摘要:本文介紹了一種將非結構化數據轉換為知識圖譜的端到端方法。通過使用大型語言模型(LLM)和一系列數據處理技術,我們能夠從原始文本中自動提取結構化的知識。這一過程包括文本分塊、LLM 提示設計、三元組提取、歸一化與去重,最終利用 NetworkX 和 ipycytoscape 構建并可視化知識圖譜。該方法不僅能夠高效地從文本中提取知識,還能通過交互式可視化幫助用戶更好地理解和分析數據。通過實驗,我們展示了該方法在處理復雜文本時的有效性和靈活性,為知識圖譜的自動化構建提供了新的思路。
?? 向所有學習者致敬!
“學習不是裝滿一桶水,而是點燃一把火。” —— 葉芝
我的博客主頁: https://lizheng.blog.csdn.net
?? 歡迎點擊加入AI人工智能社區!
?? 讓我們一起努力,共創AI未來! ??
從純文本構建知識圖譜是一項挑戰。它通常需要識別重要術語,弄清楚它們之間的關系,并使用自定義代碼或機器學習工具來提取這種結構。我們將創建一個由大型語言模型(LLM)驅動的端到端流水線,自動將原始文本轉換為交互式知識圖譜。
我們將使用幾個關鍵的 Python 庫來完成這項工作。讓我們先安裝它們。
# 安裝庫(只運行一次)pip install openai networkx "ipycytoscape>=1.3.1" ipywidgets pandas
安裝完成后,你可能需要重啟 Jupyter 內核或運行時,以便更改生效。
現在我們已經安裝好了,讓我們將所有內容導入到腳本中。
import openai # 用于 LLM 交互
import json # 用于解析 LLM 響應
import networkx as nx # 用于創建和管理圖數據結構
import ipycytoscape # 用于交互式筆記本中的圖可視化
import ipywidgets # 用于交互式元素
import pandas as pd # 用于以表格形式顯示數據
import os # 用于訪問環境變量(API 密鑰更安全)
import math # 用于基本數學運算
import re # 用于基本文本清理(正則表達式)
import warnings # 抑制潛在的棄用警告
完美!我們的工具箱已經準備好了。所有必要的庫都已加載到我們的環境中。
什么是知識圖譜?
想象一個網絡,有點像社交網絡,但除了人之外,它還連接事實和概念。這基本上就是一個知識圖譜(KG)。它有兩個主要部分:
- 節點(或實體):這些是“事物”——比如“居里夫人”、“物理學”、“巴黎”、“諾貝爾獎”。在我們的項目中,我們提取的每個獨特的主語或賓語都將變成一個節點。
- 邊(或關系):這些是事物之間的連接,顯示它們如何關聯。關鍵在于,這些連接有意義,并且通常有方向。例如:“居里夫人” — 獲得 → “諾貝爾獎”。其中的“獲得”部分是關系,定義了邊。
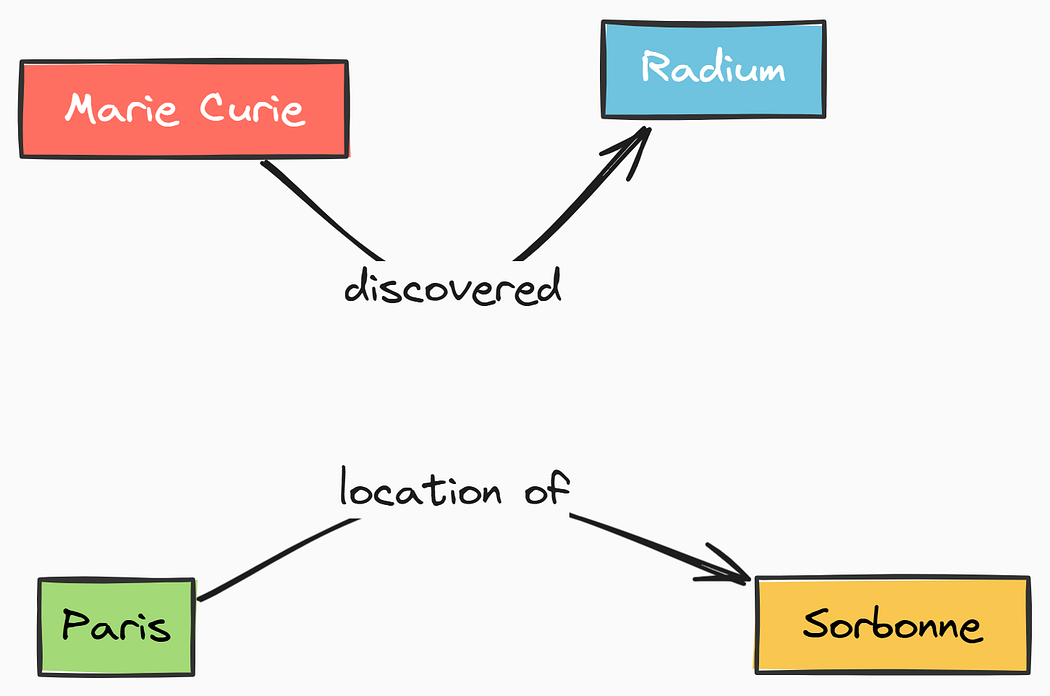
最簡單的知識圖譜示例
一個簡單的圖,顯示兩個節點(例如,“居里夫人”和“鐳”)通過一個標記為“發現”的有向邊連接。再添加一個小集群,如(“巴黎” — 位于 → “索邦大學”)。這可視化了節點-邊-節點的概念。
知識圖譜之所以強大,是因為它們以更接近我們思考連接的方式結構化信息,使我們更容易發現見解,甚至推斷出新的事實。
主語-謂語-賓語(SPO)三元組
那么,我們如何從純文本中獲取這些節點和邊呢?我們尋找簡單的事實陳述,通常以 主語-謂語-賓語(SPO) 三元組的形式出現。
- 主語:事實是關于誰或什么的(例如,“居里夫人”)。將成為一個節點。
- 謂語:連接主語和賓語的動作或關系(例如,“發現”)。將成為邊的標簽。
- 賓語:主語相關的事物(例如,“鐳”)。將成為另一個節點。
示例:句子 “居里夫人發現了鐳” 完美地分解為三元組:(居里夫人, 發現, 鐳)。
