最近開始面試了,410面試了一家公司 針對自己薄弱的面試題庫,深入了解下,也應付下面試。在這里先祝愿大家在現有公司好好沉淀,定位好自己的目標,在自己的領域上發光發熱,在自己想要的領域上(技術管理、項目管理、業務管理等)越走越遠!希望各位面試都能穩過,待遇都是杠杠的!因為內心還是很慌,所以先整理所有高頻的面試題出來,包含一些業務場景及java相關的所有面試。
JAVA基礎
1.java的各種鎖
樂觀鎖、悲觀鎖、公平鎖,非公平鎖、排他鎖、共享鎖、重入鎖、偏向鎖、重量級鎖
- 基礎鎖概念:
- 樂觀鎖:
- 假設并發沖突很少發生
- 實現方式:版本號機制、CAS操作
- 典型實現:Atomic類、StampedLock的樂觀讀
- 使用場景:讀多寫少,沖突概率低
- 悲觀鎖:
- 假設并發沖突經常發生
- 實現方式:synchronized、ReentrantLock
- 典型特點:先加鎖再訪問
- 使用場景:寫多讀少,重讀概率高
- 公平鎖:
- 按請求順序分配鎖
- 實現:ReentrantLock(true)
- 優點: 避免線程饑餓
- 缺點:吞吐量較低
- 非公平鎖:
- 允許線程“插隊”獲取鎖
- 實現:synchronized、ReentrantLock(false)
- 優點:吞吐量高
- 缺點:可能造成線程饑餓
- 排他鎖(獨占鎖)
- 同一個時刻只允許有一個線程持有
- 實現:synchronized、ReentrantLock、ReentrantReadWriteLock.WriteLock
- 共享鎖:
- 允許多個線程共同持有
- 實現:ReentrantReadWriteLock.ReadLock、Semaphore
- 樂觀鎖:
- 高級鎖特征
- 重入鎖(Reentrant Lock)
- 線程可以重復獲取已持有的鎖
- 實現:synchronized、ReentrantLock
- 鎖技術:每次重入計數+1,完全釋放需解鎖相同次數
- 鎖膨脹過程(JVM優化)
- 無鎖狀態:初始狀態
- 偏向鎖:優化單線程重復訪問
- 輕量級鎖:多線程輕度競爭時自旋等待
- 重量級鎖:競爭激烈時轉為OS互斥量
- 自旋鎖(Spin Lock)
- 線程不立即阻塞,而是循環嘗試獲取鎖
- 減少線程上下文切換開銷
- 使用場景:鎖持有時間短的場景
- 重入鎖(Reentrant Lock)
- 特殊用途鎖:
- 分段鎖(segment Lock)
- 將數據分段,每段獨立加鎖
- 典型實現:ConcurrentHashMap(JDK7版本)
- 提高并發度,減少鎖競爭
- 郵筒鎖(mailbox Lock)
- 用于線程間通信的同步機制
- 類似生產者-消費者模式中的交換區
- 條件鎖(condition Lock)
- 基于條件的等待/通知機制
- 實現:condition 接口
- 比Object.wait()/notify更靈活
- 分布式鎖:
- 跨JVM進程的鎖機制
- 常見實現:redis、zookeeper
- 典型方案:RedLock算法
- 分段鎖(segment Lock)
- JUV包中的并發工具
- 信號量(semaphore)
- 控制同時訪問特定資源的線程數量
- 可做流量控制
- 倒計時門閂(countDownLath)
- 等待多個線程完成后再繼續
- 循環柵欄(cyclicBarrier)
- 讓一組線程互相等待到達屏障點
- 相位器(Phaser)
- 更靈活的多階段同步屏障
- 信號量(semaphore)
- 其他重要概念
- 鎖消除(Lock Elimination)
- JVM在即時編譯時消除不必要的鎖
- 基于逃逸分析判斷對象不會逃逸出當前線程
- 鎖粗化(Lock coarsening)
- 將多個鎖的鎖操作合并成一個更大范圍的鎖
- 減少頻繁加鎖解鎖的開銷
- 死鎖(Dead Lock)
- 多線程互相等待對方釋放鎖
- 四個必要條件:互斥條件、請求與保持、不可剝奪、循環等待
- 活鎖(live lock)
- 線程不斷改變但無法繼續執行
- 類似“謙讓過度”的情況
- 鎖饑餓(Lock starvation)
- 某些線程長期無法獲取資源
- 常見于不合理的鎖分配策略
- 鎖消除(Lock Elimination)
- 鎖的選擇建議:
- 優先考慮內置鎖:簡單的synchronized
- 需要靈活時:選擇ReentrantLock或者ReentrantReadWriteLock
- 讀多寫少場景:考慮stampedLock的樂觀讀
- 高度并發計數:使用Atomic類
- 資源池控制:使用semaphore
- 線程協調:根據場景選擇CountDownLatch/CyclicBarrier/Phaser
Q:分布式鎖的實現邏輯?
