HashMap
一、基礎常量以及結構
//數組默認初始容量static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16//數組容量最大值static final int MAXIMUM_CAPACITY = 1 << 30;//默認擴容因子static final float DEFAULT_LOAD_FACTOR = 0.75f;//鏈表長度閾值 樹化條件static final int TREEIFY_THRESHOLD = 8;//樹中只有6個或一下轉化成鏈表static final int UNTREEIFY_THRESHOLD = 6;//樹化的條件之一 數組長度需要達到的值static final int MIN_TREEIFY_CAPACITY = 64;// 默認的數組transient Node<K,V>[] table;//判斷是否擴容的大小 因子*容量int threshold;//擴容因子final float loadFactor;
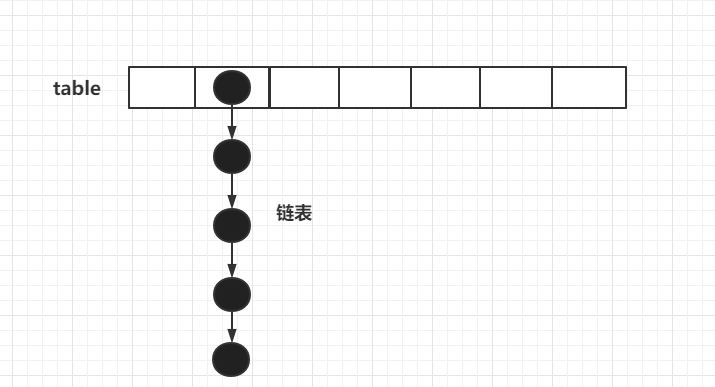
都應該知道HashMap 的結構是數組+鏈表,鏈表會在一定條件下樹化變成紅黑樹(本節我們只追究常規操作,不深究紅黑樹這種數據結構),結構如下圖所示
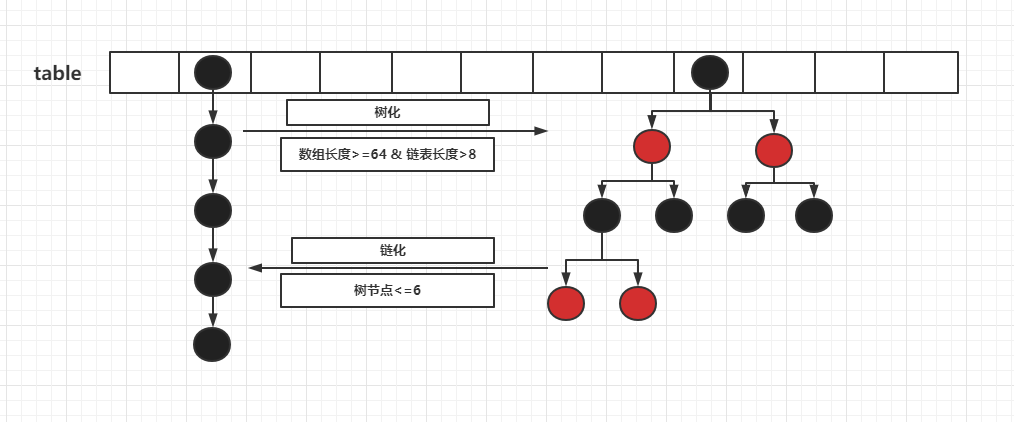
二、構造方法
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);//擴容因子this.loadFactor = loadFactor;//擴容閾值this.threshold = tableSizeFor(initialCapacity);}//實現了把一個數變為最接近的2的n次方 比如:7變成8 10變成16static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
我們可以看到初始化的時候傳的參數是初始容量大小和擴容因子,為什么在初始化的時候并沒看看數組容量的初始化,反而把數組容量賦值給了擴容閾值,閾值還沒*擴容因子?為什么數組容量的初始化要做2的n次方處理?
問題一:數組容量什么時候初始化的?擴容閾值什么時候計算的?
在對象第一次Put操作的時候初始化的,有點類似懶加載的方式,只有在用時候我才申請空間資源 下面是取證,我就直接截圖了,具體過程后面會說(可以看到初始化的時候把閾值給了數組長度,而閾值重新計算了一次)
問題二:為什么數組容量要設置成2的n次方?
因為HashMap是根據Key的Hash去確定在數組中的具體下標,HashMap為了減少數據碰撞(下標沖突),就需要使得數據分布更均勻,那就是取模算法 hashcode%length(數組長度),計算機直接求余數不如位運算效率高,所以源碼中做了優化,使用hashcode&(length-1),hashcode%length等于hashcode&(length-1)的前提是length是2的n次冪。
三、put操作
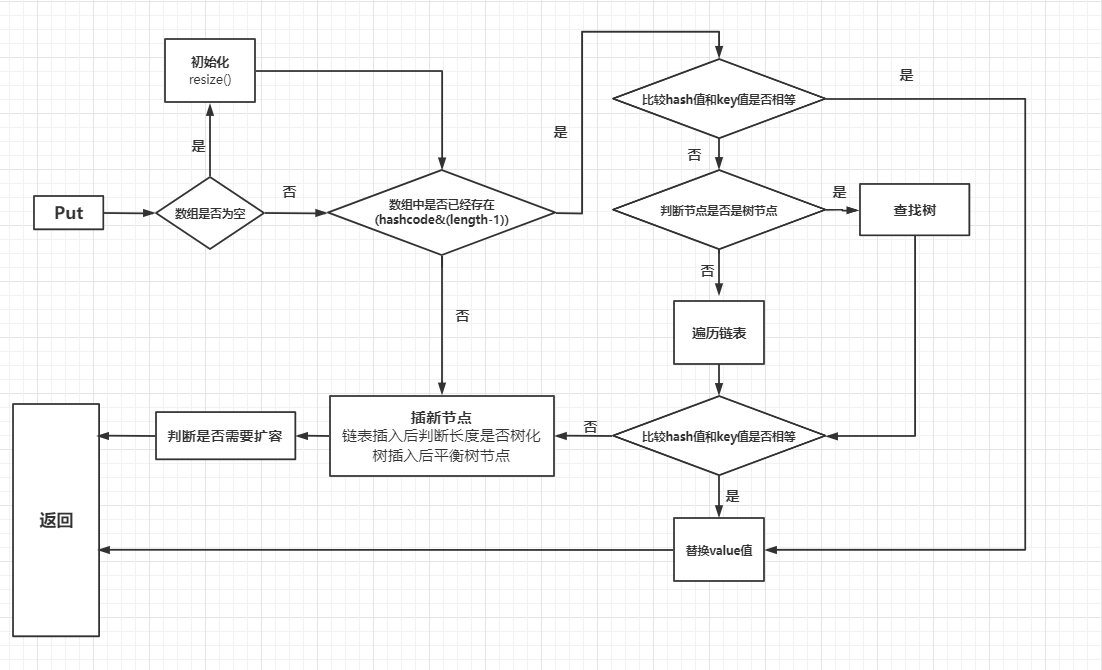
其實我們在了解HashMap的結構后,已經猜得到添加操作需要做什么了
- 數組為空的時候,擴容初始化(正如我們上面說的一樣)
- 根據要插入key的hash算出在數組中的下標(hashcode&(length-1)),看看是否已經存在,不存在則新建節點直接放入
- 如果已經存在則判斷先頭節點的hash、key與要插入的key、hash是否一致,一致則替換
- 不一致致需要判斷這個節點是樹結構還是鏈表結構
- 樹結結構則查找樹 存在則替換,不存在給樹新添一個樹節點
- 鏈表結構則遍歷鏈 存在則替換,不存在則在尾部新添一個節點,并判斷鏈表的長度是否達到樹化條件
- 以上需要替換的節點都會被取出,新值替換舊值,并返回舊值
- 到了這說明是新添加了一個節點,需要把容量+1,并判斷是否達到擴容標準,達到了還要擴容操作
源碼如下:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {Node<K,V>[] tab; //創建數組Node<K,V> p; //創建新節點int n, i;//數組為空 還沒初始化的話,就擴容操作 初始化一下if ((tab = table) == null || (n = tab.length) == 0) {//對數組進行初始化n = (tab = resize()).length;}//(n - 1) & hash 求數組的下標,然后從數組中取節點,判斷是否已經存在if ((p = tab[i = (n - 1) & hash]) == null) {// 原來數組中不存在就新建一個節點放入tab[i] = newNode(hash, key, value, null);}else {// 用來獲取已經存在的節點Node<K,V> e;K k;// hash值和key都一致則進行替換if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) {e = p;}else if (p instanceof TreeNode) {//存儲的節點的key的不存在,判斷是否為樹節點(是不是已經轉化為紅黑樹)//如果已經是樹了,那就進行樹的操作e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);}else {//頭節點不同,也不是樹結構,說明是鏈表 需要遍歷鏈表比較for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {//直接找到鏈表的尾部,直接插入p.next = newNode(hash, key, value, null);//判斷鏈表的長度是否大于可以轉化為樹結構的閾值if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st//轉化成樹treeifyBin(tab, hash);break;}if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {break;}p = e;}}// 存在映射的key,覆蓋原值,將值返回if (e != null) {V oldValue = e.value;if (!onlyIfAbsent || oldValue == null) {e.value = value;}afterNodeAccess(e);return oldValue;}}++modCount;//hashmap的容量大于閾值if (++size > threshold) {// 擴容resize();}afterNodeInsertion(evict);return null;}
四、resize 擴容機制
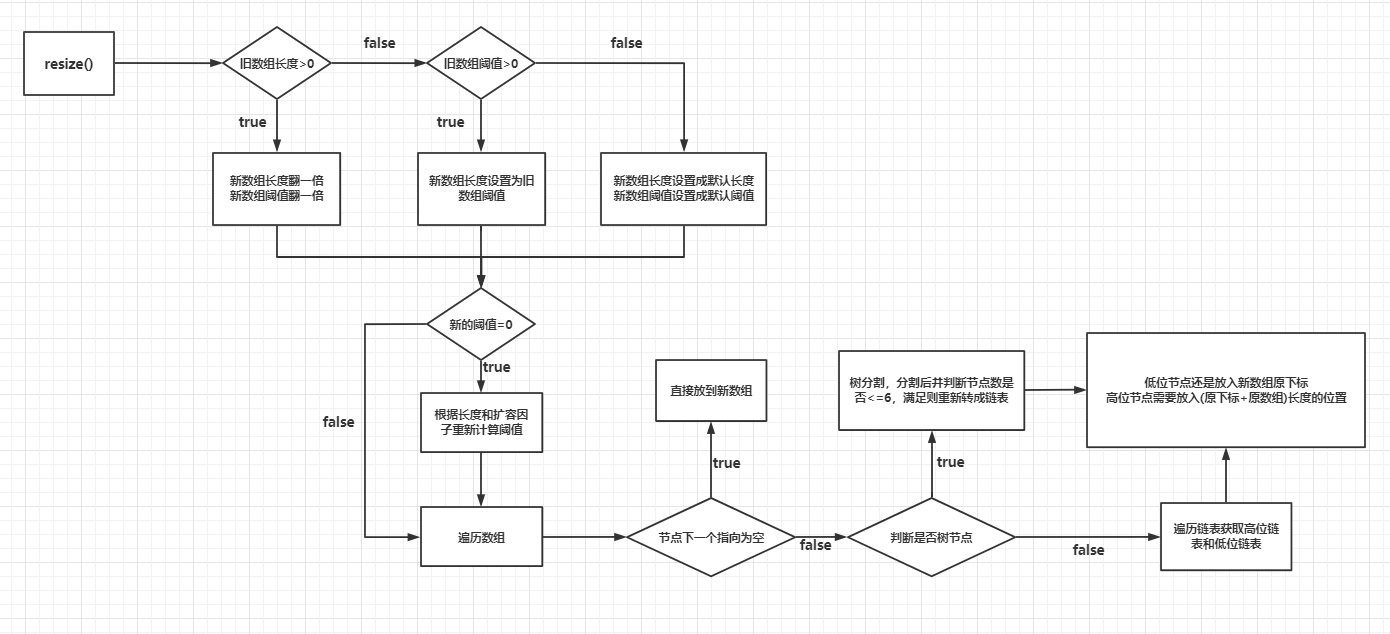
HashMap的擴容與正常的數組擴容沒啥區別都是要新建一個擴容后的數組再講數據填進去:
- 以前的數組長度>0 則將長度翻一倍,閾值也翻一倍
- 如果以前數組長度≤0,閾值>0 ,則將舊的閾值給新的長度(初始化數組的情況)
- 如果以前數組長度、閾值都≤0,則新的數組將設置為默認長度以及閾值
- 上述都設置完成如果新的閾值還為0,則根據新的長度*擴容因子重新設置
- 然后就要遍歷舊的數組,將舊數組數據轉移到新的數組上面(轉移時數據需要重新計算下標)
- 舊數據里面的節點數據如果下一個指向為空,說明只有一個節點,直接轉移過去即可
- 不為空則可能是樹結構或者是鏈表,兩者都要遍歷切割為高低位節點(樹結構切割后還需判斷長度是否≤6,滿足則重新轉為鏈表結構),然后再賦值過去(下面說為什么要切割)
