序張量的驅逐通常會導致生成非連續的空閑內存塊,因為順序張量往往是連續存儲的。
圖表:
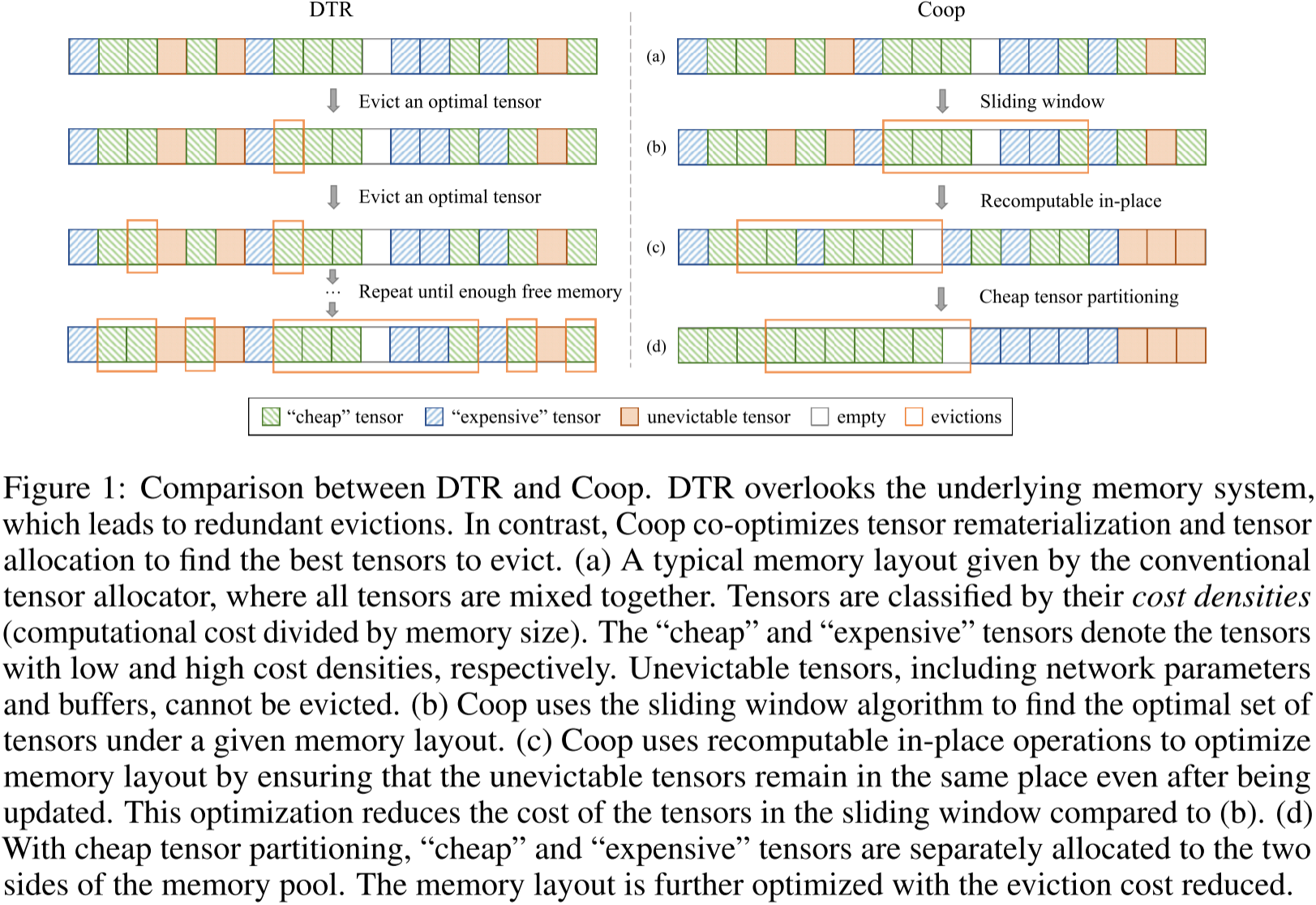
圖 1:DTR 與 Coop 的對比。DTR 忽略了底層內存系統,導致冗余的逐出操作。相比之下,Coop 共同優化了張量重計算和張量分配,以找到最優的張量進行逐出。
張量按其成本密度(計算成本除以內存大小)進行分類。“低成本”張量和“高成本”張量分別表示成本密度低和高的張量。不可逐出的張量(包括網絡參數和緩沖區)無法被逐出。
(a) 傳統張量分配器給出的典型內存布局,其中所有張量混合存儲。
(b) Coop 采用滑動窗口算法,在給定的內存布局下找到最優的張量集合。
? Coop 通過可重計算的就地(in-place)操作優化內存布局,確保不可逐出的張量在更新后仍保持原位。這一優化降低了滑動窗口內張量的成本,相較于 (b) 更加高效。
(d) 通過低成本張量劃分,“低成本”張量和“高成本”張量分別分配到內存池的兩側。進一步優化內存布局,降低逐出成本。
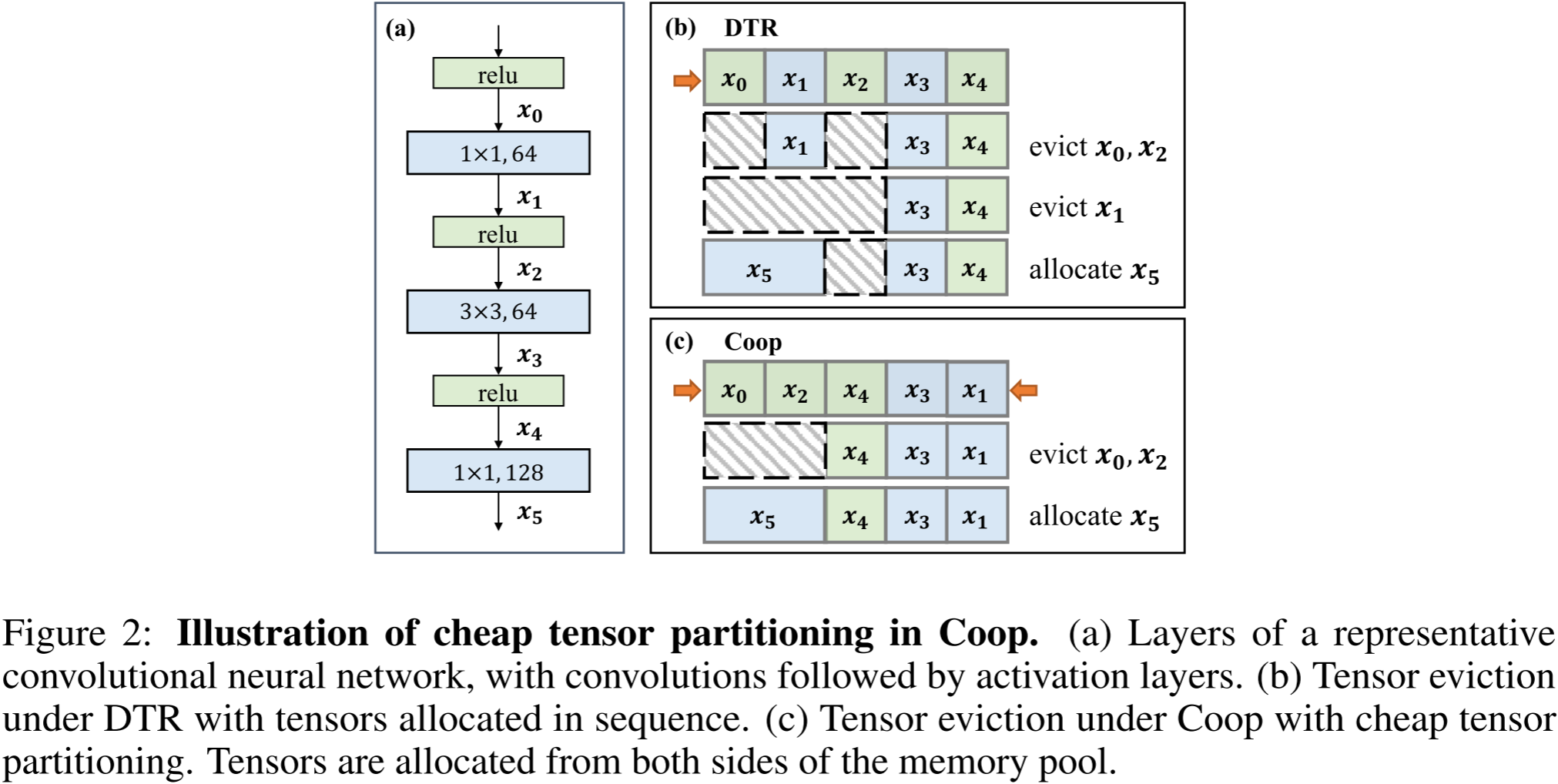
圖 2:Coop 中低成本張量劃分的示意圖。
我們觀察到,神經網絡中的大多數算子可以按照計算復雜度簡單地歸類為兩類:超線性(super-linear)(如矩陣乘法 matmul 和卷積 conv)以及線性/次線性(linear/sub-linear)(如逐元素操作 element-wise ops)。在大多數情況下,超線性操作的成本密度比其他算子高一個數量級。
(a) 典型卷積神經網絡的層結構,卷積層后接激活層。
圖 2(a) 展示了一個典型的卷積神經網絡示例,其中每個卷積層后都跟隨一個激活函數。在此,我們未包含批量歸一化(Batch Normalization),因為其計算成本密度與激活層相似,且并非所有神經網絡都必須包含該操作。
(b) DTR 下的張量逐出,張量按順序分配。