A:分布式鎖是解決分布式系統中資源互斥訪問的關鍵技術.
- 分布式鎖核心特性要求:
- 互斥性:同一時刻只有一個客戶端能持有鎖
- 防死鎖:持有鎖的客戶端崩潰后鎖能自動釋放
- 容錯性:部分節點宕機不影響鎖服務的可用性
- 可重入:同一客戶端多次獲取同一把鎖
- 高性能:獲取/釋放的操作要高效
- 主流實現方案:
- 基于數據庫實現:
- 實現流程:
- 創建數據庫表專門用來做分布式鎖,每次分配一個鎖就在數據庫插入一條數據,釋放則刪除
- 特點:
- 簡單易實現,性能較差(增加了IO開銷)
- 需要處理死鎖和超時問題
- 可考慮樂觀鎖版本號機制優化
- 實現流程:
- 基于redis實現
- 實現流程:
- setnx方案:通過redis的setnx獲取鎖,當返回成功時處理業務邏輯,其底層通過LUA腳本保證原子性
- RedLock算法(Redis官方推薦):嘗試獲取所有節點的鎖,并獲取耗時檢查
- 特點:
- 性能優異
- 需要處理鎖續期問題(看門狗機制-只要客戶端還活著即jvm進程未崩潰,就主動續約)
- RedLock需要至少5個Redis主節點
- 網絡分區可能出現腦裂問題
- 實現流程:
- 基于zookeeper實現
- 實現流程:
- 創建臨時有序節點
- 獲取所有子節點
- 判斷是否最小節點,是則獲取鎖成功,否則監聽前一個節點阻塞等待
- 特點:
- 可靠性高(cp系統)
- 性能低于Redis方案
- 天然解決鎖釋放問題(臨時節點)
- 實現相對復雜
- 實現流程:
- 基于Etcd的實現
- 實現流程:
- 獲取鎖(租約機制)
- 保持心跳持續鎖
- 釋放鎖
- 特點:
- 基于Raft協議強一致
- 支持租約自動過期
- 比zk更易實現
- 實現流程:
- 關鍵性問題解決方案:
- 鎖續期問題:
- redis方案:啟動后臺線程定期延長鎖過期時間(Redisson的watchdog機制)
- zookeeper方案:會話心跳自動維持
- 鎖誤釋放問題
- 每個鎖綁定唯一客戶端標識(UUID)
- 釋放時校驗標識(Lua腳本保證原子性)
- 鎖等待問題:
- 實現公平鎖(zk順序節點)
- 設置合理的等待超時時間
- 集群故障處理
- redis:主從切換可能導致鎖丟失(RedLock可緩解)
- zk:半數以上節點存活即可工作
- 鎖續期問題:
- 基于數據庫實現:
各方案對比
| 方案 | 一致性 | 性能 | 實現復雜度 | 適用場景 |
|---|---|---|---|---|
| 數據庫 | 強 | 低 | 簡單 | 低頻簡單場景 |
| Redis | 弱 | 高 | 中等 | 高頻、允許偶爾失效 |
| RedLock | 較強 | 中 | 復雜 | 高可靠性要求 |
| Zookeeper | 強 | 中 | 復雜 | CP系統、分布式協調 |
| Etcd | 強 | 中高 | 中等 | Kubernetes環境、CP系統 |
- 最佳實現:
- 始終設置合理的鎖超時時間
- 實現鎖的可重入人邏輯(如計數機制)
- 添加鎖獲取失敗的重試策略(帶退避算法)
- 關鍵操作記錄審計日志
- 生產環境建議使用成熟框架
- java:redisson、curator
- go:etcd/clientv3
- python:python-redis-lock
Q:redlock如何保障redis主從切換時鎖丟失問題?