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table; // 舊的數組int oldCap = (oldTab == null) ? 0 : oldTab.length; //舊的數組長度int oldThr = threshold; // 舊的閾值int newCap, newThr = 0;if (oldCap > 0) {// 舊的數組長度>0的情況下// 如果原本的長度就已經是最大值了 就繼續返回舊的數組,并將閾值也設置成最大值if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) {// 長度翻一倍且符合條件的情況下 閾值也翻一倍newThr = oldThr << 1; // double threshold}}else if (oldThr > 0) { // initial capacity was placed in threshold// 舊的長度<=0 且 舊的閾值 >0 就把新的長度設置成舊的閾值newCap = oldThr;}else { // zero initial threshold signifies using defaults// 如果舊的長度、閾值都為0 就重新設置新的長度和閾值為默認值newCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}// 一系列操作后 新的閾值為0 就重新根據新的長度設置閾值if (newThr == 0) {float ft = (float)newCap * loadFactor; //新的數組長度*擴容因子newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr; // 擴容因子賦值替換//根據新的長度初始化新的數組@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab; //數組替換if (oldTab != null) {// 遍歷舊的節點數組for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null) {// 節點下一個指向為空說明只有一個值 直接賦值即可newTab[e.hash & (newCap - 1)] = e;}else if (e instanceof TreeNode) {// 說明節點已經變成樹了 進行樹的拆分((TreeNode<K, V>) e).split(this, newTab, j, oldCap);}else {// 說明節點是鏈表//低位鏈表:存放在擴容之后的數組的下標位置,與當前數組下標位置一致//loHead:低位鏈表頭節點//loTail低位鏈表尾節點Node<K,V> loHead = null, loTail = null;//高位鏈表,存放擴容之后的數組的下標位置,=原索引+擴容之前數組容量//hiHead:高位鏈表頭節點//hiTail:高位鏈表尾節點Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;//高位為0,放在低位鏈表if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}//高位為1,放在高位鏈表else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);//低位鏈表已成,將頭節點loHead指向在原位if (loTail != null) {loTail.next = null;newTab[j] = loHead;}//高位鏈表已成,將頭節點指向新索引if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}
問題一:為什么要切割分為高低位節點,直接轉過去不好嗎?
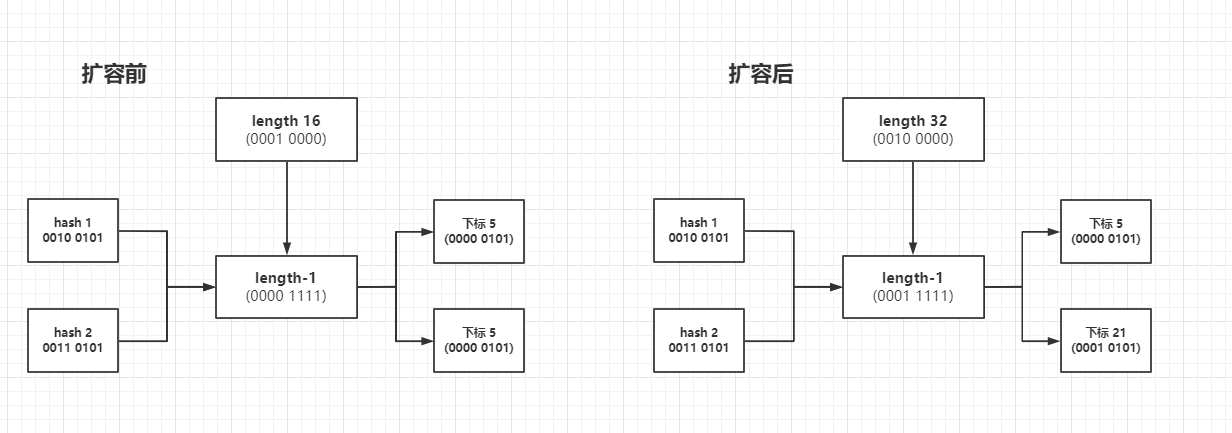
因為數組長度越小發生數組下標沖突的幾率越大,所以對于已經沖突形成鏈表或樹結構的下標數據需要重新根據新的數組長度計算數組下標值,再轉移到新數組;(這也是為什么數組長度≥64的時候才可以樹化,這之前都是選擇擴容)
如下圖所示:
兩個數據在擴容前是下標沖突的,下標都是5,在擴容后:高位為1的數據,下標已經變成了21,正好是之前的下標+原數組長度,這也是為什么上述源代碼里面高位鏈表在放到新數組里面的時候下標會加上數組長度的原因;這時候有人疑惑,你這是(hash&length-1)啊,源代碼里面可是(hash&length),細心的人已經發現了兩者是一樣的道理,前者是計算下標,后者是判斷是否高低位,下圖只是為了更好的理解
這也是把長度設計成2的n次方的牛逼之處
五、treeifyBin樹化
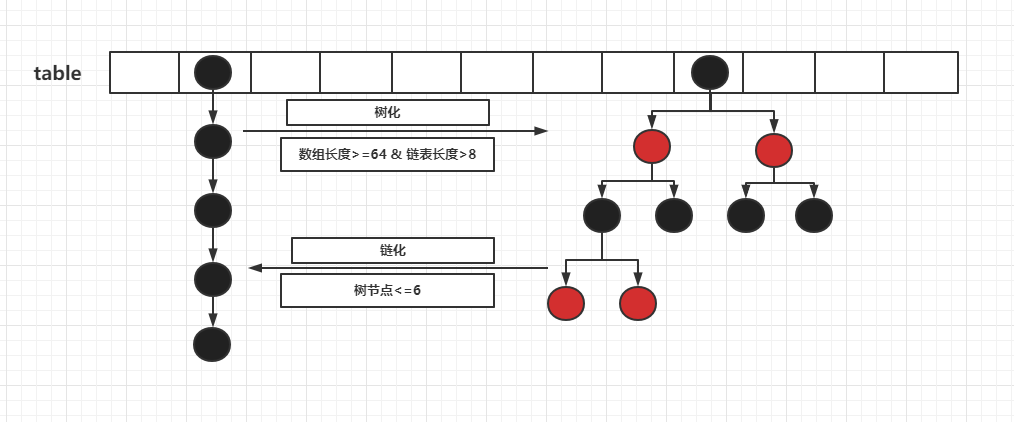
可以看到只有當數組長度≥64才會樹化,沒滿足的情況下是擴容操作
樹化的時候可以看到樹化前是將節點轉化成了樹節點,而且樹節點同時還是一個雙向鏈表
真正的樹化操作是treeify()方法(不深究,有興趣的可以研究下紅黑樹結構)
源代碼如下:
final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();else if ((e = tab[index = (n - 1) & hash]) != null) {TreeNode<K,V> hd = null, tl = null;do {//雙向鏈表TreeNode<K,V> p = replacementTreeNode(e, null);if (tl == null)hd = p;else {p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);if ((tab[index] = hd) != null)//真正的樹化操作hd.treeify(tab);}}
六、get操作
這個思路是一樣的看著HashMap的結構就能猜到獲取思路了:
- 判斷數組是否為空,節點是否存在
- 對比節點的hash與key值是否一致,一致則返回
- 判斷節點下一個指向是否為空,不為空則要判斷是否節點是樹結構
- 樹結構則獲取樹節點,鏈表則遍歷獲取節點
源代碼如下:
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;//判斷數組是否為空、節點是否存在if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) {//頭結點相同直接返回if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) {return first;}if ((e = first.next) != null) {//頭結點不同 且 下一個指向不為空 if (first instanceof TreeNode) {// 樹結構就獲取樹節點return ((TreeNode<K, V>) first).getTreeNode(hash, key);}//鏈表結構則遍歷鏈表do {if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {return e;}} while ((e = e.next) != null);}}return null;}
七、contains操作
containsKey
實際是get操作,get后判斷是否為空 **存在返回true 不存在返回:false **
源代碼如下:
public boolean containsKey(Object key) {return getNode(hash(key), key) != null;
}
containsValue
遍歷數組同時遍歷節點,存在相等的value 返回true 不存在返回 false
為什么節點的遍歷不需要考慮樹節點?
