
文章作者:
石強,鏡舟科技解決方案架構師
趙恒,StarRocks TSC Member
👉 加入 StarRocks x AI 技術討論社區 https://mp.weixin.qq.com/s/61WKxjHiB-pIwdItbRPnPA
RAG 和向量索引簡介
RAG(Retrieval-Augmented Generation,檢索增強生成)是一種結合外部知識檢索與 AI 生成的技術,彌補了傳統大模型知識靜態、易編造信息的缺陷,使回答更加準確且基于實時信息。
RAG 的核心流程
檢索(Retrieval)
-
用戶輸入問題后,RAG 從外部數據庫(如維基百科、企業文檔、科研論文等)檢索相關內容。
-
檢索工具可以是向量數據庫、搜索引擎或傳統數據庫。
生成(Generation)
-
將檢索到的相關信息與用戶輸入一起輸入生成模型(如 GPT、LLaMA 等),生成更準確的回答。
-
模型基于檢索內容“增強”輸出,而非僅依賴內部參數化知識。
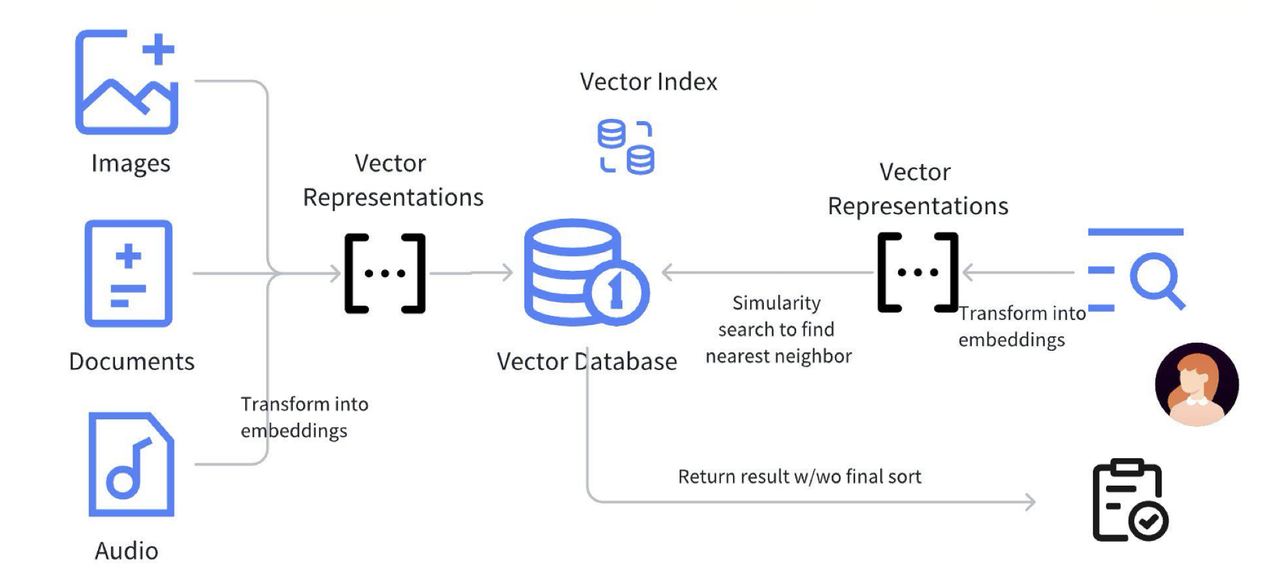
上圖展示了 RAG 的標準流程。首先,圖片、文檔、視頻和音頻等數據經過預處理,轉換為 Embedding 并存入向量數據庫。Embedding 通常是高維 float 數組,借助向量索引(如 HNSW、IVF)進行相似性搜索,加速高效檢索。
向量索引通過近似最近鄰(ANN)算法優化查詢效率,減少高維計算負擔。語義搜索匹配用戶問題與知識庫中的相關內容,使回答基于真實信息,從而降低大模型的“幻覺”風險,提升回答的自然性和可靠性。
關于向量檢索的更多介紹,可以參考 騰訊大數據基于 StarRocks 的向量檢索探索 這篇文章。這里不再展開說明。
StarRocks + DeepSeek 的典型 RAG 應用場景
DeepSeek 負責生成高質量 Embedding 和回答,StarRocks 提供實時高效的向量檢索,二者結合可構建更智能、更精準的 AI 解決方案。
企業級知識庫
適用場景:
-
企業內部知識庫(文檔搜索、FAQ)
-
法律、金融、醫藥等專業領域問答
-
代碼搜索、軟件開發文檔查詢
方案:
-
文檔嵌入(DeepSeek 負責): 將企業知識庫、FAQ、技術文檔等數據轉換為向量。
-
存儲+索引(StarRocks 負責): 使用 HNSW 或 IVFPQ 存儲向量存儲在 StarRocks 中,支持高效檢索。
-
檢索增強生成(RAG 負責): 用戶輸入問題 → DeepSeek 生成查詢向量 → StarRocks 進行向量匹配 → 返回相關文檔 → DeepSeek 結合文檔生成最終回答。
AI 客服與智能問答
適用場景:
-
智能客服(銀行、證券、電商)
-
法律、醫療等專業咨詢
-
技術支持自動問答
方案:
-
客戶對話日志嵌入(DeepSeek 負責): 訓練 LLM 處理用戶意圖,轉換歷史聊天記錄為向量。
-
存儲+索引(StarRocks 負責): 采用向量索引讓客服系統能夠高效查找相似案例。
-
檢索增強(RAG 負責): 結合歷史客服對話 + 知識庫 + DeepSeek LLM 生成答案。
示例流程:
-
用戶問:“我如何更改銀行卡預留手機號?”
-
StarRocks 檢索到 3 個最相似的客戶服務記錄
-
DeepSeek 結合這 3 條歷史記錄 + 預設 FAQ,生成精準回答
操作演示
系統組成
-
DeepSeek:提供文本向量化(embedding)和答案生成能力
-
StarRocks:高效存儲和檢索向量數據(3.4+版本支持向量索引)
實現流程:
| 步驟 | 負責組件 | 具體實現 |
| 1.環境準備 | Ollama StarRocks | 用 Ollama 在本地機器上便捷地部署和運行大型語言模型 |
| 2.數據向量化 | DeepSeek-Embedding | 文本 → 3584 維向量 |
| 3.存儲向量 | StarRocks | 創建表,存入向量 |
| 4.近似最近鄰搜索 | StarRocks 向量索引 | IVFPQ / HNSW 檢索 |
| 5.檢索增強 | 模擬 RAG 邏輯 | 結合檢索數據 |
| 6.生成答案 | DeepSeek LLM | 生成基于真實數據的回答 |
1.環境準備
1.1 DeepSeek 本地部署
Tips: 以下內容使用的是 macbook 進行 demo 演示
1.1.1 使用 ollama 安裝本地模型
在本地部署 DeepSeek 時,Ollama 主要起到模型管理和提供推理接口的作用,支持運行多個不同的 LLM,并允許用戶在本地切換和管理不同的模型。
-
下載 ollama:https://ollama.com/
-
安裝 deepseek-r1:7b
# 該命令會自動下載并加載模型ollama run deepseek-r1:7b

Tips: 如果想使用云端 LLM(如 DeepSeek 的官方 API),需要獲取并填寫 API Key
訪問 DeepSeek 官網(https://platform.deepseek.com)后注冊賬號并登錄;在儀表盤中創建 API Key(通常在 “API Keys” 或 “Developer” 部分),復制生成的密鑰(如 sk-xxxxxxxxxxxxxxxx)。
1.1.2 Deepseek 初步使用
啟動 deepseek
執行 ollama run deepseek-r1:7b 直接進入交互模式1.1.3 Deepseek 性能優化
直接在命令行設置參數:(參數單次生效)
