
docker和云服務的區別
首先明確Docker的核心功能是容器化,它通過容器技術將應用程序及其依賴項打包在一起,確保應用在不同環境中能夠一致地運行。而云服務則是由第三方提供商通過互聯網提供的計算資源,例如計算能力、存儲、數據庫等。云服務的范圍更廣,涵蓋了IaaS(基礎設施即服務)、PaaS(平臺即服務)和SaaS(軟件即服務)等多種形式。
Docker可以與云服務結合使用,例如在云服務商提供的虛擬機中運行Docker容器,或者直接使用云服務商提供的容器服務(如AWS ECS、Google Kubernetes Engine等)。但兩者本質上解決的問題不同,Docker關注的是應用的封裝和隔離,而云服務關注的是計算資源的按需分配和管理。
-
Docker底層原理:Docker利用了Linux內核的命名空間(namespace)和控制組(cgroup)技術來實現容器的隔離和資源限制。命名空間提供了進程、網絡、文件系統等方面的隔離,使得每個容器看起來像是獨立的系統。控制組則用于限制和分配容器使用的CPU、內存等資源。
-
云服務分類:
-
IaaS(基礎設施即服務):提供虛擬機、存儲、網絡等基礎計算資源,用戶可以在這些資源上部署自己的操作系統和應用。例如AWS EC2、Azure Virtual Machines。
-
PaaS(平臺即服務):除了基礎資源外,還提供了開發工具、數據庫管理、應用托管等功能,簡化了應用的開發和部署過程。例如Google App Engine、Heroku。
-
SaaS(軟件即服務):直接向用戶提供完整的軟件應用,用戶無需關心底層的技術細節。例如Salesforce、Office 365。
-
Docker與云服務的關系:雖然Docker和云服務的功能不同,但它們可以很好地互補。云服務提供了靈活的計算資源,而Docker則確保了應用在這些資源上的可移植性和一致性。例如,在Kubernetes集群中,Docker容器可以被編排和調度到不同的云實例上,從而實現高效的資源利用和應用擴展。
-
擴展知識:
-
容器與虛擬機的區別:容器和虛擬機都是用于隔離應用運行環境的技術,但容器共享宿主機的操作系統內核,而虛擬機則需要為每個實例運行一個完整操作系統。因此,容器在啟動速度、資源占用方面具有優勢,但在安全性上可能不如虛擬機。
-
