RAG(Retrieval Augmented Generation,檢索增強生成) 是一種結合了信息檢索與生成式大語言模型(LLM)的技術。它的核心思想是:在生成模型輸出內容之前,先從外部知識庫或數據源中檢索相關信息,然后將這些信息作為上下文輸入給生成模型,從而提升生成內容的準確性、時效性和相關性。
在本文中,我們將使用 LangChain、Higress 和 Elasticsearch 來構建一個 RAG 應用。本文所使用的代碼可以在 Github 上找到:https://github.com/cr7258/hands-on-lab/tree/main/gateway/higress/rag-langchain-es
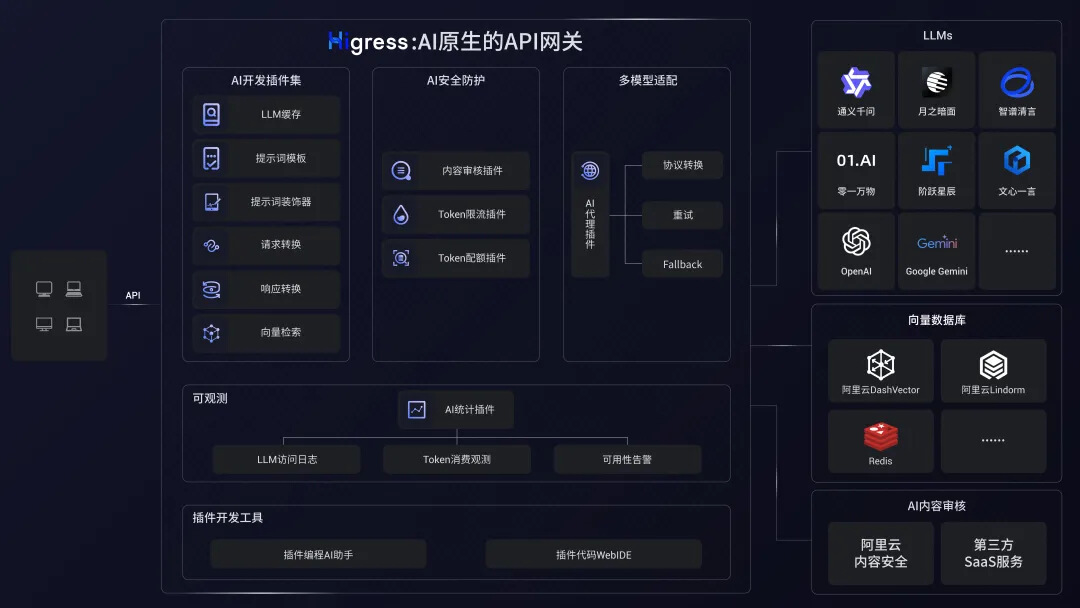
什么是 Higress?
Higress 是一款云原生 API 網關,內核基于 Istio 和 Envoy,可以用 Go/Rust/JS 等編寫 Wasm 插件,提供了數十個現成的通用插件。Higress 同時也能夠作為 AI 網關,通過統一的協議對接國內外所有 LLM 模型廠商,同時具備豐富的 AI 可觀測、多模型負載均衡/fallback、AI token 流控、AI 緩存等能力。
什么是 Elasticsearch?
Elasticsearch 是一個分布式搜索與分析引擎,廣泛用于全文檢索、日志分析和實時數據處理。Elasticsearch 在 8.x 版本中原生引入了向量檢索功能,支持基于稠密向量和稀疏向量的相似度搜索。
什么是 LangChain?
