現代生成式 AI 和大語言模型(LLM)服務給 Kubernetes 帶來了獨特的流量路由挑戰。與典型的短時、無狀態 Web 請求不同,LLM 推理會話通常是長時運行、資源密集且部分有狀態的。例如,一個基于 GPU 的模型服務器可能同時維護多個活躍的推理會話,并維護內存中的 token 緩存。
傳統的負載均衡器多基于 HTTP 路徑或輪詢調度,缺乏處理此類工作負載所需的專業能力。這些方案無法識別模型標識或請求的重要性(例如交互式對話請求與批處理作業之間的區別)。企業往往采用臨時拼湊的方式應對,但缺乏統一標準的解決方案。
為了解決這一問題,Gateway API Inference Extension 在現有 Gateway API 的基礎上,添加了針對推理任務的專屬路由能力,同時保留了 Gateways 和 HTTPRoutes 等人們熟悉的模型。通過為現有網關添加這一擴展,可以將其轉變為“推理網關”(Inference Gateway),幫助用戶以“模型即服務”的方式自托管生成式 AI 模型或 LLM。
Gateway API Inference Extension 可將支持 ext-proc 的代理或網關(如 Envoy Gateway、kGateway 或 GKE Gateway)升級為推理網關,支持推理平臺團隊在 Kubernetes 上自建大語言模型服務。

主要特性
Gateway API Inference Extension 提供了以下關鍵特性:
- 模型感知路由:與傳統僅基于請求路徑進行路由的方式不同,Gateway API Inference Extension 支持根據模型名稱進行路由。這一能力得益于網關實現(如 Envoy Proxy)對生成式 AI 推理 API 規范(如 OpenAI API)的支持。該模型感知路由能力同樣適用于基于 LoRA(Low-Rank Adaptation)微調的模型。
- 服務優先級:Gateway API Inference Extension 支持為模型指定服務優先級。例如,可為在線對話類任務(對延遲較為敏感)的模型設定更高的 criticality,而對延遲容忍度更高的任務(如摘要生成)的模型則設定較低的優先級。
- 模型版本發布:Gateway API Inference Extension 支持基于模型名稱進行流量拆分,從而實現模型版本的漸進式發布與灰度上線。
- 推理服務的可擴展性:Gateway API Inference Extension 定義了一種可擴展模式,允許用戶根據自身需求擴展推理服務,實現定制化的路由能力,以應對默認方案無法滿足的場景。
- 面向推理的可定制負載均衡:Gateway API Inference Extension 提供了一種專為推理優化的可定制負載均衡與請求路由模式,并在實現中提供了基于模型服務器實時指標的模型端點選擇(model endpoint picking)機制。該機制可替代傳統負載均衡方式,被稱為“模型服務器感知”的智能負載均衡。實踐表明,它能夠有效降低推理延遲并提升集群中 GPU 的利用率。
核心 CRD
Gateway API Inference Extension 定義了兩個核心 CRD:InferencePool 和 InferenceModel。
InferencePool
InferencePool 表示一組專注于 AI 推理的 Pod,同時定義了用于路由到這些 Pod 的擴展配置。在 Gateway API 的資源模型中,InferencePool 被視為一種 “Backend” 資源。實際上,它可以用來替代傳統的 Kubernetes Service,作為下游服務的目標。
雖然 InferencePool 在某些方面與 Service 類似(比如選擇 Pod 并指定端口),但它提供了專門面向推理場景的增強能力。InferencePool 通過 extensionRef 字段指向一個 EndPoint Picker 來管理推理感知的端點選擇,從而根據實時指標(例如請求隊列深度和 GPU 內存可用性)做出智能路由決策。
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferencePool
metadata:labels:name: vllm-llama3-8b-instruct
spec:targetPortNumber: 8000selector: # 選擇運行 LLM 服務的 Podapp: vllm-llama3-8b-instructextensionRef: # 指向 EndPoint Pickername: vllm-llama3-8b-instruct-epp
InferenceModel
InferenceModel 表示某個推理模型或適配器及其相關配置。該資源用于定義模型的重要性等級(criticality),從而支持基于優先級的請求調度。
此外,InferenceModel 還支持將用戶請求中的“模型名稱”平滑地映射到一個或多個后端實際模型名稱,便于進行版本管理、灰度發布或適配不同模型格式。多個 InferenceModel 可以關聯到同一個 InferencePool 上,從而構建出一個靈活且可擴展的模型路由體系。
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceModel
metadata:name: food-review
spec:modelName: food-review # 用戶請求中的模型名稱criticality: Standard # 模型重要性等級poolRef: # 多個 InferenceModel 可以關聯到同一個 InferencePool 上name: vllm-llama3-8b-instructtargetModels: # 指定后端實際模型名稱- name: food-review-1weight: 100
相關組件
