最近終于徹底搞懂了Evidential Deep Learning,之前有很多看不是特別明白的地方,原來是和證據理論教材(是的,不只是國內老師寫的,和國外的老師寫的教材出入也比較大)的說法有很多不一樣,所以特地寫了這一篇來做一下筆記。
證據理論做模式識別的話第一件事是構建辨識框架(FoD)及其冪集,第二件事是寫基本概率指派,基本概率指派就是一個函數,名為BPA或mass函數。ENN這里構建FoD及其冪集和證據理論的做法是一樣的,但是注意ENN所構建的mass函數是由這樣的二元組構成的:
< b , u > : ∑ i = 1 K b i + u = 1 <\mathbf{b},u>:\sum_{i=1}^{K}b_i+u=1 <b,u>:i=1∑K?bi?+u=1
其中 b = { b 1 , . . . , b K } \mathbf{b}=\{b_1,...,b_K\} b={b1?,...,bK?}是 K K K類目標的belief, u u u是uncertainty。需要注意的是如果按照我們國內證據理論的教材的話,其實 b \mathbf{b} b和 u u u都是belief,只不過 b \mathbf{b} b是賦予給單子集的belief, u u u是賦予給FoD的belief(然后呢,賦予給FoD的belief的語義是“我只知道待測樣本在這些目標之間,但是具體是哪一個我不知道”的belief,這確實是一種uncertainty,但這只是證據理論所建模的uncertainty的一種),從國內證據理論教材的角度來講,ENN還需要對介于單子集和FoD之間的那一部分假設賦予belief,但是ENN選擇了直接賦為0的操作,這種操作是可以的,但是也應該要說明一下的,文章的話是直接把這塊省略了。
第二個就是NN的輸出是 e i e_i ei?,然后有了 e i e_i ei?那么上面的 b i = e i / S b_i=e_i/S bi?=ei?/S, S = ( ∑ i = 1 K e i ) + K S=(\sum_{i=1}^{K}e_i)+K S=(∑i=1K?ei?)+K就可以算了,文章里面把這個 e i e_i ei?叫證據evidence,但是我覺得這么叫其實是有誤導作用的。正常來講,證據理論里面的一條證據evidence,也可以叫一個證據體a body of evidence,其實是說一個基本概率指派函數,也就是一個mass函數,然后全體mass函數的集合構成了全體證據。
另外知乎上還有人問這個圖咋來的。配套的文字是在我們的第一組評估中,我們使用相同的LeNet架構在MNIST訓練集上訓練模型,并在包含字母(而非數字)的notMNIST數據集上進行測試。因此,我們期望得到最大熵(即不確定性)的預測。在圖3的左面板中,我們展示了所有使用MNIST數據集訓練的模型在可能熵范圍[0, log(10)]內的經驗累積分布函數(CDF)。圖中越接近右下角(即熵值越大)的曲線越理想,這表明所有預測都具有最大熵[24]。顯然,我們模型的不確定性估計明顯優于基線方法。
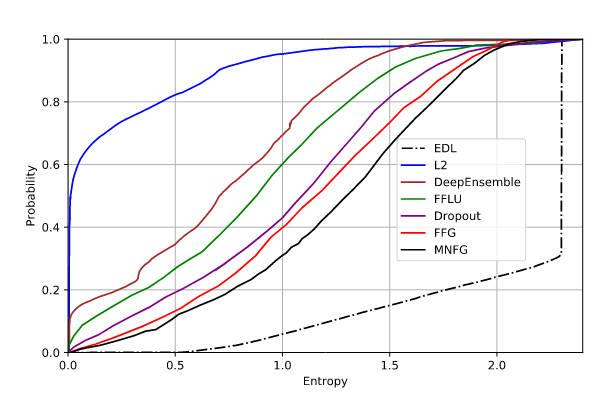
MNIST就是手寫數據集,一共有10個類,所以范圍是[0,log10]。我們知道證據理論里面只知道證據是沒法解讀的,必須把證據里面的 < b , u > <\mathbf{b},u> <b,u>轉譯成概率分布才可以。一般來說,證據理論的話最經典的會用Pignistic Transformation完成這個任務,但是這篇論文呢沒用,它直接用 p i = α i / S p_i = \alpha_i/S pi?=αi?/S, α i = e i + 1 \alpha_i=e_i+1 αi?=ei?+1這么做的。有了 p i p_i pi?,不就有了NN預測的概率了嘛,然后就可以算熵了。這篇基本可以肯定用的是Shannon 熵,而不是證據理論里面的那些熵。就是不知道為什么,ENN的結果里不確定性都這么大。像作者所說的“圖中越接近右下角(即熵值越大)的曲線越理想”更是讓人覺得費解。。

)


:Java - List、Set、Map)






![[工具]Java xml 轉 Json](http://pic.xiahunao.cn/[工具]Java xml 轉 Json)




)
等級考試試卷(五級)真題)