LangChain 是一個開源框架,旨在構建基于大語言模型(LLM)的應用程序。其核心理念是通過將多個功能組件“鏈”式組合,形成完整的業務流程。例如,可以靈活組合數據加載、檢索、提示模板與模型調用等模塊,從而實現智能問答、文檔分析、對話機器人等復雜應用。
在本文中,我們將僅使用 LangChain 的數據加載功能,RAG 檢索能力由 Higress 提供的開箱即用的 ai-search 插件實現。ai-search 插件不僅支持基于 Elasticsearch 的私有知識庫搜索,還支持 Google、Bing、Quark 等主流搜索引擎的在線檢索,以及 Arxiv 等學術文獻的搜索。
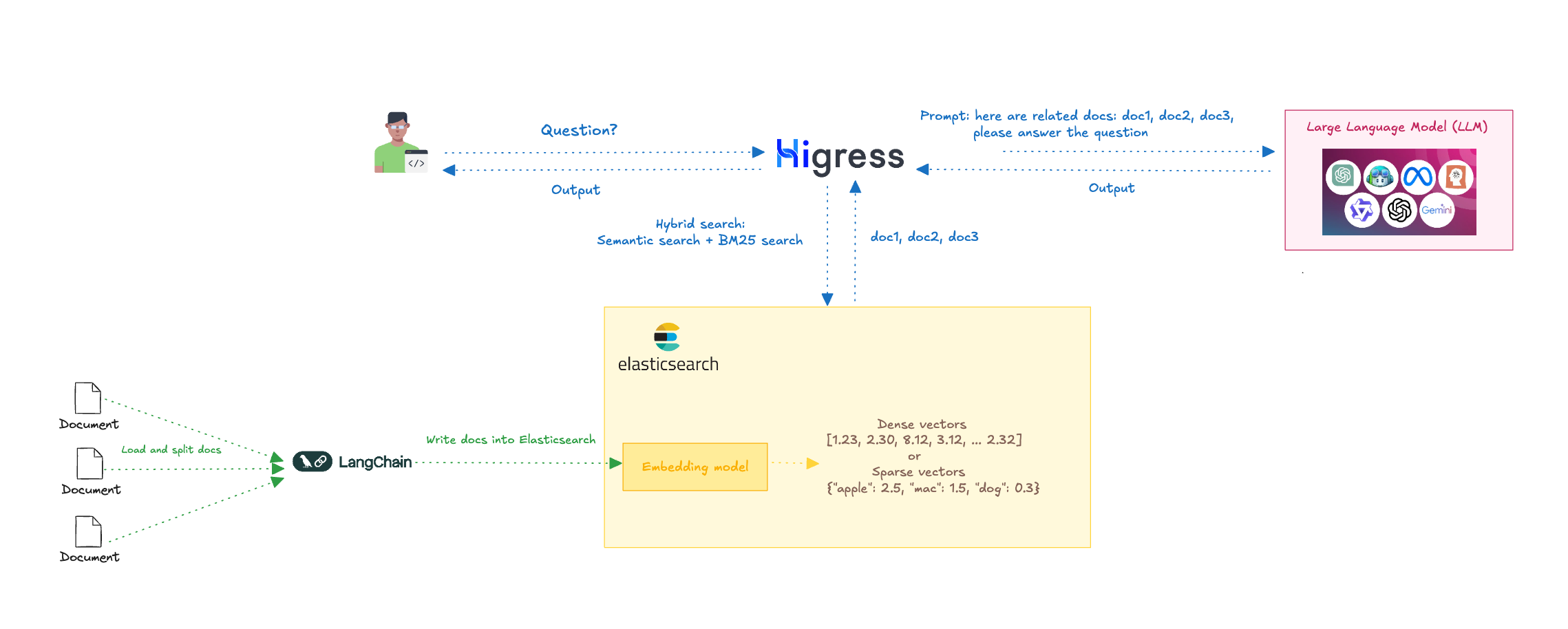
RAG 流程分析
數據預處理階段
在進行 RAG 查詢之前,我們首先需要將原始文檔進行向量化處理,并將其寫入 Elasticsearch。在本文中,我們的文檔是一份 Markdown 格式的員工手冊,我們使用 LangChain 的 MarkdownHeaderTextSplitter 對文檔進行處理。MarkdownHeaderTextSplitter 能夠解析 Markdown 文檔的結構,并根據標題將文檔拆分。Elasticsearch 支持內置的 Embedding模型,本文將使用 Elasticsearch 自帶的 ELSER v2 模型(Elastic Learned Sparse EncodeR),該模型會將文本轉換為稀疏向量。建議將 ELSER v2 模型用于英語文檔的查詢,如果想對非英語文檔執行語義搜索,請使用 E5 模型。
查詢階段
檢索增強生成(RAG)是一個多步驟的過程,首先進行信息檢索,然后進入生成階段。其工作流程如下:
-
- 輸入查詢:首先,從用戶的輸入查詢開始,例如用戶提出的問題。
-
- 信息檢索:然后,Higress 的 ai-search 插件會從 Elasticsearch 中檢索相關信息。ai-search 插件結合語義搜索和全文搜索,使用 RRF(Reciprocal Rank Fusion)進行混合搜索,從而提高搜索的準確性和相關性。
-
- 提示詞生成:Higress 將檢索到的文檔與用戶的問題一起,作為提示詞輸入給 LLM。
-
- 文本生成:LLM 根據檢索到的信息生成文本回答,這些回答通常更加準確,因為它們已經通過檢索模型提供的補充信息進行了優化。
稀疏向量和稠密向量
這里順便介紹一下稀疏向量和稠密向量的區別。稀疏向量(Sparse Vectors)和稠密向量(Dense Vectors)是兩種常見的向量表示形式,在機器學習、搜索和個性化推薦等場景中都廣泛使用。
- 稠密向量(Dense Vectors) 是指在向量空間中,幾乎所有的元素都有值(非零)。每個向量元素通常代表了某一特定特征或維度,稠密向量的維度通常較高(如 512 維或更高),并且每個維度的數值都有一定的實際意義,通常是連續的數值,反映了數據的相似度或特征的權重。
- 稀疏向量(Sparse Vectors) 稀疏向量則是指在向量空間中,大多數元素為零,只有少數元素為非零值。這些非零值通常代表了向量中某些重要特征的存在,尤其適用于文本或特定特征的表示。例如,在文本數據中,詞袋模型(Bag of Words)就是一個稀疏向量的典型例子,因為在大多數情況下,文本中并不會出現所有可能的詞匯,僅有一小部分詞匯會出現在每個文檔中,因此其他詞匯對應的向量值為零。