EndPoint Picker (EPP)
EndPoint Picker (EPP) 是專為 AI 推理場景設計的智能流量調度組件。EPP 實現了 Envoy 的 ext-proc,在 Envoy 轉發流量之前,它會先通過 gRPC 請求 EPP,EPP 會指示 Envoy 將請求路由到哪個具體的 Pod。
EPP 主要實現以下核心功能:
1. 端點選擇
EPP 的首要職責是從 InferencePool 中挑選一個合適的 Pod 作為請求的目標:
- 每個 EPP 實例只服務一個 InferencePool(每個 InferencePool 需部署一個 EPP 實例)。
- 它根據 InferencePool 的
Selector字段,從標記為“就緒”的 Pod 中選擇目標。 - 請求中的
ModelName必須匹配綁定該 InferencePool 的某個InferenceModel。 - 若找不到匹配的
ModelName,則返回錯誤響應給網關代理(如 Envoy)。
2. 流量拆分與模型名重寫
EPP 支持灰度發布和模型版本管理:
- 通過
InferenceModel中的配置,實現不同模型版本(如 LoRA 適配器)的流量按比例分配。 - 將用戶請求中的模型名(
ModelName)重寫為真實后端模型的名稱,支持靈活映射。
3. 可觀測性
EPP 還負責生成與推理流量相關的監控指標:
- 提供基于
InferenceModel的統計數據。 - 這些指標可以細化到實際使用的后端模型,方便監控和調優。
Dynamic LORA Adapter Sidecar
Dynamic LORA Adapter Sidecar 是一個基于 sidecar 的工具,用于將新的 LoRA 適配器部署到一組正在運行的 vLLM 模型服務器。用戶將 sidecar 與 vLLM 服務器一起部署,并通過 ConfigMap 指定希望配置的 LoRA 適配器。sidecar 監視 ConfigMap,并向 vLLM 容器發送加載或卸載請求,以執行用戶的配置意圖。
這里順便再解釋一下什么是 LoRA:
LoRA(Low-Rank Adaptation,低秩自適應)適配器是一種高效微調大模型的技術,它通過在預訓練模型的特定層旁添加小型可訓練的低秩矩陣,僅更新少量參數即可適配新任務,顯著降低計算和存儲成本。其核心作用包括:動態加載不同任務適配器實現多任務切換,以及保持原模型權重不變的同時提升微調效率,適用于個性化模型定制和資源受限場景。
請求流程
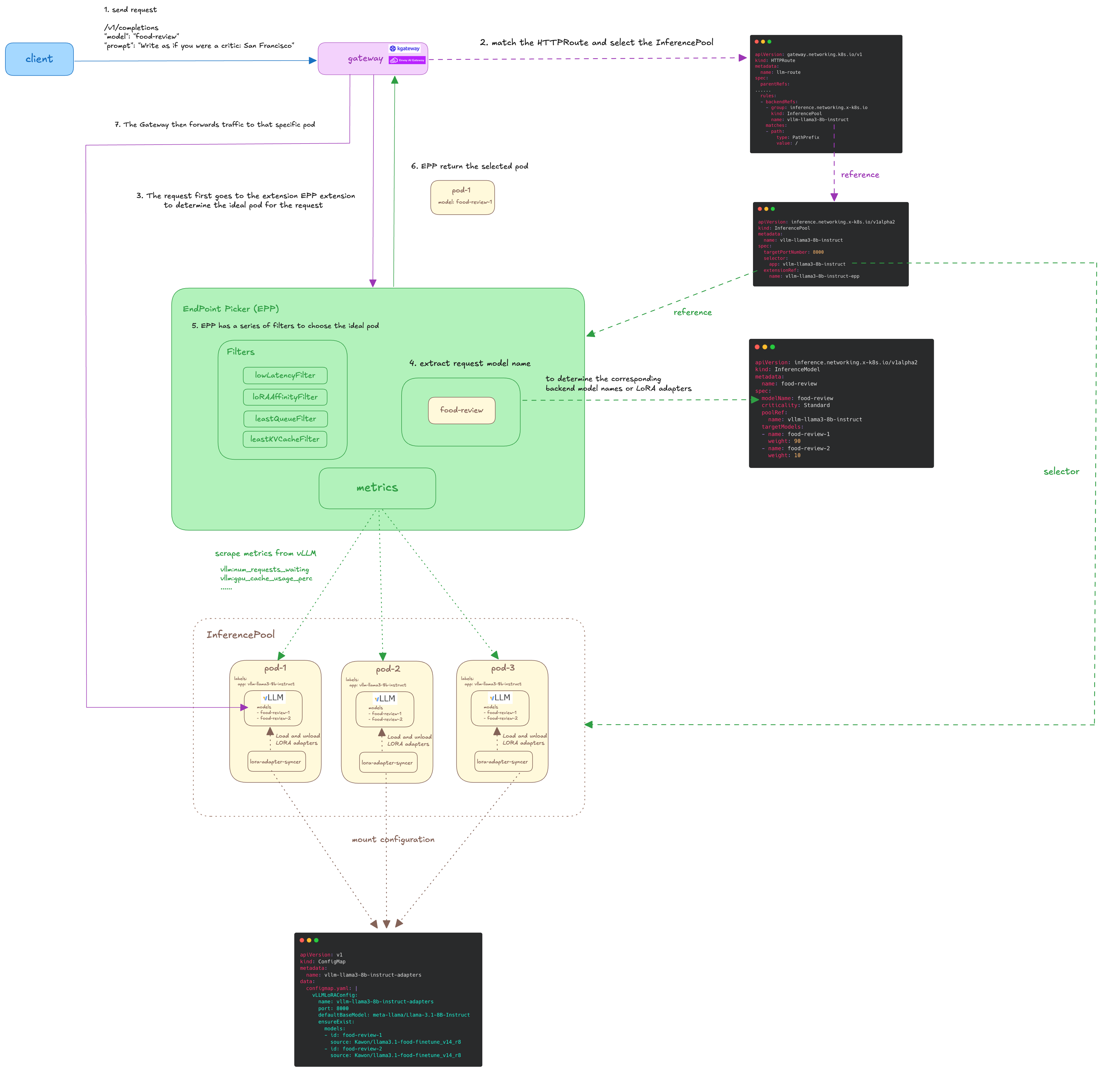
為了說明這一切是如何結合在一起的,讓我們通過一個請求示例來說明:
- 客戶端向推理網關發送請求。
- 請求到達推理網關后,網關根據 HTTPRoute 的匹配規則將請求路由到相應的 InferencePool。對于 Envoy 支持的 L7 路由器(如 kgateway 或 Istio),通常會通過路由策略和負載均衡來選擇請求的目標端點。
- 但是對于 InferencePool,請求會首先發送到一個專門的擴展組件——EndPoint Picker (EPP)。EPP 會根據來自 LLM 本身的指標來選擇合適的后端 LLM 端點。
- 當請求到達 EPP 后,EPP 會從請求正文中提取 modelName。識別出 modelName 后,EPP 會與可用的 InferenceModel 對象的 modelName 字段進行對比,確定相應的后端模型或 LoRA 適配器。例如,若 EPP 檢測到的模型名稱為
food-review,它會找到匹配的 InferenceModel,并將請求路由到適當的端點,如food-review-1或food-review-2。 - EPP 定義了一系列過濾器,用于選擇特定模型對應的端點。它會定期查詢各個 LLM Pod 的相關指標(如隊列長度、KV 緩存使用情況等),從而選擇最適合處理當前請求的 Pod。
- EPP 選定最佳 Pod 后,會將其返回給推理網關。
- 推理網關將請求路由到 EPP 選擇的 Pod。
實驗
環境準備
準備一個 GPU Kubernetes 集群,可以參考我之前寫的這篇文章快速搭建:一鍵部署 GPU Kind 集群,體驗 vLLM 極速推理。本實驗運行的模型是 meta-llama/Llama-3.1-8B-Instruct,對 GPU 的性能有一定要求,我是用 A100 的 GPU 進行實驗的。
本實驗使用的資源文件可以在 Github 上找到:https://github.com/cr7258/hands-on-lab/tree/main/gateway/gateway-api-inference-extension/get-started
創建 Hugging Face Token
需要先在 Hugging Face 創建一個 Token,并且申請 meta-llama/Llama-3.1-8B 模型的使用許可,注意填寫信息的時候國家不要選中國,否則會被秒拒。
然后創建一個 Secret,將 Token 存儲在其中。
kubectl create secret generic hf-token --from-literal=token="<your-huggingface-token>"
部署 vLLM
通過 vLLM 部署推理服務,默認配置為一個副本。如果 GPU 資源充足,可以增加副本數量。同時,配置了 lora-adapter-syncer 作為 sidecar 容器,根據 Configmap 中的配置動態管理 LoRA 適配器的加載與卸載。