上面說過了樹節點其實也是雙向鏈表
源代碼如下:
public boolean containsValue(Object value) {Node<K,V>[] tab; V v;if ((tab = table) != null && size > 0) {//遍歷數組for (int i = 0; i < tab.length; ++i) {//遍歷節點 for (Node<K,V> e = tab[i]; e != null; e = e.next) {if ((v = e.value) == value ||(value != null && value.equals(v)))return true;}}}return false;}
HashTable
一、基礎常量以及結構
// 數組容器private transient Entry<?,?>[] table;// 容器容量private transient int count;// 擴容閾值private int threshold;// 擴容因子private float loadFactor;private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
和HashMap不同,HashTable只有數組+鏈表,結構如下:
二、構造方法
public Hashtable() {this(11, 0.75f);
}public Hashtable(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal Load: "+loadFactor);if (initialCapacity==0)initialCapacity = 1;this.loadFactor = loadFactor;table = new Entry<?,?>[initialCapacity];threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
可以看到初始化的時候就已經確定了容量大小和擴容大小,默認大小是11,默認擴容因子是0.75
三、put操作
- 根據hash獲取數組下標
- 節點已經存在則遍歷鏈表,如有相同的值則替換value ,否則 添加新節點
這個跟HashMap差不多的思路,就是沒了樹結構的操作,有兩個特點就是不允許value為null,而且方法用synchronized 所修飾
源代碼如下:
public synchronized V put(K key, V value) {if (value == null) {throw new NullPointerException();}Entry<?,?> tab[] = table;int hash = key.hashCode();// 獲取hash獲取數組下標 (數組長度取余)int index = (hash & 0x7FFFFFFF) % tab.length;Entry<K,V> entry = (Entry<K,V>)tab[index];// 節點不為空則遍歷鏈表 已存在則替換value值 for(; entry != null ; entry = entry.next) {if ((entry.hash == hash) && entry.key.equals(key)) {V old = entry.value;entry.value = value;return old;}}// 不存在則添加addEntry(hash, key, value, index);return null;
}private void addEntry(int hash, K key, V value, int index) {modCount++;Entry<?,?> tab[] = table;// 添加前先判斷是否需要擴容if (count >= threshold) {// 擴容rehash();// 獲取擴容后數組tab = table;hash = key.hashCode();// 擴容后重新計算需要添加節點的數組下標index = (hash & 0x7FFFFFFF) % tab.length;}// 創建節點Entry<K,V> e = (Entry<K,V>) tab[index];tab[index] = new Entry<>(hash, key, value, e);count++;}
四、rehash()擴容操作
HashTable擴容很簡單就是正常的數組擴容:
- 新建一個數組,容量為之前的2倍+1
- 重新計算擴容閾值
- 遍歷老的數組,重新計算每個節點的數組下標并放入新的數組
源代碼如下:
protected void rehash() {int oldCapacity = table.length;Entry<?,?>[] oldMap = table;// 翻倍且+1int newCapacity = (oldCapacity << 1) + 1;if (newCapacity - MAX_ARRAY_SIZE > 0) {if (oldCapacity == MAX_ARRAY_SIZE)// Keep running with MAX_ARRAY_SIZE bucketsreturn;newCapacity = MAX_ARRAY_SIZE;}Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];modCount++;// 重新計算擴容閾值threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);table = newMap;// 遍歷轉移數據for (int i = oldCapacity ; i-- > 0 ;) {for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {Entry<K,V> e = old;old = old.next;// 重新計算每個節點數組下標int index = (e.hash & 0x7FFFFFFF) % newCapacity;e.next = (Entry<K,V>)newMap[index];newMap[index] = e;}}}
五、get操作
根據hash取下標,遍歷對比取值,主要是被synchronized修飾
源代碼如下:
public synchronized V get(Object key) {Entry<?,?> tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {if ((e.hash == hash) && e.key.equals(key)) {return (V)e.value;}}return null;}
六、contains 操作
containsValue
遍歷數組內所有節點對比value值,被synchronized修飾
源代碼如下:
public boolean containsValue(Object value) {return contains(value);}public synchronized boolean contains(Object value) {if (value == null) {throw new NullPointerException();}Entry<?,?> tab[] = table;for (int i = tab.length ; i-- > 0 ;) {for (Entry<?,?> e = tab[i] ; e != null ; e = e.next) {if (e.value.equals(value)) {return true;}}}return false;}
containsKey
遍歷數組內所有節點對比key值,被synchronized修飾
源代碼如下:
public synchronized boolean containsKey(Object key) {Entry<?,?> tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {if ((e.hash == hash) && e.key.equals(key)) {return true;}}return false;}
總結
相比于HashMap,HashTable最大的區別就是線程安全,操作方法都被synchronized關鍵字所修飾,而且舍棄了樹結構的優化,在容量方面也不在是2的n次方了
ConcurrentHashmap
一、基本常量和結構
/** 節點的hash值,這里有三種特殊的,正常的>0 */
static final int MOVED = -1; // 表示該節點槽位正在擴容中
static final int TREEBIN = -2; // 表示該節點是樹節點
static final int RESERVED = -3; // hash for transient reservations// 默認容量大小
private static final int DEFAULT_CAPACITY = 16;
//默認擴容因子
private static final float LOAD_FACTOR = 0.75f;
//鏈表長度閾值 樹化條件
static final int TREEIFY_THRESHOLD = 8;
//樹中只有6個或一下轉化成鏈表
static final int UNTREEIFY_THRESHOLD = 6;
//樹化的條件之一 數組長度需要達到的值
static final int MIN_TREEIFY_CAPACITY = 64;
// 默認的容器數組
transient volatile Node<K,V>[] table;
// 輔助擴容時使用的數組
private transient volatile Node<K,V>[] nextTable;
//元素計數器
private transient volatile long baseCount;//表初始化和大小調整控件 有4種情況
//1.sizeCtl為0,代表數組未初始化, 且數組的初始容量為16
//2.sizeCtl為正數,如果數組未初始化,那么其記錄的是數組的初始容量,如果數組已經初始化,那么其記錄的是數組的擴容閾值
//3.sizeCtl為-1,表示數組正在進行初始化
//4.sizeCtl小于0,并且不是-1,表示數組正在擴容
private transient volatile int sizeCtl;// 擴容時使用 需要轉移槽位的索引
private transient volatile int transferIndex;// 在計算元素個數時,防并發的鎖(CAS ),跟下面那個東東配合
private transient volatile int cellsBusy;
// 計算元素個數時使用(防止并發,并發時每個線程都會把當前操作的槽位節點數放入里面最后累計)
// 配合baseCount 使用
private transient volatile CounterCell[] counterCells;
大部分都是常規的常量,但是要記住sizeCtl和節點的特殊hash值,這兩者在下面的操作里面扮演著關鍵角色,從結構上來看基本和HashMap一致 數組+鏈表/紅黑樹,如下:
因ConcurrentHashmap的操作思路基本與HashMap一致,所以建議先看看HashMap!
二、構造方法
這里只列舉三個常用的構造,不過也基本是全部了(容量計算就不說了)
- **無參構造:*啥也沒有,注意此時*sizeCtl 默認為0
- 初始化容量大小的構造:sizeCtl為計算后的容量,注意是擴大1.5倍后計算的
- 完整的帶參構造:同樣的sizeCtl為計算后的容量
這時候就會有個疑問,不管怎么初始化就算了個容量?擴容因子、擴容閾值啥都沒有,難道和HashMap一樣在第一次添加操作的時候,在初始化數組里面完成的?那就直接去看數組的初始化!