問題描述:普通的redis主從架構中:客戶端向主節點申請鎖,主節點異步復制鎖的信息到從節點中。若主節點崩潰,從節點升級為主節點時,可能尚未接受到鎖信息,導致新主節點上沒有鎖信息,其他客戶端可以獲取相同的鎖,破壞了互斥性
A:RedLock通過多節點獨立獲取+多數表決機制解決該問題。
- 部署多個完全獨立的redis主節點(無主從關系,建議至少部署5個)
- 客戶端依次向所有節點申請鎖
- 當獲取多數節點(N/2+1)的鎖時,才算獲取成功
- 鎖的有效時間包含獲取鎖的時間消耗
Q:Redisson看門狗機制如何實現業務未處理完成,鎖會自動續約?
A:Redisson的看門狗機制是其分布式鎖實現的核心特性之一,它解決了業務處理時間超過鎖超時時間的問題。
- 核心原理:
- 自動續期機制:當客戶端獲取鎖后,會啟動一個后臺線程定期檢查并延長鎖的持有時間
- 健康檢查:只要客戶端還“活著”(JVM進程未崩潰),鎖就不會因為超時被意外釋放
- 默認配置:
- 鎖默認超時時間:30秒
- 續期檢查間隔:超時時間的1/3(默認10秒一次)
Q:什么是死鎖,如何避免?
A:死鎖(Deadlock)是指兩個或多個進程/線程在執行過程中,由于競爭資源或彼此通信而造成的一種互相等待的現象,若無外力干涉,這些進程/線程都將無法繼續執行下去
- 死鎖的必要提交:
- 互斥條件:資源一次只能由一個進程占用
- 請求與保持條件:進程持有至少一個資源,并等待獲取其他被占用資源
- 不可剝奪條件:已分配給進程的資源,不能被其他進程強行奪取
- 循環等待條件:存在一個進程等待的循環鏈
- 死鎖常見場景:
- 數據庫死鎖
- java多線程死鎖
- 預防策略(破壞必要條件)
| 必要條件 | 破壞方法 |
|---|---|
| 互斥條件 | 使用共享資源(如讀寫鎖) |
| 請求與保持條件 | 一次性申請所有資源(All-or-Nothing) |
| 不可剝奪條件 | 允許搶占資源(設置超時/中斷) |
| 循環等待條件 | 資源有序分配法(對所有資源排序,按固定順序申請) |
- 避免策略(運行時判斷)
- 銀行家算法:系統在分配資源先計算分配的安全性
- 資源分配圖算法:檢查圖中是否存在環
- 檢查與恢復
- 檢查機制:
- 定期檢查資源分配圖
- 使用等待圖(wait-for graph)檢測環
- 恢復措施:
- 進程終止:強制終止部分死鎖進程
- 資源搶占:回滾并搶占部分資源
- 檢查機制:
- 解決:
- 統一加鎖順序:通過固定的順序打破循環等待條件
- 按照固定順序加鎖,避免線程之間交叉申請資源
- 設置超時機制:即使退出等待狀態避免僵局
- 設置超時時間,打破占有且等待條件,通過try lock設置超時機制,未獲取到鎖時,退出等待
- 使用無鎖算法和并發工具類,盡量避免顯示加鎖
- java.util.concurrent包下面的安全容器與工具
- concurrentHashMap
- ConcurrentLinkedQueue
- AtomicInteger
- 盡量避免使用顯示加鎖
- java.util.concurrent包下面的安全容器與工具
- 減少鎖的顆粒度,限制同步范圍優先性能
- 盡量減少鎖的顆粒度,縮小鎖的臨界區,減少線程之間的競爭
- 避免鎖嵌套
- 盡量減少一個線程持有多個鎖,或者多個線程相互金正同一組鎖的場景
- 檢查死鎖
- 通過死鎖監控工具(JConsole、visualVM中的線程視圖)分析線程狀態并排查
- 統一加鎖順序:通過固定的順序打破循環等待條件
2.JVM垃圾回收原理及如何優化
- 垃圾回收核心概念:
- 可達性分析算法:通過GC Roots對象作為起點,向下搜索引用鏈,不可達的對象即為垃圾
- GC Roots包括:
- 虛擬機棧中引用的對象
- 方法區中類靜態屬性引用的對象
- 方法區中常用引用的對象
- 本地方法棧中JNI引用的對象
- 內存分代模型
- JVM將堆內存劃分為不同的代際
堆內存結構
┌───────────────────────┐
│ Young Gen │
│ ┌─────┐ ┌─────┐ ┌─────┐│
│ │Eden │ │S0 │ │S1 ││
│ └─────┘ └─────┘ └─────┘│
├───────────────────────┤
│ Old Gen │