這直接翻譯到我們的圖中:
- (居里夫人) -[發現]-> (鐳)。
我們的 LLM 的工作就是讀取文本并為我們識別這些基本的 SPO 事實。
配置我們的 LLM 連接
要使用 LLM,我們需要告訴腳本如何與之通信。這意味著提供一個 API 密鑰,有時還需要一個特定的 API 端點(URL)。
我們將使用 NebiusAI LLM 的 API,但你可以使用 Ollama 或任何其他在 OpenAI 模塊下工作的 LLM 提供商。
# 如果使用標準 OpenAI
export OPENAI_API_KEY='your_openai_api_key_here'# 如果使用本地模型,如 Ollama
export OPENAI_API_KEY='ollama' # 對于 Ollama,可以是任何非空字符串
export OPENAI_API_BASE='http://localhost:11434/v1'# 如果使用其他提供商,如 Nebius AI
export OPENAI_API_KEY='your_provider_api_key_here'
export OPENAI_API_BASE='https://api.studio.nebius.com/v1/' # 示例 URL
首先,讓我們指定我們想要使用的 LLM 模型。這取決于你的 API 密鑰和端點可用的模型。
# --- 定義 LLM 模型 ---# 選擇在你的配置端點可用的模型。# 示例:'gpt-4o', 'gpt-3.5-turbo', 'llama3', 'mistral', 'deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct', 'gemma'llm_model_name = "deepseek-ai/DeepSeek-V3" # <-- **_ 更改為你使用的模型 _**
好的,我們已經記錄下了目標模型。現在,讓我們從之前設置的環境變量中獲取 API 密鑰和基礎 URL(如果需要)。
# --- 獲取憑據 ---api_key = os.getenv("OPENAI_API_KEY")
base_url = os.getenv("OPENAI_API_BASE") # 如果未設置,則為 None(例如,對于標準 OpenAI)
客戶端已準備好與 LLM 通信。
最后,讓我們設置一些控制 LLM 行為的參數:
- 溫度:控制隨機性。較低的值意味著更專注、更確定性的輸出(適合事實提取!)。我們將溫度設置為 0.0,以實現最大的可預測性。
- 最大令牌數:限制 LLM 響應的長度。
# --- 定義 LLM 調用參數 ---llm_temperature = 0.0 # 較低的溫度用于更確定性、事實性的輸出。0.0 是提取的最佳選擇。
llm_max_tokens = 4096 # LLM 響應的最大令牌數(根據模型限制調整)
定義我們的輸入文本(原材料)
現在,我們需要將要轉換為知識圖譜的文本。我們將使用居里夫人的傳記作為示例。
unstructured_text = """
Marie Curie, born Maria Sk?odowska in Warsaw, Poland, was a pioneering physicist and chemist.
She conducted groundbreaking research on radioactivity. Together with her husband, Pierre Curie,
she discovered the elements polonium and radium. Marie Curie was the first woman to win a Nobel Prize,