OLLAMA_GPU_LAYERS=35 \OLLAMA_CPU_THREADS=6 \OLLAMA_BATCH_SIZE=128 \OLLAMA_CONTEXT_SIZE=4096 \ollama run deepseek-r1:7b
1.1.4 deepseek 使用

顯而易見:直接使用 deepseek 進行問答,返回的答案是不符合預期的,需要對知識進行修正
1.2 StarRocks 準備工作
1.2.1 集群部署
版本需求:3.4 及以上
1.2.2 配置設置
打開 vector index
ADMIN SET FRONTEND CONFIG ("enable_experimental_vector" = "true");1.2.3 建庫建表
建庫:
create database knowledge_base;建表:存儲知識庫向量
CREATE TABLE enterprise_knowledge (id BIGINT AUTO_INCREMENT,content TEXT NOT NULL,embedding ARRAY<FLOAT> NOT NULL,INDEX vec_idx (embedding) USING VECTOR ("index_type" = "hnsw","dim" = "3584","metric_type" = "l2_distance","M" = "16","efconstruction" = "40")
) ENGINE=OLAP
PRIMARY KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES ("replication_num" = "1");Tips: DeepSeek 的 deepseek-r1:7b 模型(7B 參數版本)默認生成高維嵌入向量,通常是 3584 維
2.將文本轉成向量
測試通過 deepseek 將文本轉為 3584 維向量
curl -X POST http://localhost:11434/api/embeddings -d '{"model": "deepseek-r1:7b", "prompt": "產品保修期是一年。"}'下面將轉化的向量數據保存在 StarRocks 中
3.知識存儲 (存儲向量到 StarRocks)
import pymysql
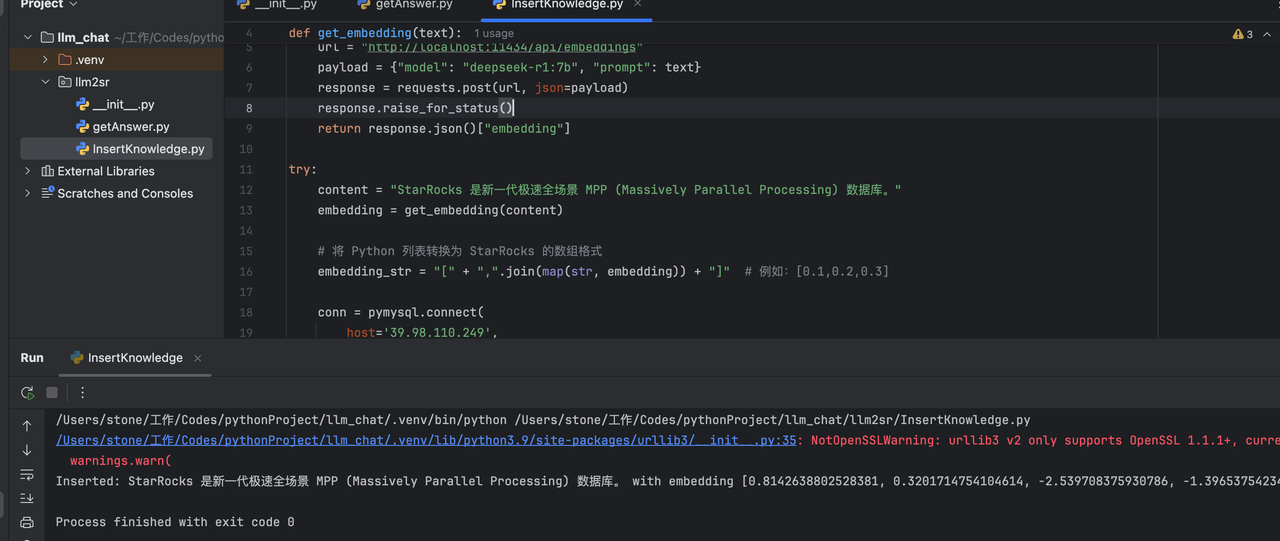
import requestsdef get_embedding(text):url = "http://localhost:11434/api/embeddings"payload = {"model": "deepseek-r1:7b", "prompt": text}response = requests.post(url, json=payload)response.raise_for_status()return response.json()["embedding"]try:content = "StarRocks 的愿景是能夠讓用戶的數據分析變得更加簡單和敏捷。"embedding = get_embedding(content)# 將 Python 列表轉換為 StarRocks 的數組格式embedding_str = "[" + ",".join(map(str, embedding)) + "]" # 例如:[0.1,0.2,0.3]conn = pymysql.connect(host='X.X.X.X',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()# 使用格式化的數組字符串sql = "INSERT INTO enterprise_knowledge (content, embedding) VALUES (%s, %s)"cursor.execute(sql, (content, embedding_str))conn.commit()print(f"Inserted: {content} with embedding {embedding[:5]}...")except requests.RequestException as e:print(f"Embedding API error: {e}")
except pymysql.Error as db_err:print(f"Database error: {db_err}")
finally:if 'cursor' in locals():cursor.close()if 'conn' in locals():conn.close()操作演示
4.知識提取 (檢索向量 & 輸出結果)
import pymysql
import requests# 獲取嵌入向量的函數
def get_embedding(text):url = "http://localhost:11434/api/embeddings"payload = {"model": "deepseek-r1:7b", "prompt": text}response = requests.post(url, json=payload)response.raise_for_status()return response.json()["embedding"]# 從 StarRocks 查詢相似內容的函數