└───────────────────────┘
│ Permanent Gen/Metaspace │
└───────────────────────┘- 主流的垃圾回收器:
- 新生代回收器:
- serial:單線程,復制算法
- parNew:serial的多線程版本
- parallel scavenge:吞吐量有限
- 老年代回收器:
- serial old:單線程,標記-整理算法
- parallel old:parallel scavenge的老年代斑斑
- CMS:低延遲,標記-清楚算法
- G1回收器:
- 面向服務端應用
- 將堆劃分為多個Region
- 可預測的停頓時間模型
- ZGC/Shenandoah
- JDK11+引入的超低延遲回收器
- 停頓時間不超過10ms
- 支持TB級堆內存
- 新生代回收器:
- 垃圾回收優化策略:
- 關鍵JVM參數:
- 設置初始和最大堆大小,老年代和新生代比例,eden/survivor比例,啟用G1回收器,啟用CMS回收器
- 優化原則:
- 內存分配優化:
- 避免過大的對象直接進入老年代
- 合理設置新生代大小,減少過早晉升
- 監控對象年齡分布,調整晉升閾值
- GC策略選擇:
- 吞吐量優先:parallel scavenge+parallel old
- 低延遲優先:CMS/G1/ZGC
- 大內存應用:G1/ZGC/Shenandoah
- 內存分配優化:
- 關鍵JVM參數:
- 常見問題解決方案:
- 頻繁full gc
- 檢查內存泄露
- 調整老年代大小
- 優先對象分配模式
- 長時間GC停頓
- 考慮切換到G1或者ZGC
- 減少存活對象數量
- 增加堆內存
- 內存碎片問題:
- 使用標記-整理算法回收器
- 適當減少-xxcmsInitiatingOccupancyFraction值
- 內存碎片問題:
- 定期重啟服務
- 使用優化技巧
- 對象池化:復用對象減少GC壓力
- 本地緩沖控制:合理使用weak /soft reference
- 集合優化:預估大小避免擴容
- 流處理:及時關閉資源
- 監控工具:
- jstat -gcutil pid
- visualVM
- GCViewer分析GC日志
- Arthas實時診斷
- 使用優化技巧
- 頻繁full gc
- 不同場景下優化建議
- web應用
- 推薦G1回收器,關注會話對象生命周期,優化緩沖策略
- 大數據處理
- 增加新生代比例,考慮使用parallel回收器,監控大對象分配
- 金融交易系統:
- 優先考慮ZGC/shenandoah,嚴格控制停頓時間,減少不可預測的對象分配
- web應用
3.工作中如何使用線程的?
? ? ? ? 框架級別的,在啟動框架時,利用多線程來處理一些批量的任務,比如spring boot在啟動的時候通過多線程來過濾自動配置類,當然他的線程是在啟動的時候過濾下,后續就關閉了。但是如果我們是對外提供的接口,如果使用線程池,有可能在高并發的場景下,創建大量的線程,從而導致過度的消息系統的資源,甚至拉垮系統,所以我們使用線程池合理的創建執行到銷毀來管理系統。
- 基礎的使用:通過直接創建線程、線程池來使用
- 典型應用:通過異常處理,主流程不需要等待結果的操作;并行計算,CPU密集型任務拆分;定時任務;生產者-消費者模式
- 線程池類型選擇
- CPU密集型:固定大小線程池
- IO密集型:可緩存線程池
- 定時/延遲任務:調度線程池
- 任務優先級管理:自定義ThreadPoolExecutor
- 推薦自定義線程池配置
- 關鍵參數建議:
- 核心線程數:CPU密集型設為CPU核心數+1,IO密集型可設更高
- 隊列容量:根據系統負載設置,避免OOM
- 拒絕策略
- AbortPolicy:默認,拋出異常
- callerRunsPolicy:由調用線程執行
- DiscardOldestPolicy:丟棄最舊任務
- DiscardPolicy:默認丟棄
-
Q:線程常見問題:
- 線程泄露,線程數持續增長不釋放
- 解決:
- 確保正確暴斃線程池、使用有界隊列、設置合理的線程存活時間
- 死鎖預防:防止死鎖四步走
- 性能監控:監控線程池狀態
Q:使用什么方式創建線程池?為何不適用jdk內置的executors創建線程池?