the first person and only woman to win the Nobel Prize twice, and the only person to win the Nobel Prize
in two different scientific fields. She won the Nobel Prize in Physics in 1903 with Pierre Curie
and Henri Becquerel. Later, she won the Nobel Prize in Chemistry in 1911 for her work on radium and
polonium. During World War I, she developed mobile radiography units, known as 'petites Curies',
to provide X-ray services to field hospitals. Marie Curie died in 1934 from aplastic anemia, likely
caused by her long-term exposure to radiation."""
讓我們打印出來,看看它的長度。
print("--- 輸入文本已加載 ---")
print(unstructured_text)
print("-" \* 25)# 基本統計信息可視化char_count = len(unstructured_text)
word_count = len(unstructured_text.split())
print(f"總字符數:{char_count}")
print(f"大約單詞數:{word_count}")
print("-" \* 25)#### 輸出結果 ####
--- 輸入文本已加載 ---
Marie Curie, born Maria Sk?odowska in Warsaw, Poland, was a pioneering physicist and chemist.
She conducted groundbreaking research on radioactivity. Together with her husband, Pierre Curie,# [... 文本其余部分在此打印 ...]includes not only her scientific discoveries but also her role in breaking gender barriers in academia
and science.-------------------------
總字符數:1995
大約單詞數:324---
所以,我們有大約 324 個單詞的居里夫人的文本,雖然在生產環境中不太理想,但足以看到知識圖譜構建的過程。
切分它:文本分塊
LLM 通常有一個處理文本的限制(它們的“上下文窗口”)。
我們的居里夫人文本相對較短,但對于更長的文檔,我們肯定需要將它們分解為更小的部分,或分塊。即使是這種文本,分塊有時也能幫助 LLM 更專注于特定部分。
我們將定義兩個參數:
- 分塊大小:每個分塊中我們希望的最大單詞數。
- 重疊:一個分塊的末尾與下一個分塊的開頭之間應該有多少單詞重疊。這種重疊有助于保留上下文,避免事實被尷尬地截斷在分塊之間。
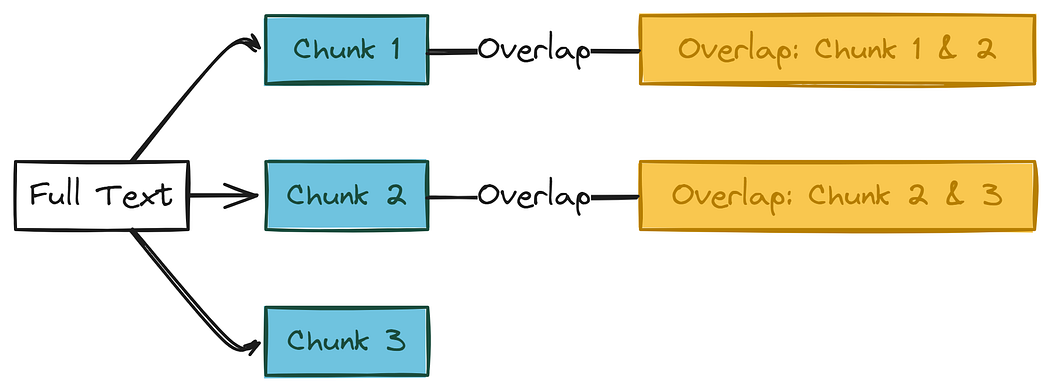
文本分塊過程
我們的完整文本被劃分為三個重疊的段(分塊)。清晰標記“分塊 1”、“分塊 2”、“分塊 3”。突出顯示分塊 1 與 2 之間以及分塊 2 與 3 之間的重疊部分。標記“分塊大小”和“重疊大小”。
讓我們設置我們期望的大小和重疊。
