一、TL;DR
- MLLM在感知方面存在不足(遠遠比不上專家模型),比如Qwen2-VL在coco上recall只有43.9%
- 提出了ChatRex,旨在從模型設計和數據開發兩個角度來填補這一感知能力的缺口
- ChatRex通過proposal邊界框輸入到LLM中將其轉化為retrieval任務
- 構建了一個data-engine,提出了Rexverse-2M數據集,支持了感知和理解的聯合訓練。
二、簡要介紹
為什么要開發本文方法?
- MLLM缺乏細粒度的感知能力,特別是在目標檢測方面。Qwen2-VL-7B在IoU閾值為0.5時僅達到了43.9%的recall
為什么出現這種情況?
MLLMs中感知和理解之間的性能差距主要源于兩個因素:
- 感知和理解這兩個任務之間的建模沖突
- 缺乏能夠平衡感知和理解的數據。
對于目標檢測,一種常見的做法是將邊界框坐標量化為LLM詞匯表中的token,以適應自回歸框架。盡管這通過next token預測確保了與理解任務的兼容性,但我們認為這種方法與準確建模感知存在沖突,原因有三:
- 錯誤傳播:表示一個邊界框通常需要9個token,包括數字、方括號和逗號,其中任何一個標記的錯誤都可能導致級聯錯誤,在多目標檢測中情況會變得更糟。在后續實驗中,我們發現這是召回率低的原因之一;
- 預測順序的模糊性:在目標感知中,物體之間沒有固有的順序,然而自回歸的特性卻強加了一個順序,LLM必須決定先預測哪個物體;
- 量化范圍限制:當圖像尺寸較大時,容易出現量化誤差。
ChatRex怎么解決?
對于像圖像描述和圖像問答這樣的多模態理解任務,我們保留了自回歸文本預測框架。對于感知,特別是目標檢測,將其轉變為一個基于檢索的任務。
具體來說,直接將邊界框作為輸入提供,每個邊界框通過將其RoI feature與其位置embedding相結合來表示為一個對象token。當LLM需要引用一個物體時,它輸出相關邊界框的索引。這種方法將每個邊界框表示為一個未量化的單一token,其順序由輸入的邊界框決定,有效地解決了之前的建模沖突。
使用這種方法有兩個關鍵挑戰:
- 需要高分辨率的視覺輸入:雙視覺編碼器設計,增加了一個額外的視覺編碼器,為感知提供高分辨率的視覺信息
- 一個強大的目標proposal模型:引入了一個通用提議網絡(UPN),它在預訓練的開放集目標檢測模型上利用基于粒度的提示學習。這使得能夠生成覆蓋多樣化粒度、類別和領域的proposal,從而為LLM提供強大的邊界框輸入。
從數據角度來看:
- 當前的MLLMs也受到缺乏能夠有效平衡感知和理解的數據的限制。
- 開發了一個完全自動化的數據引擎,構建了Rexverse-2M數據集,該數據集包含不同粒度級別的圖像-區域-文本注釋三元組。