假設張量 x 0 , . . . , x 4 x_0, ..., x_4 x0?,...,x4? 在訓練開始時生成,因此按順序存儲在內存中。如果內存已滿且需要額外的 100 MB 來存儲 x 5 x_5 x5?,根據 DTR 的策略,兩個由激活層生成的張量( x 0 x_0 x0? 和 x 2 x_2 x2?,每個 50 MB)將被優先驅逐( x 0 x_0 x0? 是內存中最舊且成本最低的張量,其驅逐會增加 x 1 x_1 x1? 的啟發式成本)。然而,由于釋放的內存塊不連續,仍需額外驅逐其他張量(例如 x 1 x_1 x1?),這會引入無效驅逐并導致內存碎片化(如圖 2(b))。
? Coop 采用低成本張量劃分進行張量逐出,張量從內存池的兩側進行分配。
我們通過從內存池的最左端和最右端分配張量來實現低成本張量分區(如圖 2?),該方法是可行的,因為用戶在訓練前已指定內存預算。我們使用**成本密度(計算成本除以內存大小)**來衡量張量的驅逐成本大小。在模型的前向傳播過程中,具有相同數量級成本密度的張量被分配到內存池的同一端。
3) 2023_ICML_A會_MODeL: Memory Optimizations for Deep Learning
MODeL 使用整數線性規劃來解決算子排序和張量內存布局的問題。
動機:深度學習框架面臨的內存碎片化問題 + 深度學習框架未針對張量的生命周期進行優化。
總結:MODeL 通過分析深度神經網絡的數據流圖,尋找算子之間的拓撲排序。MODeL 將最小化深度神經網絡訓練所需峰值內存的問題建模為一個整數線性規劃 (integer linear program, ILP),以共同優化張量的生命周期 (lifetime) 和內存位置 (memory location),從而最小化深度神經網絡訓練需要分配的內存峰值,并減少內存碎片。
摘抄:
- 當前流行的深度學習框架(如 PyTorch 和 TensorFlow)并未充分利用有限的內存資源。類似于傳統的動態內存分配器(如 tcmalloc 和 jemalloc),這些框架在運行時維護一個空閑內存塊池。當接收到內存請求時,它們會在內存池中查找足夠大的空閑塊,若無法滿足請求,則直接從物理內存中分配新塊。當空閑內存塊的大小與實際分配請求不匹配時,就會導致內存碎片化,而這種情況經常發生。
- 此外,深度神經網絡框架未對張量的生命周期進行優化。PyTorch 按照程序中定義的順序執行操作,而 TensorFlow 維護一個就緒隊列,并采用先進先出的方式執行運算。因此,張量可能會被提前分配或延遲釋放,從而浪費寶貴的內存。
