文章目錄
- 前言
- 一、數據讀取與保存
- 1. 讀取清洗后數據
- 2. 保存數據到CSV文件
- 3. 保存數據到MySQL數據庫
- 二、不同分類統計分析
- 1. 不同分類的圖書數量統計分析
- 2. 不同分類的平均評分統計分析
- 3. 不同分類的平均評價人數統計分析
- 4. 不同分類的平均價格統計分析
- 5. 分類綜合分析
- 三、不同年份統計分析
- 1. 不同年份出版的圖書數量統計分析
- 2. 不同年份出版的圖書平均評分分析
- 3. 不同年份出版的圖書平均評價人數分析
- 4. 不同年份出版的圖書平均價格分析
- 5. 年份綜合分析
- 四、不同作者統計分析
- 1. 不同作者的圖書數量統計分析
- 2. 不同作者的平均評分分析
- 3. 不同作者的平均評價人數分析
- 4. 不同作者的平均價格分析
- 5. 作者綜合分析
- 五、不同出版社分析
- 1. 不同出版社的圖書數量統計分析
- 2. 不同出版社的平均評分分析
- 3. 不同出版社的平均評價人數分析
- 4. 不同出版社的平均價格分析
- 5. 出版社綜合分析
- 六、其他分析
- 1. 圖書評分分布分析
- 2. 圖書價格分布分析
- 3. 譯者翻譯的圖書數量統計分析(前15)
- 4. 評價人數多的圖書分析(前15)
- 5. 評分最高的圖書分析(前15)
- 6. 評價人數最多且評分高的圖書分析(前15)
- 七、完整代碼
前言
本項目旨在通過對豆瓣圖書數據集的詳細分析,挖掘其中隱藏的規律和趨勢,為圖書出版行業、讀者以及相關研究人員提供有價值的參考。從數據讀取與保存這一基礎環節出發,構建了完善的數據處理流程,確保能夠高效地獲取和存儲清洗后的高質量數據,為后續分析筑牢根基。在數據分析階段,從多個維度展開深入探究。在不同分類統計分析中,詳細剖析了各類圖書在數量、平均評分、平均評價人數以及平均價格等方面的表現,有助于出版方精準把握市場需求,讀者快速定位感興趣的圖書類別。針對不同年份的統計分析,能夠清晰洞察圖書出版趨勢隨時間的演變,了解不同年份圖書在質量、受歡迎程度和價格上的變化規律。而對不同作者和出版社的分析,則為評估創作者和出版機構的影響力提供了量化依據。此外,其他分析板塊涵蓋了圖書評分分布、價格分布、熱門圖書篩選等多個視角,進一步豐富了對圖書市場的認知。
一、數據讀取與保存
1. 讀取清洗后數據
def load_data(csv_file_path):try:data = pd.read_csv(csv_file_path)return dataexcept FileNotFoundError:print("未找到指定的 CSV 文件,請檢查文件路徑和文件名。")except Exception as e:print(f"加載數據時出現錯誤: {e}")
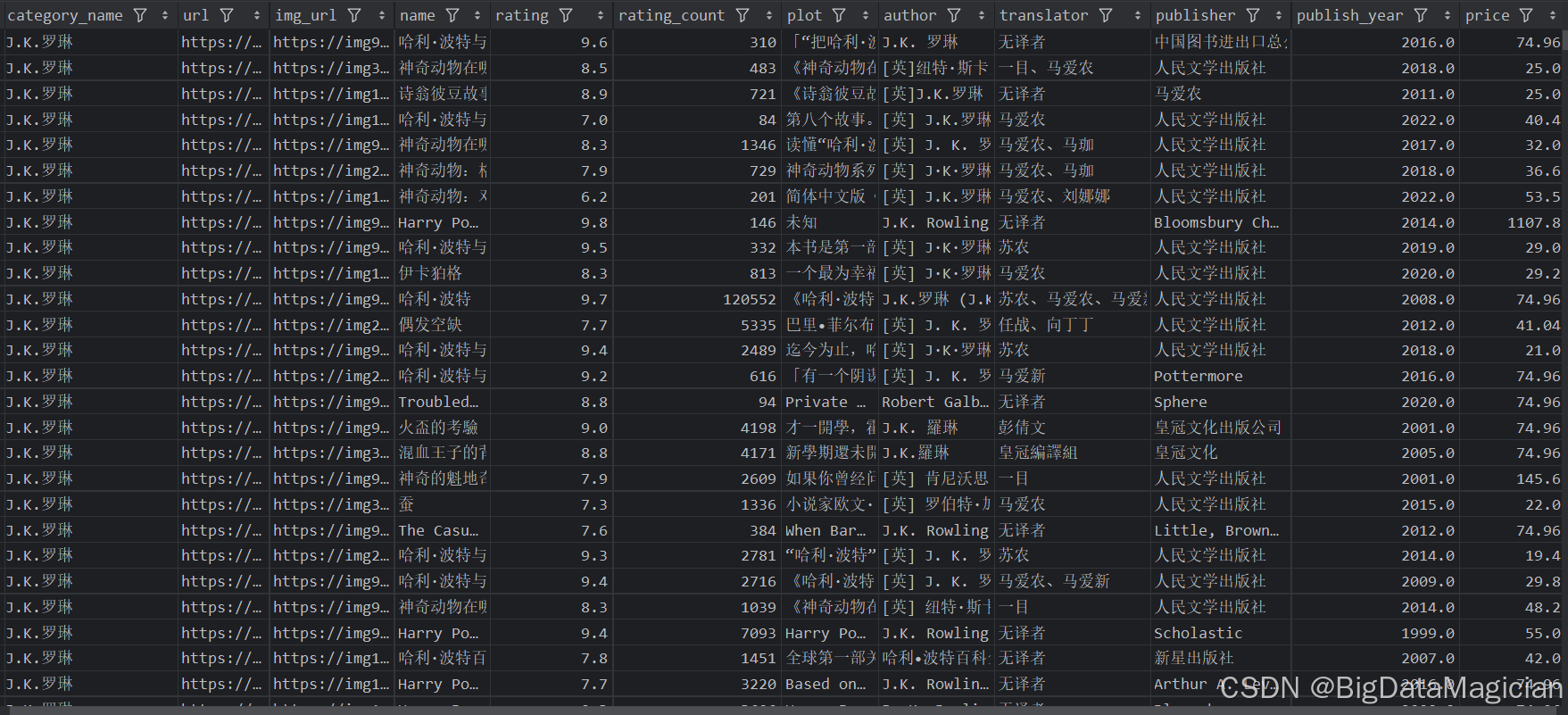
清洗后的部分數據如下圖所示:
2. 保存數據到CSV文件
def save_to_csv(data, csv_file_path):# 使用 pathlib 處理文件路徑path = Path(csv_file_path)# 檢查文件所在目錄是否存在,如果不存在則創建path.parent.mkdir(parents=True, exist_ok=True)data.to_csv(csv_file_path, index=False, encoding='utf-8-sig', mode='w', header=True)print(f'清洗后的數據已保存到 {csv_file_path} 文件')
3. 保存數據到MySQL數據庫
def save_to_mysql(data, table_name):engine = create_engine(f'mysql+mysqlconnector://root:zxcvbq@127.0.0.1:3306/douban')data.to_sql(table_name, con=engine, index=False, if_exists='replace')print(f'清洗后的數據已保存到 {table_name} 表')
二、不同分類統計分析
1. 不同分類的圖書數量統計分析
def category_count_analysis(data):# 統計每個分類的圖書數量category_counts = data['category_name'].value_counts()category_counts = category_counts.reset_index()category_counts.columns = ['category_name', 'count']save_to_csv(category_counts, './結果輸出層/數據分析結果數據/分類圖書數量統計分析.csv')save_to_mysql(category_counts, '分類圖書數量統計分析')
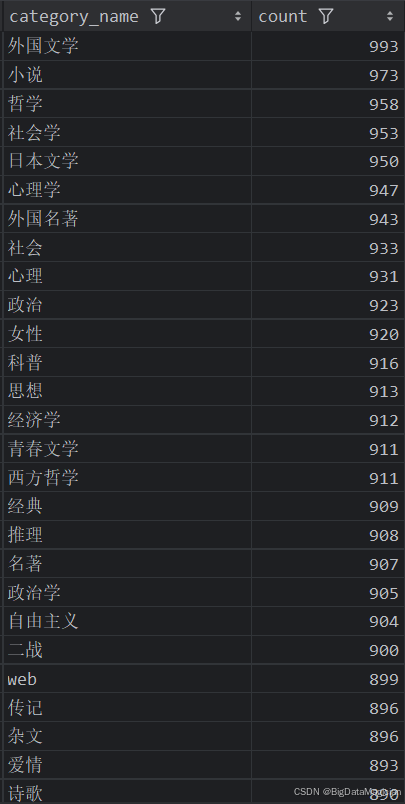
分析結果如下圖所示:
2. 不同分類的平均評分統計分析
def category_rating_analysis(data):# 計算每個分類的平均評分category_ratings = data.groupby('category_name')['rating'].mean().round(1)category_ratings = category_ratings.reset_index()category_ratings.columns = ['category_name', 'avg_rating']save_to_csv(category_ratings, './結果輸出層/數據分析結果數據/每個分類的平均評分統計分析.csv')save_to_mysql(category_ratings, '每個分類的平均評分統計分析')
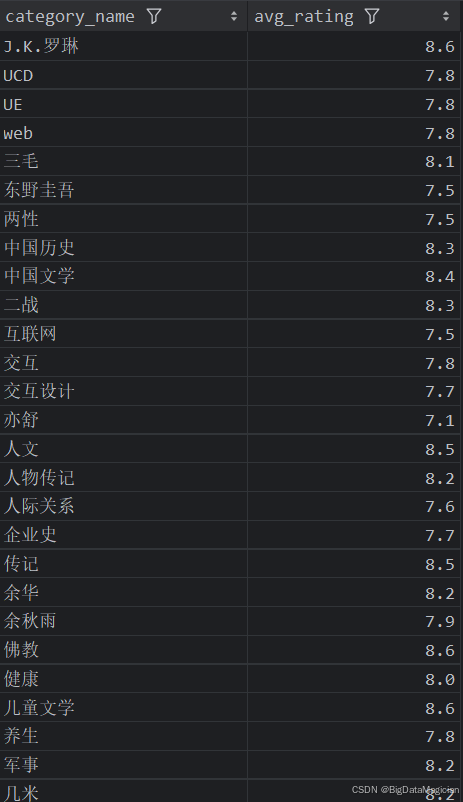
分析結果如下圖所示:
3. 不同分類的平均評價人數統計分析
def category_rating_count_analysis(data):# 計算每個分類的平均評價人數category_rating_counts = data.groupby('category_name')['rating_count'].mean().round(0)category_rating_counts = category_rating_counts.reset_index()category_rating_counts.columns = ['category_name', 'avg_rating_count']save_to_csv(category_rating_counts, './結果輸出層/數據分析結果數據/每個分類的平均評價人數統計分析.csv')save_to_mysql(category_rating_counts, '每個分類的平均評價人數統計分析')
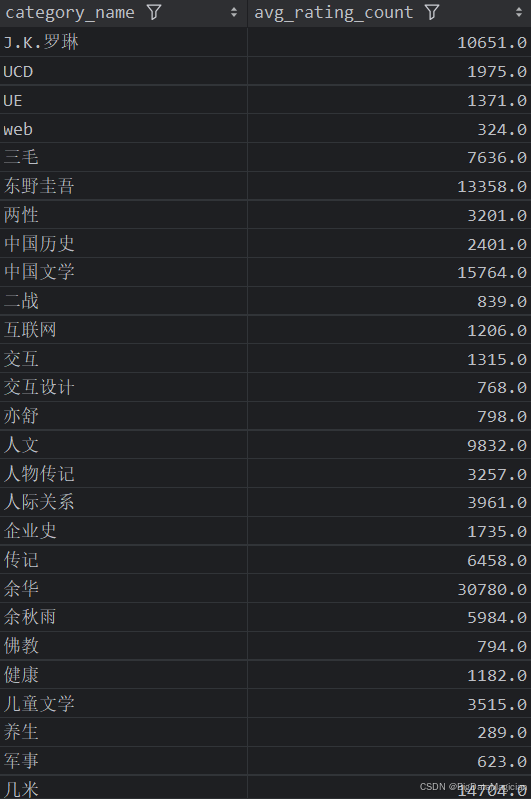
分析結果如下圖所示:
4. 不同分類的平均價格統計分析
def category_price_analysis(data):# 計算每個分類的平均價格category_prices = data.groupby('category_name')['price'].mean().round(1)category_prices = category_prices.reset_index()category_prices.columns = ['category_name', 'avg_price']save_to_csv(category_prices, './結果輸出層/數據分析結果數據/每個分類的平均價格統計分析.csv')save_to_mysql(category_prices, '每個分類的平均價格統計分析')
分析結果如下圖所示:
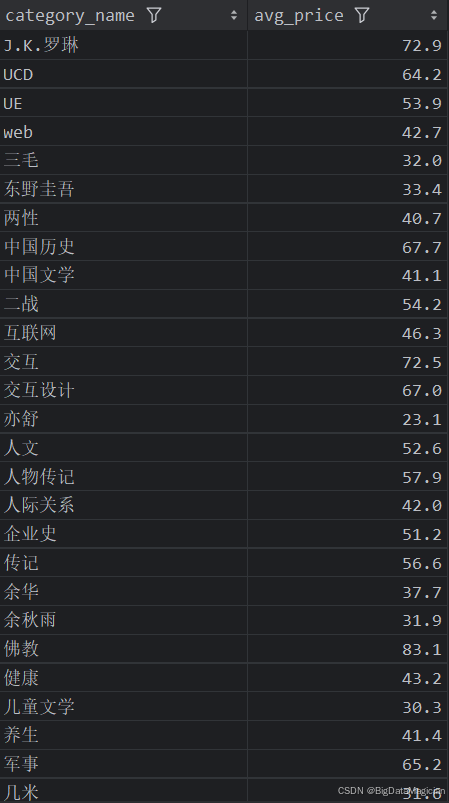
5. 分類綜合分析