def search_knowledge_base(query_embedding):try:conn = pymysql.connect(host='39.98.110.249',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()# 將查詢向量轉換為 StarRocks 的數組格式embedding_str = "[" + ",".join(map(str, query_embedding)) + "]"# 使用 L2 距離搜索最相似的記錄sql = """SELECT content, l2_distance(embedding, %s) AS distanceFROM enterprise_knowledgeORDER BY distance ASCLIMIT 1"""cursor.execute(sql, (embedding_str,))result = cursor.fetchone()if result:return result[0] # 返回最匹配的 contentelse:return "未找到相關信息。"except pymysql.Error as db_err:print(f"Database error: {db_err}")return "查詢失敗。"finally:if 'cursor' in locals():cursor.close()if 'conn' in locals():conn.close()# 主流程
try:query = "StarRocks 的愿景是什么?"query_embedding = get_embedding(query) # 將查詢轉化為向量answer = search_knowledge_base(query_embedding) # 從知識庫檢索答案print(f"問題: {query}")print(f"回答: {answer}")except requests.RequestException as e:print(f"Embedding API error: {e}")
except Exception as e:print(f"Error: {e}")執行效果

補充說明:到目前為止的流程僅依賴 StarRocks 進行向量檢索,未利用 DeepSeek LLM 進行生成,導致回答生硬且缺乏上下文整合,影響自然性和準確性。為提升效果,應引入 RAG 機制,使檢索結果與生成模型深度融合,從而優化回答質量并減少幻覺問題。
5.加入 RAG 增強
5.1 將查詢知識庫的結果,返回給 DeepSeek LLM ,優化回答質量
構造 RAG Prompt
def build_rag_prompt(query, retrieved_content):prompt = f"""[系統指令] 你是企業智能客服,基于以下知識回答用戶問題:[知識上下文] {retrieved_content}[用戶問題] {query}"""return prompt# 調用 DeepSeek 生成回答
def generate_answer(prompt):url = "http://localhost:11434/api/generate"payload = {"model": "deepseek-r1:7b", "prompt": prompt}try:response = requests.post(url, json=payload)response.raise_for_status()full_response = ""for line in response.text.splitlines():if line.strip(): # 過濾空行try:json_obj = json.loads(line)if "response" in json_obj:full_response += json_obj["response"] # 只提取答案if json_obj.get("done", False):breakexcept json.JSONDecodeError as e:print(f"JSON 解析錯誤: {e}, line: {line}")return clean_response(full_response.strip()) # 處理并去掉 <think>XXX</think>except requests.exceptions.RequestException as e:print(f"請求失敗: {e}")return "生成失敗。"5.2 創建 RAG 過程表:
用于記錄用戶問題、檢索結果和生成回答,保存上下文,方便進行長對話,至于長對話,用戶可自行探索。
customer_service_log 表建表語句如下:
CREATE TABLE customer_service_log (id BIGINT AUTO_INCREMENT,user_id VARCHAR(50),question TEXT NOT NULL,question_embedding ARRAY<FLOAT> NOT NULL,retrieved_content TEXT,generated_answer TEXT,timestamp DATETIME NOT NULL,feedback TINYINT DEFAULT NULL
) ENGINE=OLAP
PRIMARY KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES ("replication_num" = "1"
);6.優化后的版本
6.1 知識提取代碼
6.1.1 知識提取
import pymysql
import requests