# 01-gpu-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: vllm-llama3-8b-instruct
spec:replicas: 1selector:matchLabels:app: vllm-llama3-8b-instructtemplate:metadata:labels:app: vllm-llama3-8b-instructspec:containers:- name: vllmimage: "vllm/vllm-openai:latest"imagePullPolicy: Alwayscommand: ["python3", "-m", "vllm.entrypoints.openai.api_server"]args:- "--model"- "meta-llama/Llama-3.1-8B-Instruct"- "--tensor-parallel-size"- "1"- "--port"- "8000"- "--max-num-seq"- "1024"- "--compilation-config"- "3"- "--enable-lora"- "--max-loras"- "2"- "--max-lora-rank"- "8"- "--max-cpu-loras"- "12"env:# Enabling LoRA support temporarily disables automatic v1, we want to force it on# until 0.8.3 vLLM is released.- name: VLLM_USE_V1value: "1"- name: PORTvalue: "8000"- name: HUGGING_FACE_HUB_TOKENvalueFrom:secretKeyRef:name: hf-tokenkey: token- name: VLLM_ALLOW_RUNTIME_LORA_UPDATINGvalue: "true"ports:- containerPort: 8000name: httpprotocol: TCPlifecycle:preStop:exec:command:- /usr/bin/sleep- "30"livenessProbe:httpGet:path: /healthport: httpscheme: HTTPperiodSeconds: 1successThreshold: 1failureThreshold: 5timeoutSeconds: 1readinessProbe:httpGet:path: /healthport: httpscheme: HTTPperiodSeconds: 1successThreshold: 1failureThreshold: 1timeoutSeconds: 1startupProbe:failureThreshold: 600initialDelaySeconds: 2periodSeconds: 1httpGet:path: /healthport: httpscheme: HTTPresources:limits:nvidia.com/gpu: 1requests:nvidia.com/gpu: 1volumeMounts:- mountPath: /dataname: data- mountPath: /dev/shmname: shm- name: adaptersmountPath: "/adapters"initContainers:- name: lora-adapter-syncertty: truestdin: true image: us-central1-docker.pkg.dev/k8s-staging-images/gateway-api-inference-extension/lora-syncer:mainrestartPolicy: AlwaysimagePullPolicy: Alwaysenv: - name: DYNAMIC_LORA_ROLLOUT_CONFIGvalue: "/config/configmap.yaml"volumeMounts: # DO NOT USE subPath, dynamic configmap updates don't work on subPaths- name: config-volumemountPath: /configrestartPolicy: AlwaysenableServiceLinks: falseterminationGracePeriodSeconds: 130volumes:- name: dataemptyDir: {}- name: shmemptyDir:medium: Memory- name: adaptersemptyDir: {}- name: config-volumeconfigMap:name: vllm-llama3-8b-instruct-adapters
---
apiVersion: v1
kind: ConfigMap
metadata:name: vllm-llama3-8b-instruct-adapters
data:configmap.yaml: |vLLMLoRAConfig:name: vllm-llama3-8b-instruct-adaptersport: 8000defaultBaseModel: meta-llama/Llama-3.1-8B-InstructensureExist:models:- id: food-review-1source: Kawon/llama3.1-food-finetune_v14_r8
等待 vLLM 容器啟動成功,如果一切正常可以看到如下日志:
kubectl logs vllm-llama3-8b-instruct-545c578498-47wt6 -fDefaulted container "vllm" out of: vllm, lora-adapter-syncer (init)
INFO 04-05 05:51:39 [__init__.py:239] Automatically detected platform cuda.