def category_analysis(data):# 統計每個分類的圖書數量category_counts = data['category_name'].value_counts()category_counts = category_counts.reset_index()category_counts.columns = ['category_name', 'count']# 計算每個分類的平均評分category_ratings = data.groupby('category_name')['rating'].mean().round(1)category_ratings = category_ratings.reset_index()category_ratings.columns = ['category_name', 'avg_rating']# 計算每個分類的平均評價人數category_rating_counts = data.groupby('category_name')['rating_count'].mean().round(0)category_rating_counts = category_rating_counts.reset_index()category_rating_counts.columns = ['category_name', 'avg_rating_count']# 計算每個分類的平均價格category_prices = data.groupby('category_name')['price'].mean().round(1)category_prices = category_prices.reset_index()category_prices.columns = ['category_name', 'avg_price']# 合并四個結果merged_result = pd.merge(category_counts, category_ratings, on='category_name', how='outer')merged_result = pd.merge(merged_result, category_rating_counts, on='category_name', how='outer')merged_result = pd.merge(merged_result, category_prices, on='category_name', how='outer')# 保存合并后的結果到 CSV 文件save_to_csv(merged_result, './結果輸出層/數據分析結果數據/每種分類的圖書數量和平均評分和平均評價人數和平均價格統計分析.csv')save_to_mysql(merged_result, '每種分類的圖書數量和平均評分和平均評價人數和平均價格統計分析')
分析結果如下圖所示:
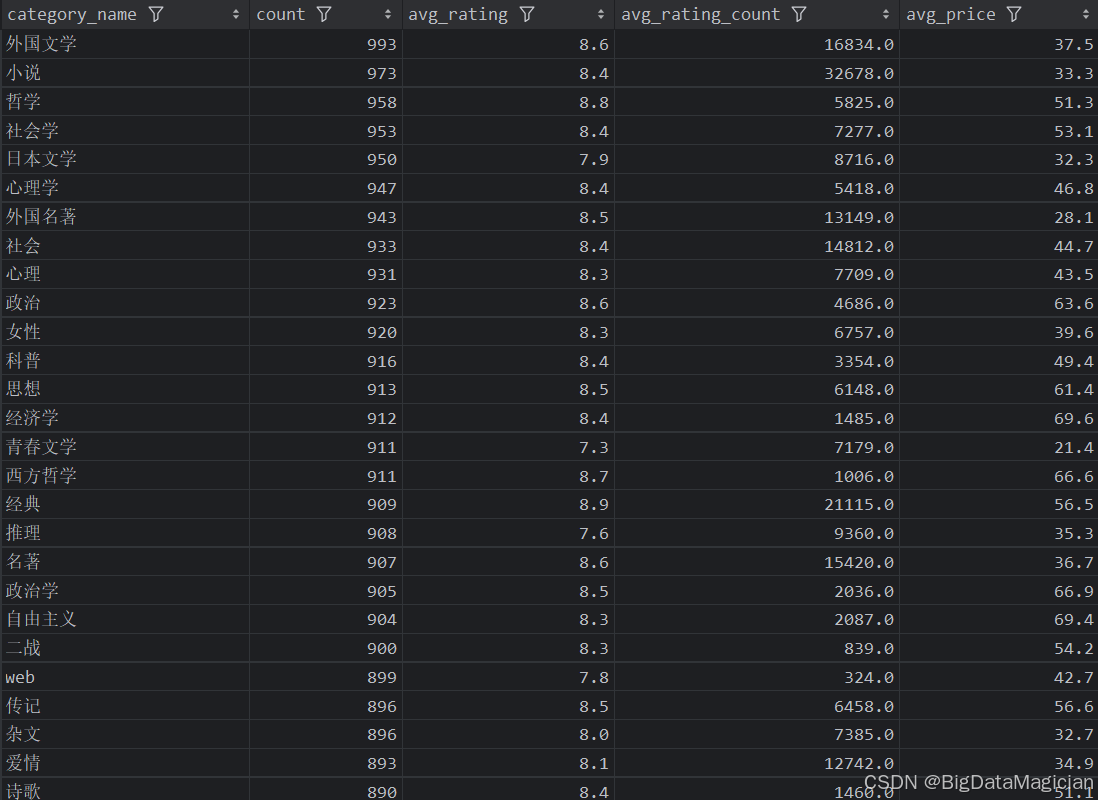
三、不同年份統計分析
1. 不同年份出版的圖書數量統計分析
def year_count_analysis(data):# 統計每年出版的圖書數量year_counts = data['publish_year'].value_counts()year_counts = year_counts.reset_index()# 按照年份升序排序year_counts = year_counts.sort_values(by='publish_year')year_counts.columns = ['publish_year', 'count']save_to_csv(year_counts, './結果輸出層/數據分析結果數據/每年出版的圖書數量統計分析.csv')save_to_mysql(year_counts, '每年出版的圖書數量統計分析')
分析結果如下圖所示:
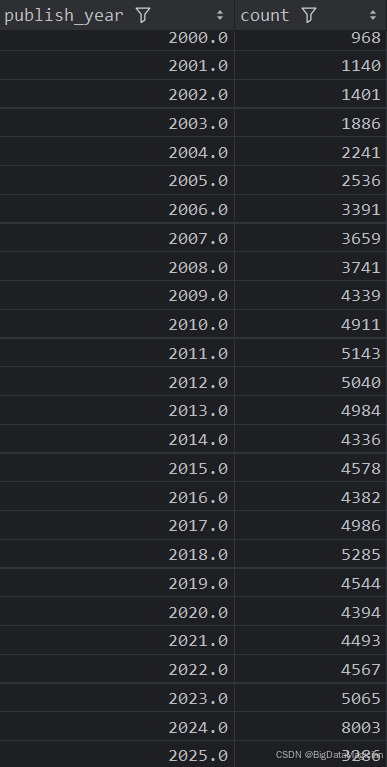
2. 不同年份出版的圖書平均評分分析
def year_rating_analysis(data):year_ratings = data.groupby('publish_year')['rating'].mean().round(1)year_ratings = year_ratings.reset_index()year_ratings = year_ratings.sort_values(by='publish_year')year_ratings.columns = ['publish_year', 'avg_rating']save_to_csv(year_ratings, './結果輸出層/數據分析結果數據/每年出版的圖書平均評分分析.csv')save_to_mysql(year_ratings, '每年出版的圖書平均評分分析')
分析結果如下圖所示:
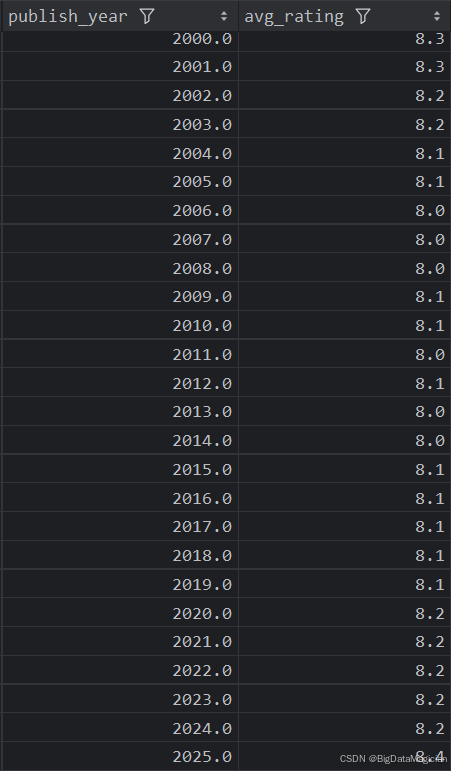
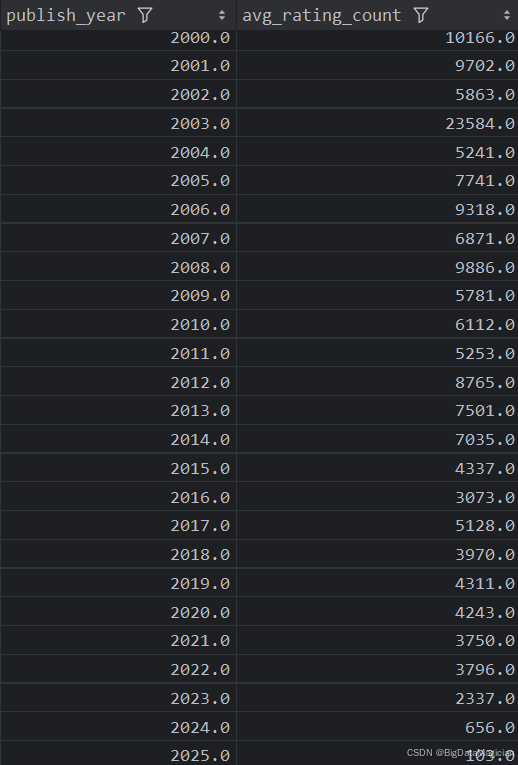
3. 不同年份出版的圖書平均評價人數分析
def year_rating_count_analysis(data):year_rating_counts = data.groupby('publish_year')['rating_count'].mean().round(0)year_rating_counts = year_rating_counts.reset_index()year_rating_counts = year_rating_counts.sort_values(by='publish_year')year_rating_counts.columns = ['publish_year', 'avg_rating_count']save_to_csv(year_rating_counts, './結果輸出層/數據分析結果數據/每年出版圖書平均評價人數分析.csv')save_to_mysql(year_rating_counts, '每年出版圖書平均評價人數分析')
分析結果如下圖所示:
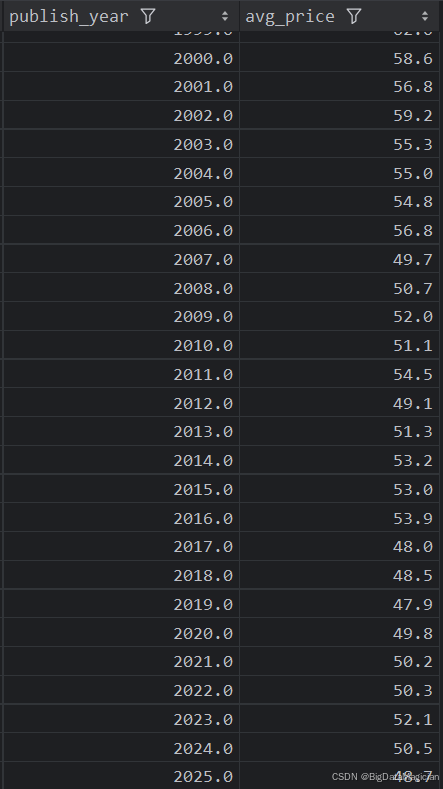
4. 不同年份出版的圖書平均價格分析
def year_price_analysis(data):year_prices = data.groupby('publish_year')['price'].mean().round(1)year_prices = year_prices.reset_index()year_prices = year_prices.sort_values(by='publish_year')year_prices.columns = ['publish_year', 'avg_price']save_to_csv(year_prices, './結果輸出層/數據分析結果數據/每年出版圖書平均價格分析.csv')save_to_mysql(year_prices, '每年出版圖書平均價格分析')
分析結果如下圖所示:
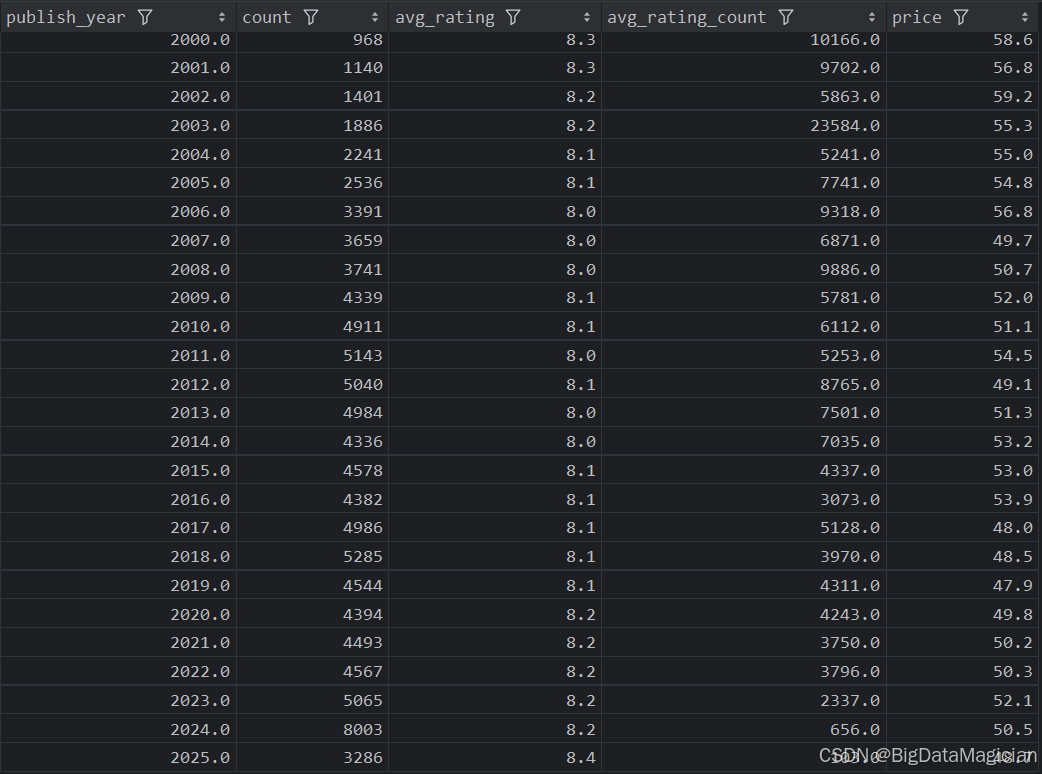
5. 年份綜合分析
def year_analysis(data):# 每年出版的圖書數量統計分析year_counts = data['publish_year'].value_counts()year_counts = year_counts.reset_index()year_counts = year_counts.sort_values(by='publish_year')year_counts.columns = ['publish_year', 'count']# 每年出版的圖書平均評分分析year_ratings = data.groupby('publish_year')['rating'].mean().round(1)year_ratings = year_ratings.reset_index()year_ratings = year_ratings.sort_values(by='publish_year')year_ratings.columns = ['publish_year', 'avg_rating']# 每年出版的圖書平均評價人數分析year_rating_counts = data.groupby('publish_year')['rating_count'].mean().round(0)year_rating_counts = year_rating_counts.reset_index()year_rating_counts = year_rating_counts.sort_values(by='publish_year')year_rating_counts.columns = ['publish_year', 'avg_rating_count']# 每年出版的圖書平均價格分析year_prices = data.groupby('publish_year')['price'].mean().round(1)year_prices = year_prices.reset_index()year_prices = year_prices.sort_values(by='publish_year')# 合并四個結果merged_result = pd.merge(year_counts, year_ratings, on='publish_year', how='outer')merged_result = pd.merge(merged_result, year_rating_counts, on='publish_year', how='outer')merged_result = pd.merge(merged_result, year_prices, on='publish_year', how='outer')# 保存合并后的結果到 CSV 文件save_to_csv(merged_result, './結果輸出層/數據分析結果數據/每年出版圖書數量和平均評分和平均價格和平均評價人數分析.csv')save_to_mysql(merged_result, '每年出版圖書數量和平均評分和平均價格和平均評價人數分析')
分析結果如下圖所示:
四、不同作者統計分析
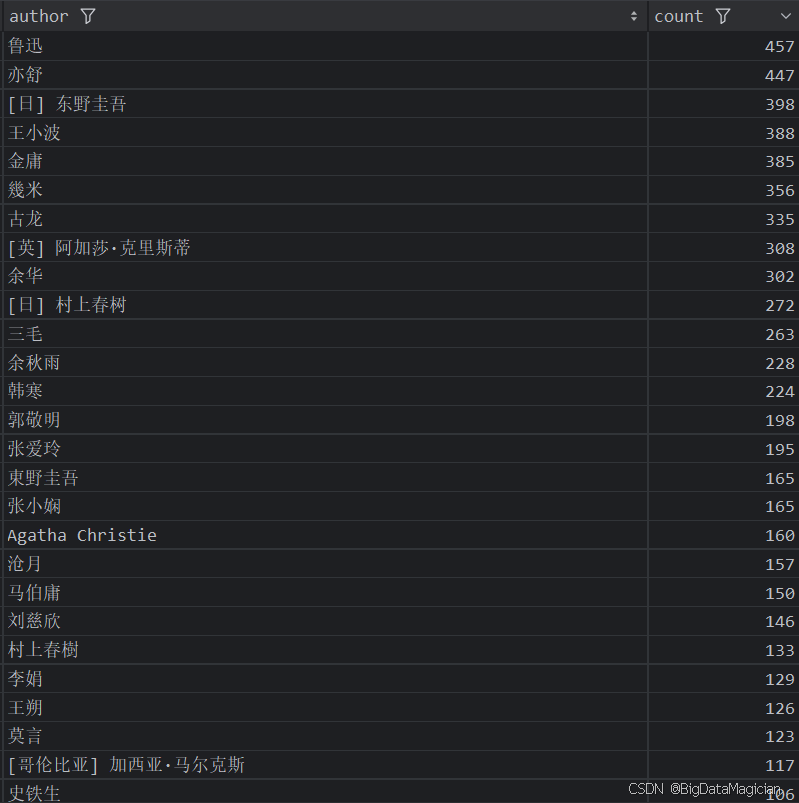
1. 不同作者的圖書數量統計分析