源代碼如下:
//無參構造
public ConcurrentHashMap() {}
//初始化容量大小的構造
public ConcurrentHashMap(int initialCapacity) {if (initialCapacity < 0) {throw new IllegalArgumentException();}int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :// 把傳參擴大了1.5倍后計算容量(變成最近的2的n次方數)tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));//sizeCtl=容量this.sizeCtl = cap;
}
//完整的帶參構造
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException();if (initialCapacity < concurrencyLevel) // Use at least as many binsinitialCapacity = concurrencyLevel; // as estimated threadslong size = (long)(1.0 + (long)initialCapacity / loadFactor);int cap = (size >= (long)MAXIMUM_CAPACITY) ?MAXIMUM_CAPACITY : tableSizeFor((int)size);//sizeCtl=容量this.sizeCtl = cap;
}
//計算容量的方法 往上找到最近的2的n次方數 比如:7變成8 10變成16
private static final int tableSizeFor(int c) {int n = c - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
三、initTable(容器初始化)
以CAS + 自旋的方式保證初始化的線程安全:
- sizeCtl<0 就代表有其他線程正在擴容或者初始化,所以讓出CPU ,讓其他線程先上
- 嘗試用CAS 把sizeCtl換成-1,失敗就繼續自旋
- 成功了就初始化容器與擴容閾值,有意思的是擴容閾值的計算(容量-1/4),這也就意味著在構造方法里面指定的擴容因子是不生效的,始終是0.75
此時sizeCtl為擴容閾值!
源代碼如下:
private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;// 自旋 只要容器數組為空 就不斷循環while ((tab = table) == null || tab.length == 0) {//sizeCtl,代表著初始化資源或者擴容資源的鎖,必須要獲取到該鎖才允許進行初始化或者擴容的操作if ((sc = sizeCtl) < 0)//放棄當前cpu的使用權,讓出時間片,線程計入就緒狀態參與競爭Thread.yield(); //CAS 比較并嘗試將sizeCtl替換成-1,如果失敗則繼續循環 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {//進行一次double check 防止在進入分支前,容器發生了變更if ((tab = table) == null || tab.length == 0) {int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")//初始化容器Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = tab = nt;//容量-容量/4 == 容量*3/4 == 擴容閾值(擴容因子0.75)sc = n - (n >>> 2);}} finally {// 此時sizeCtl為擴容閾值sizeCtl = sc;}break;}}return tab;}
四、put操作
整體邏輯和HashMap差不多:1.計算hash 2.是否初始化數組 3.是否直接插入 4. 是否插入鏈表/紅黑樹
但是加入了線程安全的操作保障(CAS+自旋+synchronized,數組操作全是內存的偏移量 ):
- 計算hash值后,直接死循環(自旋)
- 判斷容器數組是否為空,空則初始化容器數組
- 根據hash計算數組下標【(length-1)&hash】,再結合偏移量從數組中取值
- 值為空,說明槽位還沒節點,所以可以直接放入該下標對應的槽位(CAS+自旋放入)
- 值不為空,說明槽位已經被占了(下標沖突了),給該槽位加鎖(槽位第一個節點),判斷鏈表和樹插入
- 鏈表的話就直接尾部插入,樹的話就樹節點的方式插入
- 完事還要判斷鏈條長度是否需要樹化
- 最后對比容器元素個數是否達到擴容閾值,是否需要擴容
源代碼如下:
final V putVal(K key, V value, boolean onlyIfAbsent) {// 不允許為nullif (key == null || value == null) throw new NullPointerException();// 計算hash值(不深究)int hash = spread(key.hashCode());int binCount = 0;// 自旋 因為下面有CAS操作for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// 數組為空 長度為0 就要初始化數組if (tab == null || (n = tab.length) == 0)// 初始化數組(上面說過了)tab = initTable();// 計算下標 并獲取數組中的節點(tabAt就是利用偏移量*下標來獲取數組里面的值)else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 下標所在的值為null說明槽位為空 所以就可以把值放進去// 創建新的節點 利用CAS的方式 放入數組 (casTabAt就是CAS內存的偏移量)// 放入成功就結束了,CAS失敗就會自旋if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))break; }else if ((fh = f.hash) == MOVED)// 說明有其他線程正在擴容中 所以我們去協助擴容(之后說)tab = helpTransfer(tab, f);else {// 到這說明下標沖突了 所以要判斷插入鏈表或者插入樹V oldVal = null;// 給頭節點上鎖synchronized (f) {// CAS 再確認一次頭節點有沒有變if (tabAt(tab, i) == f) {// 節點的hash >0 說明是正常要插入鏈表里面(樹節點的hash是-2)if (fh >= 0) {binCount = 1;// 遍歷鏈表 把新節點插入到尾部// 這里跟hashMap一樣 因為前面已經上鎖了 所以是安全的for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key, value, null);break;}}}else if (f instanceof TreeBin) {// 這里就是樹結構了 所以要插入樹節點(看過HashMap的非常熟悉吧)Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}// 到這就插入完成啦 所以要判斷鏈表上節點個數是否需要樹化if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)// 鏈表樹化treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}// 最后要判斷容量是否到達擴容閾值 是否需要擴容// 這里和HashMap不一樣 我們后面單獨提出來說addCount(1L, binCount);return null;}
addCount
一個a++ 的操作搞這么麻煩干嘛?用原子類計數或者加把鎖不就搞定了?😭😭😭😭😭😭😭😭好了,我已經幫你們吐槽一次了
為什么不這樣做呢?原子類是采用CAS+自旋保證的計數安全,但是當競爭激烈的時候,會導致多線程頻繁自旋阻塞,加鎖那更加不用說了,所以呀我們來學習學習大佬是怎么做的?
📌首先請出兩個主角counterCells數組和baseCount計數器,baseCount就是正常的計數器,采用CAS的方式+1,如果已經存在并發競爭關系了,那就會把值放入counterCells數組中,數組長度剛開始為2,后續擴容為2倍擴容,下標方式計算為【 線程hash&(length-1】,放入的時候值已經存在了就采用CAS使其+1,CAS失敗了那就擴容并修改線程的Hash 重新放入一次,最后的size就是baseCount+counterCells數組內的所有數
該過程的偽思想圖(不是addCount()流程圖)如下:
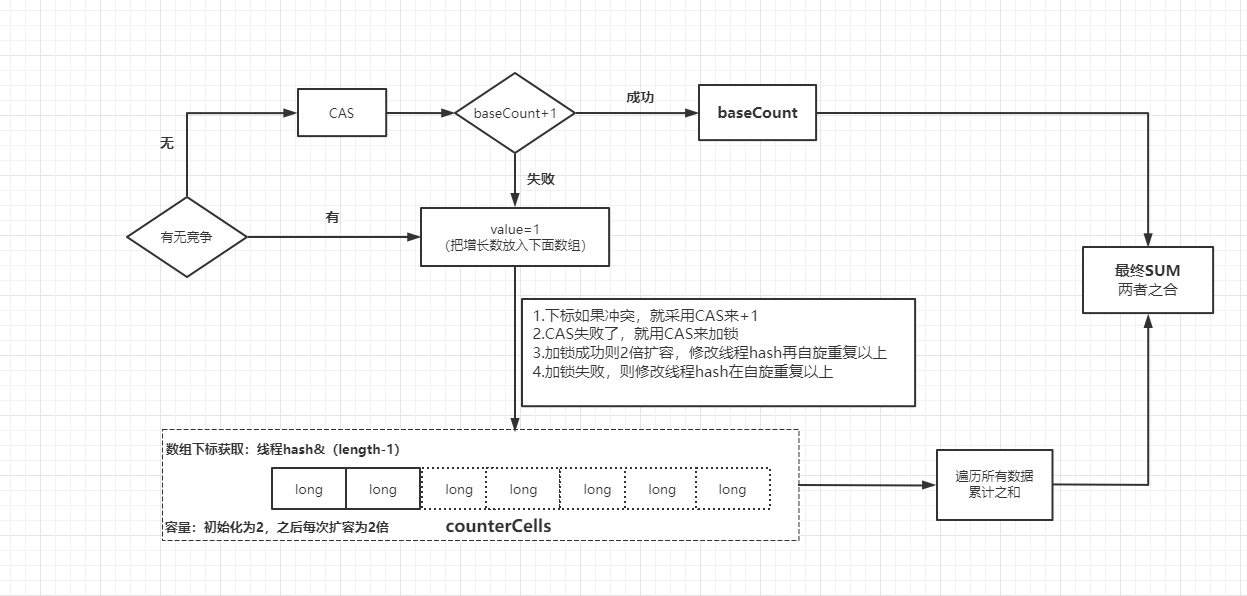
一定要搞清楚上述的思想哈,直接看代碼是很難懂的,搞懂上面的思想后,我們再代入到代碼看:
- CounterCell[] 數組不為空就代表已經存在競爭了,CAS baseCount+1失敗也代表有并發了
- ThreadLocalRandom.getProbe() 就是當前線程的hash ,根據線程hash計算下標沒取到值就進入fullAddCount()方法具體操作了
- 根據線程hash取到值但是CAS失敗了,存在并發也要進去fullAddCount()方法
- fullAddCount()里面最核心的在上面圖里面已經說了,就不再一一過了
- 上面完事了就計算一次總計s =(baseCount+counterCells數組內的所有數)
- 然后就拿著總計去對比此時的擴容閾值sizeCtl,≥就要擴容了嘛,所以自旋直至擴容結束
- 擴容又是個蛋疼的操作,這里先記著要擴容,擴容搞懂了,自然就懂了這里的處理是干嘛的了
源代碼如下:
// x就是1 ,check 就是容器數組槽位下的節點數
