一、引言
從三維建模、虛擬現實到電影級渲染,真實感建模一直是計算機視覺和圖形學的核心目標。
在傳統方法中,我們往往依賴:
- 多視角立體(MVS)
- 點云重建 + 網格擬合
- 顯式建模(如多邊形、體素、TSDF)
直到 2020 年,Google Research 提出了 Neural Radiance Fields(NeRF),用 神經網絡建模一個連續隱式 3D 場景,突破了傳統方法在細節、視角一致性、重建質量上的天花板。
NeRF 不僅是新型表示方式,更是一種將圖像建模與物理一致性結合的范式。
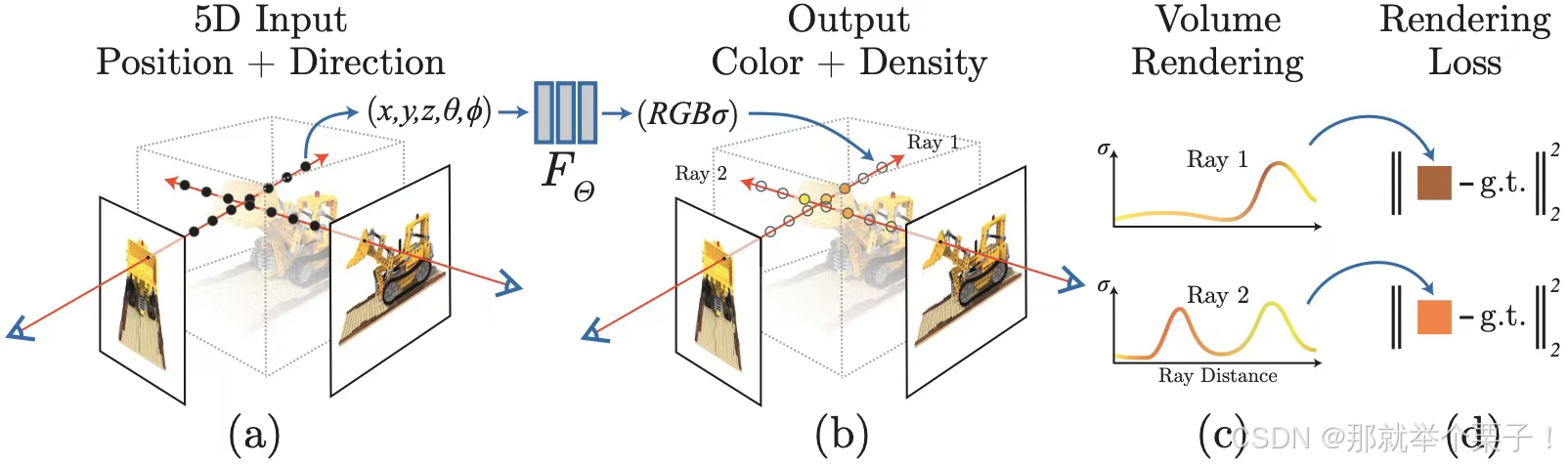
神經輻射場(Neural Radiance Fields, NeRF)是一種前沿的 3D 場景重建技術,利用深度學習從 2D 圖像中建模場景的輻射場,實現高質量的新視角合成。NeRF 在虛擬現實、增強現實、影視特效和游戲開發等領域展現出巨大潛力。
二、什么是NeRF
NeRF 將一個 3D 場景表示為一個 多層感知機(MLP),輸入為:
- 三維空間坐標
- 觀察方向
輸出為: - 顏色
- 體積密度
換句話說,NeRF 建模的是一個連續的函數:
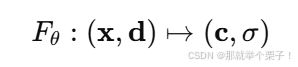
該函數表示某點在某觀察方向上的顏色及其對光線的影響(體積密度)。
三、NeRF和核心技術:體積渲染(Volume Rendering)
為了從這個神經表示中合成圖像,NeRF 引入了基于物理一致的體積渲染公式:
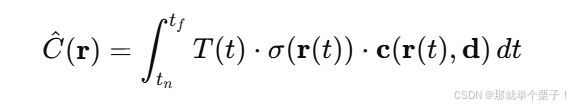
其中:
r ( t ) = o + t d \mathbf{r}(t) = \mathbf{o} + t\mathbf{d} r(t)=o+td 是射線函數
T ( t ) T(t) T(t) 是累積透射率
σ \sigma σ 是密度, c \mathbf{c} c 是顏色
實際實現中使用 分段積分近似,每條光線采樣 N N N 個點,前向傳播預測 ( σ i , c i ) (\sigma_i, \mathbf{c}_i) (σi?,ci?),累加渲染出圖像像素值。
四、NeRF的訓練原理
4.1 訓練數據要求
- 多視角圖像(一般 20~100 張)
- 每張圖像對應的相機位姿(外參)+ 相機內參
4.2 損失函數
對每個像素比較預測顏色與真實圖像顏色:
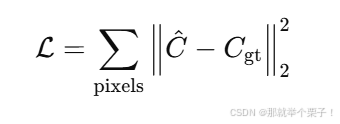
五、環境配置
5.1 硬件要求
- GPU:NeRF 的訓練和推理對計算性能要求較高,推薦使用 NVIDIA GPU(如 GTX 1080 Ti、RTX 2080 Ti 或更高型號)。
- 內存:至少 16GB 系統內存,GPU 顯存建議 8GB 以上。
- 操作系統:Ubuntu 20.04 LTS。
5.2 軟件安裝
5.2.1 克隆NeRF-Pytorch代碼
NeRF-Pytorch:https://github.com/yenchenlin/nerf-pytorch
git clone https://github.com/yenchenlin/nerf-pytorch.git