- 數據引擎由三個主要模塊組成。第一個模塊為輸入圖像生成圖像描述,第二個模塊使用一個基礎模型對引用的對象或短語進行對齊,第三個模塊在多個粒度級別上細化區域描述。
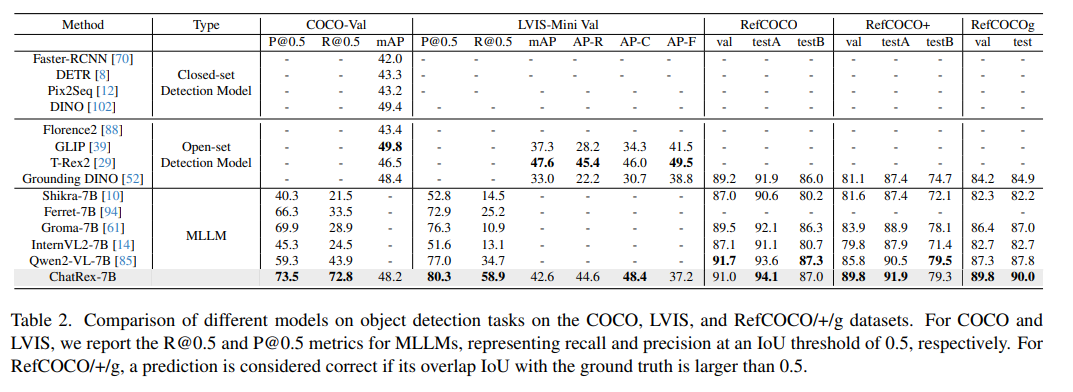
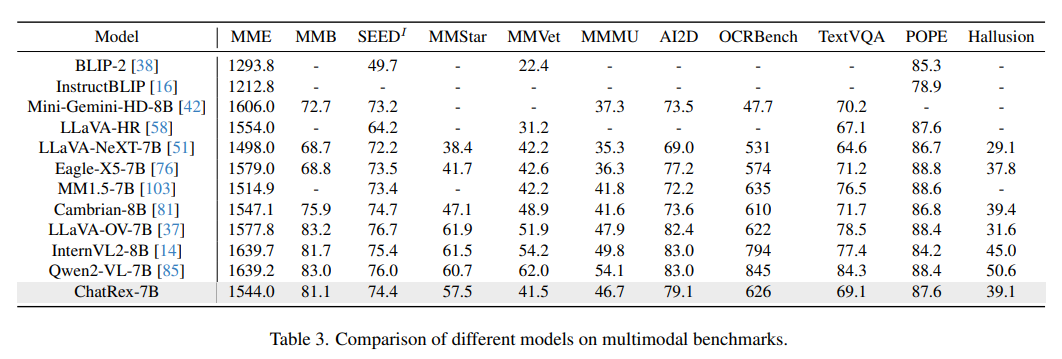
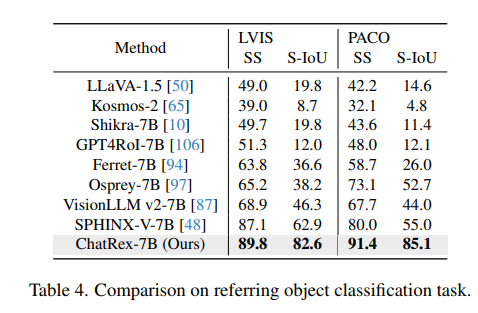
實驗結果表明,ChatRex在目標檢測任務中表現出色,包括COCO、LVIS和RefCOCO/+/g,同時在多模態基準測試中也展現出具有競爭力的性能。如圖1所示。
 三個主要貢獻:
三個主要貢獻:
-
揭示了MLLMs在感知方面的性能差距,并引入了解耦的模型ChatRex和通用提議網絡(UPN),以解決感知和理解之間的建模沖突。
-
開發了一個自動化數據引擎,創建了Rexverse-2M,這是一個全面支持感知和理解任務的數據集,用于模型訓練。
-
實驗結果表明,ChatRex展現出強大的感知和多模態理解能力,強調了這兩種互補能力對于MLLM來說都是必不可少的。
三、模型結構
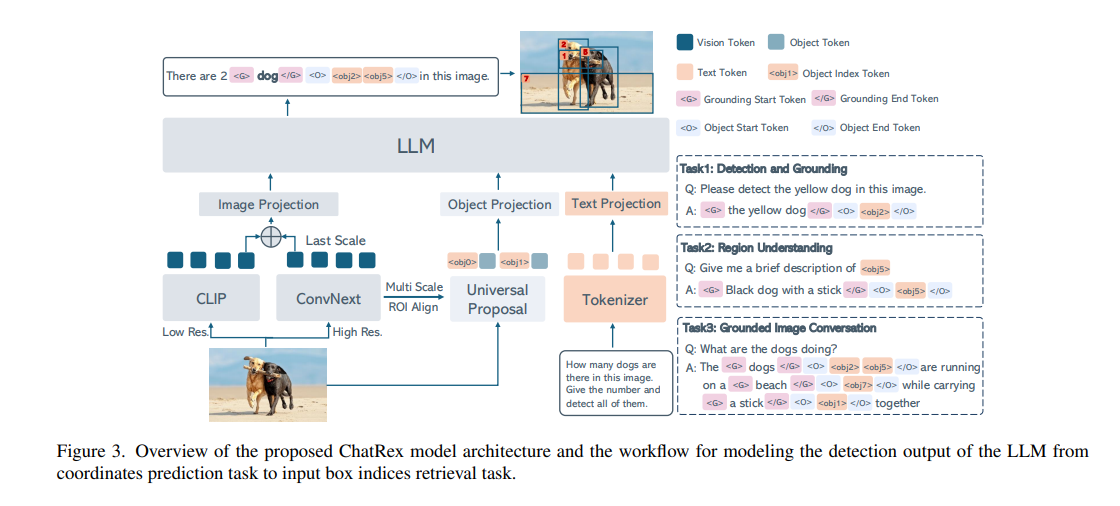
ChatRex 采用了一種將感知與理解解耦的設計(注意后面的訓練策略)。
- 對于感知部分,我們訓練了一個通用proposal網絡來檢測任意物體,并為 LLM 提供邊界框輸入。
- 對于理解部分,我們采用了標準的 LLaVA ?結構,并引入雙視覺編碼器以實現高分辨率圖像編碼。
3.1 通用提議網絡(UPN)
要求proposal模型具備兩個關鍵特性:
- 強大的泛化能力,能夠在任何場景中為任意物體生成提議框;
- proposal框應全面,涵蓋實例級和部件級的物體。
我們采用了雙粒度提示調整策略(直接采用多數據集合并不行,由于其標注規則不一樣):
具體來說,我們以 T-Rex2 作為基礎模型。該模型輸出目標查詢 Qdec,這些查詢通過一個 MLP 來預測邊界框。這些邊界框的分類是通過查詢和提示嵌入 E 之間的點積來實現的:
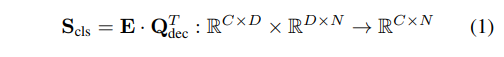
其中,C 表示類別數量,N 表示檢測查詢的數量(默認為 900),D 是輸出查詢的通道維度。我們通過引入兩個額外的可學習提示 Pfine 和 Pcoarse,并將它們連接成 Pconcat 來將邊界框分類為細粒度或粗粒度類別:
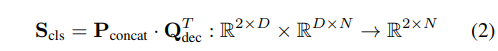
在訓練過程中,我們使用 SA-1B 作為細粒度數據集,其他檢測數據集(如 COCO 和 O365)作為粗粒度輸入。這種雙粒度提示設計有效地解決了不同數據集之間的標注歧義問題,使提議模型能夠準確地捕捉和描述不同細節級別的物體。