在 Elasticsearch 中使用稀疏向量進行搜索感覺類似于傳統的關鍵詞搜索,但略有不同。稀疏向量查詢不是直接匹配詞項,而是使用加權詞項和點積來根據文檔與查詢向量的對齊程度對文檔進行評分。

部署 Elasticsearch
在代碼目錄中,我準備了 docker-compose.yaml 文件,用于部署 Elasticsearch。執行以下命令啟動 Elasticsearch:
docker-compose up -d
在瀏覽器輸入 http://localhost:5601 訪問 Kibana 界面,用戶名是 elastic,密碼是 test123。
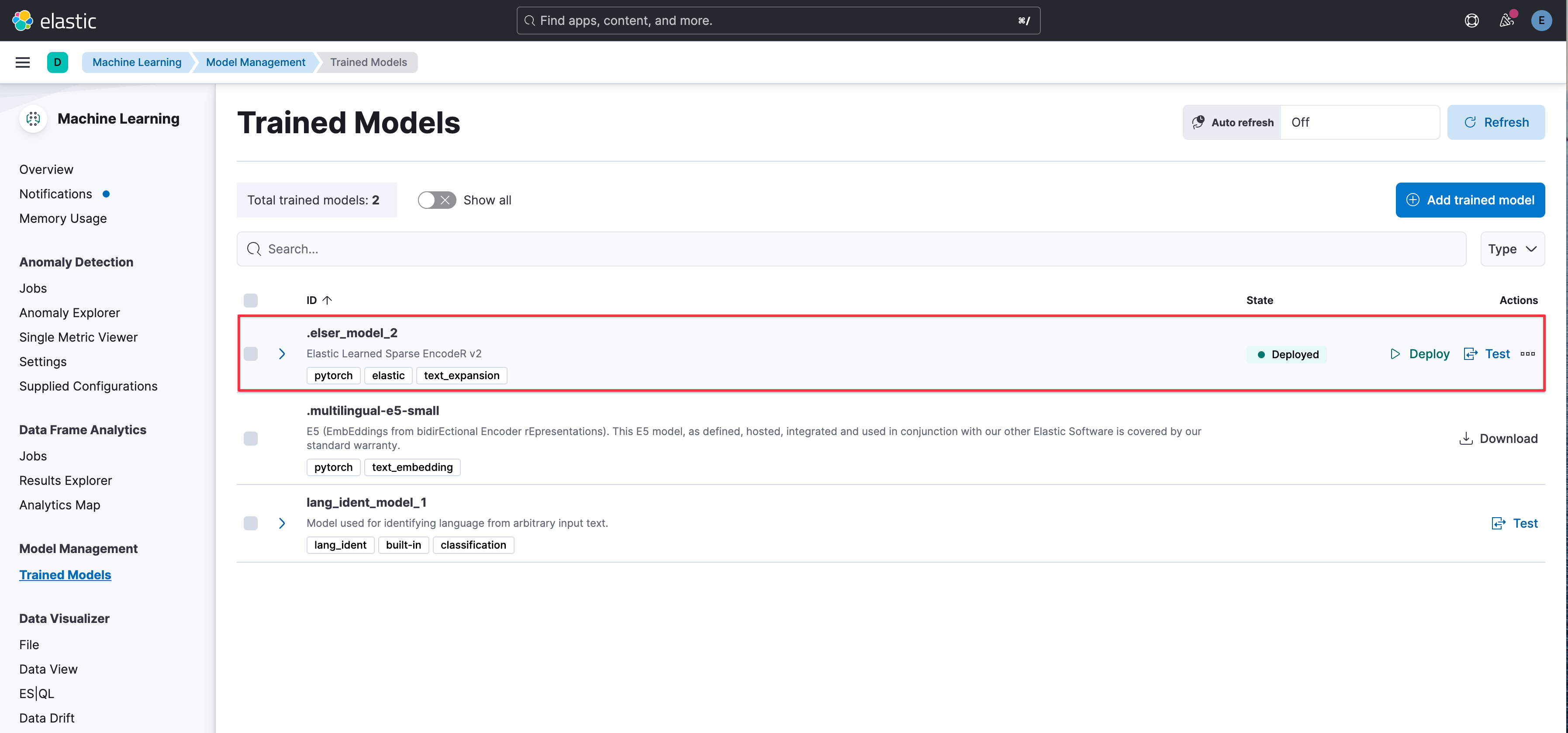
部署 Embedding 模型
Elasticsearch 默認為機器學習(ML)進程分配最多 30% 的機器總內存。如果本地電腦內存較小,可以將 xpack.ml.use_auto_machine_memory_percent 參數設置為 true,允許自動計算 ML 進程可使用的內存占比,從而避免因內存不足而無法部署 Embedding 模型的問題。
在 Kibana 的 Dev Tools 中,執行以下命令進行設置:
PUT _cluster/settings
{"persistent": {"xpack.ml.use_auto_machine_memory_percent": "true"}
}
在 Kibana 上訪問 Machine Learning -> Model Management -> Trained Models,點擊 Download 下載模型,然后點擊 Deploy 部署模型。
創建索引映射
在寫入數據之前,需要先創建索引映射。其中,semantic_text 字段用于存儲稀疏向量,以支持語義搜索;content 字段則用于存儲原始文本內容,以支持全文搜索。
在寫入數據時,只需寫入原始文本。通過 copy_to 配置,content 字段中的文本會自動復制到 semantic_text 字段,并由推理端點進行處理。如果未顯式指定推理端點,semantic_text 字段會默認使用 .elser-2-elasticsearch,這是 Elasticsearch 為 ELSER v2 模型預設的默認推理端點。
PUT employee_handbook
{"mappings": {"properties": {"semantic_text": { "type": "semantic_text"},"content": { "type": "text","copy_to": "semantic_text" }}}
}
解析文檔并寫入 Elasticsearch
安裝 LangChain 相關依賴包:
pip3 install elasticsearch langchain langchain_elasticsearch langchain_text_splitters
以下是相關的 Python 代碼:
MarkdownHeaderTextSplitter是 LangChain 提供的用于解析 Markdown 文件的工具,它能夠根據標題將 Markdown 文檔進行拆分。- 在索引內容時,LangChain 會為每個文檔計算哈希值,并記錄在