5.2.2 創建并激活虛擬環境
conda create -n nerf python=3.7
conda activate nerf
5.2.3 安裝Pytorch
根據系統級CUDA決定安裝的Pytorch版本,可以輸入nvcc --version進行查看
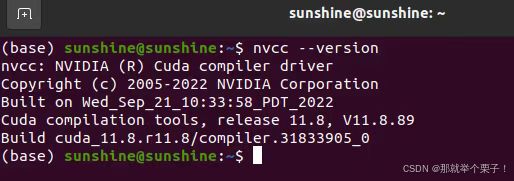
安裝支持cuda11.8的pytorch
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
驗證 PyTorch 是否支持 GPU:
python -c "import torch; print(torch.cuda.is_available())"
如果輸出 True,說明安裝成功且 GPU 可用
5.2.4 安裝項目依賴
cd nerf-pytorch
pip install -r requirements.txt
conda install imagemagick #安裝 ImageMagick(用于處理 LLFF 數據集)
六、公共示例數據集測試
6.1 下載并準備測試數據集
我們將使用官方提供的 “lego” 示例數據集進行測試。這是一個合成數據集,適合快速驗證環境和代碼是否正常工作。
(1)下載 “lego” 數據集:
bash download_example_data.sh
- 這將自動下載 “lego” 和 “fern” 數據集到 ./data 目錄。
- 下載完成后,檢查 ./data/lego 目錄,里面應包含 train、val 和 test 子目錄。
(2)檢察數據集結構
ls ./data/nerf_synthetic/lego

6.2 運行訓練(測試數據集)
(1)修改配置文件
保證自己的數據路徑與configs/fern.txt文件里的datadir路徑相同:
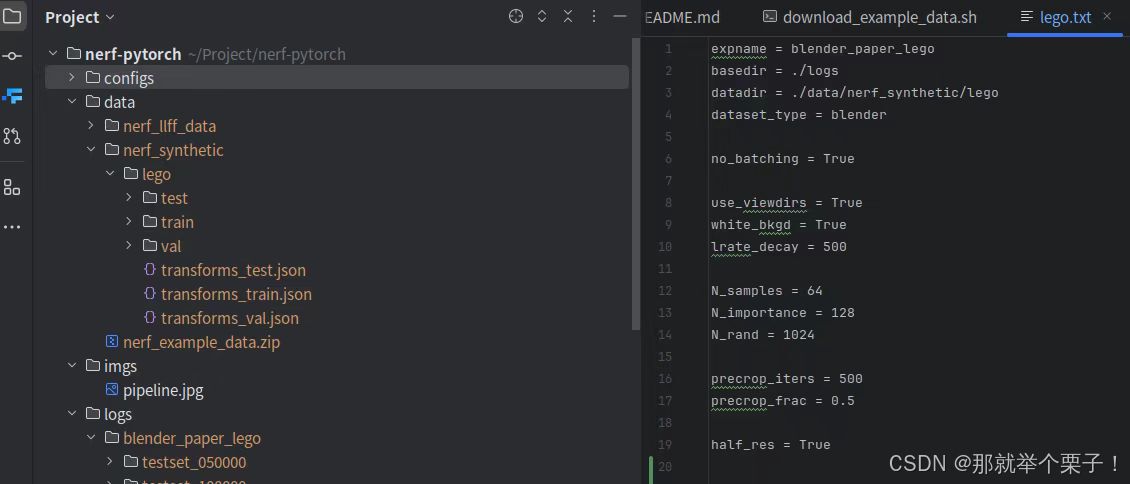
(2)使用提供的配置文件 configs/lego.txt 進行訓練:
python run_nerf.py --config configs/lego.txt
訓練將開始,模型會保存在 ./logs 目錄下。
根據你的 GPU 性能(例如我的 NVIDIA 4090),訓練可能需要半小時左右。
你可以通過以下命令監控 GPU 使用情況:
nvidia-smi
(3)檢查訓練進度:
- 訓練過程中,日志會顯示在終端上,包括損失值(loss)。
- 中間結果會保存在 ./logs/lego 目錄下,你可以用文件瀏覽器查看生成的圖片。
6.3 結果輸出
(1)輸出目錄
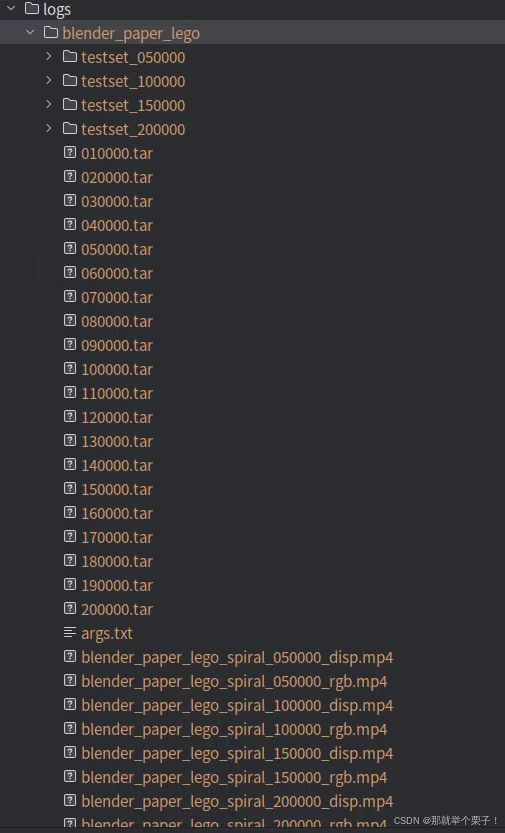
在訓練了 200k 次迭代(在單個 4090 上訓練 半小時)后,可以得到上述結果
(2)輸出結構說明
1、主目錄 logs/
存放所有訓練日志、模型權重、渲染結果等輸出文件的根目錄。
2、實驗場景目錄 blender_paper_lego
每個獨立訓練的場景或實驗對應一個子目錄。