- PyTorch 和 TensorFlow 等機器學習框架允許部分算子將其生成的數據存儲在輸入張量之一中,從而避免額外分配輸出張量。這種方法稱為 就地更新(inplace-update),可以節省內存。然而,用戶需要手動修改神經網絡以利用這一特性,并且如果使用不當,可能會導致計算錯誤。
圖表:
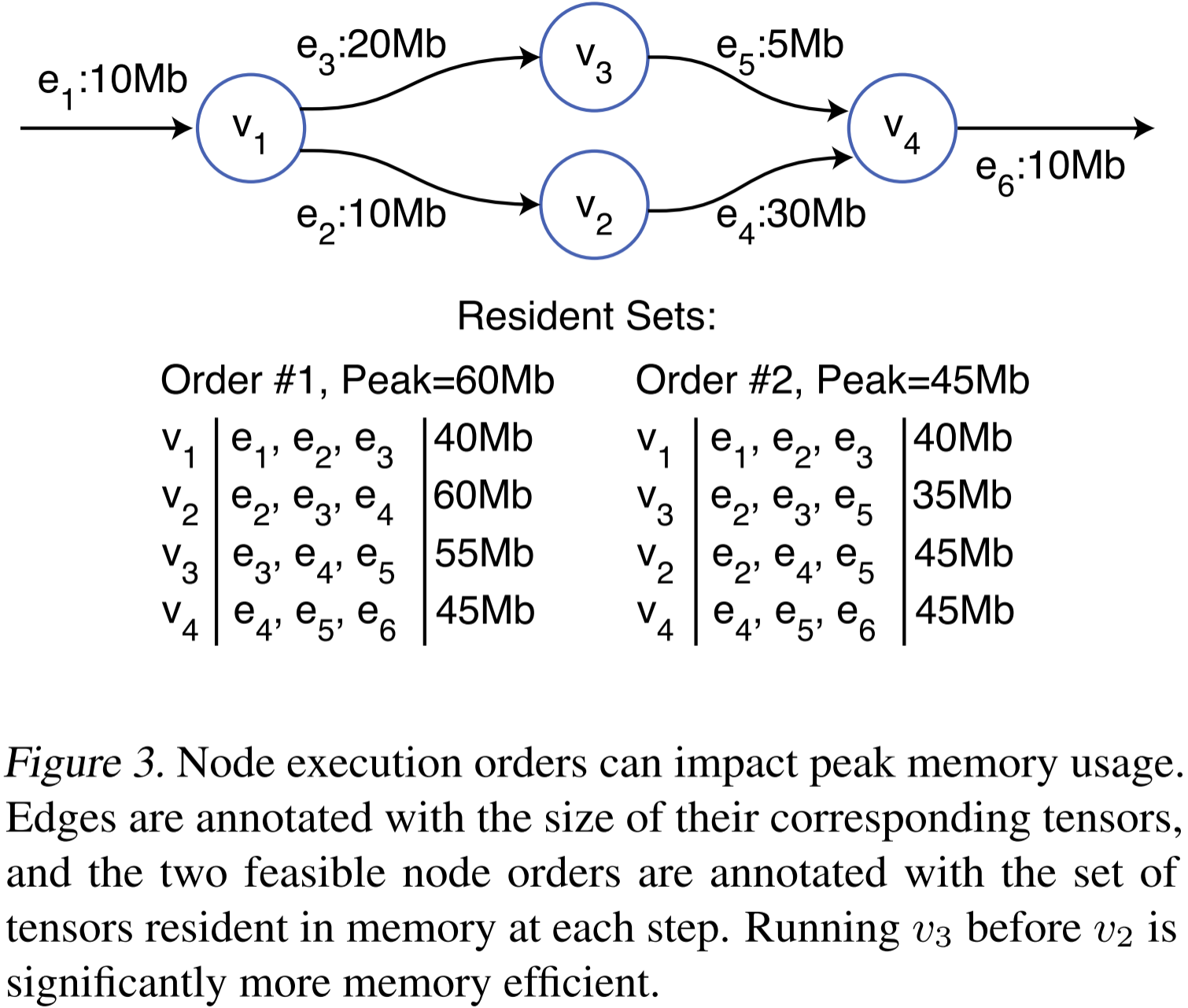
圖 3:節點執行順序會影響峰值內存占用。邊上標注了對應張量的大小,兩種可行的節點執行順序分別標注了每個步驟內存中駐留的張量集合。在 v3 先于 v2 運行的情況下,內存使用效率顯著提高。
峰值駐留集合(peak resident set) 是整個神經網絡執行過程中規模最大的駐留集合。算子執行順序會影響張量的生命周期,因此也影響內存的峰值占用。圖 3 展示了一個簡單示例,說明如何通過調整算子執行順序顯著改善內存使用情況。在所有可能的節點執行順序中,優先執行能夠釋放大量數據且自身生成少量輸出數據的節點通常更具內存效率。然而,已有研究表明,在通用 有向無環圖(DAG, Directed Acyclic Graph) 上尋找最優調度是一個 NP 完全(NP-complete) 問題,無法通過簡單的貪心策略解決。
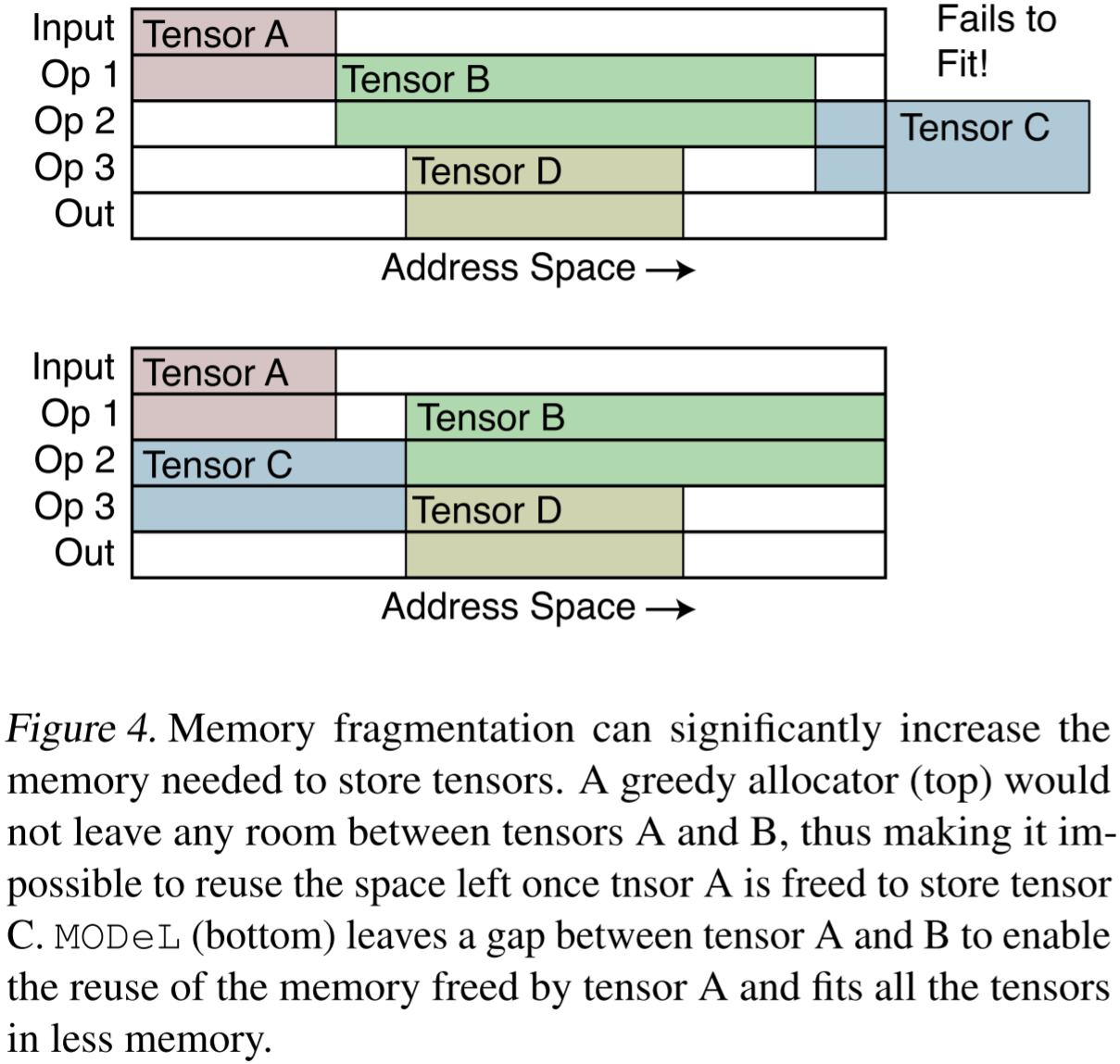
圖 4:內存碎片化可能大幅增加存儲張量所需的內存。貪心分配器(上圖)不會在張量 A 和 B 之間留下任何空隙,因此當張量 A 釋放后,無法利用其騰出的空間存儲張量 C。而 MODeL(下圖)在張量 A 和 B 之間預留了空隙,使得張量 A 釋放后的內存可被重用,從而在更少的內存中容納所有張量。
類似于 malloc 風格的內存分配器,典型的深度學習框架采用在線(online)方式進行張量分配,因此同樣會面臨內存碎片化問題。事實上,空閑內存通常被分割成小塊,并被已分配的張量所隔開,導致大量可用內存因碎片化而無法有效利用,因為這些零散的小塊不足以容納一個完整的張量。圖 4 說明了這一現象,并展示了如何通過預先規劃每個張量的存儲位置來大幅減少內存峰值占用。
4) 2023_arXiv:2310.19295_v1_ROAM: memory-efficient large DNN training via optimized operator ordering and memory layout