import json
from datetime import datetime
import logging
import re# 獲取嵌入向量
def get_embedding(text):url = "http://localhost:11434/api/embeddings"payload = {"model": "deepseek-r1:7b", "prompt": text,"stream": "true"}response = requests.post(url, json=payload)response.raise_for_status()return response.json()["embedding"]# 從 StarRocks 檢索知識
def search_knowledge_base(query_embedding):try:conn = pymysql.connect(host='X.X.X.X',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()embedding_str = "[" + ",".join(map(str, query_embedding)) + "]"sql = """SELECT content, l2_distance(embedding, %s) AS distanceFROM enterprise_knowledgeORDER BY distance ASCLIMIT 3"""cursor.execute(sql, (embedding_str,))results=cursor.fetchall()content=""for result in results:content+=result[0]return contentexcept pymysql.Error as db_err:print(f"Database error: {db_err}")return "查詢失敗。"finally:cursor.close()conn.close()def build_rag_prompt(query, retrieved_content):prompt = f"""[系統指令] 你是企業智能客服,基于以下知識回答用戶問題:[知識上下文] {retrieved_content}[用戶問題] {query}"""return prompt# 調用 DeepSeek 生成回答
def generate_answer(prompt):url = "http://localhost:11434/api/generate"payload = {"model": "deepseek-r1:7b", "prompt": prompt}try:response = requests.post(url, json=payload)response.raise_for_status()full_response = ""for line in response.text.splitlines():if line.strip(): # 過濾空行try:json_obj = json.loads(line)if "response" in json_obj:full_response += json_obj["response"] # 只提取答案if json_obj.get("done", False):breakexcept json.JSONDecodeError as e:print(f"JSON 解析錯誤: {e}, line: {line}")return clean_response(full_response.strip()) # 處理并去掉 <think>XXX</think>except requests.exceptions.RequestException as e:print(f"請求失敗: {e}")return "生成失敗。"# 記錄對話日志
def log_conversation(user_id, question, question_embedding, retrieved_content, generated_answer):try:conn = pymysql.connect(host='X.X.X.X',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()embedding_str = "[" + ",".join(map(str, question_embedding)) + "]"sql = """INSERT INTO customer_service_log (user_id, question, question_embedding, retrieved_content, generated_answer, timestamp)VALUES (%s, %s, %s, %s, %s, NOW())"""cursor.execute(sql, (user_id, question, embedding_str, retrieved_content, generated_answer))conn.commit()except pymysql.Error as db_err:print(f"Database error: {db_err}")finally:cursor.close()conn.close()def clean_response(text):# 去掉所有 <think>xxx</think> 結構return re.sub(r"<think>.*?</think>", "", text, flags=re.DOTALL).strip()# 主流程