云原生架構:隨著容器技術和云服務的發展,云原生架構逐漸成為現代應用開發的趨勢。云原生強調應用的設計應充分利用云的特點,例如彈性擴展、自動化部署、微服務架構等。Docker和Kubernetes是實現云原生的重要工具。
golang中讀取文件的流程是什么
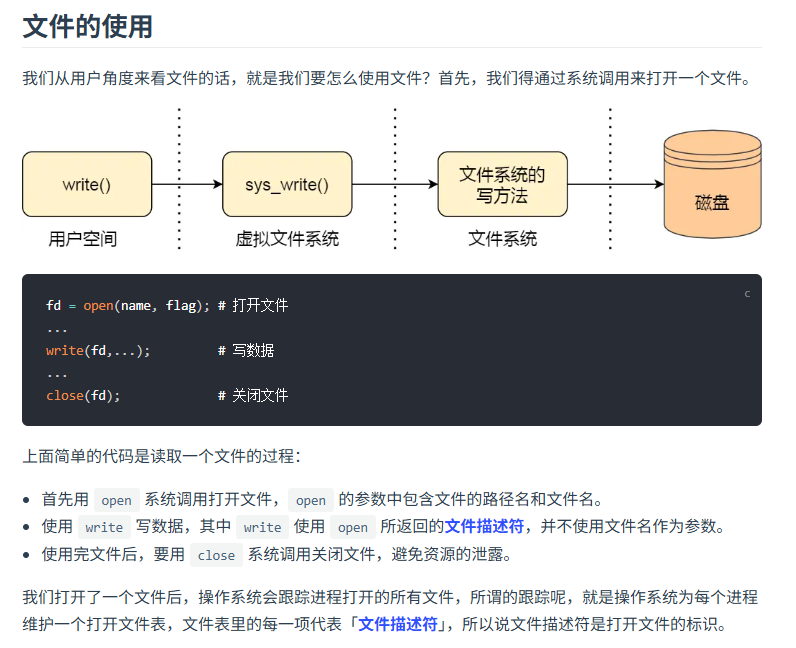
- 導入必要的包:要進行文件操作,必須先導入"os"包,如果需要更高效的緩沖讀取,則還需要導入"bufio"包。
- 打開文件:使用os.Open(path)函數打開指定路徑的文件,該函數返回一個*os.File類型的指針和可能的錯誤信息。
- 讀取文件:可以選擇不同的方式讀取文件內容。可以直接使用file.Read方法將文件內容讀取到字節切片中,也可以使用bufio.NewReader創建一個帶緩沖的Reader對象,然后逐行讀取文件內容。
- 關閉文件:無論讀取過程是否成功,都需要確保文件被正確關閉以釋放系統資源。這通常通過defer file.Close()實現,確保即使發生錯誤也能關閉文件。
- 深度知識講解:
- 文件操作涉及操作系統層面的知識,在Go語言中,文件被視為一種特殊的流(stream)。打開文件實際上是在操作系統中請求一個文件描述符(file descriptor),這個描述符是內核用來跟蹤文件狀態的一個整數標識符。
- os.Open實際上是調用了底層的操作系統API來獲取對文件的訪問權限。它返回的是一個實現了io.Reader接口的對象,這意味著你可以使用任何符合該接口的方法來處理文件數據。
- 使用bufio包的好處在于它可以提供緩沖機制,減少頻繁的系統調用,從而提高性能。例如,bufio.NewReader會預先讀取一定量的數據到內存緩沖區,后續的小批量讀取操作都會從緩沖區中獲取數據,而不是每次都向操作系統發起請求。


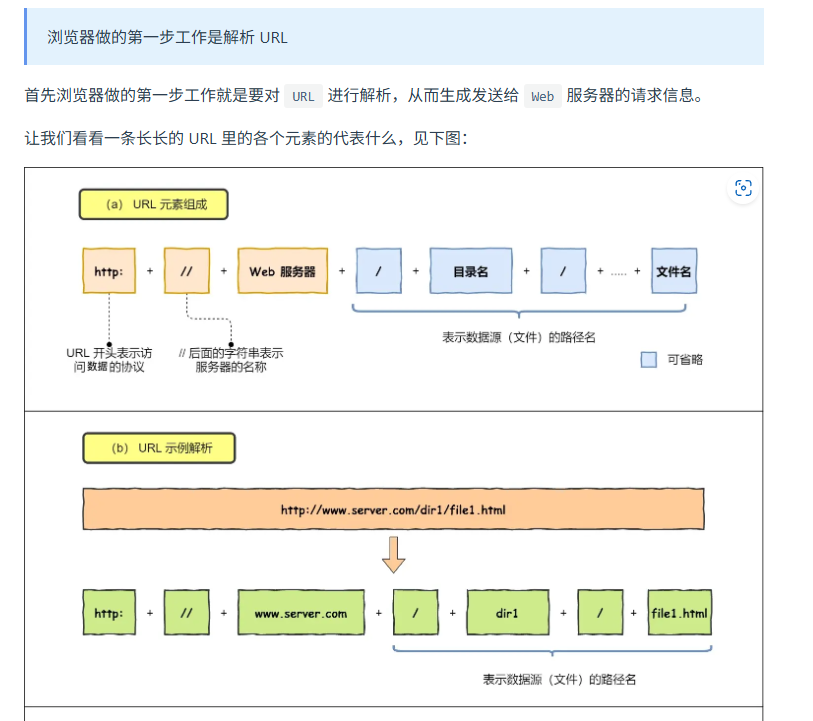
一個URL的輸入到瀏覽器展示頁面的過程
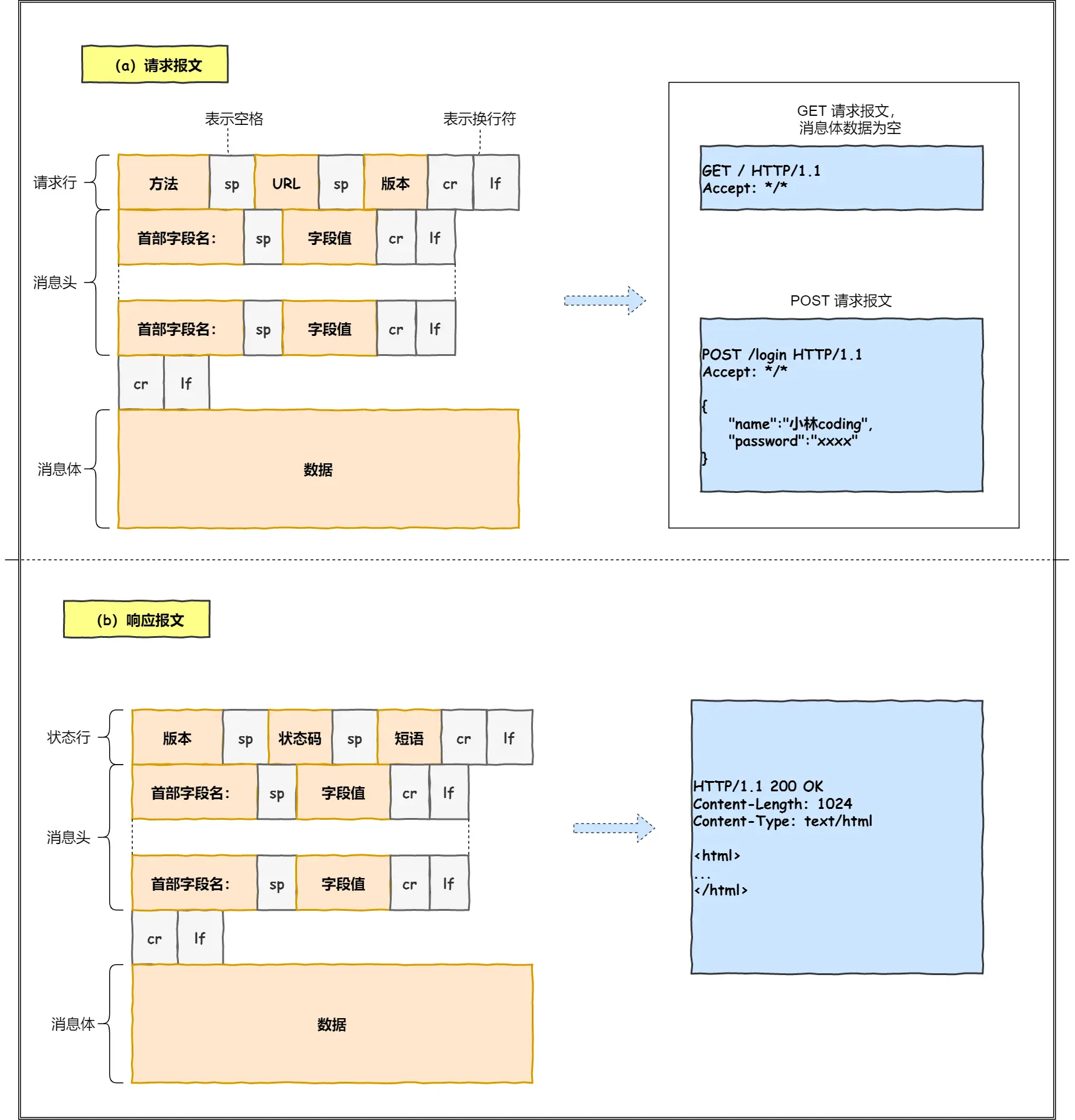
1. 瀏覽器解析url,產生http請求信息
2. DNS查詢服務器域名對應的 IP 地址
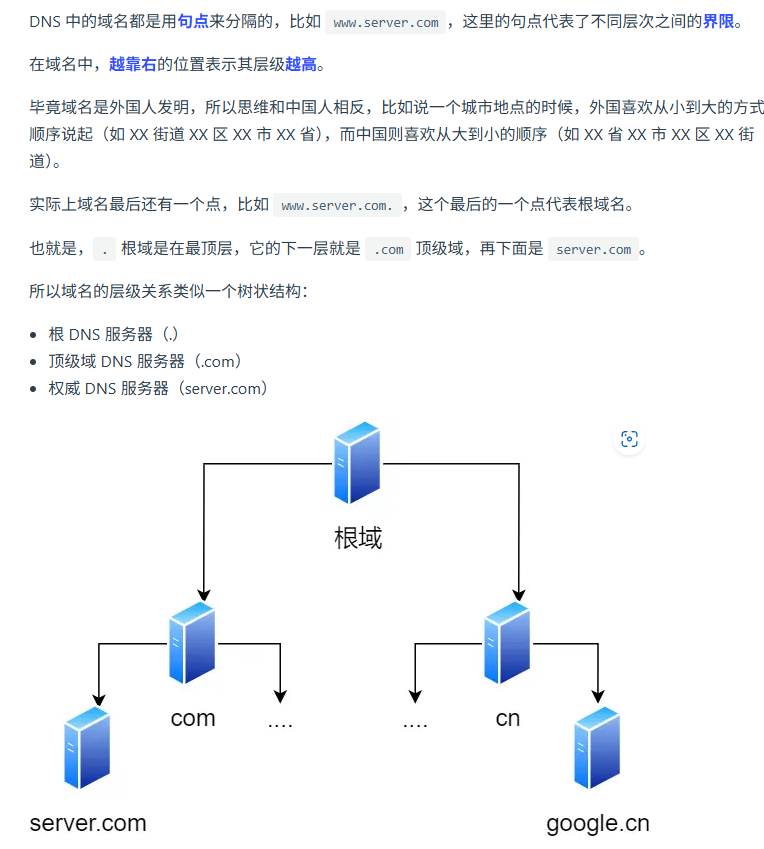
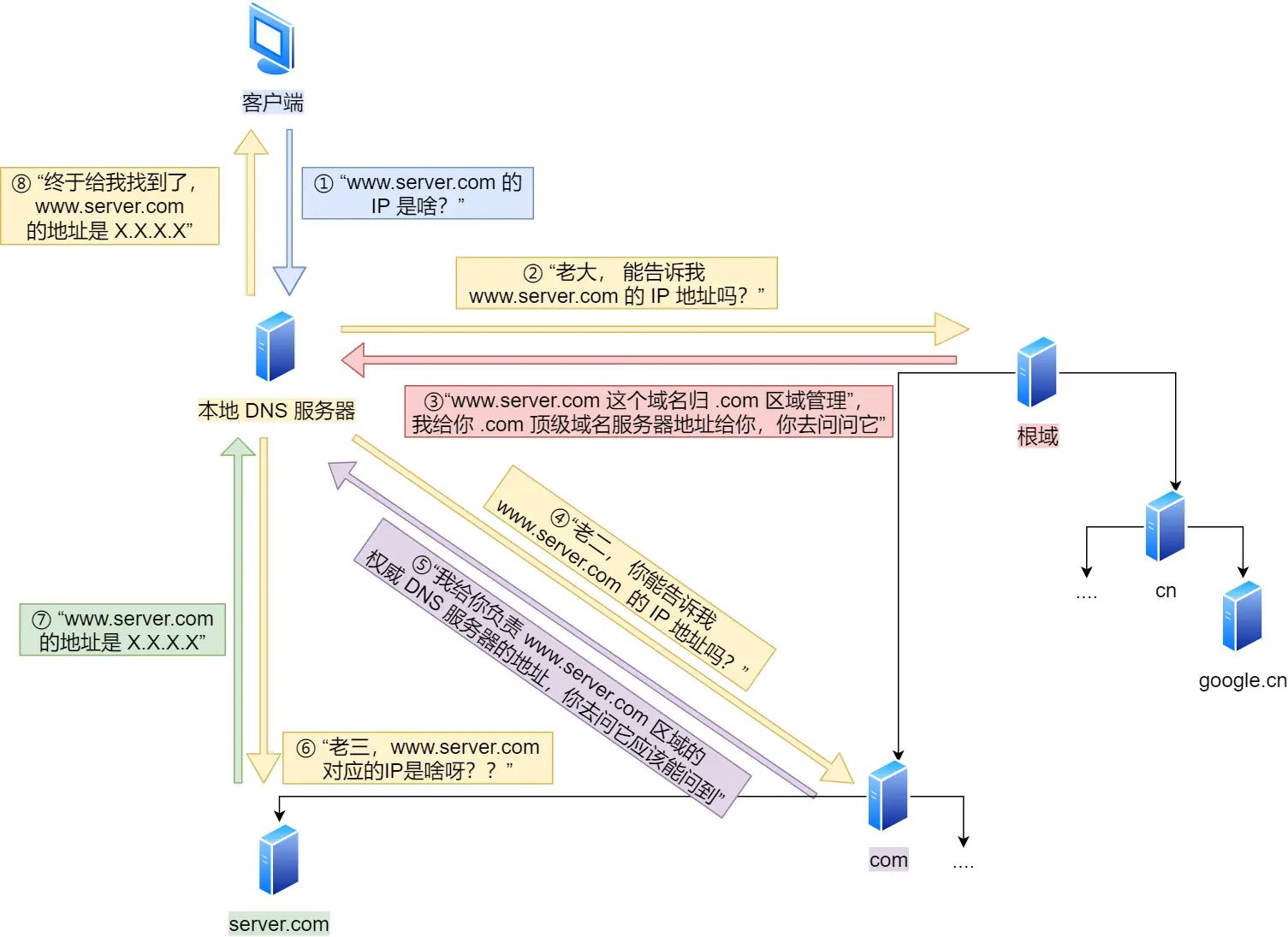