ROAM 和 MODeL 優化的都是算子排序 (operator ordering) 和內存布局 (memory layout),而且最終都把問題形式化為整數線性規劃問題。
動機:盡管卸載、重計算和壓縮等高層技術可以緩解內存壓力,但它們也會引入額外的開銷。然而,一個具備合理算子執行順序和張量內存布局的內存高效執行計劃可以顯著提升模型的內存效率,并減少高層技術帶來的開銷。
總結:ROAM 在計算圖層面進行優化。為了降低理論峰值內存,ROAM 將算子執行順序的優化轉換為張量生命周期的優化,并引入多個約束條件,以確保優化后的張量生命周期與有效的算子執行順序相對應,優化目標是最小化理論峰值內存。為了提高內存布局效率,ROAM 最關鍵的約束是確保生命周期重疊的張量不能占據重疊的地址空間,優化目標是最小化所需內存空間的大小。ROAM 使用整數線性規劃求得上述兩個問題的近似最優解,并通過一種子圖樹拆分算法將整體大任務轉換為多個小任務,以提高求解過程的執行效率,解決大型復雜圖中的優化挑戰。
摘抄:
- 當前的深度學習編譯器和框架依賴于基本的拓撲排序算法,這些算法并未考慮峰值內存使用情況。然而,這些執行順序通常并不具備內存高效性。
- Pytorch 按照程序中定義的順序執行算子。
- Tensorflow 維護一個就緒算子隊列,并根據進入隊列的時間執行它們。
- 已有研究證明,有向無環圖(DAG)的最優調度問題以及內存布局優化問題(也稱為**動態存儲分配問題,Dynamic Storage Allocation, DSA)**分別是典型的 **NP 完全(NP-Complete)**問題和 **NP 難(NP-Hard)**問題。因此,在多項式時間內找到最優解是具有挑戰性的。
圖表:
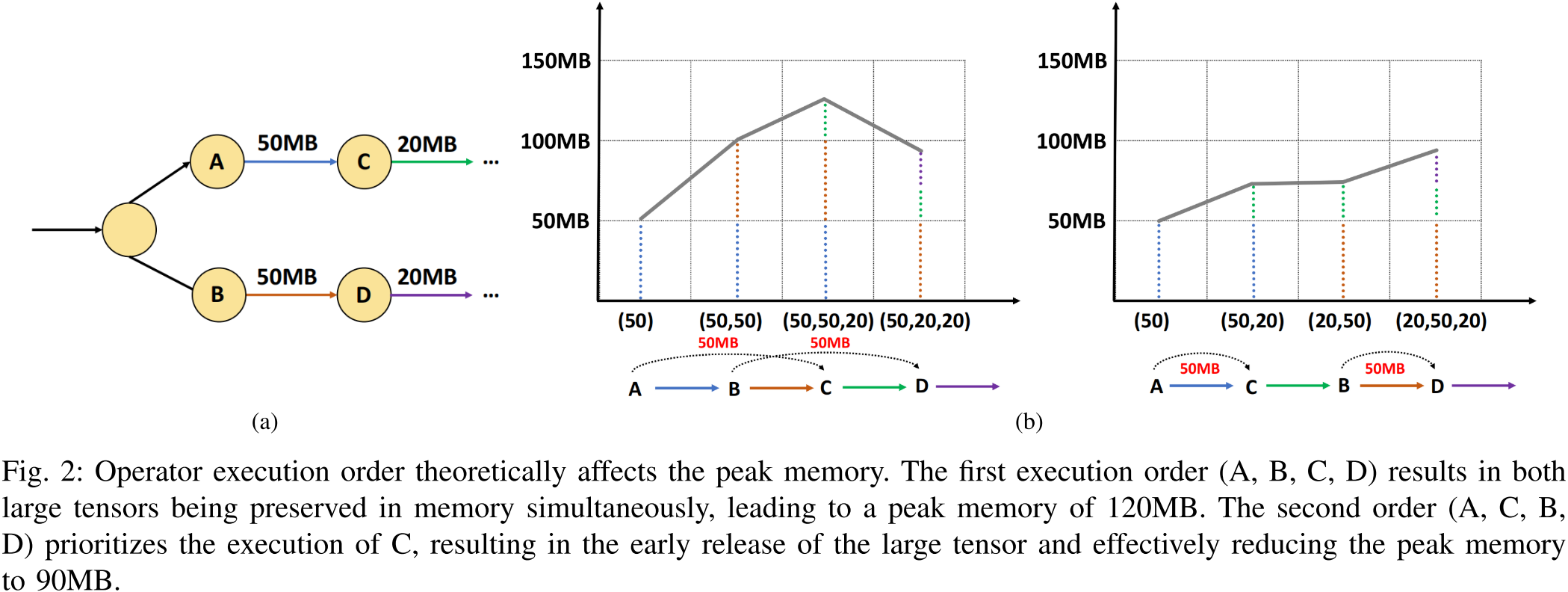
圖 2:運算符執行順序在理論上會影響峰值內存占用。第一種執行順序(A、B、C、D)會導致兩個大張量同時保留在內存中,導致峰值內存達到 120MB。而第二種執行順序(A、C、B、D)優先執行 C,從而使大張量得以及早釋放,有效地將峰值內存降低至 90MB。
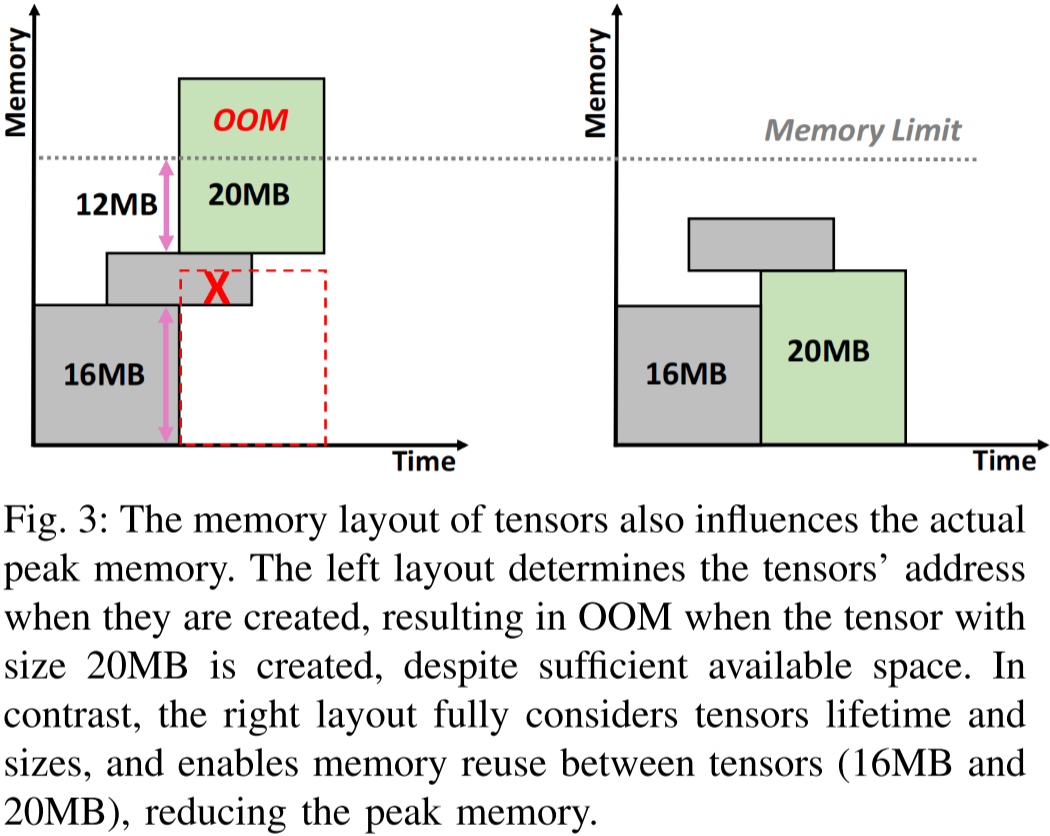