def author_count_analysis(data):# 統計每個作者的圖書數量author_counts = data['author'].value_counts()author_counts = author_counts.reset_index()author_counts.columns = ['author', 'count']save_to_csv(author_counts, './結果輸出層/數據分析結果數據/作者圖書數量統計分析.csv')save_to_mysql(author_counts, '作者圖書數量統計分析')
分析結果如下圖所示:
2. 不同作者的平均評分分析
def author_rating_analysis(data):# 計算每個作者的平均評分author_ratings = data.groupby('author')['rating'].mean().round(1)author_ratings = author_ratings.reset_index()author_ratings.columns = ['author', 'avg_rating']save_to_csv(author_ratings, './結果輸出層/數據分析結果數據/作者平均評分分析.csv')save_to_mysql(author_ratings, '作者平均評分分析')
分析結果如下圖所示:
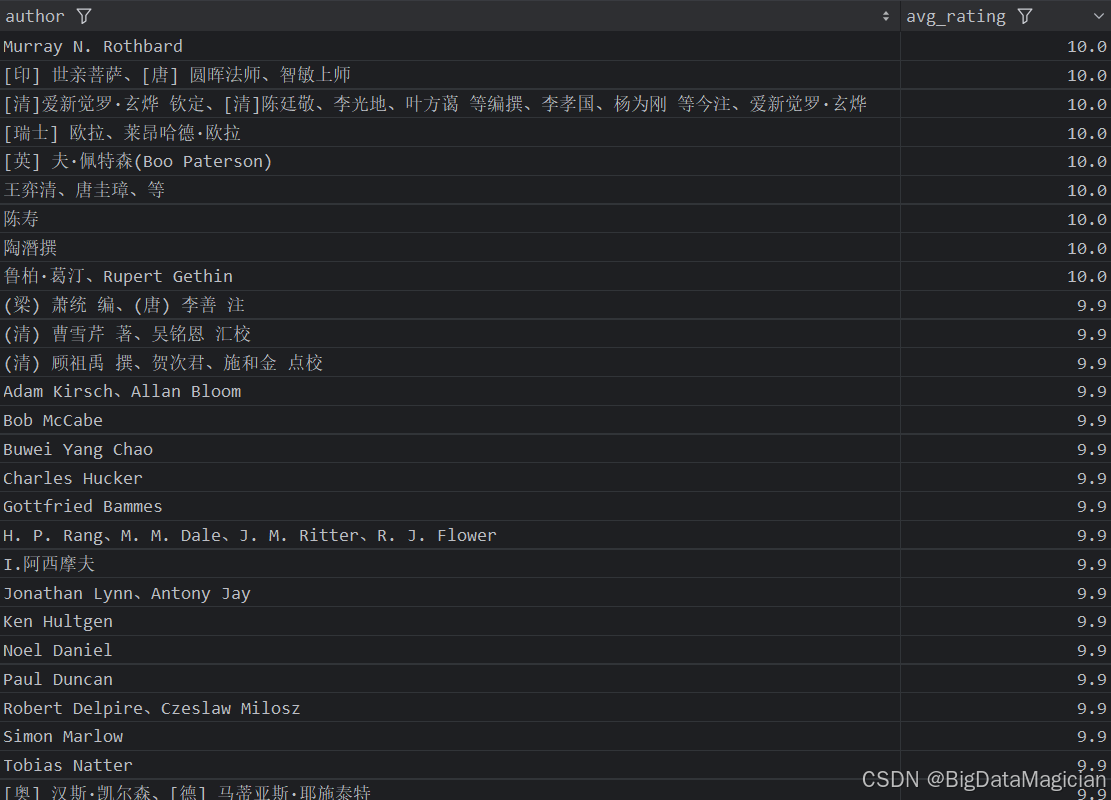
3. 不同作者的平均評價人數分析
def author_rating_count_analysis(data):# 計算每個作者的平均評價人數author_rating_counts = data.groupby('author')['rating_count'].mean().round(0)author_rating_counts = author_rating_counts.reset_index()author_rating_counts.columns = ['author', 'avg_rating_count']save_to_csv(author_rating_counts, './結果輸出層/數據分析結果數據/作者平均評價人數分析.csv')save_to_mysql(author_rating_counts, '作者平均評價人數分析')
分析結果如下圖所示:
4. 不同作者的平均價格分析
def author_price_analysis(data):# 計算每個作者的平均價格author_prices = data.groupby('author')['price'].mean().round(1)author_prices = author_prices.reset_index()author_prices.columns = ['author', 'avg_price']save_to_csv(author_prices, './結果輸出層/數據分析結果數據/作者平均價格分析.csv')save_to_mysql(author_prices, '作者平均價格分析')
分析結果如下圖所示:
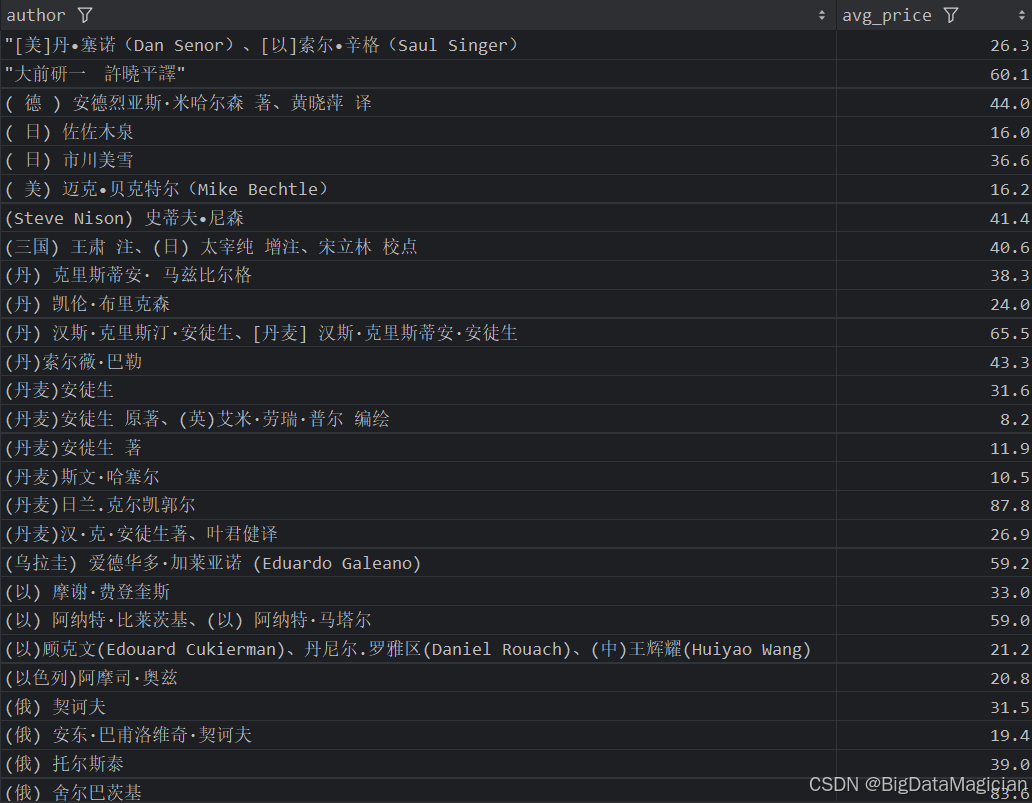
5. 作者綜合分析
def author_analysis(data):# 每個作者的圖書數量統計分析author_counts = data['author'].value_counts()author_counts = author_counts.reset_index()author_counts.columns = ['author', 'count']# 每個作者的平均評分分析author_ratings = data.groupby('author')['rating'].mean().round(1)author_ratings = author_ratings.reset_index()author_ratings.columns = ['author', 'avg_rating']# 每個作者的平均評價人數分析author_rating_counts = data.groupby('author')['rating_count'].mean().round(0)author_rating_counts = author_rating_counts.reset_index()author_rating_counts.columns = ['author', 'avg_rating_count']# 每個作者的平均價格分析author_prices = data.groupby('author')['price'].mean().round(1)author_prices = author_prices.reset_index()author_prices.columns = ['author', 'avg_price']# 合并四個結果merged_result = pd.merge(author_counts, author_ratings, on='author', how='outer')merged_result = pd.merge(merged_result, author_rating_counts, on='author', how='outer')merged_result = pd.merge(merged_result, author_prices, on='author', how='outer')# 保存合并后的結果到 CSV 文件save_to_csv(merged_result, './結果輸出層/數據分析結果數據/作者圖書數量和平均評分和平均價格和平均評價人數分析.csv')save_to_mysql(merged_result, '作者圖書數量和平均評分和平均價格和平均評價人數分析')
分析結果如下圖所示:
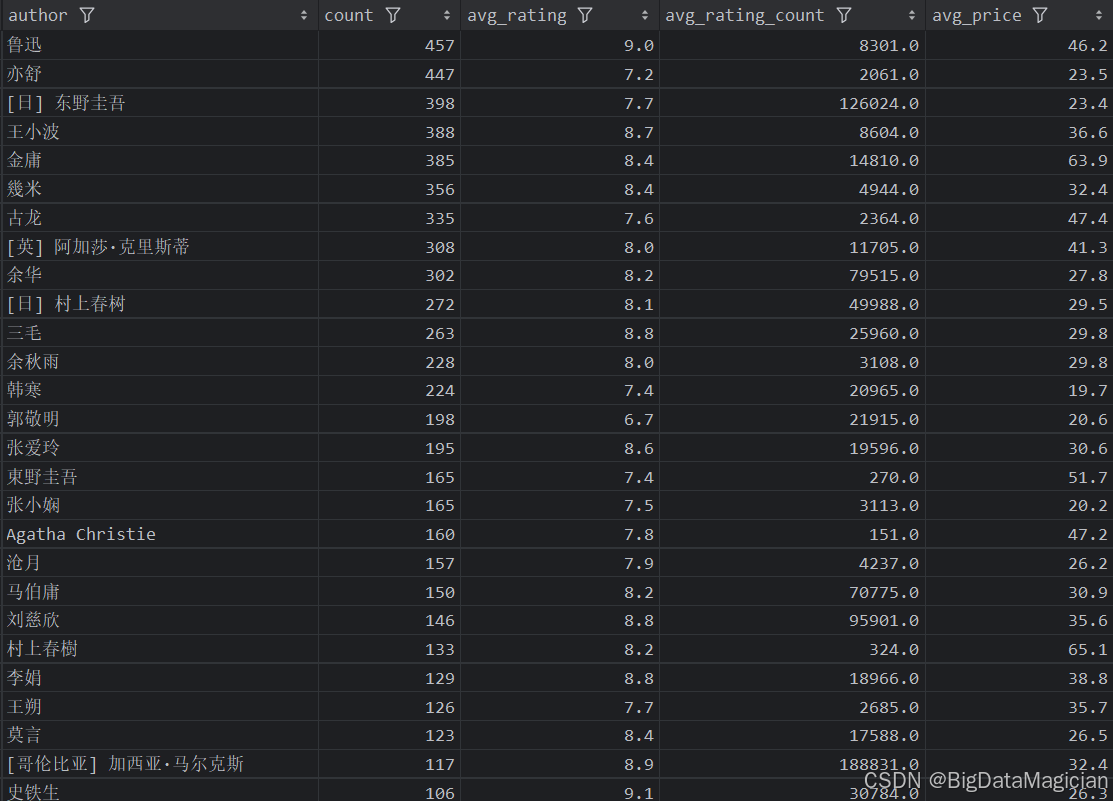
五、不同出版社分析
1. 不同出版社的圖書數量統計分析
def publish_count_analysis(data):# 統計每個出版社的圖書數量publish_counts = data['publisher'].value_counts()publish_counts = publish_counts.reset_index()publish_counts.columns = ['publisher', 'count']save_to_csv(publish_counts, './結果輸出層/數據分析結果數據/出版社圖書數量統計分析.csv')save_to_mysql(publish_counts, '出版社圖書數量統計分析')
分析結果如下圖所示:
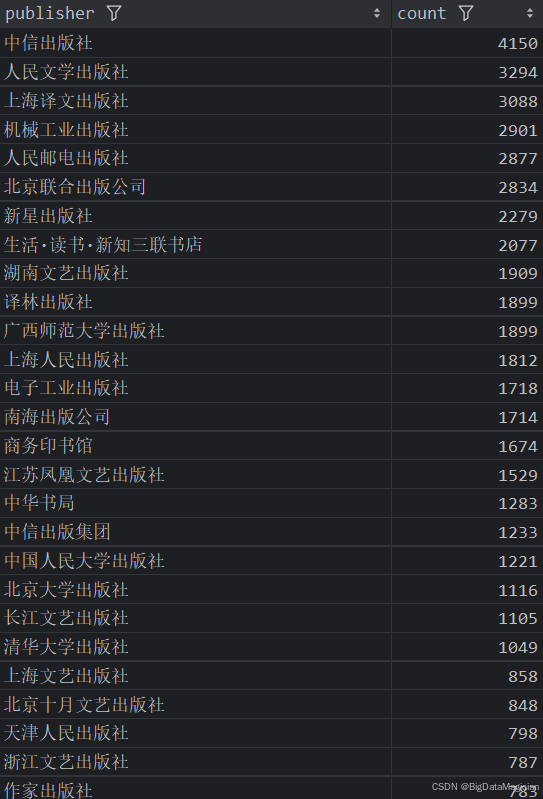
2. 不同出版社的平均評分分析
def publish_rating_analysis(data):# 計算每個出版社的平均評分publish_ratings = data.groupby('publisher')['rating'].mean().round(1)publish_ratings = publish_ratings.reset_index()publish_ratings.columns = ['publisher', 'avg_rating']save_to_csv(publish_ratings, './結果輸出層/數據分析結果數據/出版社平均評分分析.csv')save_to_mysql(publish_ratings, '出版社平均評分分析')
分析結果如下圖所示:
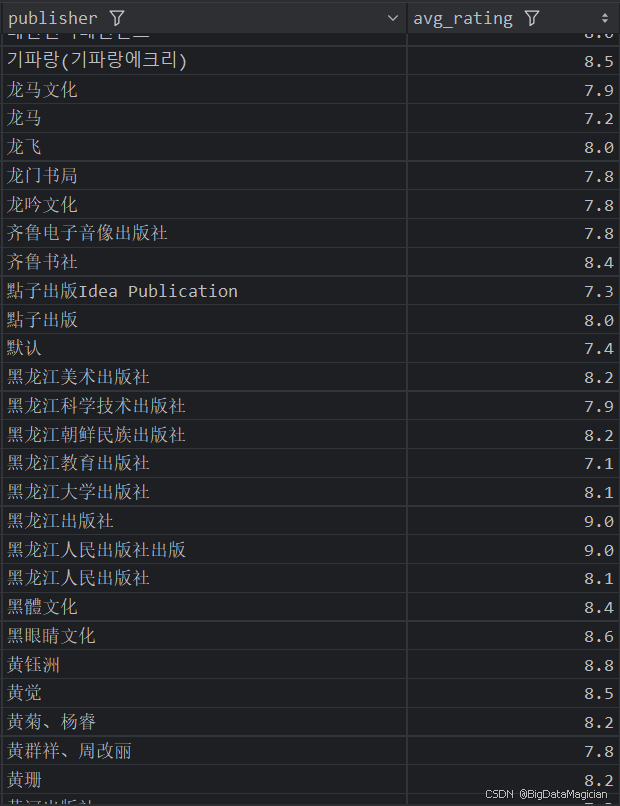
3. 不同出版社的平均評價人數分析
def publish_rating_count_analysis(data):# 計算每個出版社的平均評價人數publish_rating_counts = data.groupby('publisher')['rating_count'].mean().round(0)publish_rating_counts = publish_rating_counts.reset_index()publish_rating_counts.columns = ['publisher', 'avg_rating_count']save_to_csv(publish_rating_counts, './結果輸出層/數據分析結果數據/出版社平均評價人數分析.csv')save_to_mysql(publish_rating_counts, '出版社平均評價人數分析')
分析結果如下圖所示:
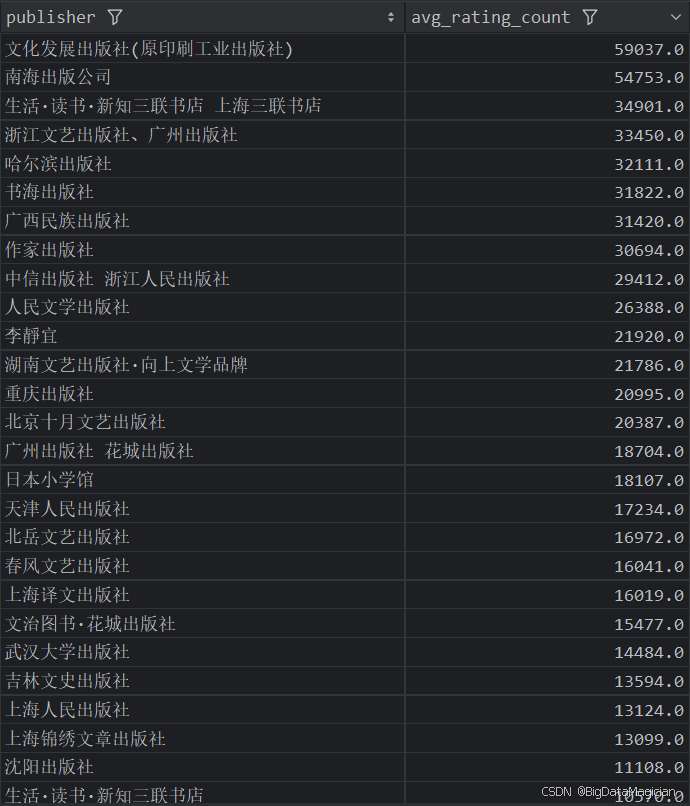
4. 不同出版社的平均價格分析
def publish_price_analysis(data):# 計算每個出版社的平均價格publish_prices = data.groupby('publisher')['price'].mean().round(1)publish_prices = publish_prices.reset_index()publish_prices.columns = ['publisher', 'avg_price']save_to_csv(publish_prices, './結果輸出層/數據分析結果數據/出版社平均價格分析.csv')save_to_mysql(publish_prices, '出版社平均價格分析')
分析結果如下圖所示:
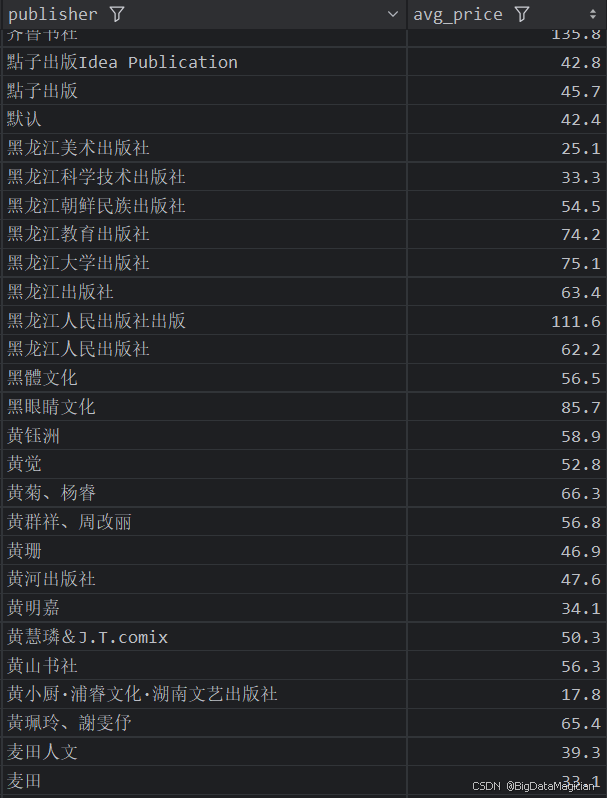
5. 出版社綜合分析
def publish_analysis(data):# 每個出版社的圖書數量統計分析publish_counts = data['publisher'].value_counts()publish_counts = publish_counts.reset_index()publish_counts.columns = ['publisher', 'count']# 每個出版社的平均評分分析publish_ratings = data.groupby('publisher')['rating'].mean().round(1)publish_ratings = publish_ratings.reset_index()publish_ratings.columns = ['publisher', 'avg_rating']# 每個出版社的平均評價人數分析publish_rating_counts = data.groupby('publisher')['rating_count'].mean().round(0)publish_rating_counts = publish_rating_counts.reset_index()publish_rating_counts.columns = ['publisher', 'avg_rating_count']# 每個出版社的平均價格分析publish_prices = data.groupby('publisher')['price'].mean().round(1)publish_prices = publish_prices.reset_index()publish_prices.columns = ['publisher', 'avg_price']# 合并四個結果merged_result = pd.merge(publish_counts, publish_ratings, on='publisher', how='outer')merged_result = pd.merge(merged_result, publish_rating_counts, on='publisher', how='outer')merged_result = pd.merge(merged_result, publish_prices, on='publisher', how='outer')# 保存合并后的結果到 CSV 文件save_to_csv(merged_result, './結果輸出層/數據分析結果數據/出版社圖書數量和平均評分和平均價格和平均評價人數分析.csv')save_to_mysql(merged_result, '出版社圖書數量和平均評分和平均價格和平均評價人數分析')
分析結果如下圖所示:
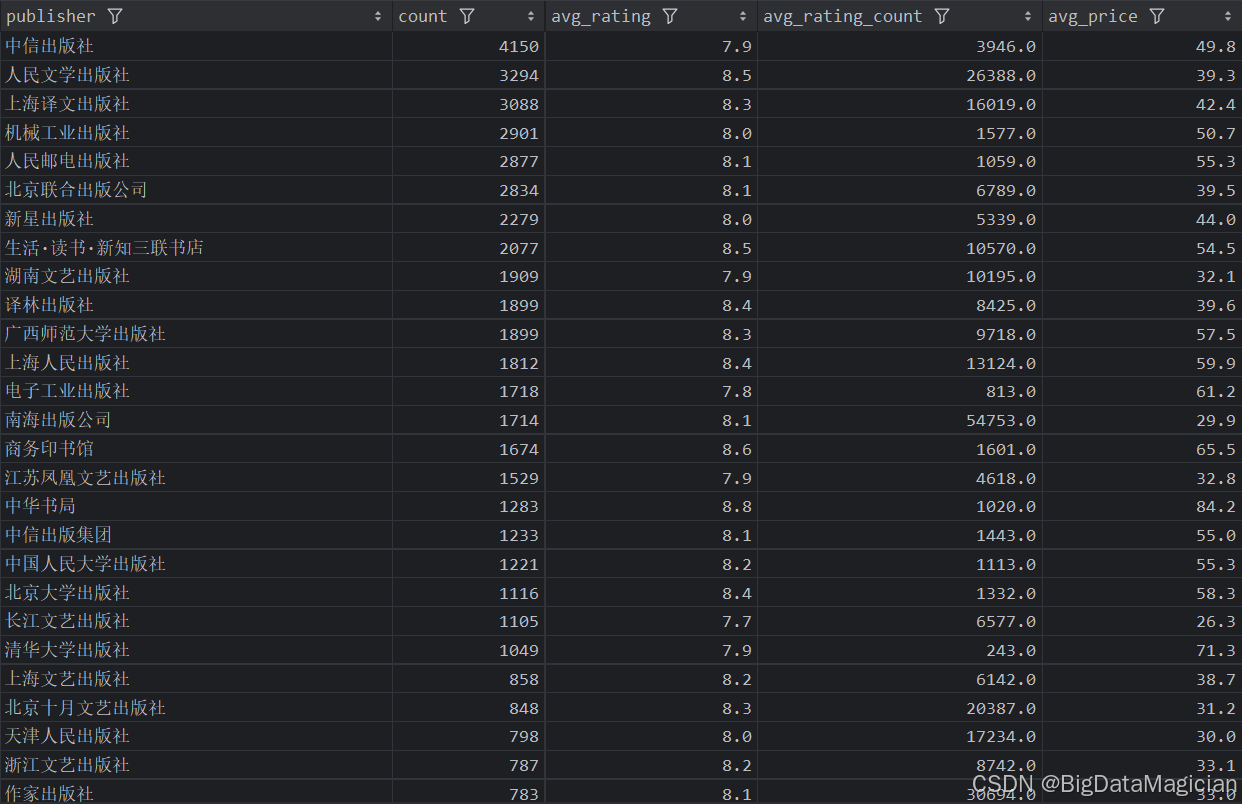
六、其他分析
1. 圖書評分分布分析
def rating_analysis(data):# 定義評分區間bins = [0, 2, 4, 6, 8, 10]labels = ['0-2', '2-4', '4-6', '6-8', '8-10']# 使用 pd.cut 函數將評分進行分組data['rating_group'] = pd.cut(data['rating'], bins=bins, labels=labels, right=False)# 統計每個評分區間的圖書數量rating_counts = data['rating_group'].value_counts()rating_counts = rating_counts.reset_index()rating_counts.columns = ['rating_range', 'count']save_to_csv(rating_counts, './結果輸出層/數據分析結果數據/評分分布統計分析.csv')save_to_mysql(rating_counts, '評分分布統計分析')
2. 圖書價格分布分析
def price_analysis(data):# 定義價格區間bins = [0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500]labels = ['0-50', '50-100', '100-150', '150-200', '200-250', '250-300', '300-350', '350-400', '400-450', '450-500']# 使用 pd.cut 函數將價格進行分組data['price_group'] = pd.cut(data['price'], bins=bins, labels=labels, right=False)# 統計每個價格區間的圖書數量price_counts = data['price_group'].value_counts()price_counts = price_counts.reset_index()price_counts.columns = ['price_range', 'count']save_to_csv(price_counts, './結果輸出層/數據分析結果數據/圖書價格分布統計分析.csv')save_to_mysql(price_counts, '圖書價格分布統計分析')
3. 譯者翻譯的圖書數量統計分析(前15)
def translator_count_analysis(data):# 統計每個譯者的圖書數量translator_counts = data['translator'].value_counts()translator_counts = translator_counts.reset_index()translator_counts.columns = ['translator', 'count']translator_counts = translator_counts.sort_values(by='count', ascending=False)translator_counts = translator_counts.head(15)save_to_csv(translator_counts, './結果輸出層/數據分析結果數據/譯者圖書數量統計分析.csv')save_to_mysql(translator_counts, '譯者圖書數量統計分析')
4. 評價人數多的圖書分析(前15)
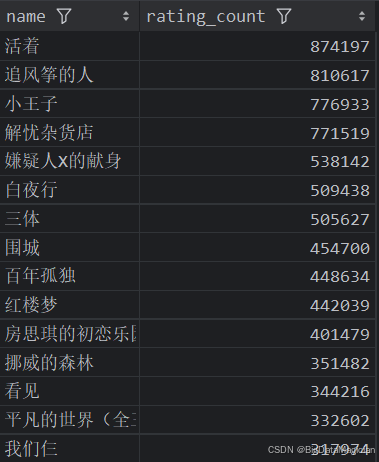
def high_rating_count_books_analysis(data):high_rating_count_books = data[['name', 'rating_count']]high_rating_count_books = high_rating_count_books.sort_values(by='rating_count', ascending=False)high_rating_count_books = high_rating_count_books.drop_duplicates(subset=['name'])high_rating_count_books = high_rating_count_books.head(15)save_to_csv(high_rating_count_books, './結果輸出層/數據分析結果數據/評價人數多的圖書分析.csv')save_to_mysql(high_rating_count_books, '評價人數多的圖書分析')
分析結果如下圖所示:
5. 評分最高的圖書分析(前15)
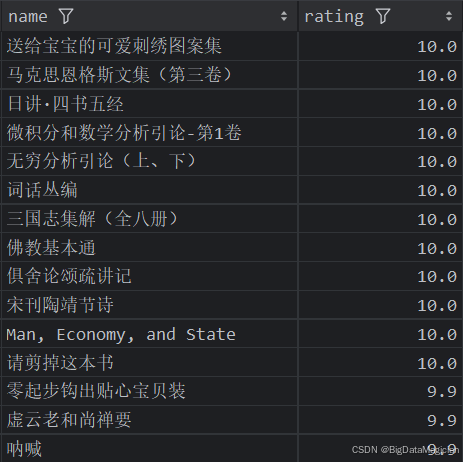
def high_rating_books_analysis(data):high_rating_books = data[['name', 'rating']]high_rating_books = high_rating_books.sort_values(by='rating', ascending=False)high_rating_books = high_rating_books.drop_duplicates(subset=['name'])high_rating_books = high_rating_books.head(15)save_to_csv(high_rating_books, './結果輸出層/數據分析結果數據/評分最高的圖書分析.csv')save_to_mysql(high_rating_books, '評分最高的圖書分析')
分析結果如下圖所示:
6. 評價人數最多且評分高的圖書分析(前15)
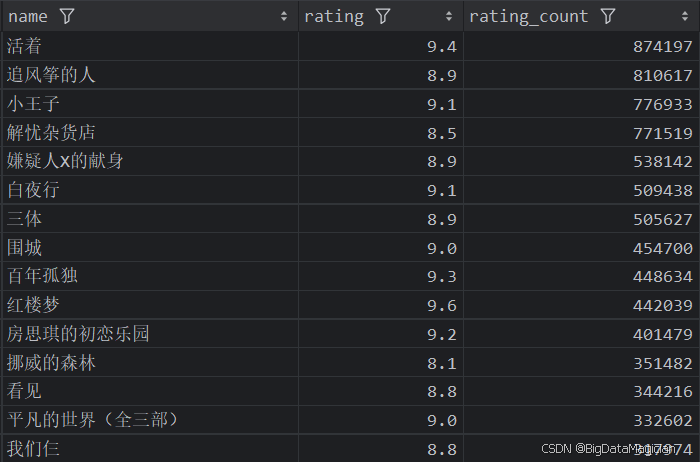