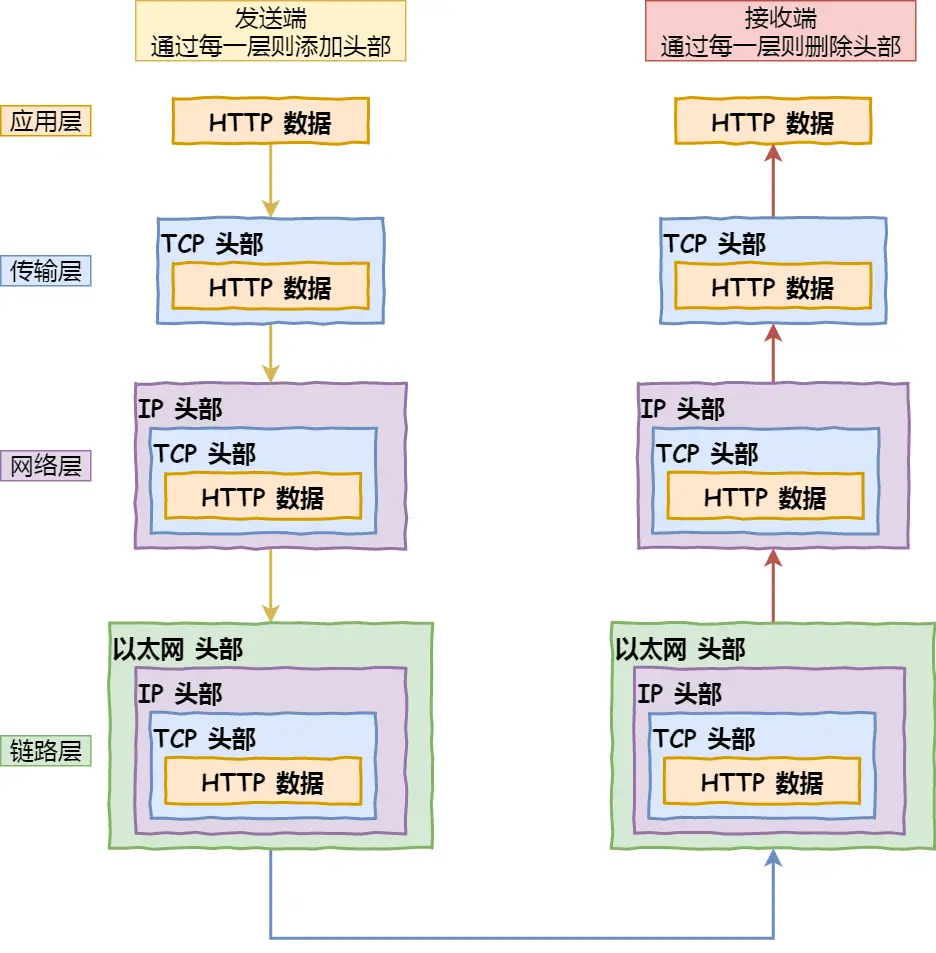
3. 應用程序(瀏覽器)通過調用Socket庫,來委托協議棧工作
協議棧的上半部分有兩塊,分別是負責收發數據的TCP和UDP協議,這兩個傳輸協議會接受應用層的委托執行收發數據的操作。
協議棧的下面一半是用IP協議控制網絡包收發操作,在互聯網上傳數據時,數據會被切分成一塊塊的網絡包,而將網絡包發送給對方的操作就是由IP負責的。

4. 可靠傳輸TCP(傳輸層)
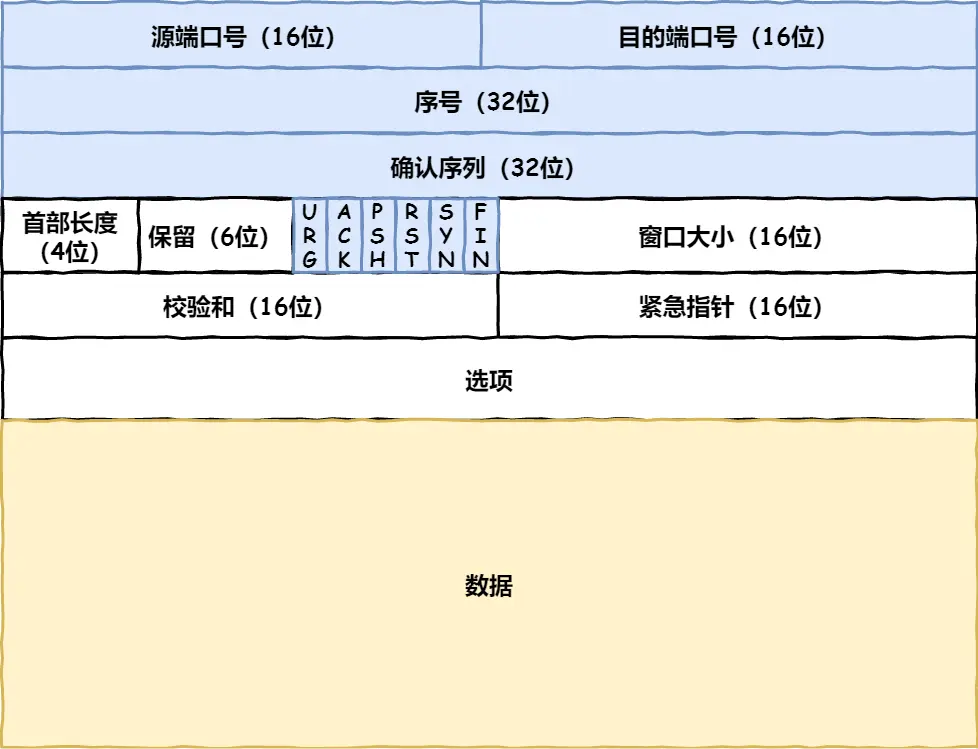
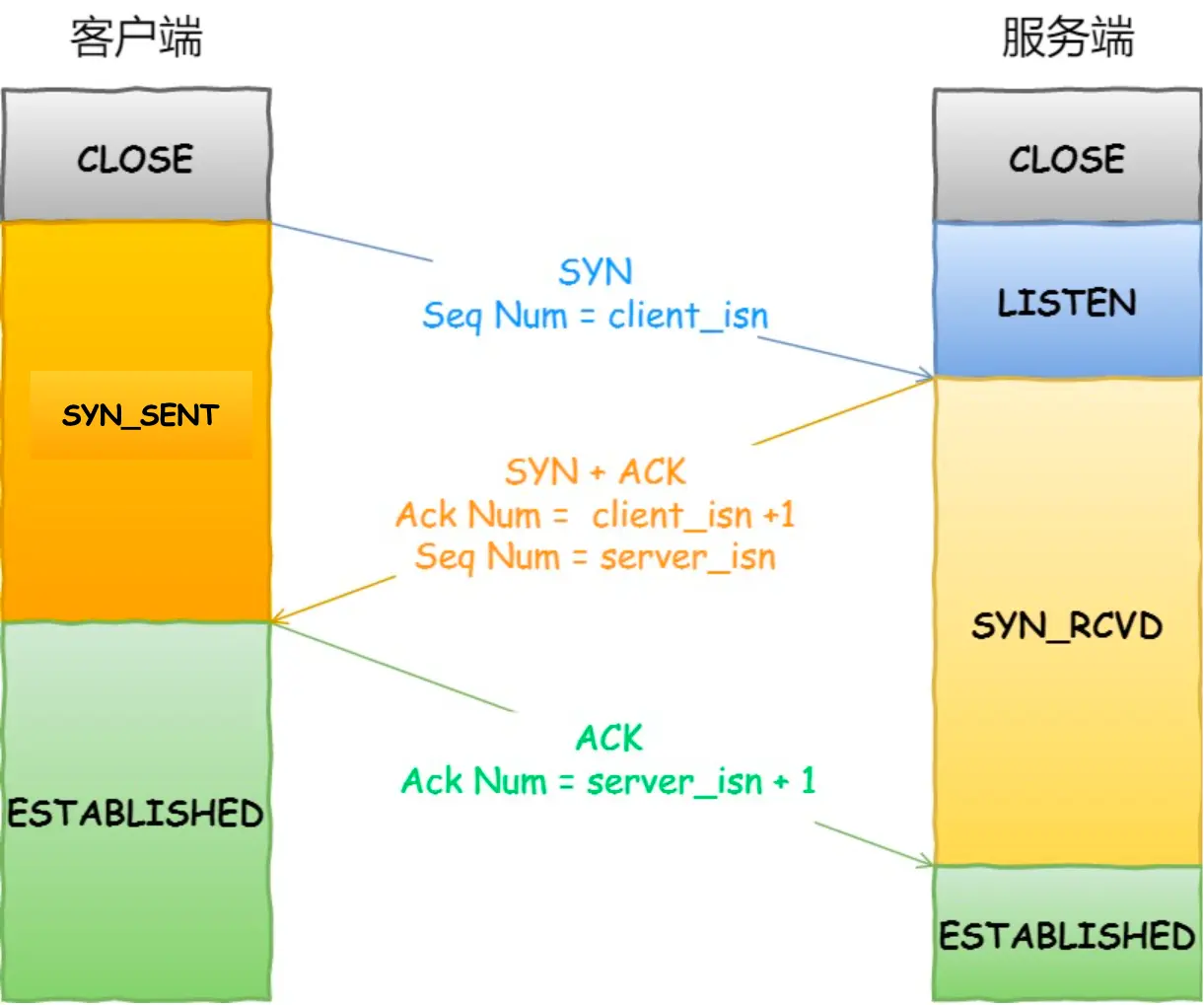
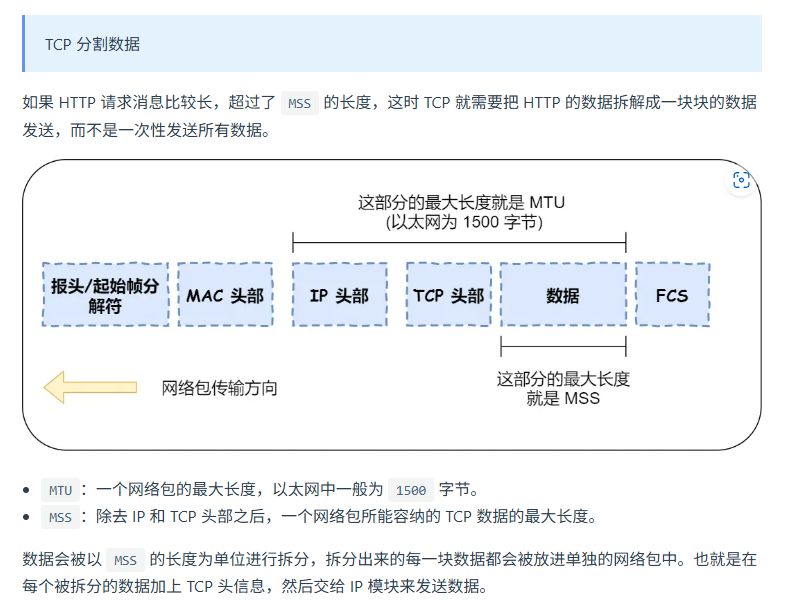 5. 遠程定位IP(網絡層)
5. 遠程定位IP(網絡層)
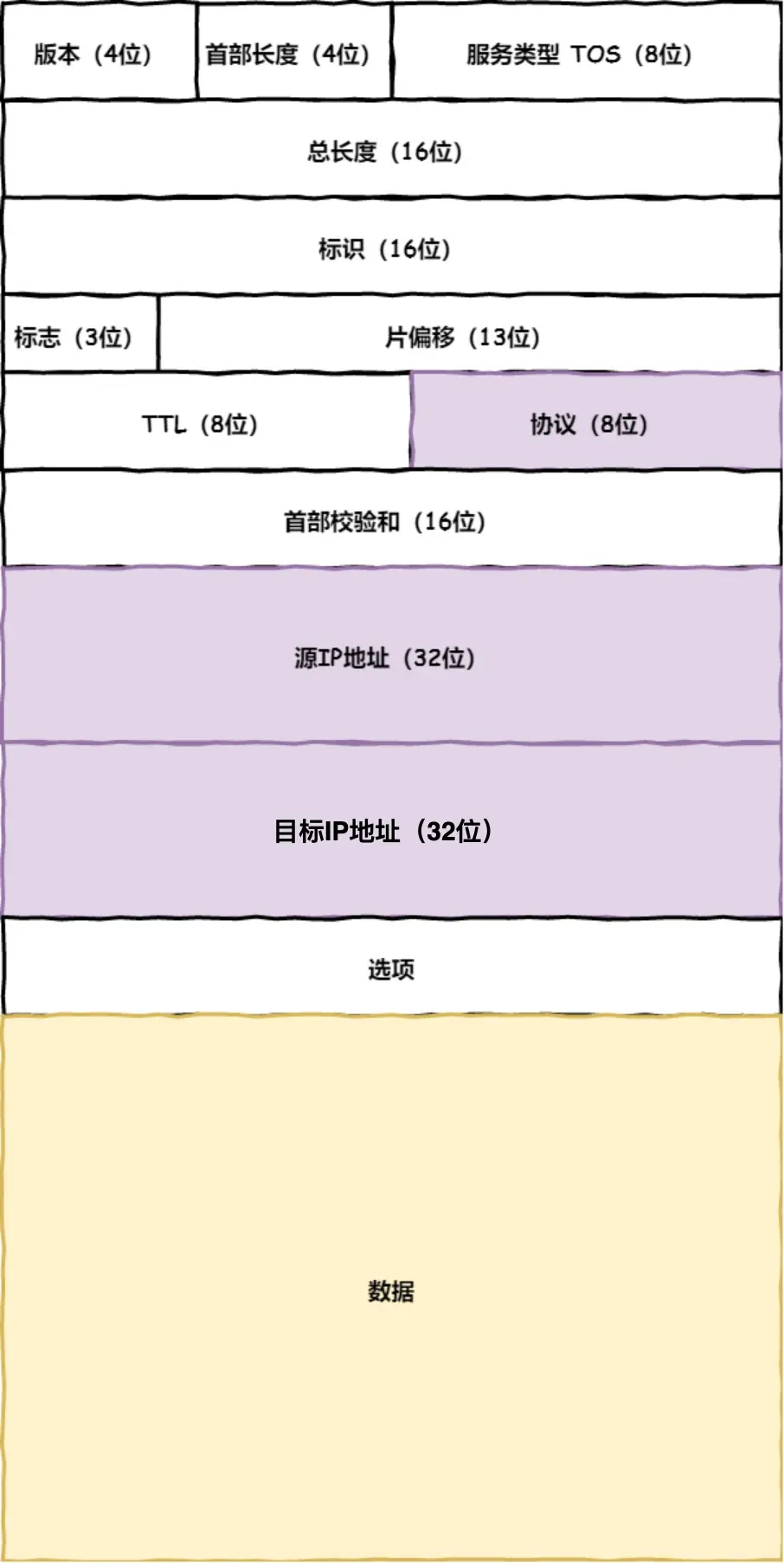
6. 兩點傳輸MAC(數據鏈路層)
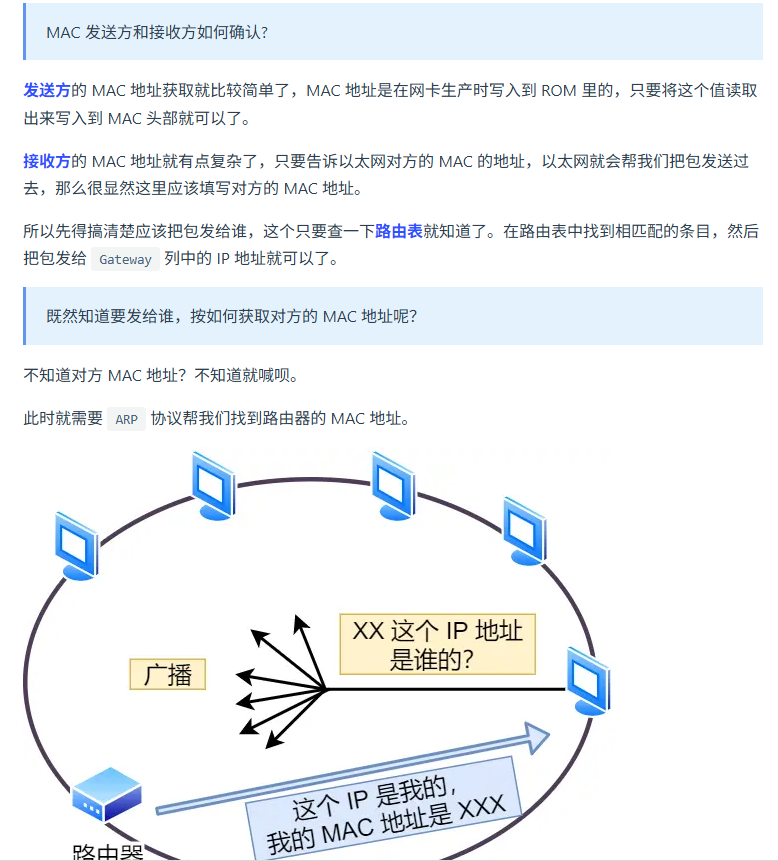
7. 網卡 網線

