目錄
協議
應用層
xml
json
protobuffer
傳輸層
端口號(Port)
UDP 協議
UDP 協議端格式
完!
協議
網絡通信中,協議是一個非常重要的概念。我們前面在網絡原理中,就已經介紹了,為了統一各方網絡,大佬們提出了協議,因為協議太多,對其進行了分層。
應用層
應用層,對應著應用程序,是跟我們程序員打交道最多的一層。調用系統提供的網絡 API 寫出的代碼,都是屬于應用層的。
應用層這里當然也有很多現成的協議,但是更多的,還是需要我們程序員根據實際的業務場景,自定義協議(網絡傳輸的數據要怎么使用,當然也要考慮到數據是什么樣的格式,里面包含那些內容~)
協議,其實就是一種與欸的那個,雖然存在很多的現有的協議(大佬們已經搞好了的),除此之外,我們程序員也可以自己來約定協議。
自定義協議,一般要約定好兩方面的內容:
1. 服務器和客戶端之間要交互那些信息
2. 數據是具體格式
(客戶端按照上述約定發送請求,服務器按照上述約定來解析請求)
(服務器按照上述約定構造響應,客戶端按照上述約定來解析響應)
舉個栗子:
住酒店:
打開出行相關的 APP,顯示出主頁,主頁里面就很顯示出一些酒店的列表。
而且這些酒店都是在我們附近的(打開軟件的時候,需要把我們的位置,告訴服務器)
顯示的酒店列表中,也會包含一些信息 -- 酒店的名稱 細節圖片 相關評分 相關簡介...
上述的這些信息,要按照什么樣的格式來進行組織呢???是有一些固定的套路的~~~
確定如何組織數據格式這件事情,往往是需要客戶端的程序員和服務器的程序員,這兩伙人坐在一起,一起把這個事情給確定下來~~~(這里的格式怎么樣約定都可以,只要是兩伙程序員達成共識即可~~~)
一個簡單粗暴但五臟俱全的栗子~~~
1. 請求,約定使用行文本的格式來進行表示:
userId,position\n? ? ? ? ? ? ? ?(一個請求以 \n 為結尾,多個字段之間只用 , 來進行分割)
比如(1003,[經緯度]\n)
2. 響應,也是使用行文本來表示,一個響應中可能會包含多個酒店,每個酒店占一行,每個酒店都要返回 id,名稱,圖片,評分,簡介
比如( 2001,A 酒店,[logo圖片地址],4.9,五星級酒店\n
? ? ? ? ? ? 2002,B酒店,[logo圖片地址],4.5,干凈衛生的民宿\n
? ? ? ? ? ?\n)
(若干行的最后,使用空行來作為所有數據的結束標志,上面的這一系列內容就是同一個響應中的數據了)
補充:
客戶端和服務器之間往往要進行交互的是”結構化數據“(交互的數據是一個結構體 / 類,其中會包含很多個屬性)網絡傳輸的數據其實是”字符串“”二進制 bit 流“。
協議約定的過程,就是把結構化數據轉換成字符串 / 二進制 bit 流的過程。
把結構化數據,轉成字符串 / 二進制 bit 流,這個操作,稱為”序列化“。
把字符串 / 二進制 bit 流還原成結構化數據,這個操作,稱為”反序列化“。
序列化 / 反序列化具體要組織成什么樣的格式,這里要包含那些信息,預定這兩件事情的過程,就是自定義協議的過程。
為了讓程序員更方便的去約定這里的協議格式,業界給出了幾個比較好用的方案:
xml
大概的模樣如下:

<> 稱為標簽(tag),一般都是成對出現的,分別為開始標簽和結束標簽。開始標簽和結束標簽中間夾著的就是標簽的值,標簽是可以嵌套的。(標簽的名字 / 標簽的值 / 標簽的嵌套關系,都是程序員自定義的~)
xml 約定
優點:使得數據內容的可讀性和拓展性都提升了很多,標簽的名字能夠對數據起到說明作用,后續要再增加一個屬性,新添加一個標簽即可,對已有代碼影響不大~
缺點:冗余信息比較多,標簽的描述性信息,占據的空間反而比數據本身還要多了~
json
大概的模樣如下:

采用的是鍵值對結構:
鍵和值之間用:進行分割,鍵值對之間用 , 進行分割。
把若干個鍵值對使用 {? }? 括起來,此時就形成了一個 json 對象,還可以把多個 json 對象放到一起,使用 , 分隔開,并且整體使用 [ ] 括起來,就形成了一個 json 數組。
json 約定:
優點:可讀性,擴展性都很好,而且對比 xml 來說,占用的空間更少了。
缺點:雖然 json 的確比 xml 占用的空間更少了,節省了寬帶,但很明顯,這里的寬帶仍然還是有浪費的部分的,尤其是這種數組格式的 json,這種情況下往往傳輸的數據字段都是相同的,很多 key 關鍵字都是被重復傳輸的(id,name 等等...)