def high_rating_and_rating_count_books_analysis(data):high_rating_and_rating_count_books = data[['name', 'rating', 'rating_count']]high_rating_and_rating_count_books = high_rating_and_rating_count_books.sort_values(by=['rating_count', 'rating'], ascending=False)high_rating_and_rating_count_books = high_rating_and_rating_count_books.drop_duplicates(subset=['name'])high_rating_and_rating_count_books = high_rating_and_rating_count_books.head(15)save_to_csv(high_rating_and_rating_count_books, './結果輸出層/數據分析結果數據/評分高且評價人數最多的圖書分析.csv')save_to_mysql(high_rating_and_rating_count_books, '評分高且評價人數最多的圖書分析')
分析結果如下圖所示:
七、完整代碼
from pathlib import Pathimport pandas as pd
from matplotlib import pyplot as plt
from sqlalchemy import create_engine# 設置支持中文的字體,這里以黑體為例
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 解決負號'-'顯示為方塊的問題def load_data(csv_file_path):try:data = pd.read_csv(csv_file_path)return dataexcept FileNotFoundError:print("未找到指定的 CSV 文件,請檢查文件路徑和文件名。")except Exception as e:print(f"加載數據時出現錯誤: {e}")# 保存分析后的數據為csv文件
def save_to_csv(data, csv_file_path):# 使用 pathlib 處理文件路徑path = Path(csv_file_path)# 檢查文件所在目錄是否存在,如果不存在則創建path.parent.mkdir(parents=True, exist_ok=True)data.to_csv(csv_file_path, index=False, encoding='utf-8-sig', mode='w', header=True)print(f'清洗后的數據已保存到 {csv_file_path} 文件')# 保存分析后的數據到MySQL數據庫
def save_to_mysql(data, table_name):engine = create_engine(f'mysql+mysqlconnector://root:zxcvbq@127.0.0.1:3306/douban')data.to_sql(table_name, con=engine, index=False, if_exists='replace')print(f'清洗后的數據已保存到 {table_name} 表')# 每種分類圖書數量統計分析
def category_count_analysis(data):# 統計每個分類的圖書數量category_counts = data['category_name'].value_counts()category_counts = category_counts.reset_index()category_counts.columns = ['category_name', 'count']save_to_csv(category_counts, './結果輸出層/數據分析結果數據/分類圖書數量統計分析.csv')save_to_mysql(category_counts, '分類圖書數量統計分析')# 每種分類的平均評分統計分析
def category_rating_analysis(data):# 計算每個分類的平均評分category_ratings = data.groupby('category_name')['rating'].mean().round(1)category_ratings = category_ratings.reset_index()category_ratings.columns = ['category_name', 'avg_rating']save_to_csv(category_ratings, './結果輸出層/數據分析結果數據/每個分類的平均評分統計分析.csv')save_to_mysql(category_ratings, '每個分類的平均評分統計分析')# 每種分類的平均評價人數統計分析
def category_rating_count_analysis(data):# 計算每個分類的平均評價人數category_rating_counts = data.groupby('category_name')['rating_count'].mean().round(0)category_rating_counts = category_rating_counts.reset_index()category_rating_counts.columns = ['category_name', 'avg_rating_count']save_to_csv(category_rating_counts, './結果輸出層/數據分析結果數據/每個分類的平均評價人數統計分析.csv')save_to_mysql(category_rating_counts, '每個分類的平均評價人數統計分析')# 每種分類的平均價格統計分析
def category_price_analysis(data):# 計算每個分類的平均價格category_prices = data.groupby('category_name')['price'].mean().round(1)category_prices = category_prices.reset_index()category_prices.columns = ['category_name', 'avg_price']save_to_csv(category_prices, './結果輸出層/數據分析結果數據/每個分類的平均價格統計分析.csv')save_to_mysql(category_prices, '每個分類的平均價格統計分析')# 每種分類的圖書數量、平均評分、平均價格和平均評價人數統計分析
def category_analysis(data):# 統計每個分類的圖書數量category_counts = data['category_name'].value_counts()category_counts = category_counts.reset_index()category_counts.columns = ['category_name', 'count']# 計算每個分類的平均評分category_ratings = data.groupby('category_name')['rating'].mean().round(1)category_ratings = category_ratings.reset_index()category_ratings.columns = ['category_name', 'avg_rating']# 計算每個分類的平均評價人數category_rating_counts = data.groupby('category_name')['rating_count'].mean().round(0)category_rating_counts = category_rating_counts.reset_index()category_rating_counts.columns = ['category_name', 'avg_rating_count']# 計算每個分類的平均價格category_prices = data.groupby('category_name')['price'].mean().round(1)category_prices = category_prices.reset_index()category_prices.columns = ['category_name', 'avg_price']# 合并四個結果merged_result = pd.merge(category_counts, category_ratings, on='category_name', how='outer')merged_result = pd.merge(merged_result, category_rating_counts, on='category_name', how='outer')merged_result = pd.merge(merged_result, category_prices, on='category_name', how='outer')# 保存合并后的結果到 CSV 文件save_to_csv(merged_result, './結果輸出層/數據分析結果數據/每種分類的圖書數量和平均評分和平均評價人數和平均價格統計分析.csv')save_to_mysql(merged_result, '每種分類的圖書數量和平均評分和平均評價人數和平均價格統計分析')# 每年出版的圖書數量統計分析