8. 交換機、路由器
KafKa
參考:https://blog.csdn.net/weixin_45366499/article/details/106943229
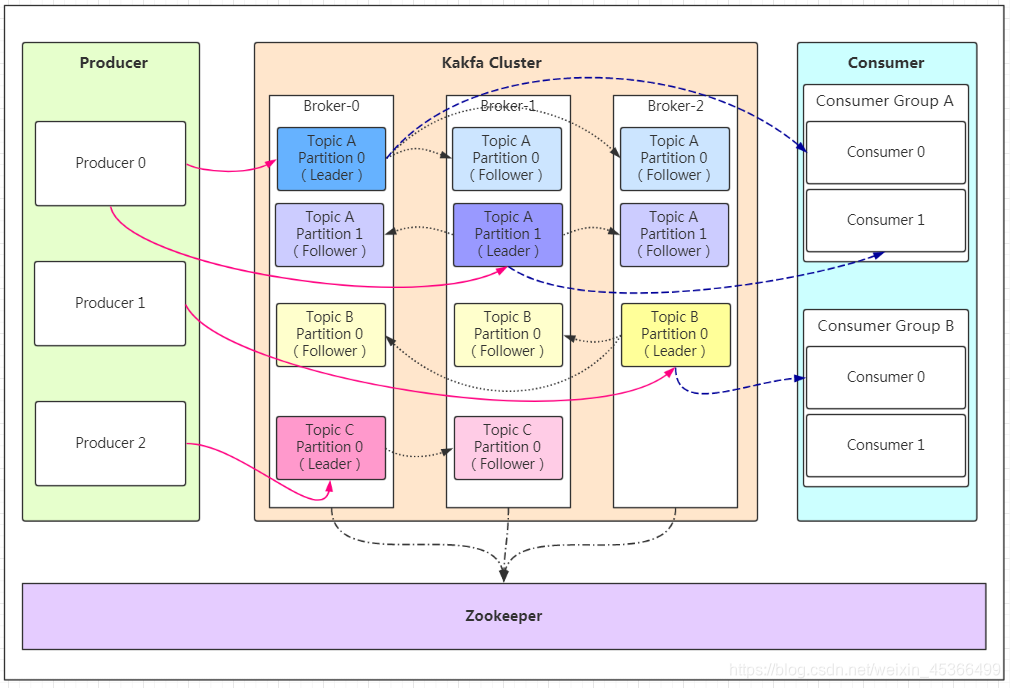
- Producer:Producer即生產者,消息的產生者,是消息的入口。
- Broker:Broker是kafka實例,每個服務器上有一個或多個kafka的實例,我們姑且認為每個broker對應一臺服務器。每個kafka集群內的broker都有一個不重復的編號,如圖中的broker-0、broker-1等……
- Topic:消息的主題,可以理解為消息的分類,kafka的數據就保存在topic。在每個broker上都可以創建多個topic。
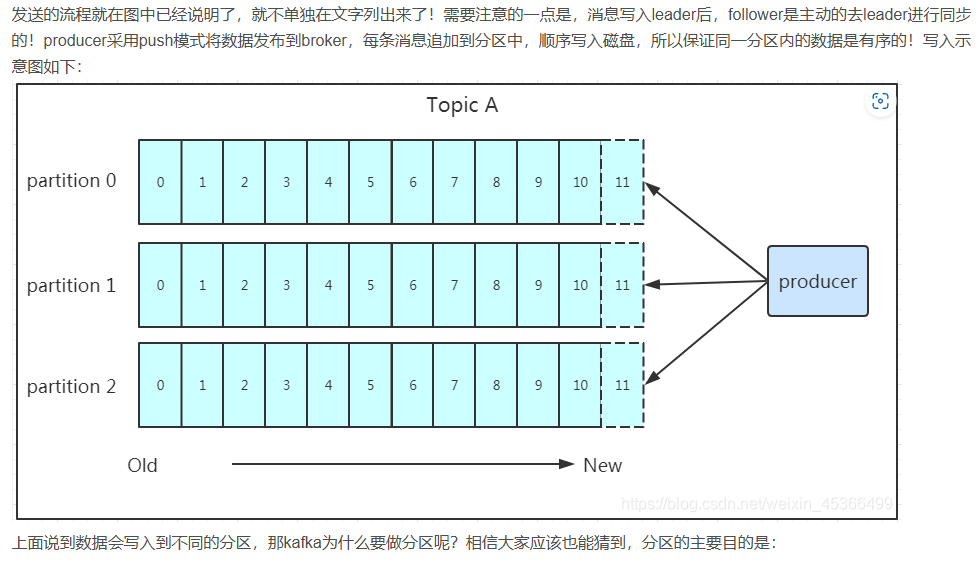
- Partition:Topic的分區,每個topic可以有多個分區,分區的作用是做負載,提高kafka的吞吐量。同一個topic在不同的分區的數據是不重復的,partition的表現形式就是一個一個的文件夾!