def rag_pipeline(user_id, query):try:logging.info(f"開始處理查詢: {query}")query_embedding = get_embedding(query)logging.info("獲取嵌入向量成功")retrieved_content = search_knowledge_base(query_embedding)logging.info(f"檢索到內容: {retrieved_content[:50]}...") # 只展示前50字符prompt = build_rag_prompt(query, retrieved_content)generated_answer = generate_answer(prompt)logging.info(f"生成回答: {generated_answer[:50]}...")log_conversation(user_id, query, query_embedding, retrieved_content, generated_answer)logging.info("日志記錄完成")return generated_answerexcept Exception as e:logging.error(f"發生錯誤: {e}", exc_info=True)return "處理失敗。"# 測試
if __name__ == '__main__':logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")user_id = "user123"query = "StarRocks 的愿景是什么?"answer = rag_pipeline(user_id, query)print(f"問題: {query}")print(f"回答: {answer}")6.1.2 操作演示

總結一下 RAG 增強后的執行流程:
輸入:用戶輸入問題
數據向量化:DeepSeek Embedding
StarRocks 向量索引,在 enterprise_knowledge 表中檢索最相似的知識
增強(Augmentation):將檢索結果與問題組合成 Prompt,傳遞給 DeepSeek
生成回答:調用 DeepSeek 生成增強后的回答
記錄日志:將問題、檢索結果和生成回答存入 customer_service_log
返回結果:將生成的回答返回給用戶
6.2 加上 web 可視化界面
<!DOCTYPE html>
<html lang="zh">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>智能問答客服系統</title><script>async function askQuestion() {let question = document.getElementById("question").value;let response = await fetch("/ask", {method: "POST",headers: {"Content-Type": "application/json"},body: JSON.stringify({ question: question })});let data = await response.json();document.getElementById("answer").innerText = data.answer;}</script>
</head>
<body><h1>智能問答客服系統</h1><input type="text" id="question" placeholder="請輸入您的問題"><button onclick="askQuestion()">提問</button><p id="answer"></p>
</body>
</html>6.3 完整問答后臺服務代碼
6.3.1 代碼結構如下
6.3.2 知識存儲代碼
import pymysql
import requestsdef get_embedding(text):url = "http://localhost:11434/api/embeddings"payload = {"model": "deepseek-r1:7b", "prompt": text}response = requests.post(url, json=payload)response.raise_for_status()return response.json()["embedding"]try:content = "StarRocks 的愿景是能夠讓用戶的數據分析變得更加簡單和敏捷。"embedding = get_embedding(content)# 將 Python 列表轉換為 StarRocks 的數組格式embedding_str = "[" + ",".join(map(str, embedding)) + "]" # 例如:[0.1,0.2,0.3]conn = pymysql.connect(host='X.X.X.X',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()# 使用格式化的數組字符串sql = "INSERT INTO enterprise_knowledge (content, embedding) VALUES (%s, %s)"cursor.execute(sql, (content, embedding_str))conn.commit()print(f"Inserted: {content} with embedding {embedding[:5]}...")except requests.RequestException as e:print(f"Embedding API error: {e}")