def year_count_analysis(data):# 統計每年出版的圖書數量year_counts = data['publish_year'].value_counts()year_counts = year_counts.reset_index()# 按照年份升序排序year_counts = year_counts.sort_values(by='publish_year')year_counts.columns = ['publish_year', 'count']save_to_csv(year_counts, './結果輸出層/數據分析結果數據/每年出版的圖書數量統計分析.csv')save_to_mysql(year_counts, '每年出版的圖書數量統計分析')# 每年出版的圖書平均評分分析
def year_rating_analysis(data):year_ratings = data.groupby('publish_year')['rating'].mean().round(1)year_ratings = year_ratings.reset_index()year_ratings = year_ratings.sort_values(by='publish_year')year_ratings.columns = ['publish_year', 'avg_rating']save_to_csv(year_ratings, './結果輸出層/數據分析結果數據/每年出版的圖書平均評分分析.csv')save_to_mysql(year_ratings, '每年出版的圖書平均評分分析')# 每年出版圖書平均評價人數分析
def year_rating_count_analysis(data):year_rating_counts = data.groupby('publish_year')['rating_count'].mean().round(0)year_rating_counts = year_rating_counts.reset_index()year_rating_counts = year_rating_counts.sort_values(by='publish_year')year_rating_counts.columns = ['publish_year', 'avg_rating_count']save_to_csv(year_rating_counts, './結果輸出層/數據分析結果數據/每年出版圖書平均評價人數分析.csv')save_to_mysql(year_rating_counts, '每年出版圖書平均評價人數分析')# 每年出版圖書平均價格分析
def year_price_analysis(data):year_prices = data.groupby('publish_year')['price'].mean().round(1)year_prices = year_prices.reset_index()year_prices = year_prices.sort_values(by='publish_year')year_prices.columns = ['publish_year', 'avg_price']save_to_csv(year_prices, './結果輸出層/數據分析結果數據/每年出版圖書平均價格分析.csv')save_to_mysql(year_prices, '每年出版圖書平均價格分析')# 每年出版圖書數量、平均評分、平均價格和平均評價人數分析
def year_analysis(data):# 每年出版的圖書數量統計分析year_counts = data['publish_year'].value_counts()year_counts = year_counts.reset_index()year_counts = year_counts.sort_values(by='publish_year')year_counts.columns = ['publish_year', 'count']# 每年出版的圖書平均評分分析year_ratings = data.groupby('publish_year')['rating'].mean().round(1)year_ratings = year_ratings.reset_index()year_ratings = year_ratings.sort_values(by='publish_year')year_ratings.columns = ['publish_year', 'avg_rating']# 每年出版的圖書平均評價人數分析year_rating_counts = data.groupby('publish_year')['rating_count'].mean().round(0)year_rating_counts = year_rating_counts.reset_index()year_rating_counts = year_rating_counts.sort_values(by='publish_year')year_rating_counts.columns = ['publish_year', 'avg_rating_count']# 每年出版的圖書平均價格分析year_prices = data.groupby('publish_year')['price'].mean().round(1)year_prices = year_prices.reset_index()year_prices = year_prices.sort_values(by='publish_year')# 合并四個結果merged_result = pd.merge(year_counts, year_ratings, on='publish_year', how='outer')merged_result = pd.merge(merged_result, year_rating_counts, on='publish_year', how='outer')merged_result = pd.merge(merged_result, year_prices, on='publish_year', how='outer')# 保存合并后的結果到 CSV 文件save_to_csv(merged_result, './結果輸出層/數據分析結果數據/每年出版圖書數量和平均評分和平均價格和平均評價人數分析.csv')save_to_mysql(merged_result, '每年出版圖書數量和平均評分和平均價格和平均評價人數分析')# 每個作者的圖書數量統計分析
def author_count_analysis(data):# 統計每個作者的圖書數量author_counts = data['author'].value_counts()author_counts = author_counts.reset_index()author_counts.columns = ['author', 'count']save_to_csv(author_counts, './結果輸出層/數據分析結果數據/作者圖書數量統計分析.csv')save_to_mysql(author_counts, '作者圖書數量統計分析')# 每個作者的平均評分分析
def author_rating_analysis(data):# 計算每個作者的平均評分author_ratings = data.groupby('author')['rating'].mean().round(1)author_ratings = author_ratings.reset_index()author_ratings.columns = ['author', 'avg_rating']save_to_csv(author_ratings, './結果輸出層/數據分析結果數據/作者平均評分分析.csv')save_to_mysql(author_ratings, '作者平均評分分析')# 每個作者的平均評價人數分析
def author_rating_count_analysis(data):# 計算每個作者的平均評價人數author_rating_counts = data.groupby('author')['rating_count'].mean().round(0)author_rating_counts = author_rating_counts.reset_index()author_rating_counts.columns = ['author', 'avg_rating_count']save_to_csv(author_rating_counts, './結果輸出層/數據分析結果數據/作者平均評價人數分析.csv')save_to_mysql(author_rating_counts, '作者平均評價人數分析')# 每個作者的平均價格分析