WARNING 04-05 05:51:44 [api_server.py:759] LoRA dynamic loading & unloading is enabled in the API server. This should ONLY be used for local development!
INFO 04-05 05:51:44 [api_server.py:981] vLLM API server version 0.8.2
INFO 04-05 05:51:44 [api_server.py:982] args: Namespace(host=None, port=8000, uvicorn_log_level='info', disable_uvicorn_access_log=False, allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, chat_template_content_format='auto', response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, enable_ssl_refresh=False, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_request_id_headers=False, enable_auto_tool_choice=False, tool_call_parser=None, tool_parser_plugin='', model='meta-llama/Llama-3.1-8B-Instruct', task='auto', tokenizer=None, hf_config_path=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=False, allowed_local_media_path=None, download_dir=None, load_format='auto', config_format=<ConfigFormat.AUTO: 'auto'>, dtype='auto', kv_cache_dtype='auto', max_model_len=None, guided_decoding_backend='xgrammar', logits_processor_pattern=None, model_impl='auto', distributed_executor_backend=None, pipeline_parallel_size=1, tensor_parallel_size=1, enable_expert_parallel=False, max_parallel_loading_workers=None, ray_workers_use_nsight=False, block_size=None, enable_prefix_caching=None, disable_sliding_window=False, use_v2_block_manager=True, num_lookahead_slots=0, seed=None, swap_space=4, cpu_offload_gb=0, gpu_memory_utilization=0.9, num_gpu_blocks_override=None, max_num_batched_tokens=None, max_num_partial_prefills=1, max_long_partial_prefills=1, long_prefill_token_threshold=0, max_num_seqs=None, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, hf_overrides=None, enforce_eager=False, max_seq_len_to_capture=8192, disable_custom_all_reduce=False, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config=None, limit_mm_per_prompt=None, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=True, enable_lora_bias=False, max_loras=2, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=12, fully_sharded_loras=False, enable_prompt_adapter=False, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', num_scheduler_steps=1, use_tqdm_on_load=True, multi_step_stream_outputs=True, scheduler_delay_factor=0.0, enable_chunked_prefill=None, speculative_config=None, speculative_model=None, speculative_model_quantization=None, num_speculative_tokens=None, speculative_disable_mqa_scorer=False, speculative_draft_tensor_parallel_size=None, speculative_max_model_len=None, speculative_disable_by_batch_size=None, ngram_prompt_lookup_max=None, ngram_prompt_lookup_min=None, spec_decoding_acceptance_method='rejection_sampler', typical_acceptance_sampler_posterior_threshold=None, typical_acceptance_sampler_posterior_alpha=None, disable_logprobs_during_spec_decoding=None, model_loader_extra_config=None, ignore_patterns=[], preemption_mode=None, served_model_name=None, qlora_adapter_name_or_path=None, show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, scheduling_policy='fcfs', scheduler_cls='vllm.core.scheduler.Scheduler', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', worker_extension_cls='', generation_config='auto', override_generation_config=None, enable_sleep_mode=False, calculate_kv_scales=False, additional_config=None, enable_reasoning=False, reasoning_parser=None, disable_cascade_attn=False, disable_log_requests=False, max_log_len=None, disable_fastapi_docs=False, enable_prompt_tokens_details=False, enable_server_load_tracking=False)
INFO 04-05 05:51:51 [config.py:585] This model supports multiple tasks: {'classify', 'generate', 'embed', 'reward', 'score'}. Defaulting to 'generate'.
WARNING 04-05 05:51:51 [arg_utils.py:1859] Detected VLLM_USE_V1=1 with LORA. Usage should be considered experimental. Please report any issues on Github.
INFO 04-05 05:51:51 [config.py:1697] Chunked prefill is enabled with max_num_batched_tokens=2048.
WARNING 04-05 05:51:51 [config.py:2381] LoRA with chunked prefill is still experimental and may be unstable.
INFO 04-05 05:51:53 [core.py:54] Initializing a V1 LLM engine (v0.8.2) with config: model='meta-llama/Llama-3.1-8B-Instruct', speculative_config=None, tokenizer='meta-llama/Llama-3.1-8B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=131072, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='xgrammar', reasoning_backend=None), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=meta-llama/Llama-3.1-8B-Instruct, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=True, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"level":3,"custom_ops":["none"],"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output"],"use_inductor":true,"compile_sizes":[],"use_cudagraph":true,"cudagraph_num_of_warmups":1,"cudagraph_capture_sizes":[512,504,496,488,480,472,464,456,448,440,432,424,416,408,400,392,384,376,368,360,352,344,336,328,320,312,304,296,288,280,272,264,256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":512}
WARNING 04-05 05:51:54 [utils.py:2321] Methods determine_num_available_blocks,device_config,get_cache_block_size_bytes,initialize_cache not implemented in <vllm.v1.worker.gpu_worker.Worker object at 0x73d836b269c0>
INFO 04-05 05:51:55 [parallel_state.py:954] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0
INFO 04-05 05:51:55 [cuda.py:220] Using Flash Attention backend on V1 engine.