except pymysql.Error as db_err:print(f"Database error: {db_err}")
finally:if 'cursor' in locals():cursor.close()if 'conn' in locals():conn.close()6.3.3 知識提取
import pymysql
import requests
import json
import logging
import re
from flask import Flask, request, jsonify, render_templateapp = Flask(__name__)# 配置日志
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")# 獲取嵌入向量
def get_embedding(text):url = "http://localhost:11434/api/embeddings"payload = {"model": "deepseek-r1:7b", "prompt": text, "stream": "true"}response = requests.post(url, json=payload)response.raise_for_status()return response.json()["embedding"]# 從 StarRocks 檢索知識
def search_knowledge_base(query_embedding):try:conn = pymysql.connect(host='X.X.X.X',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()embedding_str = "[" + ",".join(map(str, query_embedding)) + "]"sql = """SELECT content, l2_distance(embedding, %s) AS distanceFROM enterprise_knowledgeORDER BY distance ASCLIMIT 3"""cursor.execute(sql, (embedding_str,))results=cursor.fetchall()content=""for result in results:content+=result[0]# result = cursor.fetchone()return contentexcept pymysql.Error as db_err:print(f"Database error: {db_err}")return "查詢失敗。"finally:cursor.close()conn.close()# 構造 RAG Prompt
def build_rag_prompt(query, retrieved_content):return f"""[系統指令] 你是企業智能客服,基于以下知識回答用戶問題:[知識上下文] {retrieved_content}[用戶問題] {query}"""# 調用 DeepSeek 生成回答
def generate_answer(prompt):url = "http://localhost:11434/api/generate"payload = {"model": "deepseek-r1:7b", "prompt": prompt}try:response = requests.post(url, json=payload)response.raise_for_status()full_response = ""for line in response.text.splitlines():if line.strip():try:json_obj = json.loads(line)if "response" in json_obj:full_response += json_obj["response"]if json_obj.get("done", False):breakexcept json.JSONDecodeError as e:logging.warning(f"JSON 解析錯誤: {e}, line: {line}")return clean_response(full_response.strip()) # 處理并去掉 <think>XXX</think>except requests.exceptions.RequestException as e:logging.error(f"請求失敗: {e}")return "生成失敗。"# 記錄對話日志