protobuffer
這種約定是更加節省寬帶的方式,也是效率最高的方式。
protobuffer 只是在開發階段(代碼)定義出這里都有那些資源,描述每個字段的定義。程序真正運行起來的時候,實際傳輸的數據是不包含這些描述信息的。這樣的數據都是按照二進制的方式來進行組織的。
這種方式雖然程序運行的效率會非常高,但其實并不太有利于程序員閱讀~~~
雖然 protobuffer 運行效率更高,但是使用并沒有比 json 更加廣泛,只有一些對于性能要求非常搞的場景,才會使用 protobuffer。
應用層也很多線程的協議,HTTP 這種 后面詳細介紹~
傳輸層
傳輸層中,雖然是系統內核已經實現好了的,但我們仍然需要重點進行關注,我們之前在網絡編程中,使用的 socket API 就是傳輸層提供的
端口號(Port)
端口號,是一個 2 字節的整數。標識了一個主機上進行通信的不同的應用程序。
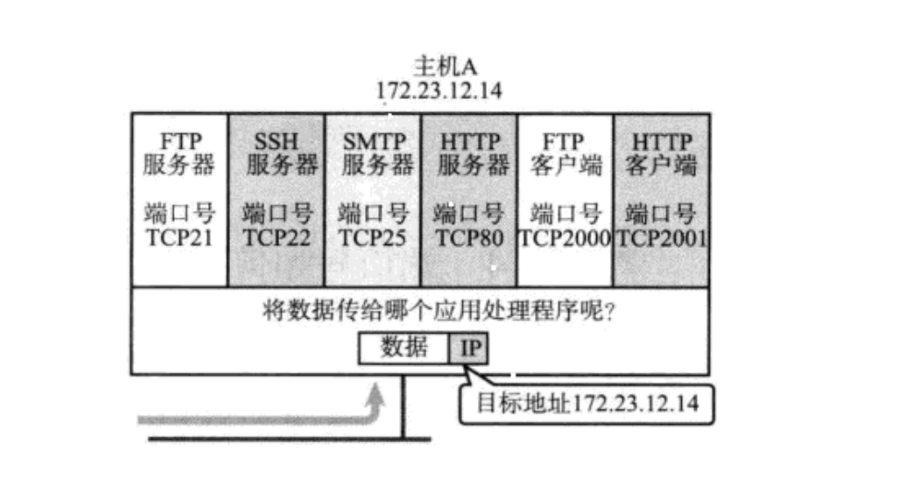
在 TCP/ IP 協議中,用源 IP,源端口號,目的 IP,目的端口號,協議號,這樣一個五元組來標識一個通信。