INFO 04-05 05:51:55 [gpu_model_runner.py:1174] Starting to load model meta-llama/Llama-3.1-8B-Instruct...
INFO 04-05 05:51:55 [topk_topp_sampler.py:53] Using FlashInfer for top-p & top-k sampling.
INFO 04-05 05:51:55 [weight_utils.py:265] Using model weights format ['*.safetensors']INFO 04-05 05:52:51 [weight_utils.py:281] Time spent downloading weights for meta-llama/Llama-3.1-8B-Instruct: 55.301468 seconds
Loading safetensors checkpoint shards: 0% Completed | 0/4 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 25% Completed | 1/4 [00:00<00:02, 1.25it/s]
Loading safetensors checkpoint shards: 50% Completed | 2/4 [00:01<00:01, 1.72it/s]
Loading safetensors checkpoint shards: 75% Completed | 3/4 [00:01<00:00, 1.50it/s]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [00:02<00:00, 1.25it/s]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [00:02<00:00, 1.33it/s]INFO 04-05 05:52:54 [loader.py:447] Loading weights took 3.27 seconds
INFO 04-05 05:52:54 [punica_selector.py:18] Using PunicaWrapperGPU.
INFO 04-05 05:52:54 [gpu_model_runner.py:1186] Model loading took 15.1749 GB and 59.268527 seconds
INFO 04-05 05:53:07 [backends.py:415] Using cache directory: /root/.cache/vllm/torch_compile_cache/253772ede5/rank_0_0 for vLLM's torch.compile
INFO 04-05 05:53:07 [backends.py:425] Dynamo bytecode transform time: 12.60 s
INFO 04-05 05:53:13 [backends.py:132] Cache the graph of shape None for later use
INFO 04-05 05:53:53 [backends.py:144] Compiling a graph for general shape takes 44.37 s
INFO 04-05 05:54:19 [monitor.py:33] torch.compile takes 56.97 s in total
INFO 04-05 05:54:20 [kv_cache_utils.py:566] GPU KV cache size: 148,096 tokens
INFO 04-05 05:54:20 [kv_cache_utils.py:569] Maximum concurrency for 131,072 tokens per request: 1.13x
INFO 04-05 05:55:41 [gpu_model_runner.py:1534] Graph capturing finished in 81 secs, took 0.74 GiB
INFO 04-05 05:55:42 [core.py:151] init engine (profile, create kv cache, warmup model) took 167.44 seconds
WARNING 04-05 05:55:42 [config.py:1028] Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
INFO 04-05 05:55:42 [serving_chat.py:115] Using default chat sampling params from model: {'temperature': 0.6, 'top_p': 0.9}
INFO 04-05 05:55:42 [serving_completion.py:61] Using default completion sampling params from model: {'temperature': 0.6, 'top_p': 0.9}
INFO 04-05 05:55:42 [api_server.py:1028] Starting vLLM API server on http://0.0.0.0:8000
INFO 04-05 05:55:42 [launcher.py:26] Available routes are:
INFO 04-05 05:55:42 [launcher.py:34] Route: /openapi.json, Methods: GET, HEAD
INFO 04-05 05:55:42 [launcher.py:34] Route: /docs, Methods: GET, HEAD
INFO 04-05 05:55:42 [launcher.py:34] Route: /docs/oauth2-redirect, Methods: GET, HEAD
INFO 04-05 05:55:42 [launcher.py:34] Route: /redoc, Methods: GET, HEAD
INFO 04-05 05:55:42 [launcher.py:34] Route: /health, Methods: GET
INFO 04-05 05:55:42 [launcher.py:34] Route: /load, Methods: GET
INFO 04-05 05:55:42 [launcher.py:34] Route: /ping, Methods: GET, POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /tokenize, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /detokenize, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /v1/models, Methods: GET
INFO 04-05 05:55:42 [launcher.py:34] Route: /version, Methods: GET
INFO 04-05 05:55:42 [launcher.py:34] Route: /v1/chat/completions, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /v1/completions, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /v1/embeddings, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /pooling, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /score, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /v1/score, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /v1/audio/transcriptions, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /rerank, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /v1/rerank, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /v2/rerank, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /invocations, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /v1/load_lora_adapter, Methods: POST
INFO 04-05 05:55:42 [launcher.py:34] Route: /v1/unload_lora_adapter, Methods: POST
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: 10.244.1.1:33920 - "GET /health HTTP/1.1" 200 OK
INFO: 10.244.1.1:33922 - "GET /health HTTP/1.1" 200 OK
查看 lora-adapter-syncer sidecar 容器的日志,可以看到加載了 food-review-1 適配器。
2025-04-05 12:55:56 - WARNING - sidecar.py:266 - skipped adapters found in both `ensureExist` and `ensureNotExist`
2025-04-05 12:55:56 - INFO - sidecar.py:271 - adapter to load food-review-1
2025-04-05 12:55:56 - INFO - sidecar.py:218 - food-review-1 already present on model server localhost:8000
2025-04-05 12:55:57 - INFO - sidecar.py:276 - adapters to unload
2025-04-05 12:55:57 - INFO - sidecar.py:310 - Waiting 5s before next reconciliation...