4.工作中如何使用策略模式+依賴注入?
在工作中總是會有通過某些枚舉來判斷做什么操作,比如在訂單支付接口中,我們需要判斷用戶提交的是微信支付還是支付寶支付,如果后面支付的方式越來越多,代碼會越來越長,那么如何使用策略模式來改造這種現象呢?
原始代碼:
public class PaymentService {public void processPayment(String paymentType, BigDecimal amount) {if ("ALIPAY".equals(paymentType)) {// 支付寶支付邏輯System.out.println("處理支付寶支付: " + amount);} else if ("WECHAT".equals(paymentType)) {// 微信支付邏輯System.out.println("處理微信支付: " + amount);} else if ("UNIONPAY".equals(paymentType)) {// 銀聯支付邏輯System.out.println("處理銀聯支付: " + amount);} else {throw new IllegalArgumentException("不支持的支付方式");}}
}上面代碼違反了開閉原則,每次新增支付方式需要調整原代碼,方法臃腫,隨著支付方式越來越多,會越來越長,難以單獨測試某中支付方式,支付邏輯與其他代碼邏輯耦合。
方式一:策略模式改造:定義策略接口
public interface PaymentStrategy {/*** 支付處理方法* @param amount 支付金額* @return 支付結果*/PaymentResult pay(BigDecimal amount);/*** 是否支持當前支付類型* @param paymentType 支付類型* @return 是否支持*/boolean supports(String paymentType);
}// 支付結果封裝
public class PaymentResult {private boolean success;private String message;private String transactionId;// getters/setters
}方式一:策略模式改造:實現具體策略模式,以支付寶方式為例
public class AlipayStrategy implements PaymentStrategy {@Overridepublic PaymentResult pay(BigDecimal amount) {// 調用支付寶SDK的具體實現System.out.println("支付寶支付處理中,金額: " + amount);PaymentResult result = new PaymentResult();result.setSuccess(true);result.setTransactionId("ALI" + System.currentTimeMillis());return result;}@Overridepublic boolean supports(String paymentType) {return "ALIPAY".equalsIgnoreCase(paymentType);}
}方式一:?策略模式改造:創建策略工廠
public class PaymentStrategyFactory {private final List<PaymentStrategy> strategies;// 通過構造器注入所有策略public PaymentStrategyFactory(List<PaymentStrategy> strategies) {this.strategies = strategies;}public PaymentStrategy getStrategy(String paymentType) {return strategies.stream().filter(s -> s.supports(paymentType)).findFirst().orElseThrow(() -> new IllegalArgumentException("不支持的支付方式: " + paymentType));}
}方式一:策略模式改造:改造支付服務
@Service
public class PaymentService {private final PaymentStrategyFactory strategyFactory;// 構造器注入public PaymentService(PaymentStrategyFactory strategyFactory) {this.strategyFactory = strategyFactory;}public PaymentResult processPayment(String paymentType, BigDecimal amount) {PaymentStrategy strategy = strategyFactory.getStrategy(paymentType);return strategy.pay(amount);}
}方式二:springboot集成優化 自動注冊策略bean
@Configuration
public class PaymentConfig {@Beanpublic PaymentStrategyFactory paymentStrategyFactory(List<PaymentStrategy> strategies) {return new PaymentStrategyFactory(strategies);}@Beanpublic PaymentStrategy alipayStrategy() {return new AlipayStrategy();}@Beanpublic PaymentStrategy wechatPayStrategy() {return new WechatPayStrategy();}@Beanpublic PaymentStrategy unionPayStrategy() {return new UnionPayStrategy();}
}方式二:springboot集成優化 使用枚舉優化支付類型
public enum PaymentType {ALIPAY("ALIPAY", "支付寶"),WECHAT("WECHAT", "微信支付"),UNIONPAY("UNIONPAY", "銀聯支付");private final String code;private final String name;// constructor/getters
}方式二:springboot集成優化 策略接口改進,使用枚舉
public interface PaymentStrategy {PaymentResult pay(BigDecimal amount);// 改為支持PaymentType枚舉boolean supports(PaymentType paymentType);
}?方式三:優化方案:策略+模板方法模式結合
public abstract class AbstractPaymentStrategy implements PaymentStrategy {@Overridepublic final PaymentResult pay(BigDecimal amount) {// 1. 參數校驗validate(amount);// 2. 執行支付PaymentResult result = doPay(amount);// 3. 記錄日志logPayment(result);return result;}protected abstract PaymentResult doPay(BigDecimal amount);private void validate(BigDecimal amount) {if (amount == null || amount.compareTo(BigDecimal.ZERO) <= 0) {throw new IllegalArgumentException("金額必須大于0");}}private void logPayment(PaymentResult result) {// 記錄支付日志}
}方式三:優化方案 策略緩存優化
public class CachedPaymentStrategyFactory {private final Map<PaymentType, PaymentStrategy> strategyCache = new ConcurrentHashMap<>();private final List<PaymentStrategy> strategies;public CachedPaymentStrategyFactory(List<PaymentStrategy> strategies) {this.strategies = strategies;}public PaymentStrategy getStrategy(PaymentType paymentType) {return strategyCache.computeIfAbsent(paymentType, type -> strategies.stream().filter(s -> s.supports(type)).findFirst().orElseThrow(() -> new IllegalArgumentException("不支持的支付方式")));}
}Spring相關面試題
1.Spring AOP底層實現原理是什么?