RecordManager中,以避免重復寫入。在本文中,我們使用了SQLRecordManager,它將記錄存儲在本地的 SQLite 數據庫中。 - 使用
ElasticsearchStore將文檔寫入 Elasticsearch,只寫入content字段(原始文本內容),并將cleanup模式設置為full。該模式可以確保無論是刪除還是更新,始終保持文檔內容與向量數據庫中的數據一致。關于文檔去重的幾種模式對比,可以參考:How to use the LangChain indexing API。
from langchain_text_splitters import MarkdownHeaderTextSplitter
from elasticsearch import Elasticsearch
from langchain_elasticsearch import ElasticsearchStore
from langchain_elasticsearch import SparseVectorStrategy
from langchain.indexes import SQLRecordManager, index# 1. 加載 Markdown 文件并按標題拆分
with open("./employee_handbook.md") as f:employee_handbook = f.read()headers_to_split_on = [("#", "Header 1"),("##", "Header 2"),("###", "Header 3"),
]markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on, strip_headers=False)
docs = markdown_splitter.split_text(employee_handbook)index_name = "employee_handbook"# 2. 使用 RecordManager 去重
namespace = f"elasticsearch/{index_name}"
record_manager = SQLRecordManager(namespace, db_url="sqlite:///record_manager_cache.sql"
)
record_manager.create_schema()# 3. 寫入 Elasticsearch,只寫入 content 字段(原始文本)
es_connection = Elasticsearch(hosts="https://localhost:9200",basic_auth=("elastic", "test123"),verify_certs=False
)vectorstore = ElasticsearchStore(es_connection=es_connection,index_name=index_name,query_field="content",strategy=SparseVectorStrategy(),
)index_result = index(docs,record_manager,vectorstore,cleanup="full",
