《Sce2DriveX: A Generalized MLLM Framework for Scene-to-Drive Learning》2025年2月發表,來自中科院軟件所和中科院大學的論文。
? ? ? ? 端到端自動駕駛直接將原始傳感器輸入映射到低級車輛控制,是Embodied AI的重要組成部分。盡管在將多模態大語言模型(MLLM)應用于高級交通場景語義理解方面取得了成功,但將這些概念語義理解有效地轉化為低級運動控制命令并在跨場景駕駛中實現泛化和共識仍然具有挑戰性。我們介紹了Sce2DriveX,一個類人驅動的思維鏈(CoT)推理MLLM框架。Sce2DriveX利用來自局部場景視頻和全局BEV地圖的多模態聯合學習,深入了解長距離時空關系和道路拓撲,增強其在3D動態/靜態場景中的綜合感知和推理能力,實現跨場景的駕駛泛化。在此基礎上,它重建了人類駕駛固有的內隱認知鏈,涵蓋場景理解、元動作推理、行為解釋分析、運動規劃和控制,從而進一步彌合了自動駕駛與人類思維過程之間的差距。為了提高模型性能,我們開發了第一個為3D空間理解和長軸任務推理量身定制的廣泛的視覺問答(VQA)駕駛指令數據集。大量實驗表明,Sce2DriveX從場景理解到端到端駕駛都達到了最先進的性能,并在CARLA Bench2Drive基準上實現了穩健的泛化。
1. 研究背景與問題
自動駕駛作為具身智能(Embodied AI)的核心應用,面臨兩大核心挑戰:
-
泛化能力不足:現有模型難以適應動態多變的交通場景(如天氣變化、復雜道路拓撲、參與者行為差異等)。
-
與人類認知脫節:傳統方法依賴剛性規則或小型模型,缺乏對駕駛過程的漸進式推理(Chain-of-Thought, CoT),導致決策邏輯不透明,難以與人類駕駛思維對齊。
2. 核心方法:Sec2DriveX框架
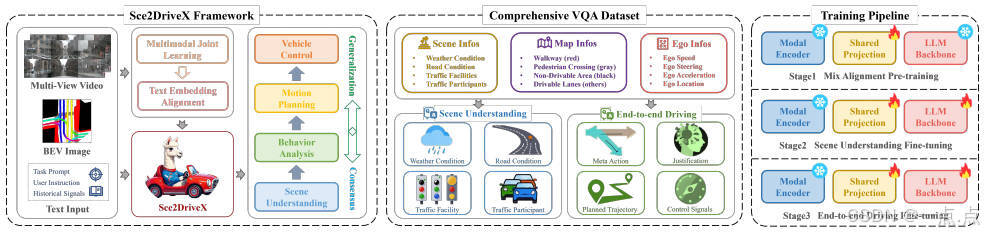
2.1 框架設計
Sec2DriveX是一個基于多模態大語言模型(MLLM)的端到端自動駕駛框架,核心目標是通過全局-局部感知與人類認知鏈建模,實現從場景理解到低層控制信號的閉環。其架構包含以下關鍵組件:
-
多模態輸入:
-
局部場景視頻:捕捉動態時空信息(如交通參與者運動)。
-
全局BEV地圖:提供道路拓撲、車道結構等靜態信息。
-
-
模態對齊:通過視頻編碼器(OpenCLIP)和圖像編碼器提取特征,映射至統一視覺特征空間。
-