- Spring AOP(面向切面編程)的底層實現基于動態代理技術,主要通過兩種實現方式:JDK動態代理和CGLIB字節碼生成。當目標類實現了接口,Spring默認使用了JDK動態代理,否則使用CGLIB方式,而spring-boot選擇了VCGLIB方式來實現。
- JDK動態代理(基于接口)
- 適用條件:目標類實現了至少一個接口
- 代理對象通過JDK直接生成,實現目標類的接口,并通過反射調用目標類
- 特點:
- 運行時生成接口的代理類
- 通過InvocationHandler攔截方法調用
- 性能較好,但只能代理接口方法
- CGLIB字節碼生成(基于子類)
- 適用條件:不能使用final
- 適用對象:目標類沒有實現接口
- CGLIB通過CFLIB-ASM操作框架生成,繼承目標類,通過子類調用父類的方式進行調用目標方法
- 特點:
- 通過ASM庫直接生成目標類的子類(Enhancer)
- 可以代理普通類方法(包括非public方法)
- 創建代理對象速度較慢,但執行效率高
- 代理創建流程
- Spring AOP創建代理的核心流程:
- 解析切面配置
- 通過@Aspect注解或者XML配置識別切面
- 解析切入點表達式(Pointcut)
- 創建代理工廠(proxyFactory)
- 選擇代理機制
- 生成代理對象
- JDK代理:proxy.newProxyInstance()
- CGLIB:enhance.create()
- Spring AOP創建代理的核心流程:
- 攔截器鏈執行
- Spring AOP通過責任鏈模式執行增強邏輯
- 增強類型與順序執行
- spring aop支持了五種通知類型
- @Aroud環繞通知
- @before前置通知
- 目標方法執行
- @AfterReturing(返回通知,正常返回時執行)
- @After(后置通知,finally塊中執行)
- @AfterThrowing(異常通知,拋出異常時執行)
- 性能優化與實現
- Spring對AOP進行了多項優化
- 緩沖機制
- 代理類緩沖DefaultAopProxyFactory
- 攔截器鏈緩沖AdvisedSupport
- 預過濾
- 預先排除不可能匹配的方法
- 選擇性代理
- 支隊匹配切入點的方法生成代理邏輯
- 其他方法直接調用目標方法
- 緩沖機制
- Spring對AOP進行了多項優化
- JDK動態代理(基于接口)
- 與AspectJ的關系
| 特性 | Spring AOP | AspectJ |
|---|---|---|
| 實現方式 | 運行時動態代理 | 編譯時/加載時織入 |
| 性能 | 較好 | 最優(編譯期完成) |
| 功能范圍 | 僅方法級別 | 字段、構造器、靜態塊等 |
| 依賴 | 僅Spring核心 | 需要AspectJ編譯器/織入器 |
| 適用場景 | 簡單切面需求 | 復雜切面需求 |
- 總結:
- Spring AOP的底層實現本質上是基于代理模式的運行時增強,其核心特點是
- 非侵入性:通過代理實現,不修改原始代碼
- 靈活性:支持多種通知類型和切入點表達式
- 可擴展性:可與AspectJ部分功能集成
- 性能平衡:通過緩存和優化策略保證運行時效率
- Spring AOP的底層實現本質上是基于代理模式的運行時增強,其核心特點是
spring boot面試相關
1.spring boot 解決跨域5種方式
什么是跨域,當你公司的域名eg:http://mywork.com要到https://baidu.com上去獲取東西
此時可以看到域名mywork->baidu不同;協議http->https不同;端口不同;二級域名不同,ip不同等。跨域不一定有異常,跨域異常只有在前端才會發生,因為瀏覽器有一個同源策略,當發現我們不同域之間的訪問是不安全的行為,他會禁止,然后拋出異常。