)print(index_result)
執行以下內容解析 Markdown 文件并寫入 Elasticsearch:
python3 load-markdown-into-es.py
輸入如下,Markdown 文件被拆分成了 22 個文檔寫入了 Elasticsearch。
{'num_added': 22, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}
我們可以先使用 LangChain 的 similarity_search 來測試查詢效果。由于其默認的查詢語句沒有使用我們想要的 RRF 混合搜索,因此需要自定義查詢語句。后續在使用 Higress 的 ai-search 插件時,也會采用相同的 RRF 混合搜索方式。
def custom_query(query_body: dict, query: str):new_query_body = {"_source": {"excludes": "semantic_text"},"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"match": {"content": query}}}},{"standard": {"query": {"semantic": {"field": "semantic_text","query": query}}}}]}}}return new_query_bodyresults = vectorstore.similarity_search("What are the working hours in the company?", custom_query=custom_query)
print(results[0])
返回內容如下,可以看到準確匹配到了工作時間的相關文檔,公司的上午 9 點到下午 6 點。
page_content='## 4. Attendance Policy
### 4.1 Working Hours
- Core hours: **Monday to Friday, 9:00 AM – 6:00 PM**
- Lunch break: **12:00 PM – 1:30 PM**
- R&D and international teams may operate with flexible schedules upon approval' metadata={'Header 3': '4.1 Working Hours', 'Header 2': '4. Attendance Policy'}
部署 Higress AI 網關
僅需一行命令,即可快速在本地搭建好 Higress AI 網關。
curl -sS https://higress.cn/ai-gateway/install.sh | bash
在瀏覽器中輸入 http://localhost:8001 即可訪問 Higress 的控制臺界面。配置好 Provider 的 ApiToken 后,就可以開始使用 Higress AI 網關了。這里以通義千問為例進行配置。
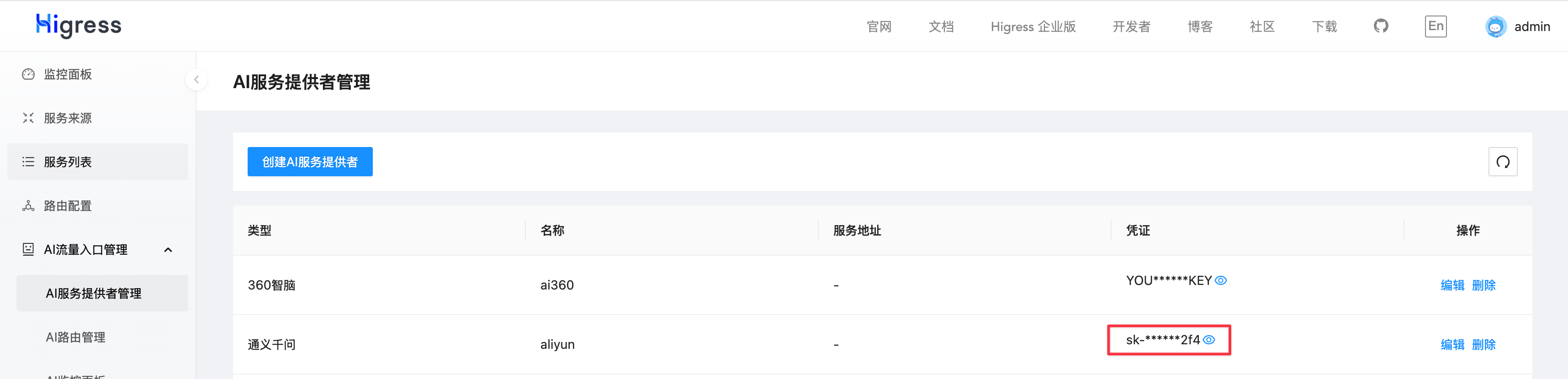