3.2 多模態大語言模型架構
雙視覺編碼器:如圖 3 所示,我們使用 CLIP 中的 ViT 進行低分辨率圖像編碼,使用 LAION ?中的 ConvNeXt 進行高分辨率圖像編碼。
為了減少輸入到 LLM 的視覺標記數量,我們首先調整兩個視覺編碼器的輸入分辨率,確保它們在最后一個尺度上生成相同數量的標記。然后,我們將這兩個標記直接沿著通道維度連接起來,產生與低分辨率標記數量相同的標記。
目標編碼器:我們將通用提議網絡輸出的每個邊界框編碼為目標標記,并將它們輸入到 LLM 中。
假設從 UPN 輸入 K 個邊界框 {Bi}i=1K,令 FH 表示高分辨率編碼器產生的多尺度視覺特征,對于每個邊界框 Bi,我們使用多尺度 RoI Align ?提取其內容特征 Ci:
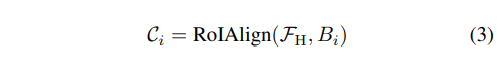
由于 RoI 特征不包含位置信息,而位置信息對于指代任務至關重要,我們通過正弦-余弦位置嵌入層對每個邊界框坐標進行編碼,并將其添加到 RoI 特征中:
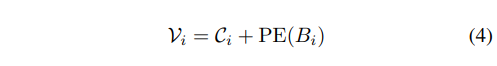
LLM:使用兩個單獨的 MLP 投影器將視覺和目標token映射到文本空間。我們還在每個目標標記中添加一個索引標記,以告知 LLM 每個目標標記的索引,具體將在第 3.3 節中描述。
視覺token隨后與文本token連接起來,并輸入到 LLM 中進行下一個token預測任務。我們默認使用 Qwen2.5-7B 作為我們的 LLM。
3.3 任務定義
將利用 LLM 進行檢測的任務定義為對輸入邊界框的索引選擇過程。為此,我們首先通過引入專用token來擴展 LLM 的詞匯表,包括目標索引標記 <obj0>、<obj1>、...、<objN>(其中 N 表示輸入邊界框的最大數量,在本工作中設置為 100),基礎token<g>、結束token</g>、目標開始token<o> 和目標結束token</o>。
LLM 輸入格式:LLM 的輸入標記序列結構如下:
![]()
其中,<image> 表示視覺編碼器的視覺token,<roi> 表示與每個相應邊界框相關聯的目標特征。每個 <roi> token都以其相應的目標索引標記作為前綴。
解耦的任務定義:LLM 產生的檢測結果使用以下名詞短語和邊界框索引的組合來構建:
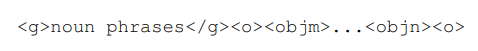
其中,<objm> 和 <objn> 指代特定的目標索引 token, token與名詞短語相關聯的檢測到的物體序列的起始(m)和結束(n)。這種結構化的格式使得名詞短語與其對應的邊界框索引之間能夠實現精確的映射。