2025-04-05 12:56:02 - INFO - sidecar.py:314 - Periodic reconciliation triggered
2025-04-05 12:56:02 - INFO - sidecar.py:255 - reconciling model server localhost:8000 with config stored at /config/configmap.yaml
安裝 Inference Extension CRD
安裝 InferencePool 和 InferenceModel 這兩個 CRD。
VERSION=v0.2.0
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/$VERSION/manifests.yaml
部署 InferenceModel
部署 InferenceModel,將用戶請求 food-review 模型的流量轉發到示例模型服務器的 food-review-1 LoRA 適配器。InferenceModel 通過 poolRef 關聯 InferencePool(將在下一小節創建)。
# 02-inferencemodel.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceModel
metadata:name: food-review
spec:modelName: food-review # 用戶請求中的模型名稱criticality: Standard # 模型重要性等級poolRef: # 多個 InferenceModel 可以關聯到同一個 InferencePool 上name: vllm-llama3-8b-instructtargetModels: # 指定后端實際模型名稱- name: food-review-1weight: 100
部署 InferencePool 和 EPP
部署 InferencePool,通過 selector 選擇運行 LLM 服務的 Pod,并通過 extensionRef 關聯 EPP。EPP 會基于實時指標(如請求隊列深度和 GPU 可用內存)做出智能路由決策。
# 03-inferencepool-resources.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferencePool
metadata:labels:name: vllm-llama3-8b-instruct
spec:targetPortNumber: 8000selector: # 選擇運行 LLM 服務的 Podapp: vllm-llama3-8b-instructextensionRef: # 指向 EndPoint Pickername: vllm-llama3-8b-instruct-epp
---
apiVersion: v1
kind: Service
metadata:name: vllm-llama3-8b-instruct-eppnamespace: default
spec:selector:app: vllm-llama3-8b-instruct-eppports:- protocol: TCPport: 9002targetPort: 9002appProtocol: http2type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:name: vllm-llama3-8b-instruct-eppnamespace: defaultlabels:app: vllm-llama3-8b-instruct-epp
spec:replicas: 1selector:matchLabels:app: vllm-llama3-8b-instruct-epptemplate:metadata:labels:app: vllm-llama3-8b-instruct-eppspec:# Conservatively, this timeout should mirror the longest grace period of the pods within the poolterminationGracePeriodSeconds: 130containers:- name: eppimage: us-central1-docker.pkg.dev/k8s-staging-images/gateway-api-inference-extension/epp:mainimagePullPolicy: Alwaysargs:- -poolName- "vllm-llama3-8b-instruct"- -v- "4"- --zap-encoder- "json"- -grpcPort- "9002"- -grpcHealthPort- "9003"env:- name: USE_STREAMINGvalue: "true"ports:- containerPort: 9002- containerPort: 9003- name: metricscontainerPort: 9090livenessProbe:grpc:port: 9003service: inference-extensioninitialDelaySeconds: 5periodSeconds: 10readinessProbe:grpc:port: 9003service: inference-extensioninitialDelaySeconds: 5periodSeconds: 10
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: pod-read
rules:
- apiGroups: ["inference.networking.x-k8s.io"]resources: ["inferencemodels"]verbs: ["get", "watch", "list"]
- apiGroups: [""]resources: ["pods"]verbs: ["get", "watch", "list"]
- apiGroups: ["inference.networking.x-k8s.io"]resources: ["inferencepools"]verbs: ["get", "watch", "list"]
- apiGroups: ["discovery.k8s.io"]resources: ["endpointslices"]verbs: ["get", "watch", "list"]
- apiGroups:- authentication.k8s.ioresources:- tokenreviewsverbs:- create
- apiGroups:- authorization.k8s.ioresources:- subjectaccessreviewsverbs:- create
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: pod-read-binding
subjects:
- kind: ServiceAccountname: defaultnamespace: default
roleRef:kind: ClusterRolename: pod-read
部署推理網關
當前支持 Gateway API Inference Extension 的網關有 Kgateway,Envoy AI Gateway 等,完整的列表可以參考 Implementations。
本文將會以 Kgateway 為例進行演示。
首先安裝 Kgateway 相關的 CRD。
KGTW_VERSION=v2.0.0
helm upgrade -i --create-namespace --namespace kgateway-system --version $KGTW_VERSION kgateway-crds oci://cr.kgateway.dev/kgateway-dev/charts/kgateway-crds
然后安裝 Kgateway,設置 inferenceExtension.enabled=true 參數啟用推理擴展。
helm upgrade -i --namespace kgateway-system --version $KGTW_VERSION kgateway oci://cr.kgateway.dev/kgateway-dev/charts/kgateway --set inferenceExtension.enabled=true
接著創建 Gateway,gatewayClassName 關聯到 Kgateway。
# 04-gateway.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:name: inference-gateway
spec:gatewayClassName: kgatewaylisteners:- name: httpport: 80protocol: HTTP
確認網關已分配 IP 地址并報告 Programmed=True 狀態。
kubectl get gateway inference-gatewayNAME CLASS ADDRESS PROGRAMMED AGE
inference-gateway kgateway 172.18.0.4 True 16s
部署 HTTPRoute,將流量路由到 InferencePool。
# 05-httproute.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:name: llm-route
spec:parentRefs:- group: gateway.networking.k8s.iokind: Gatewayname: inference-gatewayrules:- backendRefs:- group: inference.networking.x-k8s.iokind: InferencePoolname: vllm-llama3-8b-instructport: 8000 # Remove when https://github.com/kgateway-dev/kgateway/issues/10987 is fixed.matches:- path:type: PathPrefixvalue: /timeouts:request: 300s
確認 HTTPRoute 狀態條件包含 Accepted=True 和 ResolvedRefs=True:
kubectl get httproute llm-route -o yamlapiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
......