- jsonp
- 優點是因為他夠老,能兼容各種瀏覽器,無兼容問題
- 缺點只支持get,而且存在安全問題,且前后端都要相對應的去調整接受參數等信息。
- cors
- 前端不需要代碼調整,主要靠服務端進行配置,
- cors需要瀏覽器和服務器同時支持,目前所有瀏覽器都支持該功能,IE版本不能低于10
- 瀏覽器一旦發現AJAX請求跨源就會自動添加一些附加的頭信息,有時候還會多出一次附加的請求,但用戶不會有感知
- ?后端使用
CrossOrigin注解,配置:origins:允許的源列表、methods:允許的HTTP方法、maxAge:預檢請求緩存時間(秒)、allowedHeaders:允許的請求頭,這里只支持單獨的接口
- 全局cors配置
- 基于webMvcConfigure和Filter配置
- CorsFilter 過濾器
- nginx反向代理
-
?Spring Security配置CORS
-
使用Gateway統一處理(微服務架構)
| 方案 | 適用場景 | 優點 | 缺點 |
|---|---|---|---|
@CrossOrigin | 簡單項目,少量端點需要跨域 | 簡單直觀 | 需要每個Controller單獨配置 |
| 全局WebMvc配置 | 統一管理的中型項目 | 一處配置,全局生效 | 無法針對不同路徑精細控制 |
| Filter配置 | 需要精細控制過濾順序的項目 | 靈活,可與其他Filter配合 | 配置相對復雜 |
| Spring Security | 已使用Spring Security的項目 | 與安全配置統一管理 | 需要了解Security相關知識 |
| Gateway統一處理 | 微服務架構,API網關統一入口 | 前端無感知,后端統一處理 | 需要引入Spring Cloud Gateway |
mysql相關
mysql相關面試可以查看本博主其他博客:
面試題之數據庫相關-mysql篇-CSDN博客
面試題之數據庫-mysql高階及業務場景設計-CSDN博客
組合面試題
1.如何有效的阻止訂單重復提交和支付
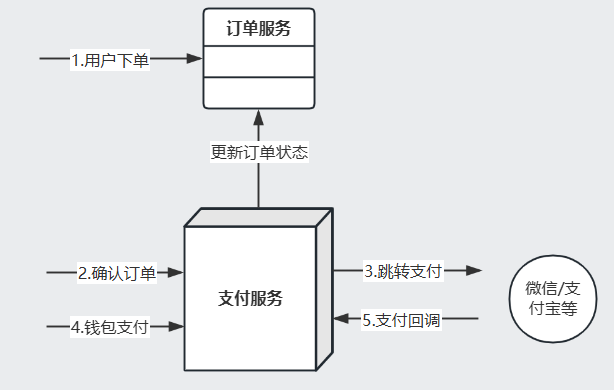
理論上只會在用戶在下單的這個動作可能因為網絡抖動、RPC重試等進行多次下單的操作,其他步驟確認訂單只是修改訂單狀態,跳轉支付和確認支付這些不會出現多次支付的問題。所以該題主要是針對用戶多次調用下單接口怎么處理即下單接口的冪等性問題。
- 訂單重復提交問題
- 前端防重復提交方案
- 按鈕置灰等操作
- PRG模式:post/redirect/get模式,用戶點擊表單時重定向跳轉到其他頁面。
- token機制,在用戶進入訂單界面前生成固定的token,前端限制一個token調用時,后端攔截token的一次性,做請求攔截限制
- 請求攔截:通過axios攔截器攔截信息
- 后端接口設計
- 冪等性設計
- 每次請求先配合客戶端生成一個唯一id,可由訂單id+用戶id+確認標識做綁定,同一接口,每次調用的id一致則不生成新的訂單,注意標識符的失效時間
- 請求參數中帶有時間戳與當前時間對比,若時間太長則默認為重復請求
- 請求狀態檢查,根據日志查詢、用戶訂單關聯查詢是否有重復數據
- 數據庫唯一約束
- 先獲取數據庫唯一ID來處理
- redis原子操作
- setnx操作,對同一個訂單id+用戶id+確認標識做綁定,設置失效時間,進行處理
- 冪等性設計
- 前端防重復提交方案
- 支付方重復方案
- 訂單狀態機制
- 第三方支付冪等
- 支付結果異步核對
- 分布式系統解決方案
- 分布式鎖
- 消息隊列去重
- 異常處理機制
- 補償事務處理
- 人工審核接口
- 監控與報警
- 重復請求監控 設置ip白名單防止惡意操作
- 建議:
- 多層次防御:前端+后端+數據庫約束等