LLM主干(Vicuna-v1.5-7b):整合多模態特征與文本指令,生成包含場景理解、元動作推理、行為解釋、運動規劃和控制信號的自然語言響應。
-
鏈式推理(CoT):模仿人類駕駛的漸進式邏輯,依次完成“場景→元動作→行為→軌跡→控制”的推理鏈。
2.2 數據集構建
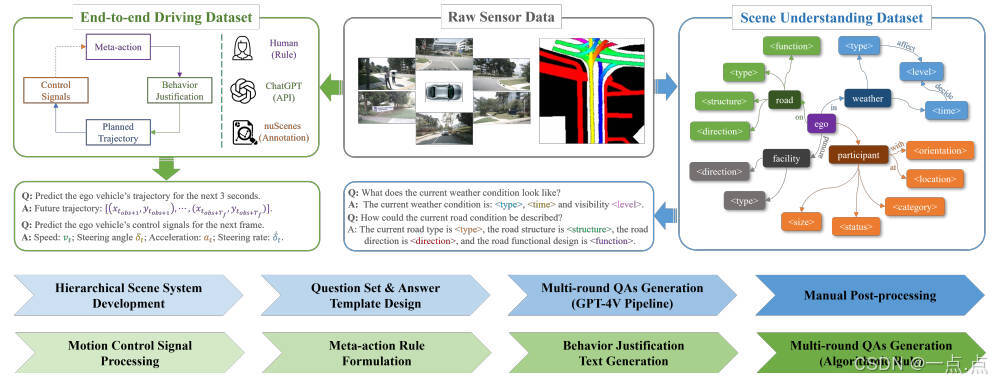
論文提出首個綜合VQA駕駛指令數據集,覆蓋以下內容:
-
層次化場景理解:
-
四類場景元素:天氣、道路、設施、交通參與者(含3D靜態屬性與2D動態行為)。
-
自動化標注:通過ChatGPT生成多輪QA對,結合人工修正避免幻覺問題。
-
-
可解釋端到端駕駛:
-
元動作規則:定義64種組合(如橫向/縱向速度層級、轉向層級),模擬人類駕駛意圖。
-
行為解釋文本:基于場景QA與元動作,由ChatGPT生成決策邏輯描述。
-
控制信號:解析nuScenes原始數據,生成軌跡(位置序列)與低層控制信號(加速度、轉向角)。
-
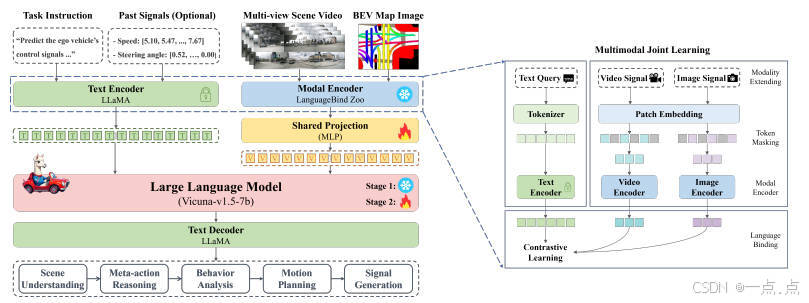
2.3 三階段訓練流程
-
混合對齊預訓練:在CC3M(圖像-文本)和WebVid-10M(視頻-文本)上對齊多模態特征,凍結編碼器權重,僅訓練共享投影層。
-
場景理解微調:使用層次化場景數據集,增強模型對3D空間關系的感知能力。
-
端到端駕駛微調:在可解釋駕駛數據集上優化長軸任務推理(如軌跡規劃與控制生成)。
3. 實驗與性能驗證
3.1 場景理解任務
-
指標:BLEU4、ROUGE、CIDEr等文本生成指標,以及分類準確率(Acc)。
-
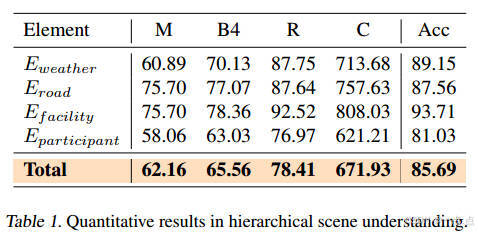
結果(表1):
-
綜合準確率85.69%,其中交通設施識別準確率最高(93.71%)。
-
CIDEr分數達671.93,表明生成描述與真實標注高度一致。
-
3.2 端到端駕駛任務
-
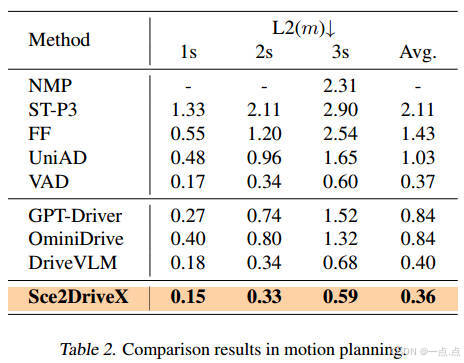
運動規劃(表2):
-
3秒軌跡的L2誤差0.36m,顯著優于傳統方法(UniAD: 1.03m)和MLLM基線(DriveVLM: 0.40m)。
-
-
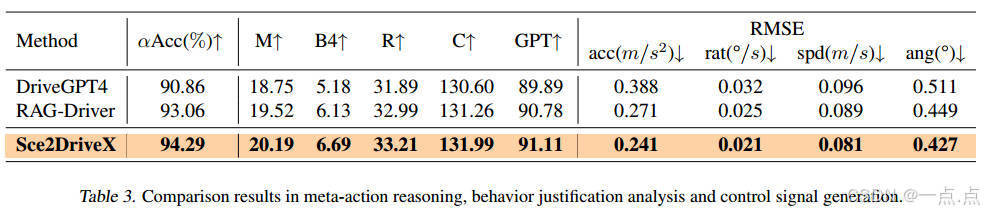
控制信號生成(表3):
-
加速度RMSE為0.241 m/s2,轉向角誤差0.427°,均優于DriveGPT4和RAG-Driver。