圖 3:張量的內存布局同樣會影響實際的峰值內存。左側的布局在創建張量時決定了它們的地址,盡管存在足夠的可用空間,但在創建大小為 20MB 的張量時仍然發生 OOM(內存溢出)。相比之下,右側的布局充分考慮了張量的生命周期和大小,使得張量(16MB 和 20MB)之間的內存得以復用,從而降低峰值內存占用。
此外,內存布局的低效性會對實際的內存需求產生顯著影響。張量的不合理內存布局會導致較低的內存復用效率,在內存中相鄰的兩個張量之間產生數據碎片,如圖 3 所示。
現有的深度學習框架通常在運行時從內存池中搜索足夠大的空閑內存塊,或者選擇直接從物理內存中分配所需的內存。它們在決定張量的內存偏移時僅考慮其生成時間。然而,內存復用還與張量的大小和生命周期密切相關。因此,這種運行時分配方法難以通過內存復用充分降低內存需求。由于不同張量的生命周期和大小存在差異,在動態分配過程中經常會出現內存碎片化問題,這可能導致因缺乏連續內存而分配失敗。
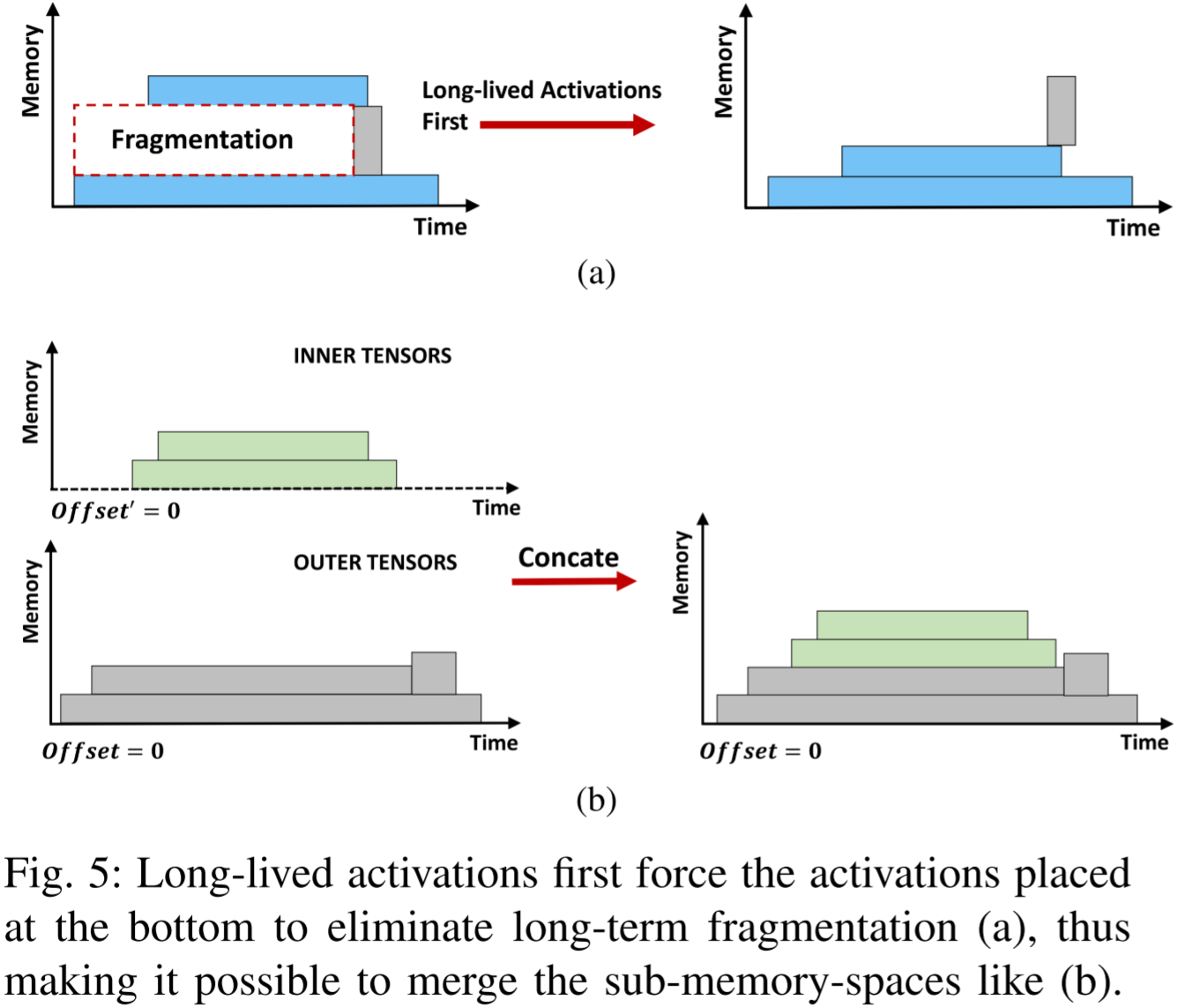
圖 5:長生命周期的激活首先迫使底部的激活張量排列,以消除長期的內存碎片化 (a),從而使得子內存空間可以像 (b) 那樣合并。
臨時緩沖區和激活被分配到不同的內存布局中,可能會導致長期碎片化,如圖 5a 所示。
為了解決這一問題,我們施加了約束,強制激活在較低偏移量處連續放置,從而防止激活與臨時緩沖區之間的交錯。
如圖 5b 所示,涉及將生命周期較短的內存布局放置在另一個布局之上。這種方法利用長期存在的激活的累積大小作為基礎偏移量,有效地減輕了長期碎片化問題。
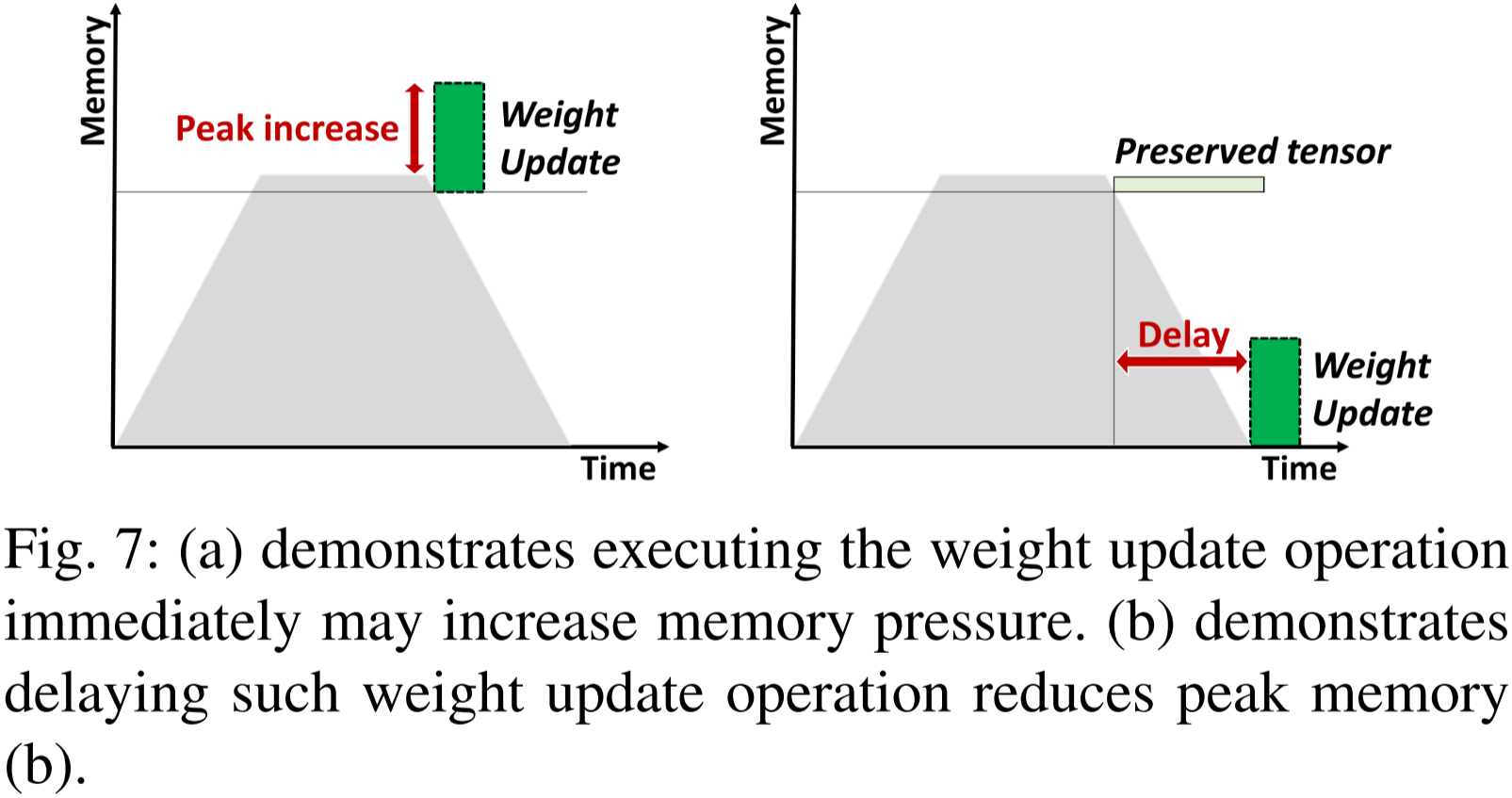
圖 7:(a) 說明立即執行權重更新操作可能會增加內存壓力。(b) 說明延遲執行權重更新操作可以降低峰值內存占用。
一旦生成梯度,相應的權重更新操作就可以安排執行。因此,權重更新操作的調度表現出強大的靈活性。權重更新操作的調度時間步可以顯著影響峰值內存。考慮兩種極端情況,一是梯度生成后立即調度權重更新,二是所有權重更新操作都在完成反向傳播過程后再調度。
如圖 7 所示,
- 在內存消耗較大時,例如大多數激活張量都被保留在內存中,盡早執行權重更新可能會產生許多大的臨時緩沖區,導致更大的內存壓力。
