文章目錄
- 導言
- 1、論文簡介
- 2、論文主要方法
- 3、論文針對的問題
- 4、論文創新點
- 總結
導言
本論文介紹了一個新興的多模態模型——LLaVA(Large Language and Vision Assistant),旨在通過指令調優提升大型語言模型(LLM)在視覺和語言理解任務中的能力。近年來,隨著對語言增強基礎視覺模型的興趣不斷增長,研究者們嘗試將語言作為一個普遍接口,將多種任務指令直接用語言表達,從而使模型能更靈活地應對不同任務。LLaVA首次利用GPT-4生成的多模態指令數據,為視覺-語言任務提供了一種新穎的訓練方案。研究表明,LLaVA在面對未見過的圖像和指令時,具備較強的表現力,并在一些基準數據集中展示了超越現有模型的能力。此外,作者還構建了評估基準,以支持未來的視覺指令跟隨研究。這項開創性的工作不僅推動了多模態智能體的研究進展,也為開發更高效的視覺-語言模型提供了寶貴的資源和靈感。
1、論文簡介
論文題目:
Visual Instruction Tuning
研究領域:
Multimodal、Computer Vision and Pattern Recognition
作者單位:
University of Wisconsin–Madison、Microsoft Research、Columbia University
論文鏈接:
https://arxiv.org/pdf/2304.08485.pdf
論文來源:
NIPS2023
2、論文主要方法
本文的主要方法可以概括為以下5個部分:
-
多模態指令生成:研究團隊首先利用語言模型(GPT-4)生成大量的多模態語言-圖像指令數據。這一過程是通過將圖像與相應的文本描述和指令進行關聯,實現數據的轉換和格式化。

-
模型架構設計:LLaVA模型的架構將視覺編碼器(如CLIP)與語言解碼器(如Vicuna)相結合,形成一個端到端的多模態模型。該模型旨在有效利用預訓練的視覺和語言模型,提高其在視覺-語言任務中的表現。
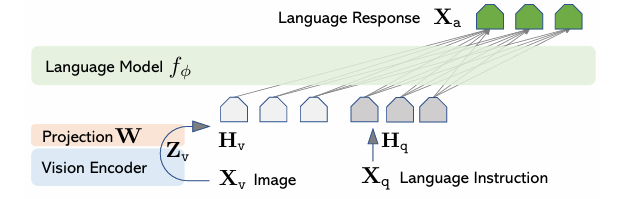
-
數據訓練與調優:通過在生成的多模態指令數據上進行指令調優,LLaVA模型得以在不同的視覺和語言理解任務中進行訓練和優化。這一過程中,作者特別關注模型的指令跟隨能力,以提升其對人類指令的適應性。

-
評估基準構建:為了確保模型的有效性,研究者們構建了LLaVA-Bench評估基準,包括多樣化和挑戰性的應用導向任務,以測試模型在各種復雜場景中的表現。

-
開源資源共享:本研究還將生成的多模態指令數據、模型代碼和檢查點公開,以促進社區的進一步研究和應用開發。
3、論文針對的問題
- 多模態指令跟隨數據的缺乏
在視覺-語言任務中,現有的指令跟隨數據通常較為稀缺,構建高質量的多模態指令數據成本高且時間消耗大。因此,如何有效生成和利用這種數據是一個關鍵挑戰。
- 端到端多模態模型的開發
現有的多模態模型通常是為特定任務而設計,并未充分利用大型語言模型(LLM)在處理指令方面的優勢。本文探索了怎樣將LLM與視覺模型結合起來,創建一個通用的、可靈活應對多種指令的多模態助手。
- 視覺-語言理解的能力提升
隨著指令跟隨能力的提升,模型在面對不同的視覺內容時如何更好地理解并執行用戶指令,成為了重要的研究目標。
- 評估標準和基準
現有的多模態模型在評估標準方面缺乏統一性和多樣性。因此,建立有效的評估基準以測量模型在復雜指令跟隨任務中的表現也是本文關注的一個問題。
4、論文創新點
-
視覺指令調優方法的提出:首次將指令調優技術引入語言-圖像的多模態領域,通過生成語言-圖像指令數據,提升模型的多任務理解和執行能力。
-
開發LLaVA模型:推出了LLaVA(Large Language and Vision Assistant),這是一種端到端的多模態模型,結合了先進的視覺編碼器和語言解碼器,能夠靈活應對各種視覺-語言任務。
-
構建全面的評估基準:創建了LLaVA-Bench評估基準,涵蓋多樣化和具有挑戰性的任務集合,為模型性能的評估提供了有效的框架,促進了未來的研究和應用。
總結
本文在多模態指令跟隨領域做出了重要的貢獻,通過引入視覺指令調優的概念和技術,成功地開發出LLaVA這一端到端的多模態助手模型。LLaVA不僅展示了在視覺和語言理解任務中的強大能力,還通過生成高質量的指令數據,為模型訓練打下了堅實的基礎。建立的LLaVA-Bench評估基準進一步推動了模型性能的系統性評估,為未來的研究提供了有力支持。我們期待這些創新能夠激發更多研究者的興趣,拓展多模態模型的應用和發展,最終實現更為智能和人性化的互動系統。
Capture CIS 原理圖繪制(下))


商品詳情 API 接口概述及 JSON 數據返回參考)










(純命令))




