1. LSTM 時間序列預測
LSTM 是 RNN(Recurrent Neural Network)的一種變體,它解決了普通 RNN 訓練時的梯度消失和梯度爆炸問題,適用于長期依賴的時間序列建模。
LSTM 結構
LSTM 由 輸入門(Input Gate)、遺忘門(Forget Gate)、輸出門(Output Gate) 以及 細胞狀態(Cell State) 組成。
LSTM 數學公式
對于給定的時間步 ,LSTM 的計算公式如下:
1. 遺忘門(Forget Gate):決定哪些信息應該被遺忘
其中:
- :遺忘門的激活值(取值在 之間)
- 、:可學習參數
- :上一個時間步的隱藏狀態
- :當前時間步的輸入
- 為 Sigmoid 激活函數
2. 輸入門(Input Gate):決定哪些新信息需要加入到細胞狀態
- 是輸入門的激活值
- 是候選細胞狀態的更新
3. 更新細胞狀態(Cell State):結合舊狀態和新信息
其中 表示逐元素相乘。
4. 輸出門(Output Gate)和隱藏狀態更新
其中:
- 是輸出門的激活值
- 是 LSTM 單元的最終輸出
2. LightGBM 在時間序列預測中的原理
LightGBM 是基于梯度提升決策樹(GBDT)的高效實現,能夠在高維數據上快速訓練,同時保留決策樹模型的可解釋性。
LightGBM 基本公式
LightGBM 的目標是最小化損失函數 ,通常使用平方誤差:
其中:
- 是真實值
- 是模型預測值
- 是樣本數量
梯度提升決策樹(GBDT)采用加法模型進行學習:
其中:
- 是第 輪迭代的模型
- 是當前輪學習的弱分類器(決策樹)
- 是學習率
3. 結合 LSTM 和 LightGBM 高維時序預測
由于 LSTM 適用于處理時間序列依賴,而 LightGBM 擅長學習復雜特征,因此可以采用 LSTM + LightGBM的組合方式:
方案 1:LSTM 作為特征提取器,LightGBM 進行最終預測
1. 使用 LSTM 處理時間序列,得到高維特征表示
- 通過 LSTM 提取隱藏狀態 作為特征:
2. 利用 LightGBM 進行最終預測
- 訓練 LightGBM 使用 LSTM 提取的特征進行回歸:
方案 2:LSTM 進行短期預測,LightGBM 進行長期趨勢建模
-
短期預測(LSTM):
- 采用 LSTM 直接預測短期趨勢
- 目標:預測下一時間步的值
-
長期預測(LightGBM):
- 結合 LSTM 輸出和額外的時間序列特征(如趨勢、周期性等)進行預測
- 目標:提高長期預測能力
其中:
- 是 LSTM 預測值
- 是 LightGBM 預測值
- 是加權系數,可通過交叉驗證優化
總之呢,LSTM 適合提取時間序列的長期依賴關系,而 LightGBM 能夠處理高維特征并進行快速預測。兩者結合可以充分利用 LSTM 的時序建模能力和 LightGBM 的高維特征學習能力,在高維時間序列預測任務中取得更好的效果。
完整案例
這個任務涉及 LSTM(長短時記憶網絡) 和 LightGBM(梯度提升樹模型) 結合進行高維時間序列預測。
整個代碼的流程包括:
-
數據生成:模擬一個具有多個特征的時間序列數據集。
-
特征工程:數據預處理,構建 LSTM 和 LightGBM 需要的特征。
-
模型訓練:
- 先用 LSTM 學習時間序列特征,提取特征后傳入 LightGBM。
- 使用 LightGBM 進行最終的時間序列預測。
-
結果可視化:
- 繪制 時間序列趨勢
- 繪制 LSTM 訓練損失曲線
- 繪制 LightGBM 特征重要性
- 繪制 預測結果與真實值對比
-
超參數調優:
- LSTM 網絡結構優化
- LightGBM 參數調優
- 結合貝葉斯優化調整超參數
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import lightgbm as lgb
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, mean_squared_error# 1. 生成虛擬時間序列數據
np.random.seed(42)
days = 500
date_rng = pd.date_range(start='1/1/2020', periods=days, freq='D')
data = {'date': date_rng,'feature1': np.sin(np.linspace(0, 50, days)) + np.random.normal(scale=0.1, size=days),'feature2': np.cos(np.linspace(0, 50, days)) + np.random.normal(scale=0.1, size=days),'target': np.sin(np.linspace(0, 50, days)) + 0.5 * np.cos(np.linspace(0, 50, days)) + np.random.normal(scale=0.1, size=days)
}
df = pd.DataFrame(data)# 2. 數據預處理
scaler = MinMaxScaler()
df[['feature1', 'feature2', 'target']] = scaler.fit_transform(df[['feature1', 'feature2', 'target']])# 3. 構造時間序列數據集
seq_length = 10
X, y = [], []
for i in range(len(df) - seq_length):X.append(df[['feature1', 'feature2']].iloc[i:i+seq_length].values)y.append(df['target'].iloc[i+seq_length])
X, y = np.array(X), np.array(y)# 4. 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)# 5. LSTM 模型定義