Higress AI 網關已經幫用戶預先配置了 AI 路由,可以根據模型名稱的前綴來路由到不同的 LLM。使用 curl 命令訪問通義千問:
curl 'http://localhost:8080/v1/chat/completions' \-H 'Content-Type: application/json' \-d '{"model": "qwen-turbo","messages": [{"role": "user","content": "Who are you?"}]}'
返回內容如下,可以看到成功收到了來自通義千問的響應。
{"id": "335b58a1-8b47-942c-aa9e-302239c6e652","choices": [{"index": 0,"message": {"role": "assistant","content": "I am Qwen, a large language model developed by Alibaba Cloud. I can answer questions, create text such as stories, emails, scripts, and more. I can also perform logical reasoning, express opinions, and play games. My capabilities include understanding natural language and generating responses that are coherent and contextually appropriate. How can I assist you today?"},"finish_reason": "stop"}],"created": 1745154868,"model": "qwen-turbo","object": "chat.completion","usage": {"prompt_tokens": 12,"completion_tokens": 70,"total_tokens": 82}
}
配置 ai-search 插件
接下來在 Higress 控制臺上配置 ai-search 插件,首先需要將 Elasticsearch 添加到服務來源中,其中 192.168.2.153 是我本機的 IP 地址,請用戶根據實際情況修改。
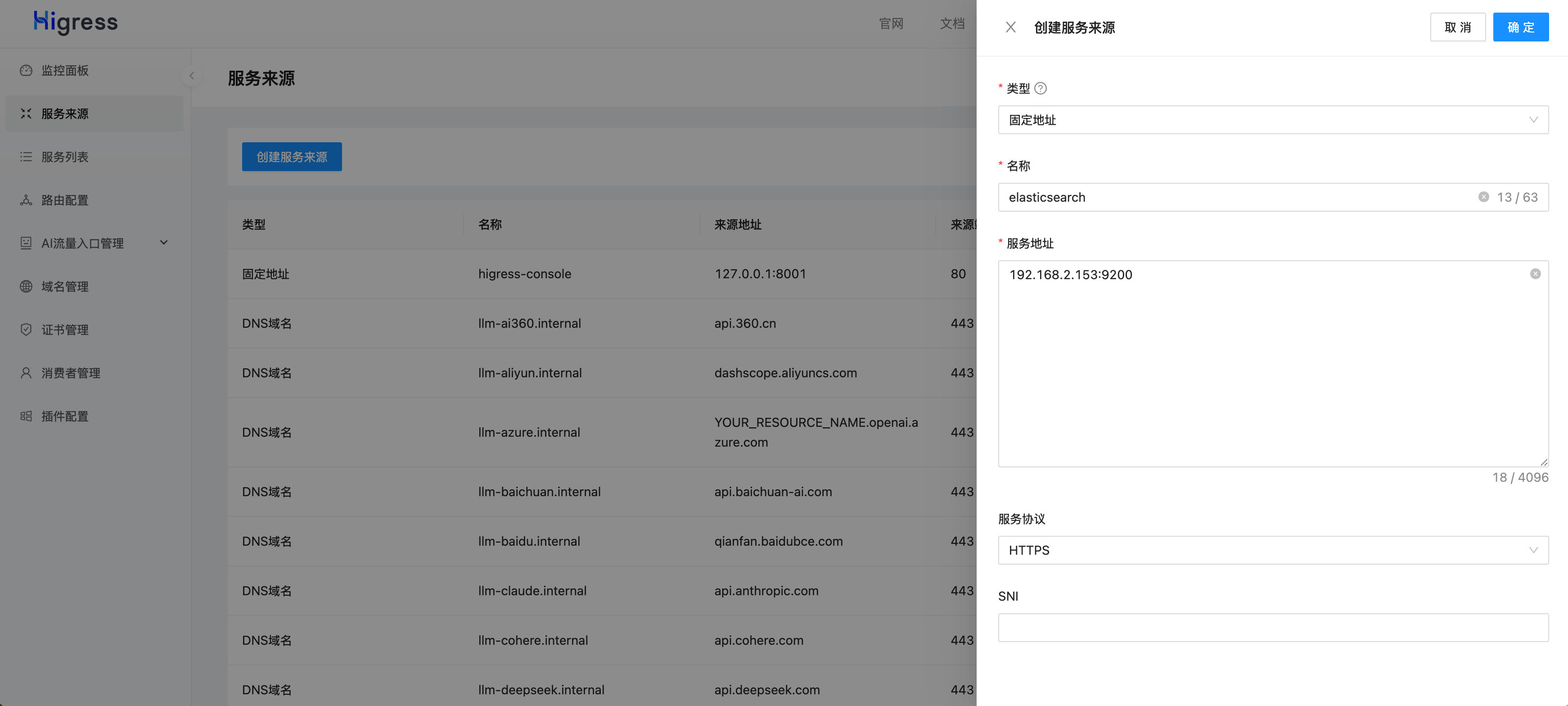
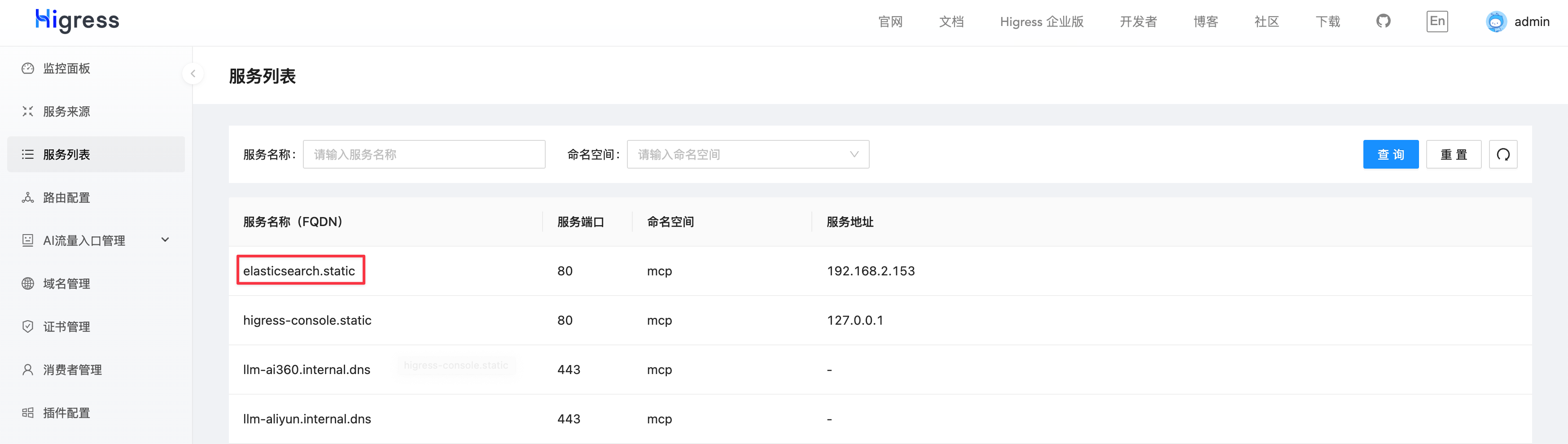
添加完服務來源后,可以在服務列表中找到服務名稱(Service Name),在本例中是 elasticsearch.static。
接下來在通義千問的這條 AI 路由中配置 ai-search 插件。
點擊 AI 搜索增強 插件:
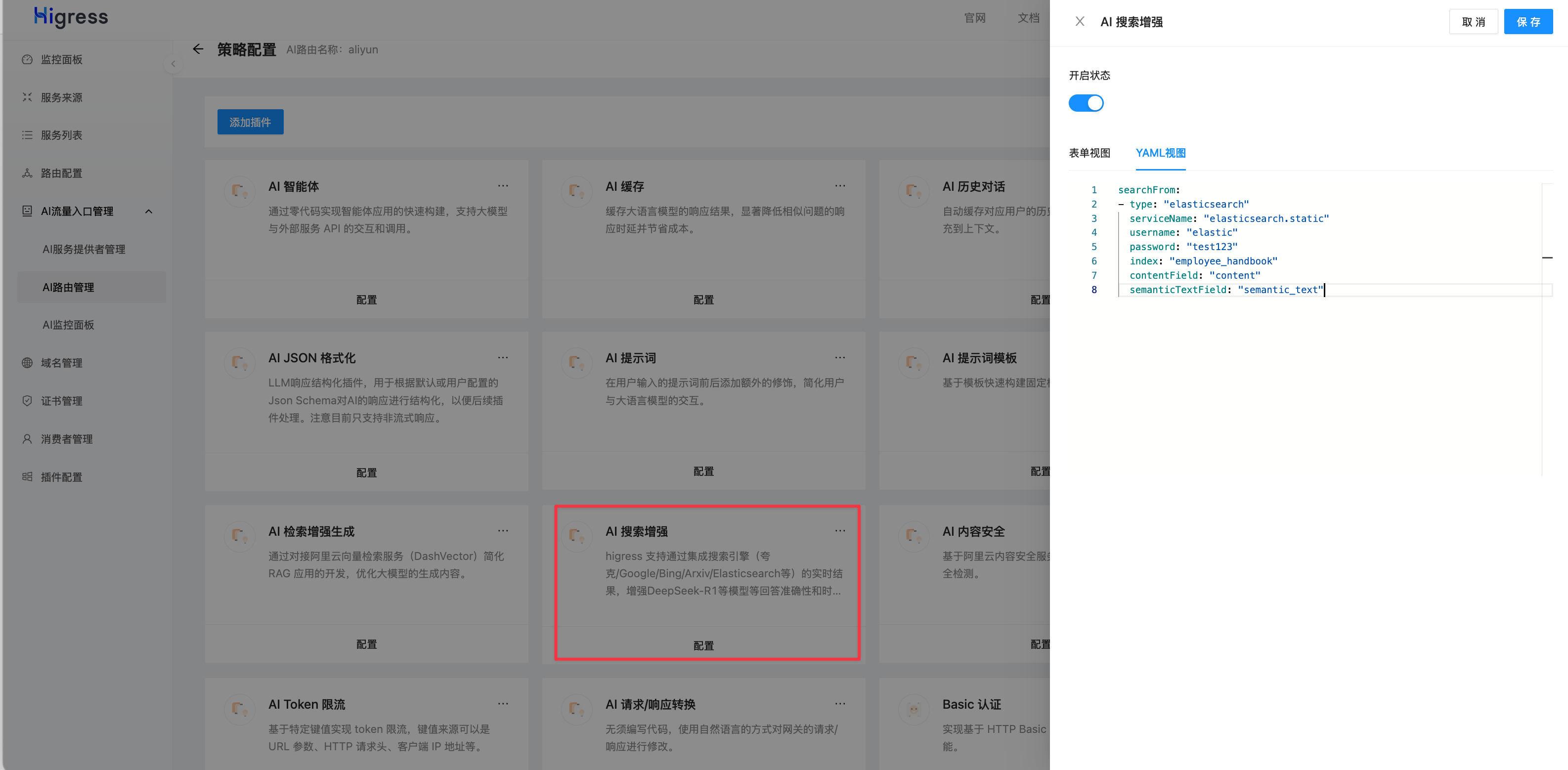
填入以下配置:
searchFrom:
- type: "elasticsearch"serviceName: "elasticsearch.static"username: "elastic"password: "test123"index: "employee_handbook"contentField: "content"semanticTextField: "semantic_text"