- 然而,選擇將所有權重更新操作延遲執行并不是一個理想的方案,因為每個梯度必須被保留相當長的時間。
- 因此,將權重更新操作分配到合適的獨立段并進行調度是非常重要的。
5) 2024_ASPLOS_A會_GMLake: Efficient and Transparent GPU Memory Defragmentation for Large-scale DNN Training with Virtual Memory Stitching
GMLake 用到了 CUDA VMM API,是虛擬內存拼接機制的首個工作,出現的時間與 PyTorch 的 Expandable Segments 相似,但都晚于 TensorFlow 的。GMLake 提供了多個版本的 PyTorch 實現,同時也是質量很高的一篇論文。
關于 CUDA VMM API 和 PyTorch 的 Expandable Segments,感興趣的讀者可以閱讀:PyTorch 源碼學習:GPU 內存管理之初步探索 expandable_segments
動機:盡管優化方法(重計算、卸載、分布式訓練和低秩適配)能夠有效減少訓練或微調大規模 DNN 模型的內存占用,但它們可能會導致較低的內存利用率。其原因在于,這些方法會引入大量規律性和動態性的內存分配請求,從而導致 GPU 內存碎片率最高可達 30%。
總結:GMLake 針對內存優化技術導致的嚴重內存碎片化問題,利用 CUDA 提供的虛擬內存管理接口,提出了一種虛擬內存拼接機制,通過虛擬內存地址映射組合非連續的物理內存塊,從而緩解了內存碎片問題。
筆者對這篇論文進行了翻譯,具體內容見:【翻譯】GMLake_ASPLOS 2024
6) 2024_ISMM_內存領域_A Heuristic for Periodic Memory Allocation with Little Fragmentation to Train Neural Networks