def author_price_analysis(data):# 計算每個作者的平均價格author_prices = data.groupby('author')['price'].mean().round(1)author_prices = author_prices.reset_index()author_prices.columns = ['author', 'avg_price']save_to_csv(author_prices, './結果輸出層/數據分析結果數據/作者平均價格分析.csv')save_to_mysql(author_prices, '作者平均價格分析')# 每個作者的圖書數量、平均評分、平均價格和平均評價人數分析
def author_analysis(data):# 每個作者的圖書數量統計分析author_counts = data['author'].value_counts()author_counts = author_counts.reset_index()author_counts.columns = ['author', 'count']# 每個作者的平均評分分析author_ratings = data.groupby('author')['rating'].mean().round(1)author_ratings = author_ratings.reset_index()author_ratings.columns = ['author', 'avg_rating']# 每個作者的平均評價人數分析author_rating_counts = data.groupby('author')['rating_count'].mean().round(0)author_rating_counts = author_rating_counts.reset_index()author_rating_counts.columns = ['author', 'avg_rating_count']# 每個作者的平均價格分析author_prices = data.groupby('author')['price'].mean().round(1)author_prices = author_prices.reset_index()author_prices.columns = ['author', 'avg_price']# 合并四個結果merged_result = pd.merge(author_counts, author_ratings, on='author', how='outer')merged_result = pd.merge(merged_result, author_rating_counts, on='author', how='outer')merged_result = pd.merge(merged_result, author_prices, on='author', how='outer')# 保存合并后的結果到 CSV 文件save_to_csv(merged_result, './結果輸出層/數據分析結果數據/作者圖書數量和平均評分和平均價格和平均評價人數分析.csv')save_to_mysql(merged_result, '作者圖書數量和平均評分和平均價格和平均評價人數分析')# 每個出版社的圖書數量統計分析
def publish_count_analysis(data):# 統計每個出版社的圖書數量publish_counts = data['publisher'].value_counts()publish_counts = publish_counts.reset_index()publish_counts.columns = ['publisher', 'count']save_to_csv(publish_counts, './結果輸出層/數據分析結果數據/出版社圖書數量統計分析.csv')save_to_mysql(publish_counts, '出版社圖書數量統計分析')# 每個出版社的平均評分分析
def publish_rating_analysis(data):# 計算每個出版社的平均評分publish_ratings = data.groupby('publisher')['rating'].mean().round(1)publish_ratings = publish_ratings.reset_index()publish_ratings.columns = ['publisher', 'avg_rating']save_to_csv(publish_ratings, './結果輸出層/數據分析結果數據/出版社平均評分分析.csv')save_to_mysql(publish_ratings, '出版社平均評分分析')# 每個出版社的平均評價人數分析
def publish_rating_count_analysis(data):# 計算每個出版社的平均評價人數publish_rating_counts = data.groupby('publisher')['rating_count'].mean().round(0)publish_rating_counts = publish_rating_counts.reset_index()publish_rating_counts.columns = ['publisher', 'avg_rating_count']save_to_csv(publish_rating_counts, './結果輸出層/數據分析結果數據/出版社平均評價人數分析.csv')save_to_mysql(publish_rating_counts, '出版社平均評價人數分析')# 每個出版社的平均價格分析
def publish_price_analysis(data):# 計算每個出版社的平均價格publish_prices = data.groupby('publisher')['price'].mean().round(1)publish_prices = publish_prices.reset_index()publish_prices.columns = ['publisher', 'avg_price']save_to_csv(publish_prices, './結果輸出層/數據分析結果數據/出版社平均價格分析.csv')save_to_mysql(publish_prices, '出版社平均價格分析')# 每個出版社的圖書數量、平均評分、平均價格和平均評價人數分析
def publish_analysis(data):# 每個出版社的圖書數量統計分析publish_counts = data['publisher'].value_counts()publish_counts = publish_counts.reset_index()publish_counts.columns = ['publisher', 'count']# 每個出版社的平均評分分析publish_ratings = data.groupby('publisher')['rating'].mean().round(1)publish_ratings = publish_ratings.reset_index()publish_ratings.columns = ['publisher', 'avg_rating']# 每個出版社的平均評價人數分析publish_rating_counts = data.groupby('publisher')['rating_count'].mean().round(0)publish_rating_counts = publish_rating_counts.reset_index()publish_rating_counts.columns = ['publisher', 'avg_rating_count']# 每個出版社的平均價格分析publish_prices = data.groupby('publisher')['price'].mean().round(1)publish_prices = publish_prices.reset_index()publish_prices.columns = ['publisher', 'avg_price']# 合并四個結果merged_result = pd.merge(publish_counts, publish_ratings, on='publisher', how='outer')merged_result = pd.merge(merged_result, publish_rating_counts, on='publisher', how='outer')merged_result = pd.merge(merged_result, publish_prices, on='publisher', how='outer')# 保存合并后的結果到 CSV 文件save_to_csv(merged_result, './結果輸出層/數據分析結果數據/出版社圖書數量和平均評分和平均價格和平均評價人數分析.csv')save_to_mysql(merged_result, '出版社圖書數量和平均評分和平均價格和平均評價人數分析')# 評分分布分析