# --- 分塊配置 ---chunk_size = 150 # 每個分塊的單詞數(根據需要調整)
overlap = 30 # 分塊之間的重疊單詞數(必須小于分塊大小)print(f"分塊大小設置為:{chunk_size} 單詞")
print(f"重疊設置為:{overlap} 單詞")# --- 基本驗證 ---
if overlap >= chunk_size and chunk_size > 0:
print(f"錯誤:重疊 ({overlap}) 必須小于分塊大小 ({chunk_size})。")
raise SystemExit("分塊配置錯誤。")
else:
print("分塊配置有效。")### 輸出結果 ###
分塊大小設置為:150 單詞
重疊設置為:30 單詞
分塊配置有效。
好的,計劃是將分塊大小設置為 150 個單詞,分塊之間的重疊為 30 個單詞。
首先,我們需要將文本拆分為單獨的單詞。
words = unstructured_text.split()
total_words = len(words)print(f"文本拆分為 {total_words} 個單詞。")# 顯示前 20 個單詞print(f"前 20 個單詞:{words[:20]}")### 輸出結果 ###
文本拆分為 324 個單詞。
前 20 個單詞:['Marie', 'Curie,', 'born', 'Maria', 'Sk?odowska', 'in',
'Warsaw,', 'Poland,', 'was', 'a', 'pioneering', 'physicist', 'and',
'chemist.', 'She', 'conducted', 'groundbreaking', 'research', 'on',
'radioactivity.']
輸出確認我們的文本有 324 個單詞,并顯示了前幾個單詞。現在,讓我們應用我們的分塊邏輯。
我們將逐步遍歷單詞列表,每次抓取 chunk_size 個單詞,然后回退 overlap 個單詞以開始下一個分塊。
chunks = []
start_index = 0
chunk_number = 1print(f"開始分塊過程...")
while start_index < total_words:end_index = min(start_index + chunk_size, total_words)chunk_text = " ".join(words[start_index:end_index])chunks.append({"text": chunk_text, "chunk_number": chunk_number}) # print(f" Created chunk {chunk_number}: words {start_index} to {end_index-1}") # Uncomment for detailed log # 計算下一個分塊的起始位置next_start_index = start_index + chunk_size - overlap # 確保有進展if next_start_index <= start_index:if end_index == total_words:break # 已經處理了最后一部分next_start_index = start_index + 1 start_index = next_start_indexchunk_number += 1 # 安全中斷(可選)if chunk_number > total_words: # 簡單安全檢查print("警告:分塊循環超出總單詞數,中斷。")breakprint(f"\n文本成功拆分為 {len(chunks)} 個分塊。")#### 輸出結果 ####
開始分塊過程...文本成功拆分為 3 個分塊。





)

--樹)








)