考慮到該文獻使用模擬退火 (Simulated Annealing, SA) 算法解決動態存儲分配 (Dynamic Storage Allocation, DSA) 問題,所以筆者將其簡稱為 DSA-SA。另外,作者在論文中也解釋了該工作的局限性:“總體而言,盡管我們的方法是離線的,其適用性受到一定限制,但在需要針對特定工作負載進行高度優化的場景下,我們的方法能夠實現接近滿負載的資源利用率,并且一旦完成分配規劃,就不會產生任何運行時開銷,因此我們認為其性能最佳。” DSA-SA 的開銷主要體現在第一次迭代。
動機:DSA 問題是 NP-hard 的,因此通過精確算法的優化成本過高。已有大量關于多項式時間近似算法的研究。然而,這些算法主要關注理論界限,其實際實現通常采用諸如首次適應(first-fit)或最佳適應(best-fit)與合并(coalescing)等啟發式方法。……我們的工作主要是受到重計算引起的內存碎片化問題的推動。
總結:DSA-SA 利用了神經網絡訓練過程中內存分配的周期性,在第一次迭代期間獲取內存的分配模式。DSA-SA 將離線 DSA 問題表述為尋找一個最優的分配之間的拓撲排序,并通過基于模擬退火的啟發式算法來解決這個 NP-hard 問題,從而可以確定一個碎片化程度最小的分配計劃。
摘抄:
- PyTorch 的 CUDA 緩存分配器使用一組塊來管理保留的 GPU 內存。這組塊類似于 dlmalloc 中的塊,后者最初用于 glibc。……此實現具有低延遲,并且通常對典型的神經網絡應用表現良好,因為訓練或推理過程中有許多相同大小的分配,并且大多數分配可以通過保留的空塊處理,而無需調用
cudaMalloc。此外,由于訓練和/或推理需要重復計算,緩存策略表現尤為出色,直到資源耗盡,此時緩存將通過使用cudaFree釋放一些未拆分的塊來銷毀。 - 現有的緩存分配器中的碎片減少技術:PyTorch 的 CUDA 緩存分配器提供了幾種選項來配置算法,以防止 OOM 錯誤。
- 如前所述,未使用的拆分塊會導致 CUDA 緩存分配器中的碎片。為了防止將大塊拆分為小分配,PyTorch 為小型(最多1MB)和大型分配使用兩個塊池。拆分大塊通常是有益的,因為它可以重復使用保留的區域,但也可能導致嚴重的碎片化。為了防止這種情況,可以配置緩存分配器在使用閾值時不拆分大塊。當這些大塊不再需要時,可以隨時使用
cudaFree釋放它們;然而,同步的cudaFree可能會降低執行吞吐量。 - 此外,緩存分配器可以配置為將每個分配的大小四舍五入到最接近的 2 的冪,以防止災難性的碎片化。然而,在大多數工作負載中,這種配置可能會導致更多碎片。