private final void addCount(long x, int check) {CounterCell[] as; long b, s;// CounterCell[] 數組不為空(已經存在競爭) 或者 baseCount總計累加失敗// 說明之前已經存在并發的情況了if ((as = counterCells) != null ||!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {CounterCell a; long v; int m;//標識是否有多線程競爭 true表示無并發 下面CAS失敗了就是false 有并發boolean uncontended = true;//當CounterCell[] 數組為空 || 長度為0//或者當前線程對應的CounterCell[] 槽位的元素為空(為空我肯定要把值放進去嘛)//或者當前線程對應的CounterCell[] 槽位的元素不為空,但是CAS累加失敗(有并發)if (as == null || (m = as.length - 1) < 0 ||(a = as[ThreadLocalRandom.getProbe() & m]) == null ||!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {// 經過上面判斷說明有并發,所以在這里面處理存在并發情況的的值(不多說了)// 這個就是有關放入CounterCell[] 數組的流程操作,核心的其實上面的圖里面已經寫了fullAddCount(x, uncontended);return;}if (check <= 1)return;// 計算一次容器數組內元素個數總計 (baseCount+counterCells數組內的所有數)s = sumCount();}// 到了這說明不管有沒有并發 元素總計也已經算好啦 此時 s變量就是總計數if (check >= 0) {Node<K,V>[] tab, nt; int n, sc;// 總計數(s)>=擴容閾值(sizeCtl) 且 容器數組不為空 (說明要擴容啦)// 滿足條件循環 (自旋) 直至擴容結束while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&(n = tab.length) < MAXIMUM_CAPACITY) {// 獲取一個很大的正數 int rs = resizeStamp(n);// 注意此時 sc 就是 sizeCtl,<0說明已經有其他線程正在擴容中了if (sc < 0) {//擴容結束或者擴容線程數達到最大值或者擴容后的數組為null或者沒有更多的桶位需要轉移,結束操作if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||transferIndex <= 0){break;}//上面判斷完到這里說明還沒擴容完,把 sizeCtl +1 代表多了一個線程協助擴容if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))// CAS 加入成功了,我們就去協助擴容transfer(tab, nt);}else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))// 注意此時sizeCtl 已經被CAS替換成了一個負數(不為-1)// 擴容操作(下面說)transfer(tab, null);// 計算一次容器數組內元素個數總計 (baseCount+counterCells數組內的所有數)s = sumCount();}}
}
五、transfer 擴容操作
雖然擴容有點繞,但是對數據的處理思想和HashMap差不多,都需要對鏈表/樹節點重新計算hash然后再放入新數組,但由于是線程安全又要考慮性能,所以加了一個分槽位轉移的操作,老規矩先上圖理解一下再看代碼:
等于是把一個數組分成了幾份,每個線程都處理一份(實際不是均分),如下假設每個線程都處理4個槽位,每處理一個槽位就把槽位標記成fwd 代表已處理,槽位如果有數據,就需要對里面的數據重新根據新數組長度計算一下下標值,然后放入新數組; 注意:在實際代碼中,是每進入一次transfer擴容方法就分配一次處理的任務,外部死循環直至槽位全部處理完,所以如果是單線程處理,會進入多次transfer擴容方法
偽思想如下圖:
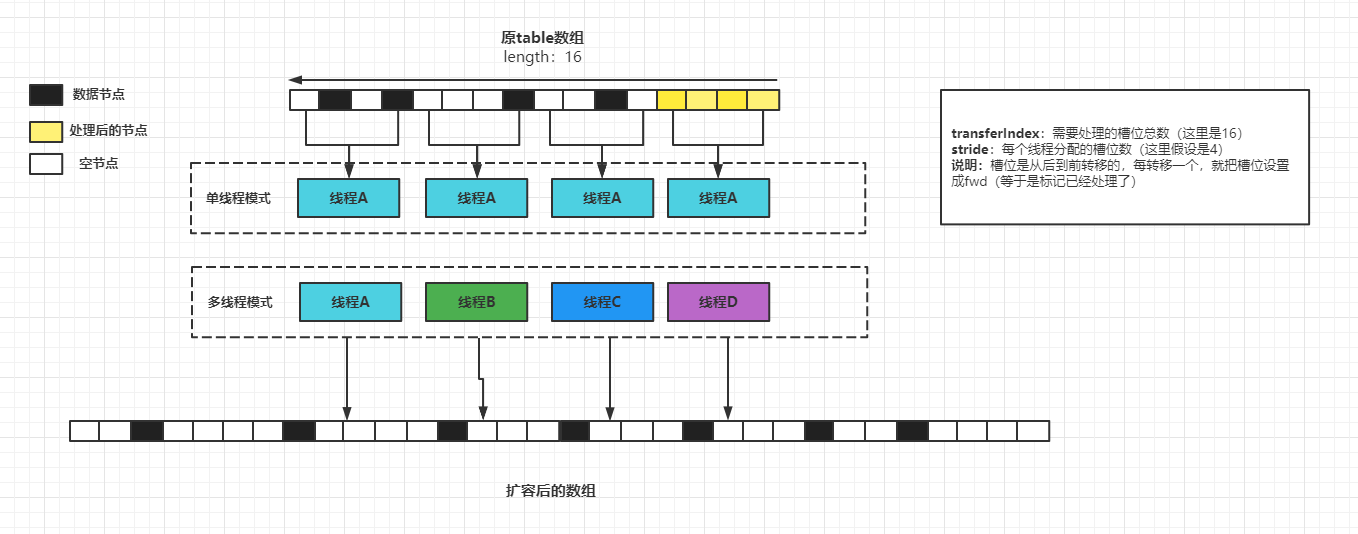
理解完上面的內容后,就可以代入看下面的代碼了:
- 根據CPU核心數分配每個線程進來需要處理的槽位數量:stride
- 第一個進來擴容的線程初始化一些參數:新數組(nextTable)、轉移的總槽位數量(transferIndex)
- 死循環 也就是自旋,因為下面有CAS操作
- 內循環,為了給線程分配槽位以及線程遍歷處理剛分配的槽位
- 每處理一個槽位需要把該槽位標記為ForwardingNode特殊節點,表示已處理
- 處理有數據的槽位時,需要把這些數據根據新數組重新計算一遍下標然后放入新數組中
- 每個線程處理完自己的任務會把sizeCtl-1,當該值與剛進入擴容的時候一致則代表擴容完成(因為進入時會+1)
- finishing為true代表擴容完成,然后把新數組賦值給容器數組,并設置新的擴容閾值sizeCtl
- 最后transferIndex為0,nextTable 為null ,外部進入transfer方法的死循環也會結束,完成擴容!
搞懂這里之后再回過頭看看addCount后面的擴容判斷操作是不是就一些豁然開朗了
(跳過了鏈表/樹 的數據處理,可以看看HashMap,主要是理解高低位賦值這個思想)
源代碼如下:
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {int n = tab.length, stride;//每個線程處理槽位的最小數目,可以看出核數越高步長越小,最小16個if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)stride = MIN_TRANSFER_STRIDE; // subdivide range// 第一個進來的擴容的線程nextTab肯定為空if (nextTab == null) { try {// 2倍擴容 Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];nextTab = nt;} catch (Throwable ex) { // try to cope with OOMEsizeCtl = Integer.MAX_VALUE;return;}// 擴容后的新數組nextTable = nextTab;// 需要轉移的槽位總數量transferIndex = n;}int nextn = nextTab.length;//擴容時的特殊節點,標明此節點正在進行遷移ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);boolean advance = true;//所有的槽位是否都已遷移完成。boolean finishing = false; // 死循環 自旋 (這個i 就是待轉移數組的下標索引)// 整個轉移過程是從數組的尾部到頭部for (int i = 0, bound = 0;;) {Node<K,V> f; int fh;//此循環的作用是確定當前線程要遷移的桶的范圍或通過更新i的值確定當前范圍內下一個要處理的節點。while (advance) {int nextIndex, nextBound;// 這一步就是為了更新 數組下標索引 iif (--i >= bound || finishing)advance = false;else if ((nextIndex = transferIndex) <= 0) {// 表示所有槽位都已經處理完了i = -1;advance = false;}else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {// 分配每個線程需要處理的槽位數 從頭分配到尾部bound = nextBound;// 設置待轉移數組的下標索引i = nextIndex - 1;advance = false;}}// 當前線程自己的活已經做完或所有線程的活都已做完if (i < 0 || i >= n || i + n >= nextn) {int sc;// 擴容結束標識if (finishing) {// 擴容結束后把擴容數組置為nullnextTable = null;// 把擴容后的數組給容器數組table = nextTab;// 設置新的擴容閾值,新容量的0.75sizeCtl = (n << 1) - (n >>> 1);return;}// 每有一個線程做完活 就把sizeCtl-1 (因為每有一個線程協助sizeCtl就會+1)if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {// 還記得剛擴容時sizeCtl 的值嗎?// 這里就是判斷sizeCtl是否與擴容前的值相等if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)// 不相等直接返回return;// 相等就代表擴容結束了 最后檢查一遍finishing = advance = true;i = n; // recheck before commit}}else if ((f = tabAt(tab, i)) == null)// CAS 把該索引處設置成ForwardingNode ,也就是hash是-1的代表擴容中// 因為擴容的同時,原數組還是可以put操作的,所以盡管此處為null 也要標記成fwd節點,表示已經處理了advance = casTabAt(tab, i, null, fwd);else if ((fh = f.hash) == MOVED)// 節點hash為-1 代表已經處理過了advance = true; // already processedelse {// 到了這說明該槽位有數據要遷移了,所以先上個鎖synchronized (f) {// 二次確認if (tabAt(tab, i) == f) {Node<K,V> ln, hn;// 鏈表處理if (fh >= 0) {int runBit = fh & n;Node<K,V> lastRun = f;for (Node<K,V> p = f.next; p != null; p = p.next) {int b = p.hash & n;if (b != runBit) {runBit = b;lastRun = p;}}if (runBit == 0) {ln = lastRun;hn = null;}else {hn = lastRun;ln = null;}for (Node<K,V> p = f; p != lastRun; p = p.next) {int ph = p.hash; K pk = p.key; V pv = p.val;if ((ph & n) == 0)ln = new Node<K,V>(ph, pk, pv, ln);elsehn = new Node<K,V>(ph, pk, pv, hn);}//低位鏈表放在i處setTabAt(nextTab, i, ln);//高位鏈表放在i+n處setTabAt(nextTab, i + n, hn);//在原table中設置ForwardingNode節點以提示該槽位處理完成setTabAt(tab, i, fwd);advance = true;}else if (f instanceof TreeBin) {// 樹節點處理TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> lo = null, loTail = null;TreeNode<K,V> hi = null, hiTail = null;int lc = 0, hc = 0;for (Node<K,V> e = t.first; e != null; e = e.next) {int h = e.hash;TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null);if ((h & n) == 0) {if ((p.prev = loTail) == null)lo = p;elseloTail.next = p;loTail = p;++lc;}else {if ((p.prev = hiTail) == null)hi = p;elsehiTail.next = p;hiTail = p;++hc;}}//如果拆分后的樹的節點數量已經少于6個就需要重新轉化為鏈表ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :(hc != 0) ? new TreeBin<K,V>(lo) : t;hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :(lc != 0) ? new TreeBin<K,V>(hi) : t;//低位放在i處setTabAt(nextTab, i, ln);//高位放在i+n處setTabAt(nextTab, i + n, hn);//在原table中設置ForwardingNode節點以提示該槽位處理完成setTabAt(tab, i, fwd);advance = true;}}}}}}
