目錄
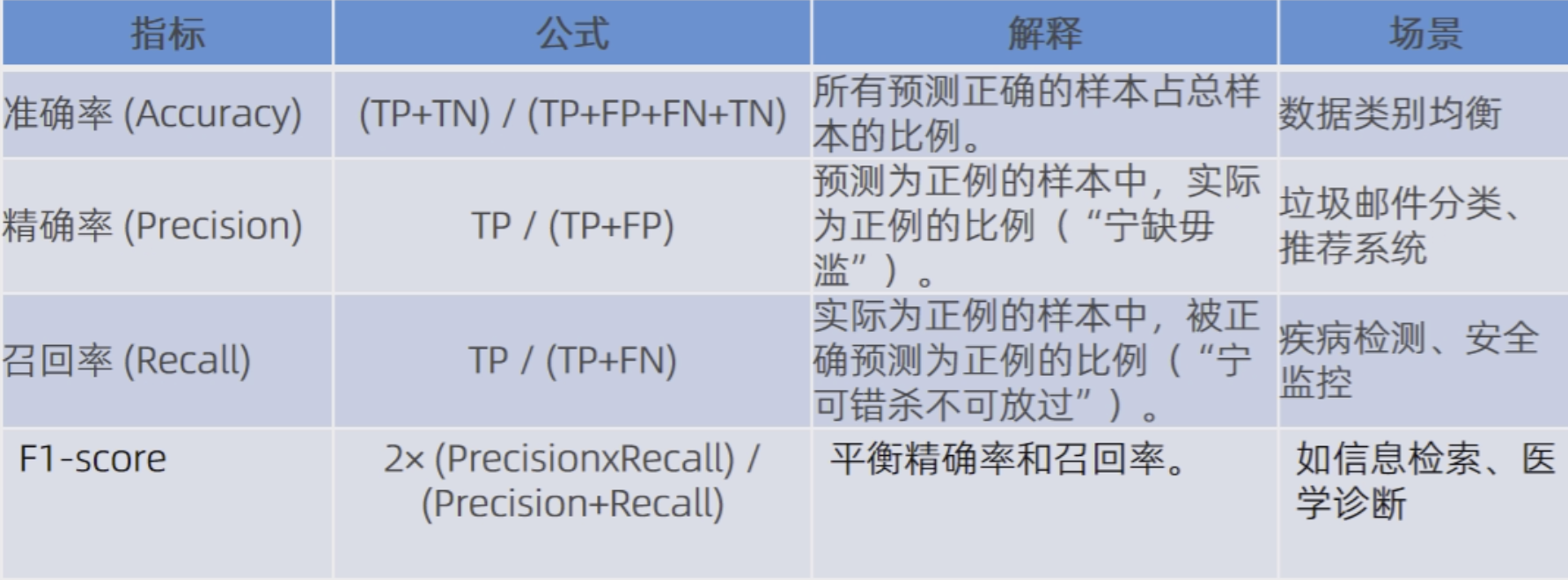
常見指標
其他的評估指標
3.1 BLEU
3.2 ROUGE
3.3 困惑度PPL(perplexity)
常見指標
其他的評估指標
3.1 BLEU
BLEU(Bilingual Evaluation Understudy,雙語評估替補)分數是評估一種語言翻譯成另一種語言的文本質量的指標。它將“質量”的好壞定義為與人類翻譯結果的一致性程度。
BLEU是一種廣泛用于評估機器翻譯和文本生成任務的自動評價指標,它通過比較生成文本(Candidate)和參考文本(Reference)之間的n-gram重疊程度,量化生成質量。
BLEU算法實際上就是在判斷兩個句子的相似程度. BLEU 的分數取值范圍是 0~1,分數越接近1,說明翻譯的質量越高。
BLEU有許多變種,根據n-gram可以劃分成多種評價指標,常見的評價指標有BLEU-1、BLEU-2、BLEU-3、BLEU-4四種,其中n-gram指的是連續的單詞個數為n,BLEU-1衡量的是單詞級別的準確性,更高階的BLEU可以衡量句子的流暢性.實踐中,通常是取N=1~4,然后對進行加權平均。
下面舉例說計算過程:
-
基本步驟:
-
分別計算預測文本candidate和目標文本reference的N-gram模型,然后統計其匹配的個數,計算匹配度
-
公式
-
BLEU-N = (Σ Count_match(N-gram)) / (Σ Count(N-gram in candidate))
-
candidate和reference中匹配的 n?gram 的個數 / candidate中 n?gram 的個數.