命名規則一般為數據集或場景名稱,如這里的 blender_paper_lego 表示使用了 Blender Lego 數據集。
3、目錄內詳細文件介紹
(一) 模型權重(.tar 文件)
010000.tar、020000.tar … 200000.tar:
這些文件是模型的訓練檢查點(checkpoints)。
文件名數字表示訓練的迭代次數(steps)。
文件內部存儲了:
模型權重參數
優化器狀態
當前訓練進度
作用:
可用于恢復訓練。
用于后續渲染與推理。
(二) 測試集渲染結果文件夾 (testset_xxxxxx)
如:testset_050000、testset_100000 等:
每個文件夾對應不同迭代次數下的測試集圖像預測結果。
文件夾內包含:
渲染后的圖片(.png),表示模型對測試集的推理結果。
圖片以序號或場景名稱為命名,便于觀察模型隨訓練進展的效果變化。
(三) 視頻文件 (.mp4)
視頻文件通常有兩種類型:
*_rgb.mp4:RGB視頻,展示模型從不同視角(一般是螺旋路徑,spiral path)渲染出的彩色場景效果。是模型可視化的直觀表現,用于快速評估渲染質量。*_disp.mp4:Disparity(視差)視頻,展示對應場景深度信息或視差圖。可用以直觀地觀察深度估計的質量。
示例:
blender_paper_lego_spiral_050000_rgb.mp4 表示迭代數 50,000 時模型渲染出的彩色視頻。blender_paper_lego_spiral_050000_disp.mp4 表示迭代數 50,000 時對應的深度渲染視頻。
四、重要配置文件 (args.txt)
記錄訓練期間的全部超參數和配置選項。
如:
訓練迭代次數 (N_iters)學習率 (lrate)數據集路徑 (datadir)模型架構參數(如隱藏層大小,深度等)便于后續復現實驗或調整優化參數。
五、如何使用這些文件?
恢復訓練
使用 checkpoint 文件:
python run_nerf.py --config configs/lego.txt --ft_path ./logs/blender_paper_lego/200000.tar
單獨渲染結果
生成圖片:
python run_nerf.py --config configs/lego.txt --render_only --ft_path ./logs/blender_paper_lego/200000.tar
生成測試視頻:
python run_nerf.py --config configs/lego.txt --render_test --ft_path ./logs/blender_paper_lego/200000.tar
六、實際情況參數調整建議
若顯存不足或訓練過慢:降低 batch size 或訓練圖片的分辨率。降低迭代次數或增加 lrate_decay(學習率衰減步數)。若模型精度不足:提高迭代次數 N_iters。調整分層采樣的數目 (N_samples, N_importance)。
(3)可視化如下所示









:解讀商業模式拼圖與關鍵指標)


)






——LeetCode51.N皇后39.組合總和)