- Replication:每一個分區都有多個副本,副本的作用是做備胎。當主分區(Leader)故障的時候會選擇一個備胎(Follower)上位,成為Leader。在kafka中默認副本的最大數量是10個,且副本的數量不能大于Broker的數量,follower和leader絕對是在不同的機器,同一機器對同一個分區也只可能存放一個副本(包括自己)。
- Message:每一條發送的消息主體。
- Consumer:消費者,即消息的消費方,是消息的出口。
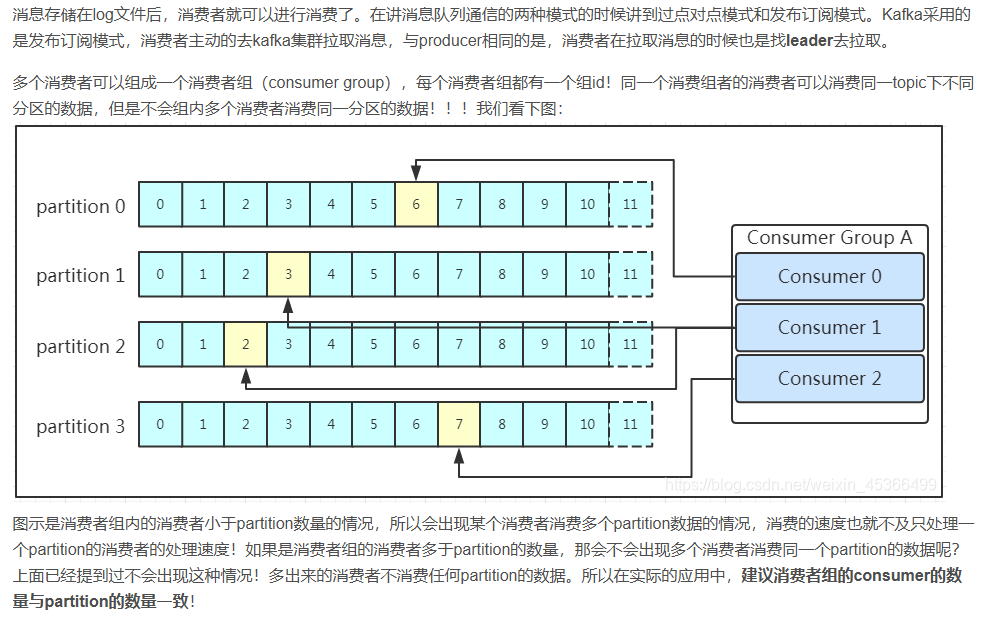
- Consumer Group:我們可以將多個消費組組成一個消費者組,在kafka的設計中同一個分區的數據只能被消費者組中的某一個消費者消費。同一個消費者組的消費者可以消費同一個topic的不同分區的數據,這也是為了提高kafka的吞吐量!
- Zookeeper:kafka集群依賴zookeeper來保存集群的的元信息,來保證系統的可用性。
發送數據
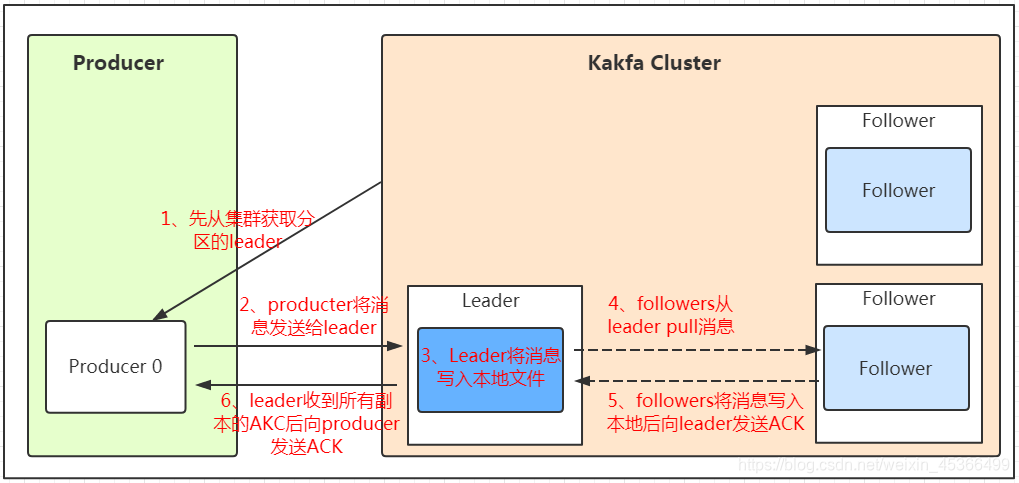

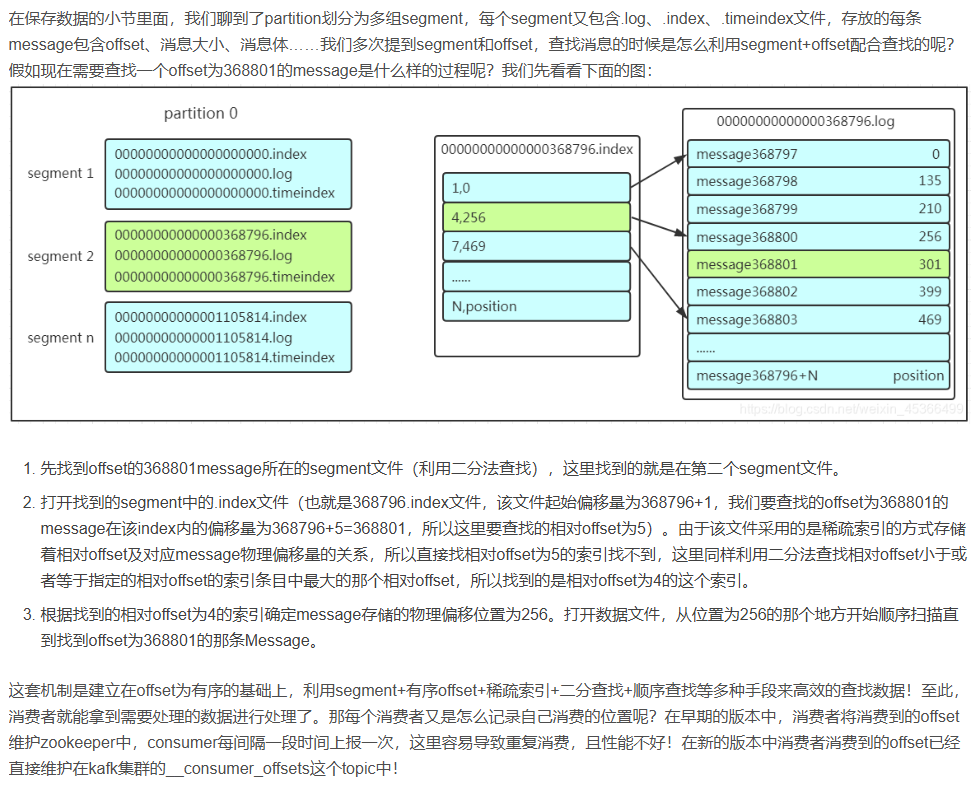
保存數據


消費數據


GMP
Go語言的GPM調度模型是Go運行時中用于處理并發的核心機制之一,它將Goroutine(輕量級線程)有效地映射到系統線程上,以最大化并發性能。GPM模型主要由三個部分組成:G(Goroutine)、P(Processor)、M(Machine)。讓我們逐一詳細介紹:
- G(Goroutine)
Goroutine 是Go語言中用于并發執行的輕量級線程,每個Goroutine都有自己的棧和上下文信息。
Goroutine相對于操作系統的線程更加輕量級,可以在同一時間內運行成千上萬的Goroutine。 - P(Processor)
P 是處理Goroutine的調度器的上下文,每個P包含一個本地運行隊列(Local Run Queue),用于存儲需要運行的Goroutine。
P的數量由GOMAXPROCS設置決定,它決定了并行執行的最大線程數。
P不僅管理Goroutine,還負責與M協作,將Goroutine分配給M執行。 - M(Machine)
M 代表操作系統的線程,負責執行Goroutine。一個M一次只能執行一個Goroutine。
M是實際執行代碼的工作單元,M與P綁定后才能執行Goroutine。
M可以通過調度器從全局運行隊列中拉取新的Goroutine,也可以與其他M協作完成工作。 - GPM模型的調度過程
調度器工作機制:Goroutine創建后會被放入P的本地隊列,P會從該隊列中選擇Goroutine,并將其分配給M執行。如果本地隊列為空,P可以從全局運行隊列或其他P的隊列中竊取任務。
工作竊取機制:如果一個P的本地隊列為空,而另一個P的本地隊列中有多個Goroutine,前者可以從后者中竊取任務,從而保持系統的高效利用率。
阻塞與調度**:當M執行的Goroutine阻塞(例如I/O操作)時,M會釋放當前的P并等待P重新分配任務,從而避免資源浪費。** - 模型優點
高效的并發調度:GPM模型使得Go語言可以高效地管理數百萬個Goroutine的并發執行。
可伸縮性:通過P與M的動態調度,GPM模型可以充分利用多核處理器的性能。