status:parents:- conditions:- lastTransitionTime: "2025-04-05T13:04:35Z"message: ""observedGeneration: 2reason: Acceptedstatus: "True"type: Accepted- lastTransitionTime: "2025-04-05T13:06:14Z"message: ""observedGeneration: 2reason: ResolvedRefsstatus: "True"type: ResolvedRefscontrollerName: kgateway.dev/kgatewayparentRef:group: gateway.networking.k8s.iokind: Gatewayname: inference-gateway
請求驗證
至此,我們已完成全部配置工作,接下來可通過 curl 命令向推理網關發送請求進行測試。
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}')
PORT=80
curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{
"model": "food-review",
"prompt": "Write as if you were a critic: San Francisco",
"max_tokens": 100,
"temperature": 0
}'
響應結果如下,可以看到模型成功處理了請求。
HTTP/1.1 200 OK
date: Sat, 05 Apr 2025 13:18:22 GMT
server: envoy
content-type: application/json
x-envoy-upstream-service-time: 1785
x-went-into-resp-headers: true
transfer-encoding: chunked{"choices": [{"finish_reason": "length","index": 0,"logprobs": null,"prompt_logprobs": null,"stop_reason": null,"text": "'s iconic seafood restaurant, Ali's Bistro, serves a variety of seafood dishes, including sushi, sashimi, and seafood paella. How would you rate Ali's Bistro 1.0? (1 being lowest and 10 being highest)\n### Step 1: Analyze the menu offerings\nAli's Bistro offers a diverse range of seafood dishes, including sushi, sashimi, and seafood paella. This variety suggests that the restaurant caters to different tastes and dietary"}],"created": 1743859102,"id": "cmpl-0046459d-d94f-43b5-b8f4-0898d8e2d50b","model": "food-review-1","object": "text_completion","usage": {"completion_tokens": 100,"prompt_tokens": 11,"prompt_tokens_details": null,"total_tokens": 111}
}
發布新的適配器版本
接下來,將演示如何發布新的適配器版本。通過修改 vllm-llama3-8b-instruct-adapters ConfigMap,讓 lora-adapter-syncer sidecar 容器加載新的適配器到 vLLM 容器。
kubectl edit configmap vllm-llama3-8b-instruct-adapters
更改 Configmap 的配置如下,增加 food-review-2 適配器。
apiVersion: v1
kind: ConfigMap
metadata:name: vllm-llama3-8b-instruct-adapters
data:configmap.yaml: |vLLMLoRAConfig:name: vllm-llama3-8b-instruct-adaptersport: 8000defaultBaseModel: meta-llama/Llama-3.1-8B-InstructensureExist:models:- id: food-review-1source: Kawon/llama3.1-food-finetune_v14_r8# 增加新的適配器- id: food-review-2source: Kawon/llama3.1-food-finetune_v14_r8
新的適配器版本將實時應用于模型服務器,無需重新啟動。查看 lora-adapter-syncer sidecar 容器日志,可以看到加載了 food-review-2 適配器。
2025-04-05 13:15:21 - INFO - sidecar.py:271 - adapter to load food-review-2, food-review-1
2025-04-05 13:15:21 - INFO - sidecar.py:231 - loaded model food-review-2
2025-04-05 13:15:21 - INFO - sidecar.py:218 - food-review-1 already present on model server localhost:8000
2025-04-05 13:15:21 - INFO - sidecar.py:276 - adapters to unload
2025-04-05 13:15:21 - INFO - sidecar.py:62 - model server reconcile to Config '/config/configmap.yaml' !
2025-04-05 13:15:22 - INFO - sidecar.py:314 - Periodic reconciliation triggered
2025-04-05 13:15:22 - INFO - sidecar.py:255 - reconciling model server localhost:8000 with config stored at /config/configmap.yaml
修改 InferenceModel 的配置以 Canary 的方式發布新的適配器版本。
kubectl edit inferencemodel food-review
將 10% 的流量路由到新的 food-review-2 適配器,90% 的流量路由到 food-review-1。
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceModel
metadata:name: food-review
spec:modelName: food-reviewcriticality: StandardpoolRef:name: vllm-llama3-8b-instructtargetModels:- name: food-review-1weight: 90- name: food-review-2weight: 10
使用相同的 curl 命令請求多次進行測試,可以觀察到 90% 的請求被路由到 food-review-1,10% 的請求被路由到 food-review-2。
curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{
"model": "food-review",
"prompt": "Write as if you were a critic: San Francisco",
"max_tokens": 100,
"temperature": 0
}'# 發送 food-review-1 的請求,可以通過響應的 model 字段辨認
HTTP/1.1 200 OK
date: Sat, 05 Apr 2025 13:18:34 GMT
server: envoy
content-type: application/json
x-envoy-upstream-service-time: 1780
x-went-into-resp-headers: true
transfer-encoding: chunked{"choices": [{"finish_reason": "length","index": 0,"logprobs": null,"prompt_logprobs": null,"stop_reason": null,"text": "'s iconic seafood restaurant, Ali's Bistro, serves a variety of seafood dishes, including sushi, sashimi, and seafood paella. How would you rate Ali's Bistro 1.0? (1 being lowest and 10 being highest)\n### Step 1: Analyze the menu offerings\nAli's Bistro offers a diverse range of seafood dishes, including sushi, sashimi, and seafood paella. This variety suggests that the restaurant caters to different tastes and dietary"}],"created": 1743859115,"id": "cmpl-99203056-cb12-4c8e-bae9-23c28c07cdd7","model": "food-review-1","object": "text_completion","usage": {"completion_tokens": 100,"prompt_tokens": 11,"prompt_tokens_details": null,"total_tokens": 111}
}curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{
"model": "food-review",
"prompt": "Write as if you were a critic: San Francisco",
"max_tokens": 100,
"temperature": 0
}'HTTP/1.1 200 OK
date: Sat, 05 Apr 2025 13:18:38 GMT
server: envoy
content-type: application/json
x-envoy-upstream-service-time: 2531
x-went-into-resp-headers: true
transfer-encoding: chunked# 發送到 food-review-2 的請求
{"choices": [{"finish_reason": "length","index": 0,"logprobs": null,"prompt_logprobs": null,"stop_reason": null,"text": "'s iconic seafood restaurant, Ali's Bistro, serves a variety of seafood dishes, including sushi, sashimi, and seafood paella. How would you rate Ali's Bistro 1.0? (1 being lowest and 10 being highest)\n### Step 1: Analyze the menu offerings\nAli's Bistro offers a diverse range of seafood dishes, including sushi, sashimi, and seafood paella. This variety suggests that the restaurant caters to different tastes and dietary"}],"created": 1743859119,"id": "cmpl-6f2e2e5f-a0e7-4ee0-bd54-5b1a2ef23399","model": "food-review-2","object": "text_completion","usage": {"completion_tokens": 100,"prompt_tokens": 11,"prompt_tokens_details": null,"total_tokens": 111}
}
確認新版本的適配器工作正常后,可以修改 InferenceModel 的配置,將 100% 的流量路由到 food-review-2。
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceModel
metadata:name: food-review
spec:modelName: food-reviewcriticality: StandardpoolRef:name: vllm-llama3-8b-instructtargetModels:- name: food-review-2weight: 100
同時修改 vllm-llama3-8b-instruct-adapters ConfigMap,將舊版本 food-review-1 移動到 ensureNotExist 列表中,從服務器卸載舊版本。
apiVersion: v1
kind: ConfigMap
metadata:name: vllm-llama3-8b-instruct-adapters
data:configmap.yaml: |vLLMLoRAConfig:name: vllm-llama3-8b-instruct-adaptersport: 8000defaultBaseModel: meta-llama/Llama-3.1-8B-InstructensureExist:models:- id: food-review-2source: Kawon/llama3.1-food-finetune_v14_r8ensureNotExist:models:- id: food-review-1source: Kawon/llama3.1-food-finetune_v14_r8
觀察 lora-adapter-syncer sidecar 容器日志,可以看到卸載了 food-review-1 適配器。
2025-04-05 13:27:53 - INFO - sidecar.py:271 - adapter to load food-review-2
2025-04-05 13:27:53 - INFO - sidecar.py:218 - food-review-2 already present on model server localhost:8000
2025-04-05 13:27:53 - INFO - sidecar.py:276 - adapters to unload food-review-1
2025-04-05 13:27:53 - INFO - sidecar.py:247 - unloaded model food-review-1
2025-04-05 13:27:53 - INFO - sidecar.py:62 - model server reconcile to Config '/config/configmap.yaml' !
2025-04-05 13:27:56 - INFO - sidecar.py:314 - Periodic reconciliation triggered
2025-04-05 13:27:56 - INFO - sidecar.py:255 - reconciling model server localhost:8000 with config stored at /config/configmap.yaml
此時,所有請求都應該由新的適配器版本提供服務。
總結
Gateway API Inference Extension 為 Kubernetes 上的 LLM 推理服務提供了專業化的流量路由解決方案。通過模型感知路由、服務優先級和智能負載均衡等特性,它有效提高了 GPU 資源利用率,降低了推理延遲。該擴展通過 InferencePool 和 InferenceModel 兩個核心 CRD,結合 EndPoint Picker 和 Dynamic LORA Adapter Sidecar 組件,實現了模型版本的灰度發布與動態 LoRA 適配器管理,為 Kubernetes 上自托管的大語言模型提供了標準化且靈活的解決方案。
參考資料
- Gateway API Inference Extension: https://gateway-api-inference-extension.sigs.k8s.io/
- Gateway API: https://gateway-api.sigs.k8s.io/
- ext-proc: https://www.envoyproxy.io/docs/envoy/latest/configuration/http/http_filters/ext_proc_filter
- InferencePool: https://gateway-api-inference-extension.sigs.k8s.io/api-types/inferencepool/
- InferenceModel: https://gateway-api-inference-extension.sigs.k8s.io/api-types/inferencemodel/
- EndPoint Picker (EPP): https://github.com/kubernetes-sigs/gateway-api-inference-extension/tree/main/pkg/epp
- Dynamic LORA Adapter Sidecar: https://github.com/kubernetes-sigs/gateway-api-inference-extension/tree/main/tools/dynamic-lora-sidecar
- Implementations: https://gateway-api-inference-extension.sigs.k8s.io/implementations
- Deep Dive into the Gateway API Inference Extension: https://kgateway.dev/blog/deep-dive-inference-extensions/
- Smarter AI Inference Routing on Kubernetes with Gateway API Inference Extension: https://kgateway.dev/blog/smarter-ai-reference-kubernetes-gateway-api/
歡迎關注














)