- 如前所述,未使用的拆分塊會導致 CUDA 緩存分配器中的碎片。為了防止將大塊拆分為小分配,PyTorch 為小型(最多1MB)和大型分配使用兩個塊池。拆分大塊通常是有益的,因為它可以重復使用保留的區域,但也可能導致嚴重的碎片化。為了防止這種情況,可以配置緩存分配器在使用閾值時不拆分大塊。當這些大塊不再需要時,可以隨時使用
- PyTorch 采用了專門的 CUDA 緩存分配器,以減少
cudaMalloc和cudaFree之類的阻塞函數調用的頻率。該緩存分配器優化了內存分配和釋放操作,顯著提升了 PyTorch 框架中 GPU 操作的整體性能。PyTorch 分配器使用了一種高效的在線 DSA 算法。
圖表:
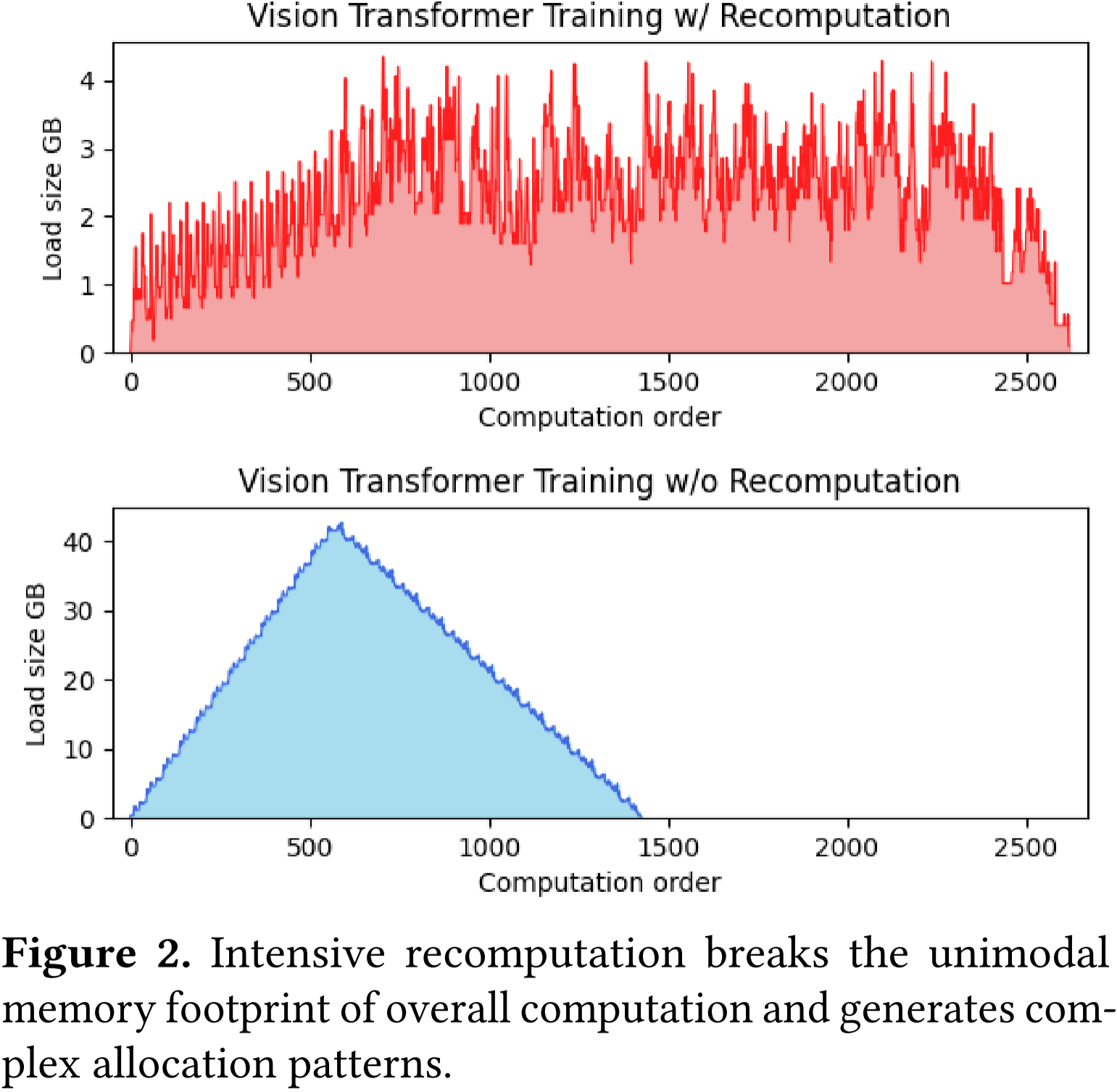
圖 2:高強度的重計算破壞了整體計算的單峰內存占用模式,并生成復雜的分配模式。
我們在圖 2 中繪制了內存消耗和計算順序,即每個算子的運行進度。沒有重計算時,內存消耗模式是單峰的(前向傳遞時增加,反向傳遞時減少),并且大多數分配器算法在峰值內存消耗時幾乎沒有碎片化。
然而,啟用重計算時,內存的分配和釋放在計算過程中交替進行,導致復雜的模式。此外,鑒于重計算的固有特性,PyTorch 緩存分配器可能會因大量小的內存分配和大內存分配之間的間隔而遭受嚴重的碎片化。
這種碎片化不僅浪費了 GPU 資源,還減慢了訓練過程。這是因為 PyTorch 的 CUDA 緩存分配器在需要釋放緩存塊以騰出空間時,使用了阻塞的 cudaMalloc 和 cudaFree 操作。

圖 4:PyTorch 緩存分配器(左)導致的碎片化,以及 GMLake 進行的碎片整理技術(中)和離線規劃(右)。每個加粗的框表示該內存段上存在某些阻塞的 CUDA API 調用。
GMLake 通過將物理內存塊拼接成連續的虛擬范圍在線運行,離線規劃的適用性有限,因為它需要對分配模式做出假設,但它能夠在沒有運行時開銷的情況下實現最大化的資源利用。


查詢圖數據庫NEO4J(2))











圖像與通道拼接函數-----合并三個單通道圖像(GMat)為一個多通道圖像的函數merge3())



(文末有下載方式))