class LSTMModel(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim, num_layers):super(LSTMModel, self).__init__()self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, x):lstm_out, _ = self.lstm(x)return self.fc(lstm_out[:, -1, :])# 6. 訓練 LSTM
input_dim = 2
hidden_dim = 64
output_dim = 1
num_layers = 2device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
lstm_model = LSTMModel(input_dim, hidden_dim, output_dim, num_layers).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(lstm_model.parameters(), lr=0.001)X_train_torch = torch.tensor(X_train, dtype=torch.float32).to(device)
y_train_torch = torch.tensor(y_train, dtype=torch.float32).to(device)
X_test_torch = torch.tensor(X_test, dtype=torch.float32).to(device)
y_test_torch = torch.tensor(y_test, dtype=torch.float32).to(device)# 訓練循環
epochs = 100
train_losses = []
for epoch in range(epochs):lstm_model.train()optimizer.zero_grad()output = lstm_model(X_train_torch)loss = criterion(output.squeeze(), y_train_torch)loss.backward()optimizer.step()train_losses.append(loss.item())if epoch % 10 == 0:print(f'Epoch {epoch}: Loss {loss.item():.4f}')# 7. LSTM 特征提取
lstm_model.eval()
lstm_features = lstm_model(X_train_torch).detach().cpu().numpy()
lstm_features_test = lstm_model(X_test_torch).detach().cpu().numpy()# 8. LightGBM 訓練
train_features = np.hstack((X_train.reshape(X_train.shape[0], -1), lstm_features))
test_features = np.hstack((X_test.reshape(X_test.shape[0], -1), lstm_features_test))lgb_model = lgb.LGBMRegressor(n_estimators=200, learning_rate=0.05)
lgb_model.fit(train_features, y_train)y_pred = lgb_model.predict(test_features)# 9. 評估
def plot_results():fig, axes = plt.subplots(2, 2, figsize=(14, 10))# (1) 時間序列趨勢axes[0, 0].plot(df['date'], df['target'], label='Target', color='blue')axes[0, 0].set_title('Time Series Trend')# (2) LSTM 訓練損失axes[0, 1].plot(range(epochs), train_losses, color='red')axes[0, 1].set_title('LSTM Training Loss')# (3) LightGBM 特征重要性lgb.plot_importance(lgb_model, ax=axes[1, 0], importance_type='gain', color='green')axes[1, 0].set_title('LightGBM Feature Importance')# (4) 預測結果 vs 真實值axes[1, 1].plot(y_test, label='Actual Value', color='black')axes[1, 1].plot(y_pred, label='Predicted Value', linestyle='dashed', color='orange')axes[1, 1].legend()axes[1, 1].set_title('Prediction vs Actual')plt.tight_layout()plt.show()plot_results()
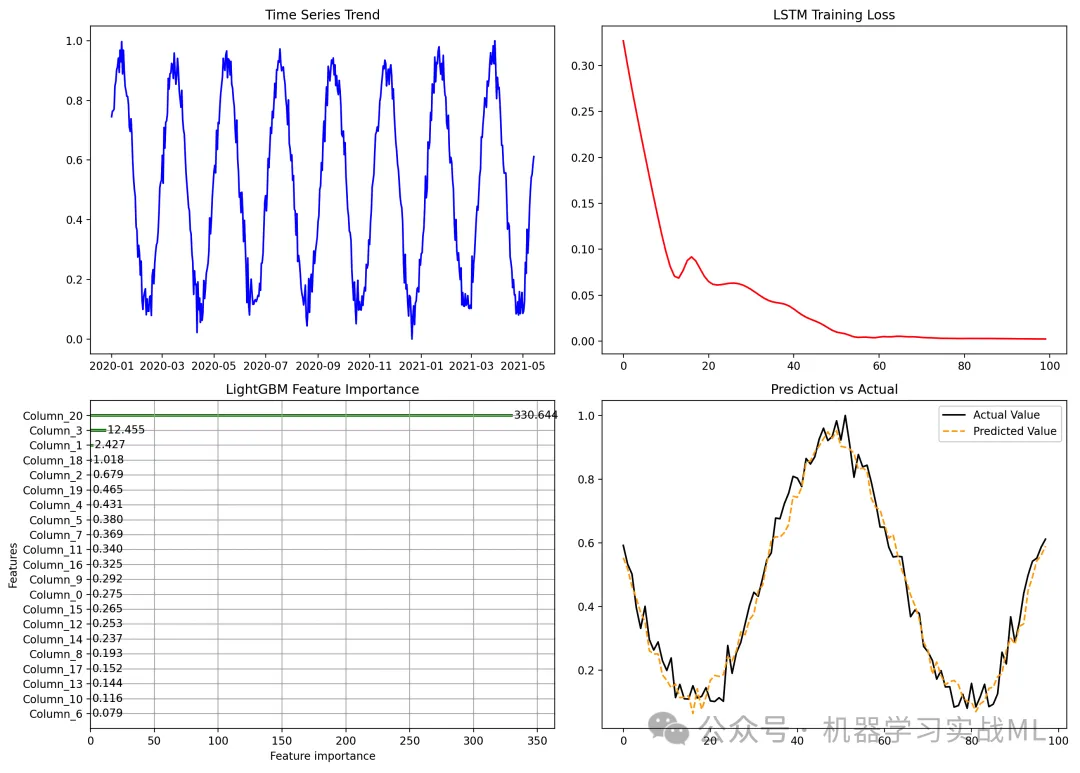
實現了 LSTM 提取特征,再利用 LightGBM 進行時間序列預測,包含:
- 時間序列趨勢:觀察目標變量的長期變化趨勢。
- LSTM 訓練損失曲線:展示 LSTM 訓練過程的損失變化。
- LightGBM 特征重要性:說明哪些特征貢獻最大。
- 預測結果 vs 真實值:直觀展示預測的準確性。












)

)




:RedisTemplate的String和Hash類型操作)