憑借這種輸入輸出模式,ChatRex 能夠處理各種任務,例如檢測、基礎定位、區域理解以及基礎對話,除了生成純文本響應之外,如圖 3 所示。
4. 數據和訓練
本文目標是為了構建一個可以有效用于感知和理解任務的數據集,最終構建了一個包含兩百萬張標注圖像的 RexVerse-2M 數據集,其多粒度標注是通過一個完全自動化的數據引擎生成的。然后,我們采用 LLaVA 中的標準兩階段訓練方法,使模型在保留感知能力的同時逐步獲得多模態理解和對話技能。
4.1 RexVerse-2M 數據引擎
我們的目標是。為了實現這一目標,我們的數據管道專注于生成包含圖像描述、區域描述和邊界框的標注三元組。如圖 4 所示,數據引擎圍繞三個核心模塊構建:圖像描述、目標定位和區域描述。
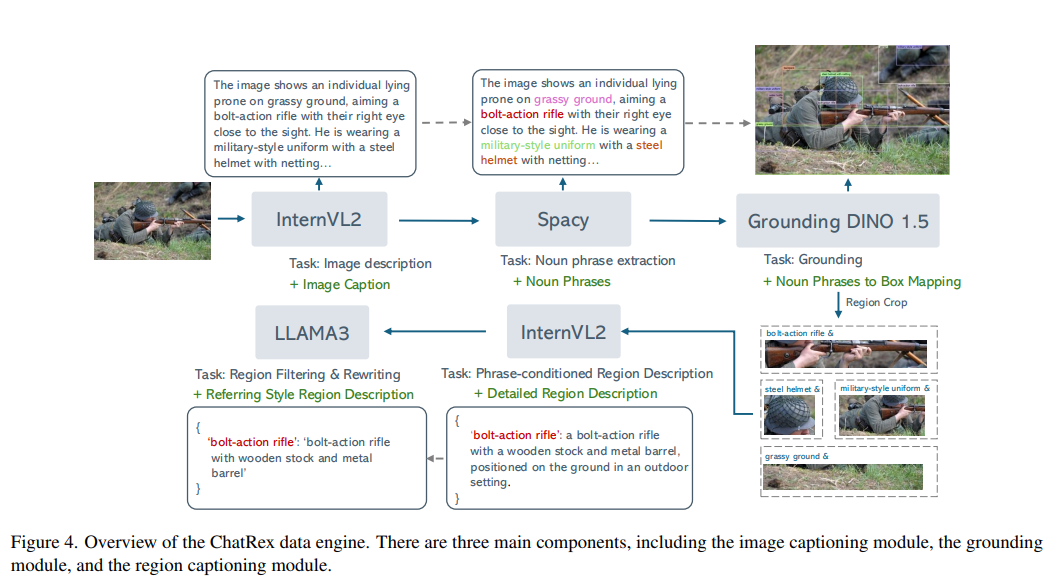
圖像收集:我們從 COYO700M 數據集中收集圖像,通過一系列過濾過程,包括移除分辨率小和帶有 NSFW 標簽的圖像。我們還訓練了一個圖像分類器,以過濾掉具有純白色背景的低內容網絡圖像。最后,我們選擇了兩百萬張圖像作為數據集圖像。
圖像描述:我們使用 InternVL2-8B 為每張圖像生成圖像描述。這些圖像描述將通過類別名稱或描述性短語引用圖像中的主要物體。
短語定位:然后,我們利用 SpaCy 從生成的圖像描述中提取名詞短語。根據描述,SpaCy 可能會識別出類別名稱,如“士兵”,或者描述性短語(每個區域至少 3 個單詞),如“軍裝風格的制服”。我們還將過濾掉一些可能不是物體的抽象名詞,如“圖像”“背景”等。隨后,我們使用 Grounding DINO 1.5 對過濾后的名詞短語進行定位。這一過程最終產生與它們的類別名稱或簡短短語描述相關聯的邊界框。
短語條件區域描述:類別名稱或簡短短語通常提供的信息有限,們實現了一種短語條件的圖像描述策略,利用 InternVL2-8B 模型 生成與每個區域相關的預定義短語相條件化的圖像描述。通過這些短語引導模型,我們確保生成的描述更加準確且與上下文相關,提高caption質量
區域描述過濾與重寫:最后,使用 LLaMA3-8B 來驗證生成的描述是否準確地與它們的原始類別名稱或簡短短語對齊,過濾掉任何剩余的幻覺輸出。驗證后,我們進一步提示模型將這些詳細的描述精煉為更簡潔的指代表達式,從而增強指代任務的訓練效果。
Rexverse-2M 數據集:
-
210 萬張帶有描述的圖像;
-
1020 萬個標注了類別標簽的區域;
-
250 萬個標注了簡短短語的區域;
-
250 萬個帶有詳細描述的區域;
-
240 萬個帶有指代表達式的區域。