-
-
-
假設分別給出一個預測文本和目標文本如下:
預測文本: It is a nice day today 目標文本: today is a nice day
-
使用1-gram進行匹配
預測文本: {it, is, a, nice, day, today}
目標文本: {today, is, a, nice, day}
?
結果:其中{today, is, a, nice, day}匹配,所以匹配度為5/6
-
使用2-gram進行匹配
預測文本: {it is, is a, a nice, nice day, day today}
目標文本: {today is, is a, a nice, nice day}
?
結果:其中{is a, a nice, nice day}匹配,所以匹配度為3/5
-
使用3-gram進行匹配
預測文本: {it is a, is a nice, a nice day, nice day today}
目標文本: {today is a, is a nice, a nice day}
?
結果:其中{is a nice, a nice day}匹配,所以匹配度為2/4
-
使用4-gram進行匹配
預測文本: {it is a nice, is a nice day, a nice day today}
目標文本: {today is a nice, is a nice day}
?
結果:其中{is a nice day}匹配,所以匹配度為1/3
上述例子會出現一種極端情況,請看下面示例:
預測文本: the the the the 目標文本: The cat is standing on the ground 如果按照1-gram的方法進行匹配,則匹配度為1,顯然是不合理的,所以計算某個詞的出現次數進行改進
-
將計算某個詞正確預測次數的方法改為計算某個詞在文本中出現的最小次數,如下所示的公式:
-
其中$k$表示在預測文本中出現的第$k$個詞語, $c_k$則代表在預測文本中這個詞語出現的次數,而$s_k$則代表在目標文本中這個詞語出現的次數。
python代碼實現:
BLEU計算公式:

BLEU 評分范圍
BLEU 分數范圍:0 ~ 1(通常用 0 ~ 100 表示)
一般理解:
BLEU 分數 質量 90 - 100 幾乎完美 70 - 90 高質量 50 - 70 可接受 30 - 50 勉強可用 0 - 30 低質量
# 第一步安裝nltk的包-->pip install nltk
from nltk.translate.bleu_score import sentence_bleudef cumulative_bleu(reference, candidate):# 指標計算:p1^w1*p2^w2 =0.6^0.5*0.25^0.5 = 0.387# math.exp(0.5 * math.log(0.6) + 0.5 * math.log(0.25)) =# math.exp(0.5*math.log(0.15)) = math.exp(math.log(0.15)^0.5) = 0.15^0.5 = 0.387bleu_1_gram = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0))bleu_2_gram = sentence_bleu(reference, candidate, weights=(0.5, 0.5, 0, 0))bleu_3_gram = sentence_bleu(reference, candidate, weights=(0.33, 0.33, 0.33, 0))bleu_4_gram = sentence_bleu(reference, candidate, weights=(0.25, 0.25, 0.25, 0.25))# print('bleu 1-gram: %f' % bleu_1_gram)# print('bleu 2-gram: %f' % bleu_2_gram)# print('bleu 3-gram: %f' % bleu_3_gram)# print('bleu 4-gram: %f' % bleu_4_gram)return bleu_1_gram, bleu_2_gram, bleu_3_gram, bleu_4_gram# 預測文本
candidate_text = ["This", "is", "some", "generated", "text"]# 目標文本列表
reference_texts = [["This", "is", "a", "reference", "text"],["This", "is", "another", "reference", "text"]]# 計算 Bleu 指標
c_bleu = cumulative_bleu(reference_texts, candidate_text)# 打印結果print("The Bleu score is:", c_bleu)
# The Bleu score is: (0.6, 0.387, 1.5949011744633917e-102, 9.283142785759642e-155)3.2 ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)指標是在機器翻譯、自動摘要、問答生成等領域常見的評估指標。ROUGE通過將模型生成的摘要或者回答與參考答案(一般是人工生成的)進行比較計算,得到對應的得分,專門用于衡量自動生成文本與人工參考文本之間的相似度。
ROUGE指標與BLEU指標非常類似,均可用來衡量生成結果和標準結果的匹配程度,不同的是ROUGE基于召回率,BLEU更看重準確率。
ROUGE分為四種方法:ROUGE-N, ROUGE-L, ROUGE-W, ROUGE-S.