六、helpTransfer協助擴容
理解的上面的擴容后,就可以知道協助擴容其實最后調用的也是transfer()擴容方法,而且這一段和addCount()后面那一段是不是基本一致?都是進去擴容方法領取一部分槽位轉移,然后自旋直至擴容結束
源代碼如下:
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {Node<K,V>[] nextTab; int sc;// 節點是fwd 節點說明正在擴容 且 nextTable數組不為空if (tab != null && (f instanceof ForwardingNode) &&(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {// 獲取一個很大的正數int rs = resizeStamp(tab.length);//死循環自旋直至擴容結束while (nextTab == nextTable && table == tab &&(sc = sizeCtl) < 0) {//擴容結束或者擴容線程數達到最大值或者擴容后的數組為null或者沒有更多的桶位需要轉移,結束操作if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || transferIndex <= 0)break;//上面判斷完到這里說明還沒擴容完,把 sizeCtl +1 代表多了一個線程協助擴容if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {// 擴容transfer(tab, nextTab);break;}}return nextTab;}return table;
}
七、get操作
與其他操作相比,get操作可以說是最低調的了,并沒有什么CAS或者加鎖的操作,邏輯也基本很簡單:
- 根據hash算出下標然后去數組查找,沒找到就返回null
- 找到了,就對比key值,一致則返回
- 不一致判斷hash是否<0,否則遍歷鏈表找對應的值返回
- hash<0的節點,說明是樹節點或者是fwd節點(擴容中的),樹節點就調用樹節點的find方法
- fwd節點就需要調用fwd節點的find的方法(下面貼出了fwd的find方法)
源代碼如下:
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;//計算hash值int h = spread(key.hashCode());//根據hash值確定節點位置if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {//如果搜索到的節點key與傳入的key相同且不為null,直接返回這個節點 if ((eh = e.hash) == h) {if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}//如果eh<0(hash <0) 說明這個節點在樹上或者在擴容中并且轉移到新數組了//所以這個find方法是樹節點的find方法或者是fwd節點的find方法else if (eh < 0)return (p = e.find(h, key)) != null ? p.val : null;//否則遍歷鏈表 找到對應的值并返回while ((e = e.next) != null) {if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null;
}// 這是ForwardingNode節點的find方法
Node<K,V> find(int h, Object k) {// 注意這里的nextTable 是擴容時傳進來的outer: for (Node<K,V>[] tab = nextTable;;) {Node<K,V> e; int n;// 沒找到直接返回 nullif (k == null || tab == null || (n = tab.length) == 0 ||(e = tabAt(tab, (n - 1) & h)) == null)return null;// 自旋for (;;) {int eh; K ek;// 找到了就返回節點if ((eh = e.hash) == h &&((ek = e.key) == k || (ek != null && k.equals(ek))))return e;// 同樣要判斷是樹節點還是ForwardingNode節點if (eh < 0) {//ForwardingNode節點就繼續往里找if (e instanceof ForwardingNode) {tab = ((ForwardingNode<K,V>)e).nextTable;continue outer;}else// 樹節點 就調用數節點的find方法return e.find(h, k);}// 沒找到就返回nullif ((e = e.next) == null)return null;}}
}
總體邏輯呢和HashMap差不多,唯一的區別啊就是有可能數組正處于擴容中呢?在擴容中的數組別忘了槽位的數據轉移完了就會變成ForwardingNode節點,所以我get也可能拿到fwd節點啊,怎么辦呢?只能去轉移后的數組里面取;
注意:轉移后的數組不是全局變量nextTable,而是在擴容里面new ForwardingNode的時候傳入了一個數組(別不信,截圖為證,也可以回頭好好看看擴容過程體會一下哈)
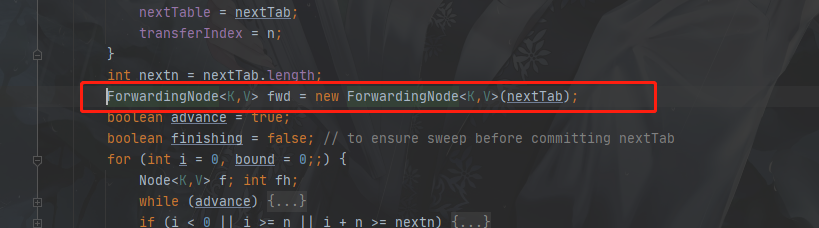
八、size 操作
前面在addCount()里面說過了,對一個數的累計都做了一個性能的優化,所以獲取時也不像其他容器一樣那么簡單了,這里需要 用baseCount+counterCells數組內的所有數(搞懂addCount方法后也很簡單對吧)
源代碼如下:
public int size() {// 總和的計算long n = sumCount();return ((n < 0L) ? 0 :(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :(int)n);
}final long sumCount() {CounterCell[] as = counterCells; CounterCell a;long sum = baseCount;if (as != null) {// 遍歷CounterCell[]數組 把數全累加起來for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;
}
九、總結
好了核心操作基本都結束了,對了,還有個remove操作(這里就不貼了,理解完上面的在自己去看看吧,會發現哇原來這么簡單),我覺得也沒啥好總結的,綜合來說使用了volatile+synchronized+CAS+自旋保證了線程安全,synchronized鎖的細粒度+分槽位可協助擴容+ 計數器特殊處理 極大程度的保證了性能的提升
下面提幾個問題,輔助大家鞏固一下吧:
- 1.ConcurrentHashMap是怎么判斷正在擴容中的?
- 2.擴容期間在未遷移到的槽位中插入數據會發生什么?
- 3.為什么get操作不需要加鎖?
- 4.擴容過程中get操作受影響嗎?怎么處理的?
- 5.ConcurrentHashMap在性能優化方面做了那些事?
- 6.擴容的時候同時發生了remove會有影響嗎?怎么處理的?
- 7.數組變量都被volatile修飾了,按理說取值就是線程安全的,為什么在數組取值的時候還需要用內存偏移量呢?
ArrayList
一、基礎常量以及結構
// 默認數組長度
private static final int DEFAULT_CAPACITY = 10;// 數組容器
transient Object[] elementData; // 長度設置成0的默認數組容器
private static final Object[] EMPTY_ELEMENTDATA = {};// 默認的數組
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};// 容器現有元素數量
private int size;
ArrayList用到的存儲結構就是數組,我們看常量有兩個空的數組常量,為什么會有兩個?(下面再說)

二、構造方法
初始化很簡單,沒有什么擴容閾值,就初始化一個數組,值得注意的就是默認的初始化和參數為0的初始化不太一樣,用了兩個不一樣的空數組,就是上面說的兩個空數組常量,所以這里猜測目的就是為了區分指定初始化容量為0的容器和默認初始化的容器。(目的是什么?有什么用?下面說)
源代碼如下:
public ArrayList(int initialCapacity) {if (initialCapacity > 0) {this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);}
}public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
三、add操作
有兩個add方法
不帶索引的: 1.擴容判斷 2.尾部賦值
帶索引的:1.下標校驗 2.擴容判斷 3.數組數據后移 4.指定位置賦值
源代碼如下:
// 默認添加 直接數組尾部添加
public boolean add(E e) {// 擴容判斷ensureCapacityInternal(size + 1); // Increments modCount!!// 賦值elementData[size++] = e;return true;
}
// 指定下標位置添加
public void add(int index, E element) {// 下標校驗rangeCheckForAdd(index);// 擴容判斷ensureCapacityInternal(size + 1); // Increments modCount!!// 數組數據移位System.arraycopy(elementData, index, elementData, index + 1, size - index);// 指定位置賦值elementData[index] = element;size++;
}
private void rangeCheckForAdd(int index) {if (index > size || index < 0)throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}private void ensureCapacityInternal(int minCapacity) {// 當數組是無參構造方法生成的默認數組的時候,這里會給一個默認的數組大小 10if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}ensureExplicitCapacity(minCapacity);
}private void ensureExplicitCapacity(int minCapacity) {modCount++;// 容量大于數組長度 就擴容if (minCapacity - elementData.length > 0)grow(minCapacity);
}
問題一:兩個默認的常量空數組有什么作用?