此外,我們還使用這個數據引擎為 ALLaVA-4V-Instruct 數據集中的 776K 條基礎對話數據進行了標注,用于指令調優。具體來說,我們將對話響應視為圖像描述,然后通過該引擎進行處理。
4.2 訓練策略
4.2.1 UPN 訓練
我們使用兩類帶有邊界框的數據集來訓練我們的通用提議網絡(UPN):
- 粗粒度數據集,包括 O365 、OpenImages、Bamboo、COCO、LVIS 、HierText 、CrowdHuman、SROIE 和 EgoObjects ;
- 細粒度數據集 SA-1B 。
所有數據集的類別被定義為粗粒度或細粒度,將任務簡化為一個二分類問題。遵循 T-Rex2 的方法,我們使用匈牙利匹配來匹配預測和真實標簽。我們采用 L1 損失和 GIOU 損失來進行邊界框預測,并使用 sigmoid 焦點損失進行分類。
4.2.2 ChatRex 訓練任務
我們采用三個主要任務來訓練 ChatRex,包括:
-
基礎定位:模型根據給定的類別名稱、短語或指代表達式輸出對應物體的索引。
-
區域理解:給定區域索引,模型生成不同詳細程度的描述,包括類別名稱、簡短短語、詳細描述或指代表達式。
-
基礎圖像對話:模型需要輸出在其生成的對話輸出中提到的物體的索引。我們將當前圖像的真實邊界框與 UPN 提出的邊界框混合,并最多保留 100 個邊界框作為輸入。
我們采用三階段訓練過程,每個階段的數據如表 1 所示。

-
第一階段:對齊訓練。在第一階段,目標是將視覺特征和目標特征與文本特征空間對齊。為此,我們訓練圖像投影 MLP、目標投影 MLP,以及 LLM 的輸入和輸出嵌入,因為我們已經為其詞匯表添加了特殊標記。
-
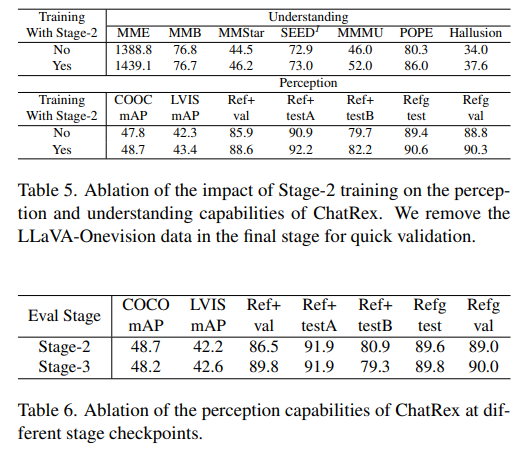
第二階段:感知訓練。在這一階段,我們通過在 Rexverse-2M 和其他基礎數據上訓練 ChatRex 來提升其感知能力。在這個階段,所有參數都是可訓練的。
-
第三階段:聯合訓練。在這一階段,我們將感知和理解任務整合到一個統一的訓練過程中,確保 ChatRex 獲得這兩種能力。這種聯合優化使模型具備全面的多模態能力,并實現感知與理解之間的相互增強。
五、Experiments





】解鎖家政平臺國際化密碼:多語言支持開發實戰)


![生物化學筆記:醫學免疫學原理15 超敏反應過敏反應(I型[蚊蟲叮咬]+II型[新生兒溶血癥、突眼型甲亢]+III型+IV型)](http://pic.xiahunao.cn/生物化學筆記:醫學免疫學原理15 超敏反應過敏反應(I型[蚊蟲叮咬]+II型[新生兒溶血癥、突眼型甲亢]+III型+IV型))



)

.zip)



?哪個大模型更好用?)