RAG 查詢
配置好 ai-search 插件后,就可以開始進行 RAG 查詢了。讓我們先詢問一下公司的工作時間是怎么規定的。
curl 'http://localhost:8080/v1/chat/completions' \-H 'Content-Type: application/json' \-d '{"model": "qwen-turbo","messages": [{"role": "user","content": "What are the working hours in the company?"}]}'
返回內容如下,工作時間是上午 9 點到下午 6 點。
{"id": "c10b9d68-2291-955f-b17a-4d072cc89607","choices": [{"index": 0,"message": {"role": "assistant","content": "The working hours in the company are as follows:\n\n- Core hours: Monday to Friday, 9:00 AM – 6:00 PM.\n- Lunch break: 12:00 PM – 1:30 PM.\n\nR\u0026D and international teams may have flexible schedules upon approval."},"finish_reason": "stop"}],"created": 1745228815,"model": "qwen-turbo","object": "chat.completion","usage": {"prompt_tokens": 433,"completion_tokens": 63,"total_tokens": 496}
}
原始文檔的內容可能會隨著時間的推移而發生變化。接下來,讓我們修改 employee_handbook.md 文件中的工作時間,改成上午 8 點到下午 5 點。
然后重新執行 load-markdown-into-es.py 腳本,這次可以看到有一個文檔被更新了。
{'num_added': 1, 'num_updated': 0, 'num_skipped': 21, 'num_deleted': 1}
再次詢問相同的問題,可以看到返回的答案也相應地更新了。
{"id": "39632a76-7432-92ab-ab86-99a04f211a0d","choices": [{"index": 0,"message": {"role": "assistant","content": "The working hours in the company are as follows:\n\n- **Core hours**: Monday to Friday, 8:00 AM – 5:00 PM.\n- There is a lunch break from **12:00 PM – 1:30 PM**.\n- R\u0026D and international teams may have flexible schedules, but this requires approval.