用于區分指定0容量初始化和默認初始化兩種情況,無參構造初始化的時候并沒有初始化默認的數組長度為10,而是在第一次add操作的時候擴容里面判斷賦值的,這里的判斷就是通過兩個數組的對比來實現的
指定0容量初始化:在第一次add操作后,數組長度為1
ArrayList<Object> objects = new ArrayList<>(0);
objects.add(1);

默認初始化:在第一次add操作后,數組長度為10
ArrayList<Object> objects = new ArrayList<>();
objects.add(1);

問題二:指定下標賦值的時候,數組數據是怎么移位的?
是利用最底層的**System.arraycopy()方法,常見的ArrayList.toArray()**方法也是利用的這個
源代碼如下:
/*** @param src 源數組* @param srcPos 源數組起始位置* @param dest 目標數組* @param destPos 目標數組的起始位置* @param length 源數組要復制的長度
*/
public static native void arraycopy(Object src, int srcPos,Object dest, int destPos,int length);
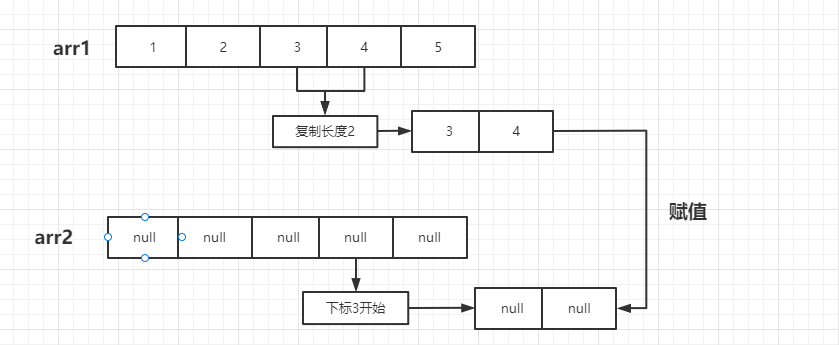
這是個數組復制的方法,簡單來說就是把源數組中的一段連續的數據截取出來,復制到目標數組的指定位置中,如下面例子:
Integer[] arr1 = { 1, 2, 3, 4, 5 };
Integer[] arr2 = new Integer[5];
System.arraycopy(arr1, 2, arr2, 3, 2);
System.out.println(Arrays.toString(arr2));
// 結果輸出 arr2為:
[null, null, null, 3, 4]
從源數組中找出從下標2開始連續兩個數,復制到目標數組的下標3處,ArrayList里面同理從原下標開始往后所有數據都復制,再賦值到數組原下標+1的位置,就完成了整體數據往后移一位的效果了
圖示只是為了更好理解,不是原理圖:
四、grow()擴容操作
這里需要注意的就是每次擴容都是原來的1.5倍,會創建一個新的數組,然后再利用System.arraycopy() 將原數據復制過去
源代碼如下:
private void grow(int minCapacity) {// 舊數組長度int oldCapacity = elementData.length;// 擴容1.5倍 int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// 擴容需要將老數據轉移到新數組上 原理上面說過了 elementData = Arrays.copyOf(elementData, newCapacity);
}
// 容量飽和策略 就是容量達到最大值的處理
private static int hugeCapacity(int minCapacity) {if (minCapacity < 0) // overflowthrow new OutOfMemoryError();return (minCapacity > MAX_ARRAY_SIZE) ?Integer.MAX_VALUE :MAX_ARRAY_SIZE;
}
五、get 操作
這個不多說了,數組取值 簡單的一批
源代碼如下:
public E get(int index) {// 下標校驗 不能超過現有容量rangeCheck(index);// 根據下標數組取值return elementData(index);
}
E elementData(int index) {return (E) elementData[index];
}
六、contains操作
遍歷對比元素,以后要有人問怎么優化,二分查找法丟過去
源代碼如下:
public boolean contains(Object o) {// 下標存在即 true return indexOf(o) >= 0;
}//遍歷取下標
public int indexOf(Object o) {if (o == null) {for (int i = 0; i < size; i++)if (elementData[i]==null)return i;} else {for (int i = 0; i < size; i++)if (o.equals(elementData[i]))return i;}return -1;
}
七、remove操作
利用System.arraycopy(),最后把尾部元素置null
源代碼如下:
public E remove(int index) {rangeCheck(index);modCount++;E oldValue = elementData(index);int numMoved = size - index - 1;if (numMoved > 0)System.arraycopy(elementData, index+1, elementData, index,numMoved);elementData[--size] = null; // clear to let GC do its workreturn oldValue;}
LinkedList
一、基本結構
// 元素的個數 (鏈表長度)
transient int size = 0;// 頭結點
transient Node<E> first;// 尾結點
transient Node<E> last;//節點類 定義如下
private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}
}
從上面源代碼可知,底層結構是鏈表,而且是一個雙向鏈表,這也就意味著不會再有容量的限制,沒了擴容操作,但自身不僅僅實現了List相關操作還實現了Deque相關操作,我們以List操作為主
二、add操作
采用尾插法,尾部為空時說明鏈表為空,新節點會同時成為尾節點和頭節點,尾部不為空,就把尾結點指向到新節點,最后鏈表長度+1
源代碼如下:
public boolean add(E e) {linkLast(e);return true;
}
void linkLast(E e) {final Node<E> l = last;// 新建一個節點final Node<E> newNode = new Node<>(l, e, null);// 尾部插入 新節點直接成為尾部節點last = newNode;// 判斷之前鏈表尾部是否為空if (l == null)// 為空說明鏈表內還沒節點 新節點直接作為頭節點first = newNode;else// 不為空說明鏈表已經有節點了 把原尾部節點指向到下一個新節點l.next = newNode;// 元素個數+1(鏈表長度+1)size++;modCount++;
}
因為是list所以同樣可以直接指定位置插入元素,操作也很簡單,先找到原來的節點,然后把新節點放進去,改變原節點的上一個指向,總得來說原來的節點下移
源代碼如下:
public void add(int index, E element) {// 索引校驗 不能<0 或者 >鏈表長度checkPositionIndex(index);// 判斷是否在尾部插入 if (index == size)// 同上尾插法linkLast(element);elselinkBefore(element, node(index));
}
// 找到索引原有位置的節點
Node<E> node(int index) {// 判斷索引位置是在鏈表上半部還是在下半部if (index < (size >> 1)) {// 上半部從頭節點開始遍歷Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {// 下半部從尾節點開始遍歷Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}
}
void linkBefore(E e, Node<E> succ) {// 獲取原節點的上一個節點final Node<E> pred = succ.prev;// 新建一個節點 原節點下移final Node<E> newNode = new Node<>(pred, e, succ);succ.prev = newNode;if (pred == null)first = newNode;elsepred.next = newNode;size++;modCount++;
}
三、get操作
就是上面說的分半然后遍歷
源代碼如下:
public E get(int index) {checkElementIndex(index);return node(index).item;
}
// 找到索引原有位置的節點
Node<E> node(int index) {// 判斷索引位置是在鏈表上半部還是在下半部if (index < (size >> 1)) {// 上半部從頭節點開始遍歷Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {// 下半部從尾節點開始遍歷Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}
}
四、set操作
找到節點,然后把節點內部的值替換
源代碼如下:
public E set(int index, E element) {checkElementIndex(index);//找到索引對應的節點Node<E> x = node(index);E oldVal = x.item;//把節點對應的值替換x.item = element;return oldVal;
}
五、contains操作
因為是允許存在null值的,所以遍歷的時候要兩種情況遍歷,一種是遍歷null值,一種是對比值,遍歷找值對應節點的索引,沒找到就返回-1 即false不存在
源代碼如下:
public boolean contains(Object o) {return indexOf(o) != -1;
}
public int indexOf(Object o) {int index = 0;if (o == null) {//遍歷鏈表 找null值for (Node<E> x = first; x != null; x = x.next) {if (x.item == null)return index;index++;}} else {//遍歷鏈表 for (Node<E> x = first; x != null; x = x.next) {if (o.equals(x.item))return index;index++;}}return -1;
}
六、remove操作
分半查找到元素,然后修改指向
源代碼如下:
public boolean remove(Object o) {if (o == null) {for (Node<E> x = first; x != null; x = x.next) {if (x.item == null) {unlink(x);return true;}}} else {for (Node<E> x = first; x != null; x = x.next) {if (o.equals(x.item)) {unlink(x);return true;}}}return false;
}E unlink(Node<E> x) {// assert x != null;final E element = x.item;final Node<E> next = x.next;final Node<E> prev = x.prev;if (prev == null) {// 上指向為空說明該節點是頭節點 所以頭節點要改成要移除節點的下指向節點 first = next;} else {prev.next = next;x.prev = null;}if (next == null) {// 下指向為空說明該節點是尾節點 所以尾節點要改成要移除節點的上指向節點last = prev;} else {next.prev = prev;x.next = null;}// 把值置為null 便于GCx.item = null;// 長度-1size--;modCount++;return element;
}
CopyOnWriteArrayList
一、基礎常量和結構
// 鎖
final transient ReentrantLock lock = new ReentrantLock();// 空數組
private transient volatile Object[] array;
可以看到底層依舊還是數組,但是沒了默認大小和容量大小的變量了,而且數組容器被volatile關鍵字修飾,同時還多了一把鎖,這同時說明了CopyOnWriteArrayList是線程安全的設計
為什么沒有默認大小了呢?難道不需要判斷擴容了?接著往下看
二、構造方法
public CopyOnWriteArrayList() {setArray(new Object[0]);
}
final void setArray(Object[] a) {array = a;
}
// 帶參構造
public CopyOnWriteArrayList(E[] toCopyIn) {setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}
兩個構造方法:
- 默認的:直接創建了個空數組然后賦值給了容器數組
- 帶參的:把傳參的數組數據賦值到了一個新數組上面然后把新數組給了容器數組(對Arrays.copyOf不熟的可以看看 上篇ArrayList介紹 )
為什么帶參的方法要搞一個新的數組出來然后在賦值給容器數組呢?