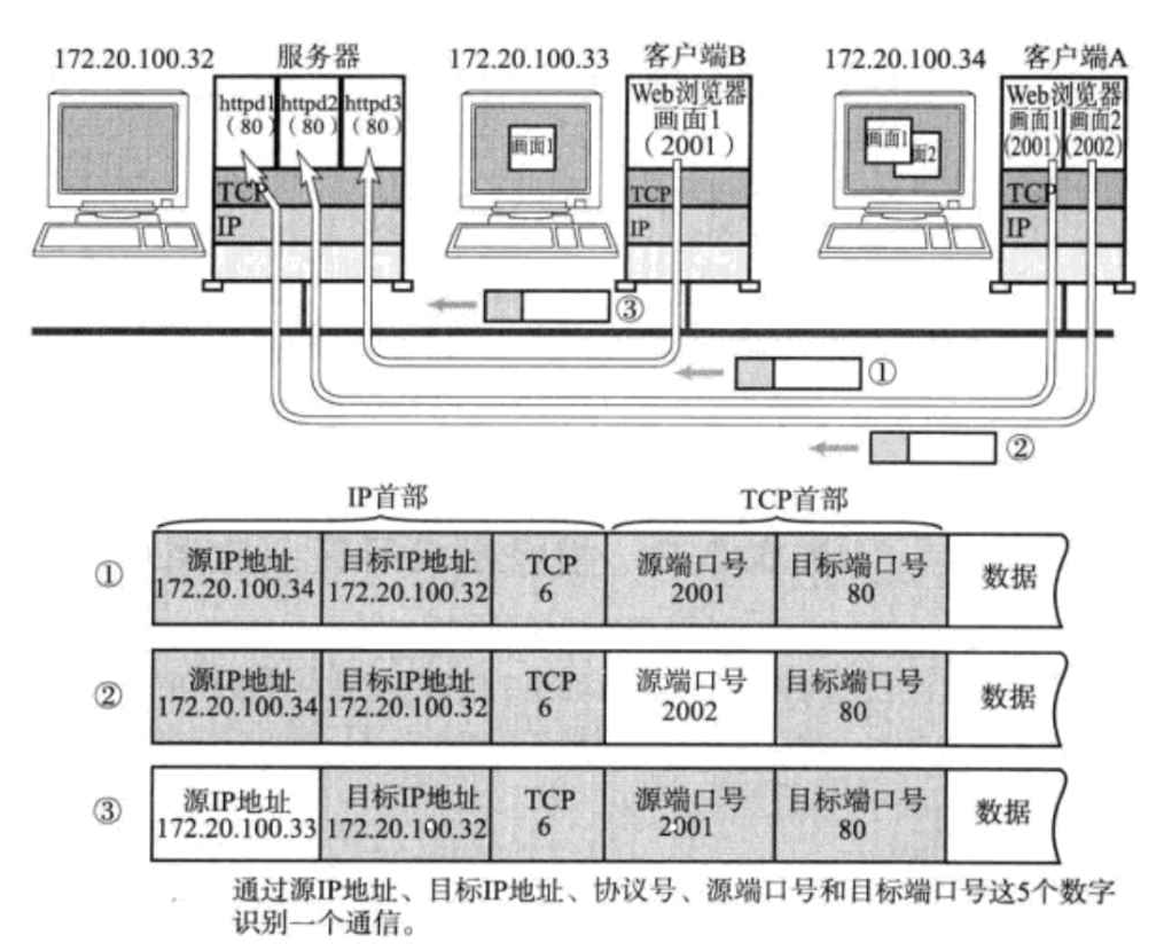
端口號范圍劃分:
0 - 1023:是一些知名端口號,HTTP,FTP,SSH 等這些廣為使用的應用層協議,他們的端口號的固定的。
1024 - 65535:操作系統動態分配的端口號。我們前面在網絡編程中,客戶端程序的端口號,就是由操作系統在這個范圍內分配的。
一些有名的端口號:
SSH 服務器:22 端口
FTP 服務器:21 端口
telnet 服務器:23 端口
HTTP 服務器:80 端口
HTTPS 服務器:443 端口
我們寫程序使用端口號的時候,需要避開這些知名端口號~
UDP 協議
前面我們已經提過,UDP 協議的四個特點:無連接,不可靠傳輸,面向數據報,全雙工。
研究一個協議,我們主要是研究報文格式,基于報文格式,來了解這個協議的各個特性。
UDP 數據報 = 報頭(重點) +? 載荷(應用層數據包)
UDP 協議端格式
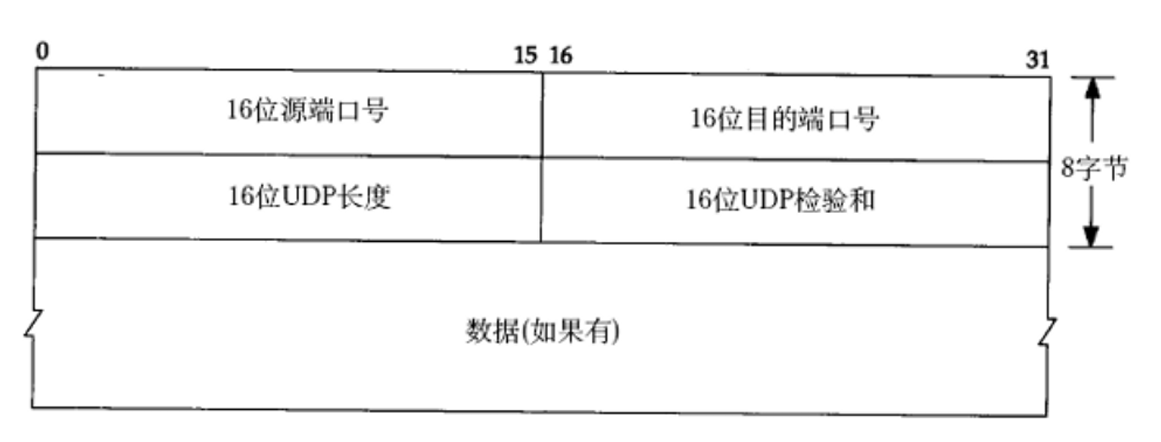
上面的這個圖,并不準確,是為了我們書籍教材排版方便做出的妥協,其實應該是下面這樣的:
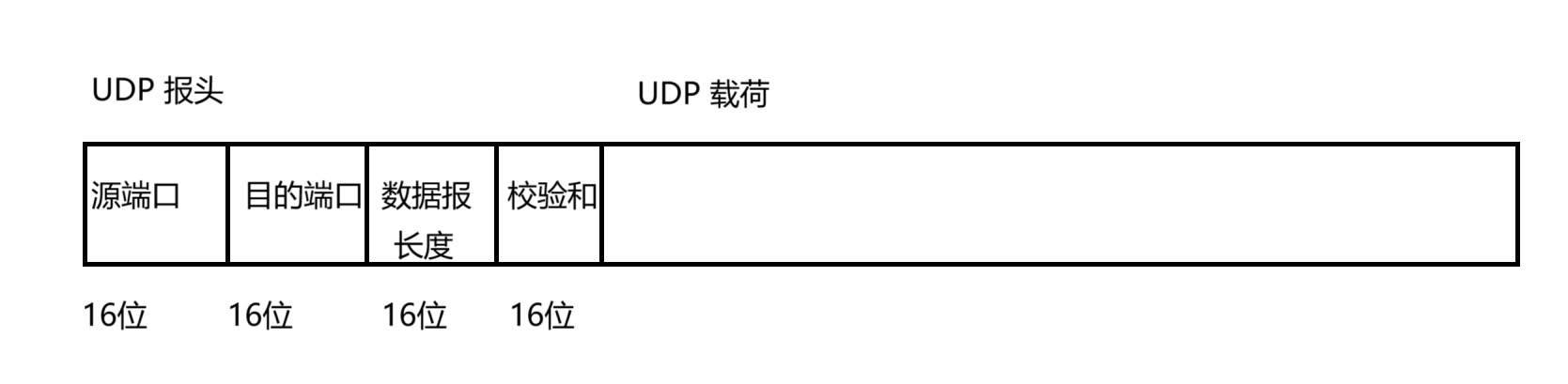
UDP 報頭中,一共有 4 個字段,每個字段 2 個字節(一共 8 個字節)
由于 UDP 協議中使用 2 個字節(16 位)來標識端口號,端口號的取值范圍就是 0 - 655335(即這里最大值就是 64KB(2^10 = 1 KB),即,一個 UDP 數據報最大的長度,就是 64 KB,沒辦法更長了),一旦整個數據報的長度超出 64 KB,此時就可能導致數據出現階段(數據后面的部分就沒有了)
(總的 UDP 數據報最大長度是 64KB,則載荷部分實際能承擔的最大長度,應該是 64KB - 8(減去報頭的長度))
為了解決數據被截斷的問題,有兩個方案。
方案一:在應用層,把數據報進行拆分,之前一個數據報表示 N 個頁面,拆分成每一個頁面占用一個 UDP 數據報,甚至可以進一步的拆分成,一個頁面對應多個 UDP 數據報。(開發和測試的成本都很大~~)
方案二:使用 TCP 代替 UDP,TCP 沒有上述的長度限制~~
那為什么,不進行擴展呢???將 UDP 數據報,擴展成 4 個字節的長度呢???