下面舉例說計算過程(這里只介紹ROUGE-N):
-
計算公式:ROUGE-N = (Σ Count_match(N-gram)) / (Σ Count(N-gram in reference))
-
基本步驟:Rouge-N實際上是將模型生成的結果和標準結果按N-gram拆分后,計算召回率
-
假設模型預測文本和一個目標文本如下:
預測文本: It is a nice day today 目標文本: Today is a nice day
-
使用ROUGE-1進行匹配
預測文本: {it, is, a, nice, day, today}
目標文本: {today, is, a, nice, day}
結果::其中{today, is, a, nice, day}匹配,所以匹配度為5/5=1,這說明生成的內容完全覆蓋了參考文本中的所有單詞,質量較高。
-
通過類似的方法,可以計算出其他ROUGE指標(如ROUGE-2、ROUGE-L、ROUGE-S)的評分,從而綜合評估系統生成的文本質量。
python代碼實現:
# 第一步:安裝rouge-->pip install rouge
from rouge import Rouge# 預測文本
generated_text = "This is some generated text."# 目標文本列表
reference_texts = ["This is a reference text.", "This is another generated reference text."]# 計算 ROUGE 指標
rouge = Rouge()
scores = rouge.get_scores(generated_text, reference_texts[1])# 打印結果
print("ROUGE-1 precision:", scores[0]["rouge-1"]["p"])
print("ROUGE-1 recall:", scores[0]["rouge-1"]["r"])
print("ROUGE-1 F1 score:", scores[0]["rouge-1"]["f"])
# ROUGE-1 precision: 0.8
# ROUGE-1 recall: 0.6666666666666666
# ROUGE-1 F1 score: 0.72727272231404963.3 困惑度PPL(perplexity)
PPL用來度量一個概率分布或概率模型預測樣本的好壞程度。PPL表示模型在預測下一個詞時的“平均不確定性”,可以理解為模型需要“猜測多少次才能正確預測下一個詞”。
PPL基本思想:
-
給測試集的句子賦予較高概率值的語言模型較好,當語言模型訓練完之后,測試集中的句子都是正常的句子,那么訓練好的模型就是在測試集上的概率越高越好.
-
基本公式(兩種方式):
?
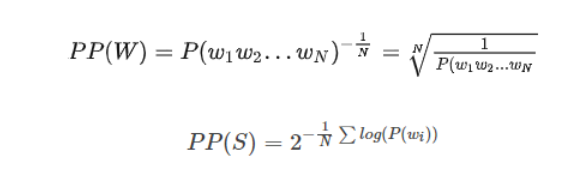
??
?
-
由公式可知,句子概率越大,語言模型越好,困惑度越小。
import math# 定義語料庫
sentences = [['I', 'have', 'a', 'pen'],['He', 'has', 'a', 'book'],['She', 'has', 'a', 'cat']
]
# 定義語言模型
unigram = {'I': 1 / 12,'have': 1 / 12,'a': 3 / 12,'pen': 1 / 12,'He': 1 / 12,'has': 2 / 12,'book': 1 / 12,'She': 1 / 12,'cat': 1 / 12
}
# 初始化困惑度為0
perplexity = 0
# 循環遍歷語料庫
for sentence in sentences:# 計算句子的概率, 句子概率等于所有單詞的概率相乘sentence_prob = 1# 循環遍歷句子中的每個單詞for word in sentence:# 計算單詞的概率并累乘, 得到句子的概率sentence_prob *= unigram[word]# -1/N * log(P(W1W2...Wn))temp = -math.log(sentence_prob, 2) / len(sentence)# 累加句子的困惑度perplexity += 2 ** temp
# 計算困惑度 2**(-1/N * log(P(W1W2...Wn)))
perplexity = perplexity / len(sentences)
print('困惑度為:', perplexity)
# 困惑度為:8.15


)

,側重點會有所不同。看看Deepseek的建議)












)