\n\nToday's date is April 21, 2025, so these working hours are still applicable."},"finish_reason": "stop"}],"created": 1745228667,"model": "qwen-turbo","object": "chat.completion","usage": {"prompt_tokens": 433,"completion_tokens": 95,"total_tokens": 528}
}
總結
本文通過實際案例演示了如何利用 LangChain、Higress 和 Elasticsearch 快速搭建 RAG 應用,實現企業知識的智能檢索與問答。通過 Higress 的 ai-search 插件,用戶可以輕松集成在線搜索和私有知識庫,從而打造高效、精準的 RAG 應用。
參考資料
- LangChain Elasticsearch vector store: https://python.langchain.com/docs/integrations/vectorstores/elasticsearch
- How to split Markdown by Headers: https://python.langchain.com/docs/how_to/markdown_header_metadata_splitter/
- How to use the LangChain indexing API: https://python.langchain.com/docs/how_to/indexing/
- Semantic search, leveled up: now with native match, knn and sparse_vector support: https://www.elastic.co/search-labs/blog/semantic-search-match-knn-sparse-vector
- Hybrid search with semantic_text: https://www.elastic.co/docs/solutions/search/hybrid-semantic-text
- Enhancing relevance with sparse vectors: https://www.elastic.co/search-labs/blog/elasticsearch-sparse-vector-boosting-personalization
- What is RAG (retrieval augmented generation)?: https://www.elastic.co/what-is/retrieval-augmented-generation
- No ML nodes with sufficient capacity for trained model deployment: https://discuss.elastic.co/t/no-ml-nodes-with-sufficient-capacity-for-trained-model-deployment/357517
歡迎關注








:節點親和性)







:解讀商業模式拼圖與關鍵指標)


)