因為數組賦值,不是值傳遞,傳遞后依舊會受原數組的影響,如下:(不清楚的了解一下值傳遞和地址傳遞)
Object[] aa=new Object[]{1,2};
Object[] aa1=aa;
System.out.println("改變前:"+aa1[0]);
aa[0]=3;
System.out.println("改變后:"+aa1[0]);//結果如下:
改變前:1
改變后:3
ps:改的是aa數組
三、add操作
默認添加
整個過程邏輯很簡單:
- 加鎖,獲取容器數組
- 創建一個長度+1 的新數組,并把之前數組的數據復制過去
- 然后新數組尾部賦值,并把新數組重新賦值給容器數組
因為每次添加都會創建一個長度+1的新數組,所以并不需要擴容了
線程安全方面: 容器array是volatile修飾的,即set和get方法都是線程安全的,整個添加過程上了鎖,所以整體是通過volatile和lock來保證的線程安全
性能方面: 可以看到舍棄了擴容操作,但每次添加都會創建個新的數組并復制數據過去,這個過程是非常耗時的,所以并不合適頻繁寫入的場景
源代碼如下:
public boolean add(E e) {final ReentrantLock lock = this.lock;// 加鎖lock.lock();try {// 獲取容器數組Object[] elements = getArray();// 獲取容器數組長度int len = elements.length;// 創建一個長度+1的新數組 并把之前的數據復制到新數組Object[] newElements = Arrays.copyOf(elements, len + 1);// 新數組尾部賦值newElements[len] = e;// 把新數組重新賦值給容器數組setArray(newElements);return true;} finally {lock.unlock();}
}
指定位置插入
同樣也可以指定位置插入,流程跟上述差不多一致,但是有個雙Copy操作:
- 加鎖,獲取容器數組
- 下標校驗
- 如果正好是尾部插入:創建一個長度+1 的新數組,并把之前數組的數據復制過去
- 不是尾部:需要復制兩次,總的來說就是下標前的數據照舊復制,下標后的數據復制后,整體位置往后移一位
- 然后新數組尾部賦值,并把新數組重新賦值給容器數組
源代碼如下:
public void add(int index, E element) {final ReentrantLock lock = this.lock;// 加鎖lock.lock();try {// 獲取容器數組Object[] elements = getArray();// 獲取容器數組長度int len = elements.length;// 下標校驗if (index > len || index < 0)throw new IndexOutOfBoundsException("Index: "+index+", Size: "+len);Object[] newElements;int numMoved = len - index;if (numMoved == 0)// 如果正好是尾部 則照舊創建并復制newElements = Arrays.copyOf(elements, len + 1);else {// 不是尾部則創建一個長度+1 的新數組newElements = new Object[len + 1];// 依舊是復制 但這里復制了兩次 // 0-index的元素復制一次 位置不變System.arraycopy(elements, 0, newElements, 0, index);// index-尾部的元素復制一次 整體位置都后移一位System.arraycopy(elements, index, newElements, index + 1,numMoved);}// 指定位置賦值newElements[index] = element;// 把新數組重新賦值給容器數組setArray(newElements);} finally {lock.unlock();}}
四、get操作
很簡單先獲取容器數組,然后根據數組下標取值就好
容器數組是volatile修飾的,所以本身get就是線程安全的,始終獲取的最新值
源代碼如下:
public E get(int index) {return get(getArray(), index);
}
final Object[] getArray() {return array;
}private E get(Object[] a, int index) {return (E) a[index];
}
五、set操作
這個我在ArrayList里面沒有介紹,因為很簡單就是替換數組下標原本的值即可
這里提一下是因為此操作也是線程安全的上了鎖:
- 加鎖,獲取下標對應的舊值
- 對比新值和舊值,值一樣則不作任何操作
- 值不一樣則創建個新的數組,然后再修改下標的值,再把新數組回寫
源代碼如下:
public E set(int index, E element) {final ReentrantLock lock = this.lock;lock.lock();try {// 獲取容器數組Object[] elements = getArray();// 獲取原本的舊值E oldValue = get(elements, index);// 對比新值和舊值if (oldValue != element) {int len = elements.length;// 值不一致 則創建個新數組,把數據復制過去Object[] newElements = Arrays.copyOf(elements, len);// 修改新數組對應下標下的值newElements[index] = element;// 把新數組寫回setArray(newElements);} else {// 新值舊值一樣 就不做任何操作 ,把數組寫回去就好了setArray(elements);}return oldValue;} finally {lock.unlock();}
}
六、remove操作
根據值remove
- 先遍歷查找元素下標所在
- 然后加鎖,判斷下標是否有效,無效需要重新找一次下標,沒找到直接返回false
- 找到了下標然后創建長度-1的新數組,雙copy,然后回寫到容器數組
總的邏輯不復雜,跟常規的list一樣,先查再移除,但由于第一次查找的時候并沒有加鎖,所以第一次找到的下標到移除的過程中數組可能已經發生了修改,下標會失效,所以在真正移除的時候加鎖之后又判斷了一次下標的有效性
為什么不直接加鎖然后在查找下標后移除呢?
當然也可以,但是加鎖會阻塞其他的操作,等于是在遍歷查找的時候其他操作就全被阻塞了,但是現在這樣假設數組沒被修改,則直接雙copy移除了,相比更優,假設數組被修改,無非就是再重新遍歷一次,從效率上來講多遍歷了一次,效率低了,從阻塞上來看都一樣是遍歷+雙copy,所以綜合來說這種設計側重于使用場景
源代碼如下:
public boolean remove(Object o) {// 獲取容器數組Object[] snapshot = getArray();// 遍歷查找元素所在的下標索引int index = indexOf(o, snapshot, 0, snapshot.length);// 根據索引移除return (index < 0) ? false : remove(o, snapshot, index);
}private boolean remove(Object o, Object[] snapshot, int index) {final ReentrantLock lock = this.lock;lock.lock();try {// 獲取當前最新的容器數組Object[] current = getArray();int len = current.length;// 判斷傳入的數組是否與當前數組相同 如果不相同則需要判斷傳入index下標的有效性if (snapshot != current) findIndex: {//得到遍歷范圍最小值,這個范圍不一定能找到元素,當元素被后移時//注意index是索引,len是數組大小。int prefix = Math.min(index, len);for (int i = 0; i < prefix; i++) {//嚴格的判斷。只有當兩個數組相同索引位置的元素不是同一個元素;//且current索引元素和參數o 是相等的時候 則重新獲取賦值index 退出分支if (current[i] != snapshot[i] && eq(o, current[i])) {index = i;break findIndex;}}// 下標已經超過或等于長度 則下標已經無效了 直接返回if (index >= len)return false;// 下標依舊有效并且值相等則 退出分支if (current[index] == o)break findIndex;// 上面都不滿足則重新查找一次下標index = indexOf(o, current, index, len);// 不存在了則直接返回if (index < 0)return false;}// 經過上面一頓操作 已經找到了要移除元素的下標了,所以創建個長度-1的新數組Object[] newElements = new Object[len - 1];// 雙復制 與之前一樣 ,index后面的元素需要往前移System.arraycopy(current, 0, newElements, 0, index);System.arraycopy(current, index + 1, newElements, index, len - index - 1);// 新數組賦值給容器數組setArray(newElements);return true;} finally {lock.unlock();}}
根據下標remove
這個和根據下標add操作有點類似:
- 判斷下標是不是尾部,是尾部則直接Arrays.copyOf
- 不是尾部則雙arraycopy,index后的數據要整體前移一位
源代碼如下:
public E remove(int index) {final ReentrantLock lock = this.lock;lock.lock();try {// 獲取容器數組Object[] elements = getArray();int len = elements.length;// 獲取舊值E oldValue = get(elements, index);int numMoved = len - index - 1;if (numMoved == 0)// 如果是尾部則直接創建長度-1的數組再復制過去 setArray(Arrays.copyOf(elements, len - 1));else {// 不是尾部 則雙copy ,index后的數據整體前移一位Object[] newElements = new Object[len - 1];System.arraycopy(elements, 0, newElements, 0, index);System.arraycopy(elements, index + 1, newElements, index,numMoved);setArray(newElements);}return oldValue;} finally {lock.unlock();}}
總結
從上面可以看出CopyOnWriteArrayList是線程安全的,是volatile和lock來保證的,但是也很明顯的可以看出弊端就是對修改的效率不高,每個修改都涉及到copy操作,甚至還有兩次copy的,而且每個修改都是在新的數組中進行的,這也應對了CopyOnWrite這個命名;就因為寫的效率不高,所以這個更適合在讀多寫少的場景中使用






)









)