def log_conversation(user_id, question, question_embedding, retrieved_content, generated_answer):try:conn = pymysql.connect(host='X.X.X.X',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()embedding_str = "[" + ",".join(map(str, question_embedding)) + "]"sql = """INSERT INTO customer_service_log (user_id, question, question_embedding, retrieved_content, generated_answer, timestamp)VALUES (%s, %s, %s, %s, %s, NOW())"""cursor.execute(sql, (user_id, question, embedding_str, retrieved_content, generated_answer))conn.commit()except pymysql.Error as db_err:logging.error(f"數據庫錯誤: {db_err}")finally:cursor.close()conn.close()# 清理回答內容,去掉 <think>XXX</think>
def clean_response(text):return re.sub(r"<think>.*?</think>", "", text, flags=re.DOTALL).strip()# RAG 處理流程
def rag_pipeline(user_id,query):try:logging.info(f"開始處理查詢: {query}")query_embedding = get_embedding(query)logging.info("獲取嵌入向量成功")retrieved_content = search_knowledge_base(query_embedding)logging.info(f"檢索到內容: {retrieved_content[:50]}...") # 只展示前50字符prompt = build_rag_prompt(query, retrieved_content)generated_answer = generate_answer(prompt)logging.info(f"生成回答: {generated_answer[:50]}...")log_conversation(user_id, query, query_embedding, retrieved_content, generated_answer)logging.info("日志記錄完成")return generated_answerexcept Exception as e:logging.error(f"發生錯誤: {e}", exc_info=True)return "處理失敗。"# Flask API
@app.route("/")
def index():return render_template("index.html") # 渲染前端頁面@app.route("/ask", methods=["POST"])
def ask():user_id="sr_01"data = request.jsonquestion = data.get("question", "")result=rag_pipeline(user_id,question)answer = f"問題:{question}。\n 回答:{result}"return jsonify({"answer": answer})if __name__ == "__main__":user_id = "sr"app.run(host="0.0.0.0", port=9033, debug=True)6.3.4 效果演示


參考文檔:
Deepseek 搭建:https://zhuanlan.zhihu.com/p/20803691410
Vector index 資料:https://docs.starrocks.io/zh/docs/table_design/indexes/vector_index/
StarRocks AI 共創計劃:讓數據分析更智能!
AI 時代已來,StarRocks 正在加速進化!我們誠邀社區開發者、數據工程師和 AI 愛好者一起探索 “AI + 數據分析” 的無限可能。無論你是擅長算法優化、應用落地,還是熱愛技術布道,這里都有你的舞臺!
🌟 你的貢獻,能讓 StarRocks 更強大!我們期待你在以下方向大展身手:
AI 增強分析:用 LLM、RAG 優化查詢、智能 SQL 生成、自然語言交互
工具 & 插件:開發 AI 擴展、模型集成、自動化運維方案
實戰案例:分享你的 AI+StarRocks 應用 Demo(附代碼/視頻更佳!)
🎁 豐厚獎勵
Top 10 優秀貢獻者將獲得 StarRocks 社區榮譽 + 2000 積分獎勵(詳情參考 StarRocks 布道師計劃)
優秀項目有機會被官方推薦,并整合進 StarRocks 生態
📢 立即行動!👉 在社區論壇分享你的創意或 AI 實踐:https://forum.mirrorship.cn/


配置和使用)
)

)


:Java - List、Set、Map)






![[工具]Java xml 轉 Json](http://pic.xiahunao.cn/[工具]Java xml 轉 Json)