技術上很容易實現,但要改,就要所有的系統一起改,如果一方改了,另一方不該,相互之間就無法進行通信了~~~大家都僵持住了...
校驗和:驗證數據在傳輸過程中是否正確~~~
前提是:數據在網絡傳輸的過程中,是可能出錯的!
網絡數據傳輸:本質上其實是光信號 / 電信號 / 電磁波進行傳輸
上述信號都是很可能收到干擾的。
比如,使用高低電平來表示 0 1,外界如果加上一個磁場,就有可能把高電平變為低電平,低電平變為高電平,此時, 0 -> 1,1 -> 0 出現了比特翻轉。現代的傳輸體系,其實有一系列的保護機制,來減少外界的干擾。
校驗和的作用就是用來識別出當前的數據是否在傳輸過程中出現錯誤。
注意:網絡中的校驗和,并非是簡單的按照數據的長度 / 數量來作為標準進行校驗的,一定是數據的內容會參與到其中。
嚴格的來說,校驗和只能用來“證偽”,即,只能是證明數據是出錯了,沒辦法確保這個數據 100% 是正確的。但是實踐中可以近似的認為檢驗和一致,數據就一致了。
UDP 中,校驗和是使用比較簡單的方法 - CRC 算法來完成校驗的(循環冗余校驗)
比如,要產生一個兩字節的校驗和:

加的過程中,產生的數據可能會比較大,超出了 short 兩個字節的范圍,溢出了,其實也無妨,這里不用管。
UDP 數據報發送方,在發送數據之前,先計算一邊 CRC,把算好的 CRC 值放到 UDP 數據報中。(設這個 CRC 值為 value1)
接下來,這個數據報會通過網絡傳輸到達接收端,接收端收到這個數據之后,也會按照同樣的算法,再算一次 CRC 的值,得到的結果是 value2。比較自己計算的 value2 和收到的 value1 是否一致。如果是一致的,就說明數據大概率是 ok 的。如果不一致,則傳輸過程中一定出現了錯誤。
上述 CRC 算法,為什么說?value1 和 value2 如果是一致的,數據大概率是 ok 的呢???如果只有一個 bit 位發生反轉,則 CRC 100% 能夠發現錯誤。但如果恰好有兩個 / 多個 bit 位發生反轉,有可能恰好校驗和仍然和之前的一樣~~~(這種情況比較低,可以忽略不計,但如果希望這里有更高的檢查精度,就需要使用其他更為嚴格的校驗和算法了)
md5 算法,md5 算法的背后,是有一系列的數學公式來進行計算的,此處不討論數學公式,來重點認識一下特點:
1. 定長:無論原始數據有多長,算出來的 md5 的最終值都是一個固定長度(md5 有 16 位版本,也有 32 版本,也有 64 位版本)
2. 分散:計算 md5 的過程中,原始數據,只要變化一點點,其算出來的 md5 值就會發生很大的變化差異。(這樣的特性,使得 md5 也可以作為一個字符的 hash 算法)
3. 不可逆:給一個源字符串,計算 md5 值,過程非常簡單(比 CRC 復雜一些,但整體比較簡單)但是如果給一個算好的 md5 值,還原為原始的字符串,理論上無法完成~
原始的字符串 ==》 md5 這個過程,會有很多信息量損失了,無法直接還原~
(一些在線解密 md5 的網站,本質上是通過“打表”的方式完成 --> 服務器在不停的計算各種字符串的 md5 值,然后存儲下來,我們輸入 md5 值,他就直接去數據庫里面查詢 == 》 只能破解出一些常見的一般的字符串的 md5值~)

)

)


CV中的應用)


)








)