輕量級:Goroutine非常輕量,創建和切換的成本比系統線程要低得多。
P的核心作用
資源隔離與負載均衡
P作為邏輯“處理器”,負責管理本地Goroutine隊列(runq),使每個OS線程(M)綁定到一個P上工作。這種設計避免了全局隊列的鎖競爭,同時支持不同P之間通過工作竊取(Work Stealing)動態平衡負載。
多核利用率
P的數量默認等于CPU核心數,確保Goroutine能均勻分配到多個核心上執行。若去掉P,調度器將無法有效利用多核,可能退化為單線程或引發全局鎖爭用。
- 去掉P的后果
全局鎖競爭加劇
所有Goroutine必須通過全局隊列調度,多個M(OS線程)會頻繁爭奪同一把鎖,導致并發性能驟降(參考Go 1.0之前的調度器問題)。
調度效率降低
P的本地隊列減少了Goroutine的調度延遲。若去掉P,每次調度都需要訪問全局隊列,增加延遲和不確定性。
阻塞操作的協作困難
當Goroutine因系統調用阻塞時,P會解綁M并創建/復用新的M繼續運行其他Goroutine。若無P,阻塞操作可能導致線程長時間掛起,浪費資源。
GC
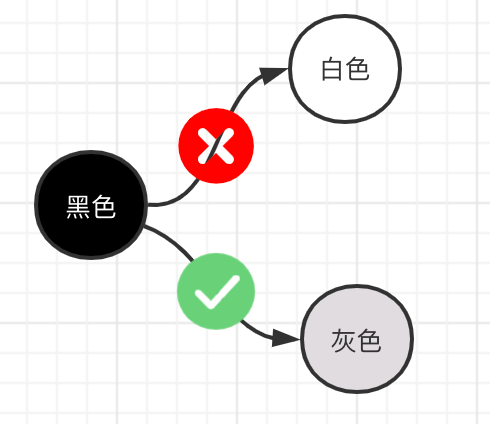
插入寫屏障:黑色對象引用的對象變為灰色(棧區不會觸發, stw+remark)

刪除寫屏障:刪除的對象如果為白色被標記為灰色(被刪除后即使沒有別的對象再引用他,也會活到下一輪)
混合寫屏障
GC期間,任何在棧上新創建的對象,均為黑色。
上面兩點只有一個目的,將棧上的可達對象全部標黑,最后無需對棧進行STW,就可以保證棧上的對象不會丟失。有人說,一直是黑色的對象,那么不就永遠清除不掉了么,這里強調一下,標記為黑色的是可達對象,不可達的對象一直會是白色,直到最后被回收。
堆上被刪除的對象標記為灰色
堆上新添加的對象標記為灰色
k個一組翻轉列表
https://leetcode.cn/problems/reverse-nodes-in-k-group/description/
/*** Definition for singly-linked list.* type ListNode struct {* Val int* Next *ListNode* }*/
func reverseKGroup(head *ListNode, k int) *ListNode {if head==nil{return nil}l,r := head, headroot := &ListNode{}rr := rootnum := 0for r!=nil{num++if num%k==0{tmp := r.Nextr.Next = nilrr.Next = reverse(l)rr = ll,r = tmp, tmp}else{r = r.Next}}rr.Next = lreturn root.Next
}
func reverse(head *ListNode) *ListNode{if head==nil || head.Next==nil{return head}l,r := head, head.Nextl.Next = nilfor r!=nil{tmp := r.Nextr.Next = ll = rr = tmp}return l
}
--樹)








)




可以通過 自定義事件 或 頁面引用 實現)