def rating_analysis(data):# 定義評分區間bins = [0, 2, 4, 6, 8, 10]labels = ['0-2', '2-4', '4-6', '6-8', '8-10']# 使用 pd.cut 函數將評分進行分組data['rating_group'] = pd.cut(data['rating'], bins=bins, labels=labels, right=False)# 統計每個評分區間的圖書數量rating_counts = data['rating_group'].value_counts()rating_counts = rating_counts.reset_index()rating_counts.columns = ['rating_range', 'count']save_to_csv(rating_counts, './結果輸出層/數據分析結果數據/評分分布統計分析.csv')save_to_mysql(rating_counts, '評分分布統計分析')# 圖書價格分布分析
def price_analysis(data):# 定義價格區間bins = [0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500]labels = ['0-50', '50-100', '100-150', '150-200', '200-250', '250-300', '300-350', '350-400', '400-450', '450-500']# 使用 pd.cut 函數將價格進行分組data['price_group'] = pd.cut(data['price'], bins=bins, labels=labels, right=False)# 統計每個價格區間的圖書數量price_counts = data['price_group'].value_counts()price_counts = price_counts.reset_index()price_counts.columns = ['price_range', 'count']save_to_csv(price_counts, './結果輸出層/數據分析結果數據/圖書價格分布統計分析.csv')save_to_mysql(price_counts, '圖書價格分布統計分析')# 譯者翻譯的圖書數量統計分析(前15)
def translator_count_analysis(data):# 統計每個譯者的圖書數量translator_counts = data['translator'].value_counts()translator_counts = translator_counts.reset_index()translator_counts.columns = ['translator', 'count']translator_counts = translator_counts.sort_values(by='count', ascending=False)translator_counts = translator_counts.head(15)save_to_csv(translator_counts, './結果輸出層/數據分析結果數據/譯者圖書數量統計分析.csv')save_to_mysql(translator_counts, '譯者圖書數量統計分析')# 價格、評分、評分人數和出版年份相關性分析
def correlation_analysis(data):# 計算價格、評分、評分人數和出版年份之間的相關性correlation = data[['price', 'rating', 'rating_count', 'publish_year']].corr()correlation = correlation.reset_index()# 保存統計結果到 CSV 文件save_to_csv(correlation, './結果輸出層/數據分析結果數據/價格、評分、評分人數和出版年份相關性分析.csv')save_to_mysql(correlation, '價格、評分、評分人數和出版年份相關性分析')# 評價人數多的圖書分析(前15)
def high_rating_count_books_analysis(data):high_rating_count_books = data[['name', 'rating_count']]high_rating_count_books = high_rating_count_books.sort_values(by='rating_count', ascending=False)high_rating_count_books = high_rating_count_books.drop_duplicates(subset=['name'])high_rating_count_books = high_rating_count_books.head(15)save_to_csv(high_rating_count_books, './結果輸出層/數據分析結果數據/評價人數多的圖書分析.csv')save_to_mysql(high_rating_count_books, '評價人數多的圖書分析')# 評分最高的圖書分析(前15)
def high_rating_books_analysis(data):high_rating_books = data[['name', 'rating']]high_rating_books = high_rating_books.sort_values(by='rating', ascending=False)high_rating_books = high_rating_books.drop_duplicates(subset=['name'])high_rating_books = high_rating_books.head(15)save_to_csv(high_rating_books, './結果輸出層/數據分析結果數據/評分最高的圖書分析.csv')save_to_mysql(high_rating_books, '評分最高的圖書分析')# 評分高且評價人數最多的圖書(前15)
def high_rating_and_rating_count_books_analysis(data):high_rating_and_rating_count_books = data[['name', 'rating', 'rating_count']]high_rating_and_rating_count_books = high_rating_and_rating_count_books.sort_values(by=['rating_count', 'rating'], ascending=False)high_rating_and_rating_count_books = high_rating_and_rating_count_books.drop_duplicates(subset=['name'])high_rating_and_rating_count_books = high_rating_and_rating_count_books.head(15)save_to_csv(high_rating_and_rating_count_books, './結果輸出層/數據分析結果數據/評分高且評價人數最多的圖書分析.csv')save_to_mysql(high_rating_and_rating_count_books, '評分高且評價人數最多的圖書分析')if __name__ == '__main__':# 加載數據data = load_data('./中間處理層/清洗后的豆瓣圖書數據集.csv')category_count_analysis(data)category_rating_analysis(data)category_rating_count_analysis(data)category_price_analysis(data)category_analysis(data)year_count_analysis(data)year_rating_analysis(data)year_rating_count_analysis(data)year_price_analysis(data)year_analysis(data)author_count_analysis(data)author_rating_analysis(data)author_rating_count_analysis(data)author_price_analysis(data)author_analysis(data)publish_count_analysis(data)publish_rating_analysis(data)publish_rating_count_analysis(data)publish_price_analysis(data)publish_analysis(data)rating_analysis(data)price_analysis(data)translator_count_analysis(data)correlation_analysis(data)high_rating_count_books_analysis(data)high_rating_books_analysis(data)high_rating_and_rating_count_books_analysis(data)
)

)

)


CV中的應用)


)








)