- 核心原則:所有寫操作必須實現冪等性接口
- 關鍵數據:訂單號、用戶ID、時間戳組合防重復
- 狀態管理:嚴格的狀態機控制流程
- 補償機制:自動核對+人工干預雙重保險
- 技術選擇
| 場景 | 推薦方案 | 優點 |
|---|---|---|
| 簡單單體系統 | 本地鎖+數據庫唯一約束 | 實現簡單 |
| 分布式高并發 | Redis分布式鎖+消息隊列 | 擴展性好 |
| 金融級支付系統 | 狀態機+定時核對+人工干預 | 可靠性最高 |
| 舊系統改造 | 前端Token+后端冪等接口 | 侵入性最小 |
2.RestTemplate 如何優化連接池
- restTemplate默認是沒有連接池,他的調用原理是每次都會創建一個HTTP連接,默認使用simpleClientHttpRequestFactory去創建連接,底層通過HttpURLConnection創建連接。在高并發的條件下,會無上限的創建連接,消耗系統資源。所以需要通過連接池來限制最大連接數,當請求的域不是很多且不隨機的情況下,還可以復用同一個域的HTTP連接;
- HTTP請求流程:在我們發起一個http請求連接的時候,會對域名解析,連接之前的三次握手,如果是HTTPS還需要傳遞安全證書,以及請求完成之后的4次揮手。但是我們真正請求和響應只在其中的一小環節,所以我們通過一個連接池就可以對同一個域來建立一個長鏈接,就無需執行每次的無關業務請求的動作,這樣就實現了連接的復用。
- 通過resttemplate來配置連接池的話有HttpClient和OkHttp.
- 具體實現:
- 代碼上引入httpclient連接池的包,修改RestTemplate請求工廠,將默認工廠的simpleClientHttpRequestFactory換成HttpClientFactory,在為這個工廠配置請求bean。最后去設置連接池參數信息。設置最大連接數,根據QPS的響應時間平均值來設置,設置某個域的長鏈接復用,但是如果該值太小,比如設置2,那么只會創建兩個長鏈接,這樣后續的接口會進行阻塞等待。
- 在實現連接池的方法時,需要注意以下幾點:
- 路由區分:對重要API設置獨立的路由連接數
- 異常處理:配置重試機制
- DNS刷新:避免DNS緩沖問題
- 連接存活時間
| 參數 | 建議值 | 說明 |
|---|---|---|
| setMaxTotal | 100-500 | 最大連接數,根據服務器配置調整 |
| setDefaultMaxPerRoute | 50-100 | 每個路由(host:port)的最大連接數 |
| setConnectTimeout | 3000-5000ms | 建立TCP連接的超時時間 |
| setSocketTimeout | 5000-10000ms | 數據傳輸超時時間 |
| setConnectionRequestTimeout | 1000-2000ms | 從連接池獲取連接的超時時間 |
| evictIdleConnections | 30-60s | 空閑連接回收時間 |
3.如何設計秒殺系統?高并發?
查看此博客:面試題之如何設計一個秒殺系統?-CSDN博客
工具類應用
1.git如何撤回已提交的push代碼
使用idea集成可視化界面操作
- 已提交 未推送
- 使用idea,找到提交的版本,選擇undo commit
- 已提交 已推送
- revert commit->本地代碼回滾到提交前的版本->在push一下 將遠程倉庫代碼覆蓋上
- 已回滾 代碼恢復
- 選擇剛才已經回滾的代碼->cherry pick還原已經寫好的代碼

)

)








![[圖論]Kruskal](http://pic.xiahunao.cn/[圖論]Kruskal)






文章思路 模型 代碼 結果分享)