-
-
可解釋性:GPT評分91.11(滿分100),表明生成的行為解釋更符合人類邏輯。
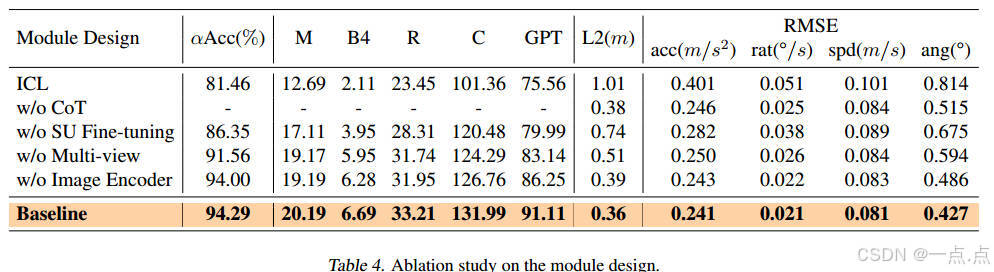
3.3 消融實驗(表4)
-
多視圖輸入:移除后軌跡誤差增加42%(0.51m→0.36m)。
-
場景理解微調:省略后元動作準確率下降8.9%(94.29%→86.35%)。
-
CoT模塊:移除導致行為解釋質量顯著下降(GPT評分從91.11→75.56)。
4. 創新點與局限性
4.1 創新貢獻
-
技術框架:
-
首次將MLLM的鏈式推理(CoT)與自動駕駛的全局-局部感知結合,實現“感知-推理-控制”一體化。
-
提出基于多視圖視頻與BEV地圖的多模態對齊方法,增強時空關系建模。
-
-
數據集:
-
構建首個針對3D空間理解與長軸任務推理的VQA駕駛指令數據集,填補領域空白。
-
-
訓練策略:
-
三階段訓練流程(預訓練→場景微調→駕駛微調)有效平衡通用性與任務適配性。
-
4.2 局限性
-
實時性:未明確模型推理速度,可能限制實際部署。
-
泛化性:實驗基于nuScenes和仿真數據(Bench2Drive),真實復雜場景(如極端天氣、突發障礙)驗證不足。
-
數據依賴:依賴ChatGPT生成標注,可能存在隱含偏差。
5. 未來方向
-
實時性優化:設計輕量級架構或模型壓縮技術,提升推理效率。
-
多模態擴展:融合激光雷達、毫米波雷達等傳感器數據,增強環境感知魯棒性。
-
跨場景驗證:在真實路測場景(如城市道路、高速公路)中評估泛化能力。
-
人機交互增強:結合人類反饋強化學習(RLHF),進一步對齊決策邏輯與人類偏好。
6. 總結
Sec2DriveX通過多模態大語言模型與鏈式推理的深度融合,為自動駕駛提供了一種可解釋、泛化性強的端到端解決方案。其核心價值在于:
-
認知對齊:模仿人類駕駛的漸進式推理邏輯,提升決策透明度。
-
技術突破:在運動規劃與控制信號生成任務中實現SOTA性能。
-
領域推動:構建的數據集與訓練框架為后續研究提供了重要基準。
盡管存在實時性與真實場景驗證的局限,Sec2DriveX為MLLM在自動駕駛中的應用開辟了新范式,有望推動智能駕駛系統向更安全、更可信的方向發展。
如果此文章對您有所幫助,那就請點個贊吧,收藏+關注 那就更棒啦,十分感謝!!!?

工業開發板硬件說明書)


技術詳解